Automatic generation of test scripts using neural networks

In recent years, the use of Deep Learning technologies has allowed significant progress in such areas as pattern recognition, automatic translation, etc. This success, as well as developments in the field of unmanned vehicles and computer achievements in the GO game, allowed us to dream that Artificial Intelligence would soon will do the work that people are doing now, and will claim their jobs .
The widespread replacement of people for robots is a fascinating process, but not a quick one. However, now you can use the increased computing power of computers in order to facilitate the solution of problems that people face every day. For example, the process of writing programs. The use of systems that facilitate the programming process is not exceptional, any development environment provides many such tools.
This article presents a technology that helps a programmer write a test based on a Java module. The technology allows you to significantly save time compared to writing a test manually.
')
Tests
In the process of creating a program module, we always want to be sure that the programmed functionality meets our requirements. In order to know that the real behavior of the program created by us corresponds to the expected result, tests are used.
Necessity, all the pros and cons of writing tests are listed here . However, there is no doubt that writing tests takes considerable time (research shows that developers spend up to 30% of the time to create tests ). In addition, this activity does not develop the functionality of the main software module, so it is logical that many teams try to avoid writing tests. On the other hand, the support of the old functionality and the programming of the new one are greatly complicated without the use of tests.
In addition to monitoring the correctness of the program, tests can also explain the functionality of the program being executed in “natural language”. That is, test scripts can be accompanied by documentation text that explains the behavior of the test and the program under test in the BDD paradigm.
In this article we discuss the technology of automatic test generation. In the synthesis of tests, we will use Gherkin-notation .
Sample test in Russian using Gherkin:
# language: ru @all : PIN- , PIN- , PIN- : PIN- @correct : PIN- @fail : PIN- , PIN- BDD, TDD
TDD and BDD techniques imply that the test is written prior to the development of the module being tested ( https://ru.wikipedia.org/wiki/Development_through_testing ),
Test -> Module
Without discussing the pros and cons of the TDD and BDD approach, I must say that in life there are very often situations (and, perhaps, most of these cases), when tests are written after the module is ready, or tests are not written at all. This leads to the fact that the code becomes unreadable and difficult to maintain, leading, in particular, to the phenomenon of legacy code.
Thus, we offer the opportunity to synthesize the test and code description in the BDD format on the basis of the finished code - if there were no tests at all or were going to write tests after creating a program module.
Module -> Test
Synthesis
The process of creating tests begins with the analysis of the finished software module. We are currently working with classes written in Java. The general scheme of work is this - at first we collect logs and information about the execution of the program module, then, on the basis of these logs, we train the neural network, then we use the neural network to generate ready-made test scripts.
Collecting logs
Suppose we have a module that serves a client bank account.
We collect logs at each step of the program, starting with information about input and output, and ending with changes to variables

The collection itself is as follows:
We take inputs - these can be data from access logs, or options provided by the programmer, or automatically generated data using various genetic or random mechanisms ( Evosuite , Randoop ).
In special cases, we can leave the log collection module in production, but in general it is not recommended.
Neural network training
Neural network learning occurs in the Neural Programmer-Interpreters paradigm.
NPI works like this: based on the input data (in the picture, “previous NPI state”, “environment observation”, “input program”), the command (“output program”) predicts.

Being able to recognize the environment for predicting simple programs (addition, matching), the program can predict Gherkin notation for this data. The quality of the use of NPI depends both on the ability to process certain input data and on the development of the neural network architecture.
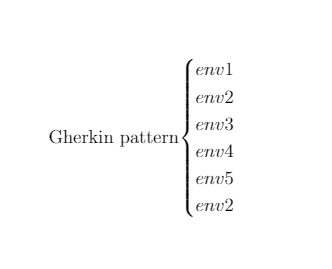
Thus, the trained neural network solves the problem traditional for software synthesis - how to find the right program (Gherkin notation, test case) for the current input data (env1 ').
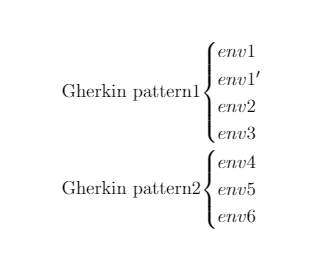
Script generation.
Test cases are generated on the basis of a trained neural network. In the simplest case, there are lists of data that have been validated and lists of data that have not passed validation.

Finished scripts can be edited to meet the final requirements. Gherkin tests are written in “natural language”, which implies the ability to read and edit these tests by the whole team, both by those who wrote the code and those who were not involved in the development of the module.
At each execution, the tests will check the conditions that are encoded in them. In the event that the functionality of the tested software module has changed, the neural network can be re-trained to generate new tests.
Tests in the Gherkin language are performed on the Cucumber test framework.
The framework supports the automatic execution of scripts when building with Maven.
<dependency> <groupId>info.cukes</groupId> <artifactId>cucumber-java</artifactId> <version>1.2.4</version> <scope>test</scope> </dependency> <dependency> <groupId>info.cukes</groupId> <artifactId>cucumber-junit</artifactId> <version>1.2.4</version> </dependency> Cucumber also integrates with other continuous integration tools such as Jenkins and more.
Test script generation, restrictions
The automatic generator has several limitations at once. All of them are due to the fact that the program does not “learn” to program or “understand” algorithms. The goal of the program is to be able to compare the types of input data it understands with the output data, and select labels, which is a simple case of conditional program generation :
Simple cases
Without intuition or a deep understanding of the logic of the program, the system can only detect simple cases of program failures (for example, parameters that lead to error messages), while at the same time there are cases that can only be detected by the programmer.
Limited set of logged parameters
It is easy to log and analyze the primitive types (lines, numbers) by the neural network, it is more difficult to log and analyze objects.
Identify simple relationships
Accordingly, it is easy to identify simple relationships in simple data. All of the above implies that, at the moment, the validation and refinement of automatic tests is done manually.
Perspectives
The main direction of the development of the system is an increase in the number and complexity of patterns recognized.
In case of interest, I will be glad to discuss in more detail - email to nayname@gmail.com
Source: https://habr.com/ru/post/358564/
All Articles