Payment system architecture. Experience proven banality
The main thing in the payment system is to take money, transfer records from one tablet to the same tablet with a minus sign. It doesn't sound very difficult until the lawyers arrived . Payment systems around the world are subject to a huge number of all kinds of burdens and instructions . Therefore, as part of the development of the payment system, it is necessary to balance all the time on the verge between a heavy enterprise and a completely normal scalable web application .
Under the cut, Philippe Delgyado’s ( dph ) story on Highload ++ is about experience that has accumulated over several years of work on the payment system for the Russian legal bookmaker business, about mistakes, but also about some achievements, and how to correctly mix, but not shake, the web with enterprise.

About the speaker : Philippe Delgyado didn’t do anything for his career - from dvuzvenok to
Visual Basic to Hardcore SQL. In recent years, he has been mainly engaged in Java-loaded projects and regularly shares his experience at various conferences.
')
For three years we have been making our payment system, of which we have been in production for two years. Two years ago I told you how to make a payment system in one year, but since then, of course, a lot has changed in our decision.
We are a rather small team: 10 programmers, mostly backend developers and only two people on the front-end, four QA and I, plus some kind of management. Since the team is small, there is not much money, especially at the beginning.
In general, the payment system is very simple: take money, transfer records from one tablet to the same sign with a minus sign - that's all!
In reality, the way it is, the payment system is a very simple thing. Until the lawyers arrived . Payment systems all over the world are subject to a huge amount of various burdens and instructions on how to transfer money from one tablet to another, how to interact with users, what they can promise, what cannot be promised, what we are responsible for, what we are not responsible for. Therefore, as part of the development of the payment system, it is necessary to balance all the time on the verge between a heavy enterprise and a completely normal scalable web application.
From the enterprise we have the following.
We work with money.
Therefore, we have complicated accounting, we need a high level of reliability, a high SLA (because neither we nor users like a simple system), and a high responsibility - we need to know exactly where the user’s money went and what happened to them moment at all happens.
We are a non-profit organization (non-bank credit organization).
This is practically a bank, but we cannot issue loans.
We have lawyers. Here are some laws that regulate the behavior of payment systems currently in the Russian Federation:

Each of these laws is quite difficult to implement, because there are still a bunch of by-laws, real use stories, and you have to work with all of this.
At the same time, besides the fact that we are such a pure enterprise, almost a bank, we are still quite a web-company.

We use Java , because it is somewhat easier to find developers on the market who at least roughly understand the reliability of working with databases in the Java world than in other languages.
I know only three databases with which you can make a payment system, but one of them is very expensive, for the second it is difficult to find support and it is also not free. As a result, PostgreSQL is the best option for us: it is easy to find sane support, and in general, for little money, you can not even think about what is happening with the databases: you have everything clean, pretty and guaranteed.
The project uses a little Kotlin - more for fun and to look to the future. So far, Kotlin is mainly used as some scripting language, plus some small services.
Of course, service architecture. Microservices can not be called categorically. Microservice in my understanding is that it is easier to rewrite than to understand and refactor. Therefore, we, of course, do not have microservice, but normal full-fledged large components.
In addition, Redis for caching, Angular for internal kitchen. The main site visible to the user is made in pure HTML + CSS with a minimum of JS.
And of course, Kafka .
Of course, I would prefer to live without services. There would be one big monolith, no problems with connectivity, no problems with versioning: picked up, wrote, laid out. It's simple.
But security requirements are coming. We have personal data in the system, personal data must be stored and processed separately, with special restrictions. We have information on bank cards, it also has to live in a separate part of the system with the relevant requirements for auditing each code change and data access requirements. Therefore it is necessary to cut everything into components.
There are requirements for reliability . I don’t want it because some gateway with one of the counterparty banks broke for some reason, take all the payment logic and put it all out: God forbid, there will be a wrong calculation, the human factor will collapse. Therefore, you still have to divide everything into relatively small services.
But since we are starting to divide the system into components according to the requirements of safety and reliability , it makes sense to separate into separate services everything that requires its own storage . Those. for the part of the database, which does not depend on the whole other system at all, it is easier to make a separate service.
“Processing” or “Reports” is a more or less normal name, “Garbage that works with a database replica” is already a bad name. Obviously, this is not one service - either several, or part of one big one.
Four of these requirements are enough for us to single out individual
services.

Of course, we still have micromonoliths, which we continue to cut, because they accumulate too many words and too many names for one service. This is an ongoing process of redistributing responsibility.
Services themselves interact via JSON RPC over http (s), as in any web-world. In addition, for each service, a separate logic is written for repeating queries and caching the results. As a result, even when a service crashes, the entire system continues to operate normally, and the user does not notice anything.
This is not a message queue, Kafka with us is only a transport layer between services, with guaranteed delivery and clear reliability / clustering . Those. if you need to send something from service A to service B, it is easier to put a message in Kafku, from Kafki and the service will take away what is necessary. And then you can not think about all this logic for repetition and caching, Kafka greatly simplifies this interaction. Now we are trying to transfer as much as possible to Kafka, this is also such an ongoing process.

Well, among other things, it is a backup source of data on all our operations . I, of course, paranoid, because the specifics of the work contributes. I saw (quite a while ago and not in this project) as a commercial database for a heap of a lot of money at some point began to write nonsense not only in its own database files, but also in all replicas and backups. And the data had to be recovered from the logs, because it was data on the payments made, and without them the company could safely close the next day.
I don’t like to pull important data out of the logs, so I’ll rather add all the necessary information to the same Kafku. If suddenly I have some kind of impossible situation, I, at least, know where to get the backup data that is not related to the main storage.
In general, it is standard practice for payment systems to have two independent data sources; it’s just scary to live without it - for me, for example.
Of course, we have a lot of logs and different. We now keep the development logs in Kafku and continue to upload to Clickhouse, because, as it turned out, it is easier and cheaper. Moreover, at the same time we study Clickhouse, which is useful for the future. However, you can make a separate report about working with logs.

Monitoring with us on Prometheus + Grafana. To be honest, I'm not happy with Prometheu.

What is the problem?
Therefore, I seriously think somewhere to go.
Then I will tell a few individual cases about what architectural challenges we had, how we solved them, what was good and what was bad.
In general, payment is quite difficult. Below is a rough description of the payment context: a set of tuples (associative arrays), lists of tuples, tuples of lists, some parameters. And all this is constantly changing due to changes in business logic.

If you do this honestly, there will be many tables, many links between them. As a result, ORM is needed, complex migration logic is needed when adding a column. Let me remind you that in PostgreSQL, even the simple addition of a new nullable column to a table can lead (in some specific situations) to the fact that for a long time this table will be completely unavailable. Those. in fact, adding a nullable column is not an atomic free operation, as many think. We even stumbled upon it just once.
All this is rather unpleasant and sad, I want to avoid all this, especially when using ORM. Therefore, we remove all these large and complex entities in JSON, simply because it is real, except on the application server, nowhere all this data and structures are completely unnecessary. I have been using this approach for 10 years already and, finally, I notice that it is becoming, if not the mainstream, then at least a generally accepted practice.
As a rule, storing complex business data in a database in the form of JSON, you won’t lose anything in performance, and maybe even win some time. Then I will tell you how to do this, so as not to accidentally shoot yourself in the foot.

First, we must immediately think about possible conflicts.
Once you had a version of an object with one set of data fields, you released another version, which already has a different set of data fields, you need to somehow read the old JSON and convert it to an object convenient for you.
To solve this problem, it is usually enough to find a good serializer / deserializer, to which you can explicitly say that this field from JSON needs to be converted into such a set of fields, these things should be serialized, and if there isn’t something, replace with default, etc. In Java, fortunately, there are no problems with such serializers. My favorite is Jackson.
Be sure to store in the database version of the structure that you write.
Those. next to each field where you have JSON stored, there must be another field where the version is stored. First of all, it is necessary not to support the code of understanding of the old version of the new one not infinitely.
When you have released a new version, and you have a new data structure, you simply make a migration script that runs through the entire database, finds all the old versions of the structure, reads them, writes in a new format, and you have a fairly limited time , the database contains a maximum of 2-3 different versions of the data, and you do not suffer with the support of the whole variety of what you have accumulated over many years. This is getting rid of legacy, getting rid of technical duty.
For PostgreSQL, you need to choose between json and jsonb.
Once there was a sense in this choice. We, for example, used JSON, because we started a long time ago. I remind you that the JSON data type is just a text field, and to get somewhere inside it will be parsed by PostgreSQL each time. Therefore, in production it is better not to get into json-objects in the database once again, only in the case of some kind of support or troubleshooting. In an amicable way, there should be no commands for working with json fields in your SQL code.
If you use JSONB, then PostgreSQL carefully parses everything into a binary format, but does not preserve the original look of the JSON object. When we, for example, store the original incoming data to us, we always use only JSON.
We still do not need JSONB, but at the moment, it really makes sense to always use JSONB and not think about it anymore. The difference in performance has become almost zero, even for simple reading and writing.
Even at the development stage, long before the release to production, we had a small simple service with bank card data, including the actual card number, which we, of course, encrypted using PostgreSQL . In this case, theoretically, the head of exploitation could probably find somewhere a key for this encryption and find out something, but we completely trusted him.
The reliability of the service was realized through active-standby - because the service is small, it restarts quickly, the other components just wait for 3-5 seconds, so it makes no sense to pile up some complex cluster system.
Before the launch, we began to undergo an PCI DSS audit, and it turned out that there are quite stringent requirements for controlling access to data, which, in the case of our auditor, boiled down to the fact that:
To begin with, we stop trusting the operations manager and try to come up with a scheme when we don’t have one person who knows the keys.

Logically, we arrive at the Shamir scheme. This is the key generation method, when several keys are generated based on the finished key, any subset of which can generate the original key.
For example, you form a long key, immediately break it up into 5 pieces so that any three of them can produce the original one. After that, distribute these three exploits, keep two in a safe just in case someone gets sick, gets hit by a bus, etc., and live in peace. The original long key you no longer need, only these pieces.
It is clear that after the transition to the Shamir scheme, the logic of generating and changing keys appears in the service. To generate a key, a separate virtual machine is used, on which:
As a result, no one can find out the original key, because it is created in the presence of the sat-Schnick, on the fast-dying system, and then only the “generated” keys are distributed
When changing keys, it turns out that we can simultaneously have two actual keys in the system: one old, one new, part of the data is encrypted with the old one, and a re-encryption procedure is needed for the new key.
Since in order to start a component, it now takes two or three people, it takes no more than 30 seconds, but several minutes. Therefore, a simple component when restarting will take several minutes, and you have to switch to the Active-Active scheme, with several instances running simultaneously.
Thus, a simple obvious service of a few dozen lines becomes a rather complex structure: with a complex start logic, with clustering, with rather complicated maintenance instructions. From a normal simple web, we happily switched to entreprise. And, unfortunately, this happens quite often - much more often than we would like. Moreover, having looked at the whole business, the top management and business said that now they need to encrypt all the data just in case in about the same way, and Active-Active also likes it everywhere. And frankly, these desires of business are not always easy to implement.
As I said, payment is quite difficult. Below is a rough diagram of the process of transferring money from the user to the final counterparty, but not everything in the diagram. In the process of paying a lot of dependencies on some external entities: there are banks, there are contractors, there is a banking information system, there are transactions, transactions, and all this should work reliably.
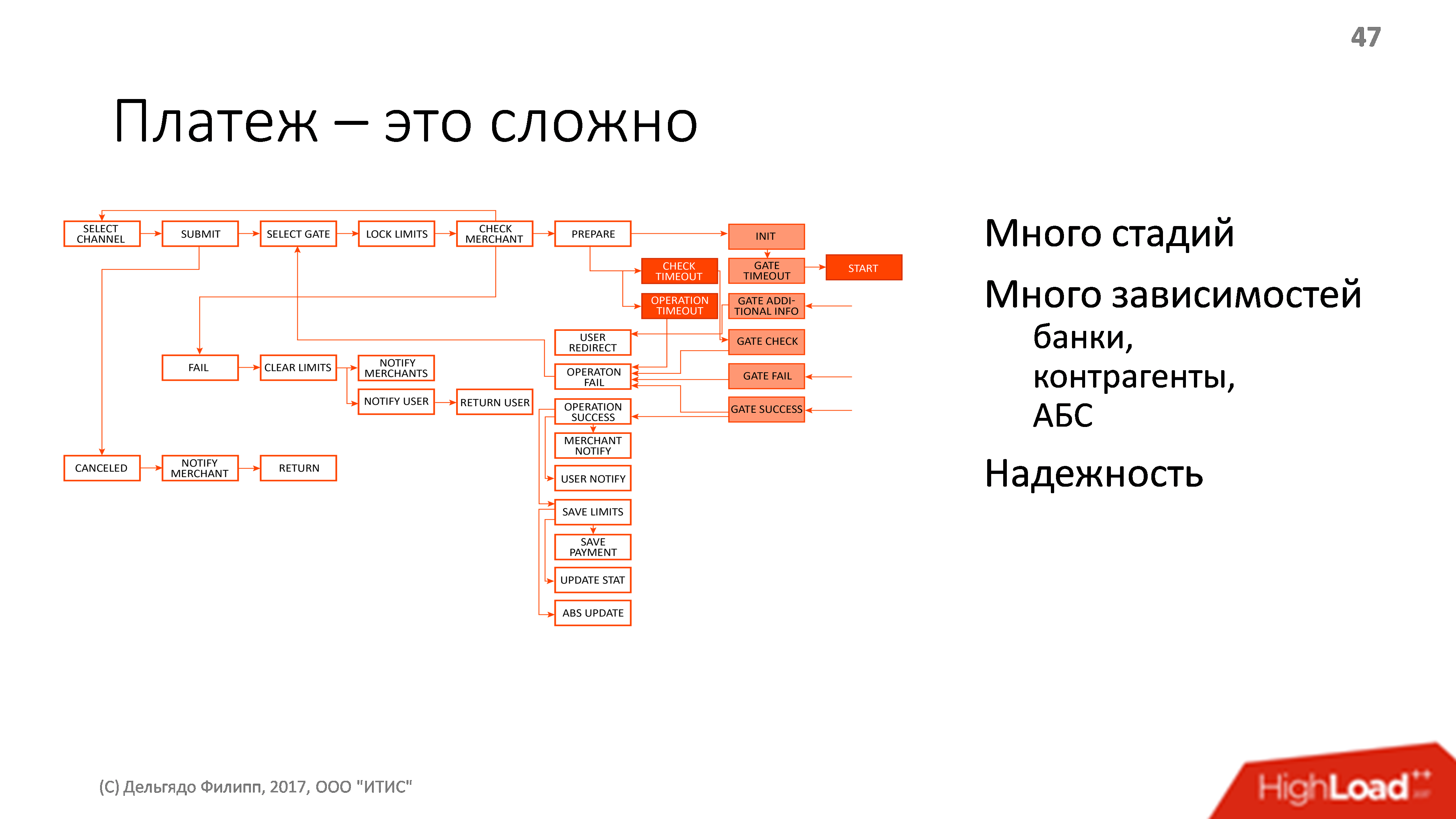
Reliably - this means that we always know on whose side the money is, and if everything has now fallen with us, from whom this money must be demanded. They can hang at any of the counterparties, as long as not from us. And we must know for sure who they are hanging on so that all this can be confirmed and communicated to the user. And, of course, it is desirable that there should be as few possible problems as possible.

Of course, at the beginning we had FSM , a normal state machine, each event is processed in a transaction. The current state is also saved in the DBMS. Implemented everything yourself.
The first problem is that we have simultaneous events.
We process the event associated, for example, with the user confirming the start of payment. At this time, an event comes from the counterparty, canceling the possibility of the operation and this event also needs to be processed. Therefore, in the logic of work, we have some locks on resources, waiting for locks to be released, etc. Fortunately, at first, all payment processing took place on the same machine, and locks could be implemented at the JVM level.
In addition, many steps have a clear maximum execution time (time-out), and these times also need to be stored, processed, watched somewhere when timeout events occur (and they also sometimes are simultaneous).
All this was implemented through the lock logic inside the Java machine, because it was not very easy to do this in the database. As a result, the system turned out with the organization of high availability only through Active-Standby and with a bunch of special logic for restoring contexts and timeouts.
We have a fairly small load, only dozens of payments per second, even less than a hundred in the case of the maximum potential peak. In this case, however, even ten payments per second leads to hundreds of requests (individual steps) per second. These are small loads, so we almost always have one car.
Everything was great, but it took Active-Active.
First, we wanted to use the Shamir scheme, well, and also there were other Wishlist: let us upload the new version to only 3% of users; let's change the payment logic often; I want to lay it out with zero downtime, etc.
It is sad to make distributed locks; it is also sad to make timeouts distributed. And we began once again to understand - what is a payment? A payment is a set of events that must be strictly sequentially processed, this is a complex changeable state, and payment processing must go in parallel.
Who learned the definition? That's right, payment is an actor .
There are many different actor models in Java. There is a beautiful Akka , there are at times strange, but funny Vert.x , there is a much less used Quasar . They are all wonderful, but they have one fundamental flaw (and not the one you thought about) - they have insufficient guarantees .
None of them guarantees the delivery of messages between actors, all of them have a problem with the work within the transaction in the database.
We looked at it for a long time, thought whether we could finish something up to a sane state, but then we made our bike: a line in PostgreSQL via select for update skip locked.

The entire solution got into a thousand lines of code and took about two man-weeks to develop and two man-weeks to test-refine. However, many of our internal needs, which in the same Akka are not normally done, have been met.
This is such a great thing to implement queues in PostgreSQL. In fact, this mechanism is in all databases, except, in my opinion, MySQL.
Suppose we have two tablets: the plate with our actors is a flow, and the table of events for these actors, it is connected in the flow column. Events are sorted by auto-increment key ID, everything is normal. We write a SQL query.

Select the very first event in the very first of the flow, indicating the magic for update skip locked. If there are no locks in the tablet, the query works exactly as normal for update - it takes and puts the lock on the first line we have chosen, i.e. on the line with the first actor and on the line with the first event for this actor.
We launch the same query a second time and it does exactly the same thing, but skipping the already blocked lines. Therefore, he will select the first event in the second actor (the third row in the table) and hang a lock on it.
Suppose, during this time, we finished processing the first of the events, deleted it and closed the transaction. The blocking was removed, so the next time we execute the request, we will receive the first, at the moment, event, in the first actor.

It all works quickly and reliably. On cheap hardware, we received about 1000 such operations per second, provided that each of them slows down for about 10 milliseconds. I used this approach several times, all the code is written in three lines and it is very easy to attach all sorts of convenient things to such a queue.

All messages are transactional : we have started a transaction, we are doing something with the database, we are sending messages to other actors somewhere, if the transaction is rolled back, messages will not be sent either, which is insanely convenient.
You can not think about sending messages that cancel previous ones, do not think that all messages should be sent in a pack only at the end of processing and after the commit. In general, you stop thinking about many things. For example, you do not need to think about locks , because you have all the events processed sequentially, for which, in fact, the actors are invented.
In our implementation, we also added a complex error handling policy , because 80% of the payment logic- this is in fact the processing of possible errors: the user has gone somewhere, the counterparty responded with some nonsense, the user has no money at all or the counterparty does not work and you need to select another counterparty, another gateway, and so on. There is an insane amount of different complex logic for handling all sorts of errors.
For us, this solution is effective - 100 payments per second suits us.
But this solution of very limited applicability is its own bike, which can be used in quite a few places. And it has very tight performance limits. That is, I would not recommend this to colleagues from Yandex.Money, because they have black Fridays, and 100 payments per second are clearly not enough for them. We, fortunately, do not have a black Friday, we have a very specific market, and therefore we can calmly manage with such a decision. At the same time, this is an honest bike, an honest enterprise approach - the OpenSource library in this case is not very suitable for us.
On paper everything was smooth. We implemented it, launched it - it works. And suddenly a problem comes - one of the locks fell .
A gateway is an implementation of a protocol for interacting with someone from a money provider. Well, fell and fell, users did not notice anything, we switched to the backup with another counterparty and began to figure out why. It turned out that the connections in the pool had run out . The reason is not clear, it seems that there was not such a big load on the gateway to exhaust all connections.
We begin to understand and find out: our counterparty began to respond to network requests not in half a second, as it was before, but in one minute. Since we have a processing of the request to the counterparty is a payment step, it is executed in a transaction. When many transactions start to run for a long time, then the connections from the database for all incoming requests are no longer enough. Such a normal behavior: when you have a lot of long transactions , for some reason your connections start to end.
We began to think that I do this. The first is that you can increase the number of connections . Unfortunately, PostgreSQL has quite understandable limits on the maximum number of connections per core.and it is not very big - about a hundred. Because in PostgreSQL, I remind you, each connection is one process. But there are still a lot of processes, tens of thousands or hundreds of thousands of cheap ones will not work. And if our counterparties start responding once a minute, simultaneous transactions may take more.
You can try to make a network call asynchronous , that is, each step is divided into two. Every time we need to pull someone out of counterparties, we need to make a call, save the state to the context database, get an answer from him. Processing the response will fall on the same actor, we will raise the status from the database, do something else that is necessary. But at the same time, the number of steps in the payment increases many times over.and in our requirement - 100 payments per second - we no longer fit. And the logic of work becomes complicated.
It remains only to manage the guarantees of conservation . We do not always need hard transaction, we do not always need hard recovery in a network call, we can almost always repeat it. Therefore, we do not need to be able to do everything through the database, we must be able to do some things around the database , bypassing transactions.
Unfortunately, there is no standard solution that would finely manage retention guarantees for a specific event. Now I try to write it, but, honestly, it turns out to be quite a trivial task to implement skip locked on some Redis on Lua. If I do all this, I will tell you about it.
As a temporary solution, we divided the payment process into several separate actors, executed on different DBMS (and on different servers). This allowed us to make asynchronous requests where it was needed and solve current problems.
We have a payment system, that is, money, and money loves when they are considered. Therefore, a business came to us very quickly with a request to make a Business Intelligence system. We do n’t have a lot of data , some hundreds of gigabytes, only top management needs it , we don’t have hundreds of analysts. And the main thing - it is necessary to do " quickly and cheaply ."

We take PowerBI - this is a solution from Microsoft: the system generates the necessary data in the form of csv, csv are loaded into the cloud, from the cloud they are loaded into PowerBI. Cheap, fast, simple, done literally on the knee, almost completely without the involvement of programmers. Reports to write in csv - it's easy.
But it turned out that cheap is if you have little data, and quickly - if there is little data . As soon as our data volume exceeded 1 GB, it turned out that it took a long time to process, and most importantly, at some point, Microsoft changed the conditions for using the service and it became very payable approximately from the size of 1 GB. And it turned out that this is already somewhat beyond our means.
Come see what you can do.
First thought - hurray, there is ClickHouse! We throw all our events in Kafku, from there we unload in batches into ClickHouse, it turns out cool, fashionable, hyipovo, analytics should work fast, everything should be free, in general, beautiful and wonderful. But the result from ClickHouse should be shown somewhere. Redash works best with Clickhouse right now. They made a test version of Redash, showed it to the business - they said that they would not work with it, because it looks, to put it mildly, ugly and there are simply no some kind of drill-down business-like things.
We started to find out what the business is dreaming about. Business dreams of something like Tableau, where everything is beautiful. Tableau integrates best with Vertica, and it turns out to be a beautiful, in theory, system: we throw all events at Kafka, with Kafka we throw at Vertica.
Vertica works quickly, efficiently, reliably, easily , and Tableau Server shows all this. But one thing - the cost of the license Vertica is not officially reported, but, to put it mildly, considerable ,. Tableau is also not very cheap. Fortunately, it turned out that, in our volumes, all this is actually not so expensive, because Vertica is free to one terabyte of data, Community Edition absolutely suits us, we are still far from terabyte. And since we only need a license for Tableau for a small number of developers and top managers, this costs some good money. Up to the point that we needed fewer licenses than the minimum package that Tableau sells.
It turned out that such a normal, completely classic heavy enterprise-solution is also normal.web-solutions . It is inexpensive and set from scratch without hesitation. Vertica pleases me so far: in her many analytical things are solved very beautifully. While you do not have a lot of data - I advise. However, in operation it is demanding to understand the principles of its work, you need to understand them before use.

At the same time, I think that if we grow beyond a terabyte in a few years, then by that time we will already have a good examination on ClickHouse, Tableau will obviously make an adapter to it, and we will carefully crawl to a free ClickHouse for what quite reasonable time.
We have quite a lot of texts:
The error in this information is quite painful. For example, if we don’t upload the commissions that we actually charge, then users may be very offended at us, and, most importantly, the regulatory authorities may be offended by us , which is much worse. Therefore, the texts for us are also code : you need to check it before publication, many people are involved in its preparation, mistakes are expensive.

At the beginning, the text was just part of the front end: all the texts were written by front-end designers, then they went into testing, were read, showed up on a demo stand, then they were already in production. But the text changes too often, and so it was just expensive to do.
And we started thinking how to automate all this .and make a CMS. Simple CMS are not suitable because:
Not simple CMSs are too expensive in every sense, they usually cost a lot of money, and their integration is very obscure, because there are a lot of things invented there.
The ideal solution would be to put a banal Git on everyone who works with texts : let them send all written texts directly to the repository. But the thought of putting Git to top managers and a copywriter and teaching them how to use it, we thought and thought and refused in horror, because git is not for normal people.
The most ideal solution would probably be a text editor , built right into IntelliJ IDEA, where you can neatly hide the complexity of using Git. But, unfortunately, JetBrains has not yet done such an editor, although I have long asked them.
I had to make the bike again:

That is, I had to write, in fact, a micro portal in enterprise style.
Honestly, if I could buy such a solution, I would prefer to buy it. But I simply did not find a single embedded CMS for large systems on the market, and, in my opinion, they are not there yet. I, frankly, once again write it from scratch, and it is very pitiful that so far no one has done it for me.

What of all this can be said? That life on the edge is quite interesting.
When you have tasks at the same time from the web and from the enterprise, you can borrow different ideas from the world of corporations , they have a lot of things thought out. Sometimes you can borrow not only ideas, but also concrete solutions like Vertica, if they are cheap.
Honestly, if I found cheap support for IBM DB2 - I would implement the project on it, I love it very much, it is cheap and very reliable, but it’s difficult to find support for this base for reasonable money in Russia. Of course, you can lure someone from the Post of Russia, but they are accustomed to such large servers that we are obviously too small for them.
Wellbig problems from the enterprise world can be solved in a web-style quite simply, what we are constantly doing.
Architecture is a dynamic concept.

There is no good architecture at all. There is an architecture that more or less satisfies you at a specific point in time . Time is changing - the architecture is changing, and we must constantly be ready for this, and always invest resources in the development of architecture. The project architecture is a process, not a result .
Java and SQL are really cool if you can cook it. We are able, therefore everything is easy, fast, and effortless, and we make quite a very small team rather complicated.
Under the cut, Philippe Delgyado’s ( dph ) story on Highload ++ is about experience that has accumulated over several years of work on the payment system for the Russian legal bookmaker business, about mistakes, but also about some achievements, and how to correctly mix, but not shake, the web with enterprise.
About the speaker : Philippe Delgyado didn’t do anything for his career - from dvuzvenok to
Visual Basic to Hardcore SQL. In recent years, he has been mainly engaged in Java-loaded projects and regularly shares his experience at various conferences.
')
For three years we have been making our payment system, of which we have been in production for two years. Two years ago I told you how to make a payment system in one year, but since then, of course, a lot has changed in our decision.
We are a rather small team: 10 programmers, mostly backend developers and only two people on the front-end, four QA and I, plus some kind of management. Since the team is small, there is not much money, especially at the beginning.
Payment system
In general, the payment system is very simple: take money, transfer records from one tablet to the same sign with a minus sign - that's all!
In reality, the way it is, the payment system is a very simple thing. Until the lawyers arrived . Payment systems all over the world are subject to a huge amount of various burdens and instructions on how to transfer money from one tablet to another, how to interact with users, what they can promise, what cannot be promised, what we are responsible for, what we are not responsible for. Therefore, as part of the development of the payment system, it is necessary to balance all the time on the verge between a heavy enterprise and a completely normal scalable web application.
From the enterprise we have the following.
We work with money.
Therefore, we have complicated accounting, we need a high level of reliability, a high SLA (because neither we nor users like a simple system), and a high responsibility - we need to know exactly where the user’s money went and what happened to them moment at all happens.
We are a non-profit organization (non-bank credit organization).
This is practically a bank, but we cannot issue loans.
- We have reporting to the Central Bank;
- We have accountability before financial monitoring;
- We have many colleagues in the banking part of the company and with banking experience;
- We are forced to interact with the automated banking system.
We have lawyers. Here are some laws that regulate the behavior of payment systems currently in the Russian Federation:
Each of these laws is quite difficult to implement, because there are still a bunch of by-laws, real use stories, and you have to work with all of this.
At the same time, besides the fact that we are such a pure enterprise, almost a bank, we are still quite a web-company.
- User convenience is fundamentally for us, because the market is highly competitive, and if we don’t care about our user, it will leave us and we’ll have no money at all.
- We are forced to do frequent calculations, because the business is actively developing. Now we have releases 23 times a week, which is much more often than at large banks, where, they say, they have recently finally started making releases once every 3 months and are very proud of it.
- Minimal time-to-market: as soon as an idea comes, you need to launch it into real life as quickly as possible - preferably faster than competitors.
- We do not have a lot of money, unlike many large banks. We don’t manage to take everything and fill it up with money, we have to somehow get out and make some decisions.
We use Java , because it is somewhat easier to find developers on the market who at least roughly understand the reliability of working with databases in the Java world than in other languages.
I know only three databases with which you can make a payment system, but one of them is very expensive, for the second it is difficult to find support and it is also not free. As a result, PostgreSQL is the best option for us: it is easy to find sane support, and in general, for little money, you can not even think about what is happening with the databases: you have everything clean, pretty and guaranteed.
The project uses a little Kotlin - more for fun and to look to the future. So far, Kotlin is mainly used as some scripting language, plus some small services.
Of course, service architecture. Microservices can not be called categorically. Microservice in my understanding is that it is easier to rewrite than to understand and refactor. Therefore, we, of course, do not have microservice, but normal full-fledged large components.
In addition, Redis for caching, Angular for internal kitchen. The main site visible to the user is made in pure HTML + CSS with a minimum of JS.
And of course, Kafka .
Services
Of course, I would prefer to live without services. There would be one big monolith, no problems with connectivity, no problems with versioning: picked up, wrote, laid out. It's simple.
But security requirements are coming. We have personal data in the system, personal data must be stored and processed separately, with special restrictions. We have information on bank cards, it also has to live in a separate part of the system with the relevant requirements for auditing each code change and data access requirements. Therefore it is necessary to cut everything into components.
There are requirements for reliability . I don’t want it because some gateway with one of the counterparty banks broke for some reason, take all the payment logic and put it all out: God forbid, there will be a wrong calculation, the human factor will collapse. Therefore, you still have to divide everything into relatively small services.
But since we are starting to divide the system into components according to the requirements of safety and reliability , it makes sense to separate into separate services everything that requires its own storage . Those. for the part of the database, which does not depend on the whole other system at all, it is easier to make a separate service.
And the main principle for us is the allocation of something into a separate service - if you can come up with an obvious name for this service itself.
“Processing” or “Reports” is a more or less normal name, “Garbage that works with a database replica” is already a bad name. Obviously, this is not one service - either several, or part of one big one.
Four of these requirements are enough for us to single out individual
services.
Of course, we still have micromonoliths, which we continue to cut, because they accumulate too many words and too many names for one service. This is an ongoing process of redistributing responsibility.
Services themselves interact via JSON RPC over http (s), as in any web-world. In addition, for each service, a separate logic is written for repeating queries and caching the results. As a result, even when a service crashes, the entire system continues to operate normally, and the user does not notice anything.
Components
Kafka
This is not a message queue, Kafka with us is only a transport layer between services, with guaranteed delivery and clear reliability / clustering . Those. if you need to send something from service A to service B, it is easier to put a message in Kafku, from Kafki and the service will take away what is necessary. And then you can not think about all this logic for repetition and caching, Kafka greatly simplifies this interaction. Now we are trying to transfer as much as possible to Kafka, this is also such an ongoing process.
Well, among other things, it is a backup source of data on all our operations . I, of course, paranoid, because the specifics of the work contributes. I saw (quite a while ago and not in this project) as a commercial database for a heap of a lot of money at some point began to write nonsense not only in its own database files, but also in all replicas and backups. And the data had to be recovered from the logs, because it was data on the payments made, and without them the company could safely close the next day.
I don’t like to pull important data out of the logs, so I’ll rather add all the necessary information to the same Kafku. If suddenly I have some kind of impossible situation, I, at least, know where to get the backup data that is not related to the main storage.
In general, it is standard practice for payment systems to have two independent data sources; it’s just scary to live without it - for me, for example.
Development logs
Of course, we have a lot of logs and different. We now keep the development logs in Kafku and continue to upload to Clickhouse, because, as it turned out, it is easier and cheaper. Moreover, at the same time we study Clickhouse, which is useful for the future. However, you can make a separate report about working with logs.
Monitoring
Monitoring with us on Prometheus + Grafana. To be honest, I'm not happy with Prometheu.
What is the problem?
- Prometheus is beautiful when you need to collect some data from ready-made standard components, and you have a lot of these components. We have quite a few cars. We have 40 different services and this is about 150 virtual locks, it is not very much. If we want to collect some business monitoring information through Prometheus, such as the number of payments going through a specific gateway, or the number of events in our internal queue, then we have to write quite a lot of code on the client side. Moreover, the code, unfortunately, is not very simple, developers have to actively understand the internal logic and how Prometheus considers something.
- Prometheus cannot be used as an honest event-oriented time-series db. I can’t even say that there is a payment start event, a payment end event, and let him calculate all other metrics himself. I have to calculate all the metrics I need in advance on the client, and if I suddenly need to change one of them, this is another layout of the production component, which is very inconvenient.
- It is very difficult to make integrated metrics. If I need to collect a common metric for a number of services (for example, percentile response time for clients across all frontend servers), then through Prometheus it is impossible to make it even theoretically. I can only do some strange average summation already at the Grafana level. Prometheus itself cannot do this.
Therefore, I seriously think somewhere to go.
Then I will tell a few individual cases about what architectural challenges we had, how we solved them, what was good and what was bad.
Database usage
In general, payment is quite difficult. Below is a rough description of the payment context: a set of tuples (associative arrays), lists of tuples, tuples of lists, some parameters. And all this is constantly changing due to changes in business logic.
If you do this honestly, there will be many tables, many links between them. As a result, ORM is needed, complex migration logic is needed when adding a column. Let me remind you that in PostgreSQL, even the simple addition of a new nullable column to a table can lead (in some specific situations) to the fact that for a long time this table will be completely unavailable. Those. in fact, adding a nullable column is not an atomic free operation, as many think. We even stumbled upon it just once.
All this is rather unpleasant and sad, I want to avoid all this, especially when using ORM. Therefore, we remove all these large and complex entities in JSON, simply because it is real, except on the application server, nowhere all this data and structures are completely unnecessary. I have been using this approach for 10 years already and, finally, I notice that it is becoming, if not the mainstream, then at least a generally accepted practice.
JSON Practices
As a rule, storing complex business data in a database in the form of JSON, you won’t lose anything in performance, and maybe even win some time. Then I will tell you how to do this, so as not to accidentally shoot yourself in the foot.
First, we must immediately think about possible conflicts.
Once you had a version of an object with one set of data fields, you released another version, which already has a different set of data fields, you need to somehow read the old JSON and convert it to an object convenient for you.
To solve this problem, it is usually enough to find a good serializer / deserializer, to which you can explicitly say that this field from JSON needs to be converted into such a set of fields, these things should be serialized, and if there isn’t something, replace with default, etc. In Java, fortunately, there are no problems with such serializers. My favorite is Jackson.
Be sure to store in the database version of the structure that you write.
Those. next to each field where you have JSON stored, there must be another field where the version is stored. First of all, it is necessary not to support the code of understanding of the old version of the new one not infinitely.
When you have released a new version, and you have a new data structure, you simply make a migration script that runs through the entire database, finds all the old versions of the structure, reads them, writes in a new format, and you have a fairly limited time , the database contains a maximum of 2-3 different versions of the data, and you do not suffer with the support of the whole variety of what you have accumulated over many years. This is getting rid of legacy, getting rid of technical duty.
For PostgreSQL, you need to choose between json and jsonb.
Once there was a sense in this choice. We, for example, used JSON, because we started a long time ago. I remind you that the JSON data type is just a text field, and to get somewhere inside it will be parsed by PostgreSQL each time. Therefore, in production it is better not to get into json-objects in the database once again, only in the case of some kind of support or troubleshooting. In an amicable way, there should be no commands for working with json fields in your SQL code.
If you use JSONB, then PostgreSQL carefully parses everything into a binary format, but does not preserve the original look of the JSON object. When we, for example, store the original incoming data to us, we always use only JSON.
We still do not need JSONB, but at the moment, it really makes sense to always use JSONB and not think about it anymore. The difference in performance has become almost zero, even for simple reading and writing.
PCI DSS. From simple to do complicated, and how the web becomes enterpris
Even at the development stage, long before the release to production, we had a small simple service with bank card data, including the actual card number, which we, of course, encrypted using PostgreSQL . In this case, theoretically, the head of exploitation could probably find somewhere a key for this encryption and find out something, but we completely trusted him.
The reliability of the service was realized through active-standby - because the service is small, it restarts quickly, the other components just wait for 3-5 seconds, so it makes no sense to pile up some complex cluster system.
Before the launch, we began to undergo an PCI DSS audit, and it turned out that there are quite stringent requirements for controlling access to data, which, in the case of our auditor, boiled down to the fact that:
- There should not be one person who can read all the information from the database. It must be at least a few people who must jointly access.
- Requires regular change of access keys.
- PCI DSS requires an infrastructure update for any discovered vulnerability, and since vulnerabilities in the operating system and infrastructure software are found quite often, it means that the system must also be updated quite often.
To begin with, we stop trusting the operations manager and try to come up with a scheme when we don’t have one person who knows the keys.
Logically, we arrive at the Shamir scheme. This is the key generation method, when several keys are generated based on the finished key, any subset of which can generate the original key.
For example, you form a long key, immediately break it up into 5 pieces so that any three of them can produce the original one. After that, distribute these three exploits, keep two in a safe just in case someone gets sick, gets hit by a bus, etc., and live in peace. The original long key you no longer need, only these pieces.
It is clear that after the transition to the Shamir scheme, the logic of generating and changing keys appears in the service. To generate a key, a separate virtual machine is used, on which:
- key is generated,
- distributed to admins
- virtual girl is killed.
As a result, no one can find out the original key, because it is created in the presence of the sat-Schnick, on the fast-dying system, and then only the “generated” keys are distributed
When changing keys, it turns out that we can simultaneously have two actual keys in the system: one old, one new, part of the data is encrypted with the old one, and a re-encryption procedure is needed for the new key.
Since in order to start a component, it now takes two or three people, it takes no more than 30 seconds, but several minutes. Therefore, a simple component when restarting will take several minutes, and you have to switch to the Active-Active scheme, with several instances running simultaneously.
Thus, a simple obvious service of a few dozen lines becomes a rather complex structure: with a complex start logic, with clustering, with rather complicated maintenance instructions. From a normal simple web, we happily switched to entreprise. And, unfortunately, this happens quite often - much more often than we would like. Moreover, having looked at the whole business, the top management and business said that now they need to encrypt all the data just in case in about the same way, and Active-Active also likes it everywhere. And frankly, these desires of business are not always easy to implement.
Payment logic. From complicated to do simple
As I said, payment is quite difficult. Below is a rough diagram of the process of transferring money from the user to the final counterparty, but not everything in the diagram. In the process of paying a lot of dependencies on some external entities: there are banks, there are contractors, there is a banking information system, there are transactions, transactions, and all this should work reliably.
Reliably - this means that we always know on whose side the money is, and if everything has now fallen with us, from whom this money must be demanded. They can hang at any of the counterparties, as long as not from us. And we must know for sure who they are hanging on so that all this can be confirmed and communicated to the user. And, of course, it is desirable that there should be as few possible problems as possible.
Finite state machine
Of course, at the beginning we had FSM , a normal state machine, each event is processed in a transaction. The current state is also saved in the DBMS. Implemented everything yourself.
The first problem is that we have simultaneous events.
We process the event associated, for example, with the user confirming the start of payment. At this time, an event comes from the counterparty, canceling the possibility of the operation and this event also needs to be processed. Therefore, in the logic of work, we have some locks on resources, waiting for locks to be released, etc. Fortunately, at first, all payment processing took place on the same machine, and locks could be implemented at the JVM level.
In addition, many steps have a clear maximum execution time (time-out), and these times also need to be stored, processed, watched somewhere when timeout events occur (and they also sometimes are simultaneous).
All this was implemented through the lock logic inside the Java machine, because it was not very easy to do this in the database. As a result, the system turned out with the organization of high availability only through Active-Standby and with a bunch of special logic for restoring contexts and timeouts.
We have a fairly small load, only dozens of payments per second, even less than a hundred in the case of the maximum potential peak. In this case, however, even ten payments per second leads to hundreds of requests (individual steps) per second. These are small loads, so we almost always have one car.
Everything was great, but it took Active-Active.
Active-Active
First, we wanted to use the Shamir scheme, well, and also there were other Wishlist: let us upload the new version to only 3% of users; let's change the payment logic often; I want to lay it out with zero downtime, etc.
It is sad to make distributed locks; it is also sad to make timeouts distributed. And we began once again to understand - what is a payment? A payment is a set of events that must be strictly sequentially processed, this is a complex changeable state, and payment processing must go in parallel.
Who learned the definition? That's right, payment is an actor .
There are many different actor models in Java. There is a beautiful Akka , there are at times strange, but funny Vert.x , there is a much less used Quasar . They are all wonderful, but they have one fundamental flaw (and not the one you thought about) - they have insufficient guarantees .
None of them guarantees the delivery of messages between actors, all of them have a problem with the work within the transaction in the database.
We looked at it for a long time, thought whether we could finish something up to a sane state, but then we made our bike: a line in PostgreSQL via select for update skip locked.
The entire solution got into a thousand lines of code and took about two man-weeks to develop and two man-weeks to test-refine. However, many of our internal needs, which in the same Akka are not normally done, have been met.
Skip locked
This is such a great thing to implement queues in PostgreSQL. In fact, this mechanism is in all databases, except, in my opinion, MySQL.
Suppose we have two tablets: the plate with our actors is a flow, and the table of events for these actors, it is connected in the flow column. Events are sorted by auto-increment key ID, everything is normal. We write a SQL query.
Select the very first event in the very first of the flow, indicating the magic for update skip locked. If there are no locks in the tablet, the query works exactly as normal for update - it takes and puts the lock on the first line we have chosen, i.e. on the line with the first actor and on the line with the first event for this actor.
We launch the same query a second time and it does exactly the same thing, but skipping the already blocked lines. Therefore, he will select the first event in the second actor (the third row in the table) and hang a lock on it.
Suppose, during this time, we finished processing the first of the events, deleted it and closed the transaction. The blocking was removed, so the next time we execute the request, we will receive the first, at the moment, event, in the first actor.
It all works quickly and reliably. On cheap hardware, we received about 1000 such operations per second, provided that each of them slows down for about 10 milliseconds. I used this approach several times, all the code is written in three lines and it is very easy to attach all sorts of convenient things to such a queue.
What do we get with such a queue?
All messages are transactional : we have started a transaction, we are doing something with the database, we are sending messages to other actors somewhere, if the transaction is rolled back, messages will not be sent either, which is insanely convenient.
You can not think about sending messages that cancel previous ones, do not think that all messages should be sent in a pack only at the end of processing and after the commit. In general, you stop thinking about many things. For example, you do not need to think about locks , because you have all the events processed sequentially, for which, in fact, the actors are invented.
In our implementation, we also added a complex error handling policy , because 80% of the payment logic- this is in fact the processing of possible errors: the user has gone somewhere, the counterparty responded with some nonsense, the user has no money at all or the counterparty does not work and you need to select another counterparty, another gateway, and so on. There is an insane amount of different complex logic for handling all sorts of errors.
For us, this solution is effective - 100 payments per second suits us.
But this solution of very limited applicability is its own bike, which can be used in quite a few places. And it has very tight performance limits. That is, I would not recommend this to colleagues from Yandex.Money, because they have black Fridays, and 100 payments per second are clearly not enough for them. We, fortunately, do not have a black Friday, we have a very specific market, and therefore we can calmly manage with such a decision. At the same time, this is an honest bike, an honest enterprise approach - the OpenSource library in this case is not very suitable for us.
Network and transactions
On paper everything was smooth. We implemented it, launched it - it works. And suddenly a problem comes - one of the locks fell .
A gateway is an implementation of a protocol for interacting with someone from a money provider. Well, fell and fell, users did not notice anything, we switched to the backup with another counterparty and began to figure out why. It turned out that the connections in the pool had run out . The reason is not clear, it seems that there was not such a big load on the gateway to exhaust all connections.
We begin to understand and find out: our counterparty began to respond to network requests not in half a second, as it was before, but in one minute. Since we have a processing of the request to the counterparty is a payment step, it is executed in a transaction. When many transactions start to run for a long time, then the connections from the database for all incoming requests are no longer enough. Such a normal behavior: when you have a lot of long transactions , for some reason your connections start to end.
We began to think that I do this. The first is that you can increase the number of connections . Unfortunately, PostgreSQL has quite understandable limits on the maximum number of connections per core.and it is not very big - about a hundred. Because in PostgreSQL, I remind you, each connection is one process. But there are still a lot of processes, tens of thousands or hundreds of thousands of cheap ones will not work. And if our counterparties start responding once a minute, simultaneous transactions may take more.
You can try to make a network call asynchronous , that is, each step is divided into two. Every time we need to pull someone out of counterparties, we need to make a call, save the state to the context database, get an answer from him. Processing the response will fall on the same actor, we will raise the status from the database, do something else that is necessary. But at the same time, the number of steps in the payment increases many times over.and in our requirement - 100 payments per second - we no longer fit. And the logic of work becomes complicated.
It remains only to manage the guarantees of conservation . We do not always need hard transaction, we do not always need hard recovery in a network call, we can almost always repeat it. Therefore, we do not need to be able to do everything through the database, we must be able to do some things around the database , bypassing transactions.
Unfortunately, there is no standard solution that would finely manage retention guarantees for a specific event. Now I try to write it, but, honestly, it turns out to be quite a trivial task to implement skip locked on some Redis on Lua. If I do all this, I will tell you about it.
As a temporary solution, we divided the payment process into several separate actors, executed on different DBMS (and on different servers). This allowed us to make asynchronous requests where it was needed and solve current problems.
The main conclusion is that if actors have appeared somewhere in your system, sooner or later they will crawl everywhere. If you think: “we will have the actor in a separate piece and we have enough performance”, this is not so. After a year of development, you will eventually find out that everyone wants to use them where it is necessary and where it is not very necessary, and they are everywhere. Just try will not succeed!
Accounting and control. Budget Business Intelligence
We have a payment system, that is, money, and money loves when they are considered. Therefore, a business came to us very quickly with a request to make a Business Intelligence system. We do n’t have a lot of data , some hundreds of gigabytes, only top management needs it , we don’t have hundreds of analysts. And the main thing - it is necessary to do " quickly and cheaply ."
Power BI - fast and cheap?
We take PowerBI - this is a solution from Microsoft: the system generates the necessary data in the form of csv, csv are loaded into the cloud, from the cloud they are loaded into PowerBI. Cheap, fast, simple, done literally on the knee, almost completely without the involvement of programmers. Reports to write in csv - it's easy.
But it turned out that cheap is if you have little data, and quickly - if there is little data . As soon as our data volume exceeded 1 GB, it turned out that it took a long time to process, and most importantly, at some point, Microsoft changed the conditions for using the service and it became very payable approximately from the size of 1 GB. And it turned out that this is already somewhat beyond our means.
Come see what you can do.
Clickhouse
First thought - hurray, there is ClickHouse! We throw all our events in Kafku, from there we unload in batches into ClickHouse, it turns out cool, fashionable, hyipovo, analytics should work fast, everything should be free, in general, beautiful and wonderful. But the result from ClickHouse should be shown somewhere. Redash works best with Clickhouse right now. They made a test version of Redash, showed it to the business - they said that they would not work with it, because it looks, to put it mildly, ugly and there are simply no some kind of drill-down business-like things.
We started to find out what the business is dreaming about. Business dreams of something like Tableau, where everything is beautiful. Tableau integrates best with Vertica, and it turns out to be a beautiful, in theory, system: we throw all events at Kafka, with Kafka we throw at Vertica.
Vertica works quickly, efficiently, reliably, easily , and Tableau Server shows all this. But one thing - the cost of the license Vertica is not officially reported, but, to put it mildly, considerable ,. Tableau is also not very cheap. Fortunately, it turned out that, in our volumes, all this is actually not so expensive, because Vertica is free to one terabyte of data, Community Edition absolutely suits us, we are still far from terabyte. And since we only need a license for Tableau for a small number of developers and top managers, this costs some good money. Up to the point that we needed fewer licenses than the minimum package that Tableau sells.
It turned out that such a normal, completely classic heavy enterprise-solution is also normal.web-solutions . It is inexpensive and set from scratch without hesitation. Vertica pleases me so far: in her many analytical things are solved very beautifully. While you do not have a lot of data - I advise. However, in operation it is demanding to understand the principles of its work, you need to understand them before use.
At the same time, I think that if we grow beyond a terabyte in a few years, then by that time we will already have a good examination on ClickHouse, Tableau will obviously make an adapter to it, and we will carefully crawl to a free ClickHouse for what quite reasonable time.
Content
We have quite a lot of texts:
- Legal information that we are obliged to provide, offers, etc .;
- Information about counterparties, including commissions that we charge to users;
- ;
- ;
- .
The error in this information is quite painful. For example, if we don’t upload the commissions that we actually charge, then users may be very offended at us, and, most importantly, the regulatory authorities may be offended by us , which is much worse. Therefore, the texts for us are also code : you need to check it before publication, many people are involved in its preparation, mistakes are expensive.
At the beginning, the text was just part of the front end: all the texts were written by front-end designers, then they went into testing, were read, showed up on a demo stand, then they were already in production. But the text changes too often, and so it was just expensive to do.
And we started thinking how to automate all this .and make a CMS. Simple CMS are not suitable because:
- ;
- , ;
- ;
- Java-.
Not simple CMSs are too expensive in every sense, they usually cost a lot of money, and their integration is very obscure, because there are a lot of things invented there.
The ideal solution would be to put a banal Git on everyone who works with texts : let them send all written texts directly to the repository. But the thought of putting Git to top managers and a copywriter and teaching them how to use it, we thought and thought and refused in horror, because git is not for normal people.
The most ideal solution would probably be a text editor , built right into IntelliJ IDEA, where you can neatly hide the complexity of using Git. But, unfortunately, JetBrains has not yet done such an editor, although I have long asked them.
I had to make the bike again:
- .
- html, html, CMS .
- — , , . .
- ( ) - . Jira, , — , , , , .
That is, I had to write, in fact, a micro portal in enterprise style.
Honestly, if I could buy such a solution, I would prefer to buy it. But I simply did not find a single embedded CMS for large systems on the market, and, in my opinion, they are not there yet. I, frankly, once again write it from scratch, and it is very pitiful that so far no one has done it for me.
findings
What of all this can be said? That life on the edge is quite interesting.
When you have tasks at the same time from the web and from the enterprise, you can borrow different ideas from the world of corporations , they have a lot of things thought out. Sometimes you can borrow not only ideas, but also concrete solutions like Vertica, if they are cheap.
Honestly, if I found cheap support for IBM DB2 - I would implement the project on it, I love it very much, it is cheap and very reliable, but it’s difficult to find support for this base for reasonable money in Russia. Of course, you can lure someone from the Post of Russia, but they are accustomed to such large servers that we are obviously too small for them.
Wellbig problems from the enterprise world can be solved in a web-style quite simply, what we are constantly doing.
Architecture is a dynamic concept.
There is no good architecture at all. There is an architecture that more or less satisfies you at a specific point in time . Time is changing - the architecture is changing, and we must constantly be ready for this, and always invest resources in the development of architecture. The project architecture is a process, not a result .
Java and SQL are really cool if you can cook it. We are able, therefore everything is easy, fast, and effortless, and we make quite a very small team rather complicated.
news
HighLoad++ 2018 8 9 , Percona Live.
Highload++ Siberia , 25 26 , , , , — .
++ , . :
- « ClickHouse » ClickHouse .
- Yury Lilekov with a report on why the developer needs statistics, or how to improve the quality of the product?
- Alexander Serbul will talk about the features of lambda architectures , the Amazon Lambda microservice platform, as well as pitfalls and victories with Node.JS and multi-threaded Java .
Source: https://habr.com/ru/post/354824/
All Articles