Natural Language Processing

Today we are touching on such an interesting topic as natural languages . Now a lot of money is being invested in this area and many different tasks are being solved in it. It attracts the attention of not only the industry, but also the scientific community.
Can a car think?
Researchers associate the analysis of natural languages with the fundamental question: can a machine think? René Descartes, the famous philosopher, gave an unambiguously negative answer. Not surprising, given the level of development of technology of the XVII century. Descartes believed that the machine could not and would never learn to think. A machine can never communicate with a person using natural speech. Even if we explain to her how to use and pronounce the words, it will still be memorized phrases, standard answers - the machine will not go beyond them.
Turing Test
Many years have passed since then, the technique has changed quite a lot, and in the 20th century this question became relevant again. The famous scientist Alan Turing in 1950 doubted that the car could not think, and offered his famous test for verification.
')
The idea of the test, according to legend, is based on the game that was practiced at student parties. Two people from the company - a boy and a girl - went to different rooms, and the rest of the people communicated with them using notes. The players' task was to guess who they were dealing with: a man or a woman. And the guy and the girl were pretending to be each other in order to mislead the rest of the players. Turing made a fairly simple modification. He replaced one of the hidden players with a computer and invited the participants to recognize with whom they interact: with the person or with the machine.
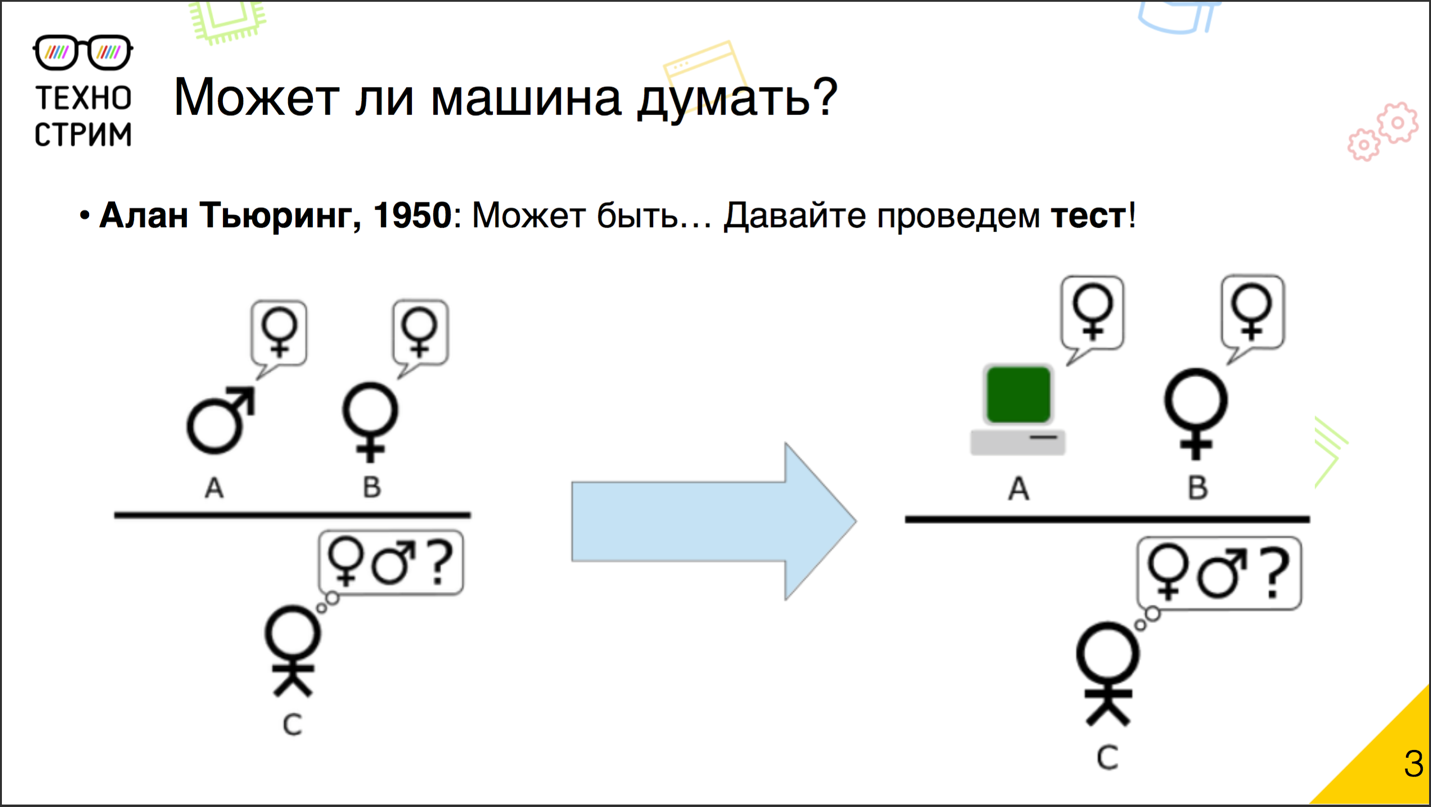
The Turing test was invented more than half a century ago. Programmers have repeatedly stated that their child passed the test. Every time there were controversial demands and questions, is it really so. There is no official authentic version of whether someone coped with the main Turing test. Some of its variations have actually been successfully completed.
Georgetown experiment
In 1954 he passed the Georgetown experiment . It included a system that automatically translated 60 sentences from Russian into French. The organizers were confident that in just three years they would achieve a global goal: they would completely solve the problem of machine translation. And failed miserably. After 12 years, the program was closed. No one could come close to solving this problem.
From a modern position it can be said: the main problem consisted in a small number of sentences. In this embodiment, the problem is almost impossible to solve. And if experimenters conducted an experiment on 60 thousand or maybe even 6 million sentences, then they would have a chance.
First chat bots
In the 1960s, the first chat bots appeared, very primitive: they mainly rephrased what the other person said to them. Modern chat bots are not far from their ancestors. Even the famous chat bot Zhenya Gustman , who is believed to have passed one of the versions of the Turing test, did not do this thanks to clever algorithms. Acting skills helped much more: the authors thought out his personality well.
Formal ontologies, Chomsky's grammar theory
Then came the era of formal methods. It was a global trend. Scientists tried to formalize everything, build a formal model, ontology, concepts, relationships, general rules of syntactic analysis and universal grammar. Then the theory of Chomsky's grammar arose. It all looked very nice, but it never reached adequate practical use, because it required a lot of hard manual work. Therefore, in the 1980s, attention shifted to a system of another class: machine learning algorithms and so-called corpus linguistics.
Machine learning and corpus linguistics
What is the main idea of corpus linguistics? We collect a corpus — a collection of documents that is large enough, and then, using machine learning methods and statistical analysis, we are trying to build a system that will solve our problem.
In the 1990s, this area received a very powerful impetus due to the development of the World Wide Web with a large amount of weakly structured text that needed to be searched, it was required to be cataloged. In the 2000s, the analysis of natural languages began to be used not only for searching the Internet, but also for solving various problems. There were large datasets with text, a lot of various tools, companies began to invest big money in it.
Modern trends
What is happening now? The main trends that can be identified in the analysis of natural languages is the active use of unsupervised learning models. They allow you to identify the structure of the text, a body without any predetermined rules. In the open access there are many large accessible buildings of different quality, marked up and not. There were models based on crowdsourcing: we are not only trying to understand something with the help of the machine, but we connect people who, for a small fee, determine in what language the text is written. In a sense, the idea of using formal ontologies began to revive, but now ontologies revolve around crowdsourcing knowledge bases, in particular, databases based on Linked Open Data . This is a whole set of knowledge bases, its center is the computer-readable version of Wpipedia DBpedia , which is also filled with a crowdsourcing model. People around the world can add something to it.
About six years ago, NLP (natural language processing, processing of natural languages) mainly absorbed techniques and methods from other areas, but over time it began to export them. Methods that have evolved in the field of natural language analysis have begun to be successfully applied in other areas. And of course, where without deep learning? Now, when analyzing natural languages, deep neural networks are also beginning to be used, so far with varying success.
What is NLP? This is not to say that NLP is a specific task. NLP is a huge range of tasks at various levels. By level of detail, for example, you can break them down like this.

At the signal level, we need to convert the input signal. This may be a speech, a manuscript, printed scanned text. It is required to convert it into a record consisting of characters that the machine can work with.
Next comes the word level . Our task is to understand that there is a word here in general, to conduct its morphological analysis, to correct mistakes, if any. Slightly higher - the level of phrases. On it there are parts of speech that need to be able to determine, the task arises to recognize named entities. In some languages, even the task of isolating words is not trivial. For example, in German, there is not necessarily a space between words, and we need to be able to isolate words from a long record.
From phrases are formed sentences . It is necessary to distinguish them, sometimes - to conduct a syntactic analysis, try to formulate an answer, if the sentence is interrogative, eliminate the ambiguity of words, if required.
It should be noted that these tasks go in two directions: related to analysis and generation. In particular, if we have found the answer to a question, we need to create a sentence that will adequately look from the point of view of the person who will read it, and answer the question.
Sentences are grouped into paragraphs , and here the question of resolving references and establishing relationships between the objects mentioned in the different sentences already arises.
With paragraphs, we can solve new problems: analyze the emotional coloring of the text, determine in which language it is written.
Paragraphs form the document . The most interesting tasks work at this level. In particular, semantic analysis (what is the document about?), Generation of automatic annotation and automatic summary, translation and creation of documents. Everyone probably heard about the famous scientific article generator SCIgen , which created the article “Rooting: Algorithm of typical unification of access points and redundancy”. SCIgen regularly tests the editorial boards of scientific journals.
But there are tasks related to the body as a whole. In particular, to deduplicate a huge body of documents, look for information in it, etc.
Example of a problem: to whom to show the post on OK.RU?
For example, in our project OK.RU, better known as Odnoklassniki, there is the task of ranking the content in the feed. Someone from your friends or groups makes a post, and there are usually quite a few such posts, especially if you take into account the posts that your friends liked. We need to choose from a variety of records those that best suit you. What are the difficulties and opportunities?
We have a large dataset, there are already more than 2 billion posts, several million new ones can appear in a day. The records contain about 40 languages, including those that are poorly studied: Uzbek, Tajik. There is a lot of noise in the documents. These are not news and non-scientific articles, they are written by ordinary people - there are errors, typos, slang, spam, copy-paste and duplicates. It would seem, why even try to analyze the content, if there are already many methods based on collaborative filtering? But in the case of the tape, such recommendations work poorly: there is always a situation of cold start. We have a new object. We still barely know who and how interacted with him, but we have to decide who to show it to and who does not. Therefore, let's apply a classic workout for the cold start task and build a system of content recommendations: let's try to teach the machine to understand what the post is written about.
Problem from afar
Having looked at the problem from the height of bird flight, let us select the main blocks. First of all, the corpus is multilingual, so first let's find out the language of the document. Custom text contains typos. Accordingly, we need some kind of typo corrector to bring the text to the canonical form . To work with documents further, you need to be able to vectorize them. Since there are many duplicates in the package, deduplication cannot be done . But the most interesting - we want to know what this post is about. Accordingly, a semantic analysis method is required. And we want to understand the attitude of the author to the object and subject. This will help the analysis of emotional coloring.
Language definition
Let's start in order. Definition of language. It uses standard machine learning techniques with a teacher. We make some labeled corpus by languages and train the classifier. As a rule, simple statistical classifiers work quite well. As signs for these classifiers, N-grams are usually taken, that is, sequences of N (say, three) consecutive characters. Build a histogram of the distribution of sequences in the document and on its basis determine the language. In more advanced models, N-grams of a different dimension can be used, and from recent developments, we note N-grams of variable length, or, as the authors called them, infinitigrams.
Since the task is quite old, there are quite a few ready-made working tools. In particular, this is Apache Tika , the Japanese language-detection library and one of the latest developments is the Python package Ldig , which just works on infinitigrams.
These methods are good for fairly large texts. If there is a paragraph or at least five sentences, the language will be determined with an accuracy of more than 99%. But if the text is short, from one sentence or several words, then the classical approach based on trigrams is often mistaken. Infinitigrams can correct the situation, but this is a new area, and far from all languages already have trained and ready classifiers.
Reduction to canonical form
We have defined the language of the text. We need to bring it to the canonical form. What for? One of the key objects in text analysis is a dictionary, and the complexity of algorithms often depends on its size. Take all the words that were used in your body. Most likely, it will be tens or even hundreds of millions of words. If we look at them more closely, we will see that in reality these are not always separate words, sometimes word forms or words written with errors can be found. To reduce the size of the dictionary (and computational complexity) and improve the quality of the work of many models, we will reduce the words to canonical form.
First, correct errors and typos. In this area there are two approaches. The first is based on the so-called phonetic matching . Here is his main idea. Why is man wrong? Because he writes the word as he hears. If we take the right word and the word with an error, and then we write down how both are heard and pronounced, we get the same option. Accordingly, the error will no longer affect the analysis.
An alternative approach is the so-called editorial distance , with the help of which we are looking for the most similar analogous words in the dictionary. Editorial distance determines how many change operations are needed in order to quickly turn one word into another. The fewer operations required, the more words are similar.
So we fixed the errors. But still, in the same Russian language, a word can have a huge number of correct word forms with various endings, prefixes, and suffixes. This dictionary explodes quite strongly. It is necessary to bring the word to the main form. And here there are two concepts.
The first concept is stemming , we are trying to find the basis of the word. It can be said that this is the root, although linguists can argue. This uses the affix stripping approach. The basic idea is that we cut off the word bit by bit from the end and from the beginning. We delete the endings, prefixes, suffixes, and as a result just remains the main part. There is a well-known implementation, the so-called Porter stemmer, or the Snowball project. The main problem of the approach: the rules for the stemmer are established by linguists, and this is quite hard work. Before connecting a new language, linguistic research is needed.
There are variations of the approach. We can either just do a dictionary lookup, or build supervised models without a teacher, again, probabilistic models based on hidden Markov chains, or teach neural networks that will lead words into reduced form.
Stemming is used for a long time. In Google - since the early 2000s. The most common tool is probably the implementation in the Apache Lucene package. But stemming has a flaw. When we cut the word down to the base, we lose some of the information. Because we only have the root, and we can lose data on whether it was an adjective or a noun. And sometimes it is important for setting further tasks.
The second concept, an alternative to stemming, is lemmatization . She tries to lead the word not to the basis or the root, but to the basic, vocabulary form - that is, the lemma. For example, the verb - to the infinitive. There are many implementations, and the theme is very well developed for user generated texts, user noisy texts. However, the conversion into the canonical form still remains a difficult and not completely solved task.
Vectorization
Led to the canonical form. Now we will display it in vector space, because almost all mathematical models work in vector spaces of large dimensions. The basic approach that many models use is the word bag method. We form a vector for a document in space, the dimension of which is equal to the size of our dictionary. Each word has its own dimension, and for the document we write down the sign of how often this word was used in it. Get the vector. There are many approaches to finding out. Dominates the so-called TF-IDF . The word frequency (term frequency, TF) is defined differently. It can be a word occurrence counter. Or a flag, we have seen the word or not. Or something a little more cunning, for example, a logarithmically smoothed number of references to a word. And that's the most interesting. Having determined the TF in the document, we multiply it with the inverse document frequency (IDF). IDF is usually calculated as the logarithm of the number of documents in the corpus, divided by the number of documents where this word is represented. Here is an example. We met a word that was used in all-all-all documents of the corps. Obviously, the logarithm will give us zero. Such a word we will not add anywhere: it does not carry any information, it is in all documents.
What is the advantage of the word bag approach? It is easy to implement. But he loses some of the information, including word order information. And now they continue to break a lot of copies on how important word order is. We have one famous example - Master Yoda. He puts the words in the sentence in a chaotic way. Yoda's speech is unusual, but we freely understand it: that is, the human brain easily restores information even with a lost order.
But sometimes this information is meaningful. For example, when analyzing emotional coloring, it is very important what the word “good” or “no” refers to, relatively speaking. Then, along with a bag of words, an N-gram bag will help: we add not only words but also phrases to the dictionary. We will not introduce all phrases, because this will lead to a combinatorial explosion, but often used statistically significant pairs or pairs corresponding to the named entities can be added, and this will improve the quality of the work of the final model.
Another example of a situation where the “bag of words” can lose or distort information is words that are synonyms or words with several different meanings (for example, a lock). In part, these situations allow us to handle methods for constructing " vector representations of words ", for example, the famous word2vec or the more fashionable skip-gramm .
Deduplication
Vectorized. Now we clean the case from duplicates. The principle is clear. We have vectors in vector space, we can determine their proximity, take the cosine, we can other proximity metrics, but usually it is the cosine that is used. Let's unite in the general group documents where cosine is close to unit.
It would seem that everything is simple, understandable, but there is one thing but: we have 2 billion documents. If we multiply 2 billion by 2 billion, we will never finish counting cosines. Need optimization, which allows you to quickly select candidates for calculating the cosine, getting rid of the complete enumeration. And here a locally sensitive hash will help. Standard hash functions evenly spread the data over the hash space. A locally sensitive hash of similar objects will place objects in the space close. With some probability, it can even give them the same hash.
There are many techniques for calculating a locally sensitive hash for various similarity metrics. If we are talking about cosine, then the method of random projections is often used. We choose a random basis from random vectors. We consider the cosine of our document with one of the basis vectors. If it is greater than zero, then we put one. Less than zero or equal to it - set zero. Then we compare with the second basis vector, we get one more zero or one. How many vectors we have in the basis - we get so many bits as a result, and this is our hash.
What is the advantage, why does it work at all? If the two documents are close in cosine with each other, then with high probability they will be on the same side of the basis vector. Therefore, similar documents with a high probability will be one. However, emissions will be. To fix them, we just repeat the procedure. In practice, we usually use two runs. On the first, we calculate the 24-bit hash and delete many almost identical documents. Then we consider another hash on a different basis, but already in 16 bits and add duplicates. After this, there are no copies left - or there are so few of them that they cannot significantly affect the quality of the models' work.
Semantic analysis
And slowly we come to the most interesting. How do we understand what the document is about? The task of semantic analysis is quite old. The old school approach is as follows: we make the ontology described in advance, strict syntactic analysis, syntax tree nodes to concepts in our ontology, we make a lot of handwritten rules, etc., as a result we get semantics. All this is beautiful theoretically, but in practice does not work: where there are a lot of hand-written rules, it is hard to work.
The modern approach is an analysis of semantics without a teacher; therefore, it is called an analysis of hidden (latent) semantics. This method (or even a family of methods) works well on large packages - it only makes sense to start the search for hidden semantics on a large package. There, as a rule, there are relatively few parameters that can be pulled in, unlike sheets with rules in old school approaches, and there are ready-made tools: take and use.
Latent semantic index
Historically, the first approach to latent semantic analysis is latent semantic indexing . The idea is very simple. We have already used well-proven matrix factorization techniques for solving the problems of collaborative recommendations.
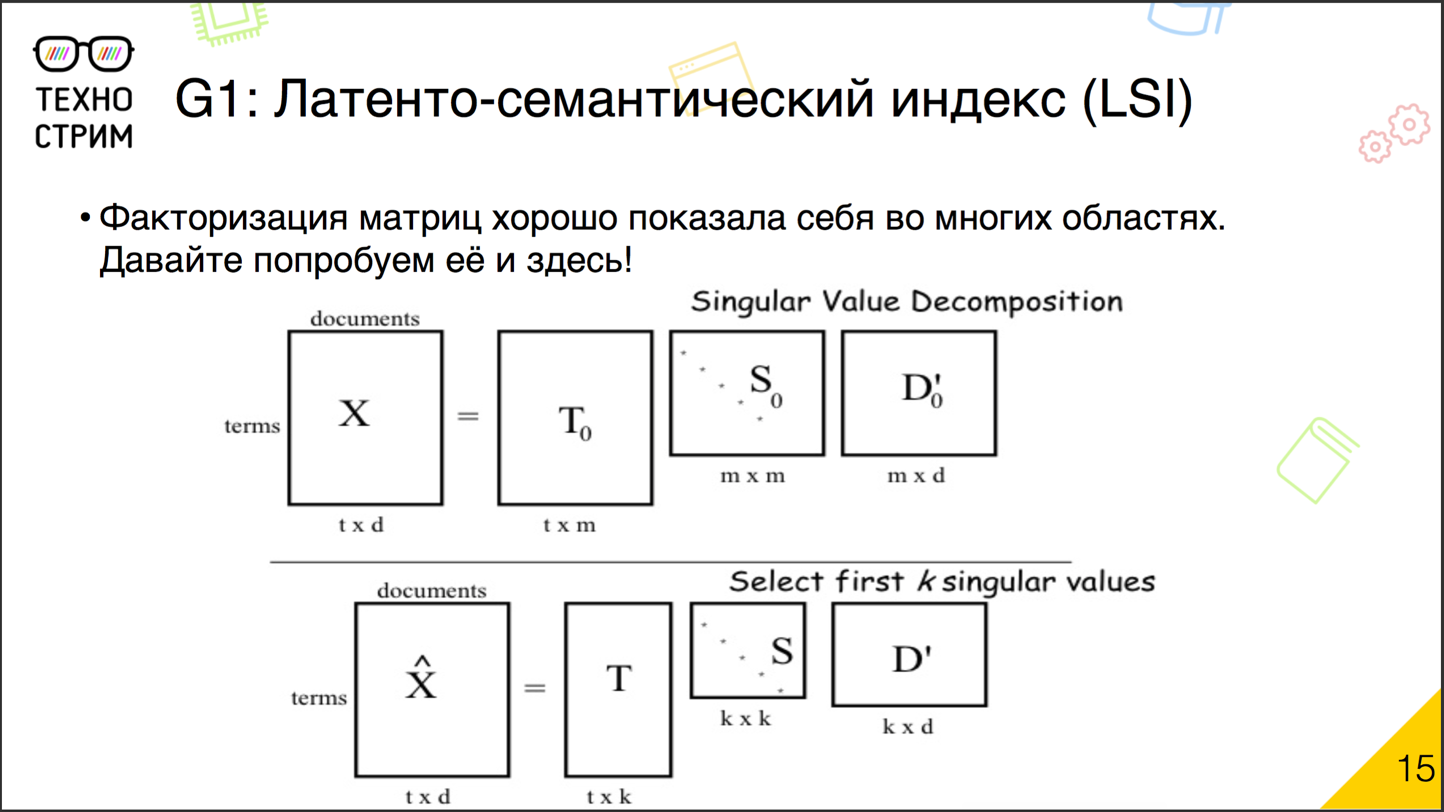
What is the essence of factorization? We have a large matrix, in recommendations it is a user - item (as far as the user likes item). We break it into pieces of small matrices. Now we have a matrix of user factors and factors of items. Then we take these two matrices (user - factor and factor - item) and multiply. We get a new user - item matrix. It, if we correctly factorized, as closely as possible corresponds to the matrix, which we initially decomposed. The same can be done with documents. We take the matrix "document - word" or "word - document" and decompose it into a product of two matrices: "document - factor" and "factor - word". It's simple, there are ready-made tools. With this approach, we automatically take into account words with various meanings, synonyms. If there are many misprints in the corpus, we will still understand that an incorrectly written word refers to such a hidden factor. , . 1990- . : . - . , . , , . .
-
- . .
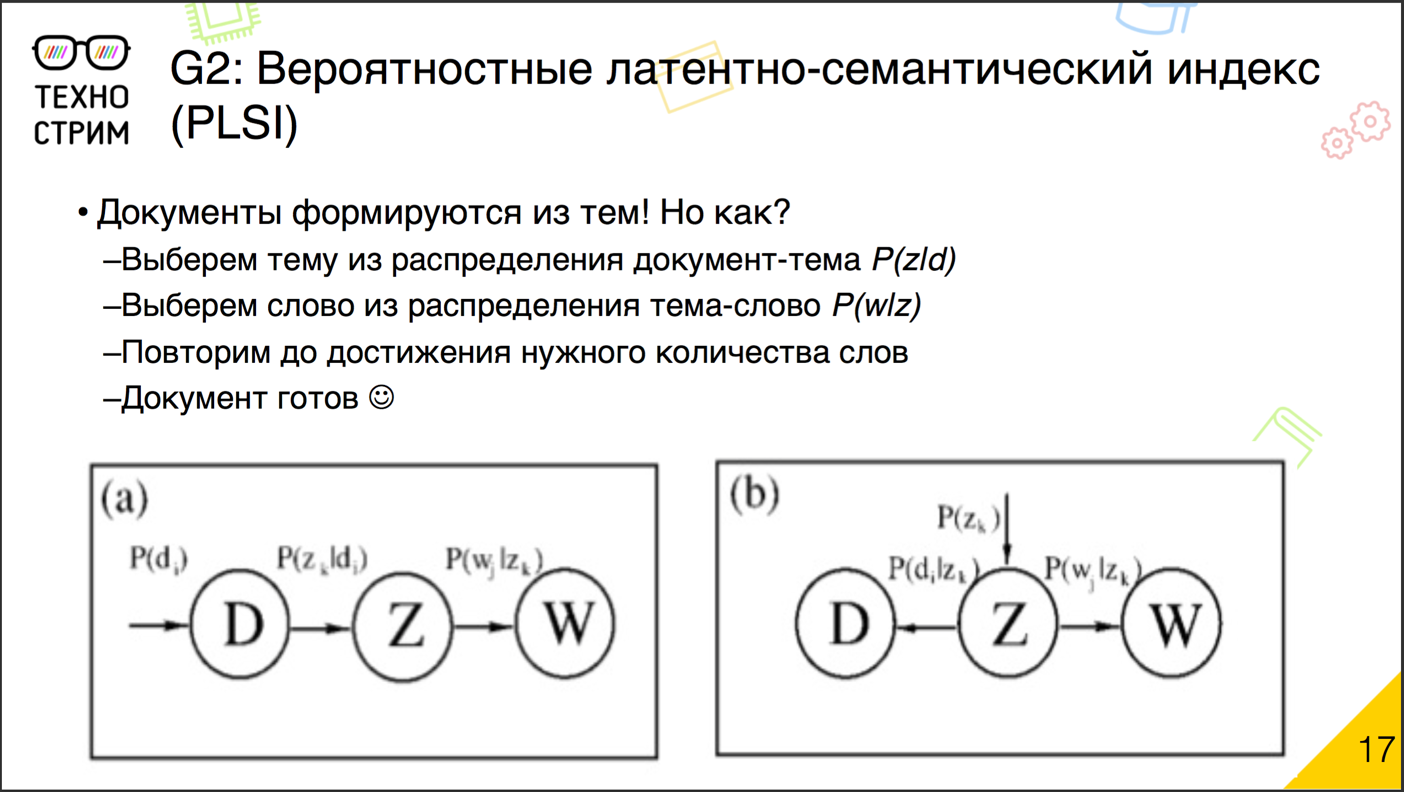
. , , , . , . . , . . . ( , , ), , .
, : .
, ? , - — . « — » : « — » « — ». , , - . . . , , , , , , : , .
— TF-. TF-IDF , .
, ? . . , , , , . .

. : , . , . . . « — » « — ». ? , .
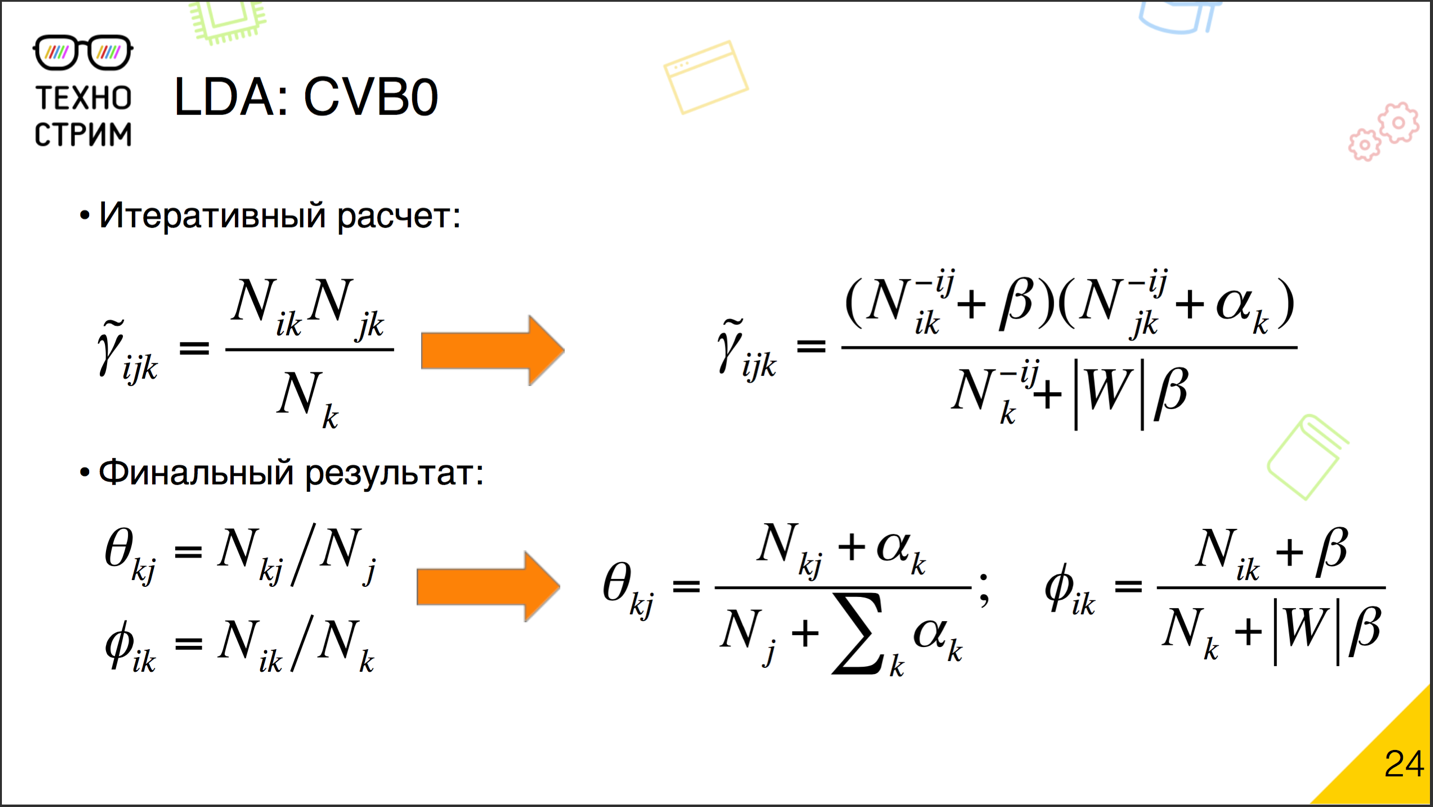
EM- . , , . . , . γ ijk : , .

. , N ik , γ ijk , — N ij . N jk , , γ ijk , . N k — . , . ijk , N ik , N jk N k γ ijk . — . γ ijk , γ ijk , , . γ ijk . . γ ijk , — γ ijk , . ., .
What you should pay attention to? -, . — : . . , , , γ ijk . , , γ ijk , . And that's all. γ ijk . . .
? « », « » « ». . ? . ? . , , .
, , . ? . . : « — » « — », , .

? . ( , ), . . , . , .
, . .

(Latent Dirichlet Allocation, LDA) — . , , .
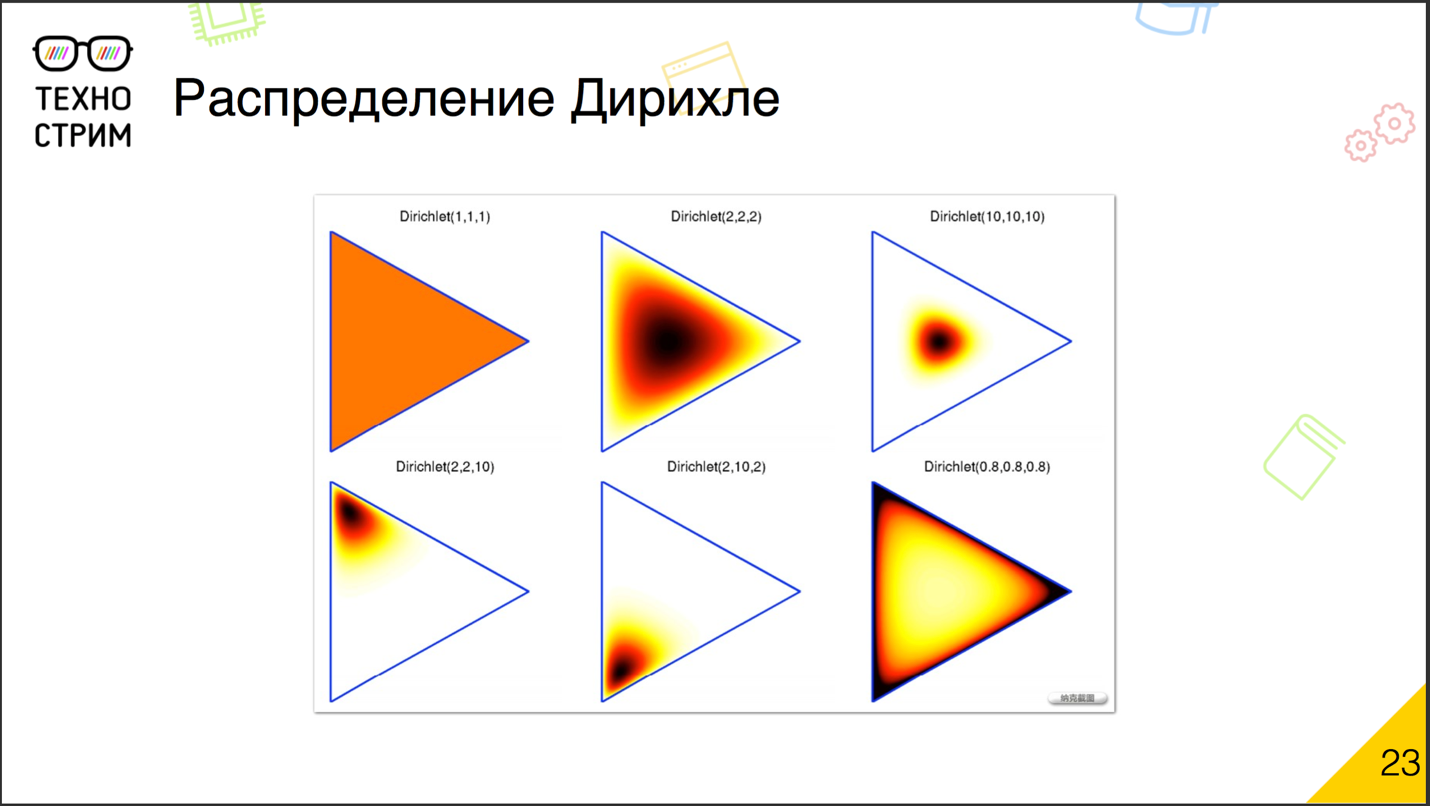
? : . ? , . , , , . , , , . — , . , - , , . , , : - .
? Very simple. , . γ ijk , . β , — α , , , . ? α β
: -, . , , . , .
. α α , β , β , .
, β , , ; , , , β . α . α — , — , . α . , domain specific themes, α , .
. . . , , . , .
. - .
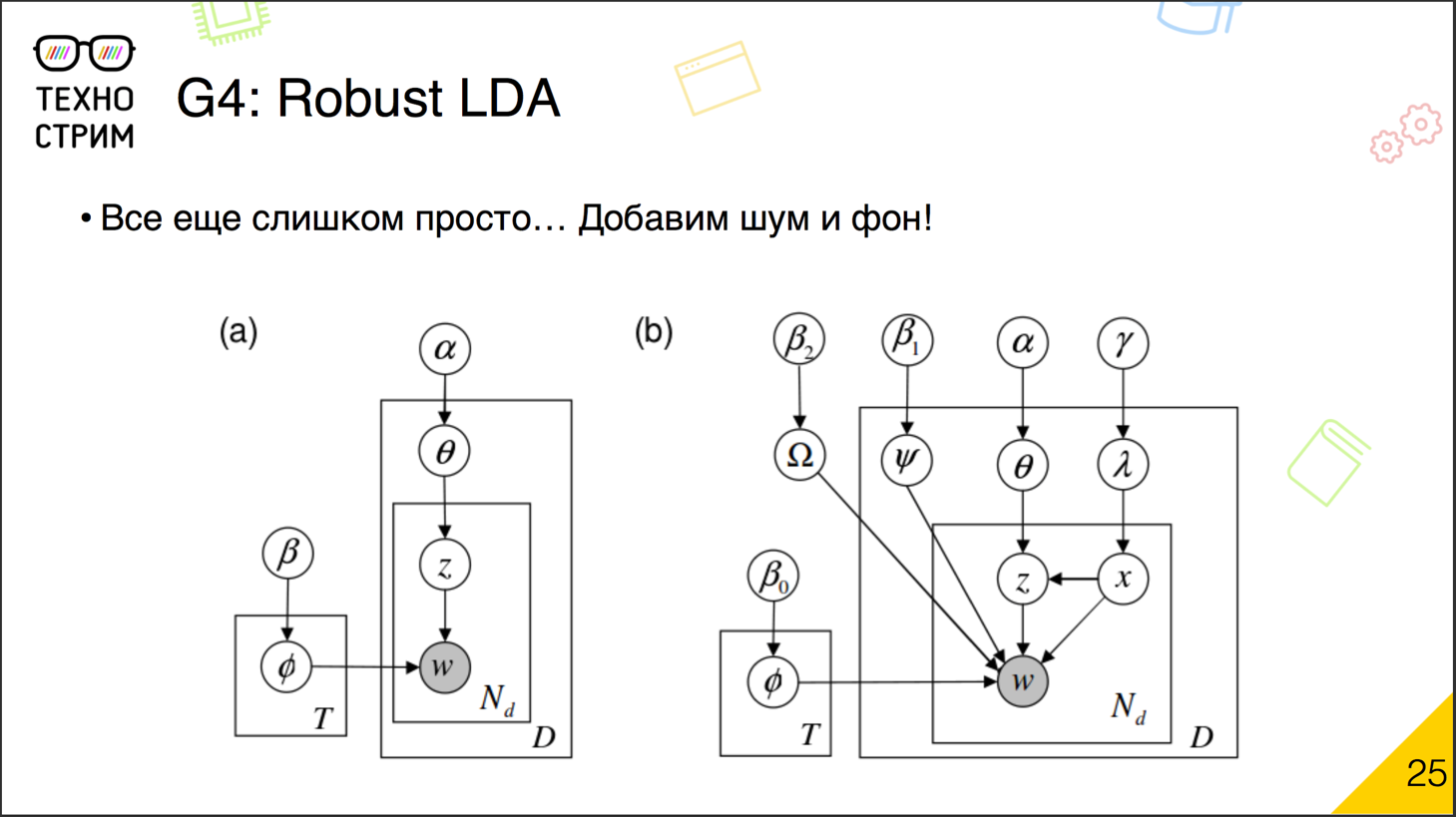
: .
. , — , . , . , -, . : , .
, — , . . — , . — , .
? , . . , , , — .

, John Snow. Snow — , Snow — . snow . , , , , . snow .
, . , , , .
What does it mean? — , , α β . , , — , . , , . .

? . , , . γ ijk , , . γ ijk Z , . , . , , , .
, , . — γ ij . : γ ij , . , γ ij , . , , , , , — .
« — » « — » , .
? . , , LDA. α β , , PLSA. α β , — PLSA-. .
. , . . , LDA-. .

, , , . . .

. , , , , , , , , . ? -, .
, . — , 1000, 250 . - , - .

, , , - , - , , , … — , , . . , . . , , , .
?
Naturally. There are many options for development. In particular, the topic “ Additive regularizers ” is now moving in Russia. In the formulas according to which we consider in the framework of an iterative update, we add new annotations, and each of them models the processes. Someone removes some of the topics, whose weight has become too small. Some kind of blurs the background topics or, conversely, flattens the domaine topics.
There are approaches aimed not only at adding regularizers, but also at complicating the generating model. For example, we will add new entities, tags, authors, readers of the document, they may have their own thematic distributions, and we will try to build a common on them.
There are attempts to cross this unsupervised LDA technique with labeled cases , when we have not the abstract Dirichlet distribution, but the distribution of topics on the marked body as the a priori distribution we want to preserve.
Interestingly, all these probabilities of the generating model are, in fact, techniques of matrix factorization. But, unlike head-on factorization on singular decomposition, these techniques support some form of interpretation. And so, LDA began to be used in other areas: they factorize the matrix of images, build collaborative recommendations on them. In the field of analysis of social networks and graphs, there is the topic of stochastic block modeling. As far as I understand, it developed more or less independently, but, in fact, it is also about factorization of matrices through a probabilistic generating model. That is, LDA and all that is dancing from it is what is exported from the analysis of natural languages to other areas.
A little about technology to unload from the numbers. The process is simple, but it takes time to build a thematic model on a large building. And we have no time. You need to understand the topic of the document that appeared right now.

We use this approach: we prepare the thematic model in advance. The model is based on the “topic-word” matrix. With the topic-word ready-cached matrix, we can tailor the document-topic distribution for a particular post when we see it. There is a regularly updated general thematic model, which is calculated by the standard map reduce, and there is a continuous stream of new posts. We process them with the help of streaming analysis tools and determine their topic on the fly - based on a pre-prepared topic-word matrix. This is a typical scheme. All machine learning algorithms in production usually work this way: the difficult part is preparing offline, the simpler part is online.
We have not yet talked about the analysis of emotional coloring. Good: we understood what the text was about, determined the probability distribution of topics. But how to understand whether the author is positive or negative about the topic?
As a rule, methods based on work with a teacher dominate here. We need a marked body of texts with positive and negative emotions, and on it we train the classifier. An approach based on a bag of words often leads to unsuccessful results. Emotions are sometimes expressed in the same words, it is the context that is important. Therefore, instead of a bag of words, N-gram bags are often used. By standard words or particles (for example, by "not") try to understand what it is. Studying the word, consider the checkbox if there was a particle “not” in front of it and at what distance. In addition, pay attention to the additional signs that the person allegedly nervous, or angry, or rejoiced when he wrote the text. There are a lot of exclamation marks, caps, non-printable characters inside words (potentially, this is shielding of foul language), etc. And they are training the classifier for all this.
Sometimes it works out well, especially if the classifier should be trained for a specific subject area. If we have a corpus of film reviews, then it’s quite realistic to train a classifier on emotions on it. The problem is that this classifier will most likely no longer work on restaurant reviews. There will be other words that often express the attitude to the restaurant. So far, successful solutions to the analysis of emotional coloration are mainly oriented specifically.
The size of the text is important enough, because emotions often change. We may have a paragraph or several sentences with one emotional message, and the others with another. For example, in reviews we sometimes write what we liked and what didn’t. Therefore it is necessary to divide the document into such areas.
As a result, emotions for medium texts are best defined. Too small - there is a risk that there is not enough information, and too long - the result is too vague.
The popular enough library SentiStrength has a web service where you can add sentences and texts and determine what kind of emotion they contain. But it must be said that here the task of classification is non-binary: as a rule, these methods say not just “positive” or “negative”, but “positive with such and such power”. Perhaps this is one of the least solved problems in this stack, and there is still much to be developed.
At the end, I will go a little more on tasks that have not yet been solved.
To begin with, this is the conversion of user texts to canonical form. We can fix typos and stamp. When we try to combine all this, it often turns out badly. For short texts, an infinitigram approach is needed: it still does not have normal industrial implementations, and it is unclear whether it will work. Thematic modeling for short texts is also difficult. The fewer the words, the more difficult it is for us to understand what the meaning is.
Another task that I haven’t talked about yet. Well, we understood what subject the document is about. But we also have a user. Objective: try to build its semantic profile. Connect semantics with emotions. It is not enough to understand that there are such and such topics and emotions. It is necessary to find out what topic caused what feelings.
It is interesting to explore thematic models in time: how they are transformed, how new themes arise and the vocabulary of existing ones changes. Deduplication works well on texts that contain copies, but can stall on texts where these copies are intentionally distorted: I'm talking about antispam. That is, this is a huge area where there are many different solutions, but even more unsolved problems. So, if someone is interested in machine learning and working with real practical tasks, - welcome.
Conclusion
Recently, in the field of text analysis, much attention has been paid to the introduction of methods based on artificial neural networks. The overwhelming success, as in the field of image analysis, was not achieved, primarily because of the low interpretability of the models, which is much more important for texts. But still there is success. Consider a few popular approaches.
"Vectors of meanings" . In the 2013 Google researchers, it was suggested using a two-layer neural network to predict words by context (the reverse version later appeared: prediction of the context by word). At the same time, the main result was not the forecast itself, but the vector representations obtained for words. According to the authors, they contained information about the meaning of the word. In vector representations it was possible to find interesting examples of “algebraic operations” on words. For example, “the king is a man + woman ≈ the queen”. In addition, vectorized words became a convenient form of transferring text data to other machine learning algorithms, which in many ways ensured the popularity of the word2vec model.
One of the important limitations of the approach with the vectors of the meanings of words is that the meaning was determined for the word, but not the document. For short texts, an adequate “aggregated” meaning could often be obtained by averaging the vectors of the words in the text, but for long texts this approach was already ineffective. Various modifications (sentence2vec, paragraph2vec, doc2vec) were proposed to bypass the restriction, but they did not spread as the base model.
Recurrent neural networks . Many "classic" methods of working with texts are based on the approach of the bag of words. It leads to loss of information about the order of words in the sentence. In many tasks this is not so critical (for example, in semantic analysis), but in some, on the contrary, it significantly impairs the result (for example, in the analysis of emotional coloring and machine translation). Approaches based on recurrent neural networks (RNS) allow us to circumvent this limitation. The RNS can take into account the word order, considering information about both the current word and the output of the same network from the previous word (and sometimes in the opposite direction from the next one).
One of the most successful RNS-architectures was the architecture based on LSTM (Long Short Term Memory) blocks. Such blocks are able to memorize a unit of information for a “long” time, and then, upon receipt of a new signal, issue an answer with regard to the stored information. The approach was gradually modified, and in 2014, the GRU model ( Gated Recurrent Units ) was proposed, which, with a smaller number of parameters, allows in many cases to achieve the same (and sometimes more) quality of work.
Considering the text as a sequence of words, each of which is represented by a vector (as a rule, a word2vec vector), turned out to be a very successful solution for the problems of classifying short texts, machine translation (sequence-to-sequence approach), and developing chat bots. However, on long texts often there is not enough memory of recurrent blocks, and the “output” of a neural network is often caused primarily by the ending of the text.
Generator networks. As in the case of images, neural networks are used to generate new texts. While the results of such networks - for the most part, "fan", but they are developing every year. Progress in this area can be tracked, for example, by looking at the Yandex.Autopoet system (2013 development), listening to the album Neuron Defense (2016) or Neurona (2017).
Networks based on N-grams and symbols . Building a neural network input based on words is associated with a number of difficulties - there can be many words, they sometimes contain errors and typos. Vector representations of words in the end are noisy. In this regard, recently approaches with symbols and / or N-grams (sequences of several, as a rule, three characters) are gaining increasing popularity.
For example, character-based recurrent networks ( Char-RNN ) quite successfully cope with the generation of both words (for example, names) and sentences. In this case, with a sufficiently large amount of data, it is possible to ensure that the network not only “learns” words and parts of speech, but also “remembers” the basic rules of declension and conjugation.
For short texts, good results in many tasks can be achieved using the “bag of trigrams” approach. In this case, the document is associated with a sparse vector of dimension 20–40 thousand (each possible trigram has its own position), which is further multi-layer processed by a dense network, as a rule, with a gradual decrease in dimension. In this view, the system can provide resistance to many types of errors and typos and successfully solve the problems of classification and matching (for example, in question-answer systems).
Networks at the level of work with signals . It should be noted the exceptional role of neural networks when parsing the raw signal. Speech in modern systems, as a rule, is recognized using recurrent networks . In the analysis of handwriting, convolutional networks are successfully used to recognize individual characters, and recurrent networks are used to segment characters in the stream.
Questions and answers
Question : Is there a Ldig tool for the Russian language?
Answer : In my opinion, there is no Russian. This is a Python package, there is a very limited selection. It was developed at Cybozu Labs. The authors switched to thematic models and said: "Everything, we are no longer interested in languages." Therefore, Ldig now nobody develops. We are trying to take some steps ourselves, but everything depends on the preparation of well-marked buildings. Maybe if we have results, we will post them. But while the infinigrams and Ldig, there are very few languages. Unlike LangDetect, in which 90 languages.
Q : Is there an open source tool for PLSA?
Answer : If the building is relatively small, there is the BigARTM library, it is being made in Moscow under the guidance of just the founding father of the robust LDA direction Konstantin Vorontsov. It can be downloaded, it is open, on the axes, fast, parallel.
There are several implementations built on distributed systems, like Mr. Lda. There in different packages have their own implementation. Spark has Vowpal Wabbit. Something, in my opinion, was even in Mahout. If you want to do something on the body, which fits into the memory on one machine, you can take BigARTM or Python modules. In Python, too, there is LDA, as far as I know.
Question : Another question about PLSA. Are there any guarantees of convergence for the ML-algorithm?
Answer : There is a mathematical analysis of convergence, and there are guarantees for it. In practice, we have never seen that it does not converge. Rather, it does not exactly converge; it can oscillate around a distribution that more or less describes what we see. That is, the documents are able to start oscillating, but the dictionary is fixed. We usually stop iterating after perplexing stops decreasing.
Question : How is the occurrence of topics in a document determined?
Answer : Based on an iterative process. We have counters of the likelihood that a particular word in a particular document is introduced by this topic. Based on this, we update the power of the topic in the document, recount everything anew, we get new values of the word counter of the document on the topic, and so it is with one another, with one another, with one another. And in the end we get the distribution.
Question : Are deep learning models used to study information from the text?
Answer : Apply. But there is such a moment. Very often for deep learning take this well-known thing word2vec, doc2vec, sentence2vec. If you take a strictly formal approach, this is actually not deep learning, but now there are really true deep networks that they are trying to use. I have mixed experience with such networks. There is a lot of noise from them, and when you try to solve a real, practical problem, it turns out that the game is not worth the trouble. But that's my personal opinion. People try.
Q : Is there a well-proven open source library for defining document and emotional coloring topics?
Answer : I advise BigARTM and Vorontsov about him. And those who are in Moscow, probably, can go to the seminars for him too. This is with regard to semantics. With emotions harder. In particular, there is SentiStrength, they can give source codes for an academic license. But, as a rule, in such tasks the main value is not a code, but a marked body. On it you can experiment, train. And if there is no case, then the code is useless. Then you need to either take an already trained, ready-made model (there are such), or make a body.
Question : What books on NLP would you recommend?
Answer : It makes sense to read articles by Vorontsov about thematic models. They give a very good review. About NLP in general, there is a Natural Language Processing Handbook. It is quite clear there, but almost all topics are covered.
Question : What are some interesting products or companies in the field of NLP?
Answer : I did not investigate the question, but for sure there are such. Those who use technology in their work? This is primarily search engines (Google, for example) and companies with large text boxes. I think Facebook probably applies to them.
Question : Is it possible to create competitive programs in small teams?
Answer : Really. There are many open questions left. Even if you look at the solutions that now exist, especially in new areas, they are often not technological. This is done by research laboratories, students. The solutions are full of crutches and tritely ineffective. If you just take a good engineer and plan to optimize the finished academic product, you can get an awesome thing. But academic expertise and good engineering skills rarely coexist.
Question : How does language limit thought?
Answer : Where he does not express it. If a language cannot express a thought, then it usually expands. The language is alive. Why did I call the unsolved problem the evolution of thematic models over time? We often observe how words appear for new social phenomena. Language is a communication tool. If he stops solving the task of communication, he improves.
Source: https://habr.com/ru/post/358736/
All Articles