Experience with WebAssembly or as C ++ undefined behavior shot in the leg
At the last C ++ Russia 2018, we talked about our experience of switching to WebAssembly, how we came across UB and how it heroically stuck, a little about the technology itself and how it works on different devices. Under the cut there will be a text version of everything relative to UB. The code for the tests used is available on GitHub .
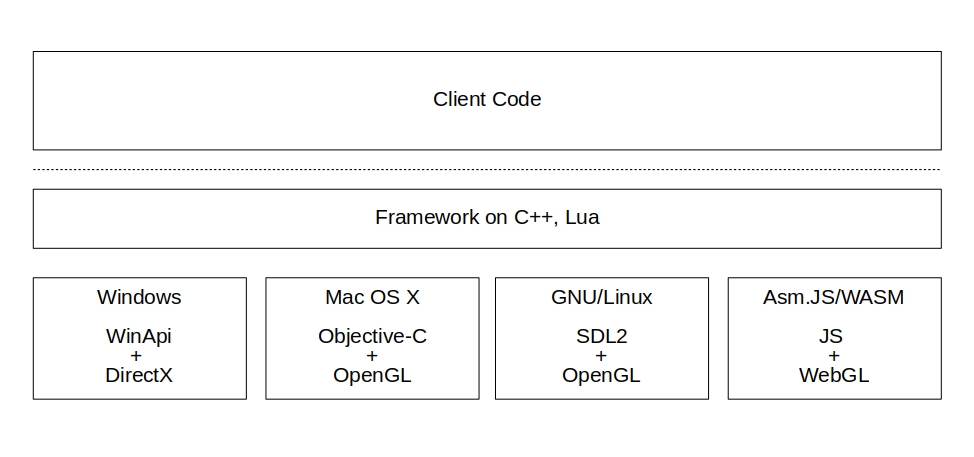
Business logic is written in C ++ using our framework. It itself is written in C ++ with Lua support. Since there is code that depends on the platform, you have to use JavaScript and DOM.
For example, for watching videos, on desktop platforms, you use a video player with codecs from Google, and in the browser you use the video tag

It is logical to assume that an int type overflow will occur and -2 147 483 648 will be output.

No, the app will crash . At the same time, everything works on asm.js and desktop applications.

The program's stopping point indicates the trunc_s or trunc_u . The documentation on this subject states the following:
Truncating a float to an int may throw an exception if the initial value of the float does not fit into the integer range or if it is NaN.
It is necessary to catch all the problem areas in which the conversion of float and double to int occurs, or to control it as otherwise.

This problem has already been discussed many times, and now a new specification is being developed on this topic for the WebAssembly standard called nontrapping-float-to-int-conversions . It is now proposed to use the BINARYEN_TRAP_MODE option with the value clamp . For all cases of float to- int conversion, a wrapper will be used that checks the possibility of conversion. If this is not possible, then truncates at the maximum or minimum value.
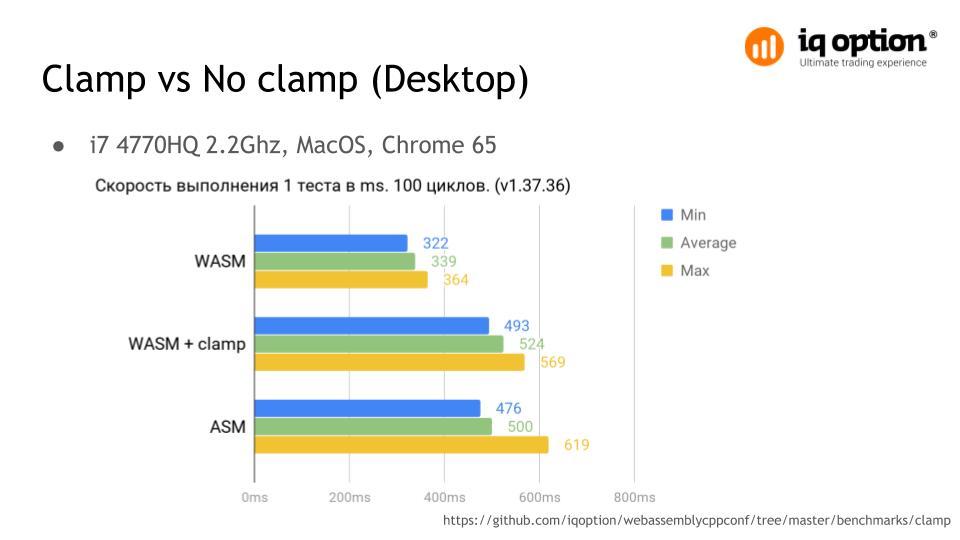
With the clamp option, the application worked stably. A simple test was made that clearly shows the situation with the clamp mode. One pass performs one hundred million float and double conversions to an int . The performance drops by about 40% compared to the assembly without the clamp option, and for version 1.37.17 , which was available at that time, this figure was even higher, so on the slide this is an optimized version of the clamp mode, but the gap is noticeable . Here, the numbers were measured on a Core i7 2.2 Ghz processor in Chrome version 65 under Mac OS X.
The clamp mode has been optimized by Alon Zakai aka kripken - the developer of emscripten , just based on this test. Now clamp on performance is practically indistinguishable from asm.js. A jump of 619 milliseconds, for asm.js, this is just the first iteration of the test for which JIT optimization was performed.
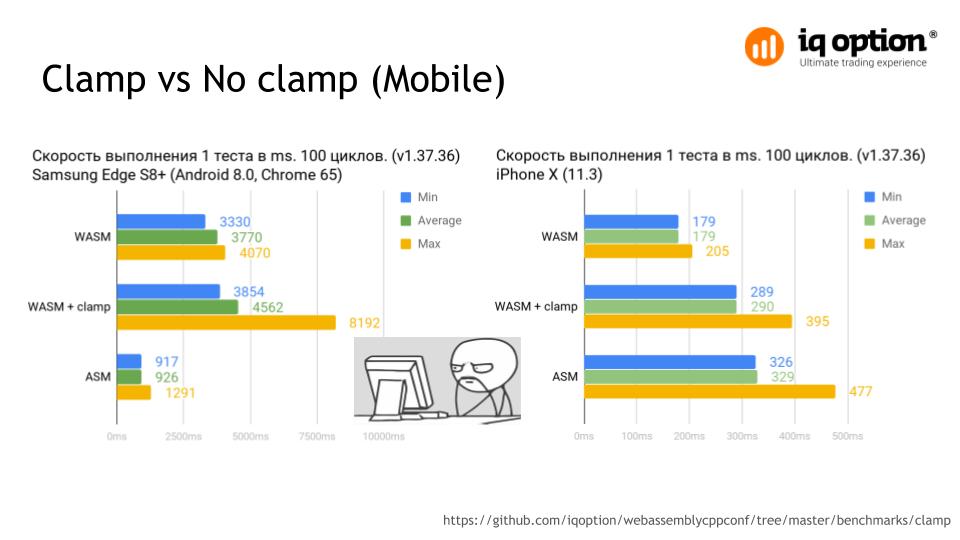
The same test on mobile devices Samsung Edge S8 + and iPhone X. The gap in the case of wasm about 20 times. This is a demonstration of how to make JIT compilation really optimal and productive.
On the iPhone X, the difference between the presence and absence of the clamp mode is approximately 40%. Under Android, such results do not apply only to this device. On other devices, the results are similar or worse.
Half a year ago, these numbers were completely different, considering that at that time iOS did not yet support WebAssembly and could only be compared with the practically non-working asm.js version.

It was decided to catch problem areas in the code with truncated float and double in integer . The easiest option is to compare the value in float with the numeric_limits<int> boundary, and also to check whether the value is NaN .

The key point, the isfinite , was generated after truncation. The optimizer considered that he could do this because he did not consider truncate a dangerous operation. In this case, the optimization is -3 , but this is not important, since any optimization will lead to the generation of such code.
We get inoperative code, even if we take into account all cases. At present, this problem in the compiler is saved, it is known, and its solution is under development, it is nontrapping-float-to-int-conversions .

Since the truncate in WebAssembly is not secure at the moment, more control is needed for code generation. For example, with the -0 option -0 all the checks in our function will be in the same order as they were written, but this affects the performance and size of the output file.
You can limit the optimization only for this function by specifying the optnone attribute for it. If you look at the results of the synthetic test, the difference in performance when using the function and without it is very noticeable and is approximately 70%. In this case, one operation is performed: a double converted to an int 20 million times. The result with the clamp option will be more productive than with our function. Test
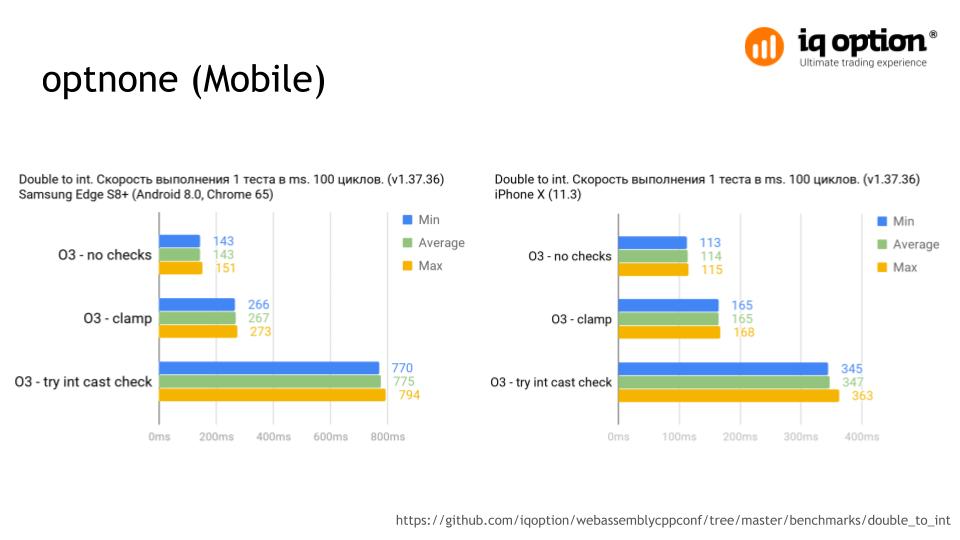
On mobile devices, using the value validation feature all the time also reduces performance. The same test. The gap is well marked on Android, more than 80% and 70% on iOS. These are quite critical results for using the function. Accordingly, it is better to use it only in cases where it is really necessary.
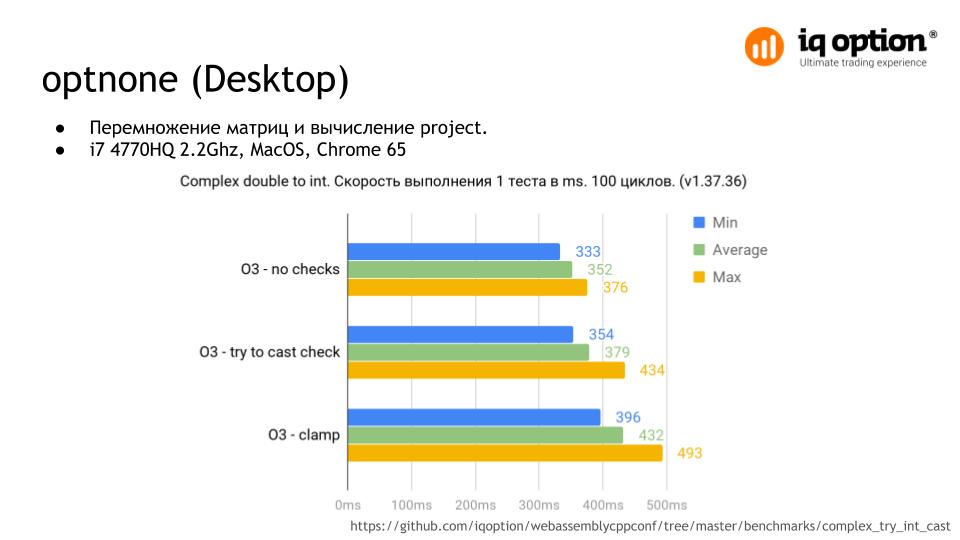
We know that in most conversions, float to integer in our program cannot go beyond certain limits. These values can be checked during float or they are initially restricted to incoming data. That use of the clamp mode will be redundant, it is enough to check only the part where there is a risk of going beyond the boundaries of the integer type.
In the next test , matrices are multiplied and points are projected onto a plane. The test result is the truncation of nine values and one of them is checked by a function. As you can see, this option already gives a performance boost of about 15% compared to clamp . But the difference is not so clearly visible on the desktop.
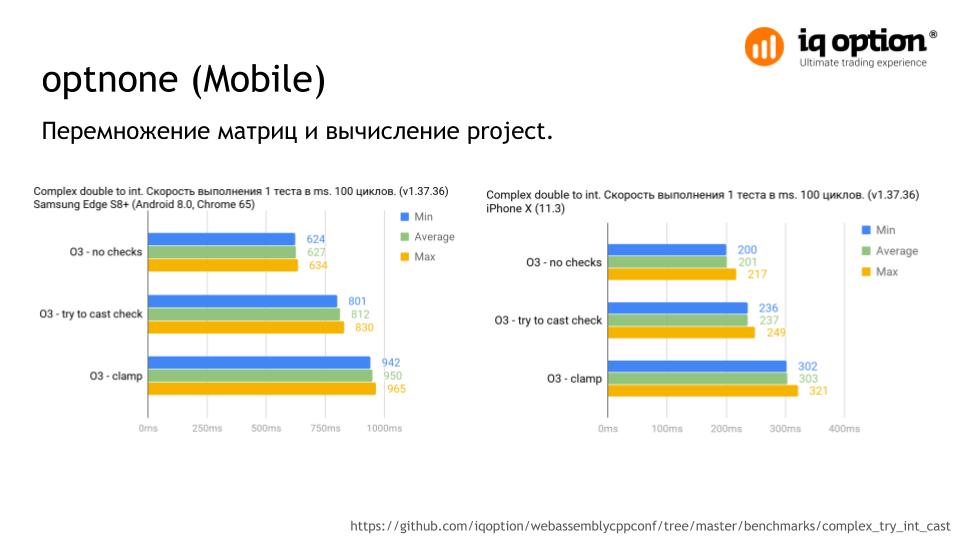
On mobile devices, the result is more noticeable. Compared to clamp , Android and iOS show a little more than 20% growth.
It all depends on the application and its performance, in our case the option with the function that checks the values turned out to be preferable. However, currently the clamp mode has become more optimized. If we were switching to WebAssembly now, we would use it, since the difference in our application is not noticeable now.
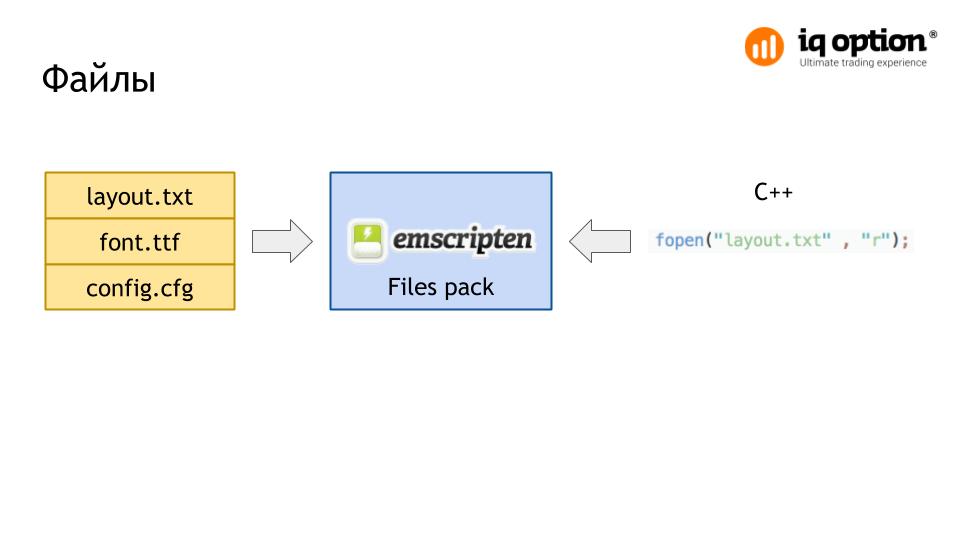
Another problem we are facing is reading data from files. Emscripten allows you to work with files from C ++ as well as with regular files. For this, a file package is created, and then it is mounted in JavaScript. In the course of our application, new elements are often created, which are loaded from files as necessary. At some point, the data from these files became invalid.

By default, after loading the data file, the data is copied to the heap, and then a pointer to this area is used. Placing in the heap increases the speed of access to files, but when memory is relocated (if the ALLOW_MEMORY_GROWTH option is ALLOW_MEMORY_GROWTH ), the pointer will become ALLOW_MEMORY_GROWTH , therefore all we read further from the files is some sort of garbage.
At that time (version v1.37.17), this was already a known problem. Solution: do not use heap for the file system. In this case, the object from xhr response will be used directly, that is, the runtime will simply receive a pointer to the already existing buffer without copying it into the heap. At the moment, in the current version of the toolchain, the no-heap-copy flag will be automatically specified if the ALLOW_MEMORY_GROWTH option is ALLOW_MEMORY_GROWTH .
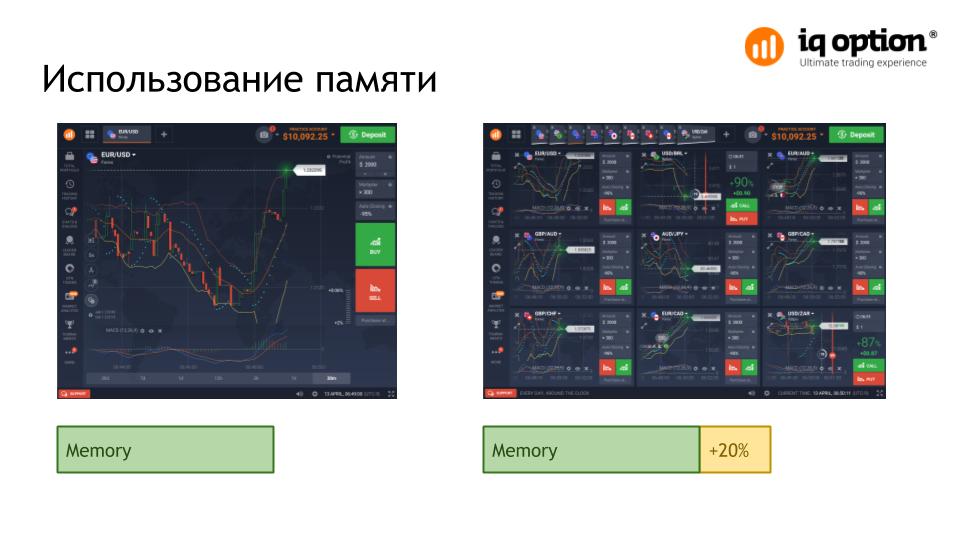
You can build on the fact that the application will not consume more than a certain amount of memory, but when working with large amounts of data, it causes difficulties and in most cases a waste of memory.
In our case, all elements of the application are created dynamically as needed, for example, the user can simultaneously open up to 9 graphs, which in real time receive quotes. But usually 1-2 graphics are used and at the start of the application this amount of memory is not used.
Having demanded more memory at the start, you risk not starting up on mobile devices. The mobile browser when compiling will throw an exception with out of memory .

What we came to and what conclusions made. The technology continues to evolve, updates with fixes and improvements for the compiler come out periodically. It is also possible to conduct a dialogue with developers on GitHub, which allows you to quickly find solutions to emerging problems.
The problem with truncate remains unresolved and it is not known when they will fix it. The used solutions to this problem currently can significantly slow down the application.
You will have to write in JavaScript since there are no other possibilities for interacting with system APIs, or use ready-made wrappers.
Debugging wasm in a browser is very difficult if you do not have a desktop version. This can make development very difficult. Some updates to the toolchain make changes that break the application.
The situation with iOS is incomprehensible. WebAssembly was supported in Safari, but subsequent updates broke and repaired WebAssembly. It saves the fact that currently Safari strongly optimized the execution of asm.js and it began to run much faster. Therefore, while using it as the main version on the iPhone.

The technology is quite alive and implemented at a sufficient level for its use in the finished project. The main plus for us is a tangible increase in performance on mobile and "weak" devices. At the moment we have been using WebAssembly since September 2017.
Separately, I would like to thank Sergey Platonov sermp , for organizing the conference.
')
Source: https://habr.com/ru/post/354690/
All Articles