Practice implementing Cisco ISE. Engineer's look
Cisco ISE is a tool for creating an access control system for a corporate network. That is, we control who connects, from where and how. We can determine the client device, how it complies with our security policies, and so on. Cisco ISE is a powerful mechanism that allows you to clearly control who is in the network and what resources it uses. We decided to talk about our most interesting projects based on Cisco ISE and at the same time recall a couple of unusual solutions from our practice.
The Cisco Identity Services Engine (ISE) is a solution for controlling access to the corporate network according to the access context. The solution integrates authentication, authorization, and event accounting (AAA) services, state assessment, profiling, and guest access control within a single platform. Cisco ISE automatically detects and classifies end devices, provides the necessary level of access, authenticating both users and devices, and also ensures that end devices comply with information security policy by assessing their security status before providing access to corporate IT infrastructure. The platform supports flexible access control mechanisms, including security groups (SG), security group labels (SGT) and security group access control lists (SGACL). We will talk about this below.
90% of our deployments include wireless access protection. Our customers are very different. Someone is buying new top-end equipment from Cisco, and someone is using what is, because the budget is limited. But for the most secure wired access, the simplest models do not fit; you need certain switches. And they are not at all. Wireless access controllers, if built on Cisco solutions, typically require only an update to support Cisco ISE.
')
For wireless access, a single controller and a bunch of points are usually used. And since we undertake wireless access, the majority of customers - about 80% - want to implement guest access, because it is convenient to use the same infrastructure for both user and guest access.
Although the industry is moving towards virtualization, half of our customers choose hardware solutions in order not to depend on the virtualization environment and the allocation of resources. The devices are already balanced, they have the right amount of RAM and processors. Customers can not worry about the allocation of virtual resources, many still prefer to take a place in the rack, but at the same time be calm that the solution is optimized for this hardware implementation.
What is our sample project? Highly likely this is wireless access protection and guest access. We all love to bring our own devices to work and go online with them. But even today, not all gadgets have GSM modules. In order not to reduce security due to the connection to the corporate network of personal devices, the BYOD infrastructure is allocated, which allows you to register your personal device automatically or semi-automatically. The system will understand that this is your gadget, not a corporate one, and will only provide you access to the Internet.
How is it done with us? If you bring your phone and connect via Wi-Fi, you will only be released to the Internet. If you connect a working laptop via Wi-Fi, it will also be allowed into the office network and all resources. This is BYOD technology.
Often, to protect against brought devices, we also implement EAP-chaining technology, which allows you to authenticate not only users, but also workstations. That is, we can determine whether a domain laptop or someone’s personal laptop is connected to the network and, depending on this, apply some policies.
That is, in addition to “authenticated / not authenticated”, “domain / non-domain” criteria appear. Based on the intersection of the four criteria, different policies can be set. For example, a domain machine, but not a domain user: it means that the administrator has come to configure something locally. Most likely, he will need special rights in the network. If it is a domain machine and a domain user, then we give standard access according to privileges. And if a domain user, but not a domain machine, this person brought his own personal laptop and it should be restricted in access rights.
We also recommend that everyone use profiling for IP phones and printers. Profiling is the definition of indirect signs of what kind of device is connected to the network. Why is it important? Take the printer. Usually he stands in the corridor, that is, there is a socket nearby, which is often not watched by a surveillance camera. Pentesters and intruders often use this: they connect a small device with several ports to a power outlet, put it behind a printer, and the device can walk around the network for a month, collect data, and get access. Moreover, the printers are not always limited in their rights, at best, thrown into another VLAN. Often this leads to a security risk. If you set up profiling, then as soon as this device enters the network, we will find out about it, come in, take out of the outlet and figure out who left it here.
Finally, we regularly use posturing - we check users for compliance with information security requirements. We usually apply this to remote users. For example, someone connected via VPN from home or business trip. Often he needs critical access. But it is very difficult for us to understand whether he is good at information security on a personal or mobile device. And posturing allows us to check, for example, whether the user has antivirus that is up to date, whether it is running, whether it has any updates. So you can, if not exclude, then at least reduce the risks.
And now we will tell about the curious project. One of our customers bought Cisco ISE many years ago. The information security policy in the company is very tough: everything that can be stated is not allowed to connect to the network of other devices, that is, no BYOD. If the user has disconnected his computer from one outlet and plugged it into the next, this is already an information security incident. Antivirus with the highest level of heuristics, local firewall prohibits any incoming connections.
The customer really wanted to receive information about which corporate devices are connected to the network, what version of the OS there is, and so on. Based on this, he formed a security policy. Our system to determine the devices required a variety of indirect data. DHCP probes are the best option: for this we need to receive a copy of DHCP traffic, or a copy of DNS traffic. But the customer categorically refused to send us traffic from its network. And there were no other effective samples in its infrastructure. We began to think about how we can determine the workstations where the firewall is located. Scan outside we can not.
In the end, we decided to use the LLDP protocol, an analogue of the Cisco CDP protocol, through which network devices exchange information about themselves. For example, the switch sends a message to another switch: “I am a switch, I have 24 ports, there are such VLANs, such settings”.
We found a suitable agent, put it on a workstation, and it sent our switches data about the connected computers, their OS and the composition of the equipment. At the same time, we were very lucky that ISE allowed us to create custom profiling policies based on the data obtained.
With the same customer came out and not the most pleasant case. The company had a Polycom conference station, which is usually placed in negotiations. Cisco announced support for Polycom equipment a few years ago, and therefore the station had to be profiled out of the box, the necessary built-in policies were contained in Cisco ISE. ISE saw and supported it, but at the customer, the station was profiled incorrectly: it was defined as an IP phone without specifying a specific model. And the customer wanted to determine in which conference room which model was worth.
Began to find out. Initial device profiling is performed based on the MAC address. As you know, the first six digits of the MAC are unique to each company and are reserved in a block. During the profiling of this conference station, we turned on debug mode and saw a very simple event in the log: ISE took the MAC and said it was Polycom, not Cisco, so I will not do any polling for CDP and LLDP.
We wrote to the vendor. From another copy of this conference station, they took the MAC address, which only in a few digits differed from ours - it was profiled correctly. It turned out that we were just unlucky with the address of this particular station, and as a result, Cisco almost released a patch for it, after which the client also began to profile correctly.
And finally, I want to talk about one of the most interesting projects of recent times. But first you need to recall the technology called SGT (Security Group Tag).
Now, at one of the customers, we have configured IP and SGT mapping, which allowed us to select 13 segments. They intersect in many ways, but thanks to the granularity, at which the lowest occurrence is always selected, down to a specific host, we were able to segment all this. ISE is used as a single repository for labels, policies, and IP and SGT compliance data. First, we identified the tags: 12 - development, 13 - this is production, 11 - testing. Further, it was determined that between 12 and 13 it is possible to interact only via the HTTPS protocol, between 12 and 11 there should be no interaction, and so on. The result is a list of networks and hosts with corresponding labels. And the entire system is implemented on four Nexus 7000 in the customer data center.
What benefits did the customer get?
Now atomic politicians are available to him. It happens that in one of the networks administrators mistakenly deploy a server from another network. For example, a production from host has been lost in the development network. As a result, then you have to transfer the server, change the IP, check whether communication with neighboring servers is broken. But now you can simply microsegment the “alien” server: declare it part of production and apply different rules to it, unlike members of the rest of the network. And at the same time the host will be protected.
In addition, the customer can now store and manage policies centrally and fault tolerantly.
But it would be really cool to use ISE to dynamically label users. We will be able to do this not only on the basis of the IP address, but also depending on the time, on the user's location, on his domain and account. We can register that if this user sits in the head office, he has some privileges and rights, and if he came to the branch, he is already seconded and has limited rights.
I would also like to watch the logs on ISE itself. Now, when using four Nexus and ISE as a centralized repository, you have to go to the switch itself to view the logs, injecting requests into the console and filtering responses. If we take advantage of Dynamic Mapping, then ISE will start collecting logs, and we will be able to centrally see why some user did not fall into a certain structure.
But so far these features have not been implemented, because the customer decided to protect only the data center. Accordingly, users come outside, and they are not connected to ISE.
Verification Center
This important innovation appeared in version 1.3 in October 2013. For example, one of our clients had printers that worked only with certificates, that is, were able to authenticate not with a password, but only with a certificate on the network. The client was upset that he could not connect the devices due to the lack of a TC, and for the sake of five printers did not want to deploy it. Then, using the integrated API, we were able to issue certificates and connect printers in a regular way.
Cisco ASA Change of Authorization (CoA) Support
Since the advent of CoA support on the Cisco ASA, we can control not only users who come to the office and connect to the network, but also remote users. Of course, we could have done this before, but for this we needed a separate IPN node device to apply authorization policies that proxied the traffic. That is, besides the fact that we have a firewall that terminates the VPN, we had to use another device only to apply the rules in Cisco ISE. It was expensive and uncomfortable.
In version 9.2.1 in December 2014, the vendor finally added support for change of authorization to Cisco ASA, as a result, all the functionality of Cisco ISE was supported. Several of our customers happily sighed and were able to use the released IPN node with more benefit than simply terminating VPN traffic.
TACACS +
All of us have been waiting for the implementation of this protocol for a long time. TACACS + allows you to authenticate administrators and log their actions. These features are very often used in PCI DSS projects for admin control. Previously, there was a separate Cisco ACS product for this, which was slowly dying until the Cisco ISE finally took over its functionality.
AnyConnect Posture
The emergence of this functionality in AnyConnect has become one of the breakthrough features of Cisco ISE. What feature is seen in the following picture. How does the posturing process look like: the user is authenticated (by login, password, certificate or MAC), and the policy with access rules arrives in response to it from Cisco ISE.
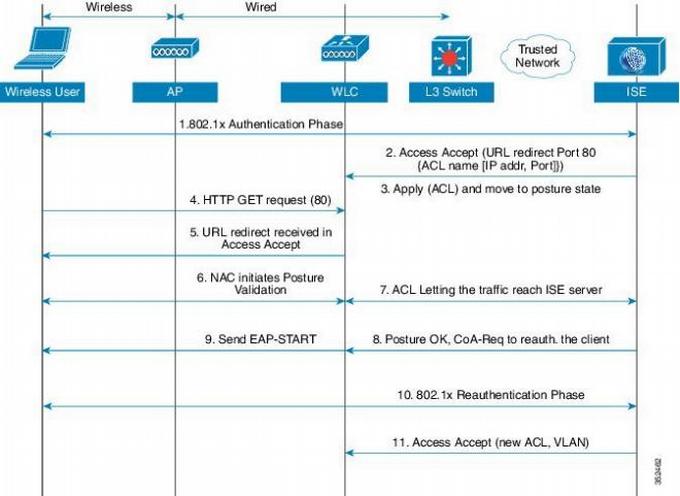
If it is necessary to check the user for compliance, redirect is sent to it - a special link that redirects all or part of the user's traffic to a specific address. The client at this moment has a special agent installed for posturing, who occasionally goes online and waits. If he is redirected to the ISE server, he will take the policy out of there, check the workstation for compliance with it and draw some conclusions.
Previously, the agent went and checked the URL every five minutes. It was long, inconvenient and at the same time littered with empty traffic network. Finally, this mechanism is included in AnyConnect. At the network level, he understands that something happened to her. Let's say we connected or reconnected to the network, or connected to Wi-Fi, or built a VPN — AnyConnect will know and work as a trigger for the agent about all these events. Due to this, the waiting time for the start of posturing has changed from 4-5 minutes to 15 seconds.
There was an interesting case with functionality, which first disappeared in one of the versions, and after a while it was returned.
Cisco ISE has accounts for guest access: a network in which even secretaries can issue passwords. And there is a very convenient feature when the system administrator can make a pack of guest accounts, seal them in envelopes and give them to the person in charge. These accounts will be valid for a specific time. For example, in our company it is a week from the moment of the first entry. The user is given an envelope, he prints it out, enters, the counter starts ticking. Convenient and practical.
Initially, this functionality has been since the advent of Cisco ISE, but in version 1.4 it disappeared. And after a few years, in version 2.1 it was returned. Due to the lack of guest access, we did not even update the Cisco ISE version for more than two years because we were not ready to restructure our business processes for the sake of it.
* * *
At parting, I remembered a funny story. Remember, we talked about a client with a very strict security policy? It is located in the Far East, and once the time zone changed there - instead of GMT + 10 it became GMT + 11. And since the customer was set up simply “Asia / Sakhalin”, he turned to us so that we could realize an accurate time display.
We wrote to Cisco, they answered that in the near future time zones would not be updated, because it took too long. They offered to use the standard zone GMT + 11. We set it up, and it turned out that Cisco had not tested its product enough: the belt became GMT-11. That is, the client time left for 12 hours. What is the most funny, in GMT + 11 is Kamchatka and Sakhalin, and in GMT-11 there are two American islands. That is, Cisco simply did not assume that someone would buy a product from these time zones from them, and did not conduct tests. They fixed this bug for quite some time, apologized.
Stanislav Kalabin, expert of the department of engineering support and information security services, Jet Infosystems
What is Cisco ISE
The Cisco Identity Services Engine (ISE) is a solution for controlling access to the corporate network according to the access context. The solution integrates authentication, authorization, and event accounting (AAA) services, state assessment, profiling, and guest access control within a single platform. Cisco ISE automatically detects and classifies end devices, provides the necessary level of access, authenticating both users and devices, and also ensures that end devices comply with information security policy by assessing their security status before providing access to corporate IT infrastructure. The platform supports flexible access control mechanisms, including security groups (SG), security group labels (SGT) and security group access control lists (SGACL). We will talk about this below.
Some of our statistics
90% of our deployments include wireless access protection. Our customers are very different. Someone is buying new top-end equipment from Cisco, and someone is using what is, because the budget is limited. But for the most secure wired access, the simplest models do not fit; you need certain switches. And they are not at all. Wireless access controllers, if built on Cisco solutions, typically require only an update to support Cisco ISE.
')
For wireless access, a single controller and a bunch of points are usually used. And since we undertake wireless access, the majority of customers - about 80% - want to implement guest access, because it is convenient to use the same infrastructure for both user and guest access.
Although the industry is moving towards virtualization, half of our customers choose hardware solutions in order not to depend on the virtualization environment and the allocation of resources. The devices are already balanced, they have the right amount of RAM and processors. Customers can not worry about the allocation of virtual resources, many still prefer to take a place in the rack, but at the same time be calm that the solution is optimized for this hardware implementation.
Our sample project
What is our sample project? Highly likely this is wireless access protection and guest access. We all love to bring our own devices to work and go online with them. But even today, not all gadgets have GSM modules. In order not to reduce security due to the connection to the corporate network of personal devices, the BYOD infrastructure is allocated, which allows you to register your personal device automatically or semi-automatically. The system will understand that this is your gadget, not a corporate one, and will only provide you access to the Internet.
How is it done with us? If you bring your phone and connect via Wi-Fi, you will only be released to the Internet. If you connect a working laptop via Wi-Fi, it will also be allowed into the office network and all resources. This is BYOD technology.
Often, to protect against brought devices, we also implement EAP-chaining technology, which allows you to authenticate not only users, but also workstations. That is, we can determine whether a domain laptop or someone’s personal laptop is connected to the network and, depending on this, apply some policies.
That is, in addition to “authenticated / not authenticated”, “domain / non-domain” criteria appear. Based on the intersection of the four criteria, different policies can be set. For example, a domain machine, but not a domain user: it means that the administrator has come to configure something locally. Most likely, he will need special rights in the network. If it is a domain machine and a domain user, then we give standard access according to privileges. And if a domain user, but not a domain machine, this person brought his own personal laptop and it should be restricted in access rights.
We also recommend that everyone use profiling for IP phones and printers. Profiling is the definition of indirect signs of what kind of device is connected to the network. Why is it important? Take the printer. Usually he stands in the corridor, that is, there is a socket nearby, which is often not watched by a surveillance camera. Pentesters and intruders often use this: they connect a small device with several ports to a power outlet, put it behind a printer, and the device can walk around the network for a month, collect data, and get access. Moreover, the printers are not always limited in their rights, at best, thrown into another VLAN. Often this leads to a security risk. If you set up profiling, then as soon as this device enters the network, we will find out about it, come in, take out of the outlet and figure out who left it here.
Finally, we regularly use posturing - we check users for compliance with information security requirements. We usually apply this to remote users. For example, someone connected via VPN from home or business trip. Often he needs critical access. But it is very difficult for us to understand whether he is good at information security on a personal or mobile device. And posturing allows us to check, for example, whether the user has antivirus that is up to date, whether it is running, whether it has any updates. So you can, if not exclude, then at least reduce the risks.
Tricky task
And now we will tell about the curious project. One of our customers bought Cisco ISE many years ago. The information security policy in the company is very tough: everything that can be stated is not allowed to connect to the network of other devices, that is, no BYOD. If the user has disconnected his computer from one outlet and plugged it into the next, this is already an information security incident. Antivirus with the highest level of heuristics, local firewall prohibits any incoming connections.
The customer really wanted to receive information about which corporate devices are connected to the network, what version of the OS there is, and so on. Based on this, he formed a security policy. Our system to determine the devices required a variety of indirect data. DHCP probes are the best option: for this we need to receive a copy of DHCP traffic, or a copy of DNS traffic. But the customer categorically refused to send us traffic from its network. And there were no other effective samples in its infrastructure. We began to think about how we can determine the workstations where the firewall is located. Scan outside we can not.
In the end, we decided to use the LLDP protocol, an analogue of the Cisco CDP protocol, through which network devices exchange information about themselves. For example, the switch sends a message to another switch: “I am a switch, I have 24 ports, there are such VLANs, such settings”.
We found a suitable agent, put it on a workstation, and it sent our switches data about the connected computers, their OS and the composition of the equipment. At the same time, we were very lucky that ISE allowed us to create custom profiling policies based on the data obtained.
With the same customer came out and not the most pleasant case. The company had a Polycom conference station, which is usually placed in negotiations. Cisco announced support for Polycom equipment a few years ago, and therefore the station had to be profiled out of the box, the necessary built-in policies were contained in Cisco ISE. ISE saw and supported it, but at the customer, the station was profiled incorrectly: it was defined as an IP phone without specifying a specific model. And the customer wanted to determine in which conference room which model was worth.
Began to find out. Initial device profiling is performed based on the MAC address. As you know, the first six digits of the MAC are unique to each company and are reserved in a block. During the profiling of this conference station, we turned on debug mode and saw a very simple event in the log: ISE took the MAC and said it was Polycom, not Cisco, so I will not do any polling for CDP and LLDP.
We wrote to the vendor. From another copy of this conference station, they took the MAC address, which only in a few digits differed from ours - it was profiled correctly. It turned out that we were just unlucky with the address of this particular station, and as a result, Cisco almost released a patch for it, after which the client also began to profile correctly.
SGT
And finally, I want to talk about one of the most interesting projects of recent times. But first you need to recall the technology called SGT (Security Group Tag).
Security Group Tag Technology
The classic network shielding method is based on the source and target IP addresses of the nodes and their ports. But this information is too small, and at the same time it is rigidly tied to the VLAN. Cisco came up with a very simple good idea: let's assign SGT tags to all senders and receivers on our equipment, and apply a policy on filtering devices according to which protocols A, B and C can exchange data between labels 11 and 10 and between 11 and 20, and between 10 and 20 is impossible. That is, a matrix of allowed and prohibited data exchange paths is obtained. And in this matrix, we can use simple access lists. We will not have any IP addresses, there will be only ports. This allows for more atomic, granular policies.
The SGT architecture consists of four components.
The SGT architecture consists of four components.
- Tags First of all we need to assign SGT tags. This can be done in four ways.
- Based on IP addresses . We say that such a network is internal, and then, based on specific IP addresses, we can specify: for example, the 10.31.10.0/24 network is a server segment, and we can apply some rules to it. Inside this server segment, we have a server that is responsible for PCI DSS — we apply stricter rules to it. You do not need to remove the server from the segment.
Why is this useful? When we want to implement a firewall somewhere, to make stricter rules, we need to place the server in the customer's infrastructure, which often develops not completely controlled. No one thought about the fact that the server should not communicate with the neighboring server, that it is better to separate it into a separate segment. And when we introduce a firewall, the most time is spent on transferring servers according to our recommendations from one segment to another. In the case of SGT, this is not required. - Based on VLAN . You can specify that VLAN1 is label 1, VLAN10 is label 10, and so on.
- Based on switch ports . The same can be done in relation to the ports: for example, all data coming from port 24 of the switch can be marked with a 10.
- And the last, most interesting way is to dynamically assign tags using ISE . That is, Cisco ISE can not only assign ACLs, send to redirects, etc., but also assign an SGT tag. As a result, we can dynamically determine: this user came from this segment, at such a time, he has such a domain account, such an IP address. And already on the basis of this data we assign a label.
- Based on IP addresses . We say that such a network is internal, and then, based on specific IP addresses, we can specify: for example, the 10.31.10.0/24 network is a server segment, and we can apply some rules to it. Inside this server segment, we have a server that is responsible for PCI DSS — we apply stricter rules to it. You do not need to remove the server from the segment.
- Exchange of tags . We need to transfer the assigned tags to where they will be applied. SXP protocol is used for this.
- SGT policy . This is the matrix about which we spoke above, it is written in it, which interactions can be used and which cannot.
- Forced SGT application . Switches do this.
An interesting project based on SGT
Now, at one of the customers, we have configured IP and SGT mapping, which allowed us to select 13 segments. They intersect in many ways, but thanks to the granularity, at which the lowest occurrence is always selected, down to a specific host, we were able to segment all this. ISE is used as a single repository for labels, policies, and IP and SGT compliance data. First, we identified the tags: 12 - development, 13 - this is production, 11 - testing. Further, it was determined that between 12 and 13 it is possible to interact only via the HTTPS protocol, between 12 and 11 there should be no interaction, and so on. The result is a list of networks and hosts with corresponding labels. And the entire system is implemented on four Nexus 7000 in the customer data center.
What benefits did the customer get?
Now atomic politicians are available to him. It happens that in one of the networks administrators mistakenly deploy a server from another network. For example, a production from host has been lost in the development network. As a result, then you have to transfer the server, change the IP, check whether communication with neighboring servers is broken. But now you can simply microsegment the “alien” server: declare it part of production and apply different rules to it, unlike members of the rest of the network. And at the same time the host will be protected.
In addition, the customer can now store and manage policies centrally and fault tolerantly.
But it would be really cool to use ISE to dynamically label users. We will be able to do this not only on the basis of the IP address, but also depending on the time, on the user's location, on his domain and account. We can register that if this user sits in the head office, he has some privileges and rights, and if he came to the branch, he is already seconded and has limited rights.
I would also like to watch the logs on ISE itself. Now, when using four Nexus and ISE as a centralized repository, you have to go to the switch itself to view the logs, injecting requests into the console and filtering responses. If we take advantage of Dynamic Mapping, then ISE will start collecting logs, and we will be able to centrally see why some user did not fall into a certain structure.
But so far these features have not been implemented, because the customer decided to protect only the data center. Accordingly, users come outside, and they are not connected to ISE.
Cisco ISE Development History
Verification Center
This important innovation appeared in version 1.3 in October 2013. For example, one of our clients had printers that worked only with certificates, that is, were able to authenticate not with a password, but only with a certificate on the network. The client was upset that he could not connect the devices due to the lack of a TC, and for the sake of five printers did not want to deploy it. Then, using the integrated API, we were able to issue certificates and connect printers in a regular way.
Cisco ASA Change of Authorization (CoA) Support
Since the advent of CoA support on the Cisco ASA, we can control not only users who come to the office and connect to the network, but also remote users. Of course, we could have done this before, but for this we needed a separate IPN node device to apply authorization policies that proxied the traffic. That is, besides the fact that we have a firewall that terminates the VPN, we had to use another device only to apply the rules in Cisco ISE. It was expensive and uncomfortable.
In version 9.2.1 in December 2014, the vendor finally added support for change of authorization to Cisco ASA, as a result, all the functionality of Cisco ISE was supported. Several of our customers happily sighed and were able to use the released IPN node with more benefit than simply terminating VPN traffic.
TACACS +
All of us have been waiting for the implementation of this protocol for a long time. TACACS + allows you to authenticate administrators and log their actions. These features are very often used in PCI DSS projects for admin control. Previously, there was a separate Cisco ACS product for this, which was slowly dying until the Cisco ISE finally took over its functionality.
AnyConnect Posture
The emergence of this functionality in AnyConnect has become one of the breakthrough features of Cisco ISE. What feature is seen in the following picture. How does the posturing process look like: the user is authenticated (by login, password, certificate or MAC), and the policy with access rules arrives in response to it from Cisco ISE.
If it is necessary to check the user for compliance, redirect is sent to it - a special link that redirects all or part of the user's traffic to a specific address. The client at this moment has a special agent installed for posturing, who occasionally goes online and waits. If he is redirected to the ISE server, he will take the policy out of there, check the workstation for compliance with it and draw some conclusions.
Previously, the agent went and checked the URL every five minutes. It was long, inconvenient and at the same time littered with empty traffic network. Finally, this mechanism is included in AnyConnect. At the network level, he understands that something happened to her. Let's say we connected or reconnected to the network, or connected to Wi-Fi, or built a VPN — AnyConnect will know and work as a trigger for the agent about all these events. Due to this, the waiting time for the start of posturing has changed from 4-5 minutes to 15 seconds.
Disappearance of features
There was an interesting case with functionality, which first disappeared in one of the versions, and after a while it was returned.
Cisco ISE has accounts for guest access: a network in which even secretaries can issue passwords. And there is a very convenient feature when the system administrator can make a pack of guest accounts, seal them in envelopes and give them to the person in charge. These accounts will be valid for a specific time. For example, in our company it is a week from the moment of the first entry. The user is given an envelope, he prints it out, enters, the counter starts ticking. Convenient and practical.
Initially, this functionality has been since the advent of Cisco ISE, but in version 1.4 it disappeared. And after a few years, in version 2.1 it was returned. Due to the lack of guest access, we did not even update the Cisco ISE version for more than two years because we were not ready to restructure our business processes for the sake of it.
* * *
Funny bug
At parting, I remembered a funny story. Remember, we talked about a client with a very strict security policy? It is located in the Far East, and once the time zone changed there - instead of GMT + 10 it became GMT + 11. And since the customer was set up simply “Asia / Sakhalin”, he turned to us so that we could realize an accurate time display.
We wrote to Cisco, they answered that in the near future time zones would not be updated, because it took too long. They offered to use the standard zone GMT + 11. We set it up, and it turned out that Cisco had not tested its product enough: the belt became GMT-11. That is, the client time left for 12 hours. What is the most funny, in GMT + 11 is Kamchatka and Sakhalin, and in GMT-11 there are two American islands. That is, Cisco simply did not assume that someone would buy a product from these time zones from them, and did not conduct tests. They fixed this bug for quite some time, apologized.
Stanislav Kalabin, expert of the department of engineering support and information security services, Jet Infosystems
Source: https://habr.com/ru/post/354888/
All Articles