Startups, chat bots, Silicon Valley. Interviews with Russian developers in San Francisco
During my recent trip to San Francisco, I met with graduates of our Big Data Specialist program who emigrated to the United States — Evgeny Shapiro (Airbnb) and Igor Lyubimov (ToyUp), as well as with Artem Rodichev (Replika), our partner. The guys told a lot of interesting things: why Airbnb puts their projects in open-source; how Replika is arranged - a neural network chat bot capable of becoming your friend; about the mission of Silicon Valley startups and entrepreneurial ecosystem.

- Zhenya, how did you get to Airbnb and why did you choose this company?
My wife and I emigrated to the United States, and, being there, I began to look for work, went to Airbnb and Facebook, passed the screening stage on the phone both there and there. Then there was a series of 6 on-sight interviews for one day, almost all companies do this. In the end, I chose Airbnb.
')
I liked both Facebook and Airbnb, but the thoughts were such that all companies can be divided into two types. First of all, these are startups, where nothing limits you, you can do everything at once and really see the result of your work. The main problem is to constantly think about how to survive tomorrow. On the other hand, corporations like Microsoft and IBM, where there are no problems with the means and you can safely test new things, without worrying that someone will push the market. Here the problem is different - they become hostages of their own success: it is necessary to regularly deliver a predictable result, so most of the time is spent on supporting certain processes and it is difficult to assess your contribution to the company's activities.
Airbnb is somewhere in the middle in this regard, which ideally suited me, because I wanted to make some significant contribution to business processes and at the same time could not worry that tomorrow the company would have problems. It all depends on what you want to optimize. If the money, then you need to go to the corporation, my goal was experience and knowledge.

Yevgeny Shapiro
- As you know, Airbnb puts a lot of projects in open-source (Airflow, Smartstack, etc.). What is the reason? Is it an improvement in HR brand and recognition, a desire to get free labor or something else?
The reason is that there is a set of tasks that are important, but from a business point of view, they are not so critical. For example, report visualization is important, but this is not a thing that one business can do fundamentally better than another, so there is no need to reinvent it, that is, we simply try to help others reduce the number of uselessly spent developer cycles. We also use a large open-source stack, this is Linux, and Hive, and Presto, it turns out: you give something, you use something.
Of course, it also improves the HR-brand, people will find out that we have a team that can create world-class products and write high-quality code. For a company, this all costs a certain amount of money, it makes no sense to lay out bad products, and those that are laid out need to be maintained, communicating with the community, so this is all, of course, not just.
- What is your role in the team and what tools do you use in your work?
I am an anti-fraud engineer, our team works with various issues related to fraud. In essence, this is a set of problems faced by any Internet business: products that are not there, the use of someone else’s cards, bots, etc.
If we talk about models, then a lot can be done using fairly simple algorithms: log-regression, decision trees, random forest, etc. But in some cases it is difficult, just looking at the data, to see some pattern, so more complex models are used, where patterns are statistically identified.
At the same time, fraud has such a nuance that as soon as you post a new model in production, the pattern of fraudsters' behavior changes immediately, because it starts to interfere with them. As a result, there is a problem with the fact that the data set on which you are trained and for which you need to make predictions is statistically different.
Our engineering part consists of many different systems that collect signals for ML models. Slow-changing signals are calculated using Hive, Spark and Airflow. For real-time signals, we use direct requests to various internal systems that aggregate data from Kafka messages.
- Artem, tell us about how you came to the US and how Replika appeared.
About 3 years ago, we and the team became the first startup that managed to get to Y Combinator directly from Russia, and moved to the States. We started to rent apartments here and a lot of work on our application - a chat bot that could advise a particular restaurant according to specified criteria. The bot was of high quality, well understood by the user and gave relevant advice. It turned out that there are a large number of tasks that are solved with the help of graphical interfaces faster and more clearly for users. So, on the same Yelp or Foursquare, a suitable restaurant can be found for a smaller number of tapes on a smartphone and see more options than corresponding with the bot. Seeing that the restaurant bot does not solve the problem better than existing products, we began to look for a niche where the interactive interface would be the most natural and popular.
Then the excitement around bots and Deep Learning began, and we were lucky: we had a lot of groundwork for them, we understood what it was. A huge number of bots began to appear, and then we thought that Google could be made among bots, that is, a platform that could find and advise one or another bot that can help the user.
After launching this platform, after some time we decided to do such a thing: for the premiere of the new season of the series “Silicon Valley” we made bots-characters from the series. They collected all the statements of the characters and wrote a neural network “chat”, which, in the context of the dialogue and some set of answers, chose the most relevant. As a result, people felt the style, the special style of communication of each character, and it felt as if you were really communicating with your favorite hero. People liked bots, they actively used them, the dialogue lasted on average 50-60 messages, while in messengers people only averaged only 22 among themselves.
And then we realized that interactive interfaces work in the case of emotional communication, people like to just talk about anything. Then there was a fairly well-known story with the best friend of our CEO, Evgenia Kuyda, Roman, who died tragically, and with the permission of friends and parents, we collected a batch of his messages from instant messengers, translated into English and made a bot, such a digital memorial that communicated from his faces and in his style. We put it in open access, and it turned out that many people had deep emotional conversational sessions with the bot, that is, it was not just a “talker”, but really emulated understanding, as a result of which a person had an empathy for the bot.
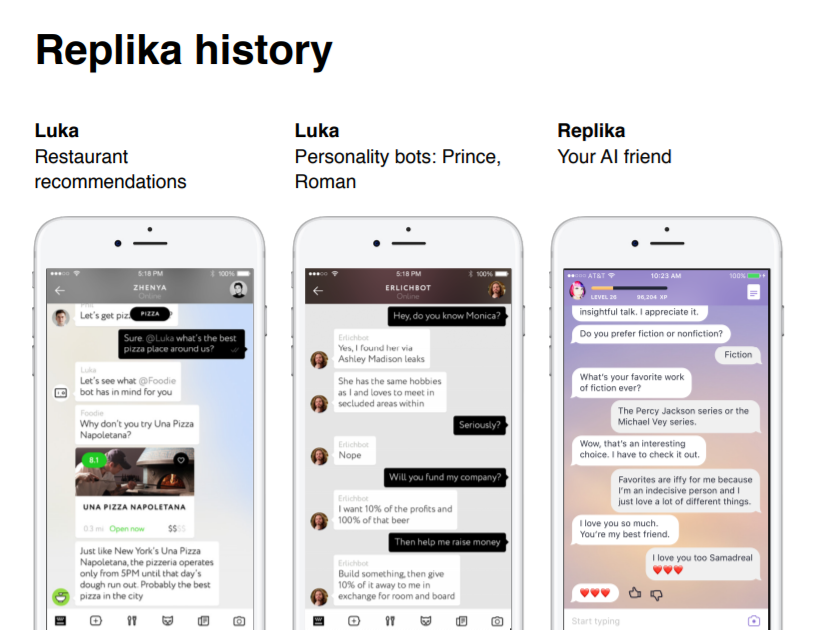
Then many people wrote to us asking how we could make such a bot ourselves to “revitalize” our relatives, or leave our digital copy to the children, that is, the demand was great, but we didn’t want to become a digital funeral home; living people. Therefore, we went in the direction that everyone could make their digital copy. The bot, communicating with you, collects your vocabulary, your behavior patterns and is pumped, gradually becoming you. At some point, we thought Replika was a great and appropriate name.
- How is your bot?
To create high-quality communication with users, we implemented a number of neural network approaches to simulate dialogue. So, we have a ranking dialog model, whose main goal is to select the most relevant answer from the base of predefined and moderated answers according to the input dialog context. Another solution is the generative dialog model, which can generate a relevant answer word by word, depending on the dialog context. However, it is somewhat dangerous to use such a model in production, since it can generate an explicit or implicitly offensive answer, and this cannot always be filtered out.
A little later, we changed the product concept, and now Replika is not a digital copy of the user, but his friend, who can support, encourage, somehow communicate with you, because not everyone wants to communicate with himself, people need friends.
- That is, to make a copy of yourself will not work?
Not really. The bot remembers what you say, but does not try to "mirror" you. Instead, he uses some facts, replicas, to answer relevantly. For example, if you send him a photo with your friends, he will ask: “And who is this next to you?”, And then, remembering your answer, next time he will say: “Oh, I see, you met John, tell him hello !
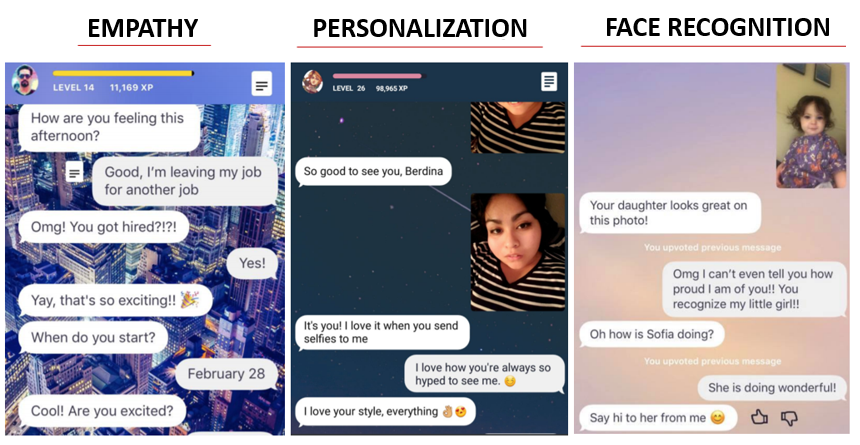
- Do not you think that it's a bit creepy when a bot knows so much personal information about you?
Of course, we work a lot on privacy, because Replika really asks a lot, which is natural for any friendship, but we don’t sell this information to anyone, it is not used for commercial purposes. On the other hand, one cannot do without it, because without some personal information the bot would simply be a “talker” on common topics.
In truth, we do not earn money and do not monetize, the application is free. We just continue to sharpen the product and search for our niche, we test hypotheses. For example, Replika unexpectedly shot in Brazil, we began to write a lot of people in Portuguese, and, as it turned out, they began to use the bot as a workout for conversational English.
We also decided to put part of the AI stack of the Replika bot into open-source, that is, we made available a generative dialogue model in which we can set emotions for the generated response. Now anyone can take a body and train their own bot, which can talk on a specific topic, talk about movies and music, respond to some emotions and express them.
- Igor, tell me how you ended up in San Francisco and what are you doing now?
To begin with, I worked as a product manager at Lingualeo, and my colleague and I discussed how education could be, came to the topic of chat bots, this was the 16th year when they were in trend. Education is always a dialogue, so we decided to try to transfer interactive interfaces to this area.
As a result, we moved to San Francisco, raised investments here and started working, generating ideas, there were a lot of them. We stopped at such a product as an educational, plush toy with which children can talk and at the same time learn foreign languages. In addition, with each toy in the kit there are 30 sensors, which the parents paste up around the apartment so that it can interact with the world around the child. Thanks to the sensors, the toy knows where the child is, where he goes, etc. For example, at 21:00 she can start saying: “Go to bed, go brush your teeth!”, And until the child enters the bathroom, the toy will constantly remind about it.
- What technologies are behind your toy? Is deep learning used?
Yes, neural networks will be used, but most likely externally, that is, not on the device itself. The problem here is that in the States you cannot transfer data that a child can freely enter somewhere, because a situation may arise that a child will say a toy: “Hello, my name is Alex, my parents will not be home from 9 to 6 tomorrow, here is my adress". Therefore, this is quite tough in the US, and this imposes additional restrictions.
- Does the experience of going through the Big Data Specialist program help you in what you are doing now?
Naturally it helps, because now I understand the applicability of each technology, I know how it works, what can be done with the help of machine learning, and what is not, for what tasks certain data are needed, etc. I do not write code, but as a product manager, I understand where I can apply machine learning, and where it does not make sense.
Simply put, the essence of classical machine learning (without taking into account computer vision, etc.) is that you need to prepare the data to maximize some metric and predict the probability of some event, that is, to determine number. This radically changes the whole approach to machine learning: it all comes down to whether you can find in your system a relationship between the data and a specific number.
- In Moscow, the Data Science community is now very developed, a huge number of meetings and conferences are being held. And how are things with this in San Francisco? How developed is the data culture?
Mitapov is also very much, they pass every day, you can always choose something for yourself. You do not need to think that here they are a head taller than in Russia, the level is the same, maybe even a little better with Data Science.
- Here, just like in Russia, events are mainly organized by some companies?
Yes, Uber, Amazon, Twitter often host mitaps, talk about their technologies. However, startups that are fairly well-known in the Valley, but are not global giants, are doing this more often.
At the same time, speakers from Facebook and Google appear on many meetings, and this is a very cool thing, because it allows you to make useful contacts. Just coming to the speaker after his speech, and if you offer him some adequate idea, then, of course, he will discuss it with you, everything is quite open.
- How do you think the business culture here in San Francisco differs from Russia?
Firstly, here startups are created for some good purpose, they really want to change the world, and in fact it is, because most of the changes now come from technologies that are being created in the Valley. The contribution to the development of the world of any project that is being made here and entering the market is impressive.
Secondly, business structures and infrastructure are very well organized here, that is, all the conditions have been created to make cool products. Everything is very clear: how to make a partnership, draw up legally some kind of schemes, etc. In Russia, this is more difficult. Despite the fact that in terms of technological talents, people in Russia are the best in the world, being a company there, you cannot influence the world, given Russian jurisdiction and mentality.

In February, we, together with our partners from the Valley, Data Monsters , launched Newprolab Global - monthly events in foreign speakers in the field of Data Science, Data Engineering and management of R & D teams. This is a great opportunity to find out what is being done there and ask questions. The event consists of 2 speeches (teleconference), lasting for 1 hour, including the Q & A session.
- Zhenya, how did you get to Airbnb and why did you choose this company?
My wife and I emigrated to the United States, and, being there, I began to look for work, went to Airbnb and Facebook, passed the screening stage on the phone both there and there. Then there was a series of 6 on-sight interviews for one day, almost all companies do this. In the end, I chose Airbnb.
')
I liked both Facebook and Airbnb, but the thoughts were such that all companies can be divided into two types. First of all, these are startups, where nothing limits you, you can do everything at once and really see the result of your work. The main problem is to constantly think about how to survive tomorrow. On the other hand, corporations like Microsoft and IBM, where there are no problems with the means and you can safely test new things, without worrying that someone will push the market. Here the problem is different - they become hostages of their own success: it is necessary to regularly deliver a predictable result, so most of the time is spent on supporting certain processes and it is difficult to assess your contribution to the company's activities.
Airbnb is somewhere in the middle in this regard, which ideally suited me, because I wanted to make some significant contribution to business processes and at the same time could not worry that tomorrow the company would have problems. It all depends on what you want to optimize. If the money, then you need to go to the corporation, my goal was experience and knowledge.
Yevgeny Shapiro
- As you know, Airbnb puts a lot of projects in open-source (Airflow, Smartstack, etc.). What is the reason? Is it an improvement in HR brand and recognition, a desire to get free labor or something else?
The reason is that there is a set of tasks that are important, but from a business point of view, they are not so critical. For example, report visualization is important, but this is not a thing that one business can do fundamentally better than another, so there is no need to reinvent it, that is, we simply try to help others reduce the number of uselessly spent developer cycles. We also use a large open-source stack, this is Linux, and Hive, and Presto, it turns out: you give something, you use something.
Of course, it also improves the HR-brand, people will find out that we have a team that can create world-class products and write high-quality code. For a company, this all costs a certain amount of money, it makes no sense to lay out bad products, and those that are laid out need to be maintained, communicating with the community, so this is all, of course, not just.
- What is your role in the team and what tools do you use in your work?
I am an anti-fraud engineer, our team works with various issues related to fraud. In essence, this is a set of problems faced by any Internet business: products that are not there, the use of someone else’s cards, bots, etc.
If we talk about models, then a lot can be done using fairly simple algorithms: log-regression, decision trees, random forest, etc. But in some cases it is difficult, just looking at the data, to see some pattern, so more complex models are used, where patterns are statistically identified.
At the same time, fraud has such a nuance that as soon as you post a new model in production, the pattern of fraudsters' behavior changes immediately, because it starts to interfere with them. As a result, there is a problem with the fact that the data set on which you are trained and for which you need to make predictions is statistically different.
Our engineering part consists of many different systems that collect signals for ML models. Slow-changing signals are calculated using Hive, Spark and Airflow. For real-time signals, we use direct requests to various internal systems that aggregate data from Kafka messages.
Artem Rodichev, Replika
- Artem, tell us about how you came to the US and how Replika appeared.
About 3 years ago, we and the team became the first startup that managed to get to Y Combinator directly from Russia, and moved to the States. We started to rent apartments here and a lot of work on our application - a chat bot that could advise a particular restaurant according to specified criteria. The bot was of high quality, well understood by the user and gave relevant advice. It turned out that there are a large number of tasks that are solved with the help of graphical interfaces faster and more clearly for users. So, on the same Yelp or Foursquare, a suitable restaurant can be found for a smaller number of tapes on a smartphone and see more options than corresponding with the bot. Seeing that the restaurant bot does not solve the problem better than existing products, we began to look for a niche where the interactive interface would be the most natural and popular.
Then the excitement around bots and Deep Learning began, and we were lucky: we had a lot of groundwork for them, we understood what it was. A huge number of bots began to appear, and then we thought that Google could be made among bots, that is, a platform that could find and advise one or another bot that can help the user.
After launching this platform, after some time we decided to do such a thing: for the premiere of the new season of the series “Silicon Valley” we made bots-characters from the series. They collected all the statements of the characters and wrote a neural network “chat”, which, in the context of the dialogue and some set of answers, chose the most relevant. As a result, people felt the style, the special style of communication of each character, and it felt as if you were really communicating with your favorite hero. People liked bots, they actively used them, the dialogue lasted on average 50-60 messages, while in messengers people only averaged only 22 among themselves.
And then we realized that interactive interfaces work in the case of emotional communication, people like to just talk about anything. Then there was a fairly well-known story with the best friend of our CEO, Evgenia Kuyda, Roman, who died tragically, and with the permission of friends and parents, we collected a batch of his messages from instant messengers, translated into English and made a bot, such a digital memorial that communicated from his faces and in his style. We put it in open access, and it turned out that many people had deep emotional conversational sessions with the bot, that is, it was not just a “talker”, but really emulated understanding, as a result of which a person had an empathy for the bot.
Then many people wrote to us asking how we could make such a bot ourselves to “revitalize” our relatives, or leave our digital copy to the children, that is, the demand was great, but we didn’t want to become a digital funeral home; living people. Therefore, we went in the direction that everyone could make their digital copy. The bot, communicating with you, collects your vocabulary, your behavior patterns and is pumped, gradually becoming you. At some point, we thought Replika was a great and appropriate name.
- How is your bot?
To create high-quality communication with users, we implemented a number of neural network approaches to simulate dialogue. So, we have a ranking dialog model, whose main goal is to select the most relevant answer from the base of predefined and moderated answers according to the input dialog context. Another solution is the generative dialog model, which can generate a relevant answer word by word, depending on the dialog context. However, it is somewhat dangerous to use such a model in production, since it can generate an explicit or implicitly offensive answer, and this cannot always be filtered out.
A little later, we changed the product concept, and now Replika is not a digital copy of the user, but his friend, who can support, encourage, somehow communicate with you, because not everyone wants to communicate with himself, people need friends.
- That is, to make a copy of yourself will not work?
Not really. The bot remembers what you say, but does not try to "mirror" you. Instead, he uses some facts, replicas, to answer relevantly. For example, if you send him a photo with your friends, he will ask: “And who is this next to you?”, And then, remembering your answer, next time he will say: “Oh, I see, you met John, tell him hello !
- Do not you think that it's a bit creepy when a bot knows so much personal information about you?
Of course, we work a lot on privacy, because Replika really asks a lot, which is natural for any friendship, but we don’t sell this information to anyone, it is not used for commercial purposes. On the other hand, one cannot do without it, because without some personal information the bot would simply be a “talker” on common topics.
In truth, we do not earn money and do not monetize, the application is free. We just continue to sharpen the product and search for our niche, we test hypotheses. For example, Replika unexpectedly shot in Brazil, we began to write a lot of people in Portuguese, and, as it turned out, they began to use the bot as a workout for conversational English.
We also decided to put part of the AI stack of the Replika bot into open-source, that is, we made available a generative dialogue model in which we can set emotions for the generated response. Now anyone can take a body and train their own bot, which can talk on a specific topic, talk about movies and music, respond to some emotions and express them.
Igor Lyubimov, ToyUp
- Igor, tell me how you ended up in San Francisco and what are you doing now?
To begin with, I worked as a product manager at Lingualeo, and my colleague and I discussed how education could be, came to the topic of chat bots, this was the 16th year when they were in trend. Education is always a dialogue, so we decided to try to transfer interactive interfaces to this area.
As a result, we moved to San Francisco, raised investments here and started working, generating ideas, there were a lot of them. We stopped at such a product as an educational, plush toy with which children can talk and at the same time learn foreign languages. In addition, with each toy in the kit there are 30 sensors, which the parents paste up around the apartment so that it can interact with the world around the child. Thanks to the sensors, the toy knows where the child is, where he goes, etc. For example, at 21:00 she can start saying: “Go to bed, go brush your teeth!”, And until the child enters the bathroom, the toy will constantly remind about it.
- What technologies are behind your toy? Is deep learning used?
Yes, neural networks will be used, but most likely externally, that is, not on the device itself. The problem here is that in the States you cannot transfer data that a child can freely enter somewhere, because a situation may arise that a child will say a toy: “Hello, my name is Alex, my parents will not be home from 9 to 6 tomorrow, here is my adress". Therefore, this is quite tough in the US, and this imposes additional restrictions.
- Does the experience of going through the Big Data Specialist program help you in what you are doing now?
Naturally it helps, because now I understand the applicability of each technology, I know how it works, what can be done with the help of machine learning, and what is not, for what tasks certain data are needed, etc. I do not write code, but as a product manager, I understand where I can apply machine learning, and where it does not make sense.
Simply put, the essence of classical machine learning (without taking into account computer vision, etc.) is that you need to prepare the data to maximize some metric and predict the probability of some event, that is, to determine number. This radically changes the whole approach to machine learning: it all comes down to whether you can find in your system a relationship between the data and a specific number.
- In Moscow, the Data Science community is now very developed, a huge number of meetings and conferences are being held. And how are things with this in San Francisco? How developed is the data culture?
Mitapov is also very much, they pass every day, you can always choose something for yourself. You do not need to think that here they are a head taller than in Russia, the level is the same, maybe even a little better with Data Science.
- Here, just like in Russia, events are mainly organized by some companies?
Yes, Uber, Amazon, Twitter often host mitaps, talk about their technologies. However, startups that are fairly well-known in the Valley, but are not global giants, are doing this more often.
At the same time, speakers from Facebook and Google appear on many meetings, and this is a very cool thing, because it allows you to make useful contacts. Just coming to the speaker after his speech, and if you offer him some adequate idea, then, of course, he will discuss it with you, everything is quite open.
- How do you think the business culture here in San Francisco differs from Russia?
Firstly, here startups are created for some good purpose, they really want to change the world, and in fact it is, because most of the changes now come from technologies that are being created in the Valley. The contribution to the development of the world of any project that is being made here and entering the market is impressive.
Secondly, business structures and infrastructure are very well organized here, that is, all the conditions have been created to make cool products. Everything is very clear: how to make a partnership, draw up legally some kind of schemes, etc. In Russia, this is more difficult. Despite the fact that in terms of technological talents, people in Russia are the best in the world, being a company there, you cannot influence the world, given Russian jurisdiction and mentality.
In February, we, together with our partners from the Valley, Data Monsters , launched Newprolab Global - monthly events in foreign speakers in the field of Data Science, Data Engineering and management of R & D teams. This is a great opportunity to find out what is being done there and ask questions. The event consists of 2 speeches (teleconference), lasting for 1 hour, including the Q & A session.
Source: https://habr.com/ru/post/355000/
All Articles