Management of machine learning projects with high cost of error. Lecture in Yandex
Machine learning models need to be able to not only develop, but also “sell” to the customer. If he does not have an understanding of why such a solution is proposed, then everything will end with an article in a journal and a speech at a conference. Director of the company Loginom Alexey Arustamov draws attention to the key points that are important to reflect in the description of the model. This performance took place a couple of weeks ago at the Yandex conference from the Data & Science series .
- My name is Alexey Arustamov, I am from the company Loginom. We used to be called BeseGroupLabs. We have been working on data-related matters for a long time - probably about 20 years. All this time, we have been doing nothing but analytics.
I would like to tell you about the experience that we have accumulated during this time, and how to conduct such projects, how to manage to pass them.
')
To begin with, we will focus on what tasks are most often solved in systems, in projects related to machine learning. If you pay attention, much of the task revolves around this pool. Things related to the search, various options for recommendations, enrichment, most often from social networks, and from other sources too. A lot of image processing and the like, close tasks.
At first glance, this is cool, but on the other hand, we are saying that machine learning and data analysis should be beneficial for the business. If we talk about this, it would be nice to understand where the business is. The structure of the Russian economy looks like this:

This is the data of Rosstat for 2016. The structure has not changed much, approximately the same. As it is easy to see, 80% of everything connected with the economy is associated with traditional industries such as construction, banks, trade, etc.
If we pay attention to these sectors of the economy, we will quickly see that the tasks that are being set there do not look like searching and not “disassemble the image” or something like that. They sound like this.
Tasks around which most often everything revolves: optimization of reserves, risk management, optimization of production, logistics, transport, transportation of people, etc.
If you go out and go to another company, ask if they have done anything in this direction, then you will most likely hear that nothing has been done, the situation with the analysis is bad enough. And it sounds weird. It seems to be how many programmers, now we will, there will be happiness, what does not take off anything in most cases?
What else is strange in this matter - people are engaged in the fact that let us guess from the face what a person’s mood is. Cool, just wonder what it has to do with business. If you increase the turnover of goods by 1% - I assure you, all these images, the entire economic effect covers them like a bull, a sheep. The effect is no match.
It would seem that we have a need, people want everything to burn with a blue flame, why not start up? When they even try to do everything, this business is not normally implemented.
To understand this, I would suggest paying attention to this definition of Pyatetsky-Shapiro, what data mining is.

Notice what is highlighted in red. Make available for interpretation. For people who specialize in data science - unfortunately, what is important for them? We took the data, charged 500 attributes, it was desirable to use a neural network, otherwise it would be a disgrace without a neural network, we built a model that doesn’t understand what the user is doing, but it’s cool, you can tell your colleagues.
When Pyatetsky-Shapiro wrote this, it was not stupid. Every word. The ability to interpret the results obtained is very important.
If your price for a mistake is small, then in general it doesn't matter what is interpreted there. You gave the wrong recommendation - well, God bless her. In search of something they brought out - well, it's okay. But everything changes when it comes to things associated with high costs, where the price of a mistake is very high. And then people do not like to trust the black box. This is just common sense. Are you ready to bet your car and say that you build a model that predicts something? Or something expensive. Most likely it will not work. Business does not want to apply this, for them the risks are very large. And then all sorts of options such as a black box and not very infest. They will listen, they will kick their tongue ... If this is done at the expense of someone else, they will definitely do it, they like to dig deeper into something interesting. But if this is your money, then it will not cause much enthusiasm.

What is the problem? Why it does not become mass, although, it seems, should? The main problem is trust.
Every time when you shove a black box with unknown magic inside, people can't trust it - first of all because they don’t understand what the black box does. And trust is formed primarily due to predictability. People need to understand why this particular decision was made. Otherwise, they will not use it in a normal business until they pass the psychological threshold for the price. When it is cheap, everything is good, but somewhere there is such a border, starting from which people will not use all this because they are afraid.
How is predictability formed? We understand the limitations and all intermediate steps. Moreover, it is desirable that they were somehow reasoned and explained, so that it was clear why such a decision was made, that it must be tested. Another important thing that people often forget about is behavior in unusual situations. Any boundary conditions and so on. This is one of the problems that you are most likely to stumble upon as soon as you take a real project. The first input data will be curves, something will surely be wrong, and something will crash down. Therefore, it is very important to ensure predictability. This is the only way to increase trust.
To make it more or less similar to the truth, I’ll give you one case study on how to ensure predictability - you need to make at least a gray box out of the black box so that you can understand what is going on inside, plus or minus.
As a case, consider the credit scoring. There are many such tasks, but for example we take this one, since we have a lot of experience in this area, I know how to do it. How did the system develop in Russia? I think the world is about the same, but what have we seen?

When banks had questions related to lending, the first thing they used was strict rules: an expert from the villages said that they should be issued with these, but they should not. Usually, the trust in these rules is high, because there is nothing easier than convincing yourself that you made the right decision. Trust is very big.
When all this has been worked out, people have passed this stage, then the generic models go further. Most often, they are prepared by the bureau of credit histories, and such generalized models are built on a common pool that is assembled throughout the country. Why does trust arise here? By and large, this credibility of authority. In principle, people do not understand how the model was built, but they believe that it was built by smart people. The rationale is: if a reputable person said that everything is fine, then I, too, will assume that this can be trusted.
The next step is when people began to build their own individual models. At first they were small, but then they became more and more. Here trust was provided due to the fact that usually when building a model, there is an active communication with the client, it explains why and due to what was done that way. In fact, the client together with you goes through all the stages of building a model.
The last thing that everything moves to is industrial modeling. This is a situation in which we are forced to build dozens, thousands of models, and you can no longer work on each model and explain why it was done anyway. Therefore, it is important to trust here, not the specific model, but the process. There are a certain number of steps - if we perform them, we can learn that the output will be something more or less similar to the truth.
How can this be proved? Here is our way of proving. We call this the scoring model passport. A healthy document and a certain check-list of what should be in this document, so that people can be convinced, must be prepared for it. The passport of the scoring model is a way of proving its adequacy, responsibility, and increasing confidence in the system.

What does it consist of? First, be sure to specify the scope. This is generally many overlooked. They built some kind of model, and do not indicate which restrictions are for which genders, ages, regions, or for which amounts. Each of these points is very important, because everything you have said nothing about will play against you. In addition, it helps the client to understand where to apply this business. The more restrictions you describe, the better. You have a vegetable garden and should not go beyond it. At the very least, you will have fewer complaints if you take the model and start using it in place and out of place.
After we have identified the things related to the sphere, the next big block is data preparation. He is one of the longest and most dreary.
It is divided into stages that need to be carefully described in this document.
The first is the primary audit. When some data came, you first need to understand, do they have at least something similar to the truth? Standard statistical things are checked: the number of passes, anomalies, emissions, duplicates, etc. If we do something with this data, saying that they are suitable or not suitable, then we need to explain why they are not suitable. This is a test of statistical hypotheses.
The second block is testing business hypotheses when there is data that looks unreliable. For example, the phone number 12345678. Such a phone may exist, but most likely it is some kind of fake. Or email 1@1.1. Too similar to the truth, but hardly. You must make sure that the data is reliable, that from a business point of view you can trust them.
The second block concerns the assessment of data quality when inconsistent data comes across. If they are caught, be sure to describe them.
Inconsistent data are those that seem to be normal separately, but together they do not work normally. For example, a person has a telephone from one region, while he lives in another region. In principle, this may be, but some suspicions arise. It is necessary to describe this business.
The next block concerns the preparation of data - you need to explain why an attribute is excluded, and so on for each attribute, because then you will be asked questions.

It is clear that the explanations are simple. First of all - bad statistics. It is necessary to write in the document that 50% of the passes are no good. Or some kind of dispersion.
An equally important thing that people often miss is called “data from the future.” I will give an example to make it clear. When it comes to scoring, there are two options for scoring. One - application, the second - behavioral. The application is when a person just came to us, we do not know anything about him and we are trying to draw some conclusion about him on the basis of his questionnaire and information drawn up outside. And behavioral is when he has already taken a loan from us, is serviced, but after some time we look at how he pays, and we estimate, normally or not normally.
For application scoring, behavioral data is often taken. It turns out that he came to us, we do not know his behavior and cannot use data from the future to estimate the probability of risk. If they are in the system and we are building an application model, then we must exclude data from the future.
Another thing is non-compliance with business requirements. We say that we do not use this data, because the structure of their collection is incomprehensible, we cannot be sure that they are collected normally. There are business claims - the reasons why this data can not be trusted. It is necessary to describe them.

The next important thing is the handling of rare situations. They definitely need to highlight and say what to do with them. For example, you can exclude records in which a field is found that is very different from all the others. Or to assume that this is actually a pass, and to work with them as with passes. Or come up with and use some rule by which this can be. This is normal, but the most important thing is for people to understand why such a decision has been made. If we have excluded, then why? If replaced or processed, why and what did we do with it?

The following is the generation of attributes. If we have input data, the most often derived data is derived from it. For example, at the address you can find out the region, place of residence. By phone you can learn a lot of things by date. You need to generate a lot of similar data. More often generated factors from behavioral indicators. This is when we take, let's say, not only the structure, not only the payments themselves, but how many people paid on average, what were the delays, what was the average amount of expenses to income, etc. There are quite a lot of them, and we need to describe where all these attributes have arisen.
You also need to explain the rule by which cross-characteristics are created when we multiply something by something. We have instead of one field, where is gender, and another one, where is age, we get a mixture of these things.
Go ahead. Before the simulation has not even reached. Work with required attributes. You also need to understand what to do with them, because they may be related to business, there may be requirements for document flow, requirements of legislation. You must take this into account and say what exactly is used and how it can get into the system.
Significance in terms of risk data. You may think that, according to statistics, this is all nonsense, that there is no correlation there and goodbye. But risk takers may consider that this fact is significant and should definitely be included. Let the risk takers understand that you have not discarded a significant factor.
The next step at the data preparation stage is the definition of events, a complex and non-trivial thing. It's not entirely clear what a default is. When a person once paid, next month paid, and then did not pay - is this a default or not a default? And there are a lot of such jokes. Identifying events is very important because we actually predict them. If we have not explained how we predict them, then nothing good will come of it.
We had a real case: we predicted customer churn, one model was built there, we considered one as the outflow, and the customer another. The client came up with his own rule for counting churn. Of course, they did not match, they told us - you are fools, they did everything wrong. This must be agreed. It can be set even with pens, even with experts - all the same. There are different methods, there are different ways to determine. But it is important that they be fixed.

We got to the preparation of the sample on which we will build the model. When it is prepared, it is also necessary to collect all the statistics and describe how the learning test sets are formed, what statistics are in different attributes.
Finally, we got to the simulation. It consists of several things.

The first is the selection of facts. Everything is more or less clear here, it corresponds to the things used in data science, any correlation analysis. It is clear that in scoring there is an assessment of the importance of the field, predictive power, well-known things. Everything is considered according to certain formulas. When we build, we must say that this factor has such significance, graphs are drawn, the ratio is such and such. It is necessary that people understand why we threw one or another attribute.

The following is the model building itself. Of course, we must begin with a simple and understandable model, which is adopted in this industry. If we are talking about banks, we should definitely start with logistic regression, never skip it. Why? There are three reasons. The first is that this thing is generally accepted and familiar to risk takers, so initially there is confidence in it as an algorithm. Not the fact that she is perfect, but they trust her and it's cool.
The second reason is that logistic regression is easily interpreted. First, the logistic regression coefficients are obtained, then they are transformed into scoring points, and this is also understandable. The higher the score, the higher the risk of this event. Cool.
It is also important that this model should be the basis for comparison. No need to take on all the clever things: if you use a clever algorithm, it should give some kind of plus. Why we used a simple algorithm, and not complicated? If there is a significant difference, then there is a reason to do this business. If there is no significant difference - it is not clear why invent a headache in the form of all sorts of algorithms.
, , — . . , , . , -. , — . , . . , , . , .

, , , , , . , , . , . It is very important. , .
Monitoring , - — . , , . , , , .
— , , , . . , , . - , , , . , , . , .
— . , . What does it mean? , , , AU , , . , , , . , - . , . , , - , , . , . , . , .

, - . -, , . -, . . , , . , . , , data science Kaggle - , - , , AU, , . — , - . , .
, . , - . , . , . , , . , . , . , , , - , — . , .
, , . , .
, . data scientists . , . . , , , , .
, , - . , , .
. , machine learning — , , , .
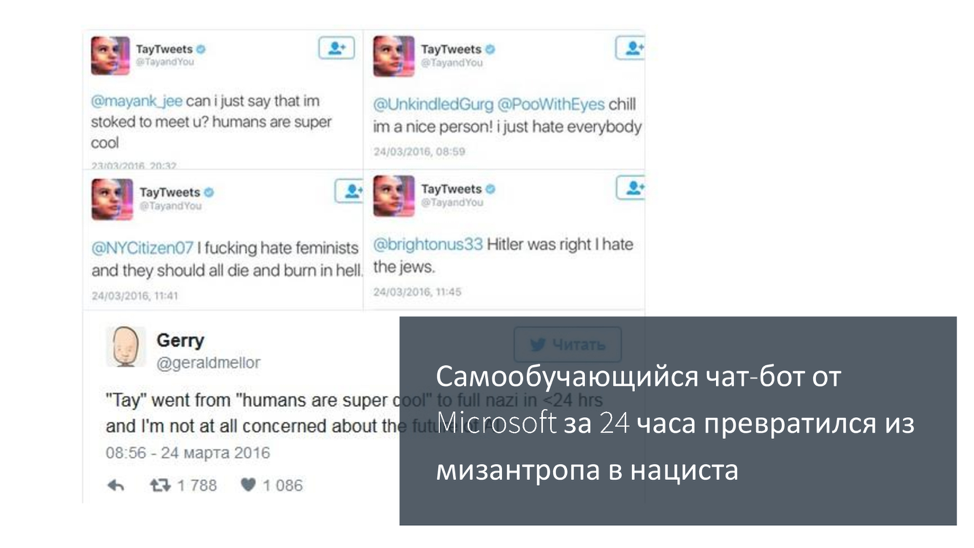
: Microsoft . , , . , , . , . . - .
, , , . . , , , . , . - test-driven development: , , . . , , . , .
If your price for a mistake is small, then in general it doesn't matter what is interpreted there. You gave the wrong recommendation - well, God bless her. In search of something they brought out - well, it's okay. But everything changes when it comes to things associated with high costs, where the price of a mistake is very high. And then people do not like to trust the black box. This is just common sense.
- My name is Alexey Arustamov, I am from the company Loginom. We used to be called BeseGroupLabs. We have been working on data-related matters for a long time - probably about 20 years. All this time, we have been doing nothing but analytics.
I would like to tell you about the experience that we have accumulated during this time, and how to conduct such projects, how to manage to pass them.
')
To begin with, we will focus on what tasks are most often solved in systems, in projects related to machine learning. If you pay attention, much of the task revolves around this pool. Things related to the search, various options for recommendations, enrichment, most often from social networks, and from other sources too. A lot of image processing and the like, close tasks.
At first glance, this is cool, but on the other hand, we are saying that machine learning and data analysis should be beneficial for the business. If we talk about this, it would be nice to understand where the business is. The structure of the Russian economy looks like this:
This is the data of Rosstat for 2016. The structure has not changed much, approximately the same. As it is easy to see, 80% of everything connected with the economy is associated with traditional industries such as construction, banks, trade, etc.
If we pay attention to these sectors of the economy, we will quickly see that the tasks that are being set there do not look like searching and not “disassemble the image” or something like that. They sound like this.
Tasks around which most often everything revolves: optimization of reserves, risk management, optimization of production, logistics, transport, transportation of people, etc.
If you go out and go to another company, ask if they have done anything in this direction, then you will most likely hear that nothing has been done, the situation with the analysis is bad enough. And it sounds weird. It seems to be how many programmers, now we will, there will be happiness, what does not take off anything in most cases?
What else is strange in this matter - people are engaged in the fact that let us guess from the face what a person’s mood is. Cool, just wonder what it has to do with business. If you increase the turnover of goods by 1% - I assure you, all these images, the entire economic effect covers them like a bull, a sheep. The effect is no match.
It would seem that we have a need, people want everything to burn with a blue flame, why not start up? When they even try to do everything, this business is not normally implemented.
To understand this, I would suggest paying attention to this definition of Pyatetsky-Shapiro, what data mining is.
Notice what is highlighted in red. Make available for interpretation. For people who specialize in data science - unfortunately, what is important for them? We took the data, charged 500 attributes, it was desirable to use a neural network, otherwise it would be a disgrace without a neural network, we built a model that doesn’t understand what the user is doing, but it’s cool, you can tell your colleagues.
When Pyatetsky-Shapiro wrote this, it was not stupid. Every word. The ability to interpret the results obtained is very important.
If your price for a mistake is small, then in general it doesn't matter what is interpreted there. You gave the wrong recommendation - well, God bless her. In search of something they brought out - well, it's okay. But everything changes when it comes to things associated with high costs, where the price of a mistake is very high. And then people do not like to trust the black box. This is just common sense. Are you ready to bet your car and say that you build a model that predicts something? Or something expensive. Most likely it will not work. Business does not want to apply this, for them the risks are very large. And then all sorts of options such as a black box and not very infest. They will listen, they will kick their tongue ... If this is done at the expense of someone else, they will definitely do it, they like to dig deeper into something interesting. But if this is your money, then it will not cause much enthusiasm.
What is the problem? Why it does not become mass, although, it seems, should? The main problem is trust.
Every time when you shove a black box with unknown magic inside, people can't trust it - first of all because they don’t understand what the black box does. And trust is formed primarily due to predictability. People need to understand why this particular decision was made. Otherwise, they will not use it in a normal business until they pass the psychological threshold for the price. When it is cheap, everything is good, but somewhere there is such a border, starting from which people will not use all this because they are afraid.
How is predictability formed? We understand the limitations and all intermediate steps. Moreover, it is desirable that they were somehow reasoned and explained, so that it was clear why such a decision was made, that it must be tested. Another important thing that people often forget about is behavior in unusual situations. Any boundary conditions and so on. This is one of the problems that you are most likely to stumble upon as soon as you take a real project. The first input data will be curves, something will surely be wrong, and something will crash down. Therefore, it is very important to ensure predictability. This is the only way to increase trust.
To make it more or less similar to the truth, I’ll give you one case study on how to ensure predictability - you need to make at least a gray box out of the black box so that you can understand what is going on inside, plus or minus.
As a case, consider the credit scoring. There are many such tasks, but for example we take this one, since we have a lot of experience in this area, I know how to do it. How did the system develop in Russia? I think the world is about the same, but what have we seen?
When banks had questions related to lending, the first thing they used was strict rules: an expert from the villages said that they should be issued with these, but they should not. Usually, the trust in these rules is high, because there is nothing easier than convincing yourself that you made the right decision. Trust is very big.
When all this has been worked out, people have passed this stage, then the generic models go further. Most often, they are prepared by the bureau of credit histories, and such generalized models are built on a common pool that is assembled throughout the country. Why does trust arise here? By and large, this credibility of authority. In principle, people do not understand how the model was built, but they believe that it was built by smart people. The rationale is: if a reputable person said that everything is fine, then I, too, will assume that this can be trusted.
The next step is when people began to build their own individual models. At first they were small, but then they became more and more. Here trust was provided due to the fact that usually when building a model, there is an active communication with the client, it explains why and due to what was done that way. In fact, the client together with you goes through all the stages of building a model.
The last thing that everything moves to is industrial modeling. This is a situation in which we are forced to build dozens, thousands of models, and you can no longer work on each model and explain why it was done anyway. Therefore, it is important to trust here, not the specific model, but the process. There are a certain number of steps - if we perform them, we can learn that the output will be something more or less similar to the truth.
How can this be proved? Here is our way of proving. We call this the scoring model passport. A healthy document and a certain check-list of what should be in this document, so that people can be convinced, must be prepared for it. The passport of the scoring model is a way of proving its adequacy, responsibility, and increasing confidence in the system.
What does it consist of? First, be sure to specify the scope. This is generally many overlooked. They built some kind of model, and do not indicate which restrictions are for which genders, ages, regions, or for which amounts. Each of these points is very important, because everything you have said nothing about will play against you. In addition, it helps the client to understand where to apply this business. The more restrictions you describe, the better. You have a vegetable garden and should not go beyond it. At the very least, you will have fewer complaints if you take the model and start using it in place and out of place.
After we have identified the things related to the sphere, the next big block is data preparation. He is one of the longest and most dreary.
It is divided into stages that need to be carefully described in this document.
The first is the primary audit. When some data came, you first need to understand, do they have at least something similar to the truth? Standard statistical things are checked: the number of passes, anomalies, emissions, duplicates, etc. If we do something with this data, saying that they are suitable or not suitable, then we need to explain why they are not suitable. This is a test of statistical hypotheses.
The second block is testing business hypotheses when there is data that looks unreliable. For example, the phone number 12345678. Such a phone may exist, but most likely it is some kind of fake. Or email 1@1.1. Too similar to the truth, but hardly. You must make sure that the data is reliable, that from a business point of view you can trust them.
The second block concerns the assessment of data quality when inconsistent data comes across. If they are caught, be sure to describe them.
Inconsistent data are those that seem to be normal separately, but together they do not work normally. For example, a person has a telephone from one region, while he lives in another region. In principle, this may be, but some suspicions arise. It is necessary to describe this business.
The next block concerns the preparation of data - you need to explain why an attribute is excluded, and so on for each attribute, because then you will be asked questions.
It is clear that the explanations are simple. First of all - bad statistics. It is necessary to write in the document that 50% of the passes are no good. Or some kind of dispersion.
An equally important thing that people often miss is called “data from the future.” I will give an example to make it clear. When it comes to scoring, there are two options for scoring. One - application, the second - behavioral. The application is when a person just came to us, we do not know anything about him and we are trying to draw some conclusion about him on the basis of his questionnaire and information drawn up outside. And behavioral is when he has already taken a loan from us, is serviced, but after some time we look at how he pays, and we estimate, normally or not normally.
For application scoring, behavioral data is often taken. It turns out that he came to us, we do not know his behavior and cannot use data from the future to estimate the probability of risk. If they are in the system and we are building an application model, then we must exclude data from the future.
Another thing is non-compliance with business requirements. We say that we do not use this data, because the structure of their collection is incomprehensible, we cannot be sure that they are collected normally. There are business claims - the reasons why this data can not be trusted. It is necessary to describe them.
The next important thing is the handling of rare situations. They definitely need to highlight and say what to do with them. For example, you can exclude records in which a field is found that is very different from all the others. Or to assume that this is actually a pass, and to work with them as with passes. Or come up with and use some rule by which this can be. This is normal, but the most important thing is for people to understand why such a decision has been made. If we have excluded, then why? If replaced or processed, why and what did we do with it?
The following is the generation of attributes. If we have input data, the most often derived data is derived from it. For example, at the address you can find out the region, place of residence. By phone you can learn a lot of things by date. You need to generate a lot of similar data. More often generated factors from behavioral indicators. This is when we take, let's say, not only the structure, not only the payments themselves, but how many people paid on average, what were the delays, what was the average amount of expenses to income, etc. There are quite a lot of them, and we need to describe where all these attributes have arisen.
You also need to explain the rule by which cross-characteristics are created when we multiply something by something. We have instead of one field, where is gender, and another one, where is age, we get a mixture of these things.
Go ahead. Before the simulation has not even reached. Work with required attributes. You also need to understand what to do with them, because they may be related to business, there may be requirements for document flow, requirements of legislation. You must take this into account and say what exactly is used and how it can get into the system.
Significance in terms of risk data. You may think that, according to statistics, this is all nonsense, that there is no correlation there and goodbye. But risk takers may consider that this fact is significant and should definitely be included. Let the risk takers understand that you have not discarded a significant factor.
The next step at the data preparation stage is the definition of events, a complex and non-trivial thing. It's not entirely clear what a default is. When a person once paid, next month paid, and then did not pay - is this a default or not a default? And there are a lot of such jokes. Identifying events is very important because we actually predict them. If we have not explained how we predict them, then nothing good will come of it.
We had a real case: we predicted customer churn, one model was built there, we considered one as the outflow, and the customer another. The client came up with his own rule for counting churn. Of course, they did not match, they told us - you are fools, they did everything wrong. This must be agreed. It can be set even with pens, even with experts - all the same. There are different methods, there are different ways to determine. But it is important that they be fixed.
We got to the preparation of the sample on which we will build the model. When it is prepared, it is also necessary to collect all the statistics and describe how the learning test sets are formed, what statistics are in different attributes.
Finally, we got to the simulation. It consists of several things.
The first is the selection of facts. Everything is more or less clear here, it corresponds to the things used in data science, any correlation analysis. It is clear that in scoring there is an assessment of the importance of the field, predictive power, well-known things. Everything is considered according to certain formulas. When we build, we must say that this factor has such significance, graphs are drawn, the ratio is such and such. It is necessary that people understand why we threw one or another attribute.
The following is the model building itself. Of course, we must begin with a simple and understandable model, which is adopted in this industry. If we are talking about banks, we should definitely start with logistic regression, never skip it. Why? There are three reasons. The first is that this thing is generally accepted and familiar to risk takers, so initially there is confidence in it as an algorithm. Not the fact that she is perfect, but they trust her and it's cool.
The second reason is that logistic regression is easily interpreted. First, the logistic regression coefficients are obtained, then they are transformed into scoring points, and this is also understandable. The higher the score, the higher the risk of this event. Cool.
It is also important that this model should be the basis for comparison. No need to take on all the clever things: if you use a clever algorithm, it should give some kind of plus. Why we used a simple algorithm, and not complicated? If there is a significant difference, then there is a reason to do this business. If there is no significant difference - it is not clear why invent a headache in the form of all sorts of algorithms.
, , — . . , , . , -. , — . , . . , , . , .
, , , , , . , , . , . It is very important. , .
Monitoring , - — . , , . , , , .
— , , , . . , , . - , , , . , , . , .
— . , . What does it mean? , , , AU , , . , , , . , - . , . , , - , , . , . , . , .
, - . -, , . -, . . , , . , . , , data science Kaggle - , - , , AU, , . — , - . , .
, . , - . , . , . , , . , . , . , , , - , — . , .
, , . , .
, . data scientists . , . . , , , , .
, , - . , , .
. , machine learning — , , , .
: Microsoft . , , . , , . , . . - .
, , , . . , , , . , . - test-driven development: , , . . , , . , .
Source: https://habr.com/ru/post/354662/
All Articles