How not to miss a single message
Event handling is one of the most common tasks in the field of serverless technologies. Today we will talk about how to create a reliable message handler that will reduce their loss to zero. By the way, the examples are written in C # using the Polly library, but the approaches shown will work with any languages (unless otherwise indicated).

I give the word to the author .
')
A few weeks ago, I published an article on how to handle events in order using Functions . In today's publication, I will explain in general how to create a reliable message handler that will reduce their loss to zero. This article could be divided into two or three parts, but I decided to combine all the information in one material. It turned out to be big, but it covers a wide range of tasks: from simple to the most complex, such as using circuit breaker patterns and exception filters. Examples are written in C #, but the approaches shown will work with any languages (unless otherwise indicated).
Imagine a system that sends events at a constant rate — for example, 100 pieces per second. Setting up the reception of these events in Azure Functions is quite simple. In just a few minutes, you can prepare many parallel instances that will handle these 100 events per second. But what if the publisher sends an incorrectly formed event? What if one of your copies fails due to a failure? Or will one of the systems go through the next processing steps? How to cope with such situations, while maintaining the overall integrity and throughput of your application?
Ensuring the reliability of message processing when using queues is a little easier. In Azure Functions, when processing a message from a queue, a function can “block” such a message, try to process it, and in case of failure, release the lock so that another instance can accept it and try again. These attempts continue until the message is successfully processed or until the maximum allowable number of attempts is reached (4 by default). In the second case, the message is added to the queue of suspicious messages. When a message from the queue goes through this cycle of attempts, parallel retrieval of other messages from the queue does not stop. Therefore, one error almost does not affect the overall throughput. However, storage queues do not guarantee order and are not optimized to provide high bandwidth services (such as event hubs).
In event streams (for example, in Azure Event Hubs), locks are not used. These services are designed to provide high bandwidth, support multiple consumer groups and the ability to play. When receiving events, they work like a tape drive. Each section in the stream has one offset pointer. You can read events in both directions. Suppose an error occurs while reading the event stream, and you decide to leave the pointer in the same place. Until it moves, further data processing from this section will not be possible. In other words, if the system still receives 100 events per second, but Azure Functions stopped moving the pointer to new events, trying to cope with incorrect, then a congestion will happen. Very quickly you will have a huge amount of unprocessed events that will constantly grow.

Handle exceptions, but do not delay the queue.
This behavior of the offset pointer and consumers was taken into account: Functions will move the pointer downstream regardless of whether the processing was successful . This means that your system and your functions should be able to handle such situations.
Azure Functions interact with the event hub as follows:
Here you should pay attention to a few things. First: if you do not handle exceptions, you may lose messages , because even if the execution was completed with an exception, the pointer will be shifted. Second: Functions guarantee at least one-time delivery (this is a common situation in distributed systems). This means that your code and its dependent systems should work correctly in situations where the same message was received twice. The following are examples of these two situations and the code that allows you to deal with them.
As part of these tests, I published 100 thousand messages for sequential processing (per section key). To test and visualize order and reliability, I will log each message as it is processed in the Redis cache. In the first test, every hundredth message generates an exception, and exception handling is not performed.
After sending 100 thousand messages to this system, Redis showed the following:
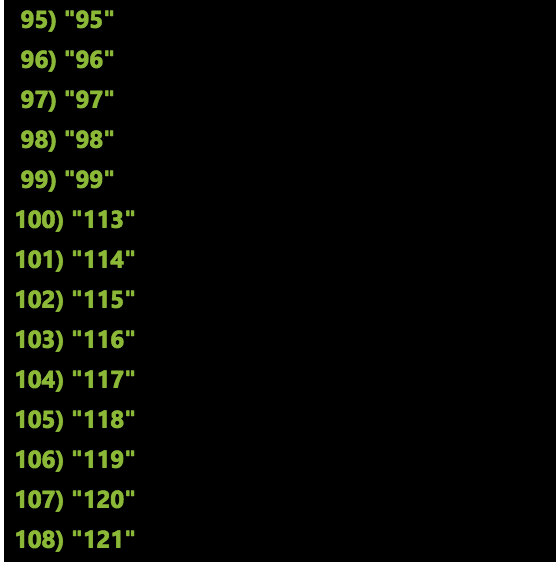
As you can see, I missed the whole chain of messages from the 100th to the 112th. What happened? At some point, one of the instances of my functions received a batch of messages for this partition key. This particular packet ended on the 112th message, but an exception was thrown on the cell. Execution was stopped, but the function node continued and counted the next packet. Technically, these messages are stored in event hubs, but in order to process them again, I need to manually request messages from the 100th to the 112th.
The easiest way to solve this problem is to add a try / catch block to the code. Now, in the case of an exception, I can process it in the same process before the pointer moves on. After adding a catch block to the above code and restarting the test, all 100,000 messages appeared in the correct order.
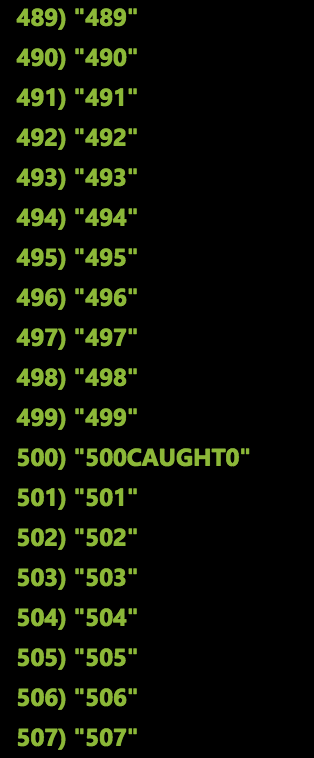
Recommendation: all functions of the event hub should have a catch block.
In this example, I used a catch block to make an additional attempt to insert data into Redis, but it is easy for him to find other reasonable uses: for example, sending a notification or placing a message in a suspicious queue or in an event hub for further processing.
Some exceptions may occur only from time to time. Sometimes for the correct execution of the operation it is enough just to repeat it. In the catch block in the code from the previous section, one retry was performed, but if it failed or resulted in an exception, I would still lose messages 100-112. There are many tools that allow you to configure more flexible retry policies with preserving the order of processing.
For testing, I used the C # error-handling library called Polly . She allowed me to set up both simple and advanced retry policies. Example: “try to insert this message three times (possibly with a delay between attempts). If all attempts were unsuccessful, add the message to the queue so that I can continue processing the events, and return to the raw or incorrect message later. ”
In this code, I add a message to the Redis cache using a fragment that creates an entry.
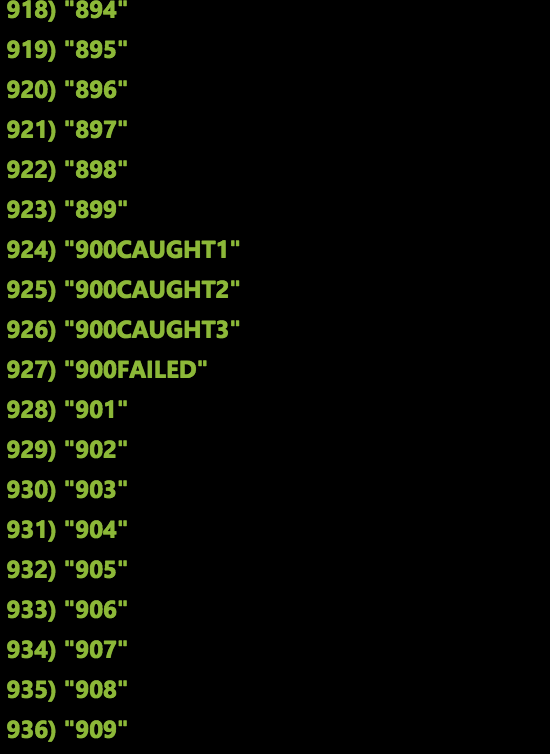
Redis final state:
When working with more advanced interception exception and retry policies, it should be borne in mind that for precompiled C # class libraries, an evaluation version is available that allows you to set "exception filters" for your function. With it, you can write a method that will be executed when an unhandled exception is generated while the function is running. More information and examples are available in this publication .
We have considered the case of generating exceptions in your code. But what if the function instance encounters an interruption in the process?

As we have already said, if Function does not complete execution, then the offset pointer does not move further, which means that when trying to receive messages, new instances will receive the same data. To simulate such a situation, I manually stopped, launched and restarted my application function during the processing of 100 thousand messages. On the left you can see some of the results. Please note: all events were processed, everything is in order, but some messages were processed several times (after the 700th, the 601th and subsequent ones were reprocessed). In general, this is good, since this behavior ensures at least one-time delivery, but this means that my code must be idempotent to a certain extent.
The above patterns and patterns of behavior are convenient for the implementation of repeated attempts and help make every effort to handle events. A certain level of failures is acceptable in many cases. But let's imagine that there are a lot of errors, and I want to stop the triggering on new events until the restoration of system performance. This can be achieved by using a circuit breaker pattern - an element that allows you to stop the event processing circuit and resume operation later.
Polly (the library with which I implemented retries) supports some of the circuit breaker capabilities. However, these templates are not very suitable for use in the case of distributed temporal functions, when a chain spans several instances without state tracking. There are several interesting approaches to solving this problem with Polly, but for now I’ll add the necessary functions manually. To implement a circuit breaker for event processing, two components are needed:
I used the Redis cache as the first component, and the second was the Azure logic apps. Both of these roles can perform many other services, but I liked these two.
Several instances can process events in parallel, therefore, to monitor the health of the chain, I need a general external state. I wanted to implement the following rule: “If, within 30 seconds, more than 100 errors were recorded for all instances in total, open the circuit and terminate operation on new messages.”
I used the TTL tracking options available on Redis and sorted sets to get a sliding interval that records the number of errors in the last 30 seconds. (If you are interested in the details, all these examples are available on GitHub .) When a new error appeared, I turned to a sliding interval. If the allowed number of errors (more than 100 in the last 30 seconds) was exceeded, I sent the event to the Azure Event Grid service. The corresponding Redis code is available here . So I could detect problems, send an event and open the circuit.
I used the Azure logic applications to manage the state of the circuit, since connectors and stateful orchestration perfectly complement each other. When the open circuit condition was triggered, I initiated a workflow (trigger for the Azure Event Grid service). The first step is to stop Azure Functions (using the Azure Resource Connector) and send a notification email and response options. After that, I can check the operation of the circuit and run it again, if everything is in order. As a result, the workflow will be resumed, the function will be started, and message processing will continue from the last checkpoint of the event hub.
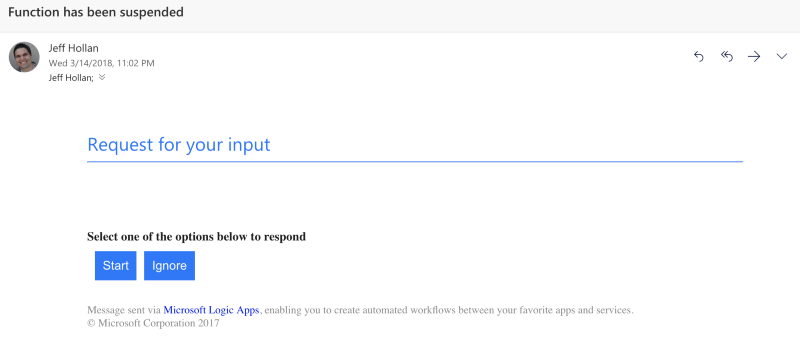
The email I received from the logic applications after stopping the function. I can press any button and resume operation of the circuit when required.
About 15 minutes ago, I sent 100 thousand messages and set up the system so that every hundredth message would lead to an error. After approximately 5,000 messages, the allowed threshold was exceeded, and the event was sent to the Azure Event Grid service. My Azure logic application immediately worked, stopped the function and sent me an email (shown above). If you look at the contents of Redis, we will see a lot of partially processed sections:
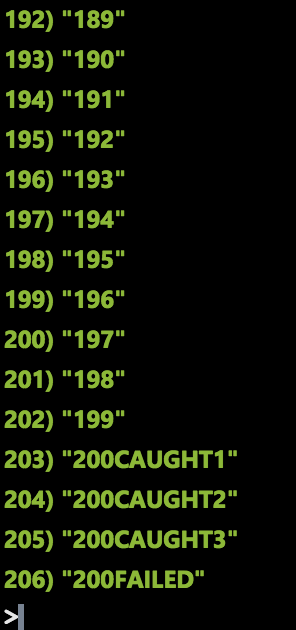
The lower part of the list is the processing of the first 200 messages for this section key, after which logic applications stopped the system.
I clicked the link in the email to resume the chain. After completing the same query in Redis, you can see that the function continued its work from the last checkpoint of the event hub. Not a single message was lost, everything was processed in a strict order, and it turned out to keep the circuit open for as long as required - the state was controlled by my logic application.

Seventeen minute delay before re-closure command.
Hopefully this post has helped you learn more about the techniques and patterns for reliably processing message flows using Azure Functions. This knowledge will allow you to take advantage of the features (in particular, their dynamic scaling and payment as resources are consumed) without compromising the reliability of the solution.
Follow the link to find the GitHub repository with pointers to each of the branches for the various reference points of this example. If you have any questions, contact me via Twitter: @jeffhollan.
I give the word to the author .
')
Reliable event handling with Azure Functions
A few weeks ago, I published an article on how to handle events in order using Functions . In today's publication, I will explain in general how to create a reliable message handler that will reduce their loss to zero. This article could be divided into two or three parts, but I decided to combine all the information in one material. It turned out to be big, but it covers a wide range of tasks: from simple to the most complex, such as using circuit breaker patterns and exception filters. Examples are written in C #, but the approaches shown will work with any languages (unless otherwise indicated).
Problems related to event flows in distributed systems
Imagine a system that sends events at a constant rate — for example, 100 pieces per second. Setting up the reception of these events in Azure Functions is quite simple. In just a few minutes, you can prepare many parallel instances that will handle these 100 events per second. But what if the publisher sends an incorrectly formed event? What if one of your copies fails due to a failure? Or will one of the systems go through the next processing steps? How to cope with such situations, while maintaining the overall integrity and throughput of your application?
Ensuring the reliability of message processing when using queues is a little easier. In Azure Functions, when processing a message from a queue, a function can “block” such a message, try to process it, and in case of failure, release the lock so that another instance can accept it and try again. These attempts continue until the message is successfully processed or until the maximum allowable number of attempts is reached (4 by default). In the second case, the message is added to the queue of suspicious messages. When a message from the queue goes through this cycle of attempts, parallel retrieval of other messages from the queue does not stop. Therefore, one error almost does not affect the overall throughput. However, storage queues do not guarantee order and are not optimized to provide high bandwidth services (such as event hubs).
In event streams (for example, in Azure Event Hubs), locks are not used. These services are designed to provide high bandwidth, support multiple consumer groups and the ability to play. When receiving events, they work like a tape drive. Each section in the stream has one offset pointer. You can read events in both directions. Suppose an error occurs while reading the event stream, and you decide to leave the pointer in the same place. Until it moves, further data processing from this section will not be possible. In other words, if the system still receives 100 events per second, but Azure Functions stopped moving the pointer to new events, trying to cope with incorrect, then a congestion will happen. Very quickly you will have a huge amount of unprocessed events that will constantly grow.
Handle exceptions, but do not delay the queue.
This behavior of the offset pointer and consumers was taken into account: Functions will move the pointer downstream regardless of whether the processing was successful . This means that your system and your functions should be able to handle such situations.
How Azure Functions Receive Events from an Event Hub
Azure Functions interact with the event hub as follows:
- For each partition in the event hub, a pointer is created (and placed in the Azure storage) (you can see it in the storage account).
- When receiving new messages of the event concentrator (by default, it is executed in batch mode), the node will try to start the function by passing a batch of messages to it.
- When the function completes (no matter with exceptions or not), the pointer moves on and its position is stored in the repository.
- If something prevents the function from completing, the node will not be able to move the pointer, and subsequent checks will receive the same messages (from the previous checkpoint).
- Stages 2–4 are repeated.
Here you should pay attention to a few things. First: if you do not handle exceptions, you may lose messages , because even if the execution was completed with an exception, the pointer will be shifted. Second: Functions guarantee at least one-time delivery (this is a common situation in distributed systems). This means that your code and its dependent systems should work correctly in situations where the same message was received twice. The following are examples of these two situations and the code that allows you to deal with them.
As part of these tests, I published 100 thousand messages for sequential processing (per section key). To test and visualize order and reliability, I will log each message as it is processed in the Redis cache. In the first test, every hundredth message generates an exception, and exception handling is not performed.
[FunctionName("EventHubTrigger")] public static async Task RunAsync([EventHubTrigger("events", Connection = "EventHub")] EventData[] eventDataSet, TraceWriter log) { log.Info($"Triggered batch of size {eventDataSet.Length}"); foreach (var eventData in eventDataSet) { // For every 100th message, throw an exception if (int.Parse((string)eventData.Properties["counter"]) % 100 == 0) { throw new SystemException("Some exception"); } // Insert the current count into Redis await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"]); } } After sending 100 thousand messages to this system, Redis showed the following:
As you can see, I missed the whole chain of messages from the 100th to the 112th. What happened? At some point, one of the instances of my functions received a batch of messages for this partition key. This particular packet ended on the 112th message, but an exception was thrown on the cell. Execution was stopped, but the function node continued and counted the next packet. Technically, these messages are stored in event hubs, but in order to process them again, I need to manually request messages from the 100th to the 112th.
Add try-catch block
The easiest way to solve this problem is to add a try / catch block to the code. Now, in the case of an exception, I can process it in the same process before the pointer moves on. After adding a catch block to the above code and restarting the test, all 100,000 messages appeared in the correct order.
Recommendation: all functions of the event hub should have a catch block.
In this example, I used a catch block to make an additional attempt to insert data into Redis, but it is easy for him to find other reasonable uses: for example, sending a notification or placing a message in a suspicious queue or in an event hub for further processing.
Retry mechanisms and policies
Some exceptions may occur only from time to time. Sometimes for the correct execution of the operation it is enough just to repeat it. In the catch block in the code from the previous section, one retry was performed, but if it failed or resulted in an exception, I would still lose messages 100-112. There are many tools that allow you to configure more flexible retry policies with preserving the order of processing.
For testing, I used the C # error-handling library called Polly . She allowed me to set up both simple and advanced retry policies. Example: “try to insert this message three times (possibly with a delay between attempts). If all attempts were unsuccessful, add the message to the queue so that I can continue processing the events, and return to the raw or incorrect message later. ”
foreach (var eventData in eventDataSet) { var result = await Policy .Handle<Exception>() .RetryAsync(3, onRetryAsync: async (exception, retryCount, context) => { await db.ListRightPushAsync("events:" + context["partitionKey"], (string)context["counter"] + $"CAUGHT{retryCount}"); }) .ExecuteAndCaptureAsync(async () => { if (int.Parse((string)eventData.Properties["counter"]) % 100 == 0) { throw new SystemException("Some Exception"); } await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"]); }, new Dictionary<string, object>() { { "partitionKey", eventData.Properties["partitionKey"] }, { "counter", eventData.Properties["counter"] } }); if(result.Outcome == OutcomeType.Failure) { await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"] + "FAILED"); await queue.AddAsync(Encoding.UTF8.GetString(eventData.Body.Array)); await queue.FlushAsync(); } } In this code, I add a message to the Redis cache using a fragment that creates an entry.
Redis final state:
When working with more advanced interception exception and retry policies, it should be borne in mind that for precompiled C # class libraries, an evaluation version is available that allows you to set "exception filters" for your function. With it, you can write a method that will be executed when an unhandled exception is generated while the function is running. More information and examples are available in this publication .
Errors and problems that are not exceptions
We have considered the case of generating exceptions in your code. But what if the function instance encounters an interruption in the process?
As we have already said, if Function does not complete execution, then the offset pointer does not move further, which means that when trying to receive messages, new instances will receive the same data. To simulate such a situation, I manually stopped, launched and restarted my application function during the processing of 100 thousand messages. On the left you can see some of the results. Please note: all events were processed, everything is in order, but some messages were processed several times (after the 700th, the 601th and subsequent ones were reprocessed). In general, this is good, since this behavior ensures at least one-time delivery, but this means that my code must be idempotent to a certain extent.
Circuit Breaker and Conveyor Stop
The above patterns and patterns of behavior are convenient for the implementation of repeated attempts and help make every effort to handle events. A certain level of failures is acceptable in many cases. But let's imagine that there are a lot of errors, and I want to stop the triggering on new events until the restoration of system performance. This can be achieved by using a circuit breaker pattern - an element that allows you to stop the event processing circuit and resume operation later.
Polly (the library with which I implemented retries) supports some of the circuit breaker capabilities. However, these templates are not very suitable for use in the case of distributed temporal functions, when a chain spans several instances without state tracking. There are several interesting approaches to solving this problem with Polly, but for now I’ll add the necessary functions manually. To implement a circuit breaker for event processing, two components are needed:
- Common to all instances of the state for monitoring and monitoring the health of the chain.
- The main process that is able to manage the state of the circuit (open or close it).
I used the Redis cache as the first component, and the second was the Azure logic apps. Both of these roles can perform many other services, but I liked these two.
Maximum allowable number of errors for all instances
Several instances can process events in parallel, therefore, to monitor the health of the chain, I need a general external state. I wanted to implement the following rule: “If, within 30 seconds, more than 100 errors were recorded for all instances in total, open the circuit and terminate operation on new messages.”
I used the TTL tracking options available on Redis and sorted sets to get a sliding interval that records the number of errors in the last 30 seconds. (If you are interested in the details, all these examples are available on GitHub .) When a new error appeared, I turned to a sliding interval. If the allowed number of errors (more than 100 in the last 30 seconds) was exceeded, I sent the event to the Azure Event Grid service. The corresponding Redis code is available here . So I could detect problems, send an event and open the circuit.
Circuit Status Management with Logic Applications
I used the Azure logic applications to manage the state of the circuit, since connectors and stateful orchestration perfectly complement each other. When the open circuit condition was triggered, I initiated a workflow (trigger for the Azure Event Grid service). The first step is to stop Azure Functions (using the Azure Resource Connector) and send a notification email and response options. After that, I can check the operation of the circuit and run it again, if everything is in order. As a result, the workflow will be resumed, the function will be started, and message processing will continue from the last checkpoint of the event hub.
The email I received from the logic applications after stopping the function. I can press any button and resume operation of the circuit when required.
About 15 minutes ago, I sent 100 thousand messages and set up the system so that every hundredth message would lead to an error. After approximately 5,000 messages, the allowed threshold was exceeded, and the event was sent to the Azure Event Grid service. My Azure logic application immediately worked, stopped the function and sent me an email (shown above). If you look at the contents of Redis, we will see a lot of partially processed sections:
The lower part of the list is the processing of the first 200 messages for this section key, after which logic applications stopped the system.
I clicked the link in the email to resume the chain. After completing the same query in Redis, you can see that the function continued its work from the last checkpoint of the event hub. Not a single message was lost, everything was processed in a strict order, and it turned out to keep the circuit open for as long as required - the state was controlled by my logic application.
Seventeen minute delay before re-closure command.
Hopefully this post has helped you learn more about the techniques and patterns for reliably processing message flows using Azure Functions. This knowledge will allow you to take advantage of the features (in particular, their dynamic scaling and payment as resources are consumed) without compromising the reliability of the solution.
Follow the link to find the GitHub repository with pointers to each of the branches for the various reference points of this example. If you have any questions, contact me via Twitter: @jeffhollan.
Source: https://habr.com/ru/post/358438/
All Articles