The patented dream of programmers 80-90
This spring, I finally managed to realize the long-standing dream of construction engineers: to build in a quarter-century prescription among American patents a very simple solution to all their problems. In essence, this is an emulation of the application database, in the construction of which all the rough, routine work of a programmer is “bracketed”.
In the solution again, the data storage system and the way they are processed, the result is an alternative to the existing ORM. The stated benefits are: improving the reliability of the database by minimizing errors when adding new data and forming requests to it, as well as reducing the risk of avalanche-like degradation of performance when working with large amounts of data (with any volumes).
It does not fundamentally change the structure of the physical storage of data, everything happens in it in the same way as in a normal database application: information is stored on the media, it is fragmented, and fragmentation increases over time. When querying data, there is also a lot of readings of separate pieces of information from the disk.
More than that, it can work in a regular relational database.
But there are nuances.
In general, now those dreams of the 90s are no longer so relevant, there are many different ORMs, and their problems are less noticeable against the background of everything else that has managed to generate progress. But sometimes you want to go back to basics ... Let's go back.
There are two qualitative improvements in data management:
- The programmer works on a higher level - on the designer level, which allows you to do an order of magnitude less work to set the structure and sample data
- The administrator works with an extremely simple database in which the tasks of clustering, mirroring, sharding and the like are also solved much easier.
Today, the implemented prototype of the kernel (even if it is called this way) of the future platform does not provide the Administrator with any ready-made tools for solving its tasks. Given the simplicity of the architecture, the adaptation of these tools for a specific project is comparable to writing them from scratch. The same applies to the transfer between environments, version control and other things.
Kernel task framework: structure management, queries and a basic interface for modifying data.
I made the minimum strapping and interface to use. For example, the transaction mechanism available in the DBMS is not used, although it will take less than an hour to implement it in the kernel. Triggers and constraints are also not used, simply because we still haven't needed all this in application development. Such things are done on top of the core (far beyond the scope of the patent formula) and, I dare say, they are done in a rather trivial way so that anyone can make them for themselves.
Now consider the mentioned nuances.
All data is physically stored in one table of 5 fields: ID, parent (ID), type (also ID), order among equals (number), value (set of bytes). It has 3 indexes: ID, type-value, parent-type. Instead of accessing a database that will find a table, it will find a field in which it will find data, the kernel refers to a single table in which it immediately finds the data of the desired type by index.
The approach implemented in the kernel will make it possible to describe any data structure in this table: in the type editor we create a metamodel of data, and the data itself on this model is available for viewing and modification in the basic interface. Combining data of different types into tables uses index statistics to make it all work at optimal speed — any RDBMS works in much the same way with data on disk.
This can be thought of as a storage device where you can send data and request it by referring to the kernel. In this case, outside, in the interface, the data looks like a set of ordinary relational database tables. Further, under the tables, I mean exactly these tables modeled by the kernel.
Indexing data
As you can see, there is some redundancy in indexing, such is the price of convenience.
The query optimizer does the dirty work for the programmer — eliminates non-optimal scans of data tables, as if the administrator analyzed the structure and built all the necessary indices manually. This is a routine task that is usually done as needed, however, if you don’t seriously engage in this, the database is unproductively consuming server resources. Sometimes very unproductive.
Of course, no optimizer will replace a person, especially someone familiar with the subject area, so in any application there is a place for a dirty, creative work of a programmer.
Further a few examples when it may be necessary to approach the solution wisely.
There are rules that you need to remember and follow in order to optimize the performance of your application. These rules were not invented by me, they relate to the general methods of effective work with large amounts of data. It should be noted that the same rules work in any relational database. Some of them are obvious to experienced developers, however, not all come to the development immediately experienced.
The inability to use the index
Avoid using a speed-critical filter on a non-indexable field value:
- The index will not apply when you use a certain function to convert a field, and then apply a filter to its result.
- It should also be borne in mind that the index is based on the value of the fields, starting with their first character, so if you use in the filter a comparison with a substring that does not begin with the first character, then the index will not be applied.
It is not often that there is a real need to apply the above-mentioned methods for selecting data in large arrays of records, but if this is really necessary, then it would be better to additionally store the pre-calculated value of the desired function.
- If in the bank account numbers you analyze the currency code by 6-8 characters, instead of using the SUBSTRING expression (Currency, 6, 3) to select the currency of the accounts, you should put the currency code in a separate field in the table of accounts and select by its value
- When you need to quickly find a person by the last digits of his phone number, instead of searching by mask% 4567, create an additional field with inverted numbers 89101234567 => 765432 (not necessarily the entire number) and then also invert the search condition before sending it to the query: 7654%
No index
If you plan to use an attribute for filtering data, which may be empty, then it should be made mandatory and put there a default value that will indicate emptiness, for example, the word NULL.

In this case, the executed order has a completed execution time, and if you do not fill this field with an analogue of an empty value, then the kernel will not save or index it. This means that the optimizer will have to look through all the orders to find the unfulfilled ones, which can take time and a large amount of unproductive work with a large number of orders.
If we set the value to “NULL” (textual) by default, the optimizer will quickly find all outstanding orders using an index.
Selection sequence of related entities
When creating a query, try to place in the report columns primarily objects or details, the selection of which, according to specified conditions, can significantly reduce the array of related data.
Usually, the optimizer does its job well, but there are times when it needs human help.
In the sample there are several tables with different numbers of records, and the selection conditions are set to which the index cannot be applied.
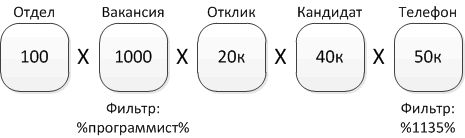
The optimizer can start building the product of the tables, starting with Department, before starting to apply the filter to the phones. This may take a long time.
In this case, it is obvious to a person that even without an index, a query to one table of records will work faster, returning several records and pulling data from the other tables. Therefore, the person will help the optimizer by moving the Phone column to the beginning of the query, and then the optimizer will start sampling from the phones.
In general, this is all you need to know about the new kernel to start working with it, if you need to master it.
My previous articles were criticized for the lack of an ecosystem around the technological advantage given by the core. Of course, it is important to provide the administrator with a minimal set of simple examples, which we are working with like-minded people on now, implementing a variety of tasks. These projects serve only to confirm the concept; they do not yet have the resources to create an Ecosystem for a wide industrial application. Nevertheless, there you can look at the results, so as not to be unfounded.
')
Source: https://habr.com/ru/post/358934/
All Articles