MIT course "Computer Systems Security". Lecture 1: "Introduction: threat models", part 2
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
If you think that the government is haunting you, security problems will be much more serious, because your computer may contain a malicious physical device, regardless of what programs are installed on it. Therefore, you should carefully approach the creation of a threat model, balancing it in the best possible way against a particular enemy. I think that the NSA standoff will cost you too much, but if you are trying to protect your Athena home directory from other students, you need not worry too much. So creating an optimal threat model looks like a balancing between various security requirements.
')
Another example of a bad threat model is a way to ensure Internet security by verifying the certificates of the sites you visit.

In these SSL / TLS protocols, when you connect to a site, the HTTPS value, that is, "secure connection", is displayed in the address bar. This means that this site received a security certificate signed by one of the certificate authorities, and which confirms that yes, this key really belongs to Amazon.com.
From the point of view of architecture, the error of the threat model is that it assumes that all these CA authorization centers are trustworthy and they will never make a mistake. But in fact, there are hundreds of SAs: the Indian Postal Administration has its own authorization center, and the Chinese government has it, and so on. And any of these centers can make a security certificate for any host or domain. As a result, if you are a bad guy and want to discredit Gmail or hack their website, you just need to compromise one of these authorization centers. And for this you can always find SA in a not too developed country. Thus, creating a threat model based on the assumption that all certified sites are safe is wrong. Because the assumption that all 300 authorization centers scattered around the globe are safe is wrong.
However, in spite of this, modern SSL still uses this assumption as the basis of its security mechanism for Internet browsers.
There are many examples of this kind, when the threat comes from where it was not expected. A funny example from the 80s is the project implemented by DARPA - the Office of Advanced Research Projects of the US Department of Defense. Then they really wanted to create invulnerable operating systems, and they attracted a bunch of universities and researchers who had to develop prototypes of secure operating systems.

After that, they created a team of "bad guys" who had to break into these secure systems in any way. As a result, it turned out that the server on which the source codes of all the operating systems were stored was on a computer in a completely unprotected office. The “bad guys” easily hacked this server, changed the source code and created a loophole in the OS based on it. Then, when the researchers built their operating systems, these fake hackers took advantage of the loophole and cracked them without much difficulty.
So you really need to think about all the possible assumptions about where your software comes from, and how a bad guy can get into it, to make sure your system is really safe. In the lecture notes there are many examples on this topic.
Probably the most common problem encountered in security mechanisms. In part, this is because the security mechanism is the most difficult part of it. This is a collection of software and hardware and other system components that enforce your security policy. And the reasons why this mechanism may break are innumerable.
So most of our lectures will be devoted specifically to security mechanisms, how to create mechanisms that ensure the correct application of security policies. We will also talk about security policy and threat models.
It turns out that it is much easier to create clear and precise principles for the development of mechanisms, to understand how they work or do not work, what to do with policies and models of threats that you need to “fit” into the contents of specific systems.
Consider some examples of errors when creating security mechanisms. You could have heard about the latter case a couple of days ago - it deals with problems with the Apple iCloud cloud service security mechanism. Anyone who has an iPhone can use the iCloud service. This service is a cloud-based file storage, and if you lose your iPhone, your files will still be stored in this cloud, it will help you find your phone, if you have lost it, and contains many more useful functions. I think that this iCloud is a “relative” of the service me.com, which was created in the same way a few years ago.
The problem that was discovered in iCloud was that the creators did not use the same security mechanism for all interfaces. Consider what this service looks like.

Various services are connected to the iCloud service, such as File Storage, Photo Archive, Phone Search and so on. All these services check if you are the correct user, if you are authenticated correctly. Probably, different performers were involved in the development of this complex service, who created different security interfaces for the services included in it. For example, the Find My iPhone service did not track how many times in a row you tried to log in to the system. This feature is very important, as I mentioned earlier that people do not bother to create a really strong password.
In fact, the system that authenticates users with passwords is pretty tricky, we'll talk about this later. But there is one good strategy, which consists in the fact that out of a million selected passwords there is one that will definitely fit into something account. So if you can create a million password options for this account, you can probably enter it, because people don’t bother to create complex passwords.
Therefore, one of the ways to protect against password guessing is that the system does not allow you to make an unlimited number of login attempts several times in a row. It is possible that after 3 or 10 unsuccessful attempts, the system activates the timeout and prompts you to try entering the password again after 10 minutes, or even an hour. This really slows down a hacker, as he can make only a few attempts to find a password instead of a million per day. And even if you do not have a very difficult password, it will be difficult for an attacker to pick it up due to large losses of time.
But in the interface “Find My iPhone” this function is not provided. A “bad guy” can send a million password packets a day, hack this service and steal iCloud's confidential data, which was the case.
This is an example of the fact that you had the correct security policy - only the correct user and the correct password can give access to the files. You even had the right security threat model that the bad guys would try to guess the password, so you need to do this by limiting the number of input attempts. However, the developer of the service just screwed up because his security mechanism contained an error. He simply forgot to apply the correct policy and the correct mechanism in one interface.
And this appears again and again in various systems, where they simply made a mistake once, and this affected the security of the entire system. There are many errors of this kind, for example, when a developer forgot to check access control in general.
For example, City Bank has a website that allows you to view your credit card information. That is, if you have a card of this bank, you go to the site and it tells you:
“Yes, you have this credit card, here are your operations,” and so on. A few years ago, the working procedure was that you enter a site, enter your username and password, and you are redirected to a site that, say, has an address, for example: citi.com/account?id=1234. It turns out that some guy guessed that if you just change these numbers, you will freely go into someone else's account. So it is not clear what to think about the developers of such a system?

Perhaps these guys thought correctly, but forgot to check how their security function works on the account page, that is, that not only can I have the correct ID number, but it can also be the ID number of the guy who has just logged in. This is an important test, but they have forgotten about it.
Or maybe the developers thought that nobody could use this URL except for you? Maybe they just had a bad threat model? Maybe they thought that if they did not type this address in the form of a link, then no one would be able to click on it? This is an example of a bad threat model. Maybe so, in any case, it is difficult to say what they were guided by, releasing such a product. Such mistakes often happen, and even a small, imperceptible mistake in the security mechanism can lead to sad consequences.
Another example, which is not so much in the identification verification errors, is represented by a problem identified in Android smartphones several months ago. This problem was related to bitcoins, I am sure that you heard about them - this is electronic currency, which is quite popular these days. The way that the Bitcoin system works, quite advanced, is that your balance is connected with the use of a personal key. Therefore, if you have someone's personal key, you can spend it bitcoins. Bitcoin security is based on the assumption that no one knows your key. It's like a password, but more important, because people can make many attempts to unravel your key. However, there is no real server to verify the keys. This is just encryption. Therefore, any computer can try to decrypt the key, and if it works out, they will be able to transfer your bitcoins to someone else. It is therefore extremely important to generate reliable, complex keys that no one can unravel.
There are people who use their bitcoins from a smartphone running Android. There is a Java API mobile application called SecureRandom that generates random key values for Bitcoin. However, people found out that in reality these are not at all random numbers. This application contains a pseudo-random number generator, or PRNG. SecureRandom gives it an initial array of several hundred random bits that the PRNG can “stretch” to as many random bits as you like. That is, first you use the original array, a kind of "seed", and then generate from it any desired number of bits, that is, cultivate your crop of keys.

Thanks to various cryptographic principles, I will not go into them, it really works. If you initially provide this PRNG with a few hundred really random bits, it will be extremely difficult to guess which pseudo-random numbers it will generate. But the problem is that there was a small error in this java library. Under certain circumstances, she forgot to provide PRNG with initial values, and the array consisted of only zeros. This meant that anyone could find out what random numbers the PRNG generated for your keys. If they start with zeros, then they generate the same values, and the hacker easily gets the same personal key as yours. That is, it simply generates your key and manages your bitcoins.
This is another example of how a seemingly small mistake of a security mechanism can lead to catastrophic results. Many people lost their bitcoins because of this. Of course, such errors are corrected at some level; you can change the Java implementation in the SecureRandom application so that it always fills the PRNG with a random array of source bits. But in any case, this is another example of the erroneous operation of the security mechanism.
Question from the audience:
- Explain whether this is different from an attack on the DSA digital signature creation algorithm?
Answer:
- In fact, the problem is much more complicated than what you are hinting at. The problem is that even if you didn’t generate your key first on your Android device, a specific Bitcoin signature scheme assumes that every time you generate a new signature using this key, you use one-time fresh, or as it is called, “nonce "Source for such a generation. And if you ever generate two signatures based on a one-time source, someone can repeat your key.
These cases are similar, but differ in details. If you can generate a key somewhere other than Android, and it will be a really reliable key, then every time you try to generate 2 signatures from the same nonce or random value, someone will be able to calculate your sign and extract your public key from them. Or, more importantly, the personal key.
I want to reiterate that any detail in computer security is important. If you make a seemingly insignificant error, for example, forget to check something, or forget to initialize a random array of source data, this can have serious consequences for the entire system.
You should have a clear idea of what features, characteristics of your system, what it should do and what surprises are hidden around the corner. In this sense, it’s good to think about how to hack your system, test it from all sides, for example, what happens if I give too free access, or what is the most “non-free” of all free access I can leave? What kind of data should I put into my system in order to plug all sorts of gaps?
One good example of this ambiguity is SSL certificates that encrypt names into the certificate itself. This problem is different from the problem of trusting CA. SSL certificates are simply a sequence of bytes sent to you by the web server. Inside this certificate is the name of the resource to which you are connecting, for example, Amazon.com. You know that you cannot just write these bytes. You need to somehow encrypt them and indicate that this is Amazon.com, and place them at the end of the line.
So, SSL certificates use a certain encryption scheme that writes Amazon.com, first writing down the number of bytes in a string.
Great, you need to write them down first. Let me have a 10 byte string called Amazon.com, it really consists of 10 bytes. Wonderful. We have 10 bytes, which are letters of the name and a dot, and behind and in front of these 10 bytes there can be some other characters in the string.
Then the browser, which is written in C, takes these bytes for processing. This language represents strings with 0, meaning end of string. Thus, in C there is no row length counter. Instead, it takes into account all the bytes, and the end of the string for it is just a zero byte. At the end of the line C writes it with a backslash - “\”, that is, it looks like amazon.com \ 0.

All this is in the memory of your browser. Somewhere in his memory there is now a line of 11 bytes with zero at the end. And when the browser interprets this line, it continues along it until it sees a zero marker at the end of the line.
Question from the audience:
- Do we have 0 in the middle of the line?
Answer:
- Yes it is. And in this sense, there is a gap in understanding how the browser interprets strings.
Suppose I own a domain foo.com. I can get a certificate for “anything- foo.com”. Thus, I can ask for a certificate in the name amazon.com \ 0x.foo.com. From the point of view of the browser, this is an absolutely correct line. This is a 20 byte name consisting of 20 bytes.
It used to be that you could go to the CA authorization center and say, "Hey, I own foo.com, give me a certificate for this thing!". And they would be perfectly prepared to do this, because amazon.com0x is a subdomain of foo.com, and it is completely yours.
But then, when the browser takes this line and loads it into memory, it does the same thing that I described earlier - it copies the string. amazon.com0x.foo.com and obediently add one more zero to the end of this line - amazon.com \ 0x.foo.com \ 0.
, , , 0 , : «, !» , . Amazon.com.
, SSL . (Moxie Marlinspike), .
, , , . , , « ». , , , . , .

, , . 6.033. , . , , , -.
, , -. - – , , , , , , , - . URL - , , - . , , , - .
, . ?
, . , , . - , . , - , , , .
, , -, , , . , , , , , . . , . , .
, , - , - . , , . , , - - .

, , -, . – , , , , , , . -, .
, , . , ( , , ), , . SSL-, . .
, .
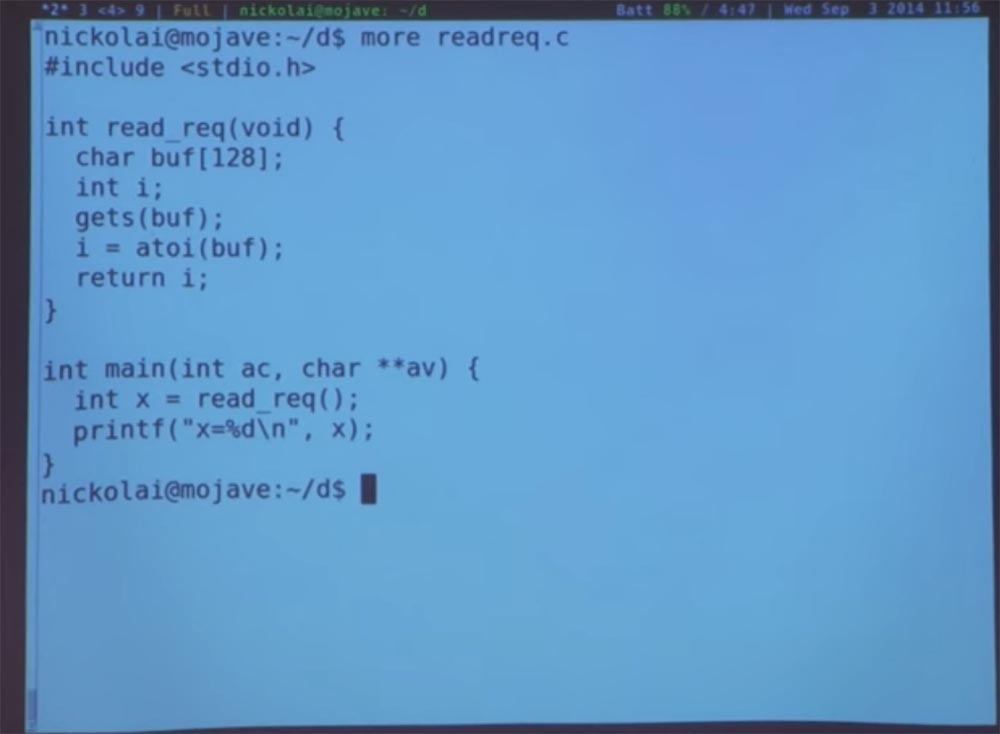
, , . , . , . , , . , , . .
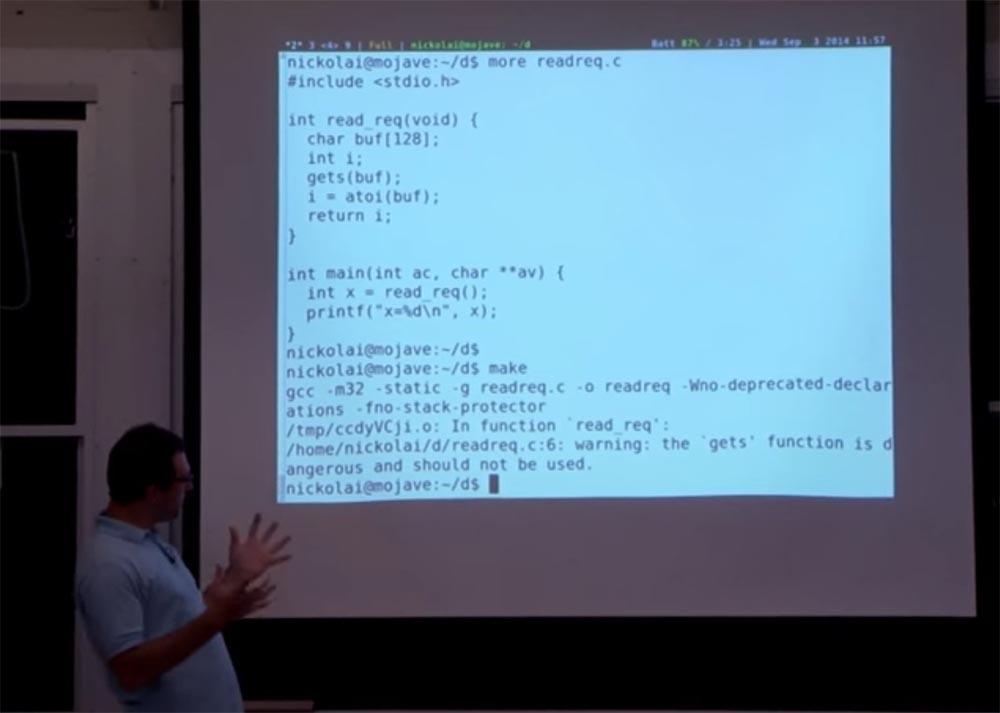
, : « ». , , - . , , , . , , , .
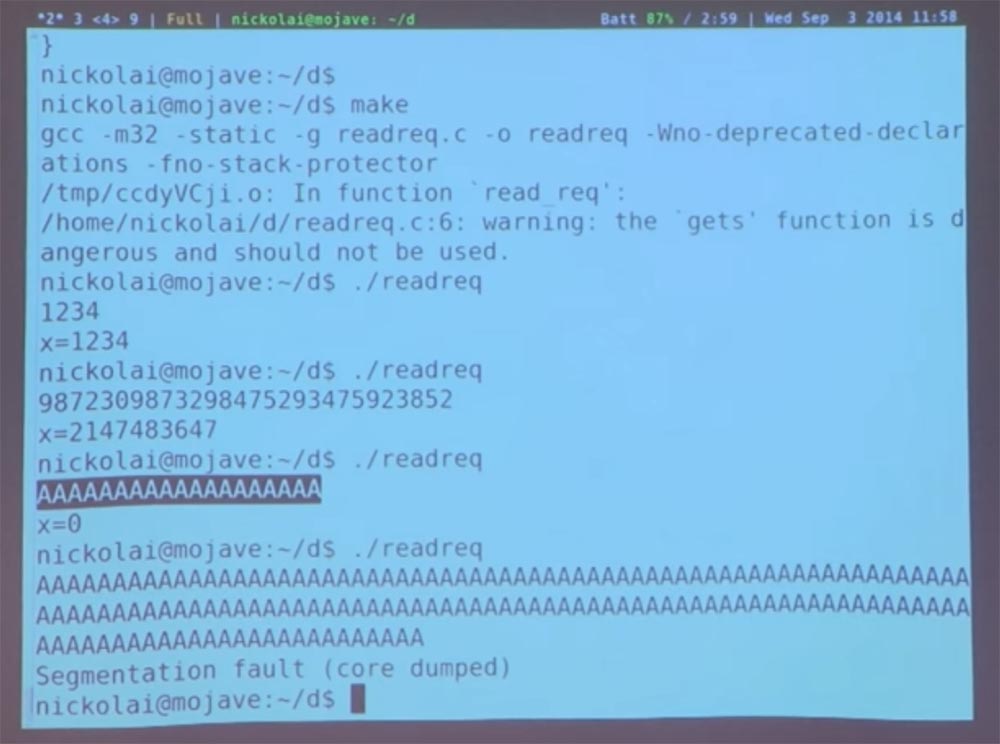
, , . 1234 = 1234, 28 ( = 2147483647) 10 . , .
19 = 0. , . . , , , 3 ? !
- . «», , . , , , , , , - , , .
: MIT « ». 1: «: », 3
.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/354894/
All Articles