Domain fronting: what is it?

You’ve probably already heard about domain fronting, especially in the context of blocking the RKN servers of Google servers responsible for google.com itself, and further the subsequent ban on Google and AWS from using their domains to bypass blockages.
What is a domain cover?
Domain fronting, or, loosely translated, domain cover is a way to bypass filters and locks by hiding the end goal of a connection using the features of a CDN. This method is possible because modern CDNs contain two principal parts that exist independently of each other and, as a rule, interact with each other only in terms of establishing a TCP connection with each other:
- There is an external part responsible for establishing a secure connection with SSL certificate data transmission.
- There is an internal part that is responsible for processing the immediately sent request after decryption. Usually - HTTP request.
Since these two parts do not have a connection between themselves, you can refer to one site when referring to the first part, and after establishing a secure connection, send a request to another site. If it concerns private CDNs, then usually there is no problem, with rare exceptions in the form of access to internal resources, to which there is usually no access. If it concerns public CDNs in which you can buy a membership, like AWS CloudFront or analogs from other companies, then everything at once becomes much more interesting.
How the censor sees a CDN
The task of the censor is to restrict access to certain resources from the list. In the case of simple HTTP, this task is not a special problem even with the accuracy of a specific page address. Of course, even in such a simple task there is a wide field for stupid mistakes that generate many beautiful ways to bypass the blockages , which are possible due to the basic stability of the network to all kinds of communication problems, which feature is simply impossible for people to think of blocking sites from helplessness and inability to cope criticized online.
In the case of encryption, the task is more complicated. Blocking a specific page address becomes impossible. The simplest solution to blocking a site for HTTPS is blocking by IP. Even if no CDN is used, this task contains a number of very unpleasant side effects . If CDN is used, then IP blocking becomes often impossible: not so much because there can be many sites on the same IP in the CDN (RKN hasn’t stopped it much), but because the site on the CDN can have many different IPs, which is impossible to know in advance.
The censors come to the censors by modern browsers, which, before establishing a secure connection, always send in plain text the name of the site to which you want to go. Provider and carrier DPI can easily see with which site the connection is established, then terminate the connection or otherwise interfere.
Experiment
Let's see how the connection setup sees the censor, and how we can circle the censor around our fingers. For the demonstration, we use tshark , although the same demonstration can be performed using tcpdump or via the GUI in Wireshark.
In the experiments we use the same site where you are reading this article, since it is located behind the CDN from QRATOR, which has all the necessary features to demonstrate this way of circumventing censorship. This demonstration itself does not mean that the used CDAT from QRATOR has some kind of vulnerability or security issue: all CDNs have worked so far, and most of the CDNs still work. Exactly the same feature is, for example, in CDN in Yandex.
In one console, run:
tshark -T fields -Y 'tcp.dstport == 443 and ssl.handshake.extensions_server_name' -e ssl.handshake.extensions_server_name Under Debian, this problem is fixed by three commands:
sudo dpkg-reconfigure wireshark-common sudo gpasswd -a $USER wireshark newgrp wireshark Under other distributions YMMV. Other things being equal, use sudo.
In the next console, let's access some HTTPS site:
curl -sI https://habr.com In the first console in the log, we will see the name of the site to which we have just accessed, despite the use of HTTPS:
Capturing on 'eno1' habr.com Surprise for the censor
Without closing the SNI logging, we try to emulate the request that cURL sends:
(echo HEAD / HTTP/1.1 echo Host: habr.com echo Connection: close echo) | openssl s_client -quiet -servername habr.com -connect habr.com:443 We will see the same answer as before when calling curl -sI https://habr.com . The tshark output is the same: the connection to habr.com is logged.
And now, without changing the request headers, let us turn not to habr.com, but by the old name of the site:
(echo HEAD / HTTP/1.1 echo Host: habr.com echo Connection: close echo) | openssl s_client -quiet -servername habrahabr.ru -connect habrahabr.ru:443 Surprise, surprise! The answer is exactly the same as before, but in the tshark log and in the openssl s_client output, openssl s_client means that we turned to habrahabr.ru, and not to habr.com:
depth=0 OU = Domain Control Validated, OU = PositiveSSL Multi-Domain, CN = habrahabr.ru The same trick can be done in the opposite direction:
(echo HEAD / HTTP/1.1 echo Host: habrahabr.ru echo Connection: close echo) | openssl s_client -quiet -servername habr.com -connect habr.com:443 The logs will indicate that we turned to habr.com, but the answer will be consistent with the conclusion:
curl -I https://habrahabr.ru Not Habrom one
In order not to go far, the same trick works for Yandex sites using their own CDN:
(echo GET / HTTP/1.1 echo Host: music.yandex.kz echo Connection: close echo) | openssl s_client -quiet -servername music.yandex.ru -connect music.yandex.ru:443 | grep -Eo '<meta[^>]*?og:url[^>]*?>' The log of the censor will show that we turned to music.yandex.ru, and the team will show that the main page music.yandex.kz has opened for us:
<meta property="og:url" content="https://music.yandex.kz/home"/> What is going on here at all?
On the flowchart, our requests look like this:
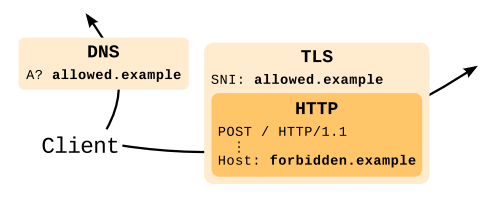
From the point of view of connection, we connect to one site, for example, google.com, but from the point of view of the HTTP protocol, we make a request to a completely different site, which only occasionally is in the same CDN.
(The illustration above is from a large review article in English that looks at the background of the issue, possible alternatives and other details about the use of domain cover.)
What can I say?
In practice, we made sure that we can send a request to one site for HTTPS, and the censor will see that we have accessed a completely different site. It was in this way that Signal went around blocking in Egypt and some other countries for more than a year, hiding behind google.com , until first Google and then Amazon forbade them to use their websites and their clients' websites to circumvent censorship.
Telegram also uses this method of circumventing censorship. Those interested can easily find in the source code of official clients exactly how this is done in the Telegram, and which CDNs are used.
It is clear that there is absolutely no practical benefit from the domain cover on CDN Habr and Yandex if you do not have a website that uses the same CDN, because, I repeat, this feature of CDN is not yet considered to be a vulnerability of an arbitrary CDN as such. Do not rush to run reports on HackerOne: your report losed as not applicable - that's all you get for now.
This situation leads to the fact that most modern CDN to some extent can be used to cover a foreign domain .
The task of searching for domains with high reputation placed on CDNs, which not every censor can decide to block, requires only time and perseverance. For example, the CDN contains many popular domains like media.tumblr.com, images.instagram.com, cdn.zendesk.com, and cdn.atlassian.com, which can be used for domain cover. There is no shortage of such popular, which means there are no suitable domains.
Do evil serve Google and Amazon?
A legitimate question arises: if Google and Amazon do not want to help circumvent censorship, does it mean that they serve the world's evil? This answer cannot be answered unambiguously, as there are facts of using domain cover not only to circumvent censorship, but also for unauthorized remote access in case of hacking .
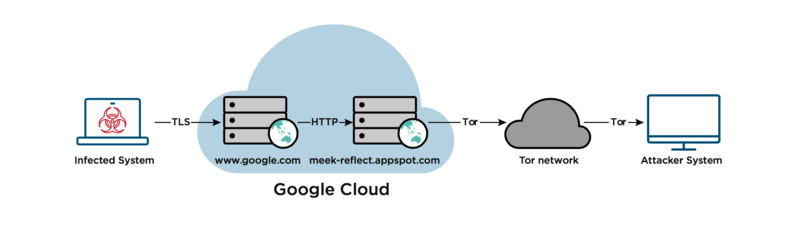
Understandably, Google and Amazon don't want to have anything to do with burglars and other criminal elements that use their decent domains for their dirty business.
The latter observation suggests that, unfortunately, we can expect that all other CDNs will gradually follow in the wake of Google and Amazon, banning or limiting the described possibilities for circumventing censorship and blocking.
If you are administering your own CDN, consider whether someone can use your services for similar, inconsistent with the expected, goals, and how you feel about it. If you do not prohibit, then you should at least know that something like this can be done on your territory.
')
Source: https://habr.com/ru/post/354814/
All Articles