Understanding how disk space is used in Linux
Prim Trans. : The author of the original article, the Spanish Open Source-enthusiast nachoparker , who develops the NextCloudPlus project (formerly known as NextCloudPi), shares his knowledge of the Linux disk subsystem, making important clarifications in answers to seemingly simple questions ...
How much space does this file take on the hard disk? How much free space do I have? How many more files can I fit into the remaining space?

')
The answers to these questions seem obvious. We all have an instinctive understanding of how file systems work, and often we imagine storing files on a disk like filling a basket with apples.
However, in modern Linux systems, such intuition can be misleading. Let's see why.
What is file size? The answer seems to be simple: a collection of all the bytes of its contents, from the beginning to the end of the file.
Often, the entire contents of the file is presented as located byte by byte:

We also perceive the concept of file size . To find out, run
In the Linux kernel, the inode memory structure is a file. And the metadata that we access with the
Fragment
Here you can see familiar attributes, such as access time and modifications, as well as
Thinking in terms of file size is intuitive, but we are more interested in how space is actually used.
For internal file storage, the file system splits the vault into blocks . The traditional block size was 512 bytes, but the more current value is 4 kilobytes. In general, the choice of this value is guided by the supported page size on typical MMU equipment (memory management unit, “memory management device ” - approx. Transl. ) .
The file system inserts the file cut into chunks into these blocks and keeps track of them in the metadata. Ideally, it looks like this:

... but in reality, files are constantly being created, resized, deleted, so the real picture is this:
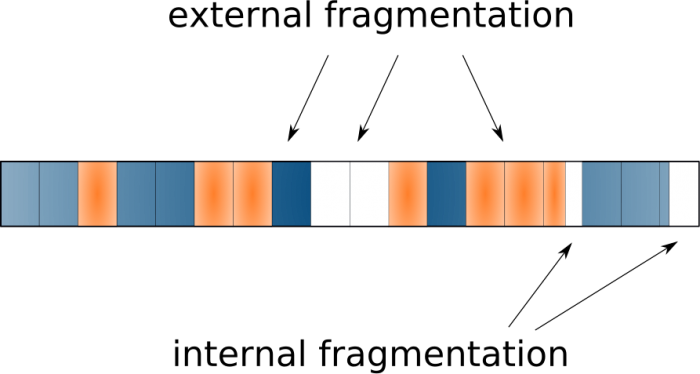
This is called external fragmentation and usually results in a drop in performance. The reason - the rotating head of the hard disk has to move from place to place to collect all the fragments, and this is a slow operation. The solution to this problem is the classic defragmentation tools.
What happens to files smaller than 4 KB? What happens to the contents of the last block after the file has been cut into pieces? Unused space will naturally occur - this is called internal fragmentation . Obviously, this side effect is undesirable and can lead to the fact that a lot of free space will not be used, especially if we have a large number of very small files.
So, the actual disk usage of the file can be seen with
Thus, we look at two values: the file size and the blocks used. We are accustomed to think in terms of the former, but we must - in terms of the latter.
In addition to the actual contents of the file, the kernel also needs to store all kinds of metadata. We have already seen the inode metadata, but there are other data with which every UNIX user is familiar: access rights , owner , uid , gid , flags, ACL .
Finally, there are other structures, such as a superblock with the representation of the file system itself, vfsmount with the representation of a mount point, as well as information about redundancy, named spaces, and so on. As we will see later, some of these metadata may also occupy a significant place.
This data is highly dependent on the file system used - in each of them the block-to-file mapping is implemented in its own way. The traditional ext2 approach is an
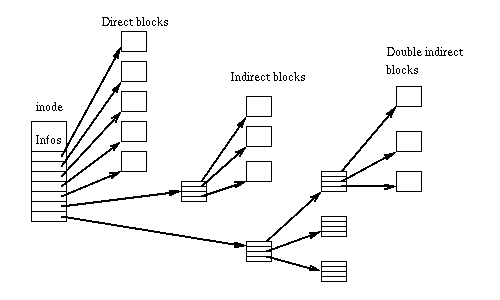
The same table can be seen in the memory structure (fragment from
For large files, this scheme leads to large overheads, since a single (large) file requires matching thousands of blocks. In addition, there is a limit on file size: using this method, the 32-bit ext3 file system supports files no more than 8 TB. The ext3 developers saved the situation by supporting 48 bits and adding extents :
The idea is really simple: to occupy the neighboring blocks on the disk and simply declare where the extent begins and what is its size. Thus, we can allocate large groups of blocks to a file, minimizing the amount of metadata and at the same time using faster sequential access.
Note to the curious: ext4 provides backward compatibility, that is, it supports both methods: indirect (indirect) and extents . You can see how space is allocated by the example of a write operation. Writing does not go directly to the repository - for performance reasons, the data first gets into the file cache. After that, at a certain point, the cache writes information to the permanent storage.
The file system cache is represented by the
... where
The latest generation of file systems also store checksums for data blocks to avoid imperceptible data corruption . This feature allows you to detect and correct random errors and, of course, leads to additional overhead in using the disk in proportion to the file size.
More modern systems like BTRFS and ZFS support checksums for data, while older systems such as ext4 have checksums for metadata.
The journaling capabilities for ext2 appeared in ext3. The log is a cyclic log that records processed transactions in order to improve the resilience to power failures. By default, it applies only to metadata , but you can also activate it for data using the
This is a special hidden file, usually with an inode number of 8 and a size of 128 MB, which can be found in the official documentation:
The ability of tail packing, also called block sub-allocation , allows file systems to use the empty space at the end of the last block (“tails”) and distribute it among different files, effectively packing the “tails” into a single block.
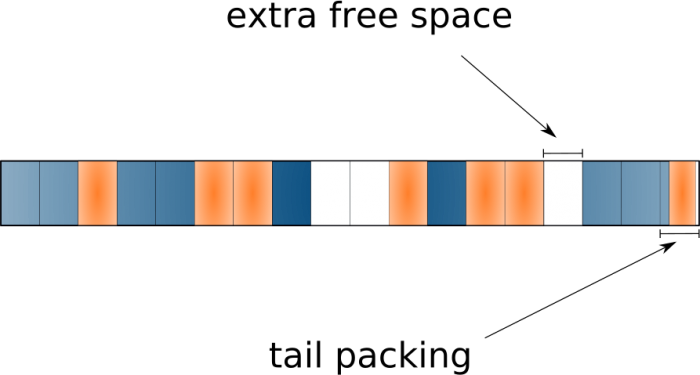
It is great to have the ability to save a lot of space, especially if you have a large number of small files ... However, it leads to the fact that existing tools do not accurately report the used space. Because with it, we cannot simply add all the occupied blocks of all files to get real data on disk usage. This feature is supported by the BTRFS and ReiserFS file systems.
Most modern file systems support sparse files . Such files may have holes that are not actually written to disk (do not occupy disk space). This time the actual file size will be larger than the blocks used.
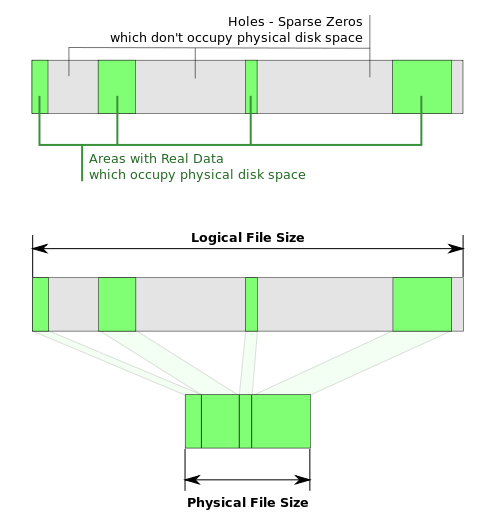
Such a feature can be very useful, for example, for quickly generating large files or for providing free space to a virtual hard disk of a virtual machine upon request.
To slowly create a 10-gigabyte file that takes up about 10 GB of disk space, you can run:
To create the same large file instantly, you just need to write the last byte ... or even do:
Or use the
The disk space allocated to the file can be changed with the
For example, you can create holes in a file, turning it into sparse, like this:
The
... and the reverse action (to make a "dense" copy of a sparse file) looks like this:
Thus, if you like working with sparse files, you can add the following alias to your terminal environment (
When processes read bytes in sections of holes, the file system provides them with pages with zeros. For example, you can see what happens when a file cache reads from a file system in the region of holes in ext4. In this case, the sequence in
After that, the memory segment that the process is trying to access using the
The next (after the ext family) file system generation brought some very interesting features. Perhaps the most attention among the features of file systems like ZFS and BTRFS deserves their COW (copy-on-write, “copy-on-write”).
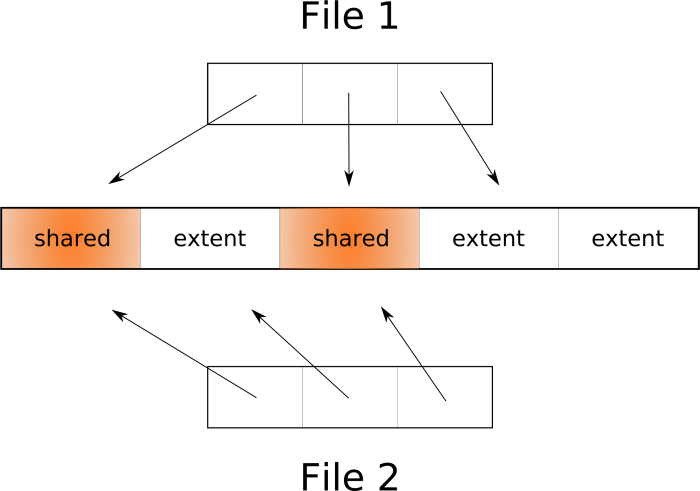
When we perform a copy-on-write operation or cloning , or a copy of a reflink , or a shallow copy , in fact, no duplication of quantities occurs. It simply creates an annotation in the metadata for the new file, which refers to the same extents of the original file, and the extent itself is marked as shared . At the same time, an illusion is created in user space that there are two separate files that can be separately modified. When a process wants to write to a shared extent, the kernel will first create a copy of it and an annotation that this extent belongs to a single file (at least for the time being). After that, the two files have more differences, but they can still share many extents. In other words, extents in file systems with COW support can be divided between files, and the file system will create new extents only if necessary.
As you can see, cloning is a very fast operation that does not require doubling of space, which is used in the case of a regular copy. This technology is behind the ability to create instant snapshots in BTRFS and ZFS. You can literally clone (or snapshot ) the entire root file system in less than a second. Very useful, for example, before updating packages in case something breaks.
BTRFS supports two methods for creating shallow copies. The first is related to subvolumes and uses the
The next step is if there are non-shallow copies or a file, or even files with duplicate extents, you can de-duplicate them so that they use (via reflink) common extents and free up space. One of the tools for this is duperemove , but note that this naturally leads to higher file fragmentation.
If we try now to figure out how disk space is used by files, everything will not be so simple. Utilities like
Similarly, in the case of BTRFS, the
Unfortunately, I don’t know simple ways to track the occupied space by individual files in file systems with COW. At the sub-volume level, using utilities like btrfs-du, we can get a rough idea of the amount of data that is unique to snapshots and that are shared between snapshots.
Read also in our blog:
How much space does this file take on the hard disk? How much free space do I have? How many more files can I fit into the remaining space?
')
The answers to these questions seem obvious. We all have an instinctive understanding of how file systems work, and often we imagine storing files on a disk like filling a basket with apples.
However, in modern Linux systems, such intuition can be misleading. Let's see why.
file size
What is file size? The answer seems to be simple: a collection of all the bytes of its contents, from the beginning to the end of the file.
Often, the entire contents of the file is presented as located byte by byte:
We also perceive the concept of file size . To find out, run
ls -l file.c or the stat command (ie, stat file.c ), which makes the stat() system call.In the Linux kernel, the inode memory structure is a file. And the metadata that we access with the
stat command is in the inode.Fragment
include/linux/fs.h : struct inode { /* excluded content */ loff_t i_size; /* file size */ struct timespec i_atime; /* access time */ struct timespec i_mtime; /* modification time */ struct timespec i_ctime; /* change time */ unsigned short i_bytes; /* bytes used (for quota) */ unsigned int i_blkbits; /* block size = 1 << i_blkbits */ blkcnt_t i_blocks; /* number of blocks used */ /* excluded content */ } Here you can see familiar attributes, such as access time and modifications, as well as
i_size — this is the file size , as defined above.Thinking in terms of file size is intuitive, but we are more interested in how space is actually used.
Blocks and block size
For internal file storage, the file system splits the vault into blocks . The traditional block size was 512 bytes, but the more current value is 4 kilobytes. In general, the choice of this value is guided by the supported page size on typical MMU equipment (memory management unit, “memory management device ” - approx. Transl. ) .
The file system inserts the file cut into chunks into these blocks and keeps track of them in the metadata. Ideally, it looks like this:
... but in reality, files are constantly being created, resized, deleted, so the real picture is this:
This is called external fragmentation and usually results in a drop in performance. The reason - the rotating head of the hard disk has to move from place to place to collect all the fragments, and this is a slow operation. The solution to this problem is the classic defragmentation tools.
What happens to files smaller than 4 KB? What happens to the contents of the last block after the file has been cut into pieces? Unused space will naturally occur - this is called internal fragmentation . Obviously, this side effect is undesirable and can lead to the fact that a lot of free space will not be used, especially if we have a large number of very small files.
So, the actual disk usage of the file can be seen with
stat , ls -ls file.c or du file.c For example, the contents of a 1-byte file still occupies 4 KB of disk space: $ echo "" > file.c $ ls -l file.c -rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c $ ls -ls file.c 4 -rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c $ du file.c 4 file.c $ dutree file.c [ file.c 1 B ] $ dutree -u file.c [ file.c 4.00 KiB ] $ stat file.c File: file.c Size: 1 Blocks: 8 IO Block: 4096 regular file Device: 2fh/47d Inode: 2185244 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1000/ nacho) Gid: ( 1000/ nacho) Access: 2018-04-30 20:41:58.002124411 +0200 Modify: 2018-04-30 20:42:24.835458383 +0200 Change: 2018-04-30 20:42:24.835458383 +0200 Birth: - Thus, we look at two values: the file size and the blocks used. We are accustomed to think in terms of the former, but we must - in terms of the latter.
File system specific features
In addition to the actual contents of the file, the kernel also needs to store all kinds of metadata. We have already seen the inode metadata, but there are other data with which every UNIX user is familiar: access rights , owner , uid , gid , flags, ACL .
struct inode { /* excluded content */ struct fown_struct f_owner; umode_t i_mode; unsigned short i_opflags; kuid_t i_uid; kgid_t i_gid; unsigned int i_flags; /* excluded content */ } Finally, there are other structures, such as a superblock with the representation of the file system itself, vfsmount with the representation of a mount point, as well as information about redundancy, named spaces, and so on. As we will see later, some of these metadata may also occupy a significant place.
Block allocation metadata
This data is highly dependent on the file system used - in each of them the block-to-file mapping is implemented in its own way. The traditional ext2 approach is an
i_block table with direct and indirect blocks ( direct / indirect blocks ) .The same table can be seen in the memory structure (fragment from
fs/ext2/ext2.h ): /* * Structure of an inode on the disk */ struct ext2_inode { __le16 i_mode; /* File mode */ __le16 i_uid; /* Low 16 bits of Owner Uid */ __le32 i_size; /* Size in bytes */ __le32 i_atime; /* Access time */ __le32 i_ctime; /* Creation time */ __le32 i_mtime; /* Modification time */ __le32 i_dtime; /* Deletion Time */ __le16 i_gid; /* Low 16 bits of Group Id */ __le16 i_links_count; /* Links count */ __le32 i_blocks; /* Blocks count */ __le32 i_flags; /* File flags */ /* excluded content */ __le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */ /* excluded content */ } For large files, this scheme leads to large overheads, since a single (large) file requires matching thousands of blocks. In addition, there is a limit on file size: using this method, the 32-bit ext3 file system supports files no more than 8 TB. The ext3 developers saved the situation by supporting 48 bits and adding extents :
struct ext3_extent { __le32 ee_block; /* first logical block extent covers */ __le16 ee_len; /* number of blocks covered by extent */ __le16 ee_start_hi; /* high 16 bits of physical block */ __le32 ee_start; /* low 32 bits of physical block */ }; The idea is really simple: to occupy the neighboring blocks on the disk and simply declare where the extent begins and what is its size. Thus, we can allocate large groups of blocks to a file, minimizing the amount of metadata and at the same time using faster sequential access.
Note to the curious: ext4 provides backward compatibility, that is, it supports both methods: indirect (indirect) and extents . You can see how space is allocated by the example of a write operation. Writing does not go directly to the repository - for performance reasons, the data first gets into the file cache. After that, at a certain point, the cache writes information to the permanent storage.
The file system cache is represented by the
address_space structure, in which the writepages operation is invoked . The whole sequence looks like this: (cache writeback) ext4_aops-> ext4_writepages() -> ... -> ext4_map_blocks() ... where
ext4_map_blocks() will call the ext4_ext_map_blocks() or ext4_ind_map_blocks() function depending on whether extents are being used. If you look at the first in extents.c , you can see the references to the holes , which will be discussed below.Checksums
The latest generation of file systems also store checksums for data blocks to avoid imperceptible data corruption . This feature allows you to detect and correct random errors and, of course, leads to additional overhead in using the disk in proportion to the file size.
More modern systems like BTRFS and ZFS support checksums for data, while older systems such as ext4 have checksums for metadata.
Journaling
The journaling capabilities for ext2 appeared in ext3. The log is a cyclic log that records processed transactions in order to improve the resilience to power failures. By default, it applies only to metadata , but you can also activate it for data using the
data=journal option, which will affect performance.This is a special hidden file, usually with an inode number of 8 and a size of 128 MB, which can be found in the official documentation:
The log presented in the ext3 file system is used in ext4 to protect the filesystem from damage in the event of system failures. A small sequential fragment of the disk (the default is 128 MB) is reserved inside the file system as a place for dropping "important" disk write operations as quickly as possible. When a transaction with important data is completely written to disk and flushed from disk (disk write cache) , the data record is also recorded in the log. Later, the log code records transactions in their final positions on the disk (an operation can lead to a long search or a large number of read-delete-erase operations) before the record of this data is erased. In the event of a system failure during the second slow write operation, the log allows you to reproduce all operations up to the last record, ensuring that everything written to disk through the journal is atomic. The result is a guarantee that the file system will not get stuck halfway through the metadata update.
"Tail packaging"
The ability of tail packing, also called block sub-allocation , allows file systems to use the empty space at the end of the last block (“tails”) and distribute it among different files, effectively packing the “tails” into a single block.
It is great to have the ability to save a lot of space, especially if you have a large number of small files ... However, it leads to the fact that existing tools do not accurately report the used space. Because with it, we cannot simply add all the occupied blocks of all files to get real data on disk usage. This feature is supported by the BTRFS and ReiserFS file systems.
Sparse files
Most modern file systems support sparse files . Such files may have holes that are not actually written to disk (do not occupy disk space). This time the actual file size will be larger than the blocks used.
Such a feature can be very useful, for example, for quickly generating large files or for providing free space to a virtual hard disk of a virtual machine upon request.
To slowly create a 10-gigabyte file that takes up about 10 GB of disk space, you can run:
$ dd if=/dev/zero of=file bs=2M count=5120 To create the same large file instantly, you just need to write the last byte ... or even do:
$ dd of=file-sparse bs=2M seek=5120 count=0 Or use the
truncate command: $ truncate -s 10G The disk space allocated to the file can be changed with the
fallocate command, which makes the fallocate() system call. More advanced operations are available with this call - for example:- Preallocate space for the file by inserting zeroes. This operation increases both disk usage and file size.
- Free up space. The operation will create a hole in the file, making it sparse and reducing the use of space without affecting the file size.
- Optimize space by reducing file size and disk usage.
- Increase the file space by inserting a hole at its end. File size increases, and disk usage does not change.
- Zero holes. Holes will not be written to disk extents, which will be read as zeros, without affecting disk space and its use.
For example, you can create holes in a file, turning it into sparse, like this:
$ fallocate -d file The
cp command supports sparse files. Using simple heuristics, it tries to determine if the source file is sparse: if so, the resulting file will also be sparse. You can copy a non-thinned file into a sparse one like this: $ cp --sparse=always file file_sparse ... and the reverse action (to make a "dense" copy of a sparse file) looks like this:
$ cp --sparse=never file_sparse file Thus, if you like working with sparse files, you can add the following alias to your terminal environment (
~/.zshrc or ~/.bashrc ): alias cp='cp --sparse=always' When processes read bytes in sections of holes, the file system provides them with pages with zeros. For example, you can see what happens when a file cache reads from a file system in the region of holes in ext4. In this case, the sequence in
readpage.c will look something like this:(cache read miss) ext4_aops-> ext4_readpages() -> ... -> zero_user_segment()After that, the memory segment that the process is trying to access using the
read() system call will get zeros directly from the fast memory.COW file systems (copy-on-write)
The next (after the ext family) file system generation brought some very interesting features. Perhaps the most attention among the features of file systems like ZFS and BTRFS deserves their COW (copy-on-write, “copy-on-write”).
When we perform a copy-on-write operation or cloning , or a copy of a reflink , or a shallow copy , in fact, no duplication of quantities occurs. It simply creates an annotation in the metadata for the new file, which refers to the same extents of the original file, and the extent itself is marked as shared . At the same time, an illusion is created in user space that there are two separate files that can be separately modified. When a process wants to write to a shared extent, the kernel will first create a copy of it and an annotation that this extent belongs to a single file (at least for the time being). After that, the two files have more differences, but they can still share many extents. In other words, extents in file systems with COW support can be divided between files, and the file system will create new extents only if necessary.
As you can see, cloning is a very fast operation that does not require doubling of space, which is used in the case of a regular copy. This technology is behind the ability to create instant snapshots in BTRFS and ZFS. You can literally clone (or snapshot ) the entire root file system in less than a second. Very useful, for example, before updating packages in case something breaks.
BTRFS supports two methods for creating shallow copies. The first is related to subvolumes and uses the
btrfs subvolume snapshot . The second is for individual files and uses cp --reflink . Such an alias (again, for ~/.zshrc or ~/.bashrc ) can be useful if you want to make fast shallow copies by default:cp='cp --reflink=auto --sparse=always'The next step is if there are non-shallow copies or a file, or even files with duplicate extents, you can de-duplicate them so that they use (via reflink) common extents and free up space. One of the tools for this is duperemove , but note that this naturally leads to higher file fragmentation.
If we try now to figure out how disk space is used by files, everything will not be so simple. Utilities like
du or dutree only consider the blocks used, not taking into account that some of them can be shared, so they will show more space than is actually used.Similarly, in the case of BTRFS, the
df command should be avoided, since the space occupied by the BTRFS file system will be shown as free. It is better to use btrfs filesystem usage : $ sudo btrfs filesystem usage /media/disk1 Overall: Device size: 2.64TiB Device allocated: 1.34TiB Device unallocated: 1.29TiB Device missing: 0.00B Used: 1.27TiB Free (estimated): 1.36TiB (min: 731.10GiB) Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Data,single: Size:1.33TiB, Used:1.26TiB /dev/sdb2 1.33TiB Metadata,DUP: Size:6.00GiB, Used:3.48GiB /dev/sdb2 12.00GiB System,DUP: Size:8.00MiB, Used:192.00KiB /dev/sdb2 16.00MiB Unallocated: /dev/sdb2 1.29TiB $ sudo btrfs filesystem usage /media/disk1 Overall: Device size: 2.64TiB Device allocated: 1.34TiB Device unallocated: 1.29TiB Device missing: 0.00B Used: 1.27TiB Free (estimated): 1.36TiB (min: 731.10GiB) Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Data,single: Size:1.33TiB, Used:1.26TiB /dev/sdb2 1.33TiB Metadata,DUP: Size:6.00GiB, Used:3.48GiB /dev/sdb2 12.00GiB System,DUP: Size:8.00MiB, Used:192.00KiB /dev/sdb2 16.00MiB Unallocated: /dev/sdb2 1.29TiB Unfortunately, I don’t know simple ways to track the occupied space by individual files in file systems with COW. At the sub-volume level, using utilities like btrfs-du, we can get a rough idea of the amount of data that is unique to snapshots and that are shared between snapshots.
Links
- Comparison oa file systems, Wikipedia ;
- Ext3 for large filesystems, LWN ;
- Ext4 (and Ext2 / Ext3) Wiki .
PS from translator
Read also in our blog:
Source: https://habr.com/ru/post/354802/
All Articles