"Fant" and Okmeter: a symbiosis for the benefit of monitoring

Having gone a long way of system administration of Linux-servers, we managed to try various implementation options as basic tools for collecting statistics and monitoring. Samopisny scripts (and even web applications), Cacti, Zabbix - the most well-established options at one time or another, which have been replaced by Okmeter and Prometheus in recent years. In this article, we collected and combined: a) Okmeter's impressions of working with us, b) feedback from team leaders and engineers of Flant on using Okmeter in numerous and diverse projects we serve (from small to large, from fairly trivial web installations) hosting to clusters Kubernetes).
Why at all Okmeter?
The choice of a third-party solution - Okmeter - instead of the usual Zabbix self-hosted installations supplemented by centralized monitoring of specific services (correct functioning of web applications, backups, performance of cron tasks ...), did not happen immediately. In order for us to agree to “give into the wrong hands” such an important part of the operation process - collecting statistics and notifying the main part of the monitoring - we had to eat a lot of cacti. However, the accumulated thorns led to the understanding that for the full closure of this issue there are two ways: either to make your development, or to trust a ready-made solution, which, to our sincere regret, turns out to be not at all an Open Source-product and to which really serious requirements are put forward ( at a minimum, penalties fixed in SLA depend on its quality, and as a maximum, the level of our service and reputation as a whole).
Despite the fact that we have a small system development department, it’s not our priority activity (if to put it simply, it’s long and expensive) to create our own scale-up full-scale monitoring system (and keep it up to date). Therefore, a year ago, the second path was chosen, and we do not regret our decision. Why specifically Okmeter? There is no simple answer, but if we talk in general, we liked the opportunities provided and the level of reliability, adequate financial conditions and prospects for cooperation (in particular, the possibility of upgrading to our needs).
')
How did this choice help in practice? If it is customary to meet people according to their clothes, then admins meet their tools for ease of configuration and further maintenance. And in the case of Okmeter, our engineers describe it like this:
“Metrics (and graphics) are really just added - just prepare JSON for Okmeter. Simplification of life is that we stopped putting and servicing Zabbix, we do not waste time setting it up, we forgot about the fact that some graphics suddenly stopped drawing (although more often curved hands were to blame for this). Basic alerts are automatically added when the software is detected - it is very convenient, do not forget to add monitoring. ”
“In Zabbix, I had to screw the templates myself, collect what I really needed from different templates, and then - oops! - and immediately drawn.
“Fortunately, one installation of Okmeter can be connected to any database in the project. I even got RDS in AWS there. ”
“For us and for customers, database metrics and nginx are very indicative and often used. This is a must have. Because in Zabbix you will draw such a fig. ”
Interaction
Despite the importance of these technical amenities, they were not the only determining factor. The importance of our cooperation brought the possibility of mutually beneficial exchange of the results of core activities.
From the side of "Flanta" it looks like this:
- In some of the projects there was a non-standard problem.
- We could not identify it or (quite exhaustively / systemically) understand it on the basis of these graphs.
- We analyzed what additional monitoring capabilities (what data, from where, in what form) would help improve the situation (ie, our actions and understanding) next time, and transferred this information to Okmeter.
- Received improvements that have spread to all our projects.
Events unfolded in this way more than once and allowed to make additions to monitoring the work of such services as, for example, Sphinx, php-fpm, Postfix ...
There were also other interaction scenarios - for example, by targeting our engineers, some triggers for MySQL proved to be useless, and dozens of bug fixes were found and fixed for the same MySQL, Linux cgroups and others.
All this has obvious benefits for Okmeter: service developers are actively building up their knowledge base, thanks to a large number of different clients, and thanks to consultations on specific issues. But back to the technical side: how exactly do we use Okmeter and what do we especially appreciate?
Exploitation
1. General diagnosis
The first and most obvious use is the daily maintenance of Linux servers, for which we especially actively use such features as:
- graphs of load on system resources (processor, disk, memory) by processes, as well as top by requests (the latter is very important for investigating accidents after the fact - you can clearly see, for example, that a process ate all the memory an hour ago);
- nginx graphics, server response time graphs, requests for different URLs (grouped without GET parameters);
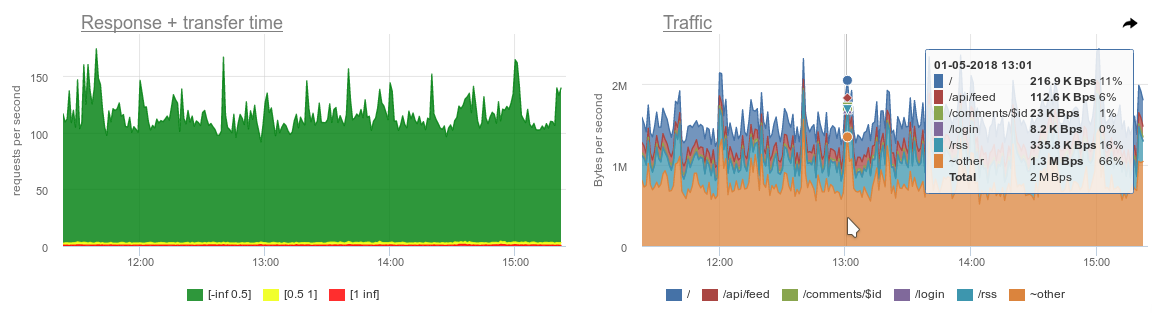
- statistics of connections by ports and addresses;
- top queries to the database, which, as one of our engineers put it, is “divine”.
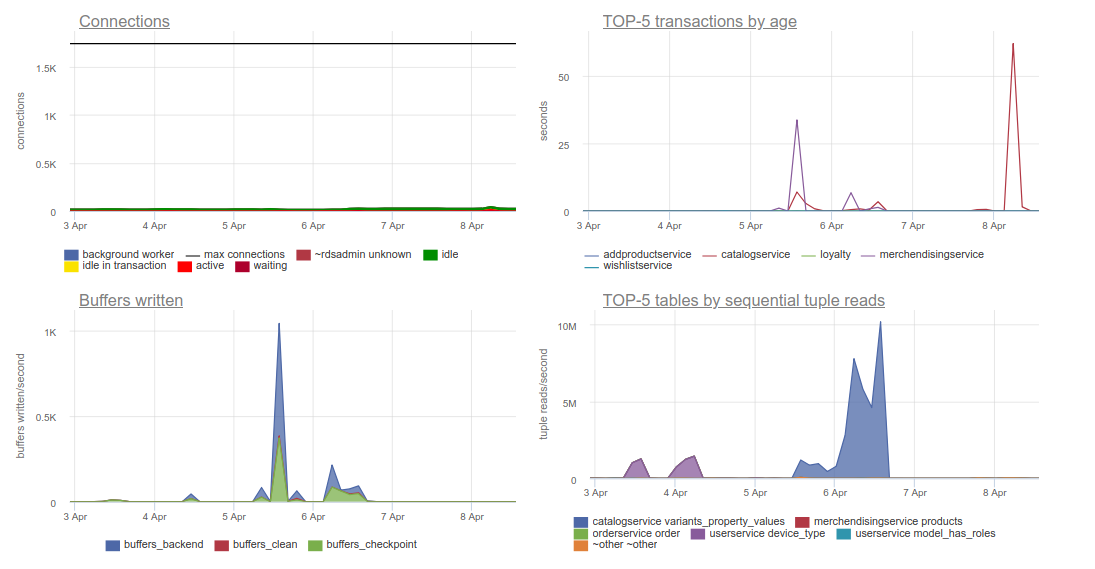
The surge by age (transaction duration) on the graph on the right above is a consequence of the recovery of the database without an index
2. Audit
Another frequent use of Okmeter with us is an audit of new projects. Before we start the service and only by signing a preliminary NDA, we issue a command to the client for execution on all servers. The result - we see a lot of metrics obtained using automatic discovery services.
Thus, statistics are quickly added even to a large number of servers, and the resulting standard graphs allow you to immediately see a number of indicators that help you understand the state of the infrastructure and form the first goals for its optimization / development:
- what processes are there on the servers and how much resources they consume;
- load on the database and web server;
- database sizes (relevant for Elasticsearch);
- … etc.
3. Containers
In the context of the specifics of operating Kubernetes clusters, Okmeter doesn’t have much of that. Nevertheless, the graphs of resource consumption broken down by containers (or served by Kubernetes) are familiar to us have, especially because of the problematic output of
docker stats in cases of a large number of containers deployed in K8s.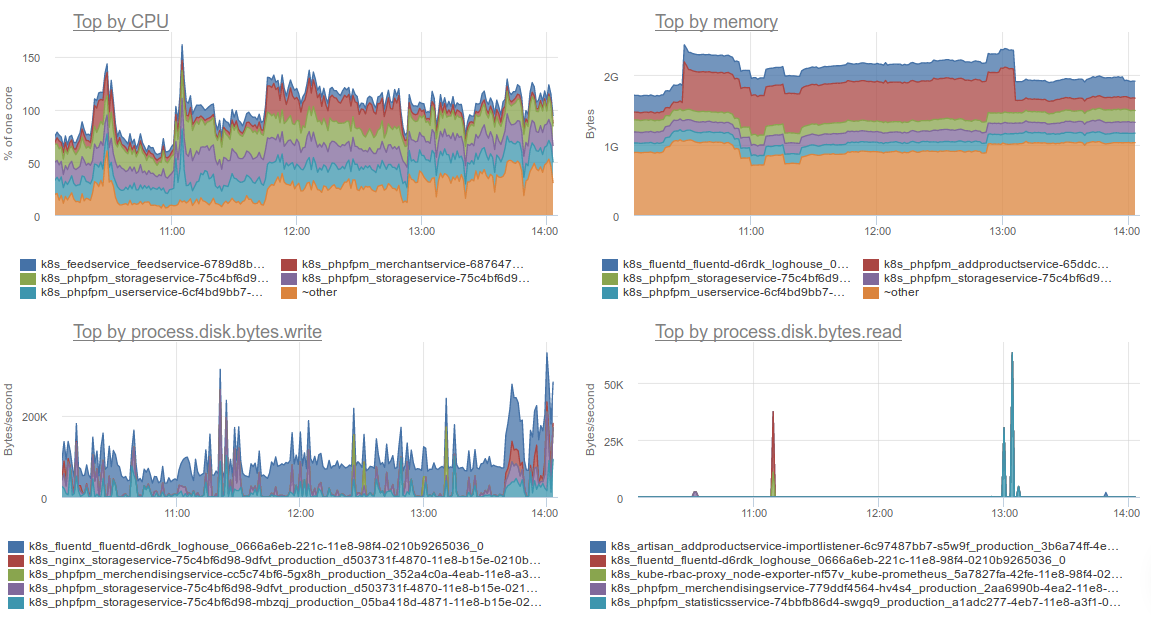
a) Resource Consumption by Container
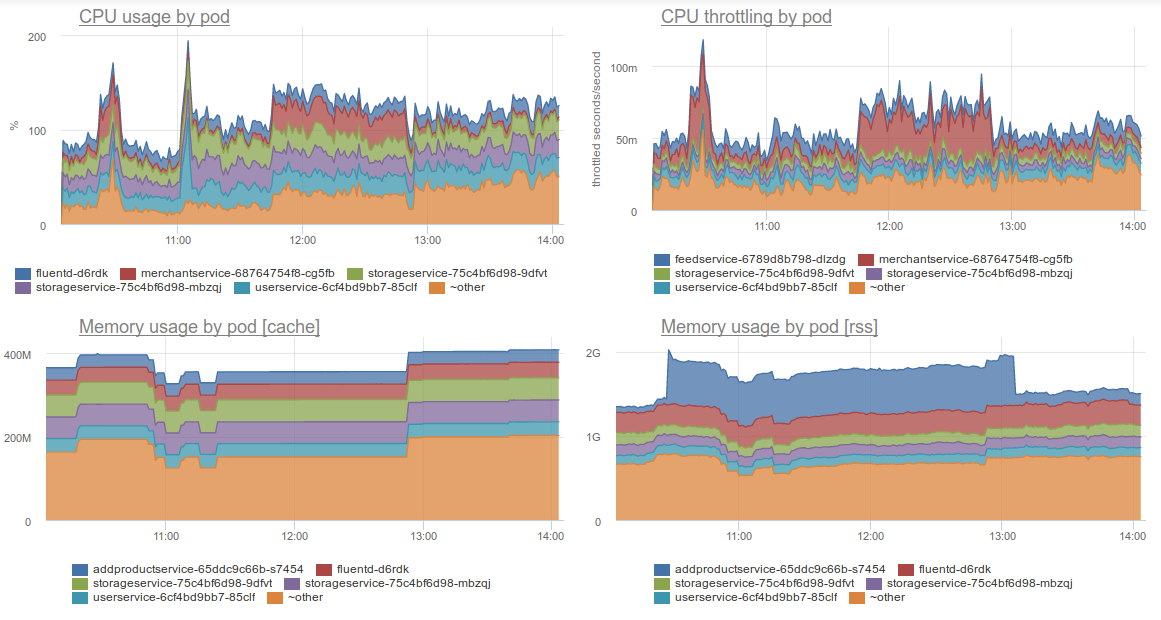
b) Consumption of resources by breakdown
Kubernetes’s full support has just begun to emerge, so we are now using Prometheus more to monitor K8s-specific indicators. But Okmeter is also aware of the prospects in this direction ...
Okmeter and Kubernetes
Talking about the interaction of "Flanta" and Okmeter as a whole (see above) , we deliberately omitted one specific and most intense area of joint interests - Kubernetes. Okmeter engineers use our knowledge and experience on Kubernetes to develop K8s monitoring in their service.
First of all, these are “live” clients, that is, clusters with K8s used in production. Each such installation is a useful data source for Okmeter, which allows you to see how Kubernetes functions in real life, what are the specifics and problems of its application, what is really important to its users.
Secondly, we (as such appeals come up) tell us how Kubernetes works, how it is deployed from specific users, and also “how it explodes” (what are the problems and what to look at first).
All this allowed Okmeter not only to improve their knowledge of Kubernetes, but also to make sure that this system is promising in the market as a whole. The presence of experts “within walking distance” also led to the quick introduction of K8s for their own needs, which corresponds to the dogfooding approach used in the company, and also contributed to the work on supporting Kubernetes in the service itself.
What is promised in this very support?
- The distribution of cluster resources between services running in K8s. All metrics can be viewed in the context of any K8s entities: from Deployment to a specific container in a specific market.
- Automatic triggers on the exhaustion of the service limit of resources.
- Problems in the work of services: container restarts, inability to start the required number of instances, etc.
- Capacity planning: how many resources are already “booked”, how many are left.
- The state of the K8s components: etcd, dns, apiserver, etc.
The main idea is a permanent audit of the basic settings of Kubernetes, created on the basis of the recommendations of the engineers of "Flants". And there will be, of course, the deployment agent Okmeter in the form of DaemonSet .
The described features are already beginning to appear in beta testing mode (for details, it’s better to contact NikolaySivko ) , and their full release is expected by September.
Results
The existing results of the cooperation between Okmeter and "Fant" are a symbiosis and synergy: we have a ready-made tool that plays an important role in our activities (but is not rational enough for internal development), with the possibility of improving it according to emerging needs, and the service is extensive ground for replenishment of their knowledge and professional assistance on specific technical issues. At the same time, over the course of cooperation, there is a trend in operation from “ordinary” projects to Kubernetes clusters, and the development of Okmeter in the appropriate direction.
PS
Read also in our blog:
- " The device and mechanism of work of Prometheus Operator in Kubernetes ";
- “ Monitoring with Prometheus at Kubernetes in 15 minutes ”;
- " 10 obvious steps to prepare the infrastructure of the online store for Black Friday ";
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes) ;
- " Infrastructure with Kubernetes as an affordable service ."
Source: https://habr.com/ru/post/354974/
All Articles