Women's networks: who makes the choice for us?
The rise of interest in machine learning is largely due to the fact that models are able to give a significant increase in profits in areas related to the prediction of the behavior of complex systems. In particular, the complex system whose behavior to predict is profitable is a person. To detect fraud at an early stage, to identify the tendency of customers to outflow - these tasks arise regularly and have already become classic in Data Science. Of course, they can be solved by various methods, depending on the preferences of a particular specialist and on the requirements of the business.
We had the opportunity to use neural networks to solve the problem of predicting the behavior of people, and the specificity of the application area was associated with the beauty industry. The main audience for the "experiences" were women. We basically came to the question: can an artificial neural network understand a real neural network (human) in an area in which even the person himself has not yet realized his behavior. As we answered this question and what we got in the end, you can find out further.

The British marketing agency offered our team to optimize marketing communications for several brands from the beauty industry. To solve this problem, we had to carry out an assault on buyers from different sides. As a result, we built a number of predictive and recommendatory models that help to find an individual approach to each of the buyers. Along the way, we decided on several important business points, and his key KPIs have grown up.
')
Any retailer wants to increase their sales. To do this, we need to offer the goods that the customer will most likely buy, using the most optimal communication channel, and do it at the right time. Thus, first of all, the store needs a recommendation system, as well as systematic orchestration of channels and several predictive models. This AI task we took, CleverDATA , commissioned by the agency Beauty Brains.

In the arsenal of brands there was a history of customer purchases, a history of customer visits to the site, as well as information on mailings and reactions to mailings from each recipient. Thus, we could see which emails the client received, which of them opened, which links it went to and what it led to.
To begin with, we made a recommender system using classical methods: matrix decomposition, collaborative filtering, association rules, etc. Then we decided to experiment whether it was possible to do something more effective for our particular case, and we came to the recommendation system on neural networks.
The advantage of the new experimental system was that it used, firstly, additional information about the products from their text descriptions, and secondly, the sequence of customer purchases was taken into account.
Then we began to connect various channels of communication: first of all, the mailing list, which is one of the cheapest channels. In addition, Facebook messages and advertisements via Adwords began to be delivered to recipients.
As a result, we have prepared a self-driving solution for marketers of the customer, which is a daily set of highly personalized newsletters. Naturally, the number of campaigns has significantly increased, and the number of recipients of each of them has dramatically decreased. That is, we have provided the marketer with a set of “micro-campaigns” as an instrument, where each specific customer receives an offer with the most relevant product on individual conditions (with a personal discount, gifts, probes, if the latter are interested in the customer, etc.).
In addition, we had at our disposal the knowledge gained from analyzing a large array of beauty blogs. I already wrote about the results of the analysis of this corpus in Habré .
Of course, in the mailing lists, LTV-prediction, prediction of outflow, calculation of loyalty, prediction of a suitable discount, as well as prediction of customer susceptibility to gifts and probes are used. The more likely that the customer will make a purchase soon, the lower the discount he gets. And if there were no purchases for a long time, a person falls into the group of customers whom the brand risks losing, and the discounts for it increase.
Testing of the system was conducted during September-December 2017, as a result the project was recognized as successful. Next, I will consider the specific case that we had to solve within the project.
 A source
A source
The number of people subscribed to the newsletter is usually much greater than the number of buyers. Naturally, there is a group of addressees in which the probability of the first purchase is increased. We can target additional advertising campaigns to these people, but we cannot launch additional campaigns on the entire contact database, since they require an additional budget.
Those. we need to predict people's behavior and run campaigns only on a narrow target audience. There is no additional information about these potential customers, the brand only knows how they opened the letters and what links they followed. Therefore, we came to the task of teaching the machine to understand the behavior of people.
This problem can be solved in many ways. We went in the direction of neural networks.
So, we will work with the sequence of actions of the recipient of the mailing,
recurrent neural networks are well suited for processing a series of events (they are often used for word processing). About this family has been repeatedly written on Habré (for example, here or here ). Recurrent neural networks in their classical implementation have a number of characteristic problems, for example, they quickly forget. If we train the classic recurrent neural network on the book, then by the middle of the chapter, it will forget how this chapter began.
Today, LSTM neural networks, which have managed to overcome many of the problems of classical neural networks, have become widespread. LSTM neural networks have memory: they operate on cells that can memorize, play, and forget information. In addition, LTSM networks are good when events are separated by time lags with indefinite duration and boundaries.
 A source
A source
In principle, you can train an LSTM neural network based on the actions of the recipients of the mailing list, but such a model will deal well with only one type of behavior, and the signs obtained from this model will be difficult to interpret and even harder to use in other models without looking inadvertently the future: if we train the model on a specific target action, then this model should have information about the future — whether the person will perform the target action in the future on the model in the training sample of the training objects.
If we are planning to use the result of the model in other models, then it is necessary to carefully monitor that the information about the future does not go along with the predictions of the model. If information about the future inadvertently happens, the new model will be retrained. Therefore, for later use, it will be more convenient to train on events without knowing their result, and to reduce the sequence of events into signs that could later be used in other predictive models. And the autoencoder, or the autocoder can help us in this.
About autoencoders on Habré can also be read, for example, here and here . They are constructed so that they have the same dimension at the input and output, and the dimension in the middle is much smaller. This restriction causes the neural network to look for generalizations and correlations in the sequence of events, so the auto-encoders are forced to somehow generalize the incoming data.
In training such a network, the principle of reverse propagation of error is used, as in training with a teacher, however, we can require that the input signal and the output signal of the network be as close as possible. As a result, we will train without using information about the result to which the sequence of actions led, i.e. get training without a teacher.
 Source of The autocoder is able to effectively reduce the dimension of the feature space: the smaller the “bottleneck” dimension, the stronger the compression, but the higher the information loss.
Source of The autocoder is able to effectively reduce the dimension of the feature space: the smaller the “bottleneck” dimension, the stronger the compression, but the higher the information loss.
The general structure of our neural network is clear: it will be an autoencoder using LSTM cells. It remains to decide how to encode the sequence of actions of a potential buyer. One option is one-hot-encoding: the action is encoded by one, the other action alternatives are zero.

The first problem that arises here is the way people go from receiving a marketing newsletter to purchasing on a website, which is different in length. It is easy to cope with it: we take a fixed length of the sequence of vectors, discarding the excess, filling the missing with zeros. The network quickly learns to understand that the extra zeros at the beginning of the sequence of events do not need to pay attention.

And now it’s worth thinking that different people need different times to get a letter, follow the links and make a purchase. Time plays a significant role in understanding human behavior. How to take into account the time sequence of client actions We added the time difference between the events as an additional element of the vector encoding the actions of the recipient.

If the difference between events in seconds, in some cases, the time component of the vector component will reach 10 3 -10 6 , which will adversely affect the training of the network. A better solution would be to use the logarithm of the time difference between the events. For a successful neural network training, it is recommended to work with numbers in the range from zero to one, therefore it is even better to normalize the logarithm of the time difference and add it as another element of the recipient's action vector. The time difference for the last event can be taken as the difference between the last event and the current point in time.
At one of the brands we received datasets from several thousand companies sent to ~ 200,000 people. Thus, the training sample consisted of approximately 200,000 vectors encoding a sequence of actions for mailing recipients.
At the beginning of the encoder we set the layer of LSTM-cells, which will translate a series of events into a vector containing information about the entire sequence. You can make a series of consecutive LSTM layers, gradually reducing their dimension. To return the representation from the vector to the sequence of events, we repeat this vector n times before submitting it to the input of the LSTM decoder layer. The general scheme of such an auto encoder on keras will take literally several lines and is shown below. Note that the LSTM decoder layer should not return a vector, but a sequence, which is indicated by the parameter return_sequences = True .
If nothing is confused with the dimensions of the tensors, then the network will train. In the future, to improve the quality of the model, we added several additional LSTM layers both to the encoder and to the decoder, and as the “bottleneck” we used several ordinary fully connected layers of neurons, naturally, not forgetting Dropout, Batch Normalization and other techniques for training neural networks.
For comparison, we tried to train the actor on convolutional neural networks (onvolution Neural Networks, CNN) on the same data set. Convolutional layers help to establish patterns of behavior of objects and reduce the number of model parameters, which significantly speeds up learning. About convolutional neural networks, too, there are articles on Habré ( here , here and, for example, here ), so we will not dwell on them in detail. Schematically, the architecture of the autocoder on convolutional neural networks is as follows:
Since the elements of tensors take values in the range from 0 to 1, then you can use the function of cross-loss entropy (binary crossentropy).
The CNN auto-encoder learning result on the quality metric was even higher than the LSTM auto-encoder, and the learning time is noticeably faster.
In addition, it is possible to make an auto-encoder on CNN and LSTM: first several convolutional layers, then an auto-encoder based on LSTM, terminated by a decoder based on convolutional layers. This auto-encoder will combine the positive aspects of both approaches. In our experience, such an auto-encoder is slightly better than an auto-encoder on CNN and much better than an auto-encoder on LSTM in terms of quality metrics in a validation sample.
After training, the encoder translates a sequence of actions for each recipient into a feature vector, and thus we get an analogue of word2vec for a series of events. The resulting vector may be used in other predictive models, clustering, searching for people who are close in behavior, and also performing anomaly search.
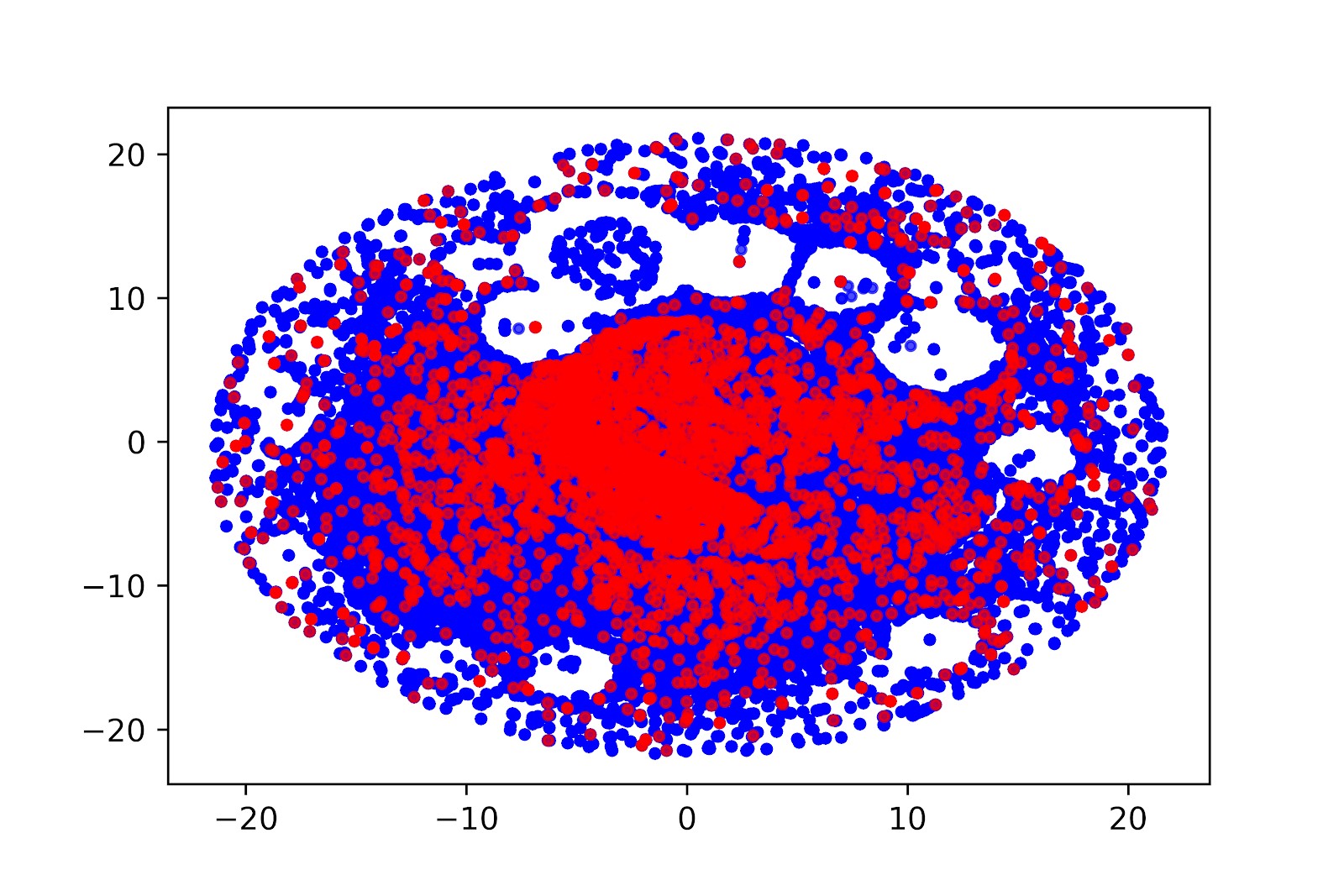 The projection on the two-dimensional space of the vectors of behavior of the recipients of letters received by the auto-encoder (t-SNE) Red dots are recipients making a purchase in the near future, blue dots are recipients who have not made a purchase. It is seen that there are areas in which inert recipients predominate, and there are areas with a high concentration of future buyers.
The projection on the two-dimensional space of the vectors of behavior of the recipients of letters received by the auto-encoder (t-SNE) Red dots are recipients making a purchase in the near future, blue dots are recipients who have not made a purchase. It is seen that there are areas in which inert recipients predominate, and there are areas with a high concentration of future buyers.
In our case, we built a model that predicts the likelihood of buying the recipient of the letter. The model on a number of basic signs gave roc-auc 0.74–0.77, and with the added vectors responsible for human behavior, roc-auc reached 0.84–0.88.
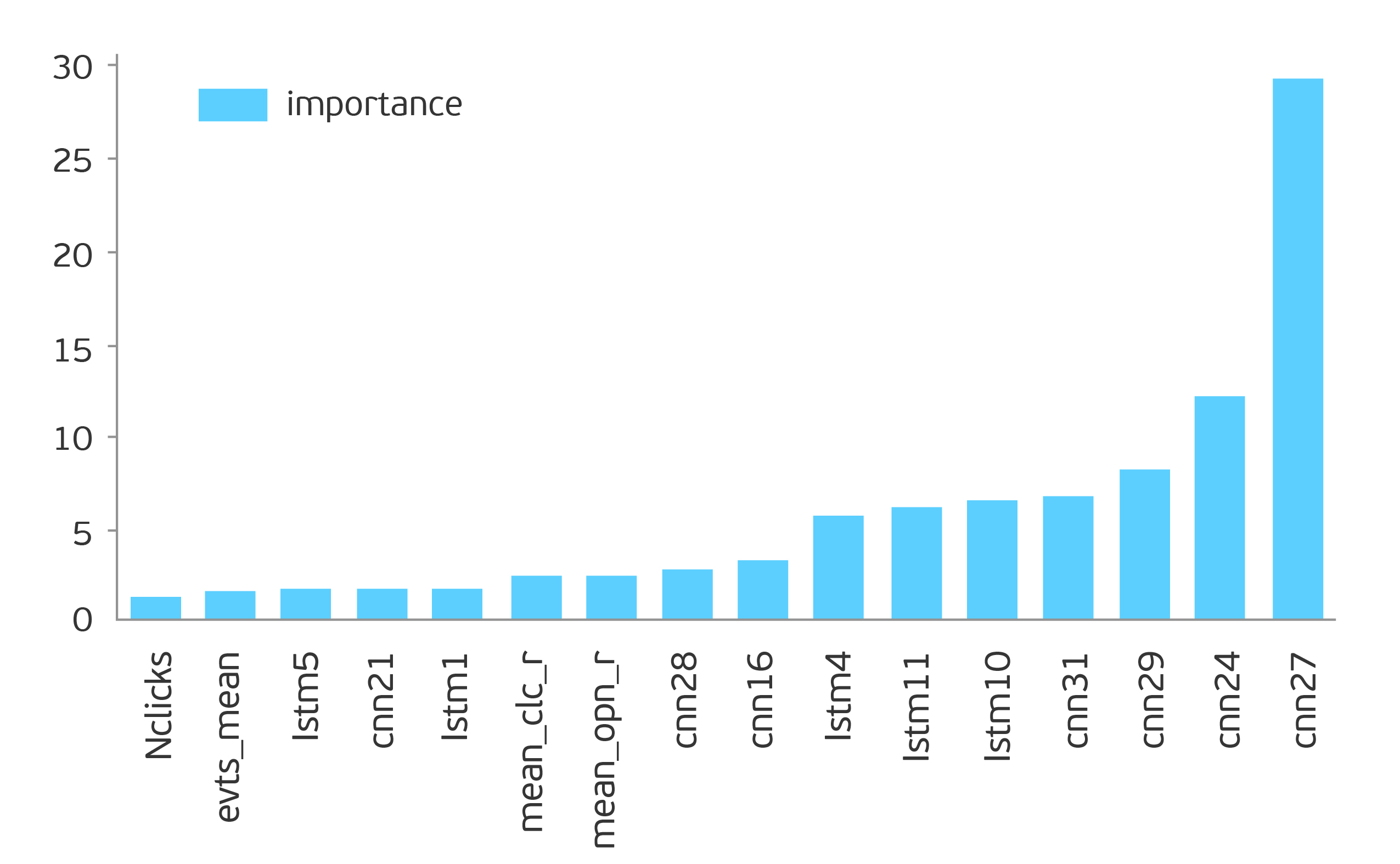 In the list of the most significant signs, the dominant position is occupied by signs from two auto-encoders: based on LSTM and CNN.
In the list of the most significant signs, the dominant position is occupied by signs from two auto-encoders: based on LSTM and CNN.
It must be recognized that the use of CNN-based autocoder for this task gave a better result, however, the LSTM autocoder gave a vector of smaller dimension and allowed roc-auc to be adjusted a little further. If we use the signs based on the auto-encoder CNN + LSTM, then roc-auc is obtained in the range of 0.82-0.87.
 Comparison of ROC curves of two models: roc-auc models on the main features 0.74-0.77, roc-auc models on the main features and signs of the autocoder 0.84-0.88.
Comparison of ROC curves of two models: roc-auc models on the main features 0.74-0.77, roc-auc models on the main features and signs of the autocoder 0.84-0.88.
Our experience confirmed the fact that it is possible to encode the behavior of people on the neural networks by means of an auto-encoder: in our case, the sequence of behavior of the distribution recipients was encoded using the auto-encoders on LSTM and on CNN-architectures. The use of this approach is not limited to sending letters: the encoded behavior of objects can be used in other tasks that require working with human behavior: search for fraudulent actions, prediction of outflow, search for anomalies, etc.
The proposed approach can be developed in the direction of variational auto-encoders, if there is a need for modeling the behavior of people.
The fact that the CNN based autocoder copes with the task considered better than on LSTM suggests that behavior patterns allow for this task to extract more informative features than features based on temporal connections between events. Nevertheless, on the prepared data set it is possible to use both approaches, and the total effect of the combined use of features of both auto-encoders gives an increase to roc-auc by 0.01-0.02.
Thus, neural networks are able to understand from the behavior of a person that he is inclined to purchase, perhaps even before the person himself realizes this. An amazing example of the fractality of our world: people's neurons help organize the training of neural networks in order to predict the result of the work of other people's neurons.

We had the opportunity to use neural networks to solve the problem of predicting the behavior of people, and the specificity of the application area was associated with the beauty industry. The main audience for the "experiences" were women. We basically came to the question: can an artificial neural network understand a real neural network (human) in an area in which even the person himself has not yet realized his behavior. As we answered this question and what we got in the end, you can find out further.
The British marketing agency offered our team to optimize marketing communications for several brands from the beauty industry. To solve this problem, we had to carry out an assault on buyers from different sides. As a result, we built a number of predictive and recommendatory models that help to find an individual approach to each of the buyers. Along the way, we decided on several important business points, and his key KPIs have grown up.
')
Instead of massive bombardment with advertising, we use point personalized offers.
Any retailer wants to increase their sales. To do this, we need to offer the goods that the customer will most likely buy, using the most optimal communication channel, and do it at the right time. Thus, first of all, the store needs a recommendation system, as well as systematic orchestration of channels and several predictive models. This AI task we took, CleverDATA , commissioned by the agency Beauty Brains.
In the arsenal of brands there was a history of customer purchases, a history of customer visits to the site, as well as information on mailings and reactions to mailings from each recipient. Thus, we could see which emails the client received, which of them opened, which links it went to and what it led to.
To begin with, we made a recommender system using classical methods: matrix decomposition, collaborative filtering, association rules, etc. Then we decided to experiment whether it was possible to do something more effective for our particular case, and we came to the recommendation system on neural networks.
The advantage of the new experimental system was that it used, firstly, additional information about the products from their text descriptions, and secondly, the sequence of customer purchases was taken into account.
Then we began to connect various channels of communication: first of all, the mailing list, which is one of the cheapest channels. In addition, Facebook messages and advertisements via Adwords began to be delivered to recipients.
As a result, we have prepared a self-driving solution for marketers of the customer, which is a daily set of highly personalized newsletters. Naturally, the number of campaigns has significantly increased, and the number of recipients of each of them has dramatically decreased. That is, we have provided the marketer with a set of “micro-campaigns” as an instrument, where each specific customer receives an offer with the most relevant product on individual conditions (with a personal discount, gifts, probes, if the latter are interested in the customer, etc.).
In addition, we had at our disposal the knowledge gained from analyzing a large array of beauty blogs. I already wrote about the results of the analysis of this corpus in Habré .
Of course, in the mailing lists, LTV-prediction, prediction of outflow, calculation of loyalty, prediction of a suitable discount, as well as prediction of customer susceptibility to gifts and probes are used. The more likely that the customer will make a purchase soon, the lower the discount he gets. And if there were no purchases for a long time, a person falls into the group of customers whom the brand risks losing, and the discounts for it increase.
Testing of the system was conducted during September-December 2017, as a result the project was recognized as successful. Next, I will consider the specific case that we had to solve within the project.
We learn networks to understand people. What tools to choose?
The number of people subscribed to the newsletter is usually much greater than the number of buyers. Naturally, there is a group of addressees in which the probability of the first purchase is increased. We can target additional advertising campaigns to these people, but we cannot launch additional campaigns on the entire contact database, since they require an additional budget.
Those. we need to predict people's behavior and run campaigns only on a narrow target audience. There is no additional information about these potential customers, the brand only knows how they opened the letters and what links they followed. Therefore, we came to the task of teaching the machine to understand the behavior of people.
This problem can be solved in many ways. We went in the direction of neural networks.
So, we will work with the sequence of actions of the recipient of the mailing,
recurrent neural networks are well suited for processing a series of events (they are often used for word processing). About this family has been repeatedly written on Habré (for example, here or here ). Recurrent neural networks in their classical implementation have a number of characteristic problems, for example, they quickly forget. If we train the classic recurrent neural network on the book, then by the middle of the chapter, it will forget how this chapter began.
Today, LSTM neural networks, which have managed to overcome many of the problems of classical neural networks, have become widespread. LSTM neural networks have memory: they operate on cells that can memorize, play, and forget information. In addition, LTSM networks are good when events are separated by time lags with indefinite duration and boundaries.
In principle, you can train an LSTM neural network based on the actions of the recipients of the mailing list, but such a model will deal well with only one type of behavior, and the signs obtained from this model will be difficult to interpret and even harder to use in other models without looking inadvertently the future: if we train the model on a specific target action, then this model should have information about the future — whether the person will perform the target action in the future on the model in the training sample of the training objects.
If we are planning to use the result of the model in other models, then it is necessary to carefully monitor that the information about the future does not go along with the predictions of the model. If information about the future inadvertently happens, the new model will be retrained. Therefore, for later use, it will be more convenient to train on events without knowing their result, and to reduce the sequence of events into signs that could later be used in other predictive models. And the autoencoder, or the autocoder can help us in this.
About autoencoders on Habré can also be read, for example, here and here . They are constructed so that they have the same dimension at the input and output, and the dimension in the middle is much smaller. This restriction causes the neural network to look for generalizations and correlations in the sequence of events, so the auto-encoders are forced to somehow generalize the incoming data.
In training such a network, the principle of reverse propagation of error is used, as in training with a teacher, however, we can require that the input signal and the output signal of the network be as close as possible. As a result, we will train without using information about the result to which the sequence of actions led, i.e. get training without a teacher.
The general structure of our neural network is clear: it will be an autoencoder using LSTM cells. It remains to decide how to encode the sequence of actions of a potential buyer. One option is one-hot-encoding: the action is encoded by one, the other action alternatives are zero.
The first problem that arises here is the way people go from receiving a marketing newsletter to purchasing on a website, which is different in length. It is easy to cope with it: we take a fixed length of the sequence of vectors, discarding the excess, filling the missing with zeros. The network quickly learns to understand that the extra zeros at the beginning of the sequence of events do not need to pay attention.
And now it’s worth thinking that different people need different times to get a letter, follow the links and make a purchase. Time plays a significant role in understanding human behavior. How to take into account the time sequence of client actions We added the time difference between the events as an additional element of the vector encoding the actions of the recipient.
If the difference between events in seconds, in some cases, the time component of the vector component will reach 10 3 -10 6 , which will adversely affect the training of the network. A better solution would be to use the logarithm of the time difference between the events. For a successful neural network training, it is recommended to work with numbers in the range from zero to one, therefore it is even better to normalize the logarithm of the time difference and add it as another element of the recipient's action vector. The time difference for the last event can be taken as the difference between the last event and the current point in time.
At one of the brands we received datasets from several thousand companies sent to ~ 200,000 people. Thus, the training sample consisted of approximately 200,000 vectors encoding a sequence of actions for mailing recipients.
From theory to practice
At the beginning of the encoder we set the layer of LSTM-cells, which will translate a series of events into a vector containing information about the entire sequence. You can make a series of consecutive LSTM layers, gradually reducing their dimension. To return the representation from the vector to the sequence of events, we repeat this vector n times before submitting it to the input of the LSTM decoder layer. The general scheme of such an auto encoder on keras will take literally several lines and is shown below. Note that the LSTM decoder layer should not return a vector, but a sequence, which is indicated by the parameter return_sequences = True .
from keras.layers import Input, LSTM, RepeatVector from keras.models import Model inputs = Input(shape=(timesteps, input_dim)) encoded = LSTM(latent_dim)(inputs) decoded = RepeatVector(timesteps)(encoded) decoded = LSTM(input_dim, return_sequences=True)(decoded) sequence_autoencoder = Model(inputs, decoded) encoder = Model(inputs, encoded) If nothing is confused with the dimensions of the tensors, then the network will train. In the future, to improve the quality of the model, we added several additional LSTM layers both to the encoder and to the decoder, and as the “bottleneck” we used several ordinary fully connected layers of neurons, naturally, not forgetting Dropout, Batch Normalization and other techniques for training neural networks.
For comparison, we tried to train the actor on convolutional neural networks (onvolution Neural Networks, CNN) on the same data set. Convolutional layers help to establish patterns of behavior of objects and reduce the number of model parameters, which significantly speeds up learning. About convolutional neural networks, too, there are articles on Habré ( here , here and, for example, here ), so we will not dwell on them in detail. Schematically, the architecture of the autocoder on convolutional neural networks is as follows:
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D from keras.models import Model input_tensor = Input(shape=input_dim) x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_tensor) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_tensor, decoded) Since the elements of tensors take values in the range from 0 to 1, then you can use the function of cross-loss entropy (binary crossentropy).
The CNN auto-encoder learning result on the quality metric was even higher than the LSTM auto-encoder, and the learning time is noticeably faster.
In addition, it is possible to make an auto-encoder on CNN and LSTM: first several convolutional layers, then an auto-encoder based on LSTM, terminated by a decoder based on convolutional layers. This auto-encoder will combine the positive aspects of both approaches. In our experience, such an auto-encoder is slightly better than an auto-encoder on CNN and much better than an auto-encoder on LSTM in terms of quality metrics in a validation sample.
After training, the encoder translates a sequence of actions for each recipient into a feature vector, and thus we get an analogue of word2vec for a series of events. The resulting vector may be used in other predictive models, clustering, searching for people who are close in behavior, and also performing anomaly search.
In our case, we built a model that predicts the likelihood of buying the recipient of the letter. The model on a number of basic signs gave roc-auc 0.74–0.77, and with the added vectors responsible for human behavior, roc-auc reached 0.84–0.88.
It must be recognized that the use of CNN-based autocoder for this task gave a better result, however, the LSTM autocoder gave a vector of smaller dimension and allowed roc-auc to be adjusted a little further. If we use the signs based on the auto-encoder CNN + LSTM, then roc-auc is obtained in the range of 0.82-0.87.
findings
Our experience confirmed the fact that it is possible to encode the behavior of people on the neural networks by means of an auto-encoder: in our case, the sequence of behavior of the distribution recipients was encoded using the auto-encoders on LSTM and on CNN-architectures. The use of this approach is not limited to sending letters: the encoded behavior of objects can be used in other tasks that require working with human behavior: search for fraudulent actions, prediction of outflow, search for anomalies, etc.
The proposed approach can be developed in the direction of variational auto-encoders, if there is a need for modeling the behavior of people.
The fact that the CNN based autocoder copes with the task considered better than on LSTM suggests that behavior patterns allow for this task to extract more informative features than features based on temporal connections between events. Nevertheless, on the prepared data set it is possible to use both approaches, and the total effect of the combined use of features of both auto-encoders gives an increase to roc-auc by 0.01-0.02.
Thus, neural networks are able to understand from the behavior of a person that he is inclined to purchase, perhaps even before the person himself realizes this. An amazing example of the fractality of our world: people's neurons help organize the training of neural networks in order to predict the result of the work of other people's neurons.
By the way, there are vacancies in our company!
Source: https://habr.com/ru/post/358238/
All Articles