How to plan the capacity of the Apache Ignite cluster
We publish the transcript of the video recording of the speech by Alexei Goncharuk (Apache Ignite PMC Member and Chief Architect of GridGain) at the Apache Ignite community meeting in St. Petersburg on March 29. You can download slides by reference .
Apache Ignite community members are often asked: “How many nodes and memory do you need in order to load such and such amount of data?” I want to talk about this today. Looking ahead: such forecasting is still quite a complex, non-trivial task. To do this, you need to understand a little about the Apache Ignite device. I will also tell you how to simplify the forecasting task and what optimization can be applied.
So, very often users come to us and say: “We have data presented in the form of files. How much memory does it take to translate this data into Apache Ignite? ”
With this formulation, it is almost impossible to answer the question, because different file formats are translated into completely different models. For example, a file can be compressed. And if it is not compressed into a classical binary form, but data can be deduplicated, then the file is implicitly compressed.
')
Also do not forget that Apache Ignite provides quick access to data using different keys or SQL indexes, so in addition to the data that lies in the file, we build additional indexes, which are associated with additional costs. So, in general, it is wrong to say that a single index will add some percentage of the total data, since the field being indexed may have a different size. That is, it is wrong to allocate a fixed percentage of memory per index.
Let's reformulate the problem. We say that our model consists of several types, and we well understand the structure of each type. Moreover, if the model has fields of variable size, say, string, then we can roughly estimate the minimum and maximum data size, as well as the size distribution in the entire data set. Based on how many data types we have and how much information is available for each type, we will plan the amount of memory and disks.
The empirical approach may be a little inaccurate, but, from the user's point of view, does not require some kind of deep immersion in the structure of the system. The essence of the approach is as follows.
Take a representative sample of the data and load it into Apache Ignite. While loading, watch the storage grow. On certain volumes, you can make "cutoffs" in order to linearly extrapolate and predict the required storage capacity for the entire data set.
A good question is usually asked here: “What should be a representative sample?”
Once we generated a sample randomly. But it turned out that the generator collected the data in such a way that the set of residues from the division during generation was included. At some point, it turned out that our random strings, which should have had a uniform distribution, in fact did not have this distribution. Therefore, when you estimate the storage capacity, make sure that in the representative sample the distributions with which you operate are really performed.
Also note the variation in the size of your objects. If you assume that they will be of the same length, then, in general, a small number of objects is sufficient for a representative sample. The greater the variability, the more combinations of field sizes, the larger the sample will need to load to understand the dependency. From my own experience I’ll say that the dependency starts to clear up with about a million objects that are loaded into one partition per node.
What exactly needs to be monitored during the loading of a representative sample? If you are working with persistence, you can look at the volume of files that you get. Or you can simply turn on the metrics of the region, the metrics in the Apache Ignite configuration, and through MX Bean monitor the increase in memory, making “cutoffs” and plotting the graph.
In this case, we will go through all the stages of changing the data structure that your object undergoes when it is saved in Apache Ignite, and also look at the surrounding data structures that can increase memory consumption. When we understand what changes occur and what data structures change, we can accurately estimate the amount of memory needed to load the data.
Let's analyze the cash put operation when writing to Apache Ignite. Data goes through 4 stages of conversion:
The first stage is optional, because some users work with the class and pass a Java object to Apache Ignite. Some users create a binary object directly, so the first stage of the object conversion is skipped. But if you work with Java objects, then this is the first transformation that an object undergoes.
After converting a Java object into a binary object, we get a class-independent format. Its essence is that you can operate with binary objects in a cluster, without having a description of classes. This allows you to change the class structure and perform the so-called rolling object structure changes. That is, your model grows, changes, and you get the opportunity to work with your data without changing classes, without expanding them in a cluster.
The third stage of change, which introduces additional overhead - writing to disk. The unit of work with the disk is traditionally the page. And starting with Apache Ignite 2.0, we switched to page architecture. This means that each page has optional headers, some metadata, which also take up space when writing objects to the page.
And the last piece, which also needs to be considered - the update index. Even if you do not use SQL, in Apache Ignite you have quick access by key. This is the main Apache Ignite cache API. Therefore, the primary key index is always built, and space is also spent on it.
This is our binary object:
We will not go deep into the structure, in general, it can be represented as a kind of title, then the fields, our essential data and the footer. The header of the binary object is 24 bytes. Perhaps this is a lot, but so much is needed to support the mutability of objects without classes.
If the data model that you put in the cache implies some kind of spreading internal structure, then it might be worth seeing if you can inject some small objects into your original large object? In principle, such inlining will save you 24 bytes per object, which gives a significant increase with a sufficiently large spreading pattern.
The size of the footer depends on the compactFooter flag, which allows you to write the structure of the object in additional metadata. That is, instead of writing the order of the fields in the object itself, we save them separately. And if compactFooter is true, then the footer will be very small. But at the same time, Apache Ignite takes additional steps to preserve and maintain this metadata. If compactFooter is false, then the object is self-sufficient and its structure can be read without additional metadata.
Currently, there is no method in our public API that returns the size of a binary object. Therefore, if you find this very interesting, you can make a hack and bring the object to implementation, then you will see its size. I think in Apache Ignite 2.5 we will add a method that will allow us to get the size of the object.
As I said, the unit of work with the disk is the page. This is done to optimize reading and writing to disk. But at the same time it imposes restrictions on the internal architecture of Apache Ignite, since any data structures that will be saved to disk should also work with pages.
In other words, any data structure is built up from building blocks, whether it is a tree or a freelist. Pages link to each other by a unique identifier. Using the same unique identifier, we can determine in a constant time a file from which these pages can be read, from which offset one or another page will be read from this file.
A single section, which is divided into many pages, can be represented as such a scheme:
Starting metastranitsy allows you to reach any other page. They are divided into different types, which are quite a lot, but to simplify the example I’ll say that we have:
Why this is needed, we will talk a little below.
Let's start with the data page . This block accepts our key and value when we write data to Apache Ignite. First, a data page is taken that can hold our information, and data is recorded in it. When a link to them is received, information is recorded in the index.
The data page has a tabular organization. At the beginning there is a table that contains the offset to the key-value pairs. The key-value pairs themselves are written in reverse order. The very first entry is located at the end of the page. This is done to make it easier to work with free space. You ask why it was so difficult? Why it is impossible to write data directly to the page and refer to the offset inside the page? This is done to defragment the page.

If you delete entry number 2 here, two free zones are formed. It is possible that record number 3 will need to be moved to the right in the future in order to accommodate a larger record here. And if we have indirect addressing, then you simply change the offset of the corresponding entry in the table. However, the external link that links to this page remains constant.
A string can be fragmented in the sense that its size will be larger than the page size. In this case, we take a blank page and write the tail of the line into it, and the remainder into the data page.
In addition to the key and value, auxiliary information is also recorded in the data page for correct system operation, for example, the version number. If you use expire policy, expiry time is also written there. In general, additional metadata takes up 35 bytes. After you know the size of the binary object and key, you add 35 bytes and get the amount of a specific record in the data page. And then calculate how many entries fit in the page.
It may be that in the data page there will be free space in which none of the entries fit. Then in the metrics you will see the fill factor, which is not equal to 1.
And a few words about the recording procedure . Suppose you had a blank page and you wrote down some data in it. A lot of space left. It would be wrong to just throw out the page so that it was somewhere lying around and no longer used.
Information about which pages have free space, which it makes sense to take into account, is stored in the “free list” data structure (freelist). If in this implementation and at the moment the page contains less than 8 bytes, it does not fall into the freelist, because there will not be such a key-value pair that would fit in 8 bytes.
After we figured out the data pages and estimated their number, we can estimate the number of index pages we need.
Any Apache Ignite index is a B-tree. This means that at the lower - the widest - level there are links to absolutely all key-value pairs. The index starts with the root page. On each of the internal pages there are links to the lower level.
The index, which is the primary key, has an element size written to the index page of 12 bytes. Depending on which page you are looking at, internal or sheet, you will have a different number of maximum elements. If you take for such a numerical estimate, then you can see the number of maximum elements in the code. For a primary index, the link size is always fixed and equal to 12 bytes. To roughly calculate the maximum number of page elements, you can divide the page size (by default, 4 megabytes) into 12 bytes.
Taking into account the growth of the tree, we can assume that each page will be filled from 50% to 75%, depending on the order of loading data. Given that the bottom level of the tree contains all the elements, you can also estimate the number of pages needed to store the index.
As for the SQL indexes - or secondary ones - here the size of the element stored in the page depends on the inline size configured. You need to carefully analyze the data model to calculate the number of index pages.
Many questions cause additional memory consumption per unit partition. To start an empty cache, in which literally one element is written in each of the partitions, a substantial amount of memory is required. The fact is that with such a structure, all the necessary metadata should be initialized for each partition.
<illustration>
The number of partitions defaults to 1024, so if you launch one node and start writing one element to each partition, then you immediately initialize a very large number of metastranits, which results in such a large initial memory overhead.
With an empirical approach, you will load a sufficiently large amount of data, and the memory consumption of the partition becomes less noticeable. But it should be considered for a more accurate assessment. If you add up the memory overhead for a partition, on all data pages and index pages, you can calculate the required amount of memory with sufficient accuracy.
How can you make life easier in the future? Apache Ignite is moving toward SQL systems, and there are many ideas for reducing overhead.
You can change the binary format to reduce the size of the header. If you move to a more strictly typed data structure in any of the caches, but you will not be able to mix objects, but the amount of memory consumed will decrease.
The second solution is to group objects of the same type in the pages and select the title or its part. In this case, Apache Ignite will independently deduplicate data already at the page level.
Another sensible idea: implement a custom data capture threshold in freelist . If you understand that the pages will be fragmented in such a way that 100 bytes will remain in them, and your data will never be less than 100 bytes, then it makes sense to tweak the freelist so that the pages do not get there and do not consume space in this freelist.
Actively discussed and performed by the system data compression at the page level , transparent to the user. There are some technical difficulties, but in general you will sacrifice performance in favor of a more compact data placement.
And the last, very demanded optimization - the cluster capacity calculator . The big question is what will be the entrance to such a utility. The following scheme appears: the user loads into the calculator the structure of objects, indicates how many lines he plans to load, and the calculator tells how much memory is needed taking into account all the indices and the Apache Ignite internal overhead.
How much memory do we need to allocate, provided that the amount of stored data is larger than the amount of available memory? If you run out of memory, Apache Ignite does the same thing as the OS: it throws out some data from the memory and loads the necessary ones. Some data can not be thrown out, but for most cases it does not matter.
Here it must be remembered that the appearance of the page itself does not imply recording. Dropping data from memory is cheap. And the subsequent reading of the data for which there was a miss from the disk is an expensive operation. In most cases, the most important characteristic to pay attention to is how much IOPS your disk can produce. If you are working with cloud deployment, then IOPS count is very easy.
For example, starting and mounting an image in Amazon, you can choose among discs those that have a write speed in MB / sec. But, in our experience, it's much better to know IOPS. Since we operate with pages, then, in fact, IOPS is the maximum number of read or write operations that we can perform on disk per unit of time.
How is the page chosen to be erased from memory? Now this is done using the LRU random algorithm. Apache Ignite keeps in memory a page that stores a display of that same page identifier at a specific physical address in memory where the data resides. When we need to throw out some of the pages, we take n random pages from this table and select the oldest one. It will not always be the oldest in the absolute sense. But more often we will fall into one n-th part, where n is the number of samples we choose.
Today, the LRU random algorithm is not resistant to full scanning, but we already have an implementation of the LRU 2 random algorithm, which is used in Apache Ignite for another task. And when we use random LRU 2 to wipe out pages, the problem of resilience to full scanning will be solved.
The preemption of pages significantly affects the delay in a single operation in the cache. Worst situation: you had some little-used SQL index or region in the cache, and it turned out that absolutely all the pages in this region were pushed out to disk, that is, kicked out of memory. If you refer to some key that will access all n pages, they will be sequentially read from disk. And we need to minimize the amount of possible reading from the disk.
Starting with Apache Ignite 2.3, it became possible to split caches into different data regions. If you know that you have a subset of hot data, and you will surely work with them, and there is also a subset of data that is historical, then it makes sense to divide these subsets into different data regions.
Also, to determine the disk / memory ratio, one should always watch not the median or average access time for a single operation in the cache, but the percentiles, because they are the most complete way to present information.
In the worst case scenario, in one percent of cases the delay will be significantly higher, because pages have to be read from disk. If you just look at the average, you will never notice this feature. If strict SLAs are important to you, then you just need to analyze the percentiles when determining the proportion.
Last thing to mention: do not run many Apache Ignite nodes with persistence enabled on the same physical media. Since the disk is physically one, the number of IOPS is divided between Apache Ignite nodes. Not only do you divide the bandwidth between nodes, in addition to this, each of the nodes can exhaust the capacity by IOPS, and the behavior of the entire cluster will become unpredictable.
If for some reason you want to run several Apache Ignite nodes on the same machine, then be sure to ensure that the physical storages for the nodes are different. This is in addition to recommending that Write-Ahead Log be carried to a separate physical medium.
You should not use a network with a bandwidth of less than 1 gigabit. Today, few people have networks with less bandwidth. The choice of CPU is very dependent on the load profile, on the number of indices. Here it is worth going back to the empirical approach and simply generate the load profile expected for your application and carefully monitor all system indicators. If you see that some of the resources are completely exhausted, then it makes sense to add it.
We welcome any questions or ideas for improving Apache Ignite.
Join our meetings in Moscow and St. Petersburg .
Apache Ignite community members are often asked: “How many nodes and memory do you need in order to load such and such amount of data?” I want to talk about this today. Looking ahead: such forecasting is still quite a complex, non-trivial task. To do this, you need to understand a little about the Apache Ignite device. I will also tell you how to simplify the forecasting task and what optimization can be applied.
So, very often users come to us and say: “We have data presented in the form of files. How much memory does it take to translate this data into Apache Ignite? ”
With this formulation, it is almost impossible to answer the question, because different file formats are translated into completely different models. For example, a file can be compressed. And if it is not compressed into a classical binary form, but data can be deduplicated, then the file is implicitly compressed.
')
Also do not forget that Apache Ignite provides quick access to data using different keys or SQL indexes, so in addition to the data that lies in the file, we build additional indexes, which are associated with additional costs. So, in general, it is wrong to say that a single index will add some percentage of the total data, since the field being indexed may have a different size. That is, it is wrong to allocate a fixed percentage of memory per index.
Let's reformulate the problem. We say that our model consists of several types, and we well understand the structure of each type. Moreover, if the model has fields of variable size, say, string, then we can roughly estimate the minimum and maximum data size, as well as the size distribution in the entire data set. Based on how many data types we have and how much information is available for each type, we will plan the amount of memory and disks.
Empirical approach
The empirical approach may be a little inaccurate, but, from the user's point of view, does not require some kind of deep immersion in the structure of the system. The essence of the approach is as follows.
Take a representative sample of the data and load it into Apache Ignite. While loading, watch the storage grow. On certain volumes, you can make "cutoffs" in order to linearly extrapolate and predict the required storage capacity for the entire data set.
A good question is usually asked here: “What should be a representative sample?”
Once we generated a sample randomly. But it turned out that the generator collected the data in such a way that the set of residues from the division during generation was included. At some point, it turned out that our random strings, which should have had a uniform distribution, in fact did not have this distribution. Therefore, when you estimate the storage capacity, make sure that in the representative sample the distributions with which you operate are really performed.
Also note the variation in the size of your objects. If you assume that they will be of the same length, then, in general, a small number of objects is sufficient for a representative sample. The greater the variability, the more combinations of field sizes, the larger the sample will need to load to understand the dependency. From my own experience I’ll say that the dependency starts to clear up with about a million objects that are loaded into one partition per node.
What exactly needs to be monitored during the loading of a representative sample? If you are working with persistence, you can look at the volume of files that you get. Or you can simply turn on the metrics of the region, the metrics in the Apache Ignite configuration, and through MX Bean monitor the increase in memory, making “cutoffs” and plotting the graph.
Numerical evaluation
In this case, we will go through all the stages of changing the data structure that your object undergoes when it is saved in Apache Ignite, and also look at the surrounding data structures that can increase memory consumption. When we understand what changes occur and what data structures change, we can accurately estimate the amount of memory needed to load the data.
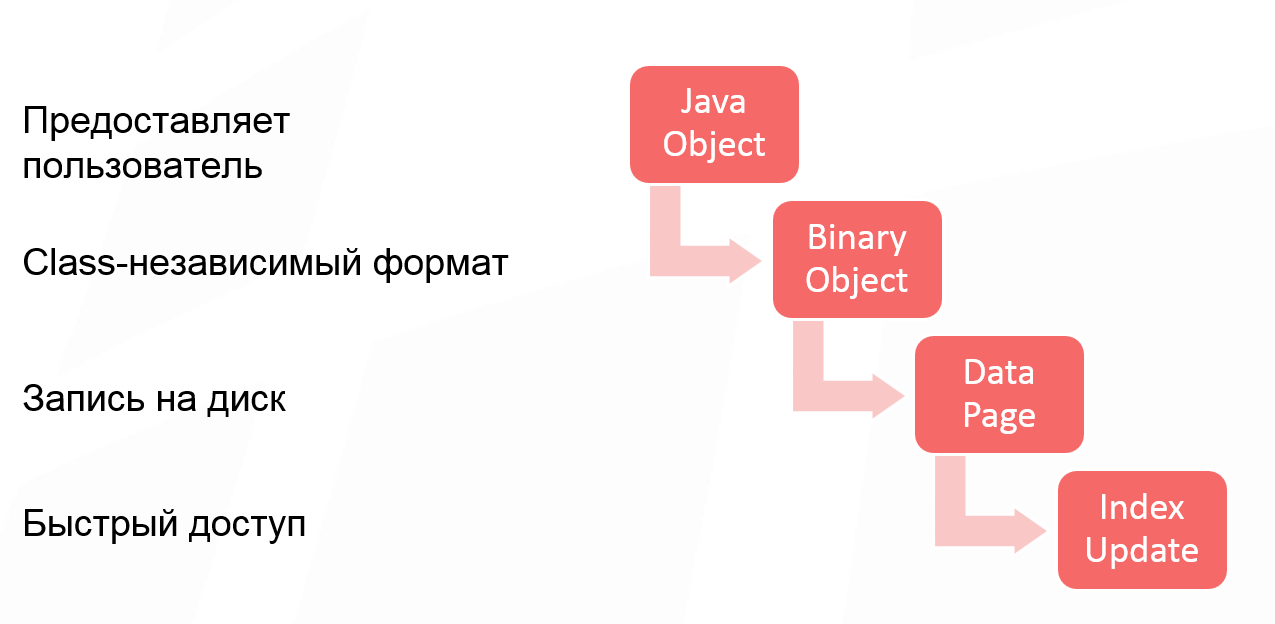
Let's analyze the cash put operation when writing to Apache Ignite. Data goes through 4 stages of conversion:
The first stage is optional, because some users work with the class and pass a Java object to Apache Ignite. Some users create a binary object directly, so the first stage of the object conversion is skipped. But if you work with Java objects, then this is the first transformation that an object undergoes.
After converting a Java object into a binary object, we get a class-independent format. Its essence is that you can operate with binary objects in a cluster, without having a description of classes. This allows you to change the class structure and perform the so-called rolling object structure changes. That is, your model grows, changes, and you get the opportunity to work with your data without changing classes, without expanding them in a cluster.
The third stage of change, which introduces additional overhead - writing to disk. The unit of work with the disk is traditionally the page. And starting with Apache Ignite 2.0, we switched to page architecture. This means that each page has optional headers, some metadata, which also take up space when writing objects to the page.
And the last piece, which also needs to be considered - the update index. Even if you do not use SQL, in Apache Ignite you have quick access by key. This is the main Apache Ignite cache API. Therefore, the primary key index is always built, and space is also spent on it.
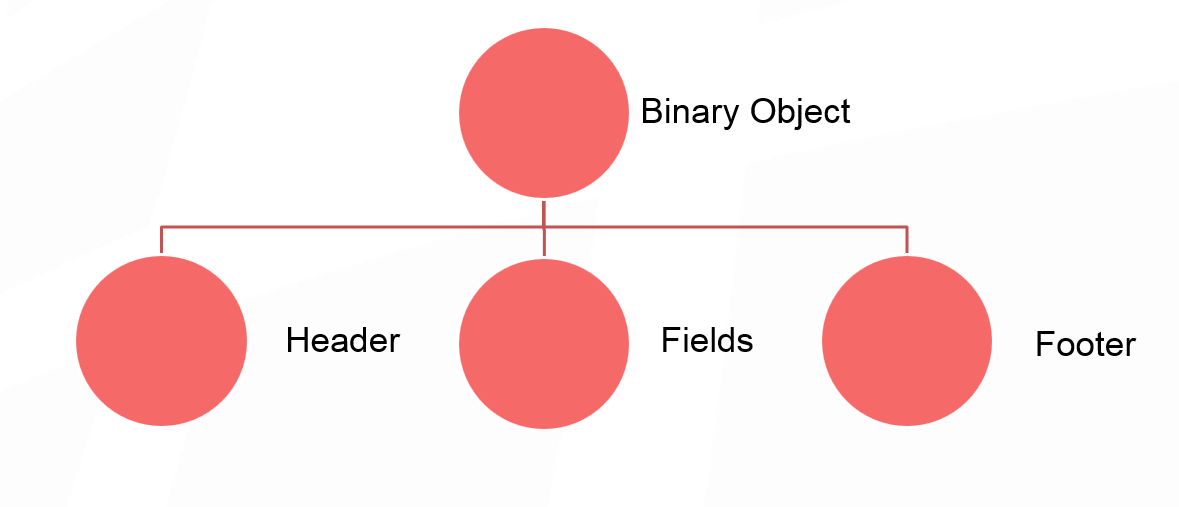
This is our binary object:
We will not go deep into the structure, in general, it can be represented as a kind of title, then the fields, our essential data and the footer. The header of the binary object is 24 bytes. Perhaps this is a lot, but so much is needed to support the mutability of objects without classes.
If the data model that you put in the cache implies some kind of spreading internal structure, then it might be worth seeing if you can inject some small objects into your original large object? In principle, such inlining will save you 24 bytes per object, which gives a significant increase with a sufficiently large spreading pattern.
The size of the footer depends on the compactFooter flag, which allows you to write the structure of the object in additional metadata. That is, instead of writing the order of the fields in the object itself, we save them separately. And if compactFooter is true, then the footer will be very small. But at the same time, Apache Ignite takes additional steps to preserve and maintain this metadata. If compactFooter is false, then the object is self-sufficient and its structure can be read without additional metadata.
Currently, there is no method in our public API that returns the size of a binary object. Therefore, if you find this very interesting, you can make a hack and bring the object to implementation, then you will see its size. I think in Apache Ignite 2.5 we will add a method that will allow us to get the size of the object.
Page architecture
As I said, the unit of work with the disk is the page. This is done to optimize reading and writing to disk. But at the same time it imposes restrictions on the internal architecture of Apache Ignite, since any data structures that will be saved to disk should also work with pages.
In other words, any data structure is built up from building blocks, whether it is a tree or a freelist. Pages link to each other by a unique identifier. Using the same unique identifier, we can determine in a constant time a file from which these pages can be read, from which offset one or another page will be read from this file.
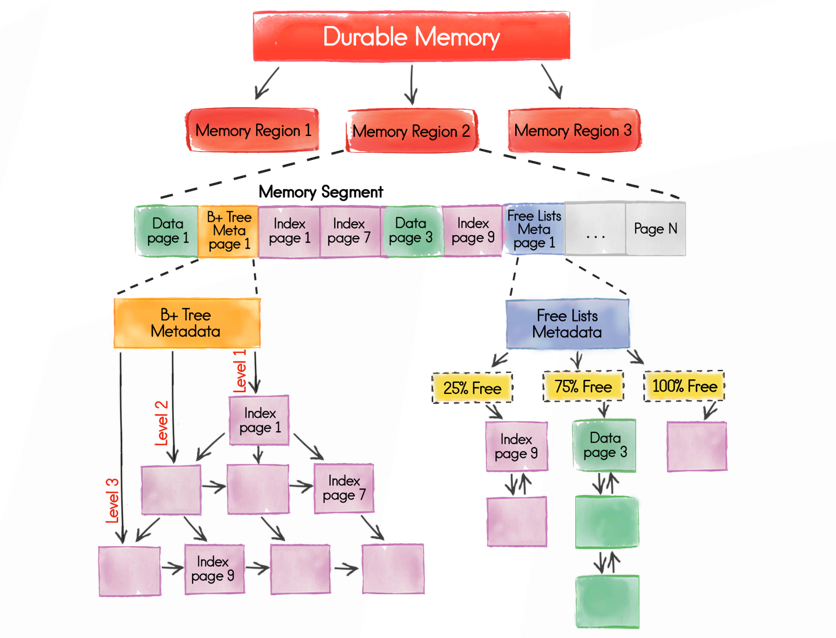
A single section, which is divided into many pages, can be represented as such a scheme:
Starting metastranitsy allows you to reach any other page. They are divided into different types, which are quite a lot, but to simplify the example I’ll say that we have:
- data pages that store data;
- index pages that allow you to build an index tree;
- helper pages for structures such as freelist or metadata.
Why this is needed, we will talk a little below.
Let's start with the data page . This block accepts our key and value when we write data to Apache Ignite. First, a data page is taken that can hold our information, and data is recorded in it. When a link to them is received, information is recorded in the index.
The data page has a tabular organization. At the beginning there is a table that contains the offset to the key-value pairs. The key-value pairs themselves are written in reverse order. The very first entry is located at the end of the page. This is done to make it easier to work with free space. You ask why it was so difficult? Why it is impossible to write data directly to the page and refer to the offset inside the page? This is done to defragment the page.
If you delete entry number 2 here, two free zones are formed. It is possible that record number 3 will need to be moved to the right in the future in order to accommodate a larger record here. And if we have indirect addressing, then you simply change the offset of the corresponding entry in the table. However, the external link that links to this page remains constant.
A string can be fragmented in the sense that its size will be larger than the page size. In this case, we take a blank page and write the tail of the line into it, and the remainder into the data page.
In addition to the key and value, auxiliary information is also recorded in the data page for correct system operation, for example, the version number. If you use expire policy, expiry time is also written there. In general, additional metadata takes up 35 bytes. After you know the size of the binary object and key, you add 35 bytes and get the amount of a specific record in the data page. And then calculate how many entries fit in the page.
It may be that in the data page there will be free space in which none of the entries fit. Then in the metrics you will see the fill factor, which is not equal to 1.
And a few words about the recording procedure . Suppose you had a blank page and you wrote down some data in it. A lot of space left. It would be wrong to just throw out the page so that it was somewhere lying around and no longer used.
Information about which pages have free space, which it makes sense to take into account, is stored in the “free list” data structure (freelist). If in this implementation and at the moment the page contains less than 8 bytes, it does not fall into the freelist, because there will not be such a key-value pair that would fit in 8 bytes.
After we figured out the data pages and estimated their number, we can estimate the number of index pages we need.
Any Apache Ignite index is a B-tree. This means that at the lower - the widest - level there are links to absolutely all key-value pairs. The index starts with the root page. On each of the internal pages there are links to the lower level.
The index, which is the primary key, has an element size written to the index page of 12 bytes. Depending on which page you are looking at, internal or sheet, you will have a different number of maximum elements. If you take for such a numerical estimate, then you can see the number of maximum elements in the code. For a primary index, the link size is always fixed and equal to 12 bytes. To roughly calculate the maximum number of page elements, you can divide the page size (by default, 4 megabytes) into 12 bytes.
Taking into account the growth of the tree, we can assume that each page will be filled from 50% to 75%, depending on the order of loading data. Given that the bottom level of the tree contains all the elements, you can also estimate the number of pages needed to store the index.
As for the SQL indexes - or secondary ones - here the size of the element stored in the page depends on the inline size configured. You need to carefully analyze the data model to calculate the number of index pages.
Many questions cause additional memory consumption per unit partition. To start an empty cache, in which literally one element is written in each of the partitions, a substantial amount of memory is required. The fact is that with such a structure, all the necessary metadata should be initialized for each partition.
<illustration>
The number of partitions defaults to 1024, so if you launch one node and start writing one element to each partition, then you immediately initialize a very large number of metastranits, which results in such a large initial memory overhead.
With an empirical approach, you will load a sufficiently large amount of data, and the memory consumption of the partition becomes less noticeable. But it should be considered for a more accurate assessment. If you add up the memory overhead for a partition, on all data pages and index pages, you can calculate the required amount of memory with sufficient accuracy.
Optimization
How can you make life easier in the future? Apache Ignite is moving toward SQL systems, and there are many ideas for reducing overhead.
You can change the binary format to reduce the size of the header. If you move to a more strictly typed data structure in any of the caches, but you will not be able to mix objects, but the amount of memory consumed will decrease.
The second solution is to group objects of the same type in the pages and select the title or its part. In this case, Apache Ignite will independently deduplicate data already at the page level.
Another sensible idea: implement a custom data capture threshold in freelist . If you understand that the pages will be fragmented in such a way that 100 bytes will remain in them, and your data will never be less than 100 bytes, then it makes sense to tweak the freelist so that the pages do not get there and do not consume space in this freelist.
Actively discussed and performed by the system data compression at the page level , transparent to the user. There are some technical difficulties, but in general you will sacrifice performance in favor of a more compact data placement.
And the last, very demanded optimization - the cluster capacity calculator . The big question is what will be the entrance to such a utility. The following scheme appears: the user loads into the calculator the structure of objects, indicates how many lines he plans to load, and the calculator tells how much memory is needed taking into account all the indices and the Apache Ignite internal overhead.
Drive / Memory Proportions
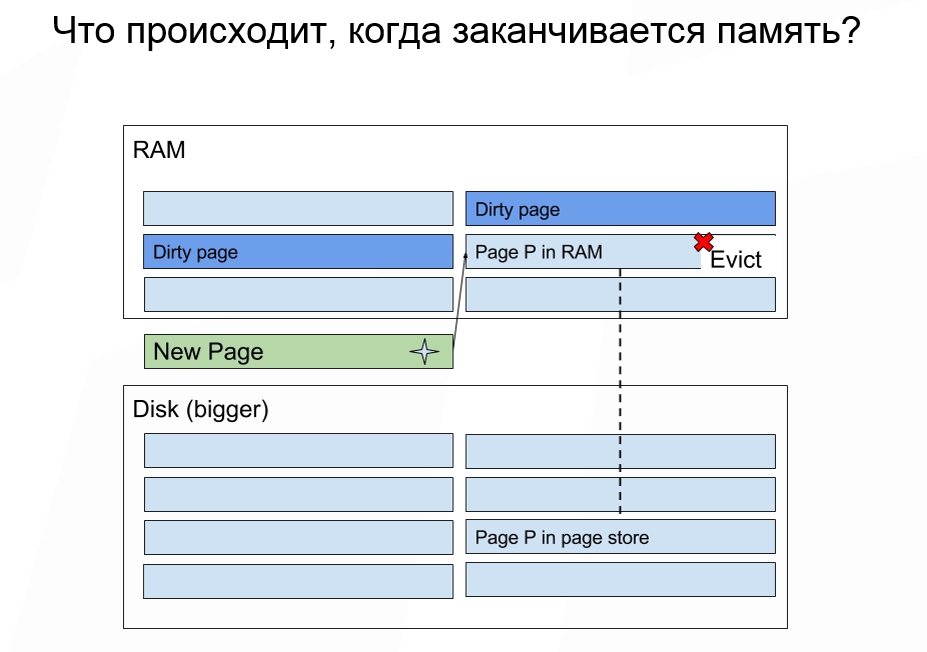
How much memory do we need to allocate, provided that the amount of stored data is larger than the amount of available memory? If you run out of memory, Apache Ignite does the same thing as the OS: it throws out some data from the memory and loads the necessary ones. Some data can not be thrown out, but for most cases it does not matter.
Here it must be remembered that the appearance of the page itself does not imply recording. Dropping data from memory is cheap. And the subsequent reading of the data for which there was a miss from the disk is an expensive operation. In most cases, the most important characteristic to pay attention to is how much IOPS your disk can produce. If you are working with cloud deployment, then IOPS count is very easy.
For example, starting and mounting an image in Amazon, you can choose among discs those that have a write speed in MB / sec. But, in our experience, it's much better to know IOPS. Since we operate with pages, then, in fact, IOPS is the maximum number of read or write operations that we can perform on disk per unit of time.
How is the page chosen to be erased from memory? Now this is done using the LRU random algorithm. Apache Ignite keeps in memory a page that stores a display of that same page identifier at a specific physical address in memory where the data resides. When we need to throw out some of the pages, we take n random pages from this table and select the oldest one. It will not always be the oldest in the absolute sense. But more often we will fall into one n-th part, where n is the number of samples we choose.
Today, the LRU random algorithm is not resistant to full scanning, but we already have an implementation of the LRU 2 random algorithm, which is used in Apache Ignite for another task. And when we use random LRU 2 to wipe out pages, the problem of resilience to full scanning will be solved.
The preemption of pages significantly affects the delay in a single operation in the cache. Worst situation: you had some little-used SQL index or region in the cache, and it turned out that absolutely all the pages in this region were pushed out to disk, that is, kicked out of memory. If you refer to some key that will access all n pages, they will be sequentially read from disk. And we need to minimize the amount of possible reading from the disk.
Starting with Apache Ignite 2.3, it became possible to split caches into different data regions. If you know that you have a subset of hot data, and you will surely work with them, and there is also a subset of data that is historical, then it makes sense to divide these subsets into different data regions.
Also, to determine the disk / memory ratio, one should always watch not the median or average access time for a single operation in the cache, but the percentiles, because they are the most complete way to present information.
In the worst case scenario, in one percent of cases the delay will be significantly higher, because pages have to be read from disk. If you just look at the average, you will never notice this feature. If strict SLAs are important to you, then you just need to analyze the percentiles when determining the proportion.
Last thing to mention: do not run many Apache Ignite nodes with persistence enabled on the same physical media. Since the disk is physically one, the number of IOPS is divided between Apache Ignite nodes. Not only do you divide the bandwidth between nodes, in addition to this, each of the nodes can exhaust the capacity by IOPS, and the behavior of the entire cluster will become unpredictable.
If for some reason you want to run several Apache Ignite nodes on the same machine, then be sure to ensure that the physical storages for the nodes are different. This is in addition to recommending that Write-Ahead Log be carried to a separate physical medium.
CPU and network bandwidth planning
You should not use a network with a bandwidth of less than 1 gigabit. Today, few people have networks with less bandwidth. The choice of CPU is very dependent on the load profile, on the number of indices. Here it is worth going back to the empirical approach and simply generate the load profile expected for your application and carefully monitor all system indicators. If you see that some of the resources are completely exhausted, then it makes sense to add it.
We welcome any questions or ideas for improving Apache Ignite.
Join our meetings in Moscow and St. Petersburg .
Other interesting videos on our channel:
Source: https://habr.com/ru/post/358546/
All Articles