Lecture on Toloka. How thousands of people help us make Yandex
Every day, tens of thousands of people perform tasks in Toloka: assess the relevance of sites, classify images, mark objects in photographs. Solving these and many other problems, they help us improve existing and create new algorithms, as well as maintain the relevance of the data.
On the one hand, Toloka appeared relatively recently - in 2014. On the other hand, it serves as the most important part of all key Yandex services and dozens of smaller services. Artem Grigoriev ortemij explained how this crowdsourcing platform is arranged, what technologies and architectural solutions are used in its development. In addition, Artyom spoke about the logic of assigning tasks to users, working with geodata on the map and quality management.
- A few words about me. I have been working for Yandex at the St. Petersburg office for more than seven years. When I first came here, I was engaged in various tools to assess the quality of the search. We developed different metrics, compared ourselves with competitors and different versions of other search engines. Now I lead a service with a long name, like on a slide.
In short, we work in three main areas. First, we are developing our crowdsourcing Yandex.Tolok platform. Secondly, we develop various services for assessors. These are special people in Yandex like moderators. Support specialists, we make different services for them, content managers, etc.
')
And finally, we are developing an infrastructure that allows all Yandex teams to work with the listed people and the results of their work. This infrastructure connects what we do and what people do, for example, when developing a search.

The report will be about our crowdsourcing platform. First I want to clarify the concept of crowdsourcing. Do not confuse with the development of outsourcing or raising money through crowdfunding, this is slightly different.

Let's imagine that you are learning machine. For example, you want to train a classifier, and you have a data set that needs to be tagged and gain some knowledge. This data set can be represented as a number of tasks, write instructions on which tasks can be completed, and send to some people who will do this.
The essence of crowdsourcing is to break your work into some separate tasks, send it to the cloud of performers, and then take the result from there. There are several different crowdsourcing platforms in the world, and we are developing one of them.

Second question. I will explain the term Toloka. Many may say that I incorrectly pronounce this word. In Russian, the emphasis is on the second syllable, but we pay tribute to what this service was initially started in our Belarusian office, many guys came to answer your questions on the sidelines.
When we started to do this service and came up with the name, we remembered that there is such an interesting concept. The meaning of this word is that we are transported to ancient times. People in the village get together and do something for the benefit of society. Each of them, perhaps, could not have done this work, but they got together, went to harvest or build a barn for public use. Toloka is a custom to get together and help each other. We thought it was similar to the modern term of crowdsourcing, so this name was chosen for our service.
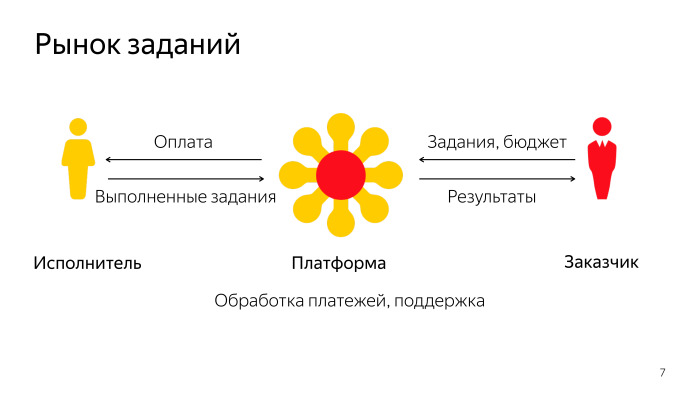
In general, Toloka and other crowdsourcing platforms operate on a simple principle: they connect customers and performers. Task platforms provide some budget for their implementation, and performers, while performing tasks, earn money and send results to customers.
The platform deals with the fact that it processes all payments, all interactions between the customer and the contractor, resolves various conflict situations, etc.
Almost all Yandex services use our platform. She is very popular.
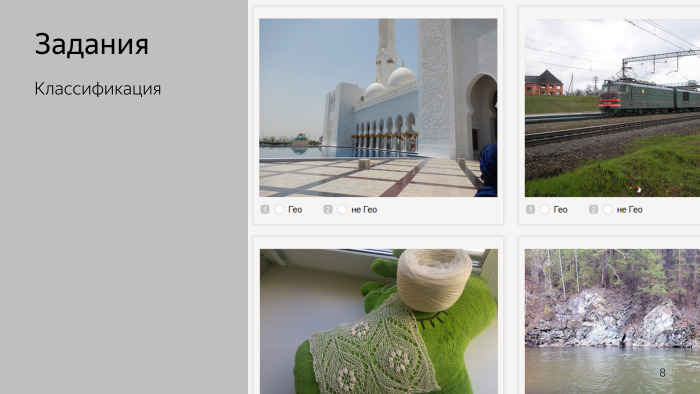
I can cite several examples of tasks that are actually being placed on the platform now.
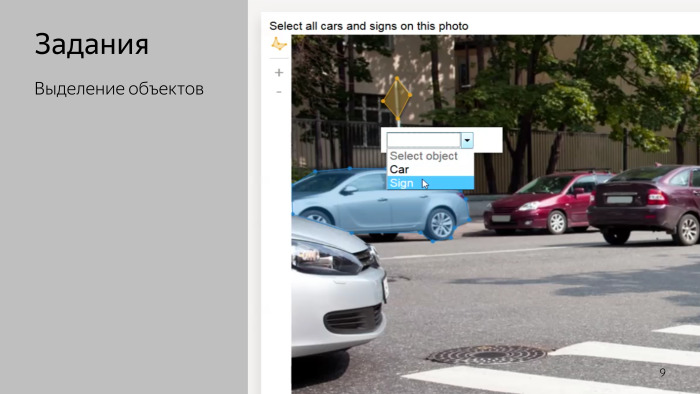
For example, tasks for a simple classification of photos. Or tasks for training unmanned vehicles. Maybe they saw a video where a Yandex car was driving along Khamovniki in Moscow, and the markup to train computer vision in this car was collected, including in Toloka.

Tasks for recognizing prices in photographs, etc. In principle, the basic is clear, the humanitarian introduction ends here.
If someone is interested in learning more about crowdsourcing, I spoke at the SmartData conference in the fall, you can find a video with that title on Youtube, it tells in more detail what crowdsourcing is and what features are interesting in it.
We are here to learn the internal, technical features of the work of our platform, so let's move on to this part.
Toloka is available in several forms. You can go to the toloka.yandex.ru website in the browser, complete tasks there. We also have mobile apps for iOS and for Android. They are used, in particular, for various tasks where mobility is required, people walk around the area and perform tasks “in the fields”, and where special phone features are needed, for example, a voice recorder or a camera.
Our backend is written mostly in Java.

We actively use SpringBoot and all its components. As a result, Toloka is presented as a set of microservices, each of which is deployed as a Docker container in our cloud system. We deploy to our inner cloud.

As storage, we use several different. The most basic business logic is made on PostgreSQL, because we work with money, it is very important for us to ensure transactions between customers and users. All the logic where this feature is critical, we have in PostgreSQL.
For those places where it is not needed, we use MongoDB. Many microservices that are built around Toloka use this storage. This is our internal implementation of MapReduce, similar to BigTable, in Yandex it is affectionately called YT .

In the development of Toloka there are several main areas in which we solve our problems. The subject area of crowdsourcing itself and the service itself is quite complex, so we have quite a lot of tasks to implement a variety of business logic. We actively use a variety of technologies, we use all sorts of optimizations, so this class of tasks is also quite large.
Finally, the subject area is quite interesting and dynamically developing, and there are quite a lot of research on this topic in the world, so we are also engaged in such research inside.
To lift the veil on what is happening inside, I will bring one task from each area, and try to tell something interesting, what is happening, on this topic.
Let's start with business logic.
The most important thing in the system is the selection of tasks by users. The first thing that sees a person who registers in Toloka is the main page, which shows a list of tasks available to him.
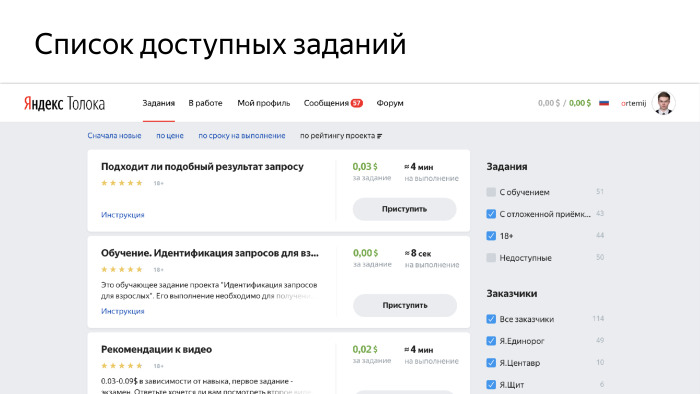
Let's try to figure out what is behind this. The page looks pretty simple, but in fact, behind every project that users see on the screen, there is a huge queue of tasks that customers upload there.
Customers usually form some task pools, sets of tasks available to a certain number of performers, and these tasks are loaded there in batches. We have a large queue, in which, on the one hand, customers fill in pools and new tasks, on the other hand, the performers come and ask what tasks are available to me, choose interesting ones for themselves, and then send the results there.
How does the list of available tasks work, the main page of Yandex.Toloki?

Firstly, we are looking for pools that are suitable for executors by filters. I will tell you more about this later, but not all tasks are available to everyone, so we must filter out those that show this user.
After that we check if the user is banned on this project. In the system, those performers who do not do well with the tasks, they are removed from them, and for various reasons, the user may be banned.
The important point is that we give the tasks not one by one, but the pages on which several tasks are shown at once, this is done to optimize the speed. We need to find those pools in which the user has enough tasks to display the page. And it is important that we don’t show the same tasks to the user a second time, he does everything once. After filtering all this, we group and display a page on the front end that a person sees.
The performer in our system is represented by several characteristics. There are computable fields, for example, the OS from which the user logs in, we can filter by this criterion. Or its IP address, region calculated by this IP, etc.
There are some data that the user entered about himself in the profile - gender, age, education. Customers can also filter users for these tasks using these profiles.

Another concept is skill. This is a kind of numerical characteristic that the customer can assign to the contractor on the outcome of the assignments on his projects. Usually it describes how well a person copes with this task. The user is represented as a long JSON in which all these characteristics are recorded.
On the other hand, we have some pools where filters are specified.

Suppose that in order to perform certain tasks, we need users who have indicated by phone number that they are located in Russia, Ukraine, Kazakhstan or Belarus, and some other restriction on skills. When a user comes to the page, we match this filter view on some pseudo language with the user’s JSON view that we have at the moment. The user's view may change, and the customer can also change the filters configured on the pool.
Previously, we compiled the JSquery filter view, such a plugin for the user. Now we have stopped doing this, because the filter view on JSquery is such a plugin for PostgreSQL. Now we have stopped doing this, because the memory on the backend itself was much faster in the memory.
We have filtered the pools, and we need to check that there are enough tasks in them that the user has not done yet to show him the full page. And we again return to the queues.
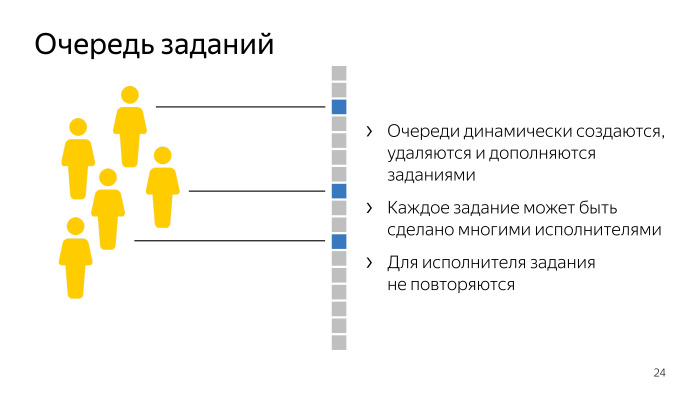
Each task pool is a task queue for a different number of users. She has some set of properties. First, these queues are dynamically created, deleted, and customers can also add new tasks to pools, so these queues can be supplemented with new elements.
Secondly, each task can be done by many performers. In this queue, there are many different customers for each job. And for the performers of the task should not be repeated, we should not pay a person twice for what he does. All these restrictions, coupled with the fact that there may be tens of thousands of such queues, are laid out in order to render the main page, which we are asked about 150 times per second, we need to do about 40 thousand checks that in this queue, in This task pool is available to the user. This is a difficult place, and we optimized it as follows - we transferred all these checks to the database.


Used such a thing in PostgreSQL, called lateral join, it allows for each element from the left table to perform a query in a loop once. It turns out, instead of joining huge tables, we make a simple selection and repeat this check on the backend of the database every time. The requests that are inside are quite easy, it turns out that instead of 40 thousand checks we do orders of magnitude less, they are all gone to the base, we don’t go there from the backend in a cycle.
Filtered, understand what pools are available to the user. Imagine that he presses the “Proceed” button. At this moment we have to reserve him some task, a page that he will see, and for which he will receive money.
Again, we check that this pool, in which this task is located, is still available to the user. After that we are looking for a ready page. If somewhere there is a prepared one that the user hasn’t done yet, we give it to him. If there is no such page, we prepare it again, we take tasks from several sources, mix them with each other and display them on the screen for the user.
At the same time we are making a financial transaction. We take money from the customer’s account and reserve it for this task.
If the user eventually completes the task, everything will be fine, the money will be transferred to his account. If he refuses the task or for some reason it is rejected, the money will be returned to the customer’s account.
This all happens in the transaction, precisely because we work with money here, and it is very important for us not to spend anything extra, not to give out the same thing twice to different people, if it is not necessary, and so on.
And this imposes such complexity on the not so simple business logic.
Imagine that many users see the same tasks and try to start them at the same time. It turns out that these people are competing for about the same tasks. It is important that they do not overflow each other in the database. Here is useful such a thing, which allows blocked lines to skip during select.

We turn to the part about technology.
I said a lot that we heavily use PostgreSQL. I want to tell you how we came to the point that we started using replicas, and what a thorny path was to this. Virtually any application that uses a database usually starts with the fact that all requests go to the master, replicas are used for fault tolerance. And on the backend some kind of connection pool is used, which allows to reuse these connections.


Use the service, the load on it begins to grow.

You increase the size of this connection pool. Then you start to watch what the CPU starts to run out of at the master, you start to optimize your requests, to watch what kind of long transactions there are, why the connections are allocated once more. We did the same.

At some point, pgbouncer was added, which allows you to have a pre-made pool of connections and not spend the processor on allocating new ones.
In a way, we twisted client settings, switched to the fast-running pool of connections hikari-cp.

In the end, it turned out that all these our optimizations did not lead to the desired effect, and the load, and the features that we constantly added, were superior to us, so at some fine moment we came to the conclusion that it was time to read from the replicas .

This is also an understandable simple task. Let's add a few more data sources; we will send those transactions that only data read, read only to them, and try to find a way to determine these read only transactions.
In Java, there is a method with a long name that should allow it to be determined at the time of the execution of transactions. But there are some features, for example, when using Spring JPA automatically generated queries, it did not work for us. Then we found these places and wrapped them in an auxiliary method, we force reading from the remarks in these places, let's do it, everything will be fine.
But here you can find a logical problem. It is that there are quite a few places in the code where you first create an entity, and then read it, start working with it, and this happens in different transactions. It turns out that the entity created on the master has not yet managed to get to the replica. And the code that works on, did not read anything.
Or another moment. The user in the UI, the customer, created a new pool of tasks, his page is drawn, and in fact it does not exist, because it was created on the master, and the reading started from replicas. We captured such places with various automatic tests, and the first thing that occurred to us, let us zakhachim and begin to forcefully read everything from the master.
We created a synonymous method, found everything, corrected it and realized that we were in an interesting situation, because we struggled to transfer the reading to cues, and we took almost all the complicated places anyway, we read nothing useful.
There is another way in PostgreSQL, there is a remote_apply flag, it says that we need to commit this transaction to another replica. She will not be committed until she passes on the master and on the cue.
In theory, it was possible to use it, but the peculiarity is that it works only for synchronous replicas. With asynchronous replicas, this flag does not work, but it is expensive to keep a bunch of synchronous replicas, the recording slows down a lot, we didn’t want to do that.
And they wanted something like this. Here is also a piece of code. We wanted to do some helper method, called it replicationBarrier, its essence is that in those places where we definitely have to wait for the data to reach the replicas, we insert this line of code and the application will not exit this method until until the data created in transactions to this place in this stream reach the replicas. It seems a convenient and simple method. Let's think about how it can be implemented.

In the 11th PostgreSQL - the 10th is being introduced into production - there will be a special WAIT FOR LSN command, where LSN is the lock sequence numbers. And we can read what position we are in the log, and wait for this position to be reached on the cue. While there is no 11th PostgreSQL, we cannot use it.
Another option is an auxiliary view in PostgreSQL, pg_stat_replication, it has all the diagnostic information on how replicas work. At the moment when we have conducted the transactions, let's measure at what position in the log we are in, and then through replay_location in this table on each replica check where we are. And if we are in the position that we need, or later, then we will get out of this barrier. , , , , - .
, , , , . replication_counter.
, , . , , , , . , , . , , . , , .
, . , , , .

- 2 , , , 32 . 1,5 . . - . 10 . , .
replication_counter - 200 , , 80 .
ping — .
, . — .
, , - . - , . , , . - , , .
, .

, . — , , . . , , , , , .
. , , , , , . , — , .
. , , , , . , . , , , . , . , .
. . , , , - .
. , .
, , — . , — , , — . . majority vote — , . , .

, , , . , , 15 . , . , .
. , -, , , . - . , , , , .
, , , , , . 40% .

. , - . , - ML Data Science . , , API , . — , - . , .
On the one hand, Toloka appeared relatively recently - in 2014. On the other hand, it serves as the most important part of all key Yandex services and dozens of smaller services. Artem Grigoriev ortemij explained how this crowdsourcing platform is arranged, what technologies and architectural solutions are used in its development. In addition, Artyom spoke about the logic of assigning tasks to users, working with geodata on the map and quality management.
- A few words about me. I have been working for Yandex at the St. Petersburg office for more than seven years. When I first came here, I was engaged in various tools to assess the quality of the search. We developed different metrics, compared ourselves with competitors and different versions of other search engines. Now I lead a service with a long name, like on a slide.
In short, we work in three main areas. First, we are developing our crowdsourcing Yandex.Tolok platform. Secondly, we develop various services for assessors. These are special people in Yandex like moderators. Support specialists, we make different services for them, content managers, etc.
')
And finally, we are developing an infrastructure that allows all Yandex teams to work with the listed people and the results of their work. This infrastructure connects what we do and what people do, for example, when developing a search.
The report will be about our crowdsourcing platform. First I want to clarify the concept of crowdsourcing. Do not confuse with the development of outsourcing or raising money through crowdfunding, this is slightly different.
Let's imagine that you are learning machine. For example, you want to train a classifier, and you have a data set that needs to be tagged and gain some knowledge. This data set can be represented as a number of tasks, write instructions on which tasks can be completed, and send to some people who will do this.
The essence of crowdsourcing is to break your work into some separate tasks, send it to the cloud of performers, and then take the result from there. There are several different crowdsourcing platforms in the world, and we are developing one of them.
Second question. I will explain the term Toloka. Many may say that I incorrectly pronounce this word. In Russian, the emphasis is on the second syllable, but we pay tribute to what this service was initially started in our Belarusian office, many guys came to answer your questions on the sidelines.
When we started to do this service and came up with the name, we remembered that there is such an interesting concept. The meaning of this word is that we are transported to ancient times. People in the village get together and do something for the benefit of society. Each of them, perhaps, could not have done this work, but they got together, went to harvest or build a barn for public use. Toloka is a custom to get together and help each other. We thought it was similar to the modern term of crowdsourcing, so this name was chosen for our service.
In general, Toloka and other crowdsourcing platforms operate on a simple principle: they connect customers and performers. Task platforms provide some budget for their implementation, and performers, while performing tasks, earn money and send results to customers.
The platform deals with the fact that it processes all payments, all interactions between the customer and the contractor, resolves various conflict situations, etc.
Almost all Yandex services use our platform. She is very popular.
I can cite several examples of tasks that are actually being placed on the platform now.
For example, tasks for a simple classification of photos. Or tasks for training unmanned vehicles. Maybe they saw a video where a Yandex car was driving along Khamovniki in Moscow, and the markup to train computer vision in this car was collected, including in Toloka.
Tasks for recognizing prices in photographs, etc. In principle, the basic is clear, the humanitarian introduction ends here.
If someone is interested in learning more about crowdsourcing, I spoke at the SmartData conference in the fall, you can find a video with that title on Youtube, it tells in more detail what crowdsourcing is and what features are interesting in it.
We are here to learn the internal, technical features of the work of our platform, so let's move on to this part.
Toloka is available in several forms. You can go to the toloka.yandex.ru website in the browser, complete tasks there. We also have mobile apps for iOS and for Android. They are used, in particular, for various tasks where mobility is required, people walk around the area and perform tasks “in the fields”, and where special phone features are needed, for example, a voice recorder or a camera.
Our backend is written mostly in Java.
We actively use SpringBoot and all its components. As a result, Toloka is presented as a set of microservices, each of which is deployed as a Docker container in our cloud system. We deploy to our inner cloud.
As storage, we use several different. The most basic business logic is made on PostgreSQL, because we work with money, it is very important for us to ensure transactions between customers and users. All the logic where this feature is critical, we have in PostgreSQL.
For those places where it is not needed, we use MongoDB. Many microservices that are built around Toloka use this storage. This is our internal implementation of MapReduce, similar to BigTable, in Yandex it is affectionately called YT .
In the development of Toloka there are several main areas in which we solve our problems. The subject area of crowdsourcing itself and the service itself is quite complex, so we have quite a lot of tasks to implement a variety of business logic. We actively use a variety of technologies, we use all sorts of optimizations, so this class of tasks is also quite large.
Finally, the subject area is quite interesting and dynamically developing, and there are quite a lot of research on this topic in the world, so we are also engaged in such research inside.
To lift the veil on what is happening inside, I will bring one task from each area, and try to tell something interesting, what is happening, on this topic.
Let's start with business logic.
The most important thing in the system is the selection of tasks by users. The first thing that sees a person who registers in Toloka is the main page, which shows a list of tasks available to him.
Let's try to figure out what is behind this. The page looks pretty simple, but in fact, behind every project that users see on the screen, there is a huge queue of tasks that customers upload there.
Customers usually form some task pools, sets of tasks available to a certain number of performers, and these tasks are loaded there in batches. We have a large queue, in which, on the one hand, customers fill in pools and new tasks, on the other hand, the performers come and ask what tasks are available to me, choose interesting ones for themselves, and then send the results there.
How does the list of available tasks work, the main page of Yandex.Toloki?
Firstly, we are looking for pools that are suitable for executors by filters. I will tell you more about this later, but not all tasks are available to everyone, so we must filter out those that show this user.
After that we check if the user is banned on this project. In the system, those performers who do not do well with the tasks, they are removed from them, and for various reasons, the user may be banned.
The important point is that we give the tasks not one by one, but the pages on which several tasks are shown at once, this is done to optimize the speed. We need to find those pools in which the user has enough tasks to display the page. And it is important that we don’t show the same tasks to the user a second time, he does everything once. After filtering all this, we group and display a page on the front end that a person sees.
The performer in our system is represented by several characteristics. There are computable fields, for example, the OS from which the user logs in, we can filter by this criterion. Or its IP address, region calculated by this IP, etc.
There are some data that the user entered about himself in the profile - gender, age, education. Customers can also filter users for these tasks using these profiles.
Another concept is skill. This is a kind of numerical characteristic that the customer can assign to the contractor on the outcome of the assignments on his projects. Usually it describes how well a person copes with this task. The user is represented as a long JSON in which all these characteristics are recorded.
On the other hand, we have some pools where filters are specified.
Suppose that in order to perform certain tasks, we need users who have indicated by phone number that they are located in Russia, Ukraine, Kazakhstan or Belarus, and some other restriction on skills. When a user comes to the page, we match this filter view on some pseudo language with the user’s JSON view that we have at the moment. The user's view may change, and the customer can also change the filters configured on the pool.
Previously, we compiled the JSquery filter view, such a plugin for the user. Now we have stopped doing this, because the filter view on JSquery is such a plugin for PostgreSQL. Now we have stopped doing this, because the memory on the backend itself was much faster in the memory.
We have filtered the pools, and we need to check that there are enough tasks in them that the user has not done yet to show him the full page. And we again return to the queues.
Each task pool is a task queue for a different number of users. She has some set of properties. First, these queues are dynamically created, deleted, and customers can also add new tasks to pools, so these queues can be supplemented with new elements.
Secondly, each task can be done by many performers. In this queue, there are many different customers for each job. And for the performers of the task should not be repeated, we should not pay a person twice for what he does. All these restrictions, coupled with the fact that there may be tens of thousands of such queues, are laid out in order to render the main page, which we are asked about 150 times per second, we need to do about 40 thousand checks that in this queue, in This task pool is available to the user. This is a difficult place, and we optimized it as follows - we transferred all these checks to the database.
Used such a thing in PostgreSQL, called lateral join, it allows for each element from the left table to perform a query in a loop once. It turns out, instead of joining huge tables, we make a simple selection and repeat this check on the backend of the database every time. The requests that are inside are quite easy, it turns out that instead of 40 thousand checks we do orders of magnitude less, they are all gone to the base, we don’t go there from the backend in a cycle.
Filtered, understand what pools are available to the user. Imagine that he presses the “Proceed” button. At this moment we have to reserve him some task, a page that he will see, and for which he will receive money.
Again, we check that this pool, in which this task is located, is still available to the user. After that we are looking for a ready page. If somewhere there is a prepared one that the user hasn’t done yet, we give it to him. If there is no such page, we prepare it again, we take tasks from several sources, mix them with each other and display them on the screen for the user.
At the same time we are making a financial transaction. We take money from the customer’s account and reserve it for this task.
If the user eventually completes the task, everything will be fine, the money will be transferred to his account. If he refuses the task or for some reason it is rejected, the money will be returned to the customer’s account.
This all happens in the transaction, precisely because we work with money here, and it is very important for us not to spend anything extra, not to give out the same thing twice to different people, if it is not necessary, and so on.
And this imposes such complexity on the not so simple business logic.
Imagine that many users see the same tasks and try to start them at the same time. It turns out that these people are competing for about the same tasks. It is important that they do not overflow each other in the database. Here is useful such a thing, which allows blocked lines to skip during select.
We turn to the part about technology.
I said a lot that we heavily use PostgreSQL. I want to tell you how we came to the point that we started using replicas, and what a thorny path was to this. Virtually any application that uses a database usually starts with the fact that all requests go to the master, replicas are used for fault tolerance. And on the backend some kind of connection pool is used, which allows to reuse these connections.
Use the service, the load on it begins to grow.
You increase the size of this connection pool. Then you start to watch what the CPU starts to run out of at the master, you start to optimize your requests, to watch what kind of long transactions there are, why the connections are allocated once more. We did the same.
At some point, pgbouncer was added, which allows you to have a pre-made pool of connections and not spend the processor on allocating new ones.
In a way, we twisted client settings, switched to the fast-running pool of connections hikari-cp.
In the end, it turned out that all these our optimizations did not lead to the desired effect, and the load, and the features that we constantly added, were superior to us, so at some fine moment we came to the conclusion that it was time to read from the replicas .
This is also an understandable simple task. Let's add a few more data sources; we will send those transactions that only data read, read only to them, and try to find a way to determine these read only transactions.
In Java, there is a method with a long name that should allow it to be determined at the time of the execution of transactions. But there are some features, for example, when using Spring JPA automatically generated queries, it did not work for us. Then we found these places and wrapped them in an auxiliary method, we force reading from the remarks in these places, let's do it, everything will be fine.
But here you can find a logical problem. It is that there are quite a few places in the code where you first create an entity, and then read it, start working with it, and this happens in different transactions. It turns out that the entity created on the master has not yet managed to get to the replica. And the code that works on, did not read anything.
Or another moment. The user in the UI, the customer, created a new pool of tasks, his page is drawn, and in fact it does not exist, because it was created on the master, and the reading started from replicas. We captured such places with various automatic tests, and the first thing that occurred to us, let us zakhachim and begin to forcefully read everything from the master.
We created a synonymous method, found everything, corrected it and realized that we were in an interesting situation, because we struggled to transfer the reading to cues, and we took almost all the complicated places anyway, we read nothing useful.
There is another way in PostgreSQL, there is a remote_apply flag, it says that we need to commit this transaction to another replica. She will not be committed until she passes on the master and on the cue.
In theory, it was possible to use it, but the peculiarity is that it works only for synchronous replicas. With asynchronous replicas, this flag does not work, but it is expensive to keep a bunch of synchronous replicas, the recording slows down a lot, we didn’t want to do that.
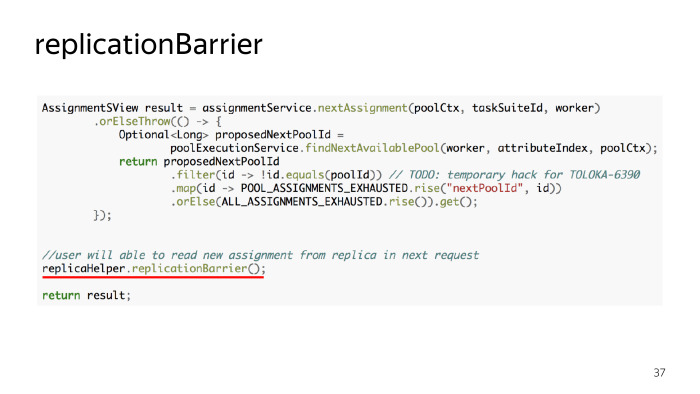
And they wanted something like this. Here is also a piece of code. We wanted to do some helper method, called it replicationBarrier, its essence is that in those places where we definitely have to wait for the data to reach the replicas, we insert this line of code and the application will not exit this method until until the data created in transactions to this place in this stream reach the replicas. It seems a convenient and simple method. Let's think about how it can be implemented.
In the 11th PostgreSQL - the 10th is being introduced into production - there will be a special WAIT FOR LSN command, where LSN is the lock sequence numbers. And we can read what position we are in the log, and wait for this position to be reached on the cue. While there is no 11th PostgreSQL, we cannot use it.
Another option is an auxiliary view in PostgreSQL, pg_stat_replication, it has all the diagnostic information on how replicas work. At the moment when we have conducted the transactions, let's measure at what position in the log we are in, and then through replay_location in this table on each replica check where we are. And if we are in the position that we need, or later, then we will get out of this barrier. , , , , - .
, , , , . replication_counter.
, , . , , , , . , , . , , . , , .
, . , , , .
- 2 , , , 32 . 1,5 . . - . 10 . , .
replication_counter - 200 , , 80 .
ping — .
, . — .
, , - . - , . , , . - , , .
, .
, . — , , . . , , , , , .
. , , , , , . , — , .
. , , , , . , . , , , . , . , .
. . , , , - .
. , .
, , — . , — , , — . . majority vote — , . , .
, , , . , , 15 . , . , .
. , -, , , . - . , , , , .
, , , , , . 40% .
. , - . , - ML Data Science . , , API , . — , - . , .
Source: https://habr.com/ru/post/358462/
All Articles