Banhammer on Amazon. Explanation of locks by whole subnets in simple and understandable language (for dummies ™)
This tutorial provides extremely simple and clear answers to the following questions:
And we begin, perhaps, with this picture:
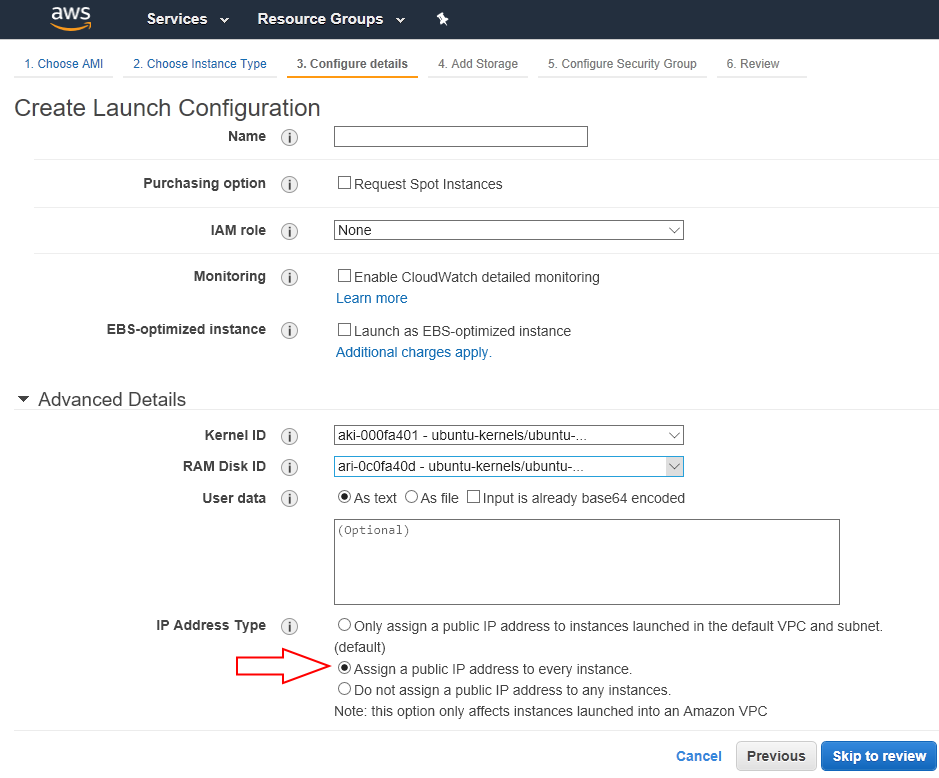
When you launch your service on Amazon, it usually happens like this:
')
a) setting up some kind of virtual machine
b) you install your service on it,
c) check that everything works, and then
d) you make from it AMI - a full cast, the image of your service along with the operating system and all the rest that is there.
It is stored in the cloud, and then, if necessary, very easily and simply (and, most importantly, automatically) is replicated on any reasonable scale with the same automatic configuration. The screenshot just shows the interface, which sets some additional settings for running multiple instances of a pre-configured nugget.
The arrow marks the option “Automatically assign external IP addresses for each instance.”
So here. When you launch your service on a large scale, Amazon can be instructed that, with a certain load on the virtual machine processor, it will deploy another instance of your service next to it. Or, for example, just a hundred pieces. Or not with the load on the processor, but, say, with a couple of hundreds of simultaneously active network connections. There are a lot of such metrics for automatic scaling , and the rules for autorun can also be configured quite flexibly.
Now let's look at this schedule:
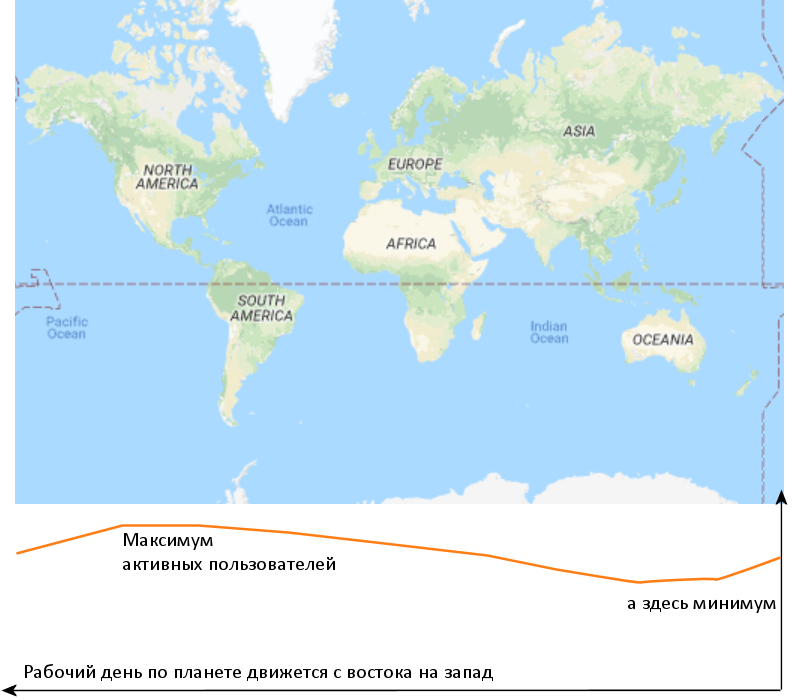
This is an approximate number of simultaneously active users of worldwide Internet services during business hours. Almost no one lives in the Pacific, China has its own Internet, and the largest number of users falls on Europe, and - in particular - the west of the United States. This is true for almost any service with worldwide coverage, even Steam, though Netflix, even Wikipedia, even Telegram.
As we see, the difference between the maximum and minimum is one and a half times. Literally, this means that if you work for the whole world, about half a day, while in the Western Hemisphere a day, you need almost twice as much power as the other half of the day, when it is a day in Asia. So you set up the appropriate rules for automatic scaling yourself, so as not to waste processor time (and your money - in the clouds like nowhere else = money) in vain at a time when it is not needed.
And half the copies of your service are simply killed by the cloud itself on a schedule when America goes to bed. And the next day, with an increase in load, it will helpfully lift them up again.
Now answer question 3). The arrow on the screenshot is not just drawn. The option "Automatically assign external IP addresses for each instance" takes the address from the available address pool - Amazon owns several million, and it rents a few more from other owners. The public IPv4 address is now scarce, so having every virtual instance on a permanent basis, whether it works now or not, is a great luxury - and costs money (moreover, in any data center in Amazon you are given only 5 permanent addresses, and increase this limit well with a very big creak).
And as soon as a copy is killed, the address immediately returns to the common pool. And so on. Who will he get next time? Yes, anyone. Maybe you, or maybe another client, who also automatically scales his service, and maybe an ephemeral instance of the service of Amazon itself. Thus, the answer to question 3) is trivial: because today this IP is yours, and after a couple of hours someone else. If your service is unwanted to someone, but automatically scaled, then you can ban it by IP, but only if you ban the entire pool.
And to question 2) the answer is also trivial: not at all worth it. The cloud itself will assign to the next instance some other address from the pool available to it, whether you want it or not.
Now about the first question.
The answer is not so obvious, but we will try to do what is called the educated guess (I don’t know how to say it better in Russian, “assumption based on experience”, perhaps?).
Amazon is the oldest of the big clouds. The software, which deals with all these automatic scaling, was written ten years ago, and since then it has worked like a clock. Amazon’s giant service itself runs smoothly in the same cloud. This binding is not broken, it does not need to be repaired, and any changes that people write have the risk of making mistakes. Therefore, the feature of isolating pools of addresses for a client, if you start developing it right now, will take up to hell of time, and if it suddenly leads to big changes, then the price of possible consequences will be calculated in billions of dollars. In the most direct sense.
And the answer to 1) sounds like this: It is simply unprofitable for Amazon to rework its infrastructure to meet the demands of a stupid supervisory authority of the state, all clients from which do not make so much money to compensate for the possible risk for themselves and clients from other countries. It sounds hard, but this, unfortunately, is a business.
By the way, with the rest of the clouds everything is exactly the same. Yutube was banned because the services of Google itself are not separated from the services of customers of Google, and work in the same cloudy space with a single pool of addresses. And with Microsoft services similarly.
Roskomnadzor, blocking cloud services, is fighting with the technology on which the clouds are built. With scripts. With algorithms. It is like fighting against the laws of physics, or trying to kick the elements: utterly stupid and pointless. It is impossible to defeat the clouds and the wind, you can only go underground, to never see them ...
- Why is Amazon not cooperating with Roskomnadzor?
- How much does it cost to permanently transfer the Telegram servers to other IP addresses inside the cloud?
- Why is it impossible to ban services hosted on Amazon with specific IPs and not subnets at once?
And we begin, perhaps, with this picture:
When you launch your service on Amazon, it usually happens like this:
')
a) setting up some kind of virtual machine
b) you install your service on it,
c) check that everything works, and then
d) you make from it AMI - a full cast, the image of your service along with the operating system and all the rest that is there.
It is stored in the cloud, and then, if necessary, very easily and simply (and, most importantly, automatically) is replicated on any reasonable scale with the same automatic configuration. The screenshot just shows the interface, which sets some additional settings for running multiple instances of a pre-configured nugget.
The arrow marks the option “Automatically assign external IP addresses for each instance.”
So here. When you launch your service on a large scale, Amazon can be instructed that, with a certain load on the virtual machine processor, it will deploy another instance of your service next to it. Or, for example, just a hundred pieces. Or not with the load on the processor, but, say, with a couple of hundreds of simultaneously active network connections. There are a lot of such metrics for automatic scaling , and the rules for autorun can also be configured quite flexibly.
Now let's look at this schedule:
This is an approximate number of simultaneously active users of worldwide Internet services during business hours. Almost no one lives in the Pacific, China has its own Internet, and the largest number of users falls on Europe, and - in particular - the west of the United States. This is true for almost any service with worldwide coverage, even Steam, though Netflix, even Wikipedia, even Telegram.
As we see, the difference between the maximum and minimum is one and a half times. Literally, this means that if you work for the whole world, about half a day, while in the Western Hemisphere a day, you need almost twice as much power as the other half of the day, when it is a day in Asia. So you set up the appropriate rules for automatic scaling yourself, so as not to waste processor time (and your money - in the clouds like nowhere else = money) in vain at a time when it is not needed.
And half the copies of your service are simply killed by the cloud itself on a schedule when America goes to bed. And the next day, with an increase in load, it will helpfully lift them up again.
Now answer question 3). The arrow on the screenshot is not just drawn. The option "Automatically assign external IP addresses for each instance" takes the address from the available address pool - Amazon owns several million, and it rents a few more from other owners. The public IPv4 address is now scarce, so having every virtual instance on a permanent basis, whether it works now or not, is a great luxury - and costs money (moreover, in any data center in Amazon you are given only 5 permanent addresses, and increase this limit well with a very big creak).
And as soon as a copy is killed, the address immediately returns to the common pool. And so on. Who will he get next time? Yes, anyone. Maybe you, or maybe another client, who also automatically scales his service, and maybe an ephemeral instance of the service of Amazon itself. Thus, the answer to question 3) is trivial: because today this IP is yours, and after a couple of hours someone else. If your service is unwanted to someone, but automatically scaled, then you can ban it by IP, but only if you ban the entire pool.
And to question 2) the answer is also trivial: not at all worth it. The cloud itself will assign to the next instance some other address from the pool available to it, whether you want it or not.
Now about the first question.
The answer is not so obvious, but we will try to do what is called the educated guess (I don’t know how to say it better in Russian, “assumption based on experience”, perhaps?).
Amazon is the oldest of the big clouds. The software, which deals with all these automatic scaling, was written ten years ago, and since then it has worked like a clock. Amazon’s giant service itself runs smoothly in the same cloud. This binding is not broken, it does not need to be repaired, and any changes that people write have the risk of making mistakes. Therefore, the feature of isolating pools of addresses for a client, if you start developing it right now, will take up to hell of time, and if it suddenly leads to big changes, then the price of possible consequences will be calculated in billions of dollars. In the most direct sense.
And the answer to 1) sounds like this: It is simply unprofitable for Amazon to rework its infrastructure to meet the demands of a stupid supervisory authority of the state, all clients from which do not make so much money to compensate for the possible risk for themselves and clients from other countries. It sounds hard, but this, unfortunately, is a business.
By the way, with the rest of the clouds everything is exactly the same. Yutube was banned because the services of Google itself are not separated from the services of customers of Google, and work in the same cloudy space with a single pool of addresses. And with Microsoft services similarly.
Roskomnadzor, blocking cloud services, is fighting with the technology on which the clouds are built. With scripts. With algorithms. It is like fighting against the laws of physics, or trying to kick the elements: utterly stupid and pointless. It is impossible to defeat the clouds and the wind, you can only go underground, to never see them ...
Source: https://habr.com/ru/post/357992/
All Articles