Antipattern testing software
Introduction
There are several articles on anti-pattern software development. But most of them talk about the details at the code level and focus on a particular technology or programming language.
In this article, I want to take a step back and list the high-level testing anti-patterns common to all. I hope you learn some of them regardless of programming language.
Terminology
Unfortunately, testing has not yet developed a common terminology. If you ask a hundred developers, what is the difference between the integration, end-to-end and component test, you get a hundred different answers. For this article we confine ourselves to such a pyramid of tests:
')
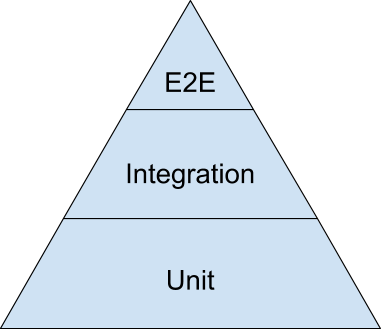
If you have not seen the pyramid of tests, I strongly recommend that you read it. Here are some good articles to get you started:
- “The forgotten layer of the pyramid of automatic tests” (Mike Cohn, 2009)
- The Pyramid of Tests (Martin Fowler, 2012)
- “Google Testing Department Blog” (Google, 2015)
- “The pyramid of tests in practice” (Ham Focke, 2018)
The test pyramid itself deserves a separate discussion, especially on the number of tests required for each category. Here I simply refer to it to define the two lowest categories of tests. Please note that this article does not mention user interface tests (the top of the pyramid) - mainly for short and because they have their own specific antipatterns.
Therefore, we define two main categories of tests: modular (unit tests) and integration tests.
| Tests | purpose | Requires | Speed | Complexity | Need setting |
|---|---|---|---|---|---|
| Unit tests | class / method | source | very fast | low | not |
| Integration tests | component / service | part of the running system | slow | average | Yes |
Unit tests are more widely known both in name and in meaning. These tests accompany the source code and have direct access to it. Usually they are performed using xUnit framework or a similar library. Unit tests work directly on the source and have a complete picture of everything. One class / method / function (or the smallest unit of work for this particular functionality) is tested, and everything else is simulated / replaced.
Integration tests (also referred to as service tests or even component tests) focus on the whole component. This can be a set of classes / methods / functions, a module, a subsystem, or even an application itself. They check the component by passing it input data and examining the output. Some kind of pre-deployment or configuration is usually required. External systems can be completely simulated or replaced (for example, using DBMS in memory instead of real), and real external dependencies are used according to the situation. Compared to unit tests, more specialized tools are required either to prepare the test environment or to interact with it.
The second category suffers from a blurry definition. This is where the most disputes about the names. The “scope” of integration tests is also quite controversial, especially in terms of the nature of access to the application (testing in a black or white box; whether mock objects are allowed or not).
The basic rule of thumb is: if the test ...
- uses database
- uses the network to call another component / application
- uses an external system (for example, a queue or mail server),
- reads / writes files or performs other I / O operations,
- relies not on the source code, but on the application binary,
... this is an integration test, not a unit test.
Having dealt with the terms, you can plunge into the list of antipatterns. Their order roughly corresponds to their prevalence. The most frequent problems are listed at the beginning.
List of antipattern software testing
- Unit tests without integration
- Integration tests without modular
- Wrong type of tests
- Testing the wrong functionality
- Internal implementation testing
- Excessive attention to test coverage
- Unreliable or slow tests
- Manual tests run
- Insufficient attention to the test code
- Failure to write tests for new production bugs
- Attitude towards TDD as a religion
- Writing tests without first reading the documentation
- Bad attitude to unknowing testing
Antipattern 1. Modular tests without integration
This is a classic problem for small and medium-sized companies. For the application, only unit tests are created (the base of the pyramid) - and nothing more. Usually the lack of integration tests is caused by one of the following problems:
- The company has no developers seniors. There are only juniors who have just graduated from college. They met only unit tests.
- At some point, integration tests existed, but they were abandoned because they caused more problems than they brought benefits. Unit tests are much easier to maintain, so they left only them.
- The working environment of the application is too “complicated” to configure. Characteristics are “tested” in production.
I can not say anything about the first paragraph. Each effective team should have a kind of mentor / leader who shows good practices to other developers. The second problem is covered in detail in antipatterns 5 , 7, and 8 .
This brings us to the final question — the complex setup of the test environment. Don't get me wrong, some applications are really hard to test. Once I had to work with a set of REST applications that required special equipment on the host. This equipment existed only in production, which made integration tests very difficult. But this is an extreme case.
For an ordinary web or server application created by a typical company, setting up a test environment should not be a problem. With the advent of virtual machines, and recently containers, it is now easier than ever. Basically, if you are trying to test an application that is difficult to configure, you must first correct the configuration process before you do the tests themselves.
But why are integration tests so important at all?
The fact is that some types of problems can only detect integration tests. The canonical example is everything related to DBMS operations. Transactions, triggers, and any stored database procedures can only be verified using integration tests that affect them. Any connections to other modules developed by you or external teams require integration tests (they are also contract tests). Any tests to check performance are integration tests by definition. Here is a brief overview of why we need integration tests:
| Type of problem | Determined by unit tests | Determined by integration tests |
|---|---|---|
| Basic business logic | Yes | Yes |
| Component Integration Problems | not | Yes |
| Transactions | not | Yes |
| Triggers / OBD procedures | not | Yes |
| Incorrect contracts with other modules / API | not | Yes |
| Wrong contracts with other systems | not | Yes |
| Performance / Timeouts | not | Yes |
| Reciprocal / self-locking | possibly | Yes |
| Cross Security Issues | not | Yes |
Typically, any cross-application problem requires integration tests. Taking into account the current insanity in microservices, integration tests become even more important as you now have contracts between your own services. If these services are developed by other groups, you must automatically check if the interface contracts are not violated. This can be covered only by integration tests.
To summarize, if you do not create something extremely isolated (for example, the Linux command line utility), then you really need integration tests to find problems not found by unit tests.
Antipattern 2. Integration tests without modular
This is the opposite of the previous anti-pattern. It is more common in large companies and large corporate projects. Almost always, this situation is associated with developers who believe that unit tests have no real value, and only integration tests can catch regressions. Many experienced developers consider unit tests to be a waste of time. Usually, if you ask them, it turns out that sometime in the past, managers demanded an increase in code coverage with tests (see antipattern 6 ) and forced them to write trivial unit tests.
Indeed, theoretically, only integration tests can be in the project. But in practice, such testing is very expensive (in terms of both development and assembly). In the table from the previous section, we saw that integration tests can also find business logic errors and therefore are capable of “replacing” unit tests. But is such a strategy viable in the long run?
Integration tests are complex
Consider an example. Suppose we have a service with four such methods / classes / functions.
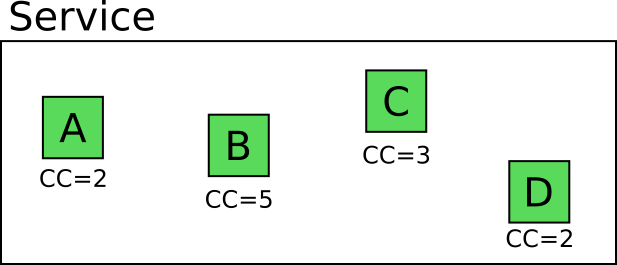
The number on each module denotes its cyclomatic complexity, that is, the number of linearly independent routes through this part of the program code.
Developer Mary is acting on a textbook and wants to write unit tests for this service (because she understands the importance of unit tests). How many tests do you need to write to fully cover all possible scenarios?
Obviously, you can write 2 + 5 + 3 + 2 = 12 isolated unit tests that fully cover the business logic of these modules. Remember that this number is only for one service, and the application Mary is working on has several services.
Developer Joe "Growler" does not believe in the value of unit tests. He believes that this is a waste of time, and decides to write only integration tests for this module. How many? He begins to look at all possible routes through all parts of the service.

Again, it should be obvious that 2 * 5 * 3 * 2 = 60 code routes are possible. Does this mean Joe will actually write 60 integration tests? Of course not! He will be cunning. First, try to select a subset of integration tests that seem to be “representative”. This “representative” subset will provide sufficient coverage with minimal effort.
In theory, everything is simple, but in practice a problem will quickly arise. In reality, these 60 scenarios are not created equally. Some of them are borderline cases. For example, module C runs through three code routes. One of them is a very special case. It can only be recreated if C receives specific input data from component B, which itself is a border case and can only be obtained with special input data from component A. So this particular scenario may require a very complex setup to select input data that will cause special condition on component C.
On the other hand, Mary will simply recreate the border case with a simple unit test without additional complexity.
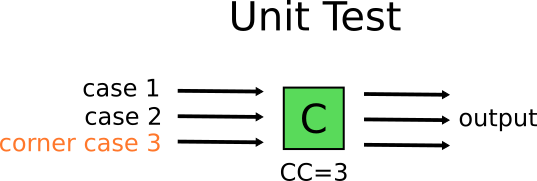
So Mary will only write unit tests? In the end, it will lead her to the anti-pattern 1 . To avoid this, she will write both unit and integration tests. Save all unit tests for real business logic, and then write one or two integration tests to verify that the rest of the system works properly (that is, parts that help these modules do their work).
Integration tests should focus on the remaining components. The business logic can be handled by unit tests. Mary's integration tests will focus on serialization / deserialization, communication with the queue and the database system.
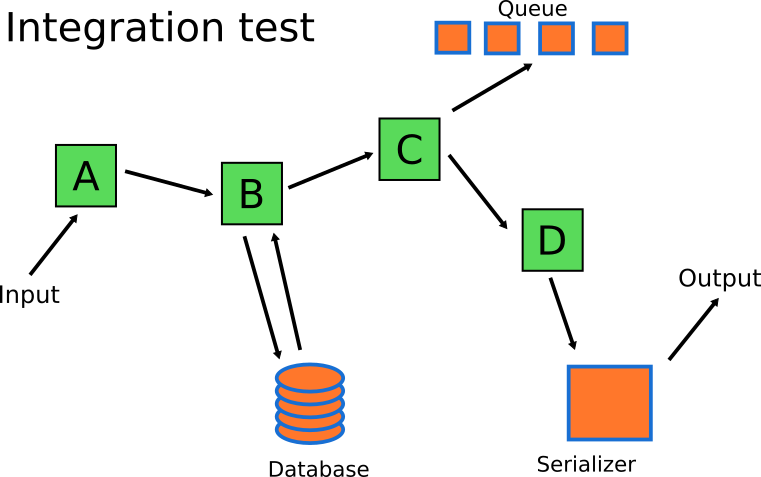
As a result, the number of integration tests is significantly less than the number of unit tests, which corresponds to the form of a pyramid of tests from the first section of this article.
Integration tests slow
The second big problem with integration tests is their speed. As a rule, an integration test is performed an order of magnitude slower than a unit test. The unit test only needs the source code of the application and nothing else. They are almost always limited by CPU load. On the other hand, integration tests can perform I / O operations with external systems, so that they are much more difficult to optimize.
To get an idea of the time difference, suppose the following numbers.
- Each unit test takes 60 ms (on average).
- Each integration test takes 800 ms (on average).
- In the application 40 services, as shown in the previous section.
- Mary writes 10 unit tests and 2 integration tests for each service.
- Joe writes 12 integration tests for each service.
Now we will count. Please note that Joe allegedly found the perfect subset of integration tests that give the same code coverage that Mary has (in reality it will not be like this).
| lead time | Having only integration tests (Joe) | Having unit tests and integration tests (Mary) |
|---|---|---|
| Only unit tests | N / A | 24 seconds |
| Only integration tests | 6.4 minutes | 64 seconds |
| All tests | 6.4 minutes | 1.4 minutes |
The difference in total work time is huge. Waiting for one minute after each code change is significantly different from waiting for the whole six minutes. And the 800 ms assumption for each integration test is extremely conservative. I saw integration test sets where one test takes a few minutes.
To summarize, an attempt to use only integration tests to cover business logic is a huge waste of time. Even if you automate tests using CI, the feedback loop (from commit to getting the test result) is still very long.
Integration tests are harder to debug than unit tests
The last reason why it is not recommended to limit itself to integration tests only (without modular ones) is the amount of time to debug a failed test. Since an integration test by definition tests several software components, a failure can be caused by any of the tested components. Identifying the problem is the more difficult the more components are involved.
If the integration test fails, you must understand the cause of the failure and how to fix it. The complexity and scope of integration tests make them extremely difficult to debug. Again, as an example, assume that only integration tests have been made for your application. Let's say this is a typical online store.
Your colleague (or you) sends a new commit that initiates the launch of integration tests with the following result:

As a developer, you look at the result and see that the integration test with the name “Customer buys goods” does not pass. In the context of an online store application, this is not very good. There are many reasons why this test may not pass.
It is impossible to find out the reason for the failure of the test without plunging into the logs and metrics of the test environment (assuming that they will help determine the exact problem). In some cases (and more complex applications), the only way to genuinely debug an integration test is to extract the code, recreate the test environment on the local machine, and then run the integration tests and attempt to reproduce the failure in the local development environment.
Now imagine that you are working with Mary on this application, so you have both integration and unit tests. Your colleagues send commits, you run all the tests and get the following:
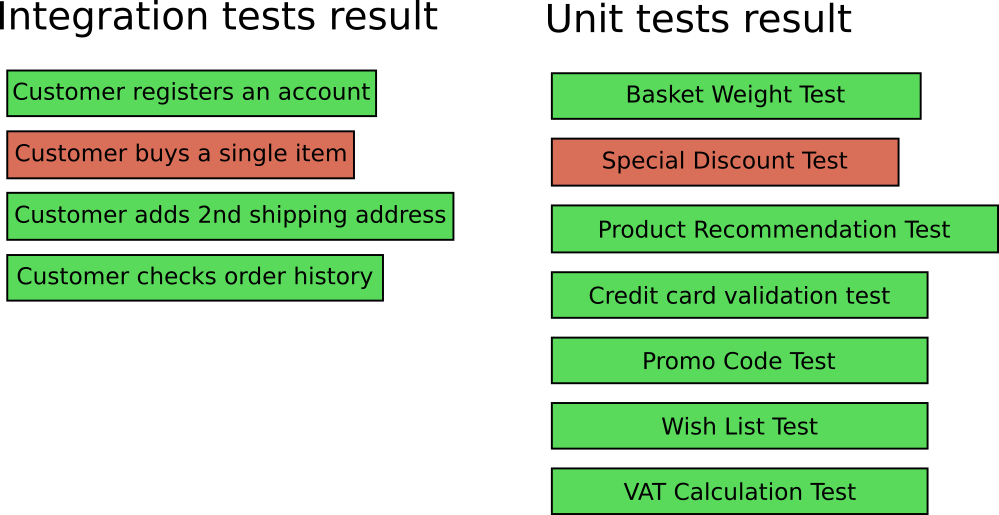
Now two tests failed:
- "Customer buys goods" does not pass as before (integration test).
- The “special discount test” also fails (unit test).
Now it is very easy to understand where to look for the problem. You can go directly to the source code of the discount functionality, find the error and correct it - and in 99% of cases the integration test will also be debugged.
Failure of a unit test before or with the integration process is a much more painless process when you need to find an error.
Summary of why unit tests are needed
This was the longest section of this article, but I think it is very important. To summarize: although theoretically you can only use integration tests, in practice
- Unit tests are easier to maintain.
- Unit tests easily reproduce borderline cases and rare situations.
- Unit tests are performed much faster than integration tests.
- Failed unit tests are easier to fix than integration ones.
If you have only integration tests, then you are wasting both development time and company money. We need both modular and integration tests at the same time. They are not mutually exclusive. There are several articles online that promote the use of only one type of test. All of these articles spread misinformation. Sad but true.
Antipattern 3. Wrong type of tests
Now we understand why we need both types of tests (modular and integration). You need to decide how many tests you need in each category.
There is no firm and clear rule. It all depends on your application. It is important to understand that you have to spend some time to understand which type of test is more valuable for your application. The test pyramid is just an assumption about the number of tests. It assumes that you are writing a commercial web application, but this is not always the case. Consider a few examples:
Example: Linux Command Line Utility
Your application is a command line utility. It takes files of one format (for example, CSV), performs some transformations and exports to another format (for example, JSON). The application is autonomous, does not communicate with any other systems and does not use the network. Transformations are complex mathematical processes that are crucial for the application to work properly (they must always be executed correctly, regardless of the speed of the work).
What you need for this example:
- Many unit tests for mathematical calculations.
- Some integration tests for reading CSV and writing JSON.
- No GUI tests, because the GUI is missing.
Here is the “pyramid” of tests for such a project:
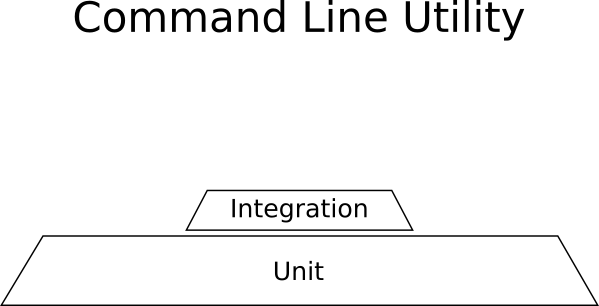
Unit tests dominate here, and the resulting form is not a pyramid.
Example: Payment Management
You add a new application that will be embedded in a large collection of existing enterprise systems. The application is a payment gateway that processes payment information for an external system. This new application should keep a log of all transactions in an external database, it should communicate with external payment providers (Paypal, Stripe, WorldPay, etc.), as well as send payment data to another system that bills.
What you need for this example:
- Almost no unit tests, because there is no business logic.
- Many integration tests for external communications, database storage, billing system.
- No GUI tests, because the GUI is missing.
Here is the “pyramid” of tests for such a project:
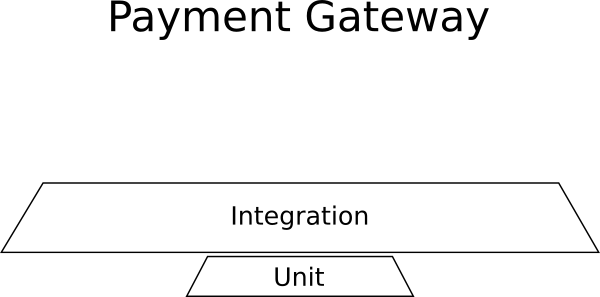
Integration tests dominate here, and the resulting form is again not a pyramid.
Example: Website Builder
You are working on a completely new startup that has developed a revolutionary way to create websites: the one-of-a-kind web application designer in the browser.
The application is a graphic designer with a set of all possible HTML elements that can be added to a web page, and a library of ready-made templates. There is the possibility of buying new templates on the market. The designer is very user-friendly, allows you to drag and drop components onto the page, resize them, edit properties, change colors and appearance.
What is needed for this contrived example:
- Almost no unit tests, because there is no business logic.
- Several integration tests for market interaction.
- A lot of GUI tests to make sure that the GUI is working properly.
Here is the “pyramid” of tests for such a project:
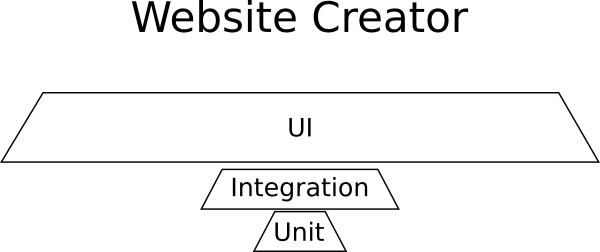
UI tests dominate here, and the resulting shape is again not a pyramid.
These extreme situations show that different applications require a different combination of tests. I personally saw payment management applications without integration tests, as well as website designers without UI tests.
On the Internet, you can find articles (I'm not going to refer to them), which call the specific ratio of integration tests, unit tests and UI tests. All of these articles are based on assumptions that may not fit your project.
Antipattern 4. Testing the wrong functionality
In the previous sections, we described the types and number of tests required for your application. The next logical step is to explain what kind of functionality you need to test.
Theoretically, the ultimate goal is to cover 100% of the code. In practice, this goal is difficult to achieve and it does not guarantee the absence of bugs.
In some cases it is really possible to test all the functionality of the application. If you start a project from scratch and work in a small team that works correctly and takes into account the effort required for the tests, then it is perfectly normal to cover all the added functionality with tests (because there are already tests for the existing code).
But not all developers are so lucky. In most cases, you inherit an existing application with a minimum number of tests (or without them at all!). If you work in a large and well-established company, then working with legacy code is more a rule rather than an exception.
Ideally, you will be given enough time to write tests for both new and existing legacy code. This romantic idea is likely to be rejected by the project manager, who is more interested in adding new features than in testing / refactoring. We'll have to prioritize and find a balance between adding new functionality (at the request of the authorities) and expanding the existing set of tests.
So what exactly will we test? What to focus on? Several times I have seen how developers spend valuable time writing unit tests that have little or no value for the overall stability of the application. The canonical example of useless testing is trivial tests that test the application's data model.
Code coverage is analyzed in detail in a separate anti-pattern . In the same section we will talk about the “importance” of the code and how it relates to tests.
If you ask any developer to show the source of any application, then he will probably open the IDE or code repository in the browser and show the individual folders.
This is the physical code model. It shows the folders in the file system containing the source code. Although this hierarchy is great for working with the code itself, unfortunately, it does not show importance. A flat list of folders implies that all the code components they contain have the same value.
This is not the case, since the various components of the code have a different impact on the overall functionality of the application. As a brief example, suppose you are writing an online store application and two errors occurred during production:
- Customers can not pay for goods from the cart, which stopped all sales.
- Customers receive incorrect recommendations when viewing products.
Although both errors are corrected, the first one is clearly of higher priority. Therefore, if you got an online store application without any tests at all, you should write new tests that directly check the functionality of the cart, and not the recommendation engine. Despite the fact that the recommendation mechanism and the basket may be located in the same level folders in the file system, they are of different importance when tested.
If we generalize, then in any medium / large application, sooner or later, the developer will have a different representation of the code - the mental model.
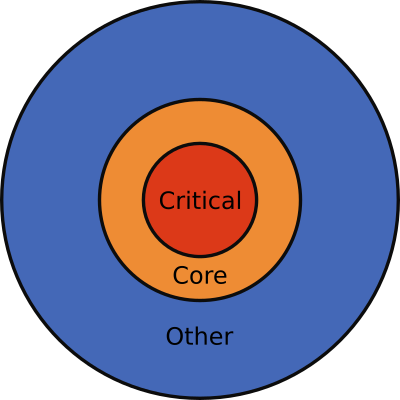
Three layers of code are shown here, but depending on the size of the application there may be more. It:
- Critical code - a code with frequent failures, where most of the new functions are introduced and which is important to users.
- , .
- , .
This mental model should be kept in mind whenever you write a new software test. Ask yourself if the functionality for which you are writing tests refers to critical or basic code. If so, write a test. If not, then maybe it makes sense to spend time on something else (for example, on another bug).
The concept of code importance also helps to answer the eternal question: what kind of code coverage is enough for an application? To answer, you need to either know the importance levels of the application code, or ask someone who knows. When you have this information, the answer is obvious: try writing tests that cover 100% of the critical code . If you have already done this, then try to write tests covering 100%main code . However, it is not recommended to try to cover with tests 100% of the total code.
It is important to note that the critical code is always only a small subset of the total. Thus, if the critical code is, say, 20% of the total, then covering tests with 20% of the total code is already a good first step for reducing the number of bugs in production.
In general, write unit and integration tests for code that:
- often breaks
- often changes
- critical for business
If there is time for further expansion of the test suite, then make sure that you are aware of a decrease in the effect of them before spending time on tests with little or no importance.
Antipattern 5. Testing internal implementation
More tests are always good. Right?
Wrong! You also need to make sure that the tests are actually well structured. The presence of incorrectly written tests causes double damage:
- First, they spend precious developer time while writing.
- Then they spend even more time when they have to redo them (when adding a new function).
Strictly speaking, the test code is similar to any other code . At some point, refactoring will be required to gradually improve it. But if you regularly change existing tests when adding new features, then your tests do not test what they should .
I have seen companies launch new projects and think that this time they will do everything right - they are starting to write a lot of tests to cover all the functionality. After some time, add a new function, but for it you need to change a few existing tests. Then add another function and update even more tests. Soon, the amount of effort to refactor / correct existing tests actually exceeds the time required to implement the function itself.
In such situations, some developers just give up. They declare that tests are a waste of time, and abandon the existing set of tests in order to fully focus on new features. In some exceptional cases, even releases are delayed due to the failure of the tests.
Of course, there is a problem in the poor quality of the tests. If they constantly need refactoring, then there is too close connection with the main code. Unfortunately, to identify such "incorrectly" written tests requires some experience.
Changing a large number of existing tests when a new function appears is only a symptom. The real problem is that tests check the internal implementation, and this is always a disaster scenario. In several manuals on software testing, an attempt is made to explain this concept, but very few people demonstrate it with clear examples.
At the beginning of the article I promised that I would not talk about a specific programming language, and I would keep the promise. Here the illustrations show the data structure of your favorite language. Think of them as structures / objects / classes that contain fields / values.
Suppose a Customer object in an online store application looks like this:

The Customer type takes only two values, where
0 means “guest” and 1 means “registered user”. The developers look at the object and write ten unit tests to check the “guests” and ten for the “registered users”. And when I say “for verification”, I mean that tests check this particular field in this particular object .Time passes, and managers decide that the branch office needs a new type of user with a value of
2 . Developers add ten more tests for affiliates. Finally, another type of user called “premium customer" has been added - and the developers add ten more tests.At the moment we have 40 tests in four categories, and they all check these specific fields. (The numbers are fictional, the example is only for demonstration. In a real project there can be ten interrelated fields in six nested objects and 200 tests).
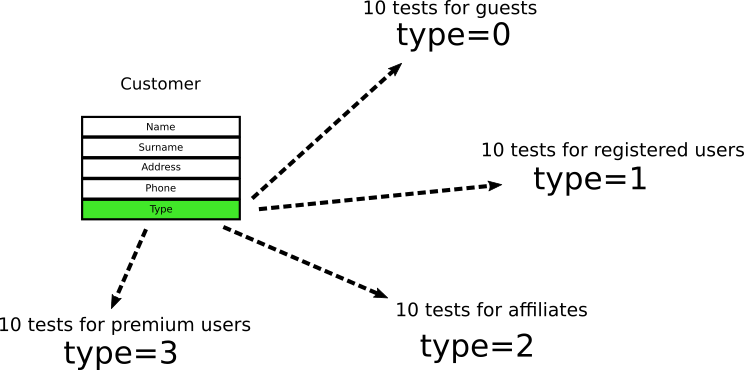
If you are an experienced developer, you can imagine further developments. New requirements come:
- Registered users need to save more email.
- For users in branches, you need to save the company name.
- Premium users are now awarded bonus points.
The client object is modified as follows:
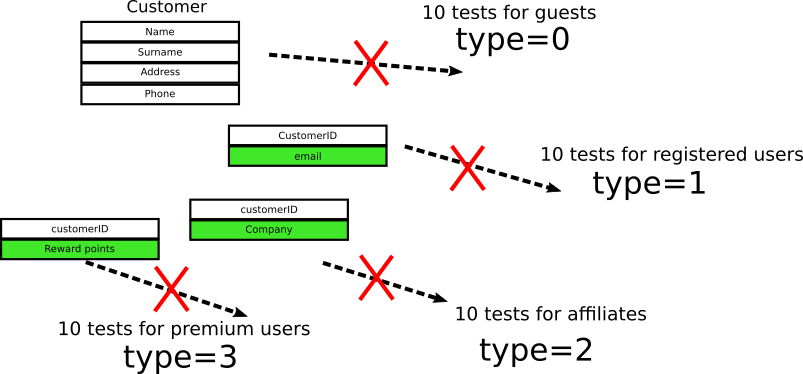
Now we have four objects associated with foreign keys, and all 40 tests immediately break down, because the field they are verifying no longer exists.
Of course, in this trivial example, you can simply keep the existing field, so as not to violate the backward compatibility with tests. In a real application, this is not always possible. Sometimes backward compatibility essentially means that you need to keep both the old and the new code (before / after the new function), which will greatly inflate it. Also note that saving the old code just for the sake of unit tests is in itself an obvious anti-pattern.
When this happens in a real situation, developers ask for extra time to fix the tests. Then project managers say that unit tests are a waste of time because they interfere with the introduction of new functionality. Then the whole team refuses the test suite, quickly disabling failed tests.
Here the main problem is not testing, but as tests. Instead of the internal implementation, the expected behavior should be tested. In our simple example, instead of testing directly the internal structure of an object, you need to check the exact business requirement in each case. Here's how to implement the same tests:
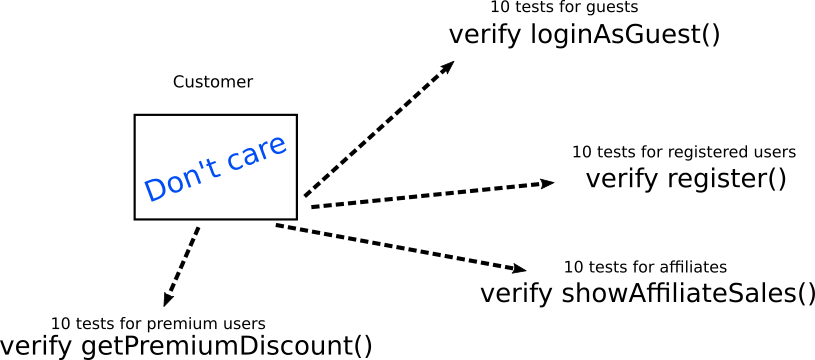
Here, tests do not check the internal structure of the object at all. They check only its interaction with other objects / methods / functions. If necessary, other objects / methods / functions should be simulated. Please note that each type of test directly corresponds to a specific business requirement, not a technical implementation (which is always a good practice).
When the internal implementation of an object changes, the test verification code remains the same. Only the configuration code for each test can be changed, which should be centrally stored in one auxiliary function
createSampleCustomer() or something similar (for more details, see antipattern 9 ).Of course, theoretically the verified objects themselves can change. In practice, the simultaneous change of
loginAsGuest() , register() , showAffiliateSales() and getPremiumDiscount() . In a realistic scenario, you will need to refactor ten tests instead of forty.To summarize, if you constantly fix existing tests as new features are added, this means that your tests are closely related to the internal implementation.
Antipattern 6. Excessive attention to test coverage
Code coverage is the industry’s favorite metric. There are endless discussions between developers and project managers about the necessary code coverage of tests.
Everyone loves to talk about coverage, because it is an understandable, easily measurable indicator. Most programming languages and testing frameworks have simple tools for displaying it.
Let me give you a little secret : code coverage is a completely useless metric. There is no “right” indicator. This is a trap question. You may have a project with 100% coverage of the code, which still has bugs and problems. In reality, you need to keep track of other metrics - the well-known indicators CTM (Codepipes Testing Metrics).
CTM metrics
Here is the definition of CTM, if you are not familiar with them:
| Metric name | Description | Perfect value | Normal value | Problem value |
|---|---|---|---|---|
| PDWT | Percentage of developers writing tests | 100% | 20% -70% | Any less than 100% |
| PBCNT | The percentage of bugs leading to the creation of new tests | 100% | 0% -5% | Any less than 100% |
| PTVB | Percentage of tests checking behavior | 100% | ten% | Any less than 100% |
| PTD | The percentage of deterministic tests | 100% | 50% -80% | Any less than 100% |
PDWT (percentage of developers writing tests) is probably the most important indicator. It makes no sense to talk about software testing anti-patterns if you don’t have tests at all. All developers in a team must write tests. Any new function can be declared made only if it is accompanied by one or several tests.
PBCNT (percentage of bugs leading to the creation of new tests). Each production bug is a great reason to write a new test that checks the corresponding fix. Any bug should appear in production no more than once. If your project suffers from the appearance of repeated bugs even after their initial “correction”, the team will really benefit from the use of this metric. For more on this, see the anti-pattern 10 .
PTVB (percentage of tests that test behavior, not implementation). Closely related tests devour a lot of time when refactoring the underlying code. This topic has already been discussed in the anti-pattern 5 .
PTD (percentage of deterministic tests of the total). Tests should fail only if something is wrong with the business code. If tests periodically break for no apparent reason, this is a huge problem that is discussed in the anti-pattern 7 .
If after reading about the metrics you still insist on setting a hard indicator to cover the code, I will give you the number 20% . This number should be used as a rule of thumb based on Pareto law . 20% of your code causes 80% of your errors, so if you really want to start writing tests, it will be good to start first with this code. The board also agrees well with the antipattern 4 , where I suggest writing tests for critical code first.
Do not try to achieve 100% total coverage. It sounds good in theory, but it is almost always a waste of time:
- you are wasting your energy, because the transition from 80% to 100% is much more difficult than from 0% to 20%;
- an increase in code coverage leads to a decrease in recoil.
In any non-trivial application there are certain scenarios that require complex unit tests to run. The effort required to write such tests usually outweighs the risk that these scenarios are implemented in production (if it ever happens at all).
If you have worked with any large application, you should know that after reaching 70% or 80% of the coverage it becomes very difficult to write useful tests for the rest of the code.
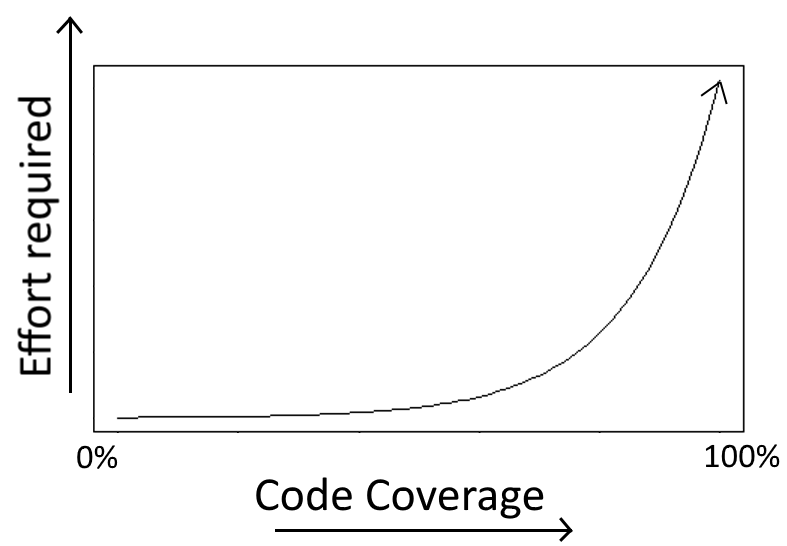
As we have already seen in the description of the anti-pattern 4 , some code routes in reality never fail in production, so it’s not recommended to write tests for them. It is better to spend time implementing the actual functionality.
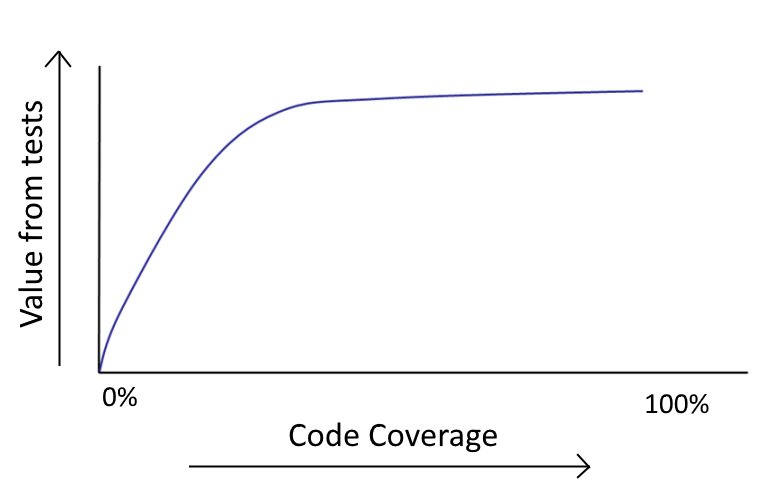
If for a project there is a condition of a certain percentage of code coverage by tests, then developers are usually forced to test trivial code or write tests that simply check the basic programming language. This is a huge waste of time, and as a developer you are obliged to complain to management about such unreasonable demands.
To summarize, code coverage with tests cannot be used as an indicator of the quality of a software project.
Antipattern 7. Unreliable or slow tests
Specifically, this anti-pattern has already been repeatedly discussed in detail , so I will only add.
Since software tests are an early indicator of regressions, they must always work reliably. Failure of the test should be a cause of concern, and those responsible for the corresponding build should start checking why the test failed.
This approach only works with tests that fall in a deterministic way. If the test sometimes fails and sometimes passes (without any code changes between checks), then it is unreliable and discredits all testing. It causes double damage:
- Developers no longer trust tests and begin to ignore them.
- Even normal test failures become difficult to detect in a sea of non-deterministic results.
A failed test should be clearly informed to all team members, since it changes the status of the entire assembly. On the other hand, in the presence of unreliable tests it is difficult to understand whether new failures occur, or whether it is the result of old unreliable tests.
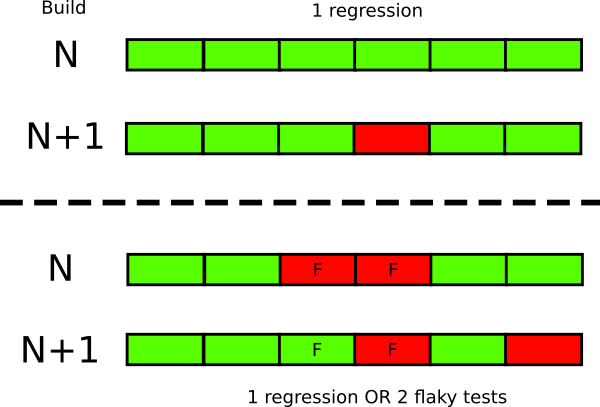
Even a small number of unreliable tests are enough to destroy trust in others. For example, you have five unreliable tests, you drove a new build through tests and got three crashes. It is not clear, everything is in order or you have three regressions.
A similar problem with very slow tests. Developers need fast feedback on the results of each commit (this is also discussed in the next section), so slow tests will eventually be ignored or not started at all.
In practice, unreliable and slow tests are almost always integration and / or user interface tests. As we climb the pyramid of tests, the likelihood of unreliable tests increases significantly. It is known that if a test handles browser events, then it is difficult to make it deterministic. Sources of unreliability can be many factors, but the test environment and its requirements are usually to blame.
The main protection against unreliable and slow tests is to isolate them in a separate test suite (provided they are incorrigible). There are many resources on the Internet on how to fix such tests in any programming language, so it makes no sense to explain it here.
To summarize, you should have an absolutely reliable test suite, let it be just a subset of the entire test suite. If the test from this set fails, then the problem is definitely with the code. Any failure of such a test means that the code should not be allowed into production.
Antipattern 8. Run tests manually
Different organizations use different types of tests. Unit tests, load tests, user acceptance tests (UAT) are typical categories of test sets that can be performed before releasing code into production.
Ideally, all tests are performed automatically without human intervention. If this is not possible, then at least tests that verify the correctness of the code (ie, unit and integration tests) should be performed automatically. Thus, developers get feedback on the code as quickly as possible. The function is very easy to fix when the code is fresh in your head and you have not yet switched the context to another function.
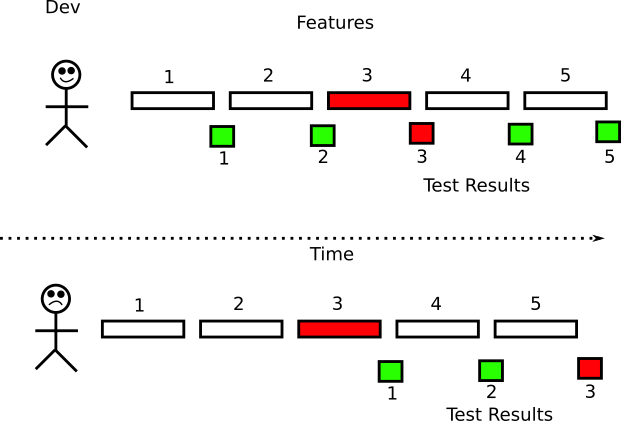
Previously, the longest stage of the software life cycle was application deployment. In the cloud, machines are created on request (in the form of VMs or containers), so that the preparation time for a new machine is reduced to a few minutes or seconds. Such a paradigm shift was taken by surprise by many companies that were not ready for such frequent cycles. Most existing practices focus on long release cycles. Expecting a specific release time with a manual “go-ahead” is one of the outdated practices that should be abandoned if the company is committed to fast deployments.
Rapid deployment implies trust in each deployment. The credibility of automatic deployment requires a high degree of confidence in the code. Although there are several ways to gain this confidence, the first line of defense is your software tests. However, having a test suite with a quick regression search is only half the battle. The second prerequisite is the automatic execution of tests (possibly, after each commit).
Many companies think that they have implemented continuous delivery and / or deployment. In fact, it is not. Practicing true CI / CD means that at any given time there is a version of the code that is ready for deployment. This means that the release candidate has already been tested. Therefore, the presence of a “ready-made” package that has not yet received the go-ahead is not a real CI / CD.
Most companies realized that human participation causes errors and delays, but there are still companies that run tests is a semi-automatic process. By “semi-automatic” is meant that the test suite itself can be automated, but people perform some maintenance tasks, such as preparing the test environment or clearing the test data to complete the tests. This is an anti-pattern, because it is not real automation. All aspects of testing should be automated.
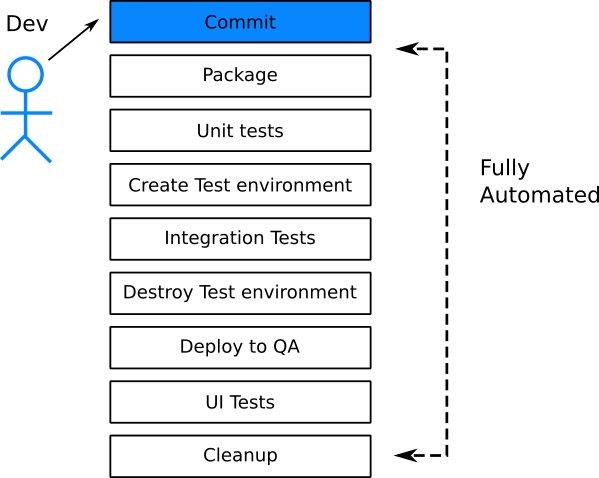
Having access to virtual machines or containers, it is very easy to create various test environments on demand. Creating a test environment on the fly for each request should become standard practice in your organization. This means that each new function is tested separately. The problem component (i.e., the failing test) must not block the rest.
A simple way to understand the level of test automation in a company is to observe the routine work of QA / testing staff. In the ideal case, testers simply create new tests that are added to the existing set. They do not start them manually. The test suite is executed by the build server.
To summarize, testing should always happen behind the scenes. Developers will recognize the test result for their particular function 5–15 minutes after the commit. Testers create new tests and refactor existing tests, but do not run them manually.
Antipattern 9. Insufficient attention to the test code
An experienced developer will always first spend some time organizing the code in his mind before starting to write. Regarding the design of the code there are several principles, and some of them are so important that even separate articles on Wikipedia are devoted to them. Here are some examples:
Perhaps the first principle is the most important because it forces the code to establish the only source of truth that is reused in several functions. Depending on the programming language, you can also use some other recommendations and design patterns. There may be separate recommendations adopted specifically in your team.
However, for some unknown reason, some developers do not apply the same principles to the software test code. I have seen projects where the function code is perfectly designed, but the test code suffers from huge amounts of duplication, hard-coded variables, copy-paste fragments and other errors that would be considered unforgivable in the main code.
It does not make sense to consider the test code as second-rate, because in the long term, all the code must be serviced. In the future, tests will have to be updated and reworked. Their variables and structure will change. If you write tests without thinking about their design, then you create additional technical debt, which will be added to the already existing one in the main code.
Try writing tests with the same attention you pay to the component code. Here you need to use all the same refactoring techniques. To start:
- All test code must be centralized. In the same way, all tests should produce test data.
- Complex verification segments should be extracted into a common library for this area.
- Frequently used imitations and emulations should not be copied with copy-paste.
- Test initialization code should be common to similar tests.
If you use static analysis tools, source code formatting or code quality, configure them to handle test code, too.
To summarize, develop tests as thoroughly as the main component code.
Antipattern 10. Failure to write tests for new production bugs
One of the tasks of testing is to find regressions. As we saw in the anti-pattern 4 , most applications have a “critical” part of the code where most bugs appear. When you correct an error, you need to make sure that it does not happen again. One of the best ways to guarantee this is to write a test for correction (either a unit test, or an integration test, or both).
Errors that leak into production are ideal candidates for writing tests:
- they show a lack of testing in this area, since the bug has already hit production;
- if you write a test for this error, it will protect future releases as well.
I am always amazed when development teams (even with a solid testing strategy) do not write a test for an error found in production . They correct the code and immediately correct the error. For some strange reason, many developers assume that writing tests only matters when adding a new function.
It is difficult to imagine something farther from the truth. I would even say that tests that derive from real errors are more valuable than tests that are added as part of a new development. In the end, you never know how often a new function will fail in production (perhaps it belongs to non-critical code that will never fail). The corresponding test is good, but its value is questionable.
But the test that you write for a real error is very valuable. It not only checks the correctness of the correction, but also ensures that it will always work, even after refactoring in this area.
If you join a legacy project without tests, this is also the most obvious way to start implementing useful testing. Instead of trying to guess which code to cover with tests, just pay attention to existing bugs - and write tests for them. After a while, tests will cover a critical part of the code, since by definition all your tests check what often fails. One of the metrics I proposed displays these efforts.
The only case where it is permissible to refuse a test is if the error in the working environment is not related to the code and comes from the environment itself. For example, incorrect configuration of the load balancer cannot be corrected with a unit test.
To summarize, if you are not sure which code to test, look at the errors that go into production.
Antipattern 11. Attitude towards TDD as a religion
TDD means development through testing . Like all previous methodologies, it is good on paper as long as the consultants do not begin to prove that this is the only right decision. At the time of this writing, this practice has gradually ceased, but I decided to mention it for completeness (since the corporate world is particularly affected by this anti-pattern).
Generally speaking, when it comes to software testing:
- tests can be written before the corresponding code;
- tests can be written simultaneously with the appropriate code;
- tests can be written after the appropriate code;
- you can never write tests for a specific code.
One of the basic principles of TDD is to always follow option 1 (writing tests before implementation code). In general, it is a good practice, but not always the best .
Writing tests before the code means that you are confident in the final API, and this is not always the case. Maybe you have a clear specification and you know the exact signatures of all the methods that should be implemented. But in other cases, you can just experiment with something or write code in the direction of the solution, and not immediately the final version.
From a practical point of view, the same startup is too early to blindly follow TDD. If you are working in a startup, then your code can change so quickly that TDD will not help much. You can even drop the code and start over again until you write the “correct” version. Writing tests after the implementation code is an absolutely correct strategy in this case.
The absence of tests in general (option 4) is also valid. As we saw in the anti-pattern 4 , some code does not need testing at all. Writing tests for a trivial code as “set by TDD” will not give you anything.
The obsession of TDD apologists to write tests first caused enormous damage to the mental health of sensible developers.. This obsession has already been spoken about several times, so I hope I don’t need to repeat myself (searching for the keywords “TDD is crap / stupid / dead”).
Here I want to confess that I myself worked several times according to the following scenario:
- First, the implementation of the main component.
- Then writing a test.
- Test run is successful.
- Commenting on critical parts of the component code.
- Test run failed.
- Delete comments, return the code to its original state.
- Running the test is success again.
- Commit
To summarize, TDD is a good idea, but you don’t have to constantly follow it. If you work for a Fortune 500 company with a bunch of business analysts and get clear specifications for what you need to implement, then TDD may be useful.
On the other hand, if you are just playing at home with a new framework on a day off and trying to understand how it works, then you don’t have to follow TDD.
Antipattern 12. Writing tests without first reading the documentation
The professional knows his work tool well. You may have to spend extra time at the beginning of the project in order to study in detail the technologies you intend to use. New web frameworks are constantly coming out, and it is always helpful to know all the features that can be used to write efficient and concise code. Elapsed time will return a hundredfold.
With the same respect must be treated to the tests. Since some developers see tests as secondary (see also antipattern 9 ), they never try to find out in detail what their testing framework is capable of. Copy-paste code from other projects and examples at first glance works, but not so should a professional behave.
Unfortunately, this picture is too common. People write several “auxiliary functions” and “utilities” for tests, not realizing that in the framework this function is either built-in or connected using external modules.
Such utilities make it difficult to understand the tests (especially for juniors), since they are filled with “internal” knowledge that does not apply to other projects / companies. Several times I have replaced “smart internal testing solutions” with standard off-the-shelf libraries that do the same in a standardized way.
You should spend some time and learn about the capabilities of your test framework. For example, how it works with:
- parameterized tests;
- imitations and emulations;
- test settings and dismantling (teardown);
- categorization of texts;
- conditional test execution.
If you are working on a typical web application, then you should do minimal research and learn best practices regarding:
- test data generators;
- HTTP client libraries;
- servers for HTTP imitation;
- mutational testing and fuzzing;
- clean / rollback db;
- load testing and so on.
No need to reinvent the wheel. This also applies to code testing. Perhaps in some border situations your application is a truly unique gem and needs some special utility for the core code. But I can bet that your modular and integration tests are completely ordinary, so writing special testing utilities is a dubious practice.
Antipattern 13. Poor attitude to unknowing testing
Although I mention this anti-pattern last, it was he who forced me to write this article. It always disappoints me when I meet people at conferences and meetings that “proudly” declare that all tests are a waste of time and that their application works fine without any tests at all. More often, there are those who are against a certain type of testing (usually against modular or integration tests), as we have seen in anti-patterns 1 or 2 .
When I meet such people, I like to ask them and find out the true reasons behind the hatred of the tests. And it always comes down to anti-patterns. Or they worked in companies with slow tests ( antipattern 7 ), or tests required constant refactoring (antipattern 5 ). Their “zadolbali” unreasonable demands to cover with tests 100% of the code ( antipattern 6 ) or TDD fanatics ( antipattern 11 ) who tried to impose their own distorted understanding of TDD on the whole team.
If you are one of those people, I really feel you. I know how hard it is to work in a company with the wrong organization of the process.
Bad past testing experience should not interfere with your objective assessment when it comes to testing the next project that starts from scratch. Try to objectively look at your team, your project and see if any antipatterns apply to you. If yes, then just testing is conducted incorrectly and no amount of tests will fix your application. Sad but true.
It's one thing when your team suffers from bad testing practices, and another is to make the junior think that “testing is a waste of time.” Please, do not do that. There are companies that do not suffer from any of the anti-patterns mentioned in the article. Try to find them!
Source: https://habr.com/ru/post/358178/
All Articles