How we organized data storage cheaper than Amazon Simple Storage Service by 35%

We have a set of storage systems, both traditional and programmatically defined. They are used in block storage format for storing virtual machines, databases, and other resources.
At the second stage, we began to use object storage, that is, storage without a hierarchy of directories. All data is at the same level, and each file can be accessed by its own key. Metadata is stored next to the file. For access, simple commands of the PUT - GET - MODIFY level are used, it is possible to access each file by its own URI, ease of rights management and ease of placement of various data and access to them are provided.
')
The minus of these solutions is the impossibility of accessing a part (segment) of a file; therefore, for applications like databases, such storages are not used. The best use is to put the website’s pictures, file bin, archives or data backups there. On the basis of object storage, we built our S3 - a storage system for not very often variable data. Directly compatible with Amazon S3.
And the classic access protocols used inside companies for file access (CIFS or NFS) are not intended for exchanging big data over the Internet. This is another reason why and why we created our object storage.
The task was to make it not just working from everywhere, but also cheap.
How did it start
When customers began to massively migrate from Western cloud providers to Russia, Amazon API compatibility was very much in demand. In particular, for data storage. For many, the application software was written to work with object storages and used their versatility, that is, it worked with files as files and didn’t really bother where they come from or where they are from. Naturally, nobody rushed to rewrite their software because of the new cloud provider. Therefore, an object storage system was needed.
The process of developing a portfolio of services can be compared to building a house. First, the foundation is laid, which is necessary for a solid foundation and the subsequent construction of rooms, floors, a balcony, a garage, etc. The service portfolio is also being formed gradually. With the advent of new services, more and more questions arose about the organization of storage. Customers asked:
- We have reporting kept for years. Can I think of something to keep it cheaper?
- We use write-only-backup. In the sense of five years it has never been used. Can it be stored cheaper?
- Is it possible to backup automatically, but it will not be stored in the general storage?
- Can you just store data? And then we have a photo bank for marketing, which ...
And the internal question was whether a horizontally scalable platform could be made. For the solution, we made a separate storage, which is focused on low cost of storage, access to data both from inside the Technoserv cloud and via the Internet. Another solution has an access interface, already accepted by the market, which has support in the products used by our customers. Read - S3. Because there were real requests.
Native S3 compatibility
Object storage is a non-hierarchical data storage method commonly used in the cloud environment. Unlike other data storage methods, object storage does not use a directory hierarchy. Separate data units (objects) coexist in the data pool at the same level. Each object has a unique identifier used by the application to access it. In addition, each object may contain metadata, obtained with it.
Both open-sourced and commercial solutions were considered. In total, six and a half solutions were tested (stand and tested the main functions). In the end, chose Cloudian HyperStore. That's why.
- Manufacturer guaranteed 100% compatibility with Amazon S3 API protocol. Cloudian ensures that HyperStore is 100% compatible with the Amazon S3 API, and this allows our customers who have previously used Amazon’s storage services or have S3-enabled solutions to use our service without any modifications or software adjustments.

- Scaling. HyperStore allows you to create a decentralized cloud storage platform with the ability to granularly manage various policies, such as reporting and administration. The solution can scale to thousands of nodes and billions of objects in one basket and can be flexibly scaled to the required number of petabytes in the shortest possible time.
- Security and encryption. HyperStore allows you to encrypt data during transmission and storage. There are functions for setting access rights and logging of all file operations, as well as the ability to encrypt data on the storage side with a client key.
- Isolated domain support (MULTI-TENANCY). It is necessary to transfer resource management to the customer, because it increases the speed of execution of basic operations (for example, start a new user, estimate the amount of resources consumed, etc.) and reduces the load on the operational service, which does not need to be distracted by simple operations. The initial support of isolated domains in the product allows for the secure sharing of resources among customers and ensures that users cannot interfere with other customers by their actions. I mean, we don’t have to put crutches in the code, and that's fine.
- Service Level Management (QoS). For some clients, it is required to allocate a guaranteed band or workflow to comply with the work of their services, and someone, on the contrary, has no requirements, and even a non-optimized service is very “hungry” and will “eat” as much as it can receive.
- Dynamic redundancy using Replica and ERASURE CODING. HyperStore supports multiple levels of redundancy using Replica and Erasure Coding (EC).
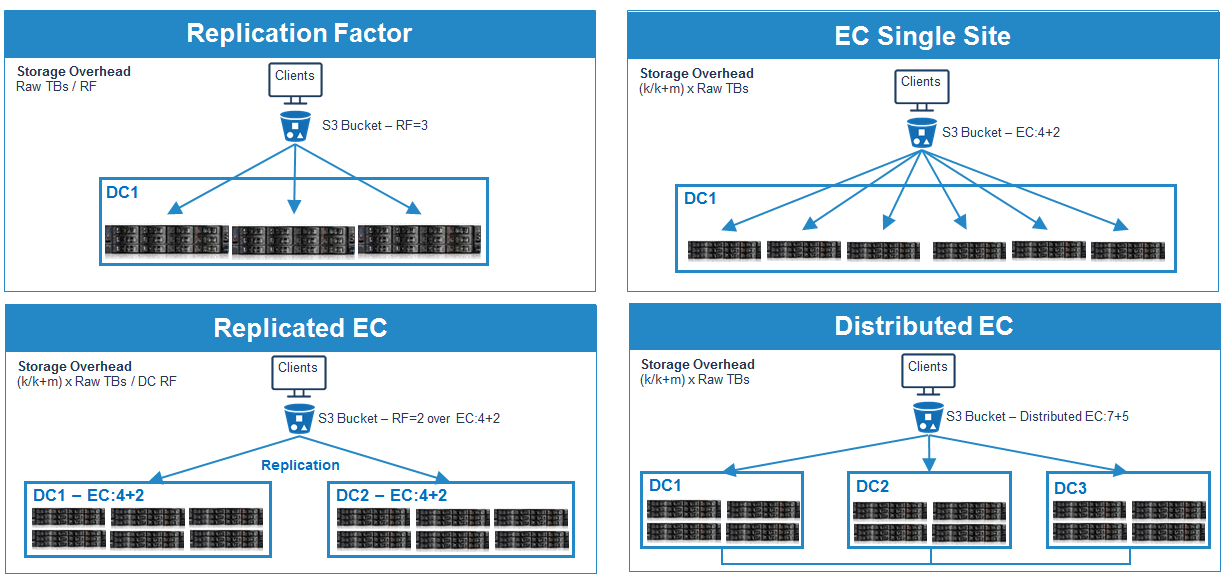
The number of replicas is set independently and can reach three. The EU allows you to set the level of redundancy in a fairly wide range and further regulate the required level of reliability.
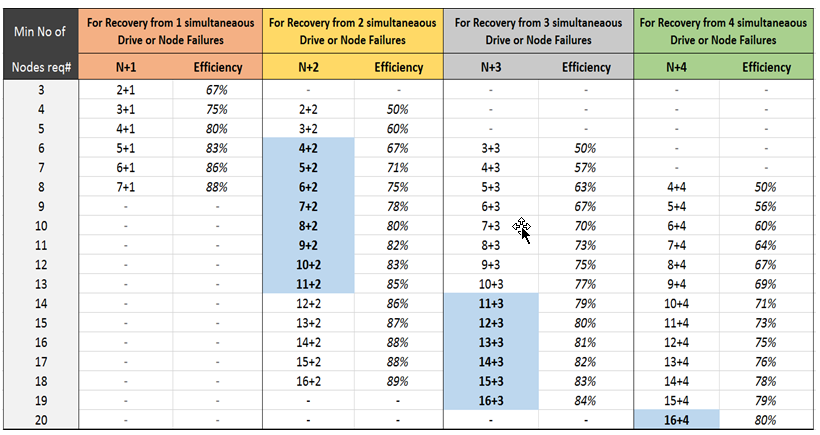
The level of protection is set granularly, that is, on a specific data segment, there is no limit to the need to select a unified protection policy for the entire system. The default reservation policy for our system is 5 + 3, which is related to the current configuration of our platform.
Granularity protection is very convenient for use. For example, we have a customer who places tens of millions of very small files (literally 10–30 KB each); in the case of using the EU, we faced a big increase in meta-information and subsidence of some operations for this data. Translation protection using copies allowed to correct the situation and reduce the overall load on the system (in part of the operations of the customer).
And what about the cost?
Below Amazon, starting with a certain amount of consumption. That is, for medium and large businesses, it is more profitable than Western solutions.
The platform has become the base for some of our services. It exists as a standalone service for external STaaS customers (Storage as a Service, for example, hosting archives, copies or content for Internet sites), as a basic storage for internal long-term archives and cold data, as backup storage for BaaS services (Backup as a Service). The BaaS configuration and interaction formats with object storage are worth a separate story, if you are interested, I can tell you the details.
The current platform configuration consists of eight Dell R730xd storage servers and two HAproxy based balance servers. Servers have the following characteristics:
- 2 processors E5-2620 v4 (8 cores, 2.1 GHz);
- 128 GB of RAM;
- Intel X520 2 ports 10 Gbps NIC (Ethernet) adapter;
- NIC adapter (Ethernet) Broadcom 5720 4 ports 1 Gbps;
- 12 SATA 8 TB hard drives;
- 2 SSD 480 GB.
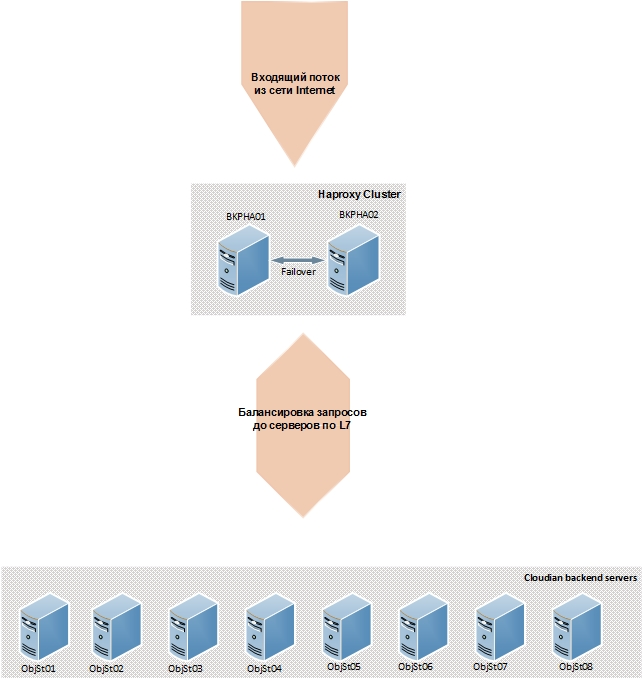
This configuration allows you to provide up to 20 Gbps (based on load testing) data flow and has the ability to increase performance by scaling.
Now there are two main tariffs corresponding to the options provided by the repository. The basic options are Hot Access and Cold Access. The “Hot Access” tariff for storing files to be accessed frequently, as well as a large number of small files (<500 Kbytes). If you select this tariff, the “Replica 3” storage policy will be used for storing files, that is, storing files in three copies. In the system (service control panels) it is denoted as R3.
In contrast to the previous tariff, “Cold access”, on the contrary, is intended for storing files that do not require frequent access. As a rule, these are backup copies. When selecting data for storing files, the “Erasure Coding 5 + 3” storage policy is used, that is, any file is encoded into eight parts to different servers, and any five parts are enough to read the file.
That is, one data set is stored in eight different places and any three of these places can be lost.
When using the “Cloud Object Storage” service, payment can be made via the Pay as you go system - in this case, payment is made only for the resources actually consumed according to the selected tariff. Another option to provide the service is in the fixed volume system. With this scheme of use, the user is provided with a strictly fixed amount of disk space, which he pays according to the selected tariff.
A little about the prices themselves:
Name | Price per unit, with VAT, rub./mon. |
|---|---|
Tariff “Frequent access” | |
| Information storage, GB | 1.65 |
| Downloading information per GB | 2.36 |
| Requests PUT / POST, a package of 10 000 pieces. | 3.54 |
| GET / HEAD requests, a package of 10,000 pcs. | 0.28 |
Rare Access Tariff | |
| Information storage, GB | 1.06 |
| Downloading information per GB | 7.38 |
| Requests PUT / POST, a package of 10 000 pieces. | 7.08 |
| GET / HEAD requests, a package of 10,000 pcs. | 0.71 |
Important! In the near future it is planned to revise the tariff scale in the direction of reducing the cost.
Finally, we came close to comparing the tariffs of Amazon and Technoserv for the case when the client plans to use Cloud Storage to store site content. In this case, it is more expedient to use the “Frequent Access” tariffs from Technoserv and S3 Standard Storage from Amazon (East USA, Northern Virginia).
| Name | Technoserv | Amazon |
|---|---|---|
| Tariff “Frequent access” | Amazon standard | |
| The cost of storing 1 GB of information | 1.65 | 1.45 |
| The cost of downloading 1 GB of information | 2.36 | 5.36 |
| The cost of the package requests put, 10 000 pcs. | 3.54 | 3.15 |
| The cost of a package of get requests, 10,000 pcs. | 0.28 | 0.2 |
| Name | Qty | Technoserv | Amazon |
| Tariff “Frequent access” | Amazon standard | ||
| The volume of information stored per month, GB | 100,000 | 165,000 | 144 900 |
| Volume of information downloaded per month, GB | 40,000 | 94 400 | 214,200 |
| Number of PUT requests per month, pcs. | 50,000,000 | 17 700.00 | 15 750,00 |
| Number of GET requests per month, pcs. | 40,000,000 | 1 120.00 | 1 008.00 |
| Cost per month | 278 220 | 375 858 | |
It is important that object storage is presented not only on the cloud, but also to provide files outside. In particular, this is important when you need a thick pipe through the Internet - now we cannot use classic corporate protocols (CIFS or NFS) via the Internet, because it turns into a chain of converter gates and slows down incredibly, especially when it comes to encrypted VPN. All this is almost perfect with object repositories. Actually, as a result, we patch the Internet - we use object protocols for the exchange. When you need classic file access, you can install a small client that implements the CIFS or NFS protocols and then presents the data within the company.
Of course, with the development of the Internet, the situation will change. One day we will overcome the remnants of the 80s and standards tied to the width of the horse’s croup, and we will have a quick exchange of data. Soon. But for now, here is a patch.
Because of the blocking, a very large pool of Amazon Web Services addresses suffered. Someone experienced only inconvenience or instability of work, while someone completely lost access to bussines-critical-systems and suffered financial losses. This situation resulted in an avalanche-like demand for accommodation in Russian clouds and the possibility of using native protocols (in particular, S3), which made it possible to migrate without changing the systems of new customers. So it turned out to be very useful to have a native S3.
Source: https://habr.com/ru/post/358376/
All Articles