High overload: electronic archive on Alfresco ECM

The task of photo-fixation of goods at various stages of transportation is typical for a transport company. Employees of the company take pictures of the goods, upload the image to the ERP-system, from which it enters the electronic archive (EA). Each photo is accompanied by meta-information: the office of the sender, the recipient, the code and index of the flight, etc. The main task of the electronic archive is the organization of a flexible, convenient and, most importantly, quick search for photos by meta-information for the last 3 years.
As is often the case, there was a supplier who offered a boxed solution - a flexible ECM system on the Alfresco Community Edition 4.2.x platform, quickly implemented it and even passed a successful test at one branch. And they even MS SQL Server fastened to the Community Edition. As for the interaction protocol with ERP, in our case it is 1C, nobody really thought about it, the customer wanted the most convenient way for him to upload files to a folder on the server, so they began to use the good old FTP.
Houston, we have problems ...
The most interesting thing started later, when they launched the replication of 120 branches. The system crashed regularly due to non-valid Lucene indexes. When this situation occurred, it was necessary to manually rebuild the indices, which led to the unavailability of the system for a day. And for a logistics company of the federal scale, this is a rather critical period. During the restructuring, the files remained on the ball, and with each failure it was more and more difficult to load the “escaping” delta. The maximum files we could receive per day were 40–60 thousand for us. The web interface also did not differ in high search speed: the maximum number of users with running downloads was 20 people. You shouldn't even mention the scalability - the system could not cope with the current volumes. There was a question about the correctness of the choice of platform. And at this stage, our cooperation with this customer began.
There was no documentation for the system, but nobody canceled the reverse engineering. Understood the code, found errors and a lot of crutches, which make it clear that the system was simply not ready for high loads: the files were first stored on the server, then the samopisny scheduler looked through the target folder, loaded the files into memory and then processed them. It goes without saying that the Alfresco mechanisms were also tuned. For example, when uploading files, it was possible to postpone actions with documents on different transactions. But, unfortunately, nobody dealt with transaction management.
And here we made a fatal mistake - we began to finish the existing system.
We managed to run on all 120 branches, and for several months we tuned the system in which users work. We tried to optimize Lucene, resized a single file, run merge indexes, change Java machine parameters, etc.
During this time, the volumes increased several times to 100,000 documents per day, the size of the indices increased to a critical level of 100 GB, after which even the standard rebuilding of indices, which previously helped us out, was not always successfully completed - the process hung at the merge stage. And we understood - it is impossible to continue this life! It was decided to completely rewrite the decision. Who does not like to give up the old bad and someone else's decision and write his own good from the height of the experience? But the task was complicated by the fact that it was necessary to support the work of the existing solution while we were developing a new one, and then also to make the data migration. The task seemed realistic, and we were optimistic.
Top View: Solution Architecture
All code was rewritten to java (part of the backend code was written in Alfresco-built JavaScript). It was also decided to change the main DBMS from MS SQL to Postgresql (in fact, this is the first thing that comes to mind when we are talking about freely distributed relational databases). Completely redone solution architecture. They completely abandoned the use of the Alfresco Share interface, developed a user-friendly, customized web interface that accesses the web services we developed for receiving data. Alfresco now serves as a REST API. Added replication of the main database using Postgresql built-in tools, which allowed building reports from replication without loading the main database. Search and download data posted on 2 servers. Two copies of Alfresco were deployed instead of one: one is responsible for finding and displaying data, the other for downloading.
Both copies of Alfresco use the same base. Due to the separation of loading and viewing, lengthy operations at loading do not affect the viewing of data, and viewing and loading can work independently of each other. Ultimately this added system performance. The capacity of the system has grown and allowed uploading up to 200k photos per day, while the number of simultaneous users increased to 70-80.
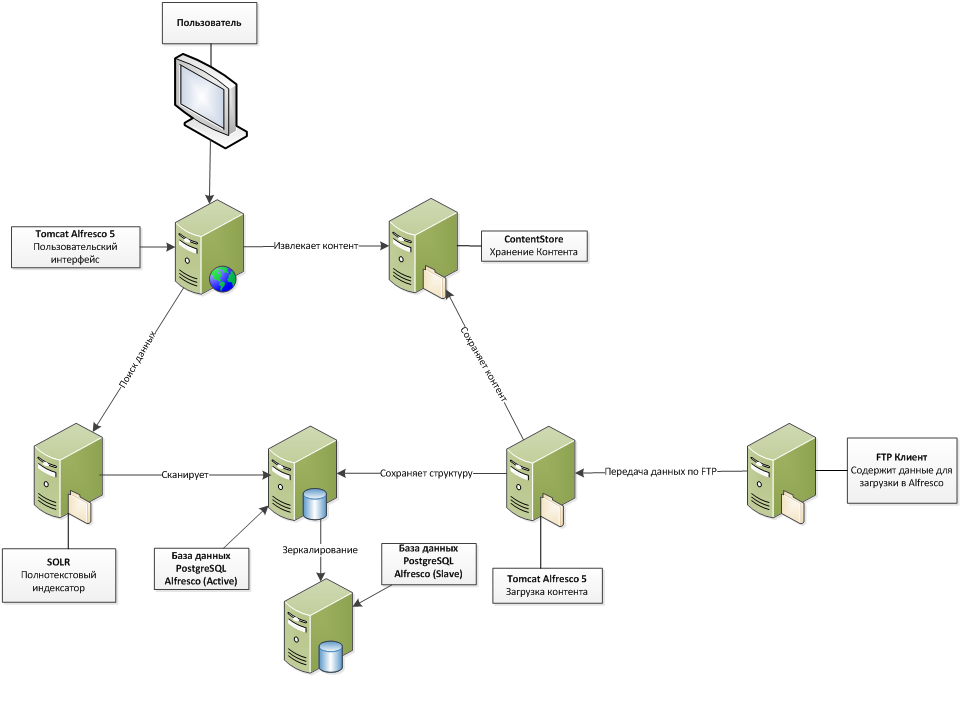
Figure 1. Solution architecture
Accelerate the download
In order to optimize system performance we:
')
- Redesigned file upload mechanism via FTP;
- Parallelized processing of XML files;
- Used a new search engine built into Alfresco 5.
FTP
The mechanism for uploading files via FTP has been revised. A virtual FTP server was implemented via Apache FTPServer. Since we have the usual maven project, we can connect any libraries. Now files are not stored on the server, but are processed immediately upon receipt, depending on the destination folder, the document type is determined. This greatly improved performance.
At once I will say that CMIS was not used, because interaction with the system via FTP was important for the customer.
XML processing
Also parallelized the processing of small blocks of xml files, manually determined the beginning and end of the transaction, by default, all actions with nodes (as all objects in Alfresco are called) are performed in one transaction.
New search engine
The transition to Alfresco 5 has provided a more reliable search engine. In our data structure, consistent requests are needed, that is, when loading, you may need objects that were loaded a second ago. SOLR does not support such queries, since it needs time to rebuild its indices. Alfresco 4 previously supported these requests via Lucene, but as described earlier, it has its own problems. In Alfresco 5, such queries are executed directly into the database (the query is transformed into a HQL query, which in turn is transformed into SQL, depending on the dialect specified). This innovation significantly increased the download speed and fault tolerance of the system.
Robot injects: barcode recognition
A task has been received to implement a bar code recognition system. Since the photos are processed and saved immediately, the task was solved by simply installing the Zbar library on the download server. A pool of running Zbar processes was implemented, the size of the pool is equal to the number of cores on the server (the number of threads is regulated separately). When uploading a photo, the photo is first “run” through Zbar, we receive a recognized barcode (as a string) in response to it, and if a document is loaded in the system, in the metadata of which this barcode is present, such a document is linked to a photo which further allows you to see the photo on the web interface when searching for a document.
We control the flight: devices
After transferring to Alfresco 5, as well as rewriting the source code, it became possible to properly maintain and develop the system, adding new functionality. First of all, after optimizing the load, it was necessary to resolve the issue of monitoring systems. Hip size, disk activity and other standard indicators were put on monitoring via Zabbix using JMX. There was a question with monitoring application metrics: download speed, Alfresco REST API response speed, number of active users, etc. To solve this problem was written JMX bean, collecting the number of users and having active tickets.

To monitor the download and the response of the web interface, 2 web services were written that are called by zabbix:
Returns the number (uploaded files or the number of calls to the REST API)

Figure 2. Number of downloads
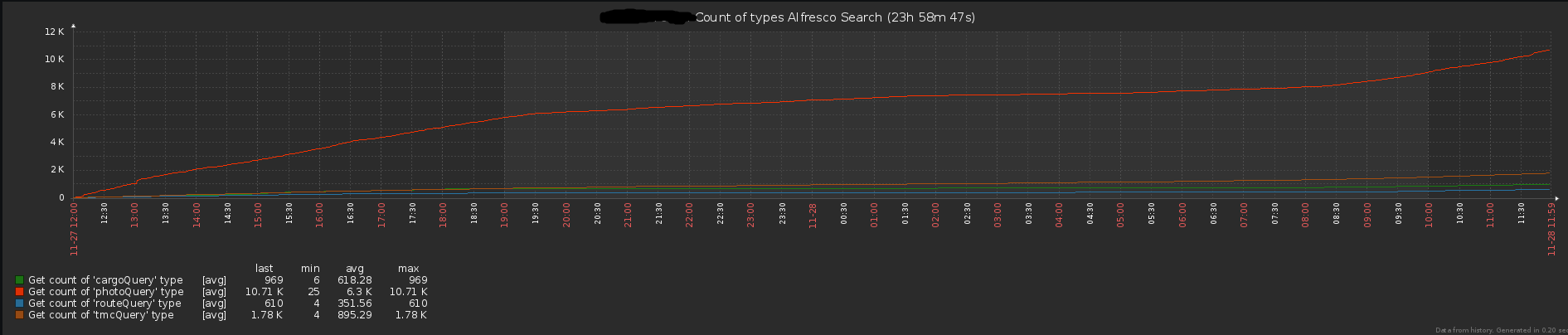
Figure 3. The number of requests in the REST API
Returns the average time (in milliseconds)
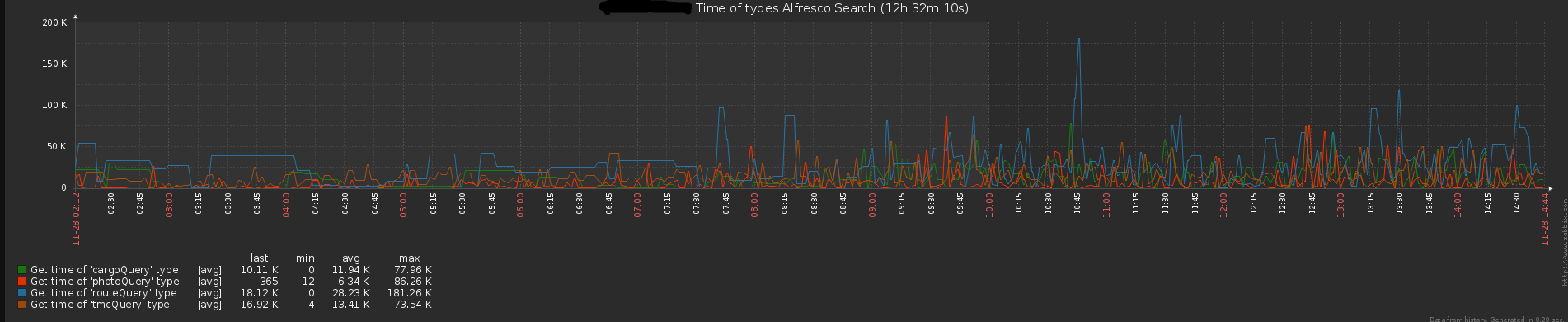
Figure 4. Response time REST API
Figure 5. File upload time
The type of the requested object is passed as the get parameter.
Space odyssey continues
The system’s own optimizations and improvements and the transition to Alfresco 5 made it possible to increase the loading capacity of up to 400,000 photos per day, taking into account that 300,000 of them pass through the recognition system. Also, the average number of active users has so far increased to 120. This is all on condition that the size of the database is about 700GB and the total size of the content is 19TB. We have over 90,000,000 documents in our system!
Alfresco Community Edition can be used as a platform for Electronic Archive. Large, large-scale space expeditions on her shoulder. But it is important to note that the success of the expedition depends on the quality of the preparatory work prior to the launch and the coordinated work of the crew during the escort.
And our flight continues, but at other speeds!
In the future, we plan to further optimize the web interface: make the so-called lazy loading of objects, which will speed up the search operations, and optimize screen forms from the point of view of user experience. (User Experience) We also plan to implement document life cycle management, in particular, to make archiving of documents on slow media.
Source: https://habr.com/ru/post/358208/
All Articles