DevConf: promising highload databases
DevConf 2018 next week! Last year, Yuri Nasretdinov made an interesting review of advanced storage systems for highload. Video with the report is available on the report page . And for habr-readers I offer short retelling.
 At the beginning I will tell you how to approach the choice of technology for a highload project.
At the beginning I will tell you how to approach the choice of technology for a highload project.
I will give examples of successful technologies.
')

MySQL and MongoDB started with very simple, oak solutions that simply work and have understandable flaws.
For which user case was Tarantool created? Imagine that you have a social network and user data spread over hundreds of mysql-servers. At the same time, users are scaled by user id. User logs in his email and wants to log in.

The obvious way is to shard users by email. But, people also have a phone number, by which he also wants to log in. Accordingly, the second obvious way out is a kind of database, fast, which contains correspondences email => userId, phone => userId and it is desirable that such a database is persistent. But at that time there were no such databases, as one of the options at that time was to put it all into memkes. But let's say the operation of adding a new field for userId search will be very difficult. There are a lot of problems with memokes, but at least it can withstand a lot of reading and writing.
So, Tarantool. Stores all data in memory. And, at the same time, on the disk. According to the developers, withstands 1 million requests per second to the processor core. Developed in mail.ru. Konstantin Osipov, one of the developers of Tarantool, used to develop MySQL.
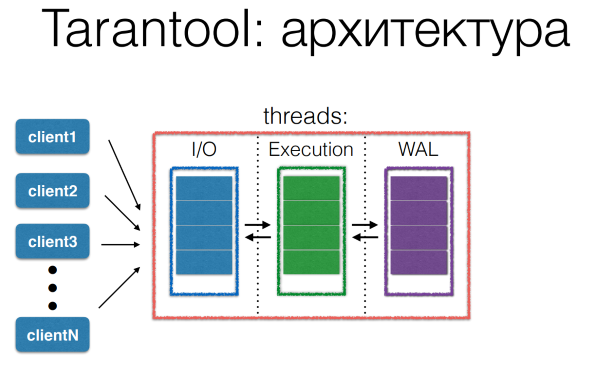
The processing of requests in Tarantool has a pipeline architecture. Many clients request the Tarantool server. All these requests are stored in a queue in the I / O thread. Then he passes them through at intervals. Thus, blocking the execution thread takes a fairly short time.

Separately, it is worth mentioning persistence. If someone uses redis with persistence, he probably notices that the radish "sticks" for a rather long period of time at the moment when the fork creation process is in progress. Tarantool has another model. Up to version 1.6.7, he kept a part of the memory in a shared region and during fork it is not copied. And while the forked child is being written to disk, parent knows that it’s impossible to touch this piece of memory. Since version 1.6.7, they have completely abandoned the fork. They support, one might say, the virtual memory mechanism in the user-space. User-space memory address translation. Instead of creating a fork process, a thread is created that goes over the user’s space snapshot and writes consistent snapshot to disk.
For what situations is Tarantool suitable:
When not to use it:
Created by Yandex just for analytics. For systems like Yandex. The analytics needed databases:
At that time there was no product meeting all three criteria. Possible solutions:
Yandex first used MySQL. but then I wrote ClickHouse, a distributed analytics database that stores data across columns, optimized for HDD (SSD is quite expensive) and extremely fast (it can scan up to a billion records per second). It has already been tested in Yandex production. ClickHouse only supports inserting and querying data. No deletion and editing.

Data is stored by monthly partitions. In each partition, the data is sorted in ascending order of the primary key. The “primary key” in this case is not very correct, since its uniqueness is not guaranteed.
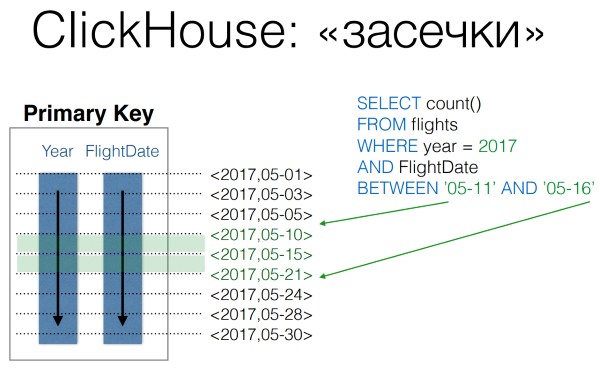
In order to be able to quickly search by the primary key in ClickHouse, the “serif” files are used, where once in a certain number of records the serifs with the primary key value are made and where it is located. This allows you to perform queries with a range of primary key with a small number of disk operations.
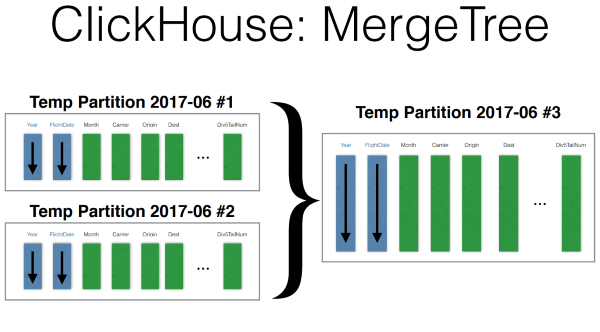
Insert happens like this. Data is written to a temporary partition, sorted. After that, the background process, when recording stops for some time, merge these partitions.
ClickHouse features:
Usage scenarios:
When not to use:

The prerequisites of creation are the same as in Tarantool. There is a user base spread across servers. And you need to search, for example by email or phone. But if Tarantool in our example acts as such a high-level index to the shards of the database, then CockroachDB offers to keep everything at home.
Possible solutions before CockroachDB:
Google Cloud Spanner
Authorizer + manual sharding (as we have already reviewed with Tarantool)
MongoDB, Cassandra - do not support distributed unique indexes.
Initially, CockroachDB was created as a distributed Key-Value Storage, but current realities suggest that few need a new Key-Value database. Everyone wants SQL. It supports SQL, JOIN, transactions, ACID, unique indexes, automatic sharding. Created by Google Spanner. Written on Go. Almost from the first time was tested Jepsen. And already used in production in Baidu.
How does the relational model fit the Key-Value store? Manually this can be organized quite simply. I will give a strongly simplified version. In CockroachDB, it's all a bit more complicated. The keys are pretty simple - the name of the table / value of the primary key / the name of the field.

Secondary indices are also pretty understandable. Another key with the name of the index. In the case of a non-unique index, along with the value of the primary key.


The data is stored in a rather trivial way, but it seems to me very correct. The global sorted Key-Value map is divided into regions, which the base tries to maintain at about 64 MB. Each of these regions is replicated to several nodes, and one of these nodes for the region is the Raft leader, i.e. the whole record (probably reading too) goes into it. Now imagine that some kind of node fell out. Raft allows you to quickly select a new leader for each region. Thus, both writing and reading will be available.
One of the main features is support for distributed transactions. When it is necessary to change data on several nodes transactionally. They are implemented so. There is a system table with a list of transactions. When modifying the value of a key, a key with a transaction number is added next. When reading such a key, the transaction table looks like, whether it is committed or not, and the desired value is selected. If successful, the values are replaced by the final ones. Failed transactions are cleared by the garbage collector.
In the future, CockroachDB may well be used as the main database of a large project. Now it is too early, since the 1.0 release was released quite recently.
When not to use:
As you can see from the description of the CockroachDB distributed transaction algorithm, this process is not fast. If the project requires low latency or high Queries per second - not worth it. Recording is also not the fastest.
If you do not need strict consistency. Although for a distributed database it is quite an important factor. Conventionally, if you need to send a message from one user to another, then records about it should appear on the server of the author of the message and on the server of the person to whom this message was sent, and it is desirable to do this atomically.
In conclusion, I want to say that each tool must be chosen wisely, clearly understanding the tasks it is solving and its limitations. Do not listen to me and check everything yourself.
This year is also a rather interesting section of Storage . Come share experiences. Habrachitatelemi discount .
- First of all, there should be an understanding of how it works. Not only strengths, but also weaknesses.
- Knowledge of how to monitor and back it up. Without good tools for this, it is early to use this technology in production.
- Sooner or later, the systems “fall” (this is a normal, regular situation) and you need to know what to do in this case.
I will give examples of successful technologies.
')
MySQL and MongoDB started with very simple, oak solutions that simply work and have understandable flaws.
Tarantool
For which user case was Tarantool created? Imagine that you have a social network and user data spread over hundreds of mysql-servers. At the same time, users are scaled by user id. User logs in his email and wants to log in.
The obvious way is to shard users by email. But, people also have a phone number, by which he also wants to log in. Accordingly, the second obvious way out is a kind of database, fast, which contains correspondences email => userId, phone => userId and it is desirable that such a database is persistent. But at that time there were no such databases, as one of the options at that time was to put it all into memkes. But let's say the operation of adding a new field for userId search will be very difficult. There are a lot of problems with memokes, but at least it can withstand a lot of reading and writing.
So, Tarantool. Stores all data in memory. And, at the same time, on the disk. According to the developers, withstands 1 million requests per second to the processor core. Developed in mail.ru. Konstantin Osipov, one of the developers of Tarantool, used to develop MySQL.
The processing of requests in Tarantool has a pipeline architecture. Many clients request the Tarantool server. All these requests are stored in a queue in the I / O thread. Then he passes them through at intervals. Thus, blocking the execution thread takes a fairly short time.
Separately, it is worth mentioning persistence. If someone uses redis with persistence, he probably notices that the radish "sticks" for a rather long period of time at the moment when the fork creation process is in progress. Tarantool has another model. Up to version 1.6.7, he kept a part of the memory in a shared region and during fork it is not copied. And while the forked child is being written to disk, parent knows that it’s impossible to touch this piece of memory. Since version 1.6.7, they have completely abandoned the fork. They support, one might say, the virtual memory mechanism in the user-space. User-space memory address translation. Instead of creating a fork process, a thread is created that goes over the user’s space snapshot and writes consistent snapshot to disk.
For what situations is Tarantool suitable:
- You have a lot of reading / writing clients.
- Lots of small read / write.
- When you have a need for some kind of central storage and working set gets into memory. Tarantool does not support sharding yet.
- The desire to write stored procedures. Tarantool supports them on Lua.
- Authorization, sessions, counters.
When not to use it:
- If needed: automatic sharding and failover, Raft / Paxos, long transactions.
- Few clients and the requirement of minimal latency. Because of the pipeline architecture, latency will be more than the minimum possible.
- The working set does not fit into the memory. Kostya Osipov has just talked about the new Vinyl engine for Tarantool, but I recommend you check it out first.
- Well, my personal opinion: Tarantool is not suitable for analytics tasks. Despite the fact that the data he keeps everything in memory, but he keeps them not as it should for these tasks.
Clickhouse
Created by Yandex just for analytics. For systems like Yandex. The analytics needed databases:
- Efficient and linearly scalable.
- Analytics in realtime.
- Free and open source.
At that time there was no product meeting all three criteria. Possible solutions:
- MySQL (MyISAM) - fast write, slow read
- Vertica, Exasol - paid
- Hadoop - write works, but reading is not realtime.
Yandex first used MySQL. but then I wrote ClickHouse, a distributed analytics database that stores data across columns, optimized for HDD (SSD is quite expensive) and extremely fast (it can scan up to a billion records per second). It has already been tested in Yandex production. ClickHouse only supports inserting and querying data. No deletion and editing.
Data is stored by monthly partitions. In each partition, the data is sorted in ascending order of the primary key. The “primary key” in this case is not very correct, since its uniqueness is not guaranteed.
In order to be able to quickly search by the primary key in ClickHouse, the “serif” files are used, where once in a certain number of records the serifs with the primary key value are made and where it is located. This allows you to perform queries with a range of primary key with a small number of disk operations.
Insert happens like this. Data is written to a temporary partition, sorted. After that, the background process, when recording stops for some time, merge these partitions.
ClickHouse features:
- SQL limited JOIN.
- Replication and work in a cluster. Supported, but we must try.
- 17 (probably already more) Group by.
- Materialized views, global JOIN's.
- Sampling samples. When can be optimally read only part of the data. For example, only for a specific user in Yandex. Analytics.
Usage scenarios:
- Tasks realtime analytics.
- Time-series - github.com/yandex/graphouse
- Storage of raw data, which ClickHouse can very quickly aggregate. Impressions, clicks, logs, etc.
When not to use:
- OLTP tasks (no transactions)
- Work with money (no transactions)
- Storage of aggregated data (does not make sense)
- Map / Reduce tasks. (Many of them are perfectly solved using SQL)
- Full-text search (not intended)
Cockroachdb
The prerequisites of creation are the same as in Tarantool. There is a user base spread across servers. And you need to search, for example by email or phone. But if Tarantool in our example acts as such a high-level index to the shards of the database, then CockroachDB offers to keep everything at home.
Possible solutions before CockroachDB:
Google Cloud Spanner
Authorizer + manual sharding (as we have already reviewed with Tarantool)
Initially, CockroachDB was created as a distributed Key-Value Storage, but current realities suggest that few need a new Key-Value database. Everyone wants SQL. It supports SQL, JOIN, transactions, ACID, unique indexes, automatic sharding. Created by Google Spanner. Written on Go. Almost from the first time was tested Jepsen. And already used in production in Baidu.
How does the relational model fit the Key-Value store? Manually this can be organized quite simply. I will give a strongly simplified version. In CockroachDB, it's all a bit more complicated. The keys are pretty simple - the name of the table / value of the primary key / the name of the field.
Secondary indices are also pretty understandable. Another key with the name of the index. In the case of a non-unique index, along with the value of the primary key.
The data is stored in a rather trivial way, but it seems to me very correct. The global sorted Key-Value map is divided into regions, which the base tries to maintain at about 64 MB. Each of these regions is replicated to several nodes, and one of these nodes for the region is the Raft leader, i.e. the whole record (probably reading too) goes into it. Now imagine that some kind of node fell out. Raft allows you to quickly select a new leader for each region. Thus, both writing and reading will be available.
One of the main features is support for distributed transactions. When it is necessary to change data on several nodes transactionally. They are implemented so. There is a system table with a list of transactions. When modifying the value of a key, a key with a transaction number is added next. When reading such a key, the transaction table looks like, whether it is committed or not, and the desired value is selected. If successful, the values are replaced by the final ones. Failed transactions are cleared by the garbage collector.
In the future, CockroachDB may well be used as the main database of a large project. Now it is too early, since the 1.0 release was released quite recently.
When not to use:
As you can see from the description of the CockroachDB distributed transaction algorithm, this process is not fast. If the project requires low latency or high Queries per second - not worth it. Recording is also not the fastest.
If you do not need strict consistency. Although for a distributed database it is quite an important factor. Conventionally, if you need to send a message from one user to another, then records about it should appear on the server of the author of the message and on the server of the person to whom this message was sent, and it is desirable to do this atomically.
In conclusion, I want to say that each tool must be chosen wisely, clearly understanding the tasks it is solving and its limitations. Do not listen to me and check everything yourself.
This year is also a rather interesting section of Storage . Come share experiences. Habrachitatelemi discount .
Source: https://habr.com/ru/post/358286/
All Articles