We brought this day as we could - a notepad in Windows 10 began to understand the unix line feed
Notepad in windows 10 began to understand the Unix line feed , not just the Windows format.
The problem of “porridge” instead of readable text has been confronted for decades by those who have tried to open text documents prepared on other operating systems in the Windows environment. Now everything changes overnight. And this change is as small as it is epic in its practical results and ideological consequences. Microsoft is again trying to play in cross-integration and support for open standards.
For many years, Windows Notepad could normally display only those text documents that contained the characters of the beginning of a new line in the Windows End of Line (EOL) format - “carriage return” (CR) and “feed per line” (LF). In fact, this led to the fact that Notepad could not correctly display the contents of text files created in Unix, Linux and macOS, where only the LF character was used as a sign of the end of a line.
')
For example, here is a screenshot of Notepad trying to display the contents of a Linux .bashrc text file that contains only Unix LF EOL characters:

And here is a screenshot of the recently updated Notepad displaying the contents of the same UNIX / Linux .bashrc file, but with the correct hyphenation:
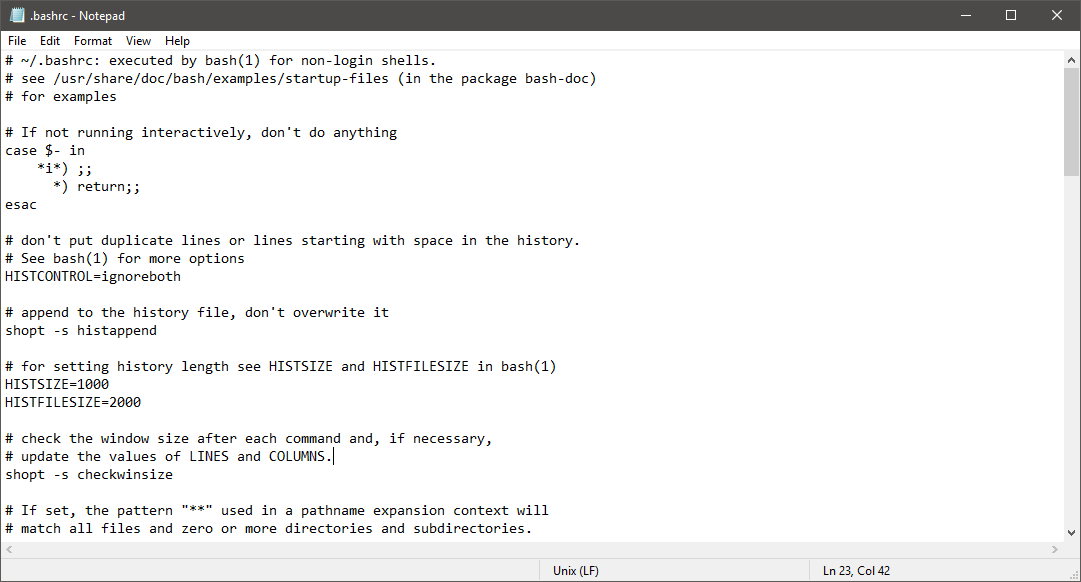
Note that the status bar indicates the detected EOL format of the currently open file.
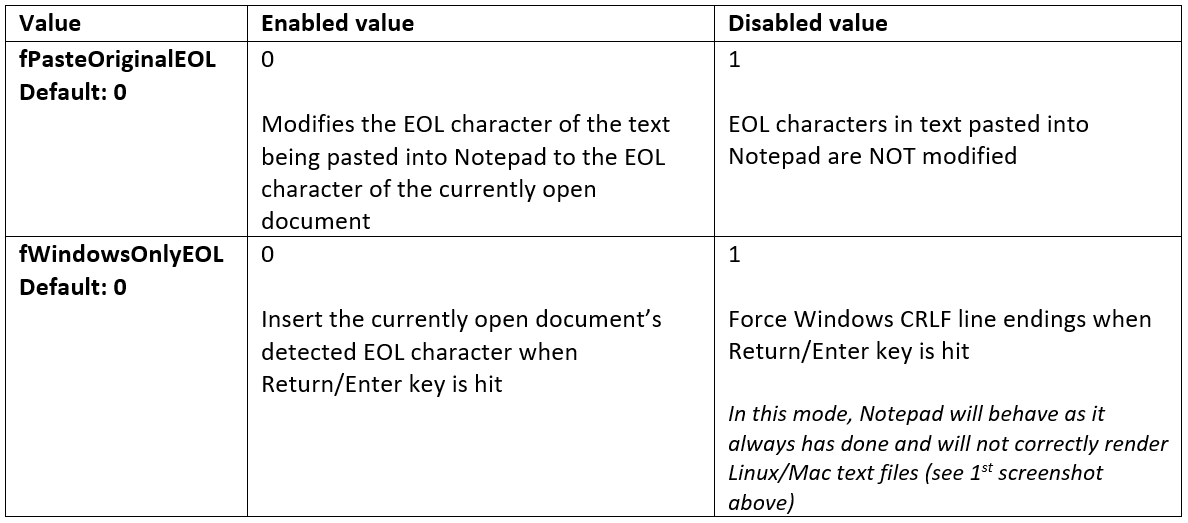
Also, for flexible management of a new feature, two additional keys are introduced in the [HKEY_CURRENT_USER \ Software \ Microsoft \ Notepad] registry key:
According to the passions, the dispute about the way of starting a new line in electronic documents is comparable to the dispute about spaces and tabs in the source texts of programs. This confrontation "for the line" had many reasons , both in the area of ancient standards and traditions, and those taking their roots in the features of the design of printing machines and teleprints. Not the least role was played by the desire of some programmers to literally execute (interpret) commands and control characters, and others - to follow common sense.
Historically, a mechanical typewriter had a lever that returned the carriage to the left edge of the page and scrolled the shaft, pushing the paper up onto the line. On teletypes and later alphanumeric printers (ADCs), instead of a carriage there was a head, in laser printers it ceased to be material, but in the term carriage return they all continued to call it carriage in order not to change it. On teletypes, carriage return and line feeds were divided, from where the tradition of representing line feeds as CR + LF went to text files.
Systems based on an ASCII or compatible character set use either LF (line feed, 0x0A), or CR (carriage return, 0x0D) separately, or the sequence CR + LF. These names are based on printer commands: a line feed means that one line on paper must be moved when printing, and a carriage return means that the print carriage must return to the beginning of the current line.
By standard, any application compatible with Unicode should be treated as a line feed each of the following characters:
Moreover, the sequence CR + LF (U + 000D U + 000A) should be taken as one line feed, not two.
But as you know, standards are standards, and the implementation of all often go different. And fuel for fire adds the need to correctly display inherited documents created before the Unicode era. The lack of a common, generally accepted representation of line feeds in different operating systems has made the exchange of text data between them a long time.
Unicode tries to reconcile this difference by equalizing CR, LF and CR + LF, however, it conflicts with ASCII inherited by it when interpreting the sequence of LF + CR that is not preceded by CR: according to ASCII it is one newline, and according to Unicode - two.
The problem of “porridge” instead of readable text has been confronted for decades by those who have tried to open text documents prepared on other operating systems in the Windows environment. Now everything changes overnight. And this change is as small as it is epic in its practical results and ideological consequences. Microsoft is again trying to play in cross-integration and support for open standards.
For many years, Windows Notepad could normally display only those text documents that contained the characters of the beginning of a new line in the Windows End of Line (EOL) format - “carriage return” (CR) and “feed per line” (LF). In fact, this led to the fact that Notepad could not correctly display the contents of text files created in Unix, Linux and macOS, where only the LF character was used as a sign of the end of a line.
')
For example, here is a screenshot of Notepad trying to display the contents of a Linux .bashrc text file that contains only Unix LF EOL characters:
And here is a screenshot of the recently updated Notepad displaying the contents of the same UNIX / Linux .bashrc file, but with the correct hyphenation:
Note that the status bar indicates the detected EOL format of the currently open file.
Also, for flexible management of a new feature, two additional keys are introduced in the [HKEY_CURRENT_USER \ Software \ Microsoft \ Notepad] registry key:
According to the passions, the dispute about the way of starting a new line in electronic documents is comparable to the dispute about spaces and tabs in the source texts of programs. This confrontation "for the line" had many reasons , both in the area of ancient standards and traditions, and those taking their roots in the features of the design of printing machines and teleprints. Not the least role was played by the desire of some programmers to literally execute (interpret) commands and control characters, and others - to follow common sense.
What can we learn about the problem from Wikipedia
Historically, a mechanical typewriter had a lever that returned the carriage to the left edge of the page and scrolled the shaft, pushing the paper up onto the line. On teletypes and later alphanumeric printers (ADCs), instead of a carriage there was a head, in laser printers it ceased to be material, but in the term carriage return they all continued to call it carriage in order not to change it. On teletypes, carriage return and line feeds were divided, from where the tradition of representing line feeds as CR + LF went to text files.
Systems based on an ASCII or compatible character set use either LF (line feed, 0x0A), or CR (carriage return, 0x0D) separately, or the sequence CR + LF. These names are based on printer commands: a line feed means that one line on paper must be moved when printing, and a carriage return means that the print carriage must return to the beginning of the current line.
- CR (ASCII 0x0D) was used in 8-bit Commodore machines, TRS-80, Apple II machines, Mac OS up to version 9 and OS-9;
- LF (ASCII 0x0A) is used in Multics, UNIX, UNIX-like operating systems (GNU / Linux, AIX, Xenix, Mac OS X, FreeBSD), BeOS, Amiga UNIX, RISC OS and others;
- CR + LF (ASCII 0x0D 0x0A) is used in DEC RT-11 and most other non-UNIX and non-IBM systems, as well as in CP / M, MP / M, MS-DOS, OS / 2, Microsoft Windows , Symbian OS, Internet protocols.
By standard, any application compatible with Unicode should be treated as a line feed each of the following characters:
- LF (U + 000A): English line feed - feed line <>;
- CR (U + 000D): English carriage return - carriage return <VK>;
- NEL (U + 0085): English next line - go to the next line;
- LS (U + 2028): English line separator - line separator;
- PS (U + 2029): English paragraph separator - paragraph separator.
Moreover, the sequence CR + LF (U + 000D U + 000A) should be taken as one line feed, not two.
But as you know, standards are standards, and the implementation of all often go different. And fuel for fire adds the need to correctly display inherited documents created before the Unicode era. The lack of a common, generally accepted representation of line feeds in different operating systems has made the exchange of text data between them a long time.
Unicode tries to reconcile this difference by equalizing CR, LF and CR + LF, however, it conflicts with ASCII inherited by it when interpreting the sequence of LF + CR that is not preceded by CR: according to ASCII it is one newline, and according to Unicode - two.
Source: https://habr.com/ru/post/358154/
All Articles