Neural network speech synthesis with their own hands
The synthesis of speech today is used in various fields. These are voice assistants, and IVR systems, smart homes, and much more. By itself, the task, for my taste, is very clear and understandable: the written text should be pronounced as a person would.
Some time ago machine learning came to the field of speech synthesis, as well as in many other areas. It turned out that a number of components of the entire system can be replaced with neural networks, which will allow not only to approach the existing algorithms in quality, but even to significantly surpass them.
')
I decided to try to make a fully neural network synthesis with my own hands, and at the same time share my experience with the community. What came out of this, you can find out by looking under the cat.
To build a speech synthesis system, we need a whole team of specialists from different areas. For each of them there is a whole mass of algorithms and approaches. Written doctoral dissertations and thick books describing the fundamental approaches. Let's first understand the surface of each of them.
If suddenly it seemed to you that all this can be simplified, figured out in your head, or quickly select some heuristics for individual modules, then just imagine that you need to do a synthesis in Hindi. If you do not speak the language, you will not even be able to assess the quality of your synthesis without attracting someone who would speak the language at the right level. My mother tongue is Russian, and I hear when the synthesis is mistaken in accents or speaks with the wrong intonation. But at the same time, all the synthesized English for me sounds about the same, not to mention the more exotic languages.
We will try to find the End-2-End (E2E) implementation of the synthesis, which would take on all the difficulties associated with the subtleties of the language. In other words, we want to build a system based on neural networks, which would accept text at the input, and give synthesized speech at the output. Is it possible to train such a network that would allow replacing a whole team of specialists from narrow areas with a team (perhaps even from one person) specializing in machine learning?
At the end2end tts query, Google produces a whole lot of results. Led by - the implementation of Tacotron from Google itself. It seemed to me the easiest to go from specific people on Github who are engaged in research in this area and spread their implementations of various architectures.
I would single out three:
Look to them in the repository, there is a whole storehouse of information. There are a lot of architectures and approaches to the E2E synthesis problem. Among the main ones:
We need to choose one. I chose Deep Convolutional Text-To-Speech (DCTTS) from Kyubyong Park as the basis for future experiments. The original article can be viewed at the link . Let's take a closer look at the implementation.
The author laid out the results of the synthesis in three different bases and at different stages of learning. For my taste, as not a native speaker, they sound quite decent. The latest database in English (Kate Winslet's Audiobook) contains only 5 hours of speech, which for me is also a great advantage, since my database contains approximately a comparable amount of data.
Some time after I trained my system, information appeared in the repository that the author had successfully trained a model for the Korean language. This is also quite important, since languages can vary greatly and robustness in relation to language is a pleasant addition. It can be expected that the learning process does not require a special approach to each set of training data: language, voice or some other characteristics.
Another important point for this kind of systems is the training time. Tacotron on the gland that I have, according to my estimates, would have studied for about 2 weeks. For prototyping at the initial level it seemed to me too resource-intensive. The pedals, of course, wouldn’t have to be turned, but it would take a lot of calendar time to create some kind of basic prototype. DCTTS in the final form is studying for a couple of days.
Every researcher has a set of tools that he uses in his work. Everyone chooses them to their liking. I love PyTorch very much. Unfortunately, I did not find the implementation of DCTTS on it, and I had to use TensorFlow. Perhaps at some point, I will post my implementation on PyTorch.
A good base for the implementation of synthesis is the main key to success. To the preparation of a new voice fit very thoroughly. A professional announcer pronounces pre-prepared phrases for many hours. For each utterance, you need to endure all the pauses, speak without jerks and delays, reproduce the correct contour of the main tone, and all this combined with the correct intonation. Among other things, not all voices sound equally pleasant.
I had about 8 hours base on my hands, recorded by a professional speaker. Now we are discussing with colleagues the opportunity to put this voice in free access for non-commercial use. If everything works out, then a distributive with a voice in addition to the recordings themselves will include the exact text for each of them.
We want to create a network that would accept text as input, and would produce synthesized sound at the output. The abundance of implementations shows that this is possible, but of course there are a number of reservations.
The main parameters of the system are usually called hyperparameters and are placed in a separate file, which is called appropriately: hparams.py or hyperparams.py , as in our case. Everything that can be twisted without touching the main code is taken into the hyperparameters. Starting from directories for logs, ending with the size of hidden layers. After this, the hyperparameters in the code are used like this:
Hereinafter, all variables with prefix hp. They are taken from the hyperparameters file. It is understood that these parameters do not change in the learning process, so be careful when restarting something with new parameters.
For text processing, the so-called embedding-layer is usually used, which is put first. Its essence is simple - it’s just a sign that associates with each character from the alphabet a certain vector of features. In the process of learning, we select the optimal values for these vectors, and when we synthesize according to the finished model, we simply take the values from this plate itself. This approach is used in the already quite widely known Word2Vec, where a vector representation for words is built.
For example, take the simple alphabet:
In the process of learning, we found out that the optimal values of each of their characters are as follows:
Then, for the aabbcc line , after passing the embedding layer, we get the following matrix:
This matrix is then fed to other layers that no longer use the concept of a symbol.
At this point, we see the first constraint that appears in us: the set of characters that we can send to synthesis is limited. For each character there must be some non-zero number of examples in the training data, preferably with a different context. This means that we need to be careful in choosing the alphabet.
In my experiments, I stopped at the option:
This is the alphabet of the Russian language, a hyphen, a space, and the end of a line. There are several important points and assumptions:
In future versions, you can pay more attention to each of the items, but for now we will leave in such a bit simplified form.
Almost all systems operate not by the signal itself, but by various kinds of spectra obtained on windows with a certain step. I will not go into details, there are quite a lot of different kinds of literature on this topic. Focus on implementation and use. The implementation of DCTTS uses two types of spectra: amplitude spectrum and chalk spectrum.
They are considered as follows (the code from this listing and all subsequent ones are taken from the DCTTS implementation, but modified for clarity):
For calculations, almost all E2E synthesis projects use the LibROSA library ( https://librosa.imtqy.com/librosa/ ). It contains a lot of useful, I recommend to look into the documentation and see what is in it.
Now let's see how the amplitude spectrum (magnitude spectrum) looks like on one of the files from the database I used:
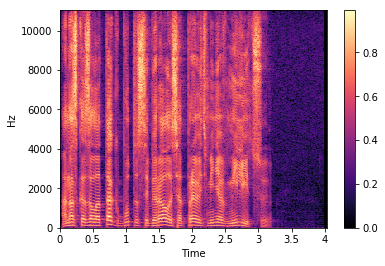
Such a variant of the representation of window spectra is called a spectrogram. On the abscissa axis is the time in seconds, on the y-axis - the frequency in Hertz. The color is the amplitude of the spectrum. The brighter the point, the greater the amplitude value.
A chalk spectrum is an amplitude spectrum, but taken on a chalk scale with a specific step and window. We set the number of steps in advance; in most implementations, the value 80 is used for the synthesis (set by the hp.n_mels parameter). The transition to the chalk spectrum makes it possible to greatly reduce the amount of data, but this preserves the characteristics important for the speech signal. The chalk spectrogram for the same file looks like this:
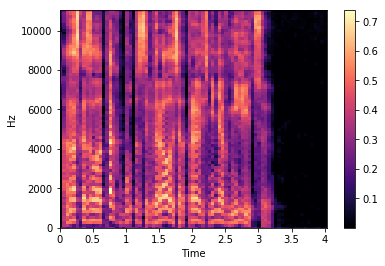
Notice the thinning of the chalk spectra in time on the last line of the listing. We take only every 4th vector ( hp.r == 4 ), thus reducing the sampling rate accordingly. Speech synthesis is reduced to predicting chalk spectra from a sequence of characters. The idea is simple: the less network you have to predict, the better it will be.
Well, we can get a spectrogram from the sound, but we can't listen to it. Accordingly, we need to be able to restore the signal back. For these purposes, the systems often use the Griffin-Lima algorithm and its more modern interpretations (for example, RTISILA, the link ). The algorithm allows the signal to be recovered from its amplitude spectra. The implementation I used:
And the signal from the amplitude spectrogram can be restored like this (steps inverse to obtaining the spectrum):
Let's try to get the amplitude spectrum, restore it back, and then listen.
Original:
Restored signal:
For my taste, the result has become worse. The authors of Tacotron (the first version also uses this algorithm) noted that they used the Griffin-Lim algorithm as a temporary solution to demonstrate the capabilities of the architecture. WaveNet and similar architectures allow synthesizing better-quality speech. But they are more heavy and require some effort for training.
DCTTS, which we have chosen, consists of two almost independent neural networks: Text2Mel and Spectrogram Super-resolution Network (SSRN).
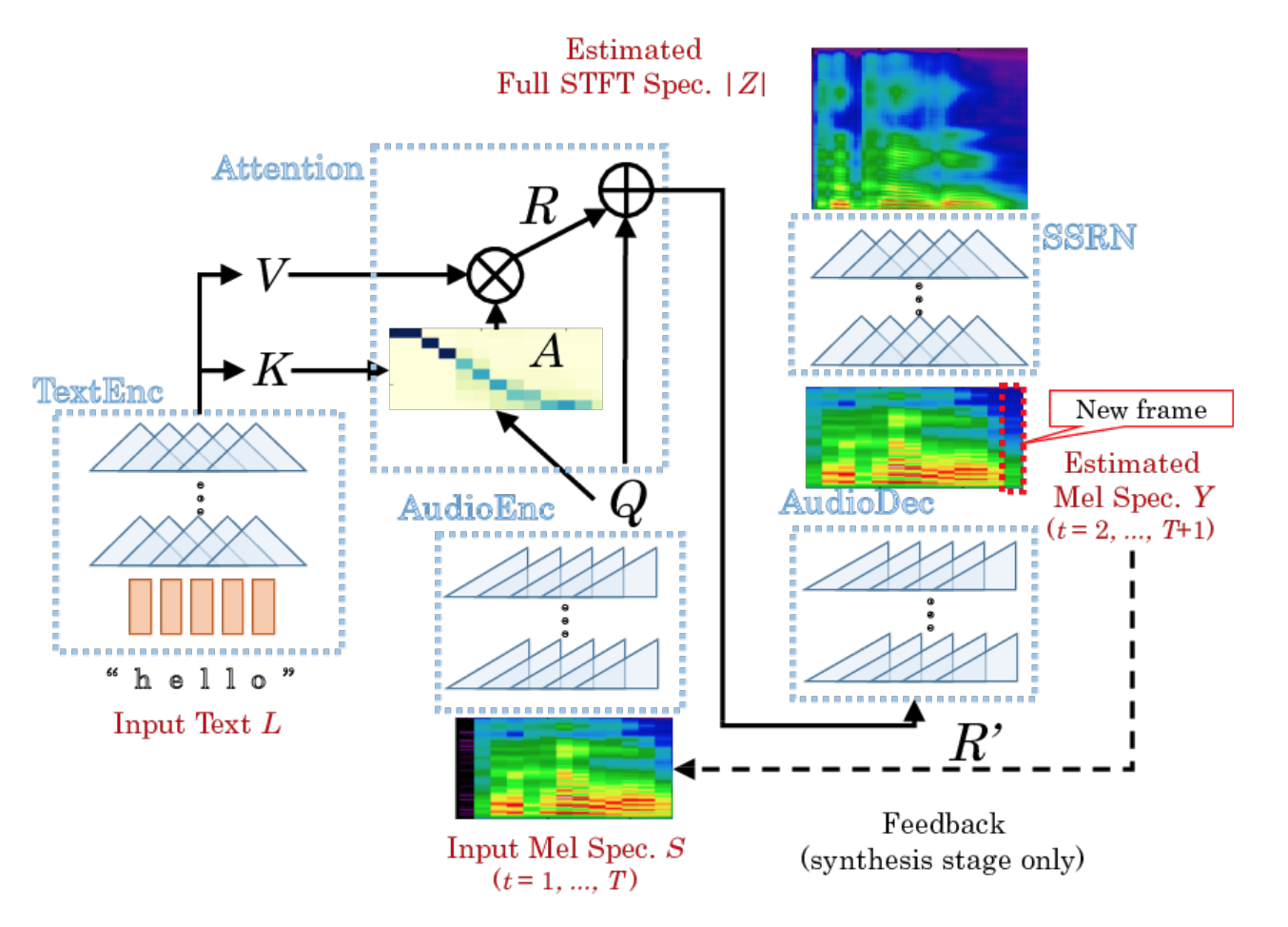
Text2Mel predicts the chalk spectrum on the text using the attention mechanism (Attention), which links two encoders (TextEnc, AudioEnc) and one decoder (AudioDec). Note that Text2Mel restores precisely the rarefied chalk spectrum.
SSRN recovers a full amplitude spectrum from the chalk spectrum, taking into account frame drops and restoring the sampling rate.
The sequence of calculations is described in some detail in the original article. In addition, there is the source code of the implementation, so you can always debug and delve into the subtleties. Please note that the author of the implementation has moved away from the article in some places. I would single out two points:
I took a voice that includes 8 hours of recordings (several thousand files). Left only entries that:
I got a little more than 5 hours. I counted the necessary spectra for all the records and in turn started the training of Text2Mel and SSRN. All this is done fairly simple:
Please note that in the original repository prepro.py is referred to as prepo.py . My inner perfectionist could not tolerate this, so I renamed it.
DCTTS contains only convolutional layers, and unlike RNN implementations like Tacotron, it learns much faster.
On my machine with an Intel Core i5-4670, 16 Gb of RAM and a GeForce 1080 on board, 50 thousand steps for Text2Mel learns in 15 hours, and 75 thousand steps for SSRN in 5 hours. The time required for a thousand steps in the learning process, I almost did not change, so you can easily estimate how long it will take to study with a large number of steps.
The size of the batch can be adjusted with the hp.B parameter. Periodically, the learning process I fell into out-of-memory, so I just divided the size of the batch by 2 and restarted the training from scratch. I believe that the problem lies somewhere in the depths of TensorFlow (I used not the freshest) and the intricacies of the implementation of batching. I did not begin to deal with this, since on the value of 8 everything stopped falling.
After the models have learned, you can finally run the synthesis. To do this, fill in the file with phrases and run:
I corrected implementation a little to generate phrases from the necessary file.
The results as wav files will be saved in the samples directory. Here are examples of the synthesis system, which turned out for me:
The result exceeded my personal expectations in quality. The system places the stress, the speech is legible, and the voice is recognizable. In general, it turned out quite well for the first version, especially given the fact that only 5 hours of training data were used for training.
There are questions about the controllability of such a synthesis. While it is impossible to even correct the stress in the word, if it is wrong. We are rigidly tied to the maximum length of the phrase and the size of the chalk spectrogram. There is no way to control intonation and playback speed.
I did not post my changes to the code of the original implementation. They touched only the download of training data and phrases for the synthesis of a ready-made system, as well as the values of hyper parameters : the alphabet ( hp.vocab ) and the size of the batch ( hp.B ). The rest of the implementation remained original.
As part of the story, I didn’t touch upon the production of such systems at all; before this, E2E speech synthesis systems are still very far away. I used a GPU with CUDA, but even in this case, everything is slower than real time. On the CPU, everything works just indecently slowly.
All these questions will be solved in the coming years by large companies and scientific communities. I am sure that it will be very interesting.
Some time ago machine learning came to the field of speech synthesis, as well as in many other areas. It turned out that a number of components of the entire system can be replaced with neural networks, which will allow not only to approach the existing algorithms in quality, but even to significantly surpass them.
')
I decided to try to make a fully neural network synthesis with my own hands, and at the same time share my experience with the community. What came out of this, you can find out by looking under the cat.
Speech synthesis
To build a speech synthesis system, we need a whole team of specialists from different areas. For each of them there is a whole mass of algorithms and approaches. Written doctoral dissertations and thick books describing the fundamental approaches. Let's first understand the surface of each of them.
Linguistics
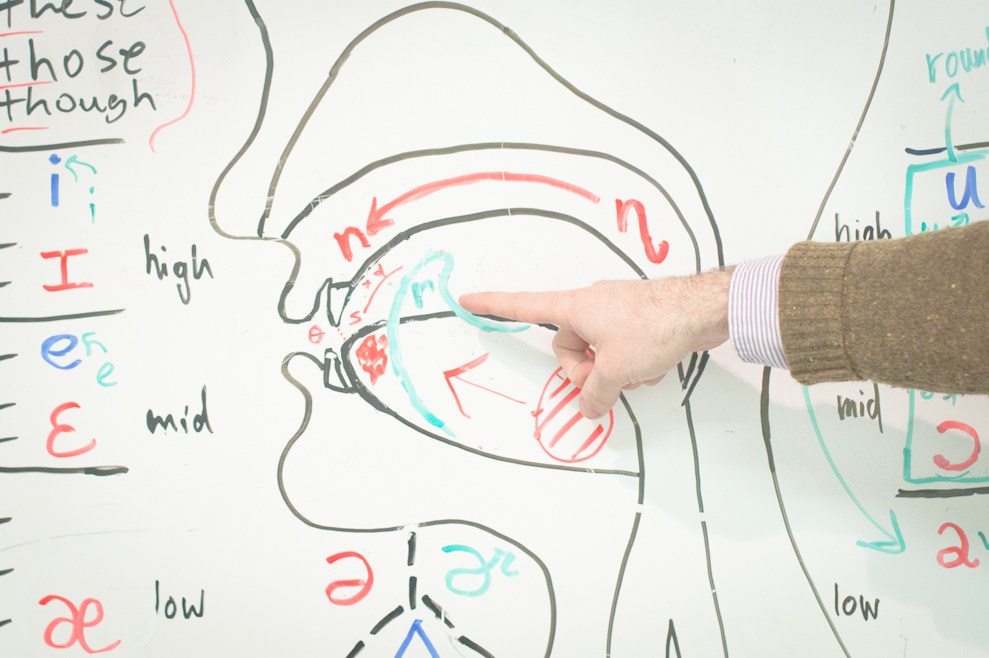
- Normalization of the text . First we need to expand all abbreviations, numbers and dates into text. The 50s of the 20th century should turn into the fifties of the twentieth century , and the city of St. Petersburg, Bolshoy Prospect P.S. to the city of St. Petersburg, Bolshoi Prospekt Petrogradskoy Side . This should occur as naturally as if the person was asked to read the writing.
- Prepare a dictionary of stress . The placement of stresses can be made according to the rules of the language. In English, stress is often placed on the first syllable, and in Spanish - on the penultimate. At the same time, there is a whole mass of exceptions from these rules that are not susceptible to any general rule. They must be taken into account. For the Russian language in the general sense, the rules of placement of accents do not exist at all, so that without a dictionary with accented accents there is absolutely no way to go.
- Removing homography . Omographs are words that are the same in spelling, but differ in pronunciation. A native speaker can easily stress: a door lock and a castle on a mountain . But the key to the lock - the task is more complicated. It is impossible to completely remove the homography without context.
Prosodic
- Selection of syntagmas and pause arrangement . Syntagma is a relatively complete segment of speech. When a person speaks, he usually inserts a pause between phrases. We need to learn how to divide the text into such syntagmas.
- Determination of the type of intonation . The expression of completeness, question and exclamation - the most simple intonation. But to express the irony, doubt or inspiration task is much more difficult.
Phonetics
- Receiving transcription . Since in the end we work with pronouncing rather than spelling, it is obvious that instead of letters (graphemes), it is logical to use sounds (phonemes). The transformation of a grapheme entry into a phonemic one is a separate task consisting of a set of rules and exceptions.
- Calculation of intonation parameters . At this point, it is necessary to decide how the pitch of the pitch and the speed of pronunciation will vary depending on the pauses placed, the selected sequence of phonemes and the type of intonation expressed. In addition to the basic tone and speed, there are other parameters with which you can experiment for a long time.
Acoustics
- Selection of sound elements . Synthesis systems operate on the so-called allophones — implementations of phonemes that depend on the environment. Records from the training data are cut into pieces by phoneme markup, which form the allophone base. Each allophone is characterized by a set of parameters such as context (phonemes neighbors), pitch, duration, and others. The synthesis process itself is the selection of the correct sequence of allophones most suitable in the current conditions.
- Modification and sound effects . For the resulting records sometimes need post-processing, some special filters that make synthesized speech a little closer to human or correct some defects.
If suddenly it seemed to you that all this can be simplified, figured out in your head, or quickly select some heuristics for individual modules, then just imagine that you need to do a synthesis in Hindi. If you do not speak the language, you will not even be able to assess the quality of your synthesis without attracting someone who would speak the language at the right level. My mother tongue is Russian, and I hear when the synthesis is mistaken in accents or speaks with the wrong intonation. But at the same time, all the synthesized English for me sounds about the same, not to mention the more exotic languages.
Implementations
We will try to find the End-2-End (E2E) implementation of the synthesis, which would take on all the difficulties associated with the subtleties of the language. In other words, we want to build a system based on neural networks, which would accept text at the input, and give synthesized speech at the output. Is it possible to train such a network that would allow replacing a whole team of specialists from narrow areas with a team (perhaps even from one person) specializing in machine learning?
At the end2end tts query, Google produces a whole lot of results. Led by - the implementation of Tacotron from Google itself. It seemed to me the easiest to go from specific people on Github who are engaged in research in this area and spread their implementations of various architectures.
I would single out three:
Look to them in the repository, there is a whole storehouse of information. There are a lot of architectures and approaches to the E2E synthesis problem. Among the main ones:
- Tacotron (version 1, 2).
- DeepVoice (versions 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
We need to choose one. I chose Deep Convolutional Text-To-Speech (DCTTS) from Kyubyong Park as the basis for future experiments. The original article can be viewed at the link . Let's take a closer look at the implementation.
The author laid out the results of the synthesis in three different bases and at different stages of learning. For my taste, as not a native speaker, they sound quite decent. The latest database in English (Kate Winslet's Audiobook) contains only 5 hours of speech, which for me is also a great advantage, since my database contains approximately a comparable amount of data.
Some time after I trained my system, information appeared in the repository that the author had successfully trained a model for the Korean language. This is also quite important, since languages can vary greatly and robustness in relation to language is a pleasant addition. It can be expected that the learning process does not require a special approach to each set of training data: language, voice or some other characteristics.
Another important point for this kind of systems is the training time. Tacotron on the gland that I have, according to my estimates, would have studied for about 2 weeks. For prototyping at the initial level it seemed to me too resource-intensive. The pedals, of course, wouldn’t have to be turned, but it would take a lot of calendar time to create some kind of basic prototype. DCTTS in the final form is studying for a couple of days.
Every researcher has a set of tools that he uses in his work. Everyone chooses them to their liking. I love PyTorch very much. Unfortunately, I did not find the implementation of DCTTS on it, and I had to use TensorFlow. Perhaps at some point, I will post my implementation on PyTorch.
Data for training
A good base for the implementation of synthesis is the main key to success. To the preparation of a new voice fit very thoroughly. A professional announcer pronounces pre-prepared phrases for many hours. For each utterance, you need to endure all the pauses, speak without jerks and delays, reproduce the correct contour of the main tone, and all this combined with the correct intonation. Among other things, not all voices sound equally pleasant.
I had about 8 hours base on my hands, recorded by a professional speaker. Now we are discussing with colleagues the opportunity to put this voice in free access for non-commercial use. If everything works out, then a distributive with a voice in addition to the recordings themselves will include the exact text for each of them.
Let's start
We want to create a network that would accept text as input, and would produce synthesized sound at the output. The abundance of implementations shows that this is possible, but of course there are a number of reservations.
The main parameters of the system are usually called hyperparameters and are placed in a separate file, which is called appropriately: hparams.py or hyperparams.py , as in our case. Everything that can be twisted without touching the main code is taken into the hyperparameters. Starting from directories for logs, ending with the size of hidden layers. After this, the hyperparameters in the code are used like this:
from hyperparams import Hyperparams as hp batch_size = hp.B # Hereinafter, all variables with prefix hp. They are taken from the hyperparameters file. It is understood that these parameters do not change in the learning process, so be careful when restarting something with new parameters.
Text
For text processing, the so-called embedding-layer is usually used, which is put first. Its essence is simple - it’s just a sign that associates with each character from the alphabet a certain vector of features. In the process of learning, we select the optimal values for these vectors, and when we synthesize according to the finished model, we simply take the values from this plate itself. This approach is used in the already quite widely known Word2Vec, where a vector representation for words is built.
For example, take the simple alphabet:
['a', 'b', 'c'] In the process of learning, we found out that the optimal values of each of their characters are as follows:
{ 'a': [0, 1], 'b': [2, 3], 'c': [4, 5] } Then, for the aabbcc line , after passing the embedding layer, we get the following matrix:
[[0, 1], [0, 1], [2, 3], [2, 3], [4, 5], [4, 5]] This matrix is then fed to other layers that no longer use the concept of a symbol.
At this point, we see the first constraint that appears in us: the set of characters that we can send to synthesis is limited. For each character there must be some non-zero number of examples in the training data, preferably with a different context. This means that we need to be careful in choosing the alphabet.
In my experiments, I stopped at the option:
# vocab = "E -" This is the alphabet of the Russian language, a hyphen, a space, and the end of a line. There are several important points and assumptions:
- I did not add punctuation to the alphabet. On the one hand, we really do not pronounce them. On the other hand, by the punctuation marks we divide the phrase into parts (syntagmas), dividing them into pauses. How can the system say the execution can not be pardoned ?
- The alphabet has no numbers. We expect that they will be deployed in numerals before serving for synthesis, that is, normalized. In general, all the E2E architectures that I have seen require exactly normalized text.
- The alphabet has no Latin characters. The English system will not be able to pronounce. You can try a transliteration and get a strong Russian accent - the notorious mi spik frome May hart .
- The alphabet has the letter . In the data for which I trained the system, it stood where it was needed, and I decided not to change this alignment. However, at that moment, when I was evaluating the results, it turned out that now, before applying for synthesis, this letter also needs to be set correctly, otherwise the system says exactly e , not .
In future versions, you can pay more attention to each of the items, but for now we will leave in such a bit simplified form.
Sound
Almost all systems operate not by the signal itself, but by various kinds of spectra obtained on windows with a certain step. I will not go into details, there are quite a lot of different kinds of literature on this topic. Focus on implementation and use. The implementation of DCTTS uses two types of spectra: amplitude spectrum and chalk spectrum.
They are considered as follows (the code from this listing and all subsequent ones are taken from the DCTTS implementation, but modified for clarity):
# y, sr = librosa.load(wavename, sr=hp.sr) # y, _ = librosa.effects.trim(y) # Pre-emphasis y = np.append(y[0], y[1:] - hp.preemphasis * y[:-1]) # linear = librosa.stft(y=y, n_fft=hp.n_fft, hop_length=hp.hop_length, win_length=hp.win_length) # mag = np.abs(linear) # - mel_basis = librosa.filters.mel(hp.sr, hp.n_fft, hp.n_mels) mel = np.dot(mel_basis, mag) # mel = 20 * np.log10(np.maximum(1e-5, mel)) mag = 20 * np.log10(np.maximum(1e-5, mag)) # mel = np.clip((mel - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1) mag = np.clip((mag - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1) # mel = mel.T.astype(np.float32) mag = mag.T.astype(np.float32) # t = mel.shape[0] num_paddings = hp.r - (t % hp.r) if t % hp.r != 0 else 0 mel = np.pad(mel, [[0, num_paddings], [0, 0]], mode="constant") mag = np.pad(mag, [[0, num_paddings], [0, 0]], mode="constant") # - mel = mel[::hp.r, :] For calculations, almost all E2E synthesis projects use the LibROSA library ( https://librosa.imtqy.com/librosa/ ). It contains a lot of useful, I recommend to look into the documentation and see what is in it.
Now let's see how the amplitude spectrum (magnitude spectrum) looks like on one of the files from the database I used:
Such a variant of the representation of window spectra is called a spectrogram. On the abscissa axis is the time in seconds, on the y-axis - the frequency in Hertz. The color is the amplitude of the spectrum. The brighter the point, the greater the amplitude value.
A chalk spectrum is an amplitude spectrum, but taken on a chalk scale with a specific step and window. We set the number of steps in advance; in most implementations, the value 80 is used for the synthesis (set by the hp.n_mels parameter). The transition to the chalk spectrum makes it possible to greatly reduce the amount of data, but this preserves the characteristics important for the speech signal. The chalk spectrogram for the same file looks like this:
Notice the thinning of the chalk spectra in time on the last line of the listing. We take only every 4th vector ( hp.r == 4 ), thus reducing the sampling rate accordingly. Speech synthesis is reduced to predicting chalk spectra from a sequence of characters. The idea is simple: the less network you have to predict, the better it will be.
Well, we can get a spectrogram from the sound, but we can't listen to it. Accordingly, we need to be able to restore the signal back. For these purposes, the systems often use the Griffin-Lima algorithm and its more modern interpretations (for example, RTISILA, the link ). The algorithm allows the signal to be recovered from its amplitude spectra. The implementation I used:
def griffin_lim(spectrogram, n_iter=hp.n_iter): x_best = copy.deepcopy(spectrogram) for i in range(n_iter): x_t = librosa.istft(x_best, hp.hop_length, win_length=hp.win_length, window="hann") est = librosa.stft(x_t, hp.n_fft, hp.hop_length, win_length=hp.win_length) phase = est / np.maximum(1e-8, np.abs(est)) x_best = spectrogram * phase x_t = librosa.istft(x_best, hp.hop_length, win_length=hp.win_length, window="hann") y = np.real(x_t) return y And the signal from the amplitude spectrogram can be restored like this (steps inverse to obtaining the spectrum):
# mag = mag.T # mag = (np.clip(mag, 0, 1) * hp.max_db) - hp.max_db + hp.ref_db # mag = np.power(10.0, mag * 0.05) # wav = griffin_lim(mag**hp.power) # De-pre-emphasis wav = signal.lfilter([1], [1, -hp.preemphasis], wav) Let's try to get the amplitude spectrum, restore it back, and then listen.
Original:
Restored signal:
For my taste, the result has become worse. The authors of Tacotron (the first version also uses this algorithm) noted that they used the Griffin-Lim algorithm as a temporary solution to demonstrate the capabilities of the architecture. WaveNet and similar architectures allow synthesizing better-quality speech. But they are more heavy and require some effort for training.
Training
DCTTS, which we have chosen, consists of two almost independent neural networks: Text2Mel and Spectrogram Super-resolution Network (SSRN).
Text2Mel predicts the chalk spectrum on the text using the attention mechanism (Attention), which links two encoders (TextEnc, AudioEnc) and one decoder (AudioDec). Note that Text2Mel restores precisely the rarefied chalk spectrum.
SSRN recovers a full amplitude spectrum from the chalk spectrum, taking into account frame drops and restoring the sampling rate.
The sequence of calculations is described in some detail in the original article. In addition, there is the source code of the implementation, so you can always debug and delve into the subtleties. Please note that the author of the implementation has moved away from the article in some places. I would single out two points:
- Additional layers appeared for normalization (normalization layers), without which, according to the author, nothing worked.
- The implementation uses a dropout mechanism for better regularization. This article is not.
I took a voice that includes 8 hours of recordings (several thousand files). Left only entries that:
- The texts contain only letters, spaces and hyphens.
- The length of the text does not exceed hp.max_N .
- The length of the chalk spectra after thinning does not exceed hp.max_T .
I got a little more than 5 hours. I counted the necessary spectra for all the records and in turn started the training of Text2Mel and SSRN. All this is done fairly simple:
$ python prepro.py $ python train.py 1 $ python train.py 2 Please note that in the original repository prepro.py is referred to as prepo.py . My inner perfectionist could not tolerate this, so I renamed it.
DCTTS contains only convolutional layers, and unlike RNN implementations like Tacotron, it learns much faster.
On my machine with an Intel Core i5-4670, 16 Gb of RAM and a GeForce 1080 on board, 50 thousand steps for Text2Mel learns in 15 hours, and 75 thousand steps for SSRN in 5 hours. The time required for a thousand steps in the learning process, I almost did not change, so you can easily estimate how long it will take to study with a large number of steps.
The size of the batch can be adjusted with the hp.B parameter. Periodically, the learning process I fell into out-of-memory, so I just divided the size of the batch by 2 and restarted the training from scratch. I believe that the problem lies somewhere in the depths of TensorFlow (I used not the freshest) and the intricacies of the implementation of batching. I did not begin to deal with this, since on the value of 8 everything stopped falling.
Result
After the models have learned, you can finally run the synthesis. To do this, fill in the file with phrases and run:
$ python synthesize.py I corrected implementation a little to generate phrases from the necessary file.
The results as wav files will be saved in the samples directory. Here are examples of the synthesis system, which turned out for me:
Conclusions and Remarks
The result exceeded my personal expectations in quality. The system places the stress, the speech is legible, and the voice is recognizable. In general, it turned out quite well for the first version, especially given the fact that only 5 hours of training data were used for training.
There are questions about the controllability of such a synthesis. While it is impossible to even correct the stress in the word, if it is wrong. We are rigidly tied to the maximum length of the phrase and the size of the chalk spectrogram. There is no way to control intonation and playback speed.
I did not post my changes to the code of the original implementation. They touched only the download of training data and phrases for the synthesis of a ready-made system, as well as the values of hyper parameters : the alphabet ( hp.vocab ) and the size of the batch ( hp.B ). The rest of the implementation remained original.
As part of the story, I didn’t touch upon the production of such systems at all; before this, E2E speech synthesis systems are still very far away. I used a GPU with CUDA, but even in this case, everything is slower than real time. On the CPU, everything works just indecently slowly.
All these questions will be solved in the coming years by large companies and scientific communities. I am sure that it will be very interesting.
Source: https://habr.com/ru/post/358816/
All Articles