How databases are arranged
This is not to say that in this article you will find selected database introspection, but rather a story about databases from the very beginning, plus a slight digging into some details that Ilya Kosmodemyansky ( @hydrobiont ) seem important. And there is every reason to believe that it is so.
This article was not born of a good life. Often, not even the novice developers, but also quite advanced ones, do not know some basic things - maybe they studied at the university a long time ago and have since forgotten, or they didn’t have to go into the theory, since they worked normally.
However, theoretical knowledge is sometimes useful to refresh . This we, including, and we will do.
')

About the speaker: Ilya Kosmodemyansky CEO and consultant for Data Egret, PostgreSQL, Oracle, DB2 database specialist. And besides, he is responsible for promoting Postgres technologies, speaking at conferences and telling people how to work with them.
Below is the material on Ilya's report on RIT ++ 2017, which was not associated with any particular database, but covered many basic aspects.
What does it need to know for?
Data storage and processing is the mission-critical task of any computer system.
Even if you have already had a blog on text files on the Internet for 30 years, as some database creators have, this text file is actually a database, but very simple.
Everyone is trying to invent a database . One of the speakers at the conference said: “20 years ago I wrote my database, I just didn’t know that it was her!” This trend in the world is very developed. Everyone is trying to do that.
To work with data database is a very handy thing . Many databases are very old technologies. They are being developed for the last half century, in the 70s there were already databases that worked according to similar principles as now.
These databases are very well and thoughtfully written , so now we can choose a programming language and use a general user-friendly data processing interface. Thus, it is possible to process data in a standardized way, without fear that they will be processed in a different way.
It is useful to remember that programming languages are changing : yesterday was Python 2, today is Python 3, tomorrow everyone ran to write on Go, the day after tomorrow on something else. You may have a piece of code that emulates the work of manipulating data, which, in theory, the database should do, and you will not know what to do next.
In most databases, the interface is very conservative . If you take PostgreSQL or Oracle, then with some tambourines you can work even with very old versions from new programming languages - well and great.
But the task is not really the easiest. If we begin to dig in the depths of how we do not “beat” the data, how quickly, efficiently and, most importantly, so that you can trust the result and process it, then it turns out that this is a difficult thing.
If you try to write your own simple persistent storage, everything will just be the first 15 minutes. Then locks and other things will begin, and at some point you will understand: “Oh, why am I doing all this?”
About this and talk.
Levels of working with data
So, there are various levels of work with data:
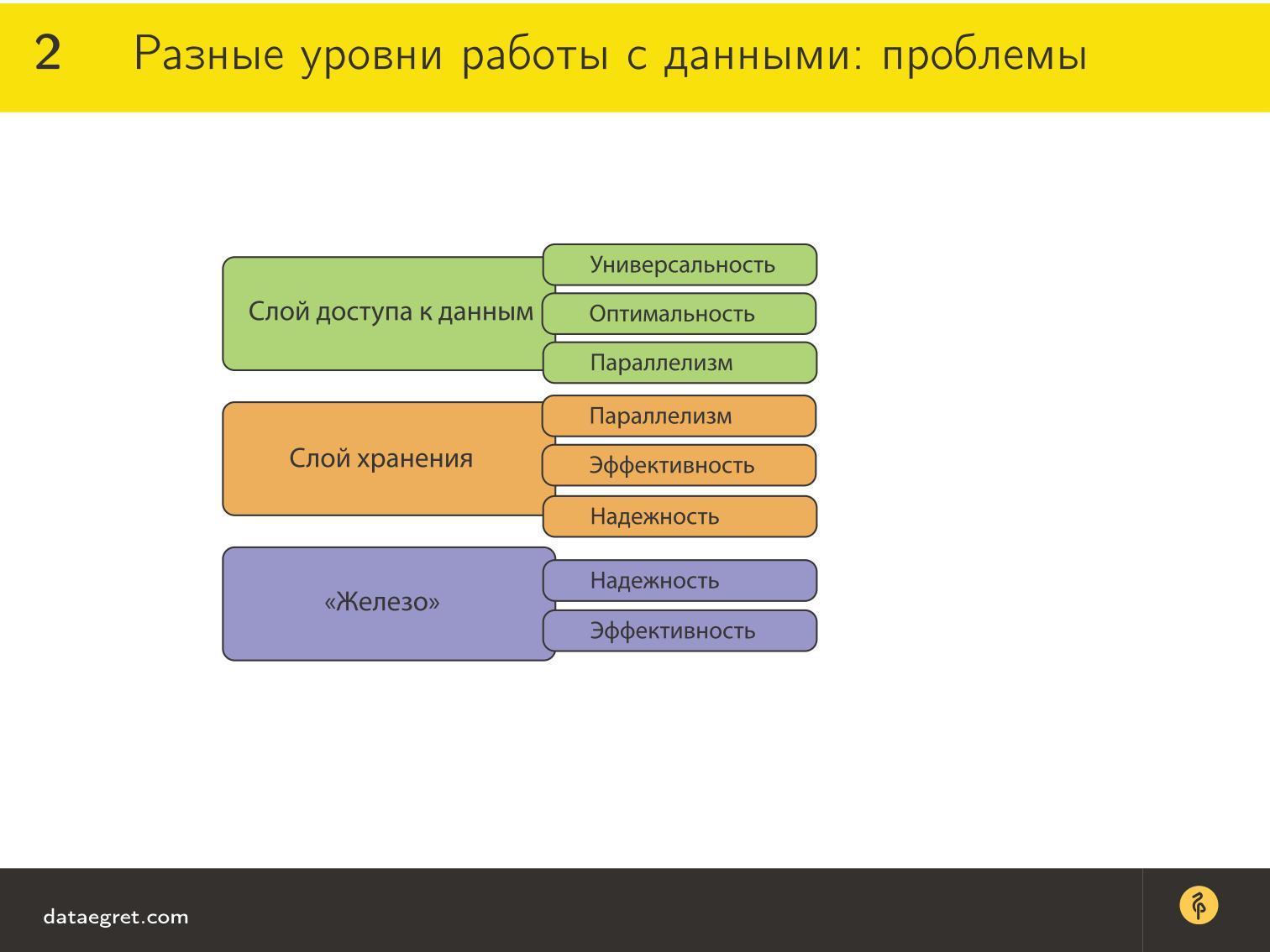
For the data access layer there are requirements that we are interested in fulfilling in order to make it convenient to work:
For the storage layer , it is still important to preserve the original concurrency so that all data is not beaten, overwritten, not truncated, etc.
At the same time, they must be securely stored and reliably reproduced. That is, if we have recorded something in the database, we must be sure that we will get it back.
If you worked with old databases, for example, FoxPro, then you know that there often appear broken data. In new databases, such as MongoDB, Cassandra and others, such problems also occur. Maybe they simply are not always noticed, because there is a lot of data that is harder to notice.
For hardware , reliability is really important. This is a sort of assumption, since we will nevertheless speak about theoretical things. In our model, if something got on the disk, then we think that everything is fine there. How to replace a disk in RAID in time - this is for us admins. We will not dive deep into this question, and practically we will not touch on how efficiently the store is physically organized.
To solve these problems, there are some approaches that are very similar across different data sources - both new and classic.
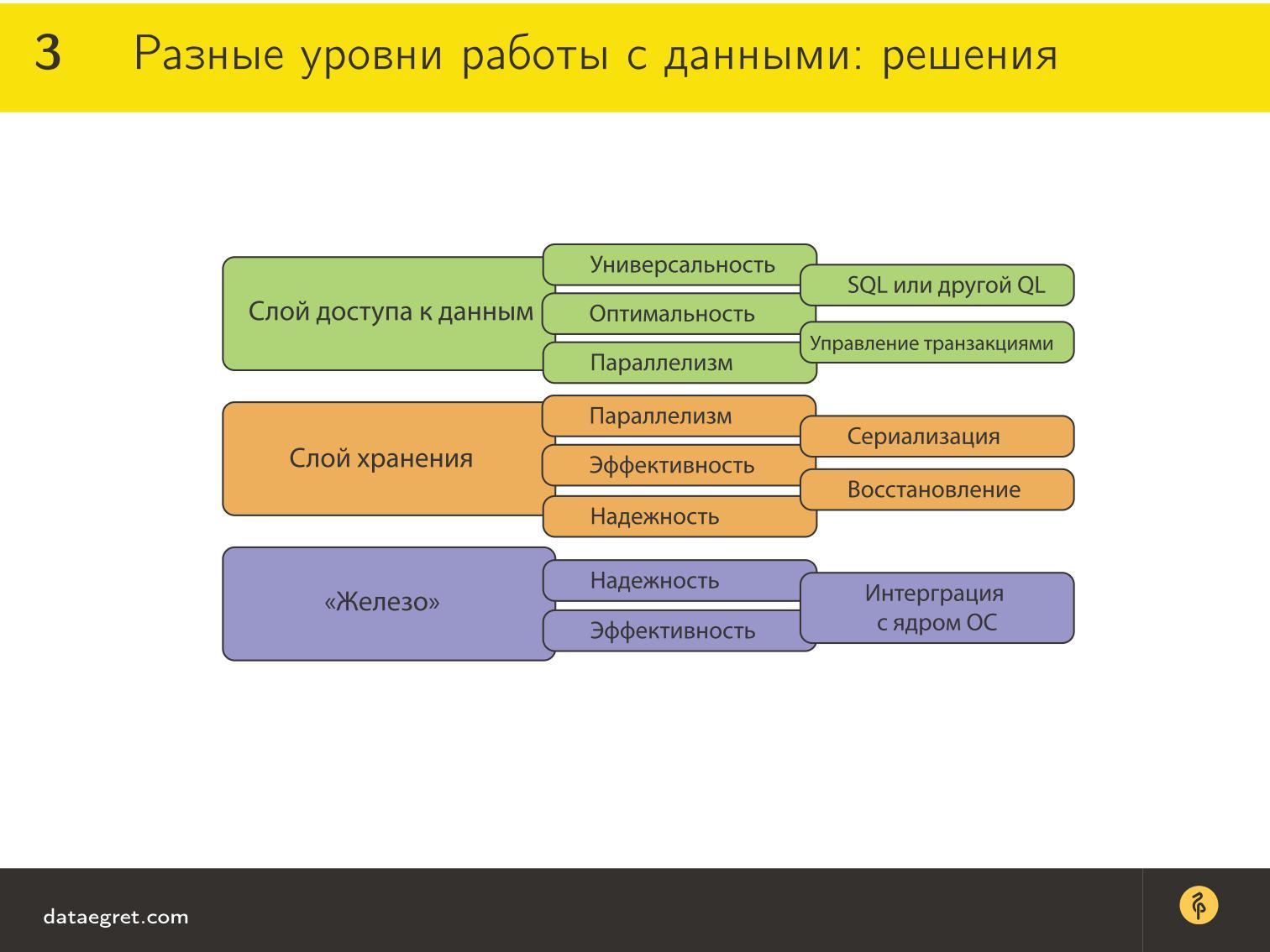
First of all, in order to provide universal and optimal access to data , there is a query language. In most cases, this is SQL (why exactly it, we will discuss further), but now I just want to draw attention to the trend. First there was SQL for a long time - of course, there were times before it, but, nevertheless, SQL dominated for a long time. Then all sorts of Key-value-storage began to appear, which, they say, work without SQL and much better.
Many Key-value-storage was mainly done to make it easier to follow data from a favorite programming language, and SQL does not fit well with a favorite programming language. It is high-level, declarative, and we want objects, so there was an idea that SQL is not needed .
But most of these technologies are now actually coming up with some kind of query language. Hibernate is very developed its own query language, someone uses Lua. Even those who have previously used Lua make their own SQL implementations. So now the trend is this: SQL is returning again , because a convenient human-readable language for working with sets is still needed.
Plus, the table view is still convenient. In varying degrees, many databases still have labels, and this is not by accident - it is thus easier to optimize queries. All optimization math is tied around relational algebra , and when you have SQL and tags, it’s much easier to work.
In the storage layer there is such a thing as serialization. When there is concurrency and competitive access, we need to ensure that this comes to the processor, to the disk in a more or less predictable manner. This requires serialization algorithms that are implemented in the storage layer.
Again, if something went wrong and the database fell, we need to quickly pick it up.
To do this, you need to recover, because, whatever you do, there will be a weak link somewhere and a very large overhead of synchronization. We can make a hundred copies per hundred servers, and as a result, a power supply or some kind of switch will burn, and it will be bad and painful.
For hardware , it is actually important that the database be well integrated with the OS, work productively, call the correct syscalls, and support all the kernel chips for quick work with the data.
Storage layer
Let's start with the storage layer. Understanding how it works, well helps to understand what is happening at the higher layers.
Storage layer provides:
✓ Parallelism and efficiency.
In other words, this is competitive access. That is, when we try to benefit from concurrency, the problem of competitive access inevitably arises. At the same time, we follow a single resource, which may be recorded incorrectly, beaten while recording and, God knows what else, it can happen.
✓ Reliability: disaster recovery.
The second problem is a sudden crash. When reliability is ensured, this means that we not only maximally provided a disaster-proof solution, but it is also important that we are able to quickly recover if something happens.
Competitive Access
When I talk about integrity, foreign keys and so on, somehow grunts and say that all they check at the code level. But as soon as you offer: “And let's take an example on your salary! Your salary is transferred to you, but it did not come, ”for some reason it becomes immediately clearer. I do not know why, but immediately there is a sparkle in the eyes and an interest in the topic of foreign keys, constraints.
Below is a code in a non-existent programming language.
Suppose we have a bank account with a balance of 1,000 rubles, and there are 2 functions. How they are arranged inside is not important to us now, these functions transfer from account a to other bank accounts 100 and 200 rubles.
Attention, the question: how much money will be in the result on the balance of the account a ? Most likely, you will answer that 700.
Problems
This is where the problems with competitive access to data begin, because my language is invented, it’s not at all clear how it is implemented, whether these functions are performed at the same time and how they are arranged inside.
We probably believe that the send_money () operation is not an elementary action. It is necessary to check the balance and where it is transferred, to perform control 1 and 2. These are not elementary operations that take some time. therefore, the order of performing elementary operations inside them is important to us.
In the sequence “read the value on the balance sheet”, “recorded on another balance sheet”, the question is important - when did we read this balance? If we do this at the same time, a conflict will arise. Both functions are performed approximately in parallel: read the same value of balance, transferred money, each recorded its own.
There may be a whole family of conflicts, as a result of which 800 rubles may appear on the balance sheet, 700 rubles, as it should be, or something will be beaten, and null on the balance sheet. This, unfortunately, happens if you do not treat this with due attention. How to deal with this, we'll talk.
In theory, everything is simple - we can execute them one by one and everything will be fine. In practice, these operations can be very much and doing them strictly consistently can be problematic.
If you remember, several years ago there was a story when Sberbank dropped Oracle and card processing stopped. They then asked for advice from the public and roughly determined how many logs the database wrote. These are huge numbers and competitive issues.
Performing operations strictly consistently is not a good idea for the simple reason that there are many operations, and we will not gain anything from concurrency. You can, of course, break operations into groups that will not conflict with each other. Such approaches also exist, but they are not very classic for modern databases.

There is one interesting story in the German rules of the road. If the road narrows, then the rules prescribe to get to the end, and only after that rebuild one at a time , and the next car should pass. All are rearranged strictly one after another - such a sign says so.
This is a living example of possible serialization, when the public is very long accustomed to the fact that the rules must be followed. I think that everyone who drives a car in Moscow understands how utopian this picture is.
Basically, we need to do the same with the data that we write to the disk.
How to improve the situation?
● Operations must be independent of each other - isolation .
In a purely theoretically controlled way, the operation must know what is happening outside. There can be no such thing that as soon as one operation changed something, the result immediately became visible to the other. There must be some rules.
This is called transaction isolation. In the simplest case, transactions do not know at all what is happening with the neighboring ones. These actions are in themselves, within the limits of one function, there is no interaction outside, until it has ended.
● The operation takes place on the principle of "all or nothing" - atomicity .
That is, either the whole operation has passed, and then its result is recorded, or, if something went wrong, we should be able to return the status quo. Such an operation must be recoverable, and if it is recoverable and isolated, then it is atomic. This is an elementary operation, which, like the result, is not divisible. It can not go half, but only entirely passes or does not pass entirely.
● We need a mechanism to check that everything happened correctly - consistency .
I asked how much money came out on the balance sheet in our example, and for some reason you said that 700. We all know that there is arithmetic, common sense, and the Criminal Code that monitors banks and accountants so that they do not do something unlawful. The Criminal Code is one of the private versions of consistency. If we talk about databases, there are many more of them: foreign keys, constraints, everything.
ACID transaction
Actions with data that have the properties of atomicity, consistency, isolation, and Durability are the definition of the ACID transaction.
D - Durability is the very model I was talking about: if the data has already been written to disk, then we think that they are there, recorded reliably and will not go anywhere. In fact, this is not the case, for example, the data must be backed up, but for our model it is not important.
Sadly, these properties can only be secured using locks. There are 3 main approaches to transaction scheduling :
A sheduler is a component that provides serialization and proper execution of a transaction.
Everybody knows about the ordering of the TimeStamp: we are looking at the time of one transaction, the time of another transaction, who was the first to get up, and sneakers. In fact, for most serious systems, this approach has a lot of problems, because, for a start, time on the server can go back, jump or go wrong - and we will come.
There are different methods to improve this, but as a single transaction synchronization method, it does not work. There are also vector clocks, Lamport clocks - probably heard such terms - but they also have their limitations.
Optimistic approaches imply that we will not have conflicts such as what I described with a bank account. But in real life they are not very successful, although there are implementations that help to carry out some operations with the help of optimistic options.
As people working with databases, we are actually always pessimists. We expect programmers to write bad code, the supplier will supply bad hardware, Marry Ivanna will pull the server out of the socket when the floor is cleaned - which is not possible!
Therefore, we love the pessimistic sheduling of transactions, namely with the help of locks. This is the only guaranteed way to ensure database integrity. There are corresponding theorems that can be proved and demonstrated.
We need efficient algorithms for taking and removing locks, because if we just block everything we need, we will most likely come to a very stupid version when we perform all operations strictly sequentially. As we already know, this is not effective in terms of the utilization of parallelism, modern CPUs, the number of servers, etc.
Herbrand semantics
A small lyrical digression, which will help to understand what will happen next. Jacques Herbrand is a French mathematician of the first half of the 20th century who, by the way, invented recursion. He even invented in pre-computer times to designate transactions in the following way:

Here S is from the word schedule. The transaction schedule includes the operation - r (read - read) or w (write - write). Still happens b (begin), with (commit), etc.
What is convenient - we have 2 transactions (numbers 1 and 2). One transaction simply reads data from some resource ( x ), and the second transaction also reads it, does some math based on these two readings x, and writes something to y .
Very convenient - transactions consist of elementary actions “read-write, read-write”. We can make a final schedule, check it, whether there are conflicts in it, with the help of any clever mathematics, and thus ensure that everything will be good and complete.
What is all this for?
Two phase locking
One of the fundamental algorithms in modern databases is the so-called two-phase blocking or 2PL (Two Phase Locking).
It is two-phase because it was noticed that in order to optimize the taking and unlocking of locks in the database, it is convenient to do it in 2 sessions:
This allows for more efficient transaction management so that they do not wait.
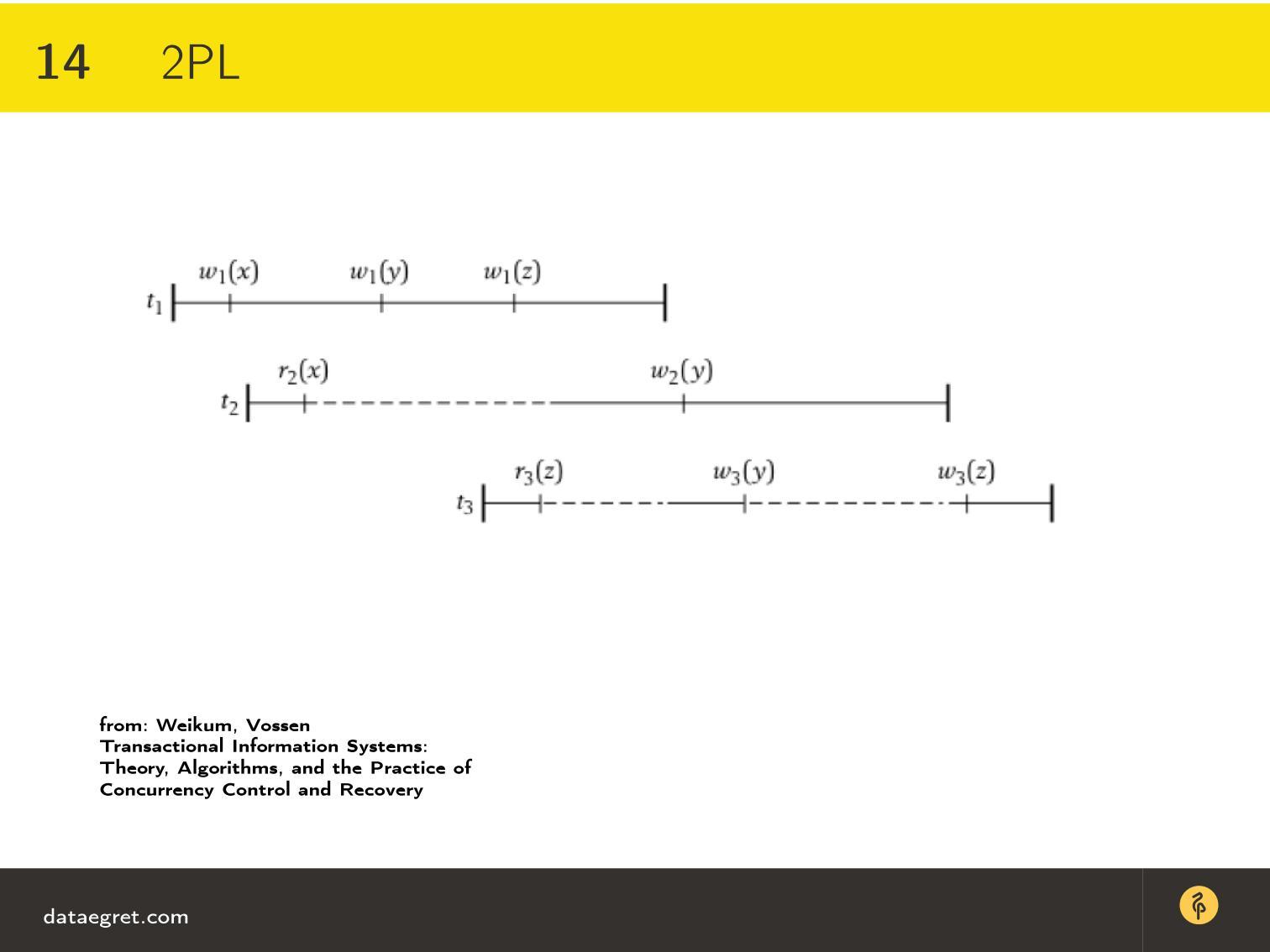
In Figure 3, the rulers denote transactions and the time of their execution. It can be seen that the write operation in the first transaction of the resource x has a nonzero time, since the recording takes some time - until the disk turns, until the pages go there, etc.
When it starts, there are no other transactions in this model, so the recording began and is being written. But the second transaction must also read x . This transaction cannot take a lock on reading x for the simple reason that x is being written by another transaction at this moment. The line becomes dashed - this means that the transaction is waiting for a lock, which was set by transaction t 1 .
As soon as transaction t 2 took all the locks that it needed in order for it to execute — it still needs a lock on y and a lock on z — only then can it begin to release them. At this point, the next transaction is unblocked, which also runs to the end.
This idea increases the efficiency of transactions and allows the same operations to be built in parallel only in such a way that elementary operations are blocked and waited only if they conflict.
What is bad in biphasic blocking?
Why can't it be so easy to solve the whole problem with all databases using one simple magic algorithm?
✓ First, with such locks, deadlocks inevitably arise when it is not clear whether a chicken or an egg.
One transaction needs a resource x , another y , they block it, and then they need to criss-cross the same resources, and it’s not clear who should release the lock first. For this purpose, databases have special control systems for deadlock and so-called deadlock shooting. Deadlock cannot be resolved in a peaceful way, but only by rolling back one of the transactions.
Usually, the mathematics inside the deadlock detection is the deadlock graph, where the transaction ID is indicated on the vertices, and the directed edges indicate which one waits for a lock from which one. On this graph, small subgraphs from one of these vertices stand out, it looks, for example, if a very large number of transactions are waiting for one transaction, then this transaction is nailed.
But there are other beautiful mathematical approaches that you can look for on the topic of deadlock-detection.
✓ The second point is slow - no one wants to wait for the lock.
There are transactions that take up a resource for a long time, for example, some report considers it occupied a resource, and everyone else has to wait. To avoid this, came up with some improvements, which will talk about later.
✓ But in this way serialization is provided .
Without biphasic blocking, there is no serialization. That is, you need to figure out how to improve biphasic blocking in order to reduce the waiting time.
In fact, there are conflicts that 2PL cannot resolve in principle, and then one of the conflicting transactions is rolled back. Usually, a mechanism is implemented in databases, when the database is waiting for some time and realizes that a certain transaction is waiting for a lock for too long, and that there is no way to resolve the conflict, the database simply kills the transaction. This is quite a rare situation and the following algorithm allows to solve some of these conflicts.
MVCC - MultiVersion Concurrency Control
Data versioning is necessary not only to speed up, but also to solve some types of conflicts that may arise.
✓ Intuitively everything is clear - in order not to wait for blocking, we take the previous version.
If a resource is locked, we can look at its old version and start working with it. If, for example, the lock was such that the transaction that blocked did not change anything on this resource, then we can continue the execution of the transaction. If there was a change and a new, more recent version of the data appeared, our transaction will be forced to re-read them again.
In any case, it is usually faster than waiting for a lock. If you remember the old MS SQL Server and the old versions of DB2, a terrible thing, then there, if there were a lot of locks, then their escalation started - everything worked badly and it was hard to live with it.
✓ All modern DBMS in one degree or another "version"
Oracle, PostgreSQL, MySQL are all “versioned” in fair form. DB2 is a bit more original on this topic, it has its own mechanism - only one previous version is stored.

This schedule, which I painted earlier, but a little more complicated. There are more transactions (3 pieces), more resources (there are z ) and 2 commits. That is, both transactions end with a commit.
As the mathematicians say in such cases: “It is easy to notice ...” - I love it very much, especially when there is a formula on half the board. Indeed, it is easy to see one thing here. For homework, try to understand why this is easy to see.
I'll tell you. This schedule is never serialized for the simple reason that the operation r 1 (y) will cause a conflict, perhaps even deadlock, if the previous version of y is not available.
That is, if the previous version of y is available here, then the transaction will normally end, there will be no problems. If this version of y is not, then the operation will conflict.
How it works?
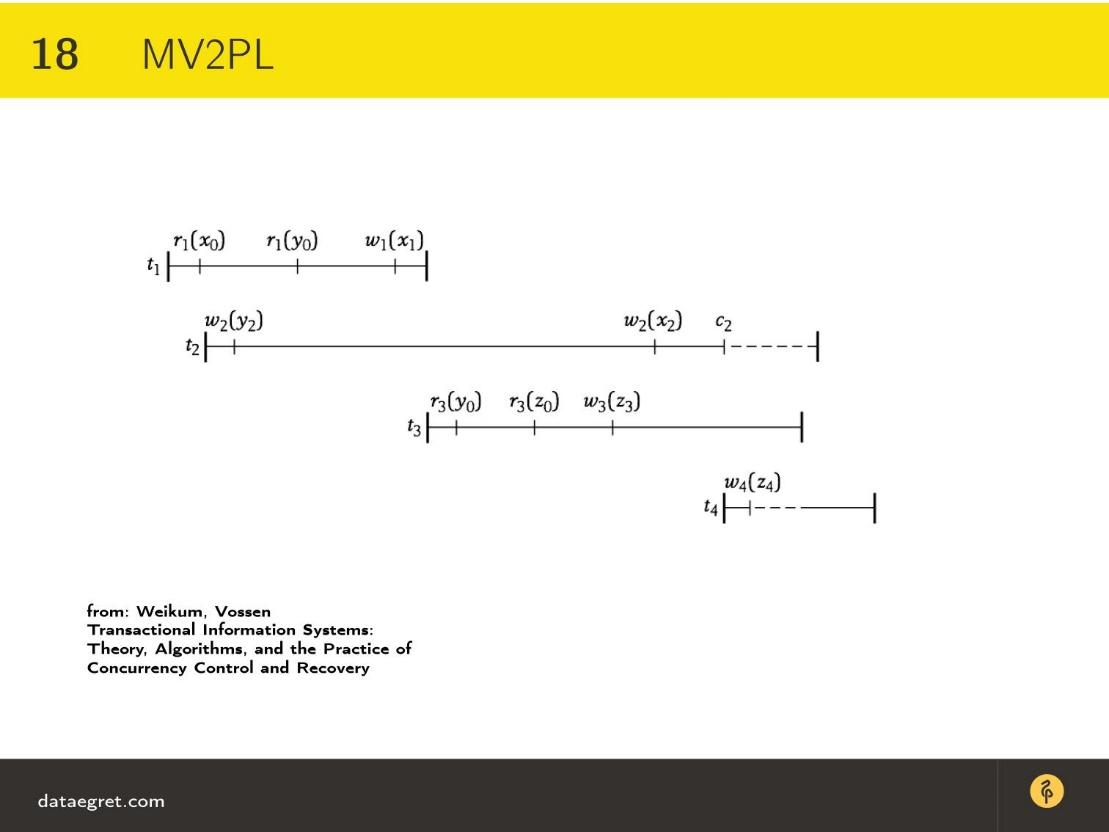
The diagram is more or less the same as biphasic blocking. This is a kind of versioned transaction sheduling, that is, it is still a two-phase blocking algorithm, only multiversion.
Another feature is added, such as the subscript - 0, 1, 2 - this is the version number.
If you try to imagine that there are no previous versions, then long dotted lines will begin immediately. When you need to read y , the solid line does not begin, but will be dashed, because w 2 ( y ) will wait for it to end t 1 . Accordingly, the schedule will go wide and everything will be much slower.
This is a big plus MVCC. Multiversion is actually faster than blocking, it’s not just a marketing feature.
And what if at the time of the transaction, which clearly has a non-zero duration, a failure occurs, for example, the hard disk collapses under the database or pulls the wires from the server?
In fact, we are ready for this, because transactions are performed like this. Consider an abstract database:
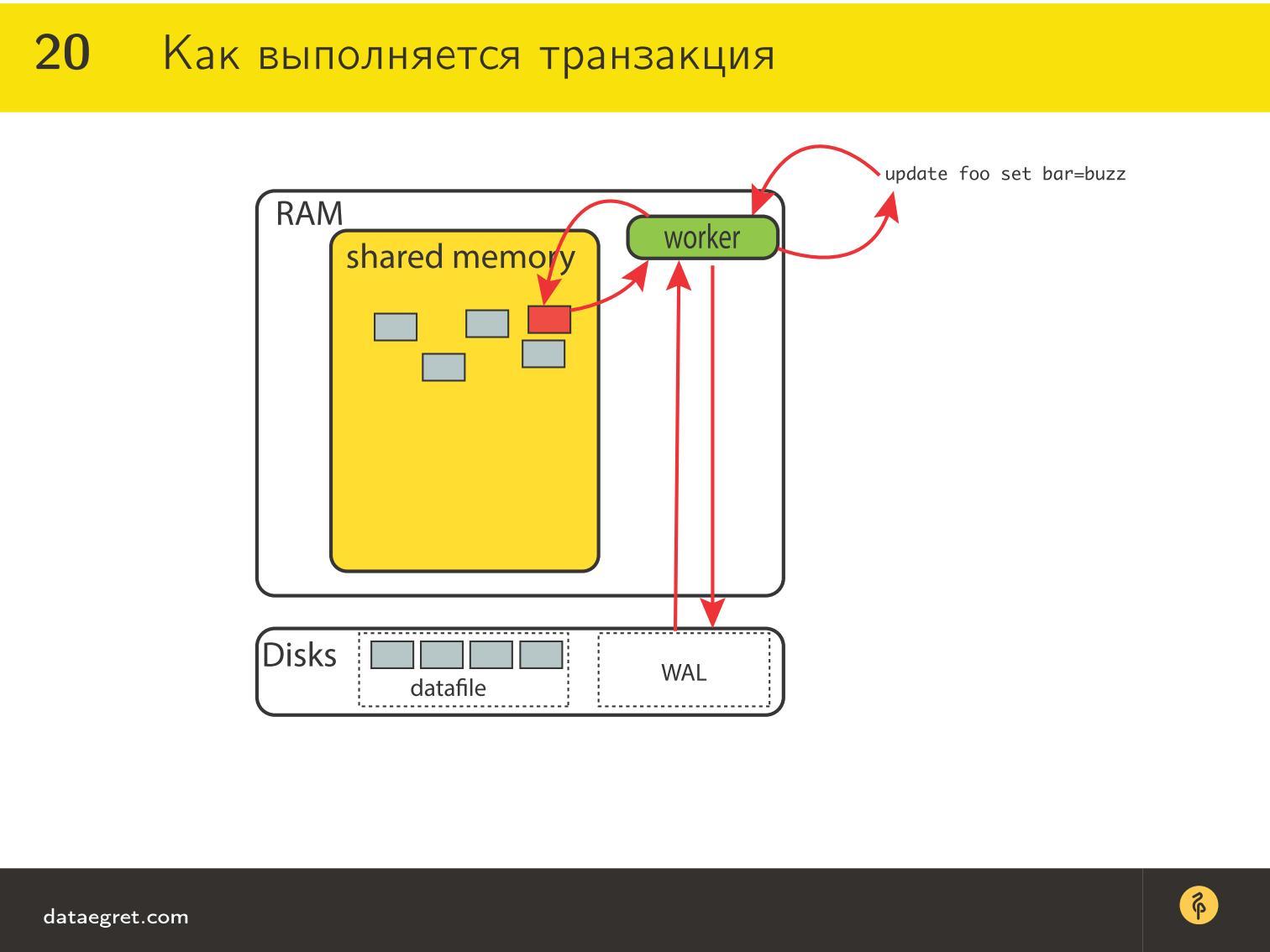
There is a certain amount of memory that is socialized between different processes or threads in which client connections are processed. The thread has its own memory, where the SQL query comes. In this memory, the SQL query (or a query in another language) is precompiled, interpreted, rebuilt in some way.
Then he goes for the data that he needs to read and change. These data on a disk lie in a special way. If you look deeper into storage, they are fixed pieces (pages) in PostgreSQL is 8Kb, in Oracle, you can use different sizes. In different databases in different ways.
This page is very convenient because there is a lot of different data in it (in fact, there are tuples in it) That is, there is a sign, and there are lines in it, these lines are packed into large pages.
If the request requires data from one of the pages, it simply raises this page to its memory and all the workers, threads and database processes will have access to it. If you need a lot, then he will raise a few. They will be cached - it is convenient, productive - the memory is faster than the disks, all things.
If you need to change at least one entry on at least one page, the whole page will be marked as so-called “dirty”. This is done because it is more convenient. We drew x and y resources on the schematic — here are the pages.
In fact, the database can block at a more granular level, including a single entry. But now we are talking about more theoretical things, and not about the intricacies of deep realization.
Accordingly, the page is marked as “dirty”, and we have a problem, which is that now the impression in memory is different from the one on the disk. If we fall now, the memory is not persistent, we will lose information about the dirty pages.
Therefore, we need to do the following operation: somewhere on a piece of paper, write down what changes we have made, so that when we get up, read this piece of paper and, using information from it, restore the page to the state in which we brought it with this update.
Therefore, before the response from the transaction returns to the client again, it writes to the so-called Write Ahead Log. This is the same piece of paper that allows you to write quickly - the record in WAL is consistent, we don’t need to look for where to put this file into a huge data file.
We recorded information about the page in the log and then returned control - everything is fine. If at some point fell, then read back Write Ahead Log and using the information about these changes, we can finish the clean pages to the level of "dirty." Our database is new again.
This allows you to perform the same recovery that we needed to provide, based on data storage problems, and allows you to recover for the most recent transaction, for the very last action that took place before Marna Ivanna pulled the server out of the socket.
Since then, the theory is not particularly added - Write Ahead Log has since remained Write Ahead Log. They all use the concept of pages and the concept of change log entries. The log can be differently named and located in different places:
In principle, everything is more or less the same everywhere - in order to recover, we use WAL.
The important point is that all this would be very unproductive if we just wrote WAL from the beginning of time. He would grow and grew, and then we would very long roll these changes into the database.
Checkpoint
Therefore, in the last reincarnation of this algorithm, there is the idea of the so-called Checkpoint - periodically the database synchronizes the "dirty" pages to disk. When we recover, you can just walk only to the previous Checkpoint. Everything else is already synchronized, we, so to speak, notice to what point we recovered.
It's like in a computer game - people, when it passes, are saved periodically. Or, as in Word, they periodically save their files so that the text does not go anywhere.
The database is able to do it all inside. It is so arranged. In addition, it speeds up the process a little bit, because sooner or later these pages should get onto the disk.
Data access
These very pages, of course, are good, but we need to get this data in some more human-readable form. The page model is convenient for storage and transactional algorithms, but not convenient for access. It is inconvenient to read the pages - bit by bit, therefore, an effective method of accessing the data in the pages is needed more convenient to a person.
There is a page on the disc, referring to Table A and Bed and . The data on the disk does not know what label they refer to. Our optimizer knows about this, that is, the engine in the database that executes our query, written in our query language.
For example, if we consider traditional SQL, then usually such a thing will be called a query plan. Using sequential sequential scan, we will take pages from the tableA and from table B - sometimes synchronously, sometimes in turn - depending on the implementation.
We will continue to impose on them, for example, JOIN, and with the result do something else, and then return the answer to the client.
What is convenient? Imagine an alternative: you are reading all this from your Python to your application, and these labels can be really huge, and the JOIN condition can exclude 90% of this data. You pull it into memory - there, respectively, go through them in cycles, sorting, returning. In fact, at each of these stages, the planner can decide how to make it more profitable. For example, it can choose a JOIN method, which can either consist entirely of cycles, or it can cache one table and attach another table to it, etc. Depending on the method, for example, you can not do full sequential scan, that is, do not read the entire table, and from the application, most likely you will have to read the entire data.
Here everything is thought up to you and implemented effectively.
findings
SQL and the relational model are convenient for optimization and for a human-readable representation, so there is no query language . The death of SQL as a technology is predicted for many years, but grandpa is very much alive. This is largely because of the easiest way to optimize and use algorithms on relational models using SQL.
Store data more convenient pages . There are different databases: object, graph, document-oriented. Basically, these are all niche, non-universal products that are used for their own purposes. It’s not easy to simply put a huge amount of transactions on such a base so that they work in a universal form. Sheduling transactions, which we considered here, on objects looks much more complicated.
In fact, each transaction is a path by column. Count can be very large. To find conflicts, you need to deal with very heavy math on graphs - therefore, there are problems with shedling in the object model.
It is no coincidence that for so many years the database with the page model has dominated, and therefore everything happens as it does. Is it good or bad, but this method has proven to be very effective.
Transactions, contrary to popular belief, this is not a way to slow down . It is often considered that transactions are some kind of syntactic sugar in databases with SQL, which simply spoils everything and bibbles, in the sense that it slows down everything, because we are waiting for locks.
In fact, transactions are a method of acceleration, since they allow processing more data in parallel without conflicts, so that they do not fight, so that the operations are not performed strictly one after the other, but in parallel. This allows more efficient use of computing resources and time.
In the words of the designer Tupolev, when he was accused of having pulled off any aircraft model: “All airplanes are equally arranged - in order to fly, they need to have wings, fuselage and tail!”
All databases inside are similar. They are either arranged equally to one degree or another, or they go there. NoSQL appeared - without transactions, without locks, without everything, it is absolutely not similar to any database. But we observe that gradually there appear locks, schemas, query language, optimization, etc.
In some even, probably, parallelism will soon appear, and this will be a great victory for the forces of reason .
If you look at modern Percona server, MariaDB, MySQL 8, you can see that they largely adopt theoretical foundations and now they are much more similar to classic databases in their structure.
This article was not born of a good life. Often, not even the novice developers, but also quite advanced ones, do not know some basic things - maybe they studied at the university a long time ago and have since forgotten, or they didn’t have to go into the theory, since they worked normally.
However, theoretical knowledge is sometimes useful to refresh . This we, including, and we will do.
')
About the speaker: Ilya Kosmodemyansky CEO and consultant for Data Egret, PostgreSQL, Oracle, DB2 database specialist. And besides, he is responsible for promoting Postgres technologies, speaking at conferences and telling people how to work with them.
Below is the material on Ilya's report on RIT ++ 2017, which was not associated with any particular database, but covered many basic aspects.
What does it need to know for?
Data storage and processing is the mission-critical task of any computer system.
Even if you have already had a blog on text files on the Internet for 30 years, as some database creators have, this text file is actually a database, but very simple.
Everyone is trying to invent a database . One of the speakers at the conference said: “20 years ago I wrote my database, I just didn’t know that it was her!” This trend in the world is very developed. Everyone is trying to do that.
To work with data database is a very handy thing . Many databases are very old technologies. They are being developed for the last half century, in the 70s there were already databases that worked according to similar principles as now.
These databases are very well and thoughtfully written , so now we can choose a programming language and use a general user-friendly data processing interface. Thus, it is possible to process data in a standardized way, without fear that they will be processed in a different way.
It is useful to remember that programming languages are changing : yesterday was Python 2, today is Python 3, tomorrow everyone ran to write on Go, the day after tomorrow on something else. You may have a piece of code that emulates the work of manipulating data, which, in theory, the database should do, and you will not know what to do next.
In most databases, the interface is very conservative . If you take PostgreSQL or Oracle, then with some tambourines you can work even with very old versions from new programming languages - well and great.
But the task is not really the easiest. If we begin to dig in the depths of how we do not “beat” the data, how quickly, efficiently and, most importantly, so that you can trust the result and process it, then it turns out that this is a difficult thing.
If you try to write your own simple persistent storage, everything will just be the first 15 minutes. Then locks and other things will begin, and at some point you will understand: “Oh, why am I doing all this?”
About this and talk.
Levels of working with data
So, there are various levels of work with data:
- The data access layer , which is convenient to use from programming languages;
- Storage layer This is a separate layer, because usually it is convenient to store data in other ways than to use: efficiently in memory, level, fold to disk. This is a schemaless question: a schema that is convenient to store is not convenient to access.
- “ Iron ” is the layer where the data lies, and there they are organized in a third way, because the disks are controlled by the operating system, and they communicate only through the driver. In this level, we will not delve into much.
For the data access layer there are requirements that we are interested in fulfilling in order to make it convenient to work:
- Universality , so that it is possible to request data using any technology.
- The optimality of this request. The access method must be such that it is good and convenient to get data from the database.
- Parallelism , because now everything is scaled, different servers simultaneously access the database for the same data. You need to do this in order to maximize the benefits of concurrency and more quickly process data in this way.
For the storage layer , it is still important to preserve the original concurrency so that all data is not beaten, overwritten, not truncated, etc.
At the same time, they must be securely stored and reliably reproduced. That is, if we have recorded something in the database, we must be sure that we will get it back.
If you worked with old databases, for example, FoxPro, then you know that there often appear broken data. In new databases, such as MongoDB, Cassandra and others, such problems also occur. Maybe they simply are not always noticed, because there is a lot of data that is harder to notice.
For hardware , reliability is really important. This is a sort of assumption, since we will nevertheless speak about theoretical things. In our model, if something got on the disk, then we think that everything is fine there. How to replace a disk in RAID in time - this is for us admins. We will not dive deep into this question, and practically we will not touch on how efficiently the store is physically organized.
To solve these problems, there are some approaches that are very similar across different data sources - both new and classic.
First of all, in order to provide universal and optimal access to data , there is a query language. In most cases, this is SQL (why exactly it, we will discuss further), but now I just want to draw attention to the trend. First there was SQL for a long time - of course, there were times before it, but, nevertheless, SQL dominated for a long time. Then all sorts of Key-value-storage began to appear, which, they say, work without SQL and much better.
Many Key-value-storage was mainly done to make it easier to follow data from a favorite programming language, and SQL does not fit well with a favorite programming language. It is high-level, declarative, and we want objects, so there was an idea that SQL is not needed .
But most of these technologies are now actually coming up with some kind of query language. Hibernate is very developed its own query language, someone uses Lua. Even those who have previously used Lua make their own SQL implementations. So now the trend is this: SQL is returning again , because a convenient human-readable language for working with sets is still needed.
Plus, the table view is still convenient. In varying degrees, many databases still have labels, and this is not by accident - it is thus easier to optimize queries. All optimization math is tied around relational algebra , and when you have SQL and tags, it’s much easier to work.
In the storage layer there is such a thing as serialization. When there is concurrency and competitive access, we need to ensure that this comes to the processor, to the disk in a more or less predictable manner. This requires serialization algorithms that are implemented in the storage layer.
Again, if something went wrong and the database fell, we need to quickly pick it up.
Do you think it is possible to write a 100% reliable fault-tolerant storage? You probably know that the database only works reliably when there is a mechanism to quickly pick it up if it falls.
To do this, you need to recover, because, whatever you do, there will be a weak link somewhere and a very large overhead of synchronization. We can make a hundred copies per hundred servers, and as a result, a power supply or some kind of switch will burn, and it will be bad and painful.
For hardware , it is actually important that the database be well integrated with the OS, work productively, call the correct syscalls, and support all the kernel chips for quick work with the data.
Storage layer
Let's start with the storage layer. Understanding how it works, well helps to understand what is happening at the higher layers.
Storage layer provides:
✓ Parallelism and efficiency.
In other words, this is competitive access. That is, when we try to benefit from concurrency, the problem of competitive access inevitably arises. At the same time, we follow a single resource, which may be recorded incorrectly, beaten while recording and, God knows what else, it can happen.
✓ Reliability: disaster recovery.
The second problem is a sudden crash. When reliability is ensured, this means that we not only maximally provided a disaster-proof solution, but it is also important that we are able to quickly recover if something happens.
Competitive Access
When I talk about integrity, foreign keys and so on, somehow grunts and say that all they check at the code level. But as soon as you offer: “And let's take an example on your salary! Your salary is transferred to you, but it did not come, ”for some reason it becomes immediately clearer. I do not know why, but immediately there is a sparkle in the eyes and an interest in the topic of foreign keys, constraints.
Below is a code in a non-existent programming language.
account_a { balance = 1000, curr = 'RUR' } send_money(account_a, account_b, 100); send_money(account_a, account_c, 200); account_a->balance = ??? Suppose we have a bank account with a balance of 1,000 rubles, and there are 2 functions. How they are arranged inside is not important to us now, these functions transfer from account a to other bank accounts 100 and 200 rubles.
Attention, the question: how much money will be in the result on the balance of the account a ? Most likely, you will answer that 700.
Problems
This is where the problems with competitive access to data begin, because my language is invented, it’s not at all clear how it is implemented, whether these functions are performed at the same time and how they are arranged inside.
We probably believe that the send_money () operation is not an elementary action. It is necessary to check the balance and where it is transferred, to perform control 1 and 2. These are not elementary operations that take some time. therefore, the order of performing elementary operations inside them is important to us.
In the sequence “read the value on the balance sheet”, “recorded on another balance sheet”, the question is important - when did we read this balance? If we do this at the same time, a conflict will arise. Both functions are performed approximately in parallel: read the same value of balance, transferred money, each recorded its own.
There may be a whole family of conflicts, as a result of which 800 rubles may appear on the balance sheet, 700 rubles, as it should be, or something will be beaten, and null on the balance sheet. This, unfortunately, happens if you do not treat this with due attention. How to deal with this, we'll talk.
In theory, everything is simple - we can execute them one by one and everything will be fine. In practice, these operations can be very much and doing them strictly consistently can be problematic.
If you remember, several years ago there was a story when Sberbank dropped Oracle and card processing stopped. They then asked for advice from the public and roughly determined how many logs the database wrote. These are huge numbers and competitive issues.
Performing operations strictly consistently is not a good idea for the simple reason that there are many operations, and we will not gain anything from concurrency. You can, of course, break operations into groups that will not conflict with each other. Such approaches also exist, but they are not very classic for modern databases.
There is one interesting story in the German rules of the road. If the road narrows, then the rules prescribe to get to the end, and only after that rebuild one at a time , and the next car should pass. All are rearranged strictly one after another - such a sign says so.
This is a living example of possible serialization, when the public is very long accustomed to the fact that the rules must be followed. I think that everyone who drives a car in Moscow understands how utopian this picture is.
Basically, we need to do the same with the data that we write to the disk.
How to improve the situation?
● Operations must be independent of each other - isolation .
In a purely theoretically controlled way, the operation must know what is happening outside. There can be no such thing that as soon as one operation changed something, the result immediately became visible to the other. There must be some rules.
This is called transaction isolation. In the simplest case, transactions do not know at all what is happening with the neighboring ones. These actions are in themselves, within the limits of one function, there is no interaction outside, until it has ended.
● The operation takes place on the principle of "all or nothing" - atomicity .
That is, either the whole operation has passed, and then its result is recorded, or, if something went wrong, we should be able to return the status quo. Such an operation must be recoverable, and if it is recoverable and isolated, then it is atomic. This is an elementary operation, which, like the result, is not divisible. It can not go half, but only entirely passes or does not pass entirely.
● We need a mechanism to check that everything happened correctly - consistency .
I asked how much money came out on the balance sheet in our example, and for some reason you said that 700. We all know that there is arithmetic, common sense, and the Criminal Code that monitors banks and accountants so that they do not do something unlawful. The Criminal Code is one of the private versions of consistency. If we talk about databases, there are many more of them: foreign keys, constraints, everything.
ACID transaction
Actions with data that have the properties of atomicity, consistency, isolation, and Durability are the definition of the ACID transaction.
D - Durability is the very model I was talking about: if the data has already been written to disk, then we think that they are there, recorded reliably and will not go anywhere. In fact, this is not the case, for example, the data must be backed up, but for our model it is not important.
Sadly, these properties can only be secured using locks. There are 3 main approaches to transaction scheduling :
- Pessimistic sheduler;
- Optimistic sheduler;
- Hybrid sheduler and based on streamlining TimeStamp ongoing transaction.
A sheduler is a component that provides serialization and proper execution of a transaction.
Everybody knows about the ordering of the TimeStamp: we are looking at the time of one transaction, the time of another transaction, who was the first to get up, and sneakers. In fact, for most serious systems, this approach has a lot of problems, because, for a start, time on the server can go back, jump or go wrong - and we will come.
There are different methods to improve this, but as a single transaction synchronization method, it does not work. There are also vector clocks, Lamport clocks - probably heard such terms - but they also have their limitations.
Optimistic approaches imply that we will not have conflicts such as what I described with a bank account. But in real life they are not very successful, although there are implementations that help to carry out some operations with the help of optimistic options.
As people working with databases, we are actually always pessimists. We expect programmers to write bad code, the supplier will supply bad hardware, Marry Ivanna will pull the server out of the socket when the floor is cleaned - which is not possible!
Therefore, we love the pessimistic sheduling of transactions, namely with the help of locks. This is the only guaranteed way to ensure database integrity. There are corresponding theorems that can be proved and demonstrated.
We need efficient algorithms for taking and removing locks, because if we just block everything we need, we will most likely come to a very stupid version when we perform all operations strictly sequentially. As we already know, this is not effective in terms of the utilization of parallelism, modern CPUs, the number of servers, etc.
Herbrand semantics
A small lyrical digression, which will help to understand what will happen next. Jacques Herbrand is a French mathematician of the first half of the 20th century who, by the way, invented recursion. He even invented in pre-computer times to designate transactions in the following way:
Here S is from the word schedule. The transaction schedule includes the operation - r (read - read) or w (write - write). Still happens b (begin), with (commit), etc.
What is convenient - we have 2 transactions (numbers 1 and 2). One transaction simply reads data from some resource ( x ), and the second transaction also reads it, does some math based on these two readings x, and writes something to y .
Very convenient - transactions consist of elementary actions “read-write, read-write”. We can make a final schedule, check it, whether there are conflicts in it, with the help of any clever mathematics, and thus ensure that everything will be good and complete.
What is all this for?
Two phase locking
One of the fundamental algorithms in modern databases is the so-called two-phase blocking or 2PL (Two Phase Locking).
It is two-phase because it was noticed that in order to optimize the taking and unlocking of locks in the database, it is convenient to do it in 2 sessions:
- First, we set locks for all resources that need to be read or written to a bunch of transactions that are currently in the database.
- Not a single lock is released until all necessary locks are set.
This allows for more efficient transaction management so that they do not wait.
In Figure 3, the rulers denote transactions and the time of their execution. It can be seen that the write operation in the first transaction of the resource x has a nonzero time, since the recording takes some time - until the disk turns, until the pages go there, etc.
When it starts, there are no other transactions in this model, so the recording began and is being written. But the second transaction must also read x . This transaction cannot take a lock on reading x for the simple reason that x is being written by another transaction at this moment. The line becomes dashed - this means that the transaction is waiting for a lock, which was set by transaction t 1 .
As soon as transaction t 2 took all the locks that it needed in order for it to execute — it still needs a lock on y and a lock on z — only then can it begin to release them. At this point, the next transaction is unblocked, which also runs to the end.
This idea increases the efficiency of transactions and allows the same operations to be built in parallel only in such a way that elementary operations are blocked and waited only if they conflict.
I recommend the book Transactional Information Systems (Gerhard Weikum, Gottfried Vossen) - this is a fundamental textbook on transaction theory.
What is bad in biphasic blocking?
Why can't it be so easy to solve the whole problem with all databases using one simple magic algorithm?
✓ First, with such locks, deadlocks inevitably arise when it is not clear whether a chicken or an egg.
One transaction needs a resource x , another y , they block it, and then they need to criss-cross the same resources, and it’s not clear who should release the lock first. For this purpose, databases have special control systems for deadlock and so-called deadlock shooting. Deadlock cannot be resolved in a peaceful way, but only by rolling back one of the transactions.
Usually, the mathematics inside the deadlock detection is the deadlock graph, where the transaction ID is indicated on the vertices, and the directed edges indicate which one waits for a lock from which one. On this graph, small subgraphs from one of these vertices stand out, it looks, for example, if a very large number of transactions are waiting for one transaction, then this transaction is nailed.
But there are other beautiful mathematical approaches that you can look for on the topic of deadlock-detection.
✓ The second point is slow - no one wants to wait for the lock.
There are transactions that take up a resource for a long time, for example, some report considers it occupied a resource, and everyone else has to wait. To avoid this, came up with some improvements, which will talk about later.
✓ But in this way serialization is provided .
Without biphasic blocking, there is no serialization. That is, you need to figure out how to improve biphasic blocking in order to reduce the waiting time.
In any modern database, two-phase locking is the main way to ensure integrity and serialization, even if we are talking about versioned databases.
In fact, there are conflicts that 2PL cannot resolve in principle, and then one of the conflicting transactions is rolled back. Usually, a mechanism is implemented in databases, when the database is waiting for some time and realizes that a certain transaction is waiting for a lock for too long, and that there is no way to resolve the conflict, the database simply kills the transaction. This is quite a rare situation and the following algorithm allows to solve some of these conflicts.
MVCC - MultiVersion Concurrency Control
Data versioning is necessary not only to speed up, but also to solve some types of conflicts that may arise.
✓ Intuitively everything is clear - in order not to wait for blocking, we take the previous version.
If a resource is locked, we can look at its old version and start working with it. If, for example, the lock was such that the transaction that blocked did not change anything on this resource, then we can continue the execution of the transaction. If there was a change and a new, more recent version of the data appeared, our transaction will be forced to re-read them again.
In any case, it is usually faster than waiting for a lock. If you remember the old MS SQL Server and the old versions of DB2, a terrible thing, then there, if there were a lot of locks, then their escalation started - everything worked badly and it was hard to live with it.
✓ All modern DBMS in one degree or another "version"
Oracle, PostgreSQL, MySQL are all “versioned” in fair form. DB2 is a bit more original on this topic, it has its own mechanism - only one previous version is stored.
This schedule, which I painted earlier, but a little more complicated. There are more transactions (3 pieces), more resources (there are z ) and 2 commits. That is, both transactions end with a commit.
As the mathematicians say in such cases: “It is easy to notice ...” - I love it very much, especially when there is a formula on half the board. Indeed, it is easy to see one thing here. For homework, try to understand why this is easy to see.
I'll tell you. This schedule is never serialized for the simple reason that the operation r 1 (y) will cause a conflict, perhaps even deadlock, if the previous version of y is not available.
That is, if the previous version of y is available here, then the transaction will normally end, there will be no problems. If this version of y is not, then the operation will conflict.
How it works?
The diagram is more or less the same as biphasic blocking. This is a kind of versioned transaction sheduling, that is, it is still a two-phase blocking algorithm, only multiversion.
Another feature is added, such as the subscript - 0, 1, 2 - this is the version number.
- When we went to execute transaction t 1 , there is a read x 0 , i.e. the most original version.
- Further at t 2, we begin to write y of a different version, because it was changed.
- In the transaction t 1 , which started earlier than we started writing y , the previous version y 0 is still visible, since t 2 has not finished yet, and we can calmly start working with it.
- Since transaction t 1 ends earlier than w 2 ( y 2 ), y will reread, and after that in transaction t 2, normal operation is completed, and the other transaction just completes normally.
If you try to imagine that there are no previous versions, then long dotted lines will begin immediately. When you need to read y , the solid line does not begin, but will be dashed, because w 2 ( y ) will wait for it to end t 1 . Accordingly, the schedule will go wide and everything will be much slower.
This is a big plus MVCC. Multiversion is actually faster than blocking, it’s not just a marketing feature.
And what if at the time of the transaction, which clearly has a non-zero duration, a failure occurs, for example, the hard disk collapses under the database or pulls the wires from the server?
In fact, we are ready for this, because transactions are performed like this. Consider an abstract database:
There is a certain amount of memory that is socialized between different processes or threads in which client connections are processed. The thread has its own memory, where the SQL query comes. In this memory, the SQL query (or a query in another language) is precompiled, interpreted, rebuilt in some way.
Then he goes for the data that he needs to read and change. These data on a disk lie in a special way. If you look deeper into storage, they are fixed pieces (pages) in PostgreSQL is 8Kb, in Oracle, you can use different sizes. In different databases in different ways.
This page is very convenient because there is a lot of different data in it (in fact, there are tuples in it) That is, there is a sign, and there are lines in it, these lines are packed into large pages.
If the request requires data from one of the pages, it simply raises this page to its memory and all the workers, threads and database processes will have access to it. If you need a lot, then he will raise a few. They will be cached - it is convenient, productive - the memory is faster than the disks, all things.
If you need to change at least one entry on at least one page, the whole page will be marked as so-called “dirty”. This is done because it is more convenient. We drew x and y resources on the schematic — here are the pages.
In fact, the database can block at a more granular level, including a single entry. But now we are talking about more theoretical things, and not about the intricacies of deep realization.
Accordingly, the page is marked as “dirty”, and we have a problem, which is that now the impression in memory is different from the one on the disk. If we fall now, the memory is not persistent, we will lose information about the dirty pages.
Therefore, we need to do the following operation: somewhere on a piece of paper, write down what changes we have made, so that when we get up, read this piece of paper and, using information from it, restore the page to the state in which we brought it with this update.
Therefore, before the response from the transaction returns to the client again, it writes to the so-called Write Ahead Log. This is the same piece of paper that allows you to write quickly - the record in WAL is consistent, we don’t need to look for where to put this file into a huge data file.
We recorded information about the page in the log and then returned control - everything is fine. If at some point fell, then read back Write Ahead Log and using the information about these changes, we can finish the clean pages to the level of "dirty." Our database is new again.
This allows you to perform the same recovery that we needed to provide, based on data storage problems, and allows you to recover for the most recent transaction, for the very last action that took place before Marna Ivanna pulled the server out of the socket.
This algorithm is called ARIES and in its present form it was made quite a long time ago. The fundamental article on its device and method of recovery in relational databases was published by Mohan in 1992.
Since then, the theory is not particularly added - Write Ahead Log has since remained Write Ahead Log. They all use the concept of pages and the concept of change log entries. The log can be differently named and located in different places:
- In MySQL, it is inside InnoDB,
- In PostgreSQL, this is a separate directory, which finally in version 10 was called WAL instead of PGX-Log;
- In Oracle, this is called Redo Log;
- In DB2 - WAL.
In principle, everything is more or less the same everywhere - in order to recover, we use WAL.
The important point is that all this would be very unproductive if we just wrote WAL from the beginning of time. He would grow and grew, and then we would very long roll these changes into the database.
Checkpoint
Therefore, in the last reincarnation of this algorithm, there is the idea of the so-called Checkpoint - periodically the database synchronizes the "dirty" pages to disk. When we recover, you can just walk only to the previous Checkpoint. Everything else is already synchronized, we, so to speak, notice to what point we recovered.
It's like in a computer game - people, when it passes, are saved periodically. Or, as in Word, they periodically save their files so that the text does not go anywhere.
The database is able to do it all inside. It is so arranged. In addition, it speeds up the process a little bit, because sooner or later these pages should get onto the disk.
Data access
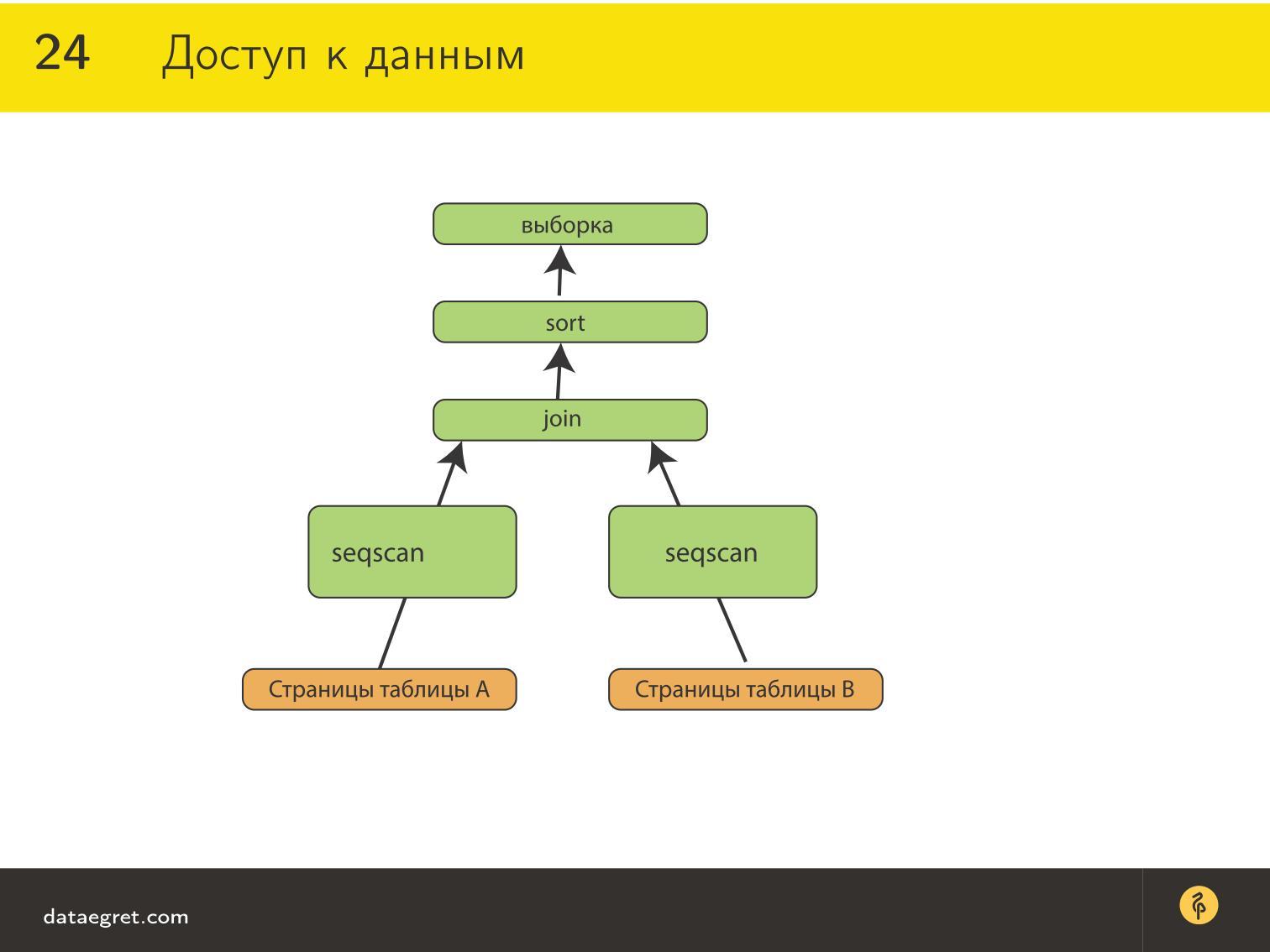
These very pages, of course, are good, but we need to get this data in some more human-readable form. The page model is convenient for storage and transactional algorithms, but not convenient for access. It is inconvenient to read the pages - bit by bit, therefore, an effective method of accessing the data in the pages is needed more convenient to a person.
There is a page on the disc, referring to Table A and Bed and . The data on the disk does not know what label they refer to. Our optimizer knows about this, that is, the engine in the database that executes our query, written in our query language.
For example, if we consider traditional SQL, then usually such a thing will be called a query plan. Using sequential sequential scan, we will take pages from the tableA and from table B - sometimes synchronously, sometimes in turn - depending on the implementation.
We will continue to impose on them, for example, JOIN, and with the result do something else, and then return the answer to the client.
What is convenient? Imagine an alternative: you are reading all this from your Python to your application, and these labels can be really huge, and the JOIN condition can exclude 90% of this data. You pull it into memory - there, respectively, go through them in cycles, sorting, returning. In fact, at each of these stages, the planner can decide how to make it more profitable. For example, it can choose a JOIN method, which can either consist entirely of cycles, or it can cache one table and attach another table to it, etc. Depending on the method, for example, you can not do full sequential scan, that is, do not read the entire table, and from the application, most likely you will have to read the entire data.
Here everything is thought up to you and implemented effectively.
findings
SQL and the relational model are convenient for optimization and for a human-readable representation, so there is no query language . The death of SQL as a technology is predicted for many years, but grandpa is very much alive. This is largely because of the easiest way to optimize and use algorithms on relational models using SQL.
Store data more convenient pages . There are different databases: object, graph, document-oriented. Basically, these are all niche, non-universal products that are used for their own purposes. It’s not easy to simply put a huge amount of transactions on such a base so that they work in a universal form. Sheduling transactions, which we considered here, on objects looks much more complicated.
In fact, each transaction is a path by column. Count can be very large. To find conflicts, you need to deal with very heavy math on graphs - therefore, there are problems with shedling in the object model.
It is no coincidence that for so many years the database with the page model has dominated, and therefore everything happens as it does. Is it good or bad, but this method has proven to be very effective.
No transaction in any way!
Transactions, contrary to popular belief, this is not a way to slow down . It is often considered that transactions are some kind of syntactic sugar in databases with SQL, which simply spoils everything and bibbles, in the sense that it slows down everything, because we are waiting for locks.
In fact, transactions are a method of acceleration, since they allow processing more data in parallel without conflicts, so that they do not fight, so that the operations are not performed strictly one after the other, but in parallel. This allows more efficient use of computing resources and time.
In the words of the designer Tupolev, when he was accused of having pulled off any aircraft model: “All airplanes are equally arranged - in order to fly, they need to have wings, fuselage and tail!”
All databases inside are similar. They are either arranged equally to one degree or another, or they go there. NoSQL appeared - without transactions, without locks, without everything, it is absolutely not similar to any database. But we observe that gradually there appear locks, schemas, query language, optimization, etc.
In some even, probably, parallelism will soon appear, and this will be a great victory for the forces of reason .
If you look at modern Percona server, MariaDB, MySQL 8, you can see that they largely adopt theoretical foundations and now they are much more similar to classic databases in their structure.
, , ?
… ++ , , Highload++ Siberia , - .
, :
- , Oracle 7- 18- , .
- (Altinity) (Ivinco) MySQL ClickHouse .
- () LZ4 .
Source: https://habr.com/ru/post/358984/
All Articles