Marvin Minsky "The Emotion Machine": Chapter 5 "Imagination"
How to bring "human" technology and how technology helps to understand and improve and scale the "human"?
This will help us harsh Marvin Minsky, who with his merciless mind analyzes feelings, emotions, pain, love and consciousness.

')
When Carol picks up one of the blocks, this action seems incredibly simple for her: she simply reaches for the block, takes it and picks it up. She sees the block and just starts acting. It seems that there is no “thinking” here.
However, the seeming "simplicity" of the world around us is an illusion that stems from our inability to sense its complexity. For, much of what we see stems from our knowledge and imagination. Thus, consider the portrait of Abraham Lincoln, made by my old friend Leon Harmon - a pioneer in the field of computer graphics. (On the left is a portrait that I made from Leon)

How do you define such unexpressed features, such as the nose or eyes, which represent only three or four points of light and dark colors in the photo shown? Obviously, you do this thanks to your additional knowledge. For example, when you sit at a table in front of your friends, you do not see either their legs or their backs, but your knowledge-based internal brain system implies the presence of these hidden details by default. Thus, we take our perceptual talents for granted, and our “vision of the world” seems simple to us only because the rest of the mind is unaware of the processes that we use to perceive visual images.
In 1965, our goal was to develop machines that could do some things that most children could do, such as pouring liquid into cups, creating arches and towers from an irregular set of building blocks. [5] For this, we created various mechanical hands and electronic eyes and connected it all to our computers.
When we built the first robot that could operate with building blocks, he made hundreds of all sorts of mistakes. [6] He tried to put blocks on top of the blocks themselves, or tried to put two blocks in the same place, because he did not have any adequate knowledge to manipulate physical objects! Even now, no one has ever created a visual system that would behave in the same way as the human visual system. But in the end, our army of students developed programs that could “see” the arrangement of wooden bars so distinctly that the computer could conclude that there was “a horizontal block that lies on two other blocks” in front of it.

It took us several years to create a robot, called the Builder, who could do a variety of work - for example, build arches and tower blocks, which he took from a pile of children's cubes after he was shown a solution based on a computer. We encountered problems at every stage of the creation of this robot, but sometimes defective programs started working when we collected them into a sequence of different levels of execution. (Note that they are not similar to Model Six, but are built from concrete to abstract.)
Start with the image of individual points
Define their textures and edges, etc.
Group them into regions and forms
Connect them into possible objects
Try to associate them with familiar things.
Describe their spatial relationship

However, these low-level stages often can not find a sufficient number of features used. Look at a fragment of this enlarged image, which shows the front upper part of the arch.

The edge of the block is extremely difficult to see, because the two adjacent regions have almost the same texture. [7] We tried hundreds of different ways to define edges, none of the methods worked adequately alone. As a result, we got the best results when we were able to combine these methods. And we had the same at each of the levels under consideration: none of the methods used is sufficient, but the assembly of methods helped to resolve various situations. However, in the end, this step-by-step model was unsuccessful, because the Builder made too many mistakes. We concluded that this was due to the fact that the information in our system flowed straight from the input to the output, and if any of the systems made a mistake, there was not a single chance to correct it. To resolve this problem, we have added many “downstream” paths, thus forcing information to flow in both directions.

The same applies to the actions that we commit, because when we want to change the situation in which we find ourselves - we need to have plans for our further actions, so all these actions are related to the “That” rules. For example, the rule: “If you see a block, then pick it up” leads to a complex set of actions: before you begin to lift the block, you need to make a plan for the movement of your shoulder, arm and palm in order to do this without affecting other objects. Therefore, it is again necessary to use high-level processes, and creating plans should be used for multiple levels of information processing, so our diagram should look like this:

Each action planner responds to a specific episode by composing a sequence of Motor Actions, each of which performs a specific Motor Skill, for example: “reach”, “take”, “lift” and “move”. Each Motor Action is an expert in controlling the actions of certain muscles and joints, therefore, what at the beginning usually seemed to be the Responsive Machine turned into a large and complex system, in which each “If” and “That” involves numerous steps and processes at each stage signaling in both the downstream and the upstream.
In early times, the most common view was the view that our visual systems work in an “ascending” direction, first distinguishing the low-level features of objects, and then putting together separate images and forms, which allowed them to recognize whole objects. However, in recent years it has become clear that our expectations at higher levels affect how information is processed at lower levels.
V.S. Ramachandran: [Most old models of perception] are based on the discredited model of the “team brigade”, a consistent hierarchical model that attributes our aesthetic taste only to the last level of perception. In my opinion ... at each stage of the visual segmentation to the final "Aha" there are many small stages. Indeed, the very act of perception, a group of objects, can correlate with the resolution of the puzzle. Art, in other words, is a visual prelude before the final culmination of recognition. ” [eight]
In fact, we now know that the visual systems in our brain receive a huge amount of signals from the rest of the brain, and not just from our eyes.
Richard Gregory: “Such an important contribution of accumulated knowledge to the field of perception is consistent with the discovery of a large number of downward paths in the brain. About 80% of nerve fibers descend onto the lateral geniculate nucleus descend from the cortex, and only 20% of the nerve fibers go to this nucleus from the retina. ”
Presumably, these signals indicate what features of objects we can detect in objects that are in our area of visibility. Thus, as soon as you start thinking that you are in the kitchen, you are more likely to perceive various objects as saucers and cups.
All this suggests that the highest levels of the brain never perceive the world around us as a set of pigment spots, instead, your resources describing a picture should represent the above-described block arch in terms of (for example) "Horizontal block over vertical". Without the use of such high-level descriptions, the “If” rules are very rarely practical.
Accordingly, in order for the Builder to use sensory signals, he needed to know what the data meant, so we then gave an idea of the objects used to the Builder. Then, assuming that something was made of rectangular blocks, one of these programs could often "determine" which block appeared in its field of view, based only on its silhouette! The builder could do things like this because of similar judgments:

As soon as the program determined some of the edges of the shape, it began to represent even more parts of the blocks to which these edges belong, and using this knowledge, the program began to search for even more necessary values, repeating the cycle described above. At this stage, the program was already much better than the researchers who programmed it. [10]
We also gave the Builder additional knowledge about the most common "concepts" of the words angle and edge. For example, if the program found an edge, then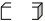 she could assume that this edge belongs to a certain figure. The program then tried to find this shape and identify its remaining edges. [11]
she could assume that this edge belongs to a certain figure. The program then tried to find this shape and identify its remaining edges. [11]
Our low-level systems look at a large number of fragments, but then we use the “context” to determine what these fragments mean, and then confirm our guesses using some intermediate level processes. In other words, we “recognize” (re-cognize) things by “remembering” them and relating them to familiar objects that can relate to the presented fragments. But we still don’t know enough about how our high-level expectations affect how low-level systems recognize the world around us. For example, why do we not see that the middle figure presented below has the same shape as its neighbors?

In an excellent overview of this issue, Zenon Pilishin describes several theories that can describe a similar phenomenon, but he comes to the conclusion that we still have a lot to learn. [12]
For the translation, thanks to Stanislav Sukhanitsky. Who wants to help with the translation - write in a personal or mail magisterludi2016@yandex.ru

Marvin Lee Minsky (Eng. Marvin Lee Minsky; August 9, 1927 - January 24, 2016) - American scientist in the field of artificial intelligence, co-founder of the Laboratory of artificial intelligence at the Massachusetts Institute of Technology. [ Wikipedia ]
Interesting Facts:
This will help us harsh Marvin Minsky, who with his merciless mind analyzes feelings, emotions, pain, love and consciousness.
')
§5-7. Imagination
“We do not see things as they are. We see things as we see them. ”
- Anais Nin
When Carol picks up one of the blocks, this action seems incredibly simple for her: she simply reaches for the block, takes it and picks it up. She sees the block and just starts acting. It seems that there is no “thinking” here.
However, the seeming "simplicity" of the world around us is an illusion that stems from our inability to sense its complexity. For, much of what we see stems from our knowledge and imagination. Thus, consider the portrait of Abraham Lincoln, made by my old friend Leon Harmon - a pioneer in the field of computer graphics. (On the left is a portrait that I made from Leon)
How do you define such unexpressed features, such as the nose or eyes, which represent only three or four points of light and dark colors in the photo shown? Obviously, you do this thanks to your additional knowledge. For example, when you sit at a table in front of your friends, you do not see either their legs or their backs, but your knowledge-based internal brain system implies the presence of these hidden details by default. Thus, we take our perceptual talents for granted, and our “vision of the world” seems simple to us only because the rest of the mind is unaware of the processes that we use to perceive visual images.
In 1965, our goal was to develop machines that could do some things that most children could do, such as pouring liquid into cups, creating arches and towers from an irregular set of building blocks. [5] For this, we created various mechanical hands and electronic eyes and connected it all to our computers.
When we built the first robot that could operate with building blocks, he made hundreds of all sorts of mistakes. [6] He tried to put blocks on top of the blocks themselves, or tried to put two blocks in the same place, because he did not have any adequate knowledge to manipulate physical objects! Even now, no one has ever created a visual system that would behave in the same way as the human visual system. But in the end, our army of students developed programs that could “see” the arrangement of wooden bars so distinctly that the computer could conclude that there was “a horizontal block that lies on two other blocks” in front of it.
It took us several years to create a robot, called the Builder, who could do a variety of work - for example, build arches and tower blocks, which he took from a pile of children's cubes after he was shown a solution based on a computer. We encountered problems at every stage of the creation of this robot, but sometimes defective programs started working when we collected them into a sequence of different levels of execution. (Note that they are not similar to Model Six, but are built from concrete to abstract.)
Start with the image of individual points
Define their textures and edges, etc.
Group them into regions and forms
Connect them into possible objects
Try to associate them with familiar things.
Describe their spatial relationship
However, these low-level stages often can not find a sufficient number of features used. Look at a fragment of this enlarged image, which shows the front upper part of the arch.
The edge of the block is extremely difficult to see, because the two adjacent regions have almost the same texture. [7] We tried hundreds of different ways to define edges, none of the methods worked adequately alone. As a result, we got the best results when we were able to combine these methods. And we had the same at each of the levels under consideration: none of the methods used is sufficient, but the assembly of methods helped to resolve various situations. However, in the end, this step-by-step model was unsuccessful, because the Builder made too many mistakes. We concluded that this was due to the fact that the information in our system flowed straight from the input to the output, and if any of the systems made a mistake, there was not a single chance to correct it. To resolve this problem, we have added many “downstream” paths, thus forcing information to flow in both directions.
The same applies to the actions that we commit, because when we want to change the situation in which we find ourselves - we need to have plans for our further actions, so all these actions are related to the “That” rules. For example, the rule: “If you see a block, then pick it up” leads to a complex set of actions: before you begin to lift the block, you need to make a plan for the movement of your shoulder, arm and palm in order to do this without affecting other objects. Therefore, it is again necessary to use high-level processes, and creating plans should be used for multiple levels of information processing, so our diagram should look like this:
Each action planner responds to a specific episode by composing a sequence of Motor Actions, each of which performs a specific Motor Skill, for example: “reach”, “take”, “lift” and “move”. Each Motor Action is an expert in controlling the actions of certain muscles and joints, therefore, what at the beginning usually seemed to be the Responsive Machine turned into a large and complex system, in which each “If” and “That” involves numerous steps and processes at each stage signaling in both the downstream and the upstream.
In early times, the most common view was the view that our visual systems work in an “ascending” direction, first distinguishing the low-level features of objects, and then putting together separate images and forms, which allowed them to recognize whole objects. However, in recent years it has become clear that our expectations at higher levels affect how information is processed at lower levels.
V.S. Ramachandran: [Most old models of perception] are based on the discredited model of the “team brigade”, a consistent hierarchical model that attributes our aesthetic taste only to the last level of perception. In my opinion ... at each stage of the visual segmentation to the final "Aha" there are many small stages. Indeed, the very act of perception, a group of objects, can correlate with the resolution of the puzzle. Art, in other words, is a visual prelude before the final culmination of recognition. ” [eight]
In fact, we now know that the visual systems in our brain receive a huge amount of signals from the rest of the brain, and not just from our eyes.
Richard Gregory: “Such an important contribution of accumulated knowledge to the field of perception is consistent with the discovery of a large number of downward paths in the brain. About 80% of nerve fibers descend onto the lateral geniculate nucleus descend from the cortex, and only 20% of the nerve fibers go to this nucleus from the retina. ”
Presumably, these signals indicate what features of objects we can detect in objects that are in our area of visibility. Thus, as soon as you start thinking that you are in the kitchen, you are more likely to perceive various objects as saucers and cups.
All this suggests that the highest levels of the brain never perceive the world around us as a set of pigment spots, instead, your resources describing a picture should represent the above-described block arch in terms of (for example) "Horizontal block over vertical". Without the use of such high-level descriptions, the “If” rules are very rarely practical.
Accordingly, in order for the Builder to use sensory signals, he needed to know what the data meant, so we then gave an idea of the objects used to the Builder. Then, assuming that something was made of rectangular blocks, one of these programs could often "determine" which block appeared in its field of view, based only on its silhouette! The builder could do things like this because of similar judgments:
As soon as the program determined some of the edges of the shape, it began to represent even more parts of the blocks to which these edges belong, and using this knowledge, the program began to search for even more necessary values, repeating the cycle described above. At this stage, the program was already much better than the researchers who programmed it. [10]
We also gave the Builder additional knowledge about the most common "concepts" of the words angle and edge. For example, if the program found an edge, then
she could assume that this edge belongs to a certain figure. The program then tried to find this shape and identify its remaining edges. [11]Our low-level systems look at a large number of fragments, but then we use the “context” to determine what these fragments mean, and then confirm our guesses using some intermediate level processes. In other words, we “recognize” (re-cognize) things by “remembering” them and relating them to familiar objects that can relate to the presented fragments. But we still don’t know enough about how our high-level expectations affect how low-level systems recognize the world around us. For example, why do we not see that the middle figure presented below has the same shape as its neighbors?
In an excellent overview of this issue, Zenon Pilishin describes several theories that can describe a similar phenomenon, but he comes to the conclusion that we still have a lot to learn. [12]
For the translation, thanks to Stanislav Sukhanitsky. Who wants to help with the translation - write in a personal or mail magisterludi2016@yandex.ru
Table of Contents of The Emotion Machine
Introduction
Chapter 5. LEVELS OF MENTAL ACTIVITIES
Chapter 6. COMMON SENSE
Chapter 7. Thinking.
Chapter 8. Resourcefulness.
Chapter 9. The Self.
Chapter 1. Falling in Love
Chapter 2. ATTACHMENTS AND GOALS
Chapter 3. FROM PAIN TO SUFFERING
Chapter 4. CONSCIOUSNESSChapter 5. LEVELS OF MENTAL ACTIVITIES
Chapter 6. COMMON SENSE
Chapter 7. Thinking.
Chapter 8. Resourcefulness.
Chapter 9. The Self.
about the author
Marvin Lee Minsky (Eng. Marvin Lee Minsky; August 9, 1927 - January 24, 2016) - American scientist in the field of artificial intelligence, co-founder of the Laboratory of artificial intelligence at the Massachusetts Institute of Technology. [ Wikipedia ]
Interesting Facts:
- Minsky was a friend of critic Harold Bloom from Yale University (Yale University), who spoke of him as “sinister Marvin Minsky”.
- Isaac Asimov described Minsky as one of two people who are smarter than himself; the second, in his opinion, was Karl Sagan.
- Marvin is a robot with artificial intelligence from the cycle of Douglas Adams novels Hitchhiker's Guide to the Galaxy and Hitchhiker's Guide to the Galaxy (film).
- Minsky has a contract to freeze his brain after death in order to be “resurrected” in the future.
- In honor of Minsk named the dog of the protagonist in the movie Tron: Legacy. [ Wikipedia ]
About #philtech
#philtech (technology + philanthropy) is an open, publicly described technology that aligns the standard of living of as many people as possible by creating transparent platforms for interaction and access to data and knowledge. And satisfying the principles of filteha:
1. Opened and replicable, not competitive proprietary.
2. Built on the principles of self-organization and horizontal interaction.
3. Sustainable and prospective-oriented, and not pursuing local benefits.
4. Built on [open] data, not traditions and beliefs.
5. Non-violent and non-manipulative.
6. Inclusive, and not working for one group of people at the expense of others.
Philtech's social technology startups accelerator is a program of intensive development of early-stage projects aimed at leveling access to information, resources and opportunities. The second stream: March – June 2018.
Chat in Telegram
A community of people developing filtech projects or simply interested in the topic of technologies for the social sector.
#philtech news
Telegram channel with news about projects in the #philtech ideology and links to useful materials.
Subscribe to the weekly newsletter
#philtech (technology + philanthropy) is an open, publicly described technology that aligns the standard of living of as many people as possible by creating transparent platforms for interaction and access to data and knowledge. And satisfying the principles of filteha:
1. Opened and replicable, not competitive proprietary.
2. Built on the principles of self-organization and horizontal interaction.
3. Sustainable and prospective-oriented, and not pursuing local benefits.
4. Built on [open] data, not traditions and beliefs.
5. Non-violent and non-manipulative.
6. Inclusive, and not working for one group of people at the expense of others.
Philtech's social technology startups accelerator is a program of intensive development of early-stage projects aimed at leveling access to information, resources and opportunities. The second stream: March – June 2018.
Chat in Telegram
A community of people developing filtech projects or simply interested in the topic of technologies for the social sector.
#philtech news
Telegram channel with news about projects in the #philtech ideology and links to useful materials.
Subscribe to the weekly newsletter
Source: https://habr.com/ru/post/359054/
All Articles