As I built the year extension for the browser that reads articles by voice (with synchronization in the podcast)
Not once I tried to use third-party APIs to get a voice from the text that I’m interested to read - you can switch the reading to your ears when your eyes are tired, or listen during a comput. I know this is not one, even people far from IT can download text somewhere and download mp3. And podcasts / audiobooks are becoming more popular, and voice interfaces. It is obvious that the audience is there, hundreds of thousands of users have top extensions in Chrome Market on this topic. But they usually don’t have voices from Amazon (the best available, better than the new one from Google ), and where there isn’t anything else, such as the ability to listen in an extension — not just add to your podcast. He proposed a project idea inside the company - an apruv was received - development went.
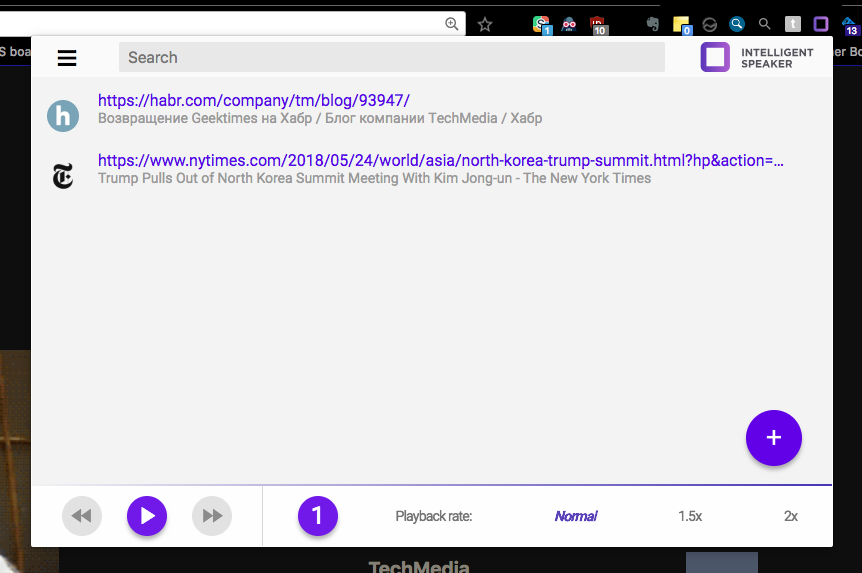
Browser extensions are a unique phenomenon loved by many - other software distribution methods do not have a similar client mocking mechanism. For example, Evernote desktop client - it is impossible to make the font more, it is impossible to make a dark theme - only if you partially hack binary files and partly CSS - the editor in the client uses web technologies. Whereas my recent Google search looks like this:
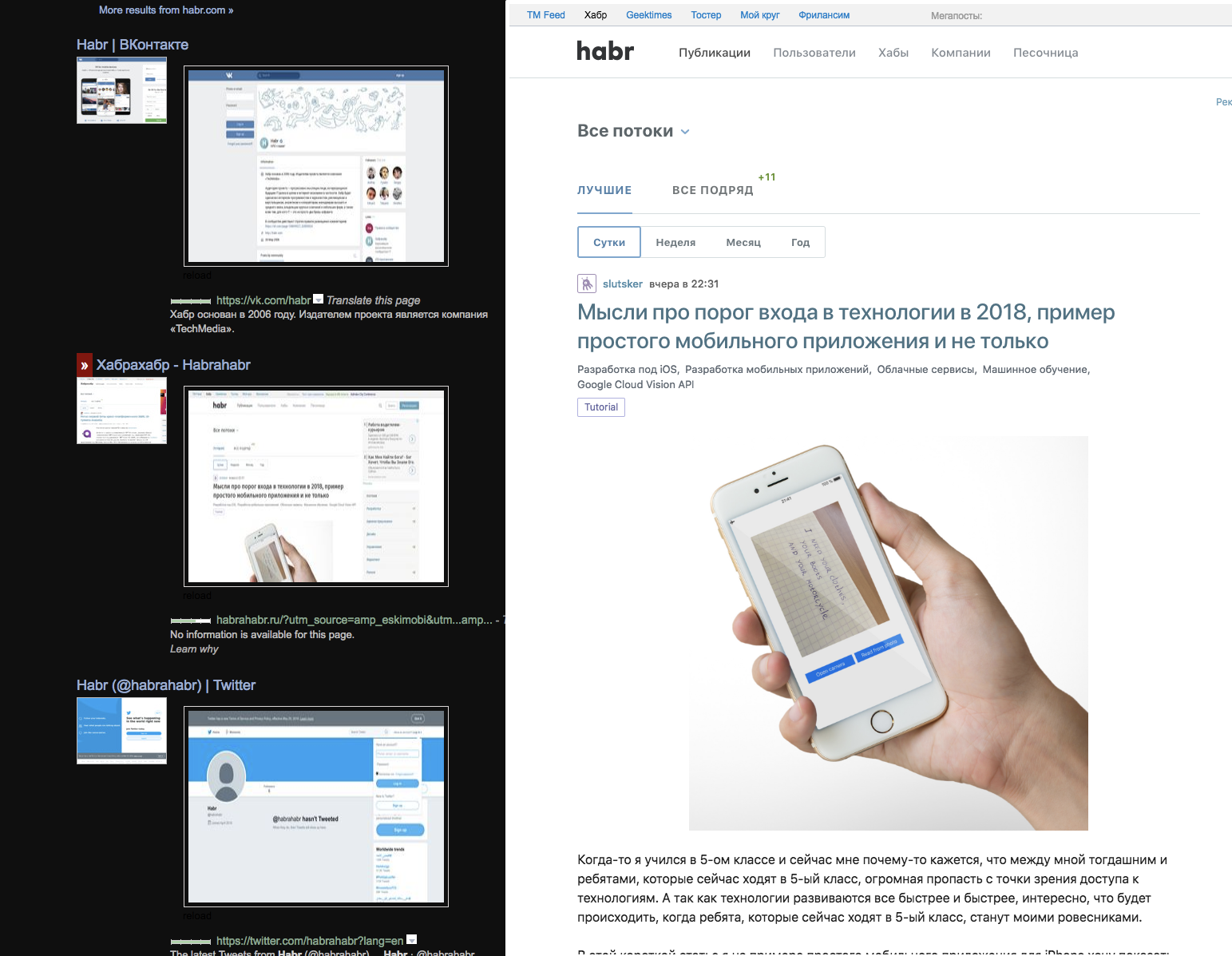
There are several extensions - a dark theme, two previews with a picture (main and page) and loading previews in the iframe on mouse over, without JS - thanks to this it loads faster - and it's interesting to see which site without scripts can work which is not - and understand that all animations are made in pure styles. And these extensions were found and installed from stores - and there are screenshots and some kind of security check - that is, each site / service lives in an environment where add-ons exist implicatively. If your popular service is inconvenient somewhere, the community sets up its alterations, sometimes even before the mashups - when data from several services can be on one page. Changing the owner of a DOM service or CSS class names can break someone's workflow .
Thanks to userscrypt and userstyle, we can change the look and functionality of websites - sometimes it is more pleasant for many of us to have our custom sharpening for daily use services. In Mac, for example, Finder cannot be made dark if the authors have not taken care of, and they have taken care of that third-party hacks to stop working have to be done. In the browser, all opensource - until we wait for WebAssembly where different languages can be compiled into binaries.
')
Several years ago I made my first extension for Firefox - there was no translator on it through Yandex. I made it so that the translation was displayed in the system pop-up window - so as not to litter the DOM pages.
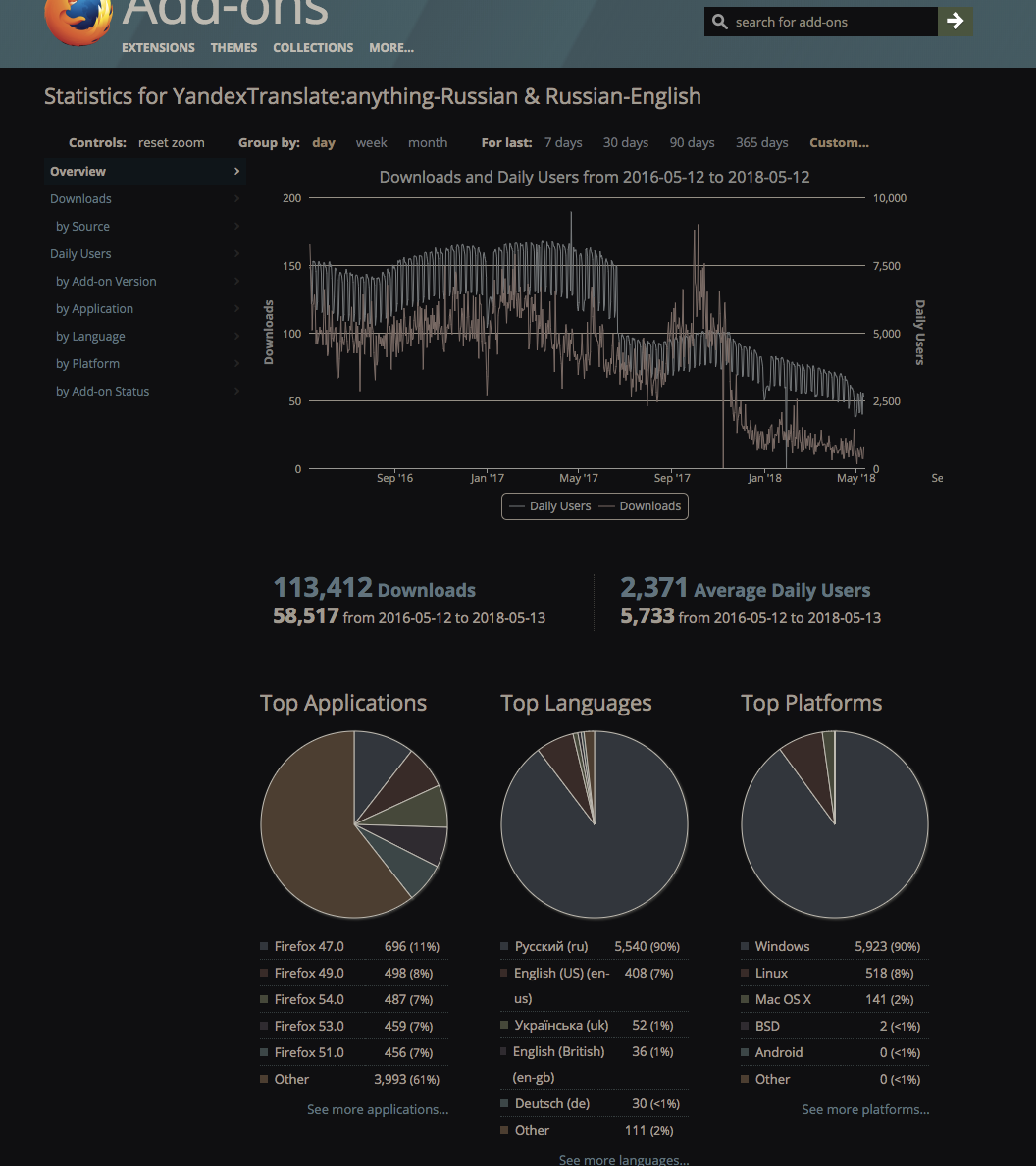
Worked smartly. At the peak of a little more than 8k users, the decline in graphics is after Firefox 57 where the extension stopped working:
I have not looked for a long time, today I thought a hundred people in general on the old browser, it turns out several thousand more. A positive rating of that experience and good reviews added motivation.
That expansion was a non-profit personal pet project, right there - the first incubator experience inside the company and the expansion should be commercially successful. At the heart of the product is the best available service for generating voice from text - Amazon Polly . Recently, a synthesis from Google came out: WaveNet, which sounded like a person in advertising, actually turned out to be worse in quality and four times more expensive.
The first version of the backend, or rather the first prototype for the local machine, was written on Python on the built-in server (it is interesting to know built in before moving on to the frameworks, if they are needed at all). The main “problem” was in splitting text by chunks - a limit of 1500 characters (all text-to-speech APIs have approximately the same limit). The first prototype was ready in a few weeks:
Almost everything seemed ready and ready - well, another UI, a site, something else and there will be many users.
The main target platform has obviously become the popular Google Chrome. Began to study how its WebExtensions works. It turned out that I got into a good time - Firefox 57 just appeared where this format is supported - that is, you can write one code for Chrome and Firefox, and even for Edge, well, for Opera - it is generally on the Chrome engine. This is great, my old extension only worked in Firefox, and now up to version 57 only. If you recently developed an extension for Google Chrome, it will most likely work today in Firefox. And even if the author of the extension did not bother with this - you can download the addon archive yourself from the Chrome Store and install it in Firefox - I think only now, from the 60 version of Firefox, it can be said that its implementation of WebExtensions has stabilized and got rid of many children's problems.
At first I played the sound in the so-called popup UI - this is what you see when you press the extension button and its interface appears, but it turns out that as soon as this window closes, this normal page is unloaded from memory and the sound stops playing. Ok, we play from the page space - this is called Isolated Worlds, where only DOM is fumbled with your extension, origin remains extension (if you don’t ask for the rights to access pages). The sound was played with a closed extension, but then I got to know the Content Security Policy in practice - I didn’t play for Medium - it turned out there was clearly written where media elements could come from. It remains the third place where you can play - background / event page. Each extension has three "pages" - they communicate with messages. Event page means that the extension exists in memory only when needed - for example, it responded to the event (click), lived for a few seconds and unloaded (similar to the Service Worker). Firefox currently only supports background page - the extension is always in the background. I checked all my installed extensions - I found several that are always in memory, although functionally they only react to events, the most famous of them is Evernote Clipper. I can not refuse it, although after installation the browser is clearly slower. They insert a lot of their code into each page that opens. Perhaps it speeds up response when you click on their button, but I think this does not justify global braking. Wrote them about it.
They insert the code into the page, even into your private Google Doc - every marketplace with extensions has automatic and manual code checking for security. In Chrome, as I understand it, the check is automatic - people only watch when they are booting, Firefox is always watched by a person - and sometimes I see ads on their blog that new volunteers are looking for this position. Opera - requires that a developer version of the code be attached with instructions on how to play the build. The popular problem with Opera - the review is very slow, for example, our extension has been in the queue for several months already - and it has not yet come out in their store. When once all the same, someone from the Opera began to check the addon for security - gave a red light due to the fact that the hash of the archive was different from the archive hash I provided.
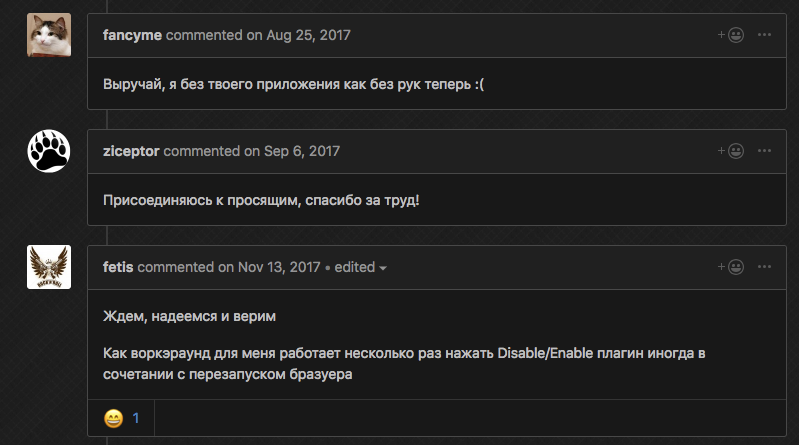
Chrome Store for several months removed the extension with each update - and sent a standard letter about the possible causes - where none of our products were described. Every time we sent letters to them and even called.
Edge as always - something did not work there, but devtools did not open , tried the pre-release build of Windows - the same thing, asked for StackOverflow - no answer.
Faced the problem that playing the sound does not prevent the extension from unloading - it started a bug , wrote a funny workaround:
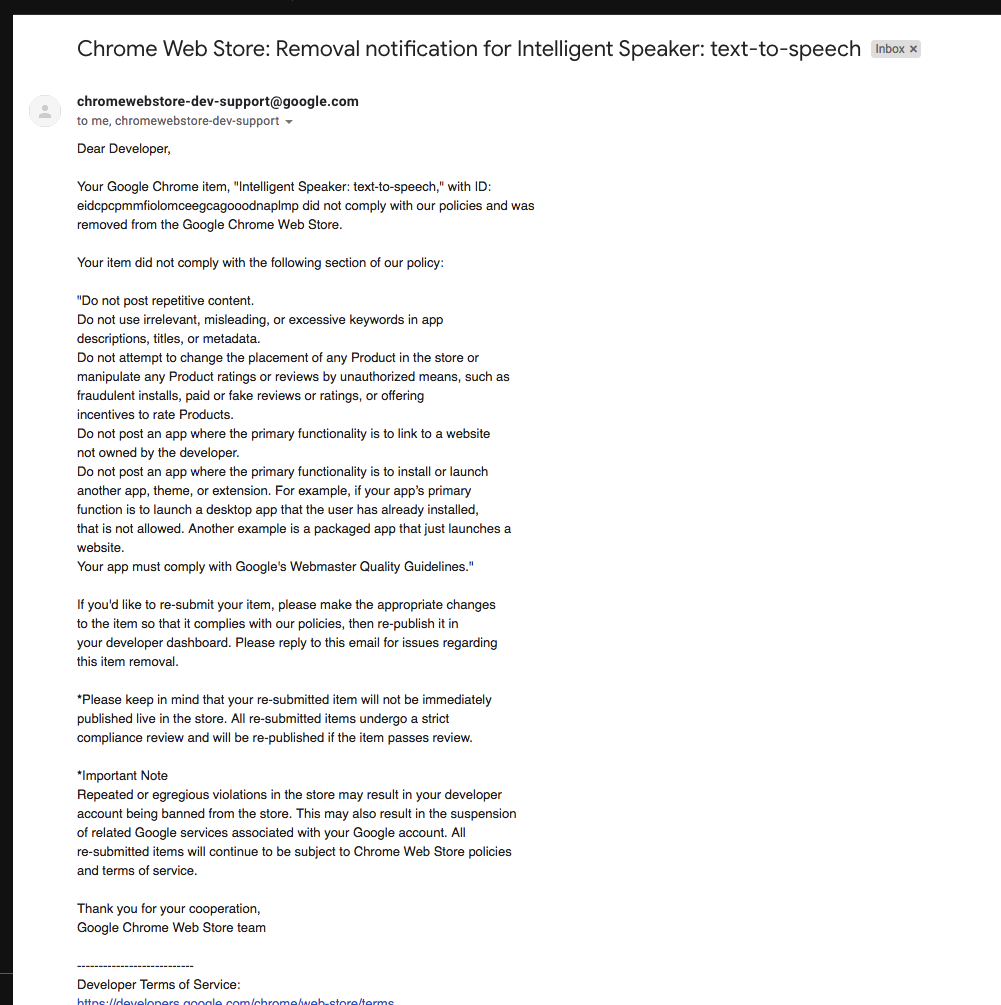
Parallel work was done on the server side. The mentor, who is also the developer himself (although he did not write code in this project), convinced me to use DynamoDB for the database (NotOnlySQL from Amazon) and Lambda instead of the classic server. Today I enjoy lambdas - these are virtual machines (Amazon Linux, based on Red Hat) that run on events, in my case - on HTTP requests that go through the Amazon API Gateway. Today it is ridiculous to remember - but at first when I did not understand that lambdas are not EC2 - I tried to use the Python server to process HTTP - only then I learned that lambdas communicate with the Internet via API Gateway - that is, it turns out that a separate service calls the container for each request. In addition to HTTP, lambdas can wake up to other events - for example, updating the database or adding a file to S3. If the load rises hundreds of times — hundreds of lambdas run simultaneously — scalability is one of the selling points of this technology. Lambda lives a maximum of five minutes. The container always processes only one request, the container can be automatically reused for the next request, and maybe not. All this makes a little change the style of development . Stateless - a hard disk (half a gigabyte) only for temporary files (I have already had such a lifestyle for a long time that the hard disk of a laptop should also be stateless - so that the damage was minimal from data loss - all state in the clouds, configs in git). I am surprised, but now for such a small product a dozen lambda is already used. Isolating these microservices makes the code easier - this listing screen is the whole microservice, this code screen is the second independent microservice. Understand why lose coupling is good.
Lambdas have become popular, Google Cloud and Microsoft Azure and Openstack have their own analogues. The firmware is updated automatically - security updates and Python updates happen themselves. On other projects, we inside the company for the server first consider the Lambda. For your personal microprojects, lambdas are also good because they cost a fraction of a cent, and if for example you need to start something automatically once a month, lambda can be a good solution. With a high load EC2 will cost less money - but that is if you do not have problems with scaling and other maintenance.
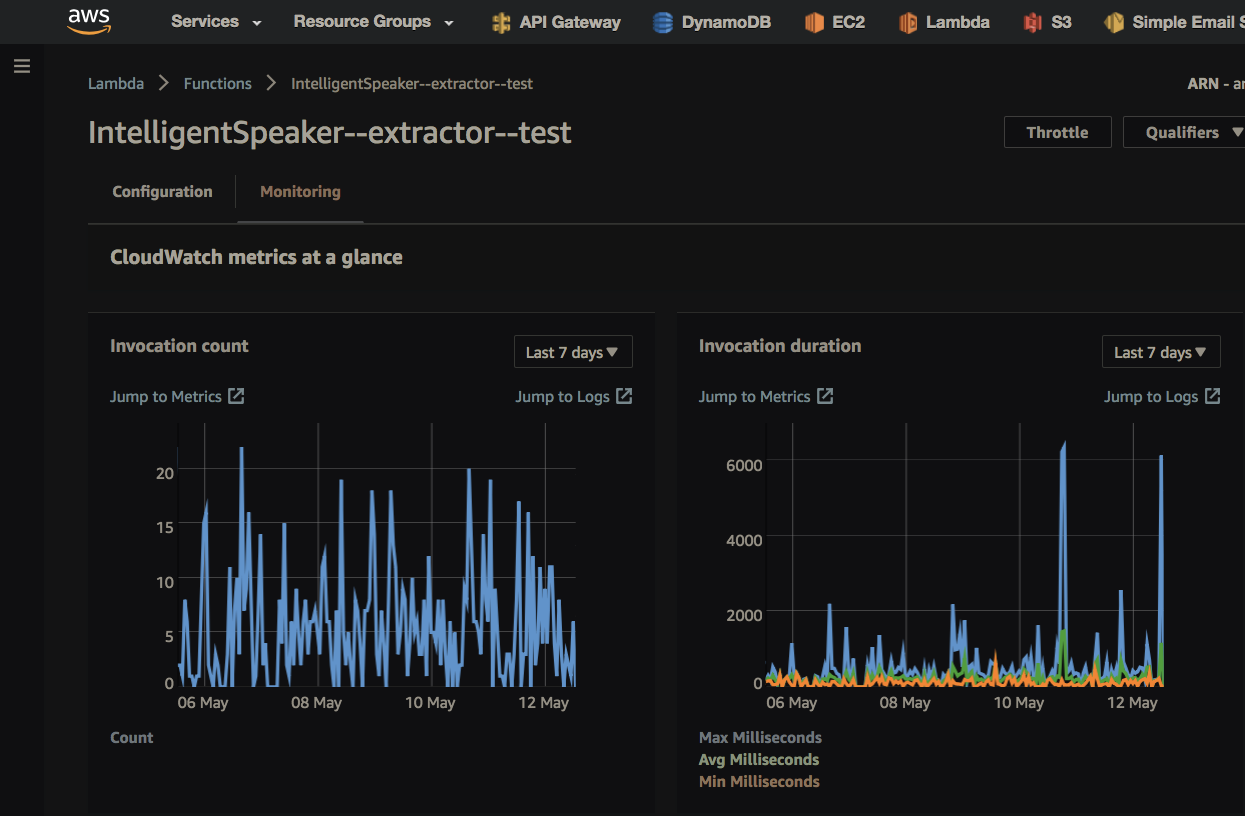
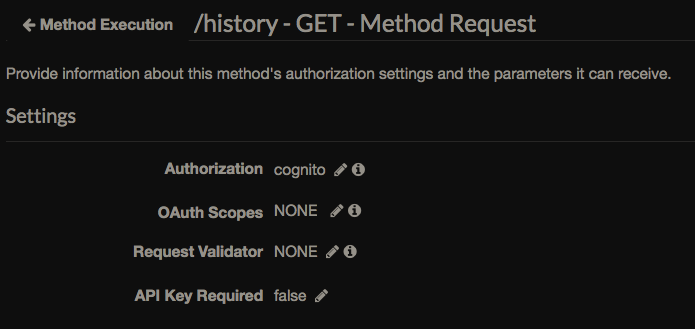
DynamoDB just works, as long as there's nothing to say about it (as long as the entire database is just a few megabytes). They promise to automatically scale. The base is popular so there are many ready-made tools, for example for export. Plus, for example, open Postgres - you can make communication via API Gateway directly to the DynamoDB API - without intermediate Lambda, the access policy can be configured at the level of indexes and columns of the table. My user mail (table key) is taken from a verified token - API Gateway checks for itself:
When creating an HTTP endpoint without Lambda, you can write an input request to the Amazon service that has an API and modify the output structure — using Apache Velocity syntax, for example, updating the database:
It's bad that when exporting a geytvey, this code will be saved in one line, in porridge with other information about endpoint, and even with each export, the sorting of lines may change - a mess is formed in the Gita, it is more difficult to track changes in this code:
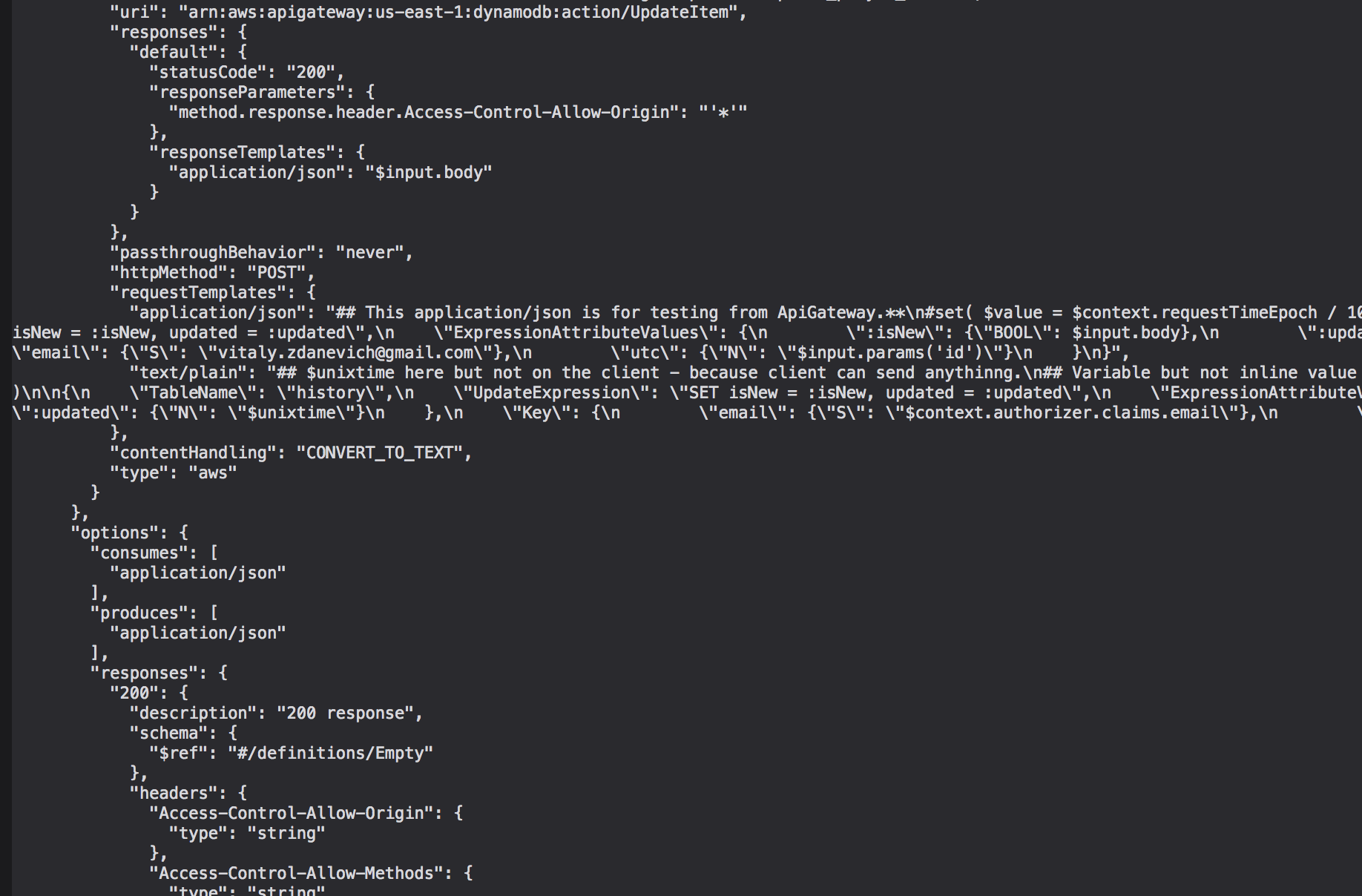
Each time the extension window is opened, a request is sent to the “server” - to synchronize history and status (heard or not) - API Gateway directly to HTTP API DynamoDB.
It turned out that when installing the extension, it does not require any permissions - they are not needed if all you need is to work with the current DOM and send it to the server (even without permisens - you can guess that they are looking for security scans when publishing). I thought I would have to enter permission to communicate with the parent site for authentication - but it worked out - I thought that when the window was opened, if I didn’t find an id_token from Amazon Cognito, an API Gateway request was made -> Lambda where the state_on_tokens table is checked - is there such a state (cryptographic string ), if there is, the token is returned and this entry in the table is deleted.
So far, text from HTML is removed only on the server (on Lambda) - this allows using a single microservice when retrieving text / HTML from the browser and from letters. When gaining popularity and increasing the load, it will be possible to remove the text on the client (there are libraries), and this will probably work faster.
We do not store texts and HTML in ourselves, only the received sound on S3. Each user has his own folder. When adding an article, we check if there is a subfolder with the same hash, if there is - the sound is reused. While you can add two identical articles, perhaps in the future we will warn if the hashes match.
We agreed that for such an extension that adds and reads the texts it would be logical to synchronize with the personal podcast feed - well, of course, I do the same service for myself, I need this functionality. It turned out that besides not the best mp3 today, you can use a more effective aac - Android plays it from the fourth version. Month fiddled with different methods of stitching ogg chunks into a single file, tried ffmpeg, libav, something else, corresponded with Amazon and project bugtrackers - the sound was obtained with defects. I stopped at the minimal solution, as I like - nothing different - one binary program decodes ogg to wav ( oggdec ), the second from pipe aac ( fdkaac ) - the Python executes the shell command:
Here in --comments there can be a link to the original page (if the text was not sent by mail) - it turned out that on iOS the built-in podcast player can conveniently show what is behind the link.
When the user gets the answer that the article is added - in fact, we just took the text out of HTML and returned the hash of this text (which works as a link) while the user moves the mouse to the Play button - the sound is still being synthesized. When I started listening to the article, the sound is probably not ready for the whole text, so sometimes you have to wait while rewinding. After rendering the last chunk of the sound, another Lambda is launched in this chain - which generates m4a for the podcast and modifies the xml feed file.
Lambda has a limit on transfer payload to another lambda - only 128 kilobytes. I wrote an exception handler - use a separate transit bake and transfer the hash of the file to the lambda of synthesizing the sound, in the bake the policy is set to delete the file in a day (minimum value).
For audio coding, I considered Amazon Elastic Transcoder , but I was surprised that the sound there can only be obtained with a static bitrate - and I wanted dynamic for better compression. Even the letter in the support wrote - how can it be that there is no such basic option, maybe it is in another place or I did not understand something? Answered that the encoding is true only in static:
If there is a lot of text - five minutes a cheap lambda may not be enough - so set the maximum CPU - enough to encode for six hours at a time.
Each user has an inbound email as in Evernote - I see an interesting article in the phone - I rummage to the mail program and send a link or text (from any program) to a personal address, switch to a program with podcasts - a new episode is here - I start playing and continue to twist pedals in the snow. This means that you can use a third-party service that sends an email to each new post from RSS - this means that you can subscribe to the blog as a podcast. On the phone, while extension does not work - although Firefox and YandexBrowser for Android support extensions, but there I see only the UI with non-working buttons; or wait for Progressive Web Apps for iOS when it can be fumbled as in a native program. Although incoming mail already offers this functionality - links will also remain in the sent ones.
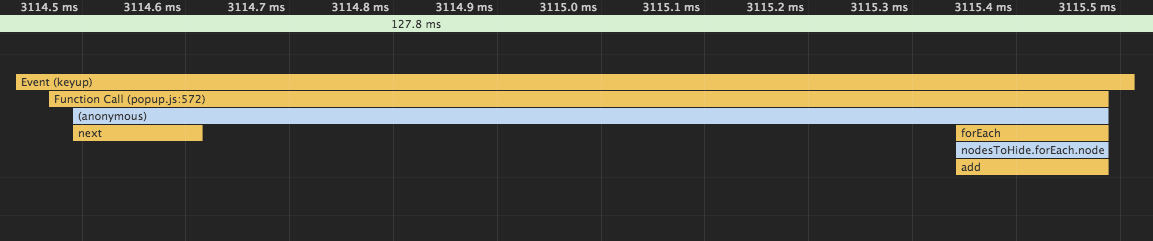
When implementing the search on the client, I encountered a warning Chrome Violation Long running JavaScript task took xx . Well, something was slowly working there, not critical, okay, I decided to dig, study Chrome's beautiful profiler:

Many operations, redrawing, so slows down.
Found that this happens when filtering and changing the class of necessary nodes:
Well, what can you do, but the premonition dictated me to try the wholesale approach:
More operations, more code, and work has become much faster:
Here you can see that in fact the browser does much less operations.
One of the best decisions when developing a product is to show a feedback form after removal. Used the usual Google Forms:
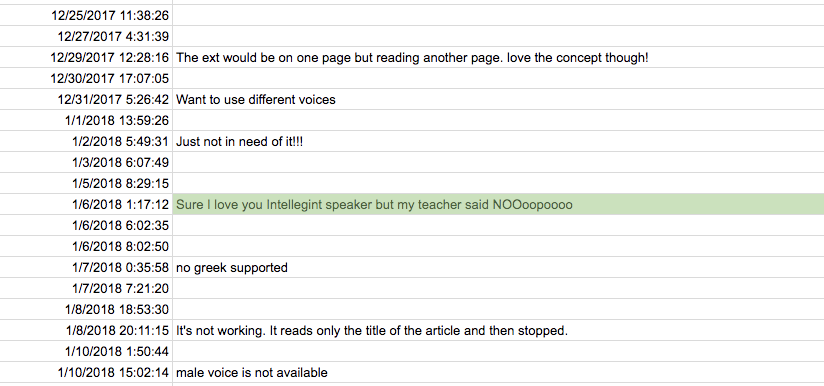
Ordered the site / landing - their portfolio was beautiful. But it turned out that our site was made by other people:
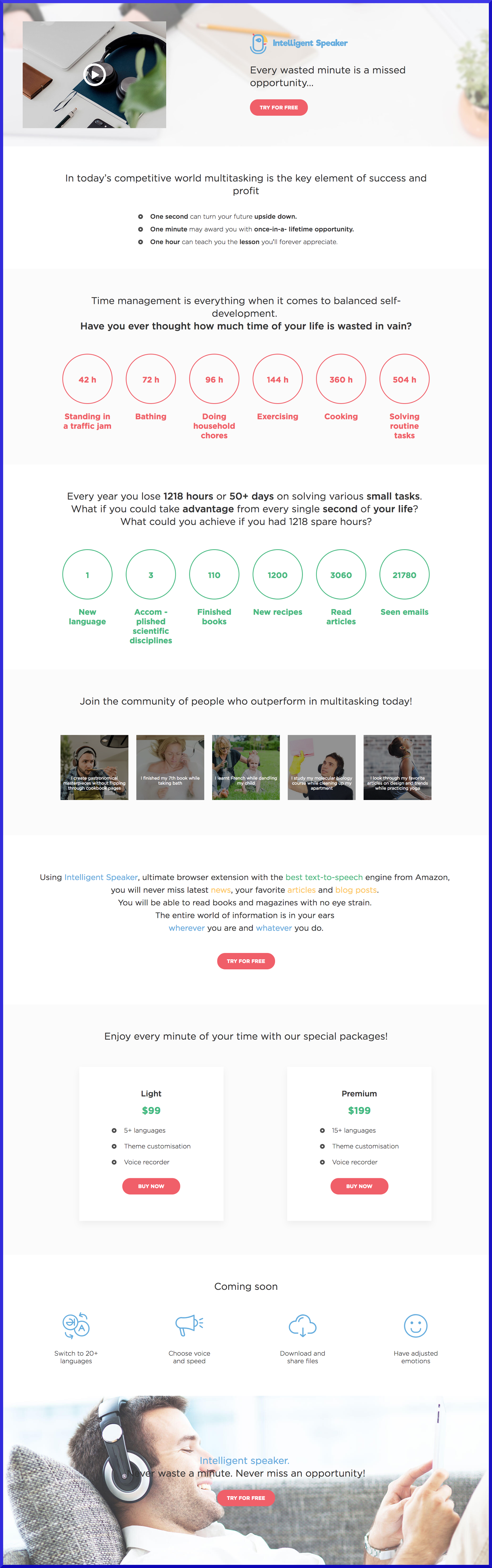
We had in mind one similar product, I and the marketer laughed at his website with a non-working main link to the stop - it became clear that ours looked worse. So we lived a few months with this design. Then the mentor decided to order another site from another team, with our modifications it turned out better:

That's how it looks now. Not perfect, you need to refine, but I like the agile approach - first we will do it somehow, then we will do it better, then a little better. Because I do not know what can be improved. One of the reasons for writing this article is to get feedback.
Feedback from Larry is real - he liked the product so much (or rather the voice of Amazon) that he put our logo on his new book, that's it. I was surprised that people use the Intelligent Speaker for pro-freezing (when writing an article and reading ears to feel from a different angle) and dyslexia. For example, a letter of thanks came from an American coach that it’s great to listen to lyrics now.
For hosting, the site initially chose GitHub - I already had experience with static sites using its ability to add my own domain. But as it turned out, it’s impossible to keep your domain on Github with an SSL certificate. Today it is already possible (since this month, by the way), but in 2017 for this reason I emigrated to GitLab. I had to write the first ci in my life so that the site was copied from one folder to another - the minimal process of working with static pages. Not always this (free note) ci works - some problems of GitLab, but in general I am pleased with it, recently found out that they had such an old logo

Wow, this charisma is more casual to me.

LastPass shows the best version:

Hmm, but there is still no extension to have an old logo? Saw similar jokes .
Today, ci for the site, including minifits HTML / CSS / JS - I have long wanted to implement this best practice, usually this does not bother - there are more important tasks. After minification - gz archivers are created for each file - now even on this free static hosting we received Content-Encoding: gzip, I hope Google will rank higher from this and users will open faster (and it seems Gitlab does not give up quickly).
Ci is also written for the extension assembly publication: minification and HTTP POST. It is launched locally manually - it could be screwed to the server where the Git extension lives - in our case VSTS , but for now there is no need. The site lives in a submodule - maybe it was worth having one repository, but then I thought that there was no need to drive into Gitlab a code that does not belong to the site - even more so that ci runs, although yes you can configure the site to be assembled only when pushing to a specific brunch.
The first version of the extension UI looked like this:
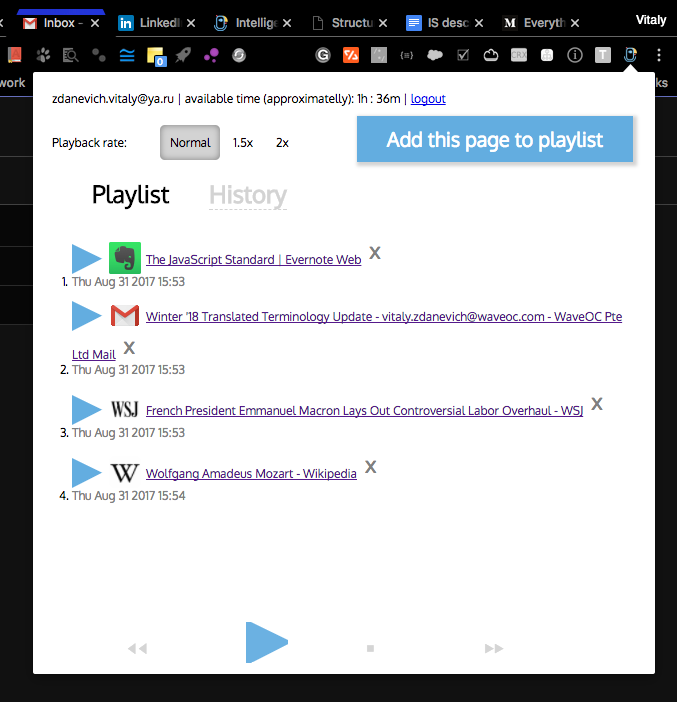
Then the mentor said that the way the studio will make a normal design:
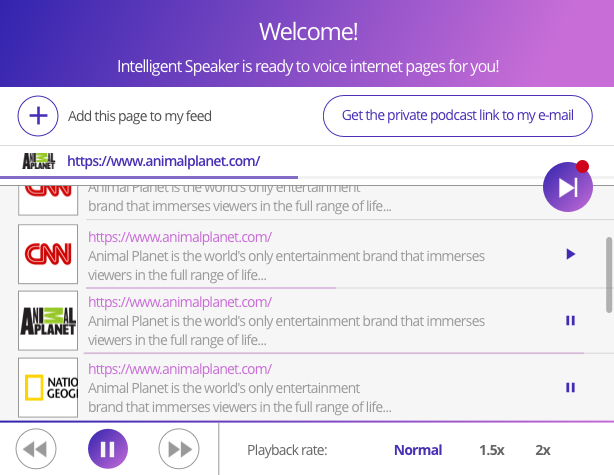
We felt that we needed better.
We decided to try Material - we are not opposed to non-irritating facelessness, let it be felt as part of the browser, and I think this increases the chances of becoming Featured in the Chrome Store - because the visual style is from the same company. Although today we have already been explained that the Material does not mean when everything is the same. Today's result:
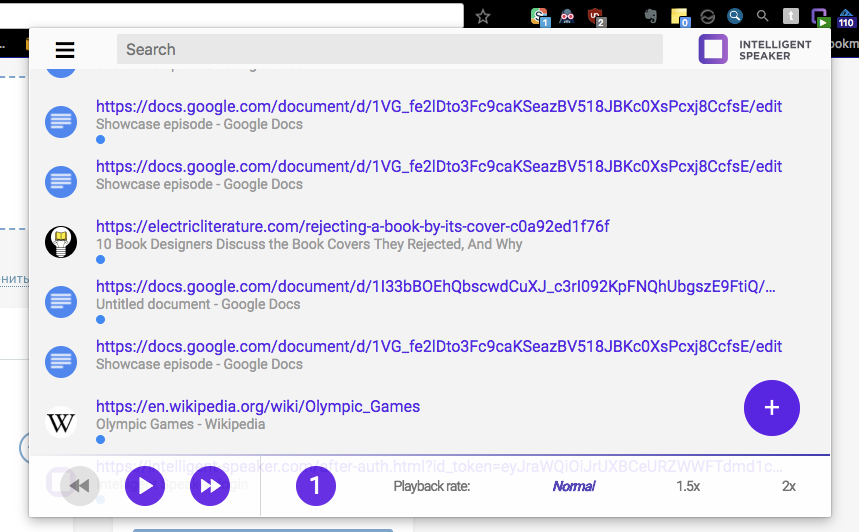
The product chip is that it will not only detect the text for reading as readability mode, but also cleverly adapt the text for sounding - for example, it would be convenient to listen to the comment tree when nicknames, dates, citations are read by another intonation. It is still in the plans, we plan to start with Reddit. But already at an early stage of development, it became clear that the capacity of libraries for HTML distillation is not enough - for example, on Wikipedia [0], there are [1] and [2] such [3] pieces [4], Google Doc was not picked up at all (but I wanted to get a die in the Chrome Store that we support it). The solution - for Wikipedia, their API is used, for Google Doc - a tricky code for getting the selected text and the entire document - so as not to ask the user for permission to access the entire Google Drive. Chose a dozen other popular sites and checked / adapted reading on them.
The mentor with the marketer decided that they needed a blog with social networks. He began to look for a static blogger - for speed, simplicity, low cost and security. If I ever open a blog for myself, then only as a product of a static generator, so that all posts are kept in Gita. From my good friendMarcel Proust, umputun heard that Hugo is good. A few days of study, tests, topic selection - the blog is ready. At first, we stored generated asets in Gita, then I added ci on Gitlab to collect them there - cleaner, Git, the marketer is easier to add posts (I thought it’s impossible to teach this lovely girl to write posts in a notepad with a markdown and push). To build the site, use the Ubuntu container in which everything you need is installed - including Hugo - and it turns out that when Hugo is updated - when you push a new post in Git - the blog engine will also be updated on the site, beauty. Although for security it is better not to have external dependencies - so that the site is assembled even when GitHub is unavailable.
Once having read about Go, love fast execution and all sorts of optimizations, I wrote a minimal test - HTTP GET - it turned out that Lambda worked out faster, the bulky benchmarks showed high speed. The following microservice wrote already on Go - now it is my main server language instead of Python. I liked the presence of the built-in `go fmt` tool for formatting the code, you know, everyone likes it, even though there are tabs. To convert a JSON string to an object, it is necessary to describe the structure in advance - after Python and JS it seemed incredible - why? Even more incredible it turned out that there is no contains () method in arrays or slices - I welcome minimalism, but is it really a correct language design when you need to write your own loop for such a basic thing? Other minor drawbacks of Go before Python - lambda deploy is a copied executable file - for example, 6 megabytes and not kilobytes of code (you have to wait a few seconds), and also more code (the level of abstraction is sometimes lower, but I like to better understand how it is working). It's nice that the code being compiled is safer - fewer errors in the runtime, and types in Python I already wrote with 3.5 - languages are faster with types (but types only for validation in Python) are clearer and safer. Golang also has an analogue of duck typing via implicit interfaces - if there are the necessary methods - then the object fits the interface.
I thought - why Go and not like Java? I did not test it myself, but I read that a cold start on Lambda will be longer. Perhaps you can write a lambda that will keep all other lambdas warm and use Java, perhaps. I don’t like to jump by technology, I prefer to go deeper and improve in the current stack, but here Go’s speed plus its overall positive assessment by the industry and the fact that Liamds now support it so much so that Amazon wrote all its SDKs and Go too - although this is technology from a rival corporation - the transition was worth it. In our small company on another project, they are also switching from Python to Go.
From Go, I liked one of the statements that A little copying is better than a little dependency , this is also one of my mottos, that is, I try not to bang the library to save five lines. One of my favorite extensions has 639 dependencies, you can imagine:

From the early stage, the extension was able to play from the context menu, and when it was playing, it was possible to pause and rewind to the chunk back and forth:
But it was decided to make the UI more convenient to the detriment of functionality - instead of the submenu, now there is only one item that adds a page or selected to the list:

This decision was difficult, but I see the main story by adding pages for listening later, but you can still listen right away - you just need to open the extension and play window.
The logo, as you can see, also changed - during the prototyping of the site, the girl designer put the dagger - this square seemed to us better than a parrot.
Testing: Selenium cannot open the extension window, so I use it in conjunction with pyautogui for clicks and scikit-image to compare the expected and current images. I have never done this before, this is interesting - this way I can test CSS.
All the code throughout the year (and earlier) I wrote in Vima. Learned more about this great editor. The time has come when I felt that Vime was really productive. Magic peace of software. In all of it, for me, Wim has become a feature of the industry that makes up the best parts. It has its own style. And it is preinstalled in many places - ssh anywhere - the working environment remains comfortable, I even have it out of the box in Android. Plug-ins extend functionality, and their asynchronous operation has recently been supported. I have analyzer linters, the ability to see the previous version of the hunk gita, some refactoring (renaming functions in all places), bookmarks in the code, color hexes are highlighted in color, and everywhere I have a dark color - I remember in Intelligent IDEA on several monitors in external Windows could not get rid of the white frame Makovsky window.Saw and more sophisticated plugins like hints, documentation when writing, integration with external utilities, but in Vime there are so many things hidden — and external commands to the selected text can be easily performed - for example, count the number of characters (wc ) or translate selected text ( trans ). I heard complaints several times that something cannot be done in Vima - but in fact it is possible. It was possible to work on Salesforce using the corresponding plugin - right from Wima I ran tests on a remote server. I remember how I perceived phreaking when I heard that someone works in Vima or Emax, but this also happened to me. I don’t urge to try - it really takes time to figure out how to do basic operations, you need to invest time and effort to get to the pulp.
Today’s Chrome Store analytics:
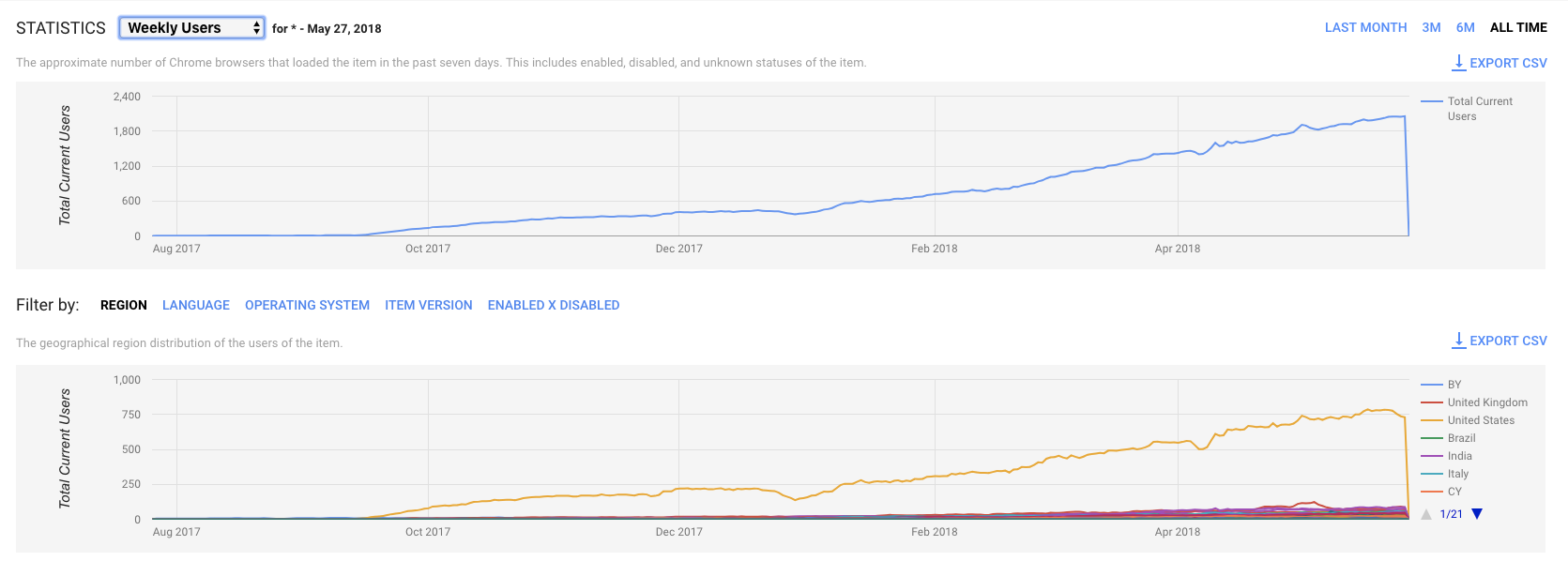
Change in growth rates between December and February - we added localization to extension to all languages that Polly reads - so now, for example, for French edition, we are higher. I think the localization of the site will give the same effect. Site statistics:
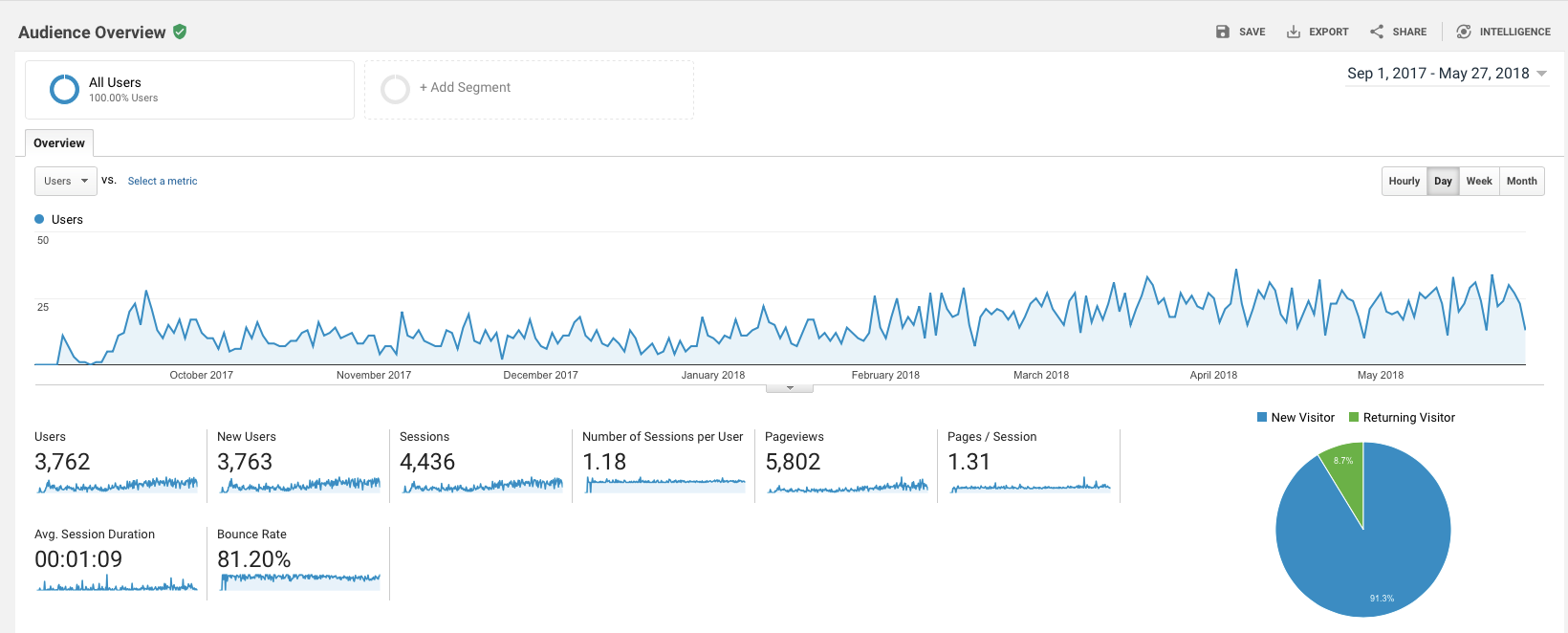
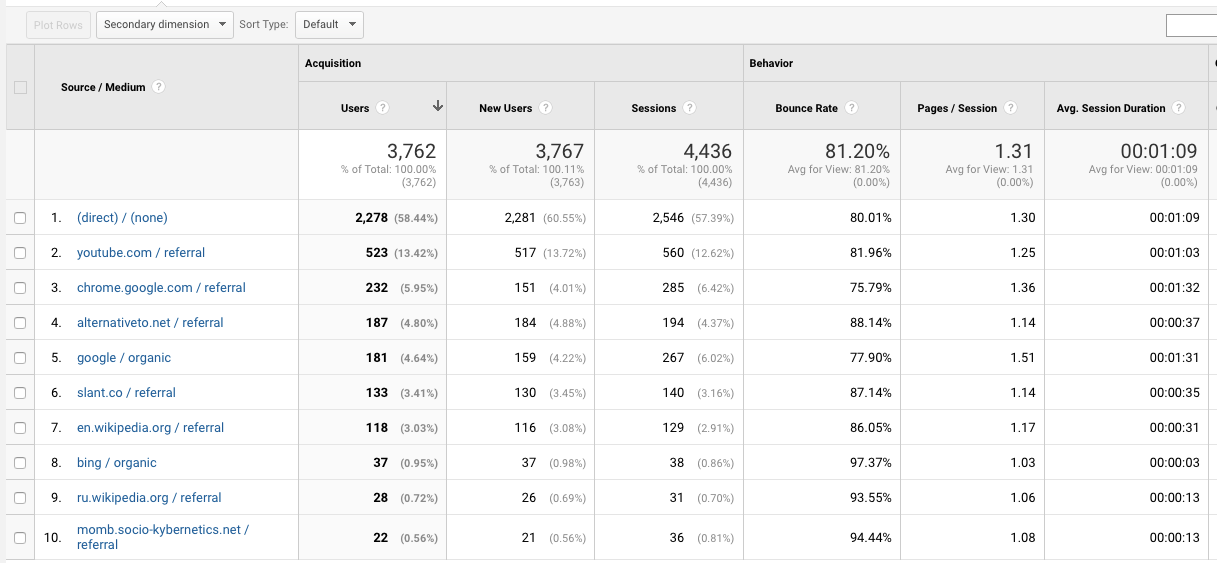
The growth turned out to be lower than planned, although there is no paid advertising - only organic traffic. Six people signed up for $ 6.99 per month. Perhaps over time, the numbers will start to grow. What do you think?
This is the story of my year.
Browser extensions are a unique phenomenon loved by many - other software distribution methods do not have a similar client mocking mechanism. For example, Evernote desktop client - it is impossible to make the font more, it is impossible to make a dark theme - only if you partially hack binary files and partly CSS - the editor in the client uses web technologies. Whereas my recent Google search looks like this:
There are several extensions - a dark theme, two previews with a picture (main and page) and loading previews in the iframe on mouse over, without JS - thanks to this it loads faster - and it's interesting to see which site without scripts can work which is not - and understand that all animations are made in pure styles. And these extensions were found and installed from stores - and there are screenshots and some kind of security check - that is, each site / service lives in an environment where add-ons exist implicatively. If your popular service is inconvenient somewhere, the community sets up its alterations, sometimes even before the mashups - when data from several services can be on one page. Changing the owner of a DOM service or CSS class names can break someone's workflow .
Thanks to userscrypt and userstyle, we can change the look and functionality of websites - sometimes it is more pleasant for many of us to have our custom sharpening for daily use services. In Mac, for example, Finder cannot be made dark if the authors have not taken care of, and they have taken care of that third-party hacks to stop working have to be done. In the browser, all opensource - until we wait for WebAssembly where different languages can be compiled into binaries.
')
Several years ago I made my first extension for Firefox - there was no translator on it through Yandex. I made it so that the translation was displayed in the system pop-up window - so as not to litter the DOM pages.
Worked smartly. At the peak of a little more than 8k users, the decline in graphics is after Firefox 57 where the extension stopped working:
I have not looked for a long time, today I thought a hundred people in general on the old browser, it turns out several thousand more. A positive rating of that experience and good reviews added motivation.
That expansion was a non-profit personal pet project, right there - the first incubator experience inside the company and the expansion should be commercially successful. At the heart of the product is the best available service for generating voice from text - Amazon Polly . Recently, a synthesis from Google came out: WaveNet, which sounded like a person in advertising, actually turned out to be worse in quality and four times more expensive.
The first version of the backend, or rather the first prototype for the local machine, was written on Python on the built-in server (it is interesting to know built in before moving on to the frameworks, if they are needed at all). The main “problem” was in splitting text by chunks - a limit of 1500 characters (all text-to-speech APIs have approximately the same limit). The first prototype was ready in a few weeks:
Almost everything seemed ready and ready - well, another UI, a site, something else and there will be many users.
The main target platform has obviously become the popular Google Chrome. Began to study how its WebExtensions works. It turned out that I got into a good time - Firefox 57 just appeared where this format is supported - that is, you can write one code for Chrome and Firefox, and even for Edge, well, for Opera - it is generally on the Chrome engine. This is great, my old extension only worked in Firefox, and now up to version 57 only. If you recently developed an extension for Google Chrome, it will most likely work today in Firefox. And even if the author of the extension did not bother with this - you can download the addon archive yourself from the Chrome Store and install it in Firefox - I think only now, from the 60 version of Firefox, it can be said that its implementation of WebExtensions has stabilized and got rid of many children's problems.
At first I played the sound in the so-called popup UI - this is what you see when you press the extension button and its interface appears, but it turns out that as soon as this window closes, this normal page is unloaded from memory and the sound stops playing. Ok, we play from the page space - this is called Isolated Worlds, where only DOM is fumbled with your extension, origin remains extension (if you don’t ask for the rights to access pages). The sound was played with a closed extension, but then I got to know the Content Security Policy in practice - I didn’t play for Medium - it turned out there was clearly written where media elements could come from. It remains the third place where you can play - background / event page. Each extension has three "pages" - they communicate with messages. Event page means that the extension exists in memory only when needed - for example, it responded to the event (click), lived for a few seconds and unloaded (similar to the Service Worker). Firefox currently only supports background page - the extension is always in the background. I checked all my installed extensions - I found several that are always in memory, although functionally they only react to events, the most famous of them is Evernote Clipper. I can not refuse it, although after installation the browser is clearly slower. They insert a lot of their code into each page that opens. Perhaps it speeds up response when you click on their button, but I think this does not justify global braking. Wrote them about it.
They insert the code into the page, even into your private Google Doc - every marketplace with extensions has automatic and manual code checking for security. In Chrome, as I understand it, the check is automatic - people only watch when they are booting, Firefox is always watched by a person - and sometimes I see ads on their blog that new volunteers are looking for this position. Opera - requires that a developer version of the code be attached with instructions on how to play the build. The popular problem with Opera - the review is very slow, for example, our extension has been in the queue for several months already - and it has not yet come out in their store. When once all the same, someone from the Opera began to check the addon for security - gave a red light due to the fact that the hash of the archive was different from the archive hash I provided.
Chrome Store for several months removed the extension with each update - and sent a standard letter about the possible causes - where none of our products were described. Every time we sent letters to them and even called.
Edge as always - something did not work there, but devtools did not open , tried the pre-release build of Windows - the same thing, asked for StackOverflow - no answer.
Faced the problem that playing the sound does not prevent the extension from unloading - it started a bug , wrote a funny workaround:
function _doNotSleep() { if (audioCurrent) { setTimeout(_ => { // only some http request, neither console.log() nor creating obj fetch(chrome.runtime.getURL('manifest.json')); _doNotSleep(); }, 2000); } } Parallel work was done on the server side. The mentor, who is also the developer himself (although he did not write code in this project), convinced me to use DynamoDB for the database (NotOnlySQL from Amazon) and Lambda instead of the classic server. Today I enjoy lambdas - these are virtual machines (Amazon Linux, based on Red Hat) that run on events, in my case - on HTTP requests that go through the Amazon API Gateway. Today it is ridiculous to remember - but at first when I did not understand that lambdas are not EC2 - I tried to use the Python server to process HTTP - only then I learned that lambdas communicate with the Internet via API Gateway - that is, it turns out that a separate service calls the container for each request. In addition to HTTP, lambdas can wake up to other events - for example, updating the database or adding a file to S3. If the load rises hundreds of times — hundreds of lambdas run simultaneously — scalability is one of the selling points of this technology. Lambda lives a maximum of five minutes. The container always processes only one request, the container can be automatically reused for the next request, and maybe not. All this makes a little change the style of development . Stateless - a hard disk (half a gigabyte) only for temporary files (I have already had such a lifestyle for a long time that the hard disk of a laptop should also be stateless - so that the damage was minimal from data loss - all state in the clouds, configs in git). I am surprised, but now for such a small product a dozen lambda is already used. Isolating these microservices makes the code easier - this listing screen is the whole microservice, this code screen is the second independent microservice. Understand why lose coupling is good.
Lambdas have become popular, Google Cloud and Microsoft Azure and Openstack have their own analogues. The firmware is updated automatically - security updates and Python updates happen themselves. On other projects, we inside the company for the server first consider the Lambda. For your personal microprojects, lambdas are also good because they cost a fraction of a cent, and if for example you need to start something automatically once a month, lambda can be a good solution. With a high load EC2 will cost less money - but that is if you do not have problems with scaling and other maintenance.
DynamoDB just works, as long as there's nothing to say about it (as long as the entire database is just a few megabytes). They promise to automatically scale. The base is popular so there are many ready-made tools, for example for export. Plus, for example, open Postgres - you can make communication via API Gateway directly to the DynamoDB API - without intermediate Lambda, the access policy can be configured at the level of indexes and columns of the table. My user mail (table key) is taken from a verified token - API Gateway checks for itself:
When creating an HTTP endpoint without Lambda, you can write an input request to the Amazon service that has an API and modify the output structure — using Apache Velocity syntax, for example, updating the database:
#set( $unixtime = $context.requestTimeEpoch / 1000 ) { "TableName": "history", "UpdateExpression": "SET isNew = :isNew, updated = :updated", "ExpressionAttributeValues": { ":isNew": {"BOOL": $input.body}, ":updated": {"N": "$unixtime"} }, "Key": { "email": {"S": "$context.authorizer.claims.email"}, "utc": {"N": "$input.params('id')"} } } It's bad that when exporting a geytvey, this code will be saved in one line, in porridge with other information about endpoint, and even with each export, the sorting of lines may change - a mess is formed in the Gita, it is more difficult to track changes in this code:
Each time the extension window is opened, a request is sent to the “server” - to synchronize history and status (heard or not) - API Gateway directly to HTTP API DynamoDB.
It turned out that when installing the extension, it does not require any permissions - they are not needed if all you need is to work with the current DOM and send it to the server (even without permisens - you can guess that they are looking for security scans when publishing). I thought I would have to enter permission to communicate with the parent site for authentication - but it worked out - I thought that when the window was opened, if I didn’t find an id_token from Amazon Cognito, an API Gateway request was made -> Lambda where the state_on_tokens table is checked - is there such a state (cryptographic string ), if there is, the token is returned and this entry in the table is deleted.
So far, text from HTML is removed only on the server (on Lambda) - this allows using a single microservice when retrieving text / HTML from the browser and from letters. When gaining popularity and increasing the load, it will be possible to remove the text on the client (there are libraries), and this will probably work faster.
We do not store texts and HTML in ourselves, only the received sound on S3. Each user has his own folder. When adding an article, we check if there is a subfolder with the same hash, if there is - the sound is reused. While you can add two identical articles, perhaps in the future we will warn if the hashes match.
We agreed that for such an extension that adds and reads the texts it would be logical to synchronize with the personal podcast feed - well, of course, I do the same service for myself, I need this functionality. It turned out that besides not the best mp3 today, you can use a more effective aac - Android plays it from the fourth version. Month fiddled with different methods of stitching ogg chunks into a single file, tried ffmpeg, libav, something else, corresponded with Amazon and project bugtrackers - the sound was obtained with defects. I stopped at the minimal solution, as I like - nothing different - one binary program decodes ogg to wav ( oggdec ), the second from pipe aac ( fdkaac ) - the Python executes the shell command:
f'''cd /tmp; curl {urls} | /var/task/oggdec - -o - | /var/task/fdkaac -m5 - -o {episode_filename} --title="{title_escaped}" --artist='Intelligent Speaker' --album-artist='Intelligent Speaker' --album='Intelligent Speaker' --genre='Podcast' --date='{date}' --comment='Voiced text from {url_article or "email"}' ''' Here in --comments there can be a link to the original page (if the text was not sent by mail) - it turned out that on iOS the built-in podcast player can conveniently show what is behind the link.
When the user gets the answer that the article is added - in fact, we just took the text out of HTML and returned the hash of this text (which works as a link) while the user moves the mouse to the Play button - the sound is still being synthesized. When I started listening to the article, the sound is probably not ready for the whole text, so sometimes you have to wait while rewinding. After rendering the last chunk of the sound, another Lambda is launched in this chain - which generates m4a for the podcast and modifies the xml feed file.
Lambda has a limit on transfer payload to another lambda - only 128 kilobytes. I wrote an exception handler - use a separate transit bake and transfer the hash of the file to the lambda of synthesizing the sound, in the bake the policy is set to delete the file in a day (minimum value).
For audio coding, I considered Amazon Elastic Transcoder , but I was surprised that the sound there can only be obtained with a static bitrate - and I wanted dynamic for better compression. Even the letter in the support wrote - how can it be that there is no such basic option, maybe it is in another place or I did not understand something? Answered that the encoding is true only in static:
If there is a lot of text - five minutes a cheap lambda may not be enough - so set the maximum CPU - enough to encode for six hours at a time.
Each user has an inbound email as in Evernote - I see an interesting article in the phone - I rummage to the mail program and send a link or text (from any program) to a personal address, switch to a program with podcasts - a new episode is here - I start playing and continue to twist pedals in the snow. This means that you can use a third-party service that sends an email to each new post from RSS - this means that you can subscribe to the blog as a podcast. On the phone, while extension does not work - although Firefox and YandexBrowser for Android support extensions, but there I see only the UI with non-working buttons; or wait for Progressive Web Apps for iOS when it can be fumbled as in a native program. Although incoming mail already offers this functionality - links will also remain in the sent ones.
When implementing the search on the client, I encountered a warning Chrome Violation Long running JavaScript task took xx . Well, something was slowly working there, not critical, okay, I decided to dig, study Chrome's beautiful profiler:
Many operations, redrawing, so slows down.
Found that this happens when filtering and changing the class of necessary nodes:
search.addEventListener('keyup', function() { for (const node of nodes) if (node.innerText.toLowerCase().includes(this.value.toLowerCase())) node.classList.remove('hidden'); else node.classList.add('hidden'); }); Well, what can you do, but the premonition dictated me to try the wholesale approach:
search.addEventListener('keyup', function() { const nodesToHide = []; const nodesToShow = []; for (const node of nodes) if (node.innerText.toLowerCase().includes(this.value.toLowerCase())) nodesToShow.push(node); else nodesToHide.push(node); nodesToHide.forEach(node => node.classList.add('hidden')); nodesToShow.forEach(node => node.classList.remove('hidden')); }); More operations, more code, and work has become much faster:
Here you can see that in fact the browser does much less operations.
One of the best decisions when developing a product is to show a feedback form after removal. Used the usual Google Forms:
Ordered the site / landing - their portfolio was beautiful. But it turned out that our site was made by other people:
We had in mind one similar product, I and the marketer laughed at his website with a non-working main link to the stop - it became clear that ours looked worse. So we lived a few months with this design. Then the mentor decided to order another site from another team, with our modifications it turned out better:
That's how it looks now. Not perfect, you need to refine, but I like the agile approach - first we will do it somehow, then we will do it better, then a little better. Because I do not know what can be improved. One of the reasons for writing this article is to get feedback.
Feedback from Larry is real - he liked the product so much (or rather the voice of Amazon) that he put our logo on his new book, that's it. I was surprised that people use the Intelligent Speaker for pro-freezing (when writing an article and reading ears to feel from a different angle) and dyslexia. For example, a letter of thanks came from an American coach that it’s great to listen to lyrics now.
For hosting, the site initially chose GitHub - I already had experience with static sites using its ability to add my own domain. But as it turned out, it’s impossible to keep your domain on Github with an SSL certificate. Today it is already possible (since this month, by the way), but in 2017 for this reason I emigrated to GitLab. I had to write the first ci in my life so that the site was copied from one folder to another - the minimal process of working with static pages. Not always this (free note) ci works - some problems of GitLab, but in general I am pleased with it, recently found out that they had such an old logo
Wow, this charisma is more casual to me.
LastPass shows the best version:
Hmm, but there is still no extension to have an old logo? Saw similar jokes .
Today, ci for the site, including minifits HTML / CSS / JS - I have long wanted to implement this best practice, usually this does not bother - there are more important tasks. After minification - gz archivers are created for each file - now even on this free static hosting we received Content-Encoding: gzip, I hope Google will rank higher from this and users will open faster (and it seems Gitlab does not give up quickly).
Ci is also written for the extension assembly publication: minification and HTTP POST. It is launched locally manually - it could be screwed to the server where the Git extension lives - in our case VSTS , but for now there is no need. The site lives in a submodule - maybe it was worth having one repository, but then I thought that there was no need to drive into Gitlab a code that does not belong to the site - even more so that ci runs, although yes you can configure the site to be assembled only when pushing to a specific brunch.
The first version of the extension UI looked like this:
Then the mentor said that the way the studio will make a normal design:
We felt that we needed better.
We decided to try Material - we are not opposed to non-irritating facelessness, let it be felt as part of the browser, and I think this increases the chances of becoming Featured in the Chrome Store - because the visual style is from the same company. Although today we have already been explained that the Material does not mean when everything is the same. Today's result:
The product chip is that it will not only detect the text for reading as readability mode, but also cleverly adapt the text for sounding - for example, it would be convenient to listen to the comment tree when nicknames, dates, citations are read by another intonation. It is still in the plans, we plan to start with Reddit. But already at an early stage of development, it became clear that the capacity of libraries for HTML distillation is not enough - for example, on Wikipedia [0], there are [1] and [2] such [3] pieces [4], Google Doc was not picked up at all (but I wanted to get a die in the Chrome Store that we support it). The solution - for Wikipedia, their API is used, for Google Doc - a tricky code for getting the selected text and the entire document - so as not to ask the user for permission to access the entire Google Drive. Chose a dozen other popular sites and checked / adapted reading on them.
The mentor with the marketer decided that they needed a blog with social networks. He began to look for a static blogger - for speed, simplicity, low cost and security. If I ever open a blog for myself, then only as a product of a static generator, so that all posts are kept in Gita. From my good friend
Once having read about Go, love fast execution and all sorts of optimizations, I wrote a minimal test - HTTP GET - it turned out that Lambda worked out faster, the bulky benchmarks showed high speed. The following microservice wrote already on Go - now it is my main server language instead of Python. I liked the presence of the built-in `go fmt` tool for formatting the code, you know, everyone likes it, even though there are tabs. To convert a JSON string to an object, it is necessary to describe the structure in advance - after Python and JS it seemed incredible - why? Even more incredible it turned out that there is no contains () method in arrays or slices - I welcome minimalism, but is it really a correct language design when you need to write your own loop for such a basic thing? Other minor drawbacks of Go before Python - lambda deploy is a copied executable file - for example, 6 megabytes and not kilobytes of code (you have to wait a few seconds), and also more code (the level of abstraction is sometimes lower, but I like to better understand how it is working). It's nice that the code being compiled is safer - fewer errors in the runtime, and types in Python I already wrote with 3.5 - languages are faster with types (but types only for validation in Python) are clearer and safer. Golang also has an analogue of duck typing via implicit interfaces - if there are the necessary methods - then the object fits the interface.
I thought - why Go and not like Java? I did not test it myself, but I read that a cold start on Lambda will be longer. Perhaps you can write a lambda that will keep all other lambdas warm and use Java, perhaps. I don’t like to jump by technology, I prefer to go deeper and improve in the current stack, but here Go’s speed plus its overall positive assessment by the industry and the fact that Liamds now support it so much so that Amazon wrote all its SDKs and Go too - although this is technology from a rival corporation - the transition was worth it. In our small company on another project, they are also switching from Python to Go.
From Go, I liked one of the statements that A little copying is better than a little dependency , this is also one of my mottos, that is, I try not to bang the library to save five lines. One of my favorite extensions has 639 dependencies, you can imagine:
From the early stage, the extension was able to play from the context menu, and when it was playing, it was possible to pause and rewind to the chunk back and forth:
But it was decided to make the UI more convenient to the detriment of functionality - instead of the submenu, now there is only one item that adds a page or selected to the list:
This decision was difficult, but I see the main story by adding pages for listening later, but you can still listen right away - you just need to open the extension and play window.
The logo, as you can see, also changed - during the prototyping of the site, the girl designer put the dagger - this square seemed to us better than a parrot.
Testing: Selenium cannot open the extension window, so I use it in conjunction with pyautogui for clicks and scikit-image to compare the expected and current images. I have never done this before, this is interesting - this way I can test CSS.
All the code throughout the year (and earlier) I wrote in Vima. Learned more about this great editor. The time has come when I felt that Vime was really productive. Magic peace of software. In all of it, for me, Wim has become a feature of the industry that makes up the best parts. It has its own style. And it is preinstalled in many places - ssh anywhere - the working environment remains comfortable, I even have it out of the box in Android. Plug-ins extend functionality, and their asynchronous operation has recently been supported. I have analyzer linters, the ability to see the previous version of the hunk gita, some refactoring (renaming functions in all places), bookmarks in the code, color hexes are highlighted in color, and everywhere I have a dark color - I remember in Intelligent IDEA on several monitors in external Windows could not get rid of the white frame Makovsky window.Saw and more sophisticated plugins like hints, documentation when writing, integration with external utilities, but in Vime there are so many things hidden — and external commands to the selected text can be easily performed - for example, count the number of characters (wc ) or translate selected text ( trans ). I heard complaints several times that something cannot be done in Vima - but in fact it is possible. It was possible to work on Salesforce using the corresponding plugin - right from Wima I ran tests on a remote server. I remember how I perceived phreaking when I heard that someone works in Vima or Emax, but this also happened to me. I don’t urge to try - it really takes time to figure out how to do basic operations, you need to invest time and effort to get to the pulp.
Today’s Chrome Store analytics:
Change in growth rates between December and February - we added localization to extension to all languages that Polly reads - so now, for example, for French edition, we are higher. I think the localization of the site will give the same effect. Site statistics:
The growth turned out to be lower than planned, although there is no paid advertising - only organic traffic. Six people signed up for $ 6.99 per month. Perhaps over time, the numbers will start to grow. What do you think?
This is the story of my year.
Source: https://habr.com/ru/post/358374/
All Articles