noBackend, or How to survive the era of fat clients
The name of the article should not be taken literally: the backend has not gone away , just the focus of development - especially at the initial stage of development of the new project - is greatly shifted towards the “ client side ”. There is a great temptation to take something understandable for storing data and already “tied up” REST API, to abandon PHP / Python / Ruby / Java / etc as much as possible, write 80% of the code “on the client side”, minimally worrying about the fuss “on the server side ".
This article is based on the report of Nikolai Samokhvalov , who, in turn, summarized the experience of a number of projects written in React, React Native and Swift and shifting to the noBackend paradigm at the expense of PostgreSQL + PostgREST .
At the end, you will find a list of must-check-questions for working with the noBackend approach, and if your Postgres experience allows, then immediately after reading you can begin to deploy a safe, high-performance and usable for the rapid development of the REST API .
')

About the speaker: Nikolai Samokhvalov has been working with PostgreSQL for more than a decade. He is a co-organizer of the Russian community RuPostgres.org and currently helps various companies to optimize, scale and automate the processes associated with the operation of PostgreSQL. Next is the decoding of Nikolai's report on Backend Conf , designed for both the backend and the front-end developers.
The last years I spend a lot of time in Silicon Valley and want to share with you the trends that I see there. Of course, from here you can also see everything perfectly, but there they are clearer, because professional conversations about advanced technologies are conducted literally in every cafe.
Let's first define what a fat client is and what kind of era it is.

These four ducklings appeared in one year and, in fact, it is clear which of them is ugly, right? Naturally, this is javascript.

He was “on the knee” written for 10 days by an employee who, in preparation for the new Netscape browser, wrote a scripting language. Initially, it was even called differently, and then, when they screwed Java, they also decided to rename at the same time, and now for 23 years some newcomers have confused these languages . Then for many years JavaScript performed a secondary role and was in order to make some kind of animation or count some reaction in the browser.
But gradually, somewhere from 2003-2004, the hype around WEB 2.0 began, GMail, Google Maps and others appeared, and JavaScript, of course, gained more importance - customers began to get fat. And now we have single-page applications and a huge number of JS frameworks. For example, there is a React Ecosystem for the browser and React Native for mobile devices. In Silicon Valley, React is a huge area that involved a huge number of people. In one day and on the neighboring streets of San Francisco, several React meetings with an audience of several hundred people took place.
From the point of view of JavaScript, this is a story about distribution , that technologies are not very good at first, but if they are installed in all browsers and conveyed to each client machine, then naturally, over time we will all have to deal with this, because there is simply no other. This story is about how distribution has allowed this language to develop, to take a leadership position among other programming languages.
Below is a graph from the RedMonk.com study for the first quarter of 2018.
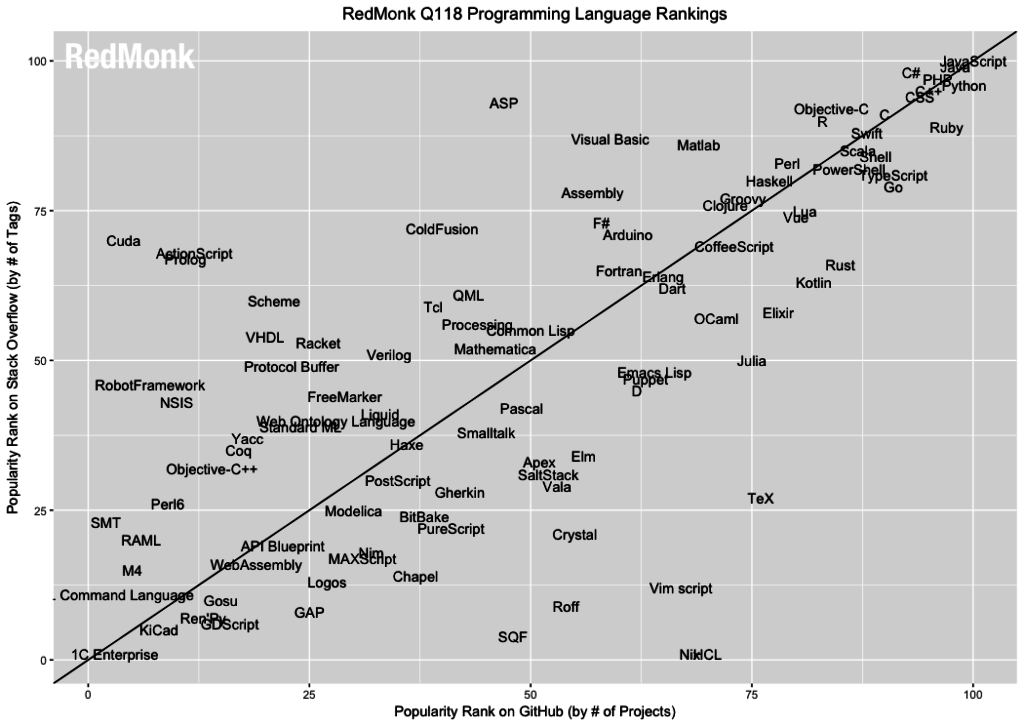
By OY - the number of tags in questions StackOverflow, and by OX - the number of projects in GitHub. We see that JavaScript wins in both categories, but the other 3 ducks are also very close: Java, it’s stuck there, PHP, Ruby is also very close, that is, these are 4 languages that were born one year 23 years ago. Almost all other studies also confirm that JavaScript is ahead of all programming languages.
I'm a little worried about SQL, because I saw that if SQL on GitHub was measured a little differently, it would even be ahead of JavaScript, because it exists in very many projects, despite the hype around noSQL. But it is clear that JavaScript is a language that can not be ignored .
And the second aspect of fat clients. Four years ago, there was an advance of mobile devices over the desktop. Back in 2015, Google announced that they use their search more on mobile devices than on computers.

These two aspects lead us to the idea that when we start a new project, we don’t want to think about the backend at all .

The idea is this - let's not think about Backend at all. Of course, if we have many users and they somehow interact, then we need somewhere to store this data, of course, on the server and somehow work with it. It just has to be: efficient, reliable, safe .
Another important aspect is that if you do not have a new project, but a long-playing one, which has a website, an application for iOS, Android, maybe for smartTV and even a clock, then naturally you need Backend and a universal API.

The whole zoo should interact in a unified way and either you use the REST API or GraphQL from the React Ecosystem - in any case, you need to have something like that.
How to survive
First option. Clouds
Let's, we will have no servers at all, we will live entirely in the clouds . Unfortunately, such (specialized cloud services offering API deployment in the cloud with a minimum of effort) online projects did not survive. Two prominent representatives: StackMob.com and Parse.

In both cases, the company that absorbed the project simply transferred the engineers to more pressing projects. It can be said that in these cases competition was lost to general-purpose clouds such as Amazon and Google, but there are also other aspects, such as an obscure API, lack of storage and low productivity, but high prices, etc. A few years ago there was a lot of hype, but However, these services did not survive.
In general, the idea is this: if we have clouds, then let's get more reliable, understandable, and which will not go away tomorrow, the solutions are Amazon and Google. They have some elements of the noBackend approach, this is Lambda and the service for Cognito authentication / authorization.
If you really want noBackend for API or something else, then here’s a link to specialized solutions so that you don’t have your Backend servers at all, but write client code right away.
The second option. Postgrest
And now I say, but let's still do it in earnest . And here - PostgREST. Despite the fact that I strongly urge to use it, the article will be quite general.

There is such an actively developing PostgREST thing — in fact, this is the path of a real Jedi, because it allows you to quickly get all the power.
PostgREST strength
PostgREST is written in Haskell and distributed under a very liberal license, is actively developing, and you can get support in gitter chat . At the present moment, PostgREST has matured to excellent condition and is “run-in” in many projects.

The slide above shows how this can be launched: the v1 diagram is the scheme in which the first version of our API lives, we can quickly create a label, or, if we already have some labels, we can assemble a “virtual label "- view (view). And then we get API-endpoint / person, where you can use parameters for filtering, page-by-page navigation, sorting, and joining with other tables.
Four methods are supported: GET is automatically translated to SELECT for SQL, POST - to INSERT, PATCH - to UPDATE, DELETE - to DELETE.
You can also write a stored procedure and, most likely, if you use PostgREST, you will. I know that many people say that stored procedures are evil. But I do not think so, my experience is quite large and I used different DBMS and “storage” - not evil . Yes, there are some difficulties with debugging, but debugging is generally a complicated thing.
PL / pgSQL is the main language for stored procedures and there are debuggers for it. But you can also use other languages, including PL / Python or plv8 (this is JavaScript, but one that cannot communicate with the outside world). That is, there are many different possibilities, including a language for analytics and PL / R statistics. Stored procedures can be called using POST / rpc / procedure_name (then we pass named parameters in the body) or GET / rpc / procedure_name (then only GET parameters can be used, which imposes corresponding restrictions).
All the lessons that will be in the article, at the end we will summarize in the memo . If you are a "front-end", you can take this memo and just check by points how good the decision you have chosen for the backend. If you are a backend, you should check how good the backend you are building.
Quality
Let's start with the first lesson that I had to learn in several projects.
When you start building an API, you need to overlap the tests almost immediately, definitely. And, if you have not yet used (although I think most of you use) Continuous Integration tools, then you definitely need to do this and impose tests, especially “bad tests,” so that nothing can be discovered that cannot be opened outside. It’s one thing if you made superuser in the database and your rubists use it, and another thing sticks it out and you can do something bad. Any hacker will come sooner or later, I have had such cases many times.

Shortly before the report (2016) @backendsecret conducted a survey on Twitter, and I actually expected that half would be without Continuous Integration, but in fact everything was pretty cool.
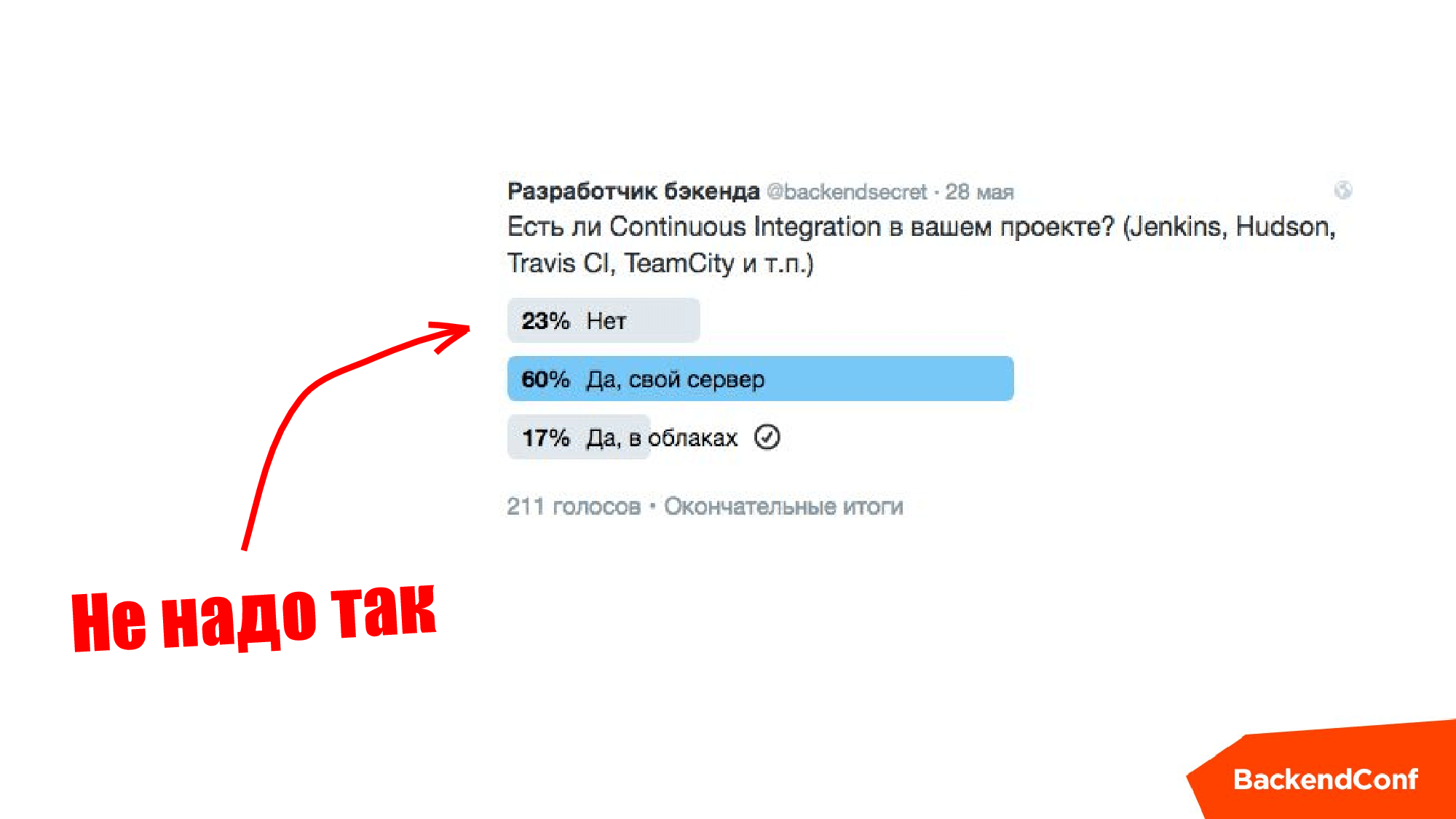
If you are in the first paragraph on the slide above, then do not do it this way, this is the “loser” approach.
REST API
Not everyone knows that right in Firefox, the request that was made, just change it there is Edit and Resend, there is cURL, there is a console utility HTTPie, in which more convenient output.

But our main tool is the Postman extension for Google Chrome. If you work with API, then it will be very useful for you. It solves a number of problems: you can throw a bunch of requests, save them, make them abstracted from the environment. Those. you have a dev server, a staging server, a production server — there are different hosts, there are different logins, passwords, all this can be started as an environment, unloaded into files and further, with the help of newman, which is like an addition to Postman, to call from the console. And place in your CI so that the API tests run automatically with every change in the project.
Security
Few people like to think about security, but it needs to be done . For example, if we have a label and we simply create a view in PostgREST as “SELECT * FROM this label”, then we create a security problem for ourselves. Because, if the user, under which our API operates, has rights, then anyone can go into anything, including, say, someone else's user_id, that is, it is a complete mess.

In this case, you need to understand the rights of the relational database and give only those rights that are needed. If you use utilities for migrating DDL changes, for example, Sqitch has the ability to test changes , that is, they can be verified using the migration-test. And in particular, you can assign privileges, but I recommend you such a trick (the arrow on the slide on the slide above leads to it): if there is a division by zero, an error will be detected and this will help to verify that the user does not have a privilege on this table.
From the point of view of the API, we must verify that the API responds with the appropriate code (in the case of PostgREST, most often the code will be 400). If you write a test in Postman, it is automatically unloaded, and then with newman everything is automatically turned and checked. This must be done, and it is imperative to think in advance where the doors are and where to close them.
In fact, there may be three levels of security issues, let's talk about each separately.
Anonymous requests
The first level of problems is the validation of an anonymous user, i.e. a user who does not have a PostgREST signature header. If the header is, but PostgREST does not recognize it, it will be an "invalid token." If there is no header, then this is considered to be anonymous and then its actions in the PostgREST database will be executed under another user.

Your task is that this user does not have any rights at all except: registration, login and password reset - this is enough. Then you can write a test and make sure that this user does not have such rights as I described in the previous slides. This solves the anonymous problem.
Column rights
What is it about? If you make a SELECT * from the “user” table, then you at least “shine” the password hash (I hope that you store them in a hashed form). But you "shine" and email - this can not be done.

If you let other users look at the list of users, you should at least take care to cut off those columns that cannot be “shined”. This is done in an obvious way: when creating this view, you list which fields you can read, rather than “SELECT *”. In PostgREST, it has been possible for a very long time to show a table to an anonym , if suddenly you are impatient and he can read it. But you can remove the right to read on some separate columns. You can also do INSERT and UPDATE and make it very flexible . For example, it is obvious that the user should not have the right to change his ID. The rights to the columns help us protect the data that a person should not have the right to change.
Prohibition of access to "alien" lines
It is so more difficult to be sighted, but a very important aspect is that you cannot let other people's lines change. Those. if we gave the opportunity to update the view, then in fact, any user by default will be able to update other people's lines through the API - and this is a disaster.

This is another door, the closeness of which should be automatically checked. And how to close it? If you have the most advanced PostgREST, then use Row-Level Security - this is the preferred method. If you have an older version, then we write stored procedures: PostgREST makes the session variable (claimss.XXXXX), and we know who exactly executes this procedure and we can check everything.
Performance
Let's start with a typical example, let's say you have a user base and collections with posts, and suppose you have millions and millions of blogs, plus more links between users and collections. In the slide below, I noted 4 tables: person, post, collection, person2collection is a typical model of any social media and standard task.

Of course, the giants, for example, Instagram and Twitter show us news not in chronological order, but in our example we will build a chronological order of shows.
There are two options for solving this problem "in the forehead." The first way is in case we are afraid of joining: we first select posts, then, knowing from which collections they are, choose collections, then we choose the author.
The second more PostgREST style: write a JOIN from 4 tables and then it’s all "digest". For example, above I gave row_to_json, and then PostgREST will return you json, in which json will be embedded with information about authors and collections.
But both of these requests are bad in terms of performance . But the first request is much worse, because there are 3 requests, 3 API calls . When you write in Ruby / PHP / Python, then you may not worry much about it, in some DBMS it is more convenient to make three quick and short SQL queries instead of one. But it’s quite another thing when you do it through an API. Imagine that a person from another country, and round-trip time can be 100-200 milliseconds, and now you already have 600 extra milliseconds . They could be 200, and now 600. That is, the first option needs to be swept away immediately - we should try to do everything in one request, if, of course, it is possible
So, the first sub-lesson here is that first of all we need to think about network complexity.
If you have large amounts of data, you will get problems with the second method, because it will work for seconds, or even tens of seconds.

Many projects have come up against this, including several of mine, and I’m very much rescued by the famous PostgREST expert living in Australia, Maxim Boguk, I highly recommend this presentation of his report on PGday . After studying it, you will be able to master Jedi techniques, such as: working with recursive queries, with arrays, folding and unfolding of a string, including an approach that is very economical in reading Loose IndexScan data.
Below is the actual request for one of the projects similar to the first two, but which runs a few milliseconds on the same data.
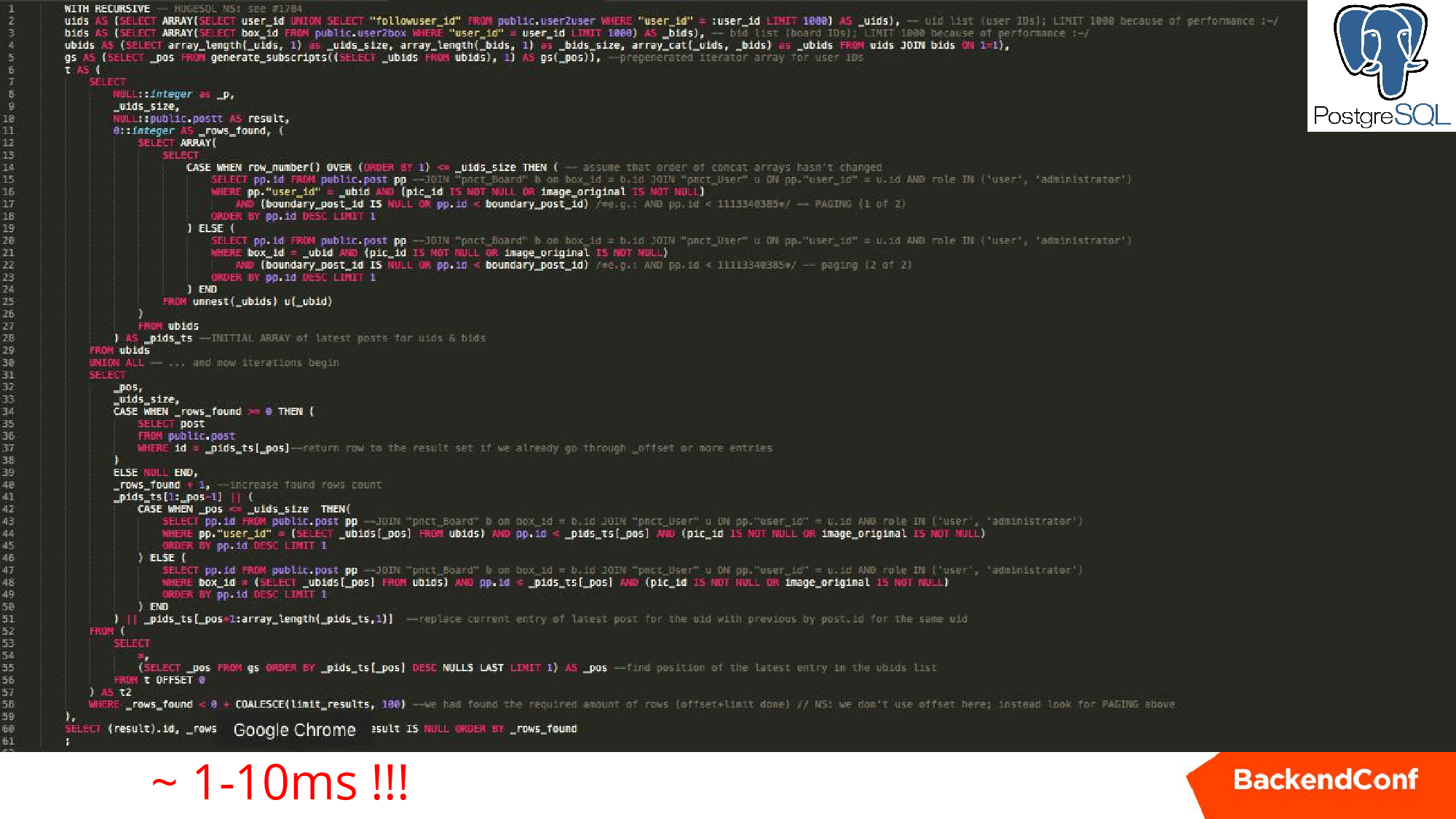
He recursively spins up our task, getting one post from each collection, forms a set, then goes replacing, replacing, until he collects 25 posts that can already be shown. Very cool thing, I advise you to study.
When using PostgREST you have a huge amount of tools to increase productivity, you can use force.
Scalability
First level: it is clear that we do not have a session, the RESTful approach and PostgREST can be put on a large number of machines and it will work quietly.
Second level. For example, if you need to scale the reading load, then you can also configure special PostgREST instances that will only access the slave, and use ngnix to balance the load. Here everything is transparent, in contrast to the monolithic approaches.
In this case, when you have a GET, then 100% is only a read SELECT transaction (unless it is the SELECT / rpc / procedure_name mentioned above). Therefore, ngnix is easy to set up the configuration so that it sends some traffic to another host. Everything is in the hands of the admin who deals with ngnix. Those who do not need it all yet can be sure that in the future you will be able to scale your project.
Question: how to scale the master? Right off the bat - so far, but the Poctgres-community is actively working on this.

There is also a philosophical aspect : all the hype around WebScale. When you need to dig up a field, what would you prefer: 100 migrant workers with shovels or a tractor? Now PostgreSQL is approaching to make a million transactions per second on one server. In fact, this is a tractor that is improved every year, a new version is released every year, and it is really very advanced.
If you put a solution like MongoDB, then, firstly, it works worse on one machine, and, secondly, they simply do not have PosgreSQL capabilities - this is far from a tractor. You, as well as with migrant workers, need to worry about all of them, the servers on MongoDB need to be serviced, they fail, are capricious.
The task of digging up a field can be solved by a tractor much more efficiently in terms of cost, time, and in the future this may turn out to be better.
What not to do inside?
The answer is obvious! If you are requesting an external server, you should not do this directly in PostgREST, because it will take unpredictable time, and you should not hold the Posgres backend on master for incomprehensible time.

It is worth using the methods LISTEN / NOTIFY - this is an old, long-established, thing. Or implement the queue directly in the database, using very efficient processing in many threads using “SELECT ... FOR UPDATE SKIP LOCKED”.
You can make a script on Node.js or RUBY or, whatever, this daemon subscribes to PostgREST events, and then the stored procedure simply sends a message in this event, and your daemon picks it up.
If you want to events that suddenly for some time no one listened, were not lost, you will have to change all the systems of queues. There are a number of solutions for this, this is a topic that has been rather crawled, just to cite a few references:
And finally, the promised memo. This is a list of everything we discussed today. If you are starting a new project or reworking the old one to use the internal API, go through these points and you will be happy.

Contacts and links:
Email: ru@postgresql.org
Website: http://PostgreSQL.support
Twitter: https://twitter.com/postgresmen
YouTube: https://youtube.com/c/RuPostgres
Mitapas: http://RuPostgres.org
This article is based on the report of Nikolai Samokhvalov , who, in turn, summarized the experience of a number of projects written in React, React Native and Swift and shifting to the noBackend paradigm at the expense of PostgreSQL + PostgREST .
At the end, you will find a list of must-check-questions for working with the noBackend approach, and if your Postgres experience allows, then immediately after reading you can begin to deploy a safe, high-performance and usable for the rapid development of the REST API .
')
About the speaker: Nikolai Samokhvalov has been working with PostgreSQL for more than a decade. He is a co-organizer of the Russian community RuPostgres.org and currently helps various companies to optimize, scale and automate the processes associated with the operation of PostgreSQL. Next is the decoding of Nikolai's report on Backend Conf , designed for both the backend and the front-end developers.
The last years I spend a lot of time in Silicon Valley and want to share with you the trends that I see there. Of course, from here you can also see everything perfectly, but there they are clearer, because professional conversations about advanced technologies are conducted literally in every cafe.
The era of gaining customers
Let's first define what a fat client is and what kind of era it is.
Curious fact. Did you know that Ruby appeared in the same year with PHP, Java and JavaScript?
These four ducklings appeared in one year and, in fact, it is clear which of them is ugly, right? Naturally, this is javascript.
He was “on the knee” written for 10 days by an employee who, in preparation for the new Netscape browser, wrote a scripting language. Initially, it was even called differently, and then, when they screwed Java, they also decided to rename at the same time, and now for 23 years some newcomers have confused these languages . Then for many years JavaScript performed a secondary role and was in order to make some kind of animation or count some reaction in the browser.
But gradually, somewhere from 2003-2004, the hype around WEB 2.0 began, GMail, Google Maps and others appeared, and JavaScript, of course, gained more importance - customers began to get fat. And now we have single-page applications and a huge number of JS frameworks. For example, there is a React Ecosystem for the browser and React Native for mobile devices. In Silicon Valley, React is a huge area that involved a huge number of people. In one day and on the neighboring streets of San Francisco, several React meetings with an audience of several hundred people took place.
From the point of view of JavaScript, this is a story about distribution , that technologies are not very good at first, but if they are installed in all browsers and conveyed to each client machine, then naturally, over time we will all have to deal with this, because there is simply no other. This story is about how distribution has allowed this language to develop, to take a leadership position among other programming languages.
Below is a graph from the RedMonk.com study for the first quarter of 2018.
By OY - the number of tags in questions StackOverflow, and by OX - the number of projects in GitHub. We see that JavaScript wins in both categories, but the other 3 ducks are also very close: Java, it’s stuck there, PHP, Ruby is also very close, that is, these are 4 languages that were born one year 23 years ago. Almost all other studies also confirm that JavaScript is ahead of all programming languages.
I'm a little worried about SQL, because I saw that if SQL on GitHub was measured a little differently, it would even be ahead of JavaScript, because it exists in very many projects, despite the hype around noSQL. But it is clear that JavaScript is a language that can not be ignored .
And the second aspect of fat clients. Four years ago, there was an advance of mobile devices over the desktop. Back in 2015, Google announced that they use their search more on mobile devices than on computers.
These two aspects lead us to the idea that when we start a new project, we don’t want to think about the backend at all .
The idea is this - let's not think about Backend at all. Of course, if we have many users and they somehow interact, then we need somewhere to store this data, of course, on the server and somehow work with it. It just has to be: efficient, reliable, safe .
Another important aspect is that if you do not have a new project, but a long-playing one, which has a website, an application for iOS, Android, maybe for smartTV and even a clock, then naturally you need Backend and a universal API.
The whole zoo should interact in a unified way and either you use the REST API or GraphQL from the React Ecosystem - in any case, you need to have something like that.
How to survive
First option. Clouds
Let's, we will have no servers at all, we will live entirely in the clouds . Unfortunately, such (specialized cloud services offering API deployment in the cloud with a minimum of effort) online projects did not survive. Two prominent representatives: StackMob.com and Parse.
In both cases, the company that absorbed the project simply transferred the engineers to more pressing projects. It can be said that in these cases competition was lost to general-purpose clouds such as Amazon and Google, but there are also other aspects, such as an obscure API, lack of storage and low productivity, but high prices, etc. A few years ago there was a lot of hype, but However, these services did not survive.
In general, the idea is this: if we have clouds, then let's get more reliable, understandable, and which will not go away tomorrow, the solutions are Amazon and Google. They have some elements of the noBackend approach, this is Lambda and the service for Cognito authentication / authorization.
If you really want noBackend for API or something else, then here’s a link to specialized solutions so that you don’t have your Backend servers at all, but write client code right away.
The second option. Postgrest
And now I say, but let's still do it in earnest . And here - PostgREST. Despite the fact that I strongly urge to use it, the article will be quite general.
There is such an actively developing PostgREST thing — in fact, this is the path of a real Jedi, because it allows you to quickly get all the power.
PostgREST strength
PostgREST is written in Haskell and distributed under a very liberal license, is actively developing, and you can get support in gitter chat . At the present moment, PostgREST has matured to excellent condition and is “run-in” in many projects.
The slide above shows how this can be launched: the v1 diagram is the scheme in which the first version of our API lives, we can quickly create a label, or, if we already have some labels, we can assemble a “virtual label "- view (view). And then we get API-endpoint / person, where you can use parameters for filtering, page-by-page navigation, sorting, and joining with other tables.
Four methods are supported: GET is automatically translated to SELECT for SQL, POST - to INSERT, PATCH - to UPDATE, DELETE - to DELETE.
You can also write a stored procedure and, most likely, if you use PostgREST, you will. I know that many people say that stored procedures are evil. But I do not think so, my experience is quite large and I used different DBMS and “storage” - not evil . Yes, there are some difficulties with debugging, but debugging is generally a complicated thing.
PL / pgSQL is the main language for stored procedures and there are debuggers for it. But you can also use other languages, including PL / Python or plv8 (this is JavaScript, but one that cannot communicate with the outside world). That is, there are many different possibilities, including a language for analytics and PL / R statistics. Stored procedures can be called using POST / rpc / procedure_name (then we pass named parameters in the body) or GET / rpc / procedure_name (then only GET parameters can be used, which imposes corresponding restrictions).
All the lessons that will be in the article, at the end we will summarize in the memo . If you are a "front-end", you can take this memo and just check by points how good the decision you have chosen for the backend. If you are a backend, you should check how good the backend you are building.
Quality
Let's start with the first lesson that I had to learn in several projects.
By the way, PostgreSQL is not necessarily a purely relational DBMS, you can store JSON there, some do even in payment systems, such a kind of NoSQL.
When you start building an API, you need to overlap the tests almost immediately, definitely. And, if you have not yet used (although I think most of you use) Continuous Integration tools, then you definitely need to do this and impose tests, especially “bad tests,” so that nothing can be discovered that cannot be opened outside. It’s one thing if you made superuser in the database and your rubists use it, and another thing sticks it out and you can do something bad. Any hacker will come sooner or later, I have had such cases many times.
Shortly before the report (2016) @backendsecret conducted a survey on Twitter, and I actually expected that half would be without Continuous Integration, but in fact everything was pretty cool.
If you are in the first paragraph on the slide above, then do not do it this way, this is the “loser” approach.
REST API
Not everyone knows that right in Firefox, the request that was made, just change it there is Edit and Resend, there is cURL, there is a console utility HTTPie, in which more convenient output.
But our main tool is the Postman extension for Google Chrome. If you work with API, then it will be very useful for you. It solves a number of problems: you can throw a bunch of requests, save them, make them abstracted from the environment. Those. you have a dev server, a staging server, a production server — there are different hosts, there are different logins, passwords, all this can be started as an environment, unloaded into files and further, with the help of newman, which is like an addition to Postman, to call from the console. And place in your CI so that the API tests run automatically with every change in the project.
Security
Few people like to think about security, but it needs to be done . For example, if we have a label and we simply create a view in PostgREST as “SELECT * FROM this label”, then we create a security problem for ourselves. Because, if the user, under which our API operates, has rights, then anyone can go into anything, including, say, someone else's user_id, that is, it is a complete mess.
In this case, you need to understand the rights of the relational database and give only those rights that are needed. If you use utilities for migrating DDL changes, for example, Sqitch has the ability to test changes , that is, they can be verified using the migration-test. And in particular, you can assign privileges, but I recommend you such a trick (the arrow on the slide on the slide above leads to it): if there is a division by zero, an error will be detected and this will help to verify that the user does not have a privilege on this table.
From the point of view of the API, we must verify that the API responds with the appropriate code (in the case of PostgREST, most often the code will be 400). If you write a test in Postman, it is automatically unloaded, and then with newman everything is automatically turned and checked. This must be done, and it is imperative to think in advance where the doors are and where to close them.
In fact, there may be three levels of security issues, let's talk about each separately.
Anonymous requests
The first level of problems is the validation of an anonymous user, i.e. a user who does not have a PostgREST signature header. If the header is, but PostgREST does not recognize it, it will be an "invalid token." If there is no header, then this is considered to be anonymous and then its actions in the PostgREST database will be executed under another user.
Your task is that this user does not have any rights at all except: registration, login and password reset - this is enough. Then you can write a test and make sure that this user does not have such rights as I described in the previous slides. This solves the anonymous problem.
Column rights
What is it about? If you make a SELECT * from the “user” table, then you at least “shine” the password hash (I hope that you store them in a hashed form). But you "shine" and email - this can not be done.
If you let other users look at the list of users, you should at least take care to cut off those columns that cannot be “shined”. This is done in an obvious way: when creating this view, you list which fields you can read, rather than “SELECT *”. In PostgREST, it has been possible for a very long time to show a table to an anonym , if suddenly you are impatient and he can read it. But you can remove the right to read on some separate columns. You can also do INSERT and UPDATE and make it very flexible . For example, it is obvious that the user should not have the right to change his ID. The rights to the columns help us protect the data that a person should not have the right to change.
Prohibition of access to "alien" lines
It is so more difficult to be sighted, but a very important aspect is that you cannot let other people's lines change. Those. if we gave the opportunity to update the view, then in fact, any user by default will be able to update other people's lines through the API - and this is a disaster.
This is another door, the closeness of which should be automatically checked. And how to close it? If you have the most advanced PostgREST, then use Row-Level Security - this is the preferred method. If you have an older version, then we write stored procedures: PostgREST makes the session variable (claimss.XXXXX), and we know who exactly executes this procedure and we can check everything.
Performance
Let's start with a typical example, let's say you have a user base and collections with posts, and suppose you have millions and millions of blogs, plus more links between users and collections. In the slide below, I noted 4 tables: person, post, collection, person2collection is a typical model of any social media and standard task.
Of course, the giants, for example, Instagram and Twitter show us news not in chronological order, but in our example we will build a chronological order of shows.
There are two options for solving this problem "in the forehead." The first way is in case we are afraid of joining: we first select posts, then, knowing from which collections they are, choose collections, then we choose the author.
The second more PostgREST style: write a JOIN from 4 tables and then it’s all "digest". For example, above I gave row_to_json, and then PostgREST will return you json, in which json will be embedded with information about authors and collections.
But both of these requests are bad in terms of performance . But the first request is much worse, because there are 3 requests, 3 API calls . When you write in Ruby / PHP / Python, then you may not worry much about it, in some DBMS it is more convenient to make three quick and short SQL queries instead of one. But it’s quite another thing when you do it through an API. Imagine that a person from another country, and round-trip time can be 100-200 milliseconds, and now you already have 600 extra milliseconds . They could be 200, and now 600. That is, the first option needs to be swept away immediately - we should try to do everything in one request, if, of course, it is possible
So, the first sub-lesson here is that first of all we need to think about network complexity.
By the way, if you work with a relational database, remember that in no case should you use OFFSET for page-by-page navigation. In the slide, it is made using WHERE and using the previous ID.
If you have large amounts of data, you will get problems with the second method, because it will work for seconds, or even tens of seconds.
Many projects have come up against this, including several of mine, and I’m very much rescued by the famous PostgREST expert living in Australia, Maxim Boguk, I highly recommend this presentation of his report on PGday . After studying it, you will be able to master Jedi techniques, such as: working with recursive queries, with arrays, folding and unfolding of a string, including an approach that is very economical in reading Loose IndexScan data.
Below is the actual request for one of the projects similar to the first two, but which runs a few milliseconds on the same data.
He recursively spins up our task, getting one post from each collection, forms a set, then goes replacing, replacing, until he collects 25 posts that can already be shown. Very cool thing, I advise you to study.
When using PostgREST you have a huge amount of tools to increase productivity, you can use force.
Scalability
First level: it is clear that we do not have a session, the RESTful approach and PostgREST can be put on a large number of machines and it will work quietly.
Second level. For example, if you need to scale the reading load, then you can also configure special PostgREST instances that will only access the slave, and use ngnix to balance the load. Here everything is transparent, in contrast to the monolithic approaches.
Note that this whole topic is very similar to Object-Relational Mapping. That is, of course, not ORM, but such JSON-Relational Mapping.
In this case, when you have a GET, then 100% is only a read SELECT transaction (unless it is the SELECT / rpc / procedure_name mentioned above). Therefore, ngnix is easy to set up the configuration so that it sends some traffic to another host. Everything is in the hands of the admin who deals with ngnix. Those who do not need it all yet can be sure that in the future you will be able to scale your project.
Question: how to scale the master? Right off the bat - so far, but the Poctgres-community is actively working on this.
There is also a philosophical aspect : all the hype around WebScale. When you need to dig up a field, what would you prefer: 100 migrant workers with shovels or a tractor? Now PostgreSQL is approaching to make a million transactions per second on one server. In fact, this is a tractor that is improved every year, a new version is released every year, and it is really very advanced.
If you put a solution like MongoDB, then, firstly, it works worse on one machine, and, secondly, they simply do not have PosgreSQL capabilities - this is far from a tractor. You, as well as with migrant workers, need to worry about all of them, the servers on MongoDB need to be serviced, they fail, are capricious.
The task of digging up a field can be solved by a tractor much more efficiently in terms of cost, time, and in the future this may turn out to be better.
What not to do inside?
The answer is obvious! If you are requesting an external server, you should not do this directly in PostgREST, because it will take unpredictable time, and you should not hold the Posgres backend on master for incomprehensible time.
It is worth using the methods LISTEN / NOTIFY - this is an old, long-established, thing. Or implement the queue directly in the database, using very efficient processing in many threads using “SELECT ... FOR UPDATE SKIP LOCKED”.
You can make a script on Node.js or RUBY or, whatever, this daemon subscribes to PostgREST events, and then the stored procedure simply sends a message in this event, and your daemon picks it up.
If you want to events that suddenly for some time no one listened, were not lost, you will have to change all the systems of queues. There are a number of solutions for this, this is a topic that has been rather crawled, just to cite a few references:
- LISTEN / NOTIFY (see PostgREST postgrest.com/examples/users/#password-reset for an example).
- mbus (R. Druzyagin, I. Frolkov, report PgDay'15 pgday.ru/files/papers/23/pgday.2015.messaging.frolkov.druzyagin.pdf ).
- Messages in AMPQ (for example, PostgreSQL LISTEN Exchange: github.com/aweber/pgsql-listen-exchange ).
And finally, the promised memo. This is a list of everything we discussed today. If you are starting a new project or reworking the old one to use the internal API, go through these points and you will be happy.
Contacts and links:
Email: ru@postgresql.org
Website: http://PostgreSQL.support
Twitter: https://twitter.com/postgresmen
YouTube: https://youtube.com/c/RuPostgres
Mitapas: http://RuPostgres.org
At the nearest Backend Conf, Nikolay will continue to carry Postgres to the masses, in particular, promises to present a new tool for semi-automatic search for bottlenecks in performance that does not require in-depth knowledge of internal components.
Do not forget about Highload ++ Siberia , before the summer conference of developers of high-loaded projects for less than two months - it's time to book tickets .
Source: https://habr.com/ru/post/358502/
All Articles