Comparing Google TPUv2 and Nvidia V100 on ResNet-50

Recently, Google has added the Tensor Processing Unit v2 (TPUv2) to the list of cloud services — a processor specifically designed to accelerate deep learning. This is the second generation of the world's first publicly available deep learning accelerator, which claims to be an alternative to Nvidia GPUs. Recently, we talked about first impressions . Many have asked for a more detailed comparison with Nvidia V100 graphics processors.
Objectively and meaningfully comparing the accelerators of deep learning is not a trivial task. But because of the future importance of this category of products and the lack of detailed comparisons, we felt the need to conduct independent tests. This includes taking into account the views of potentially opposing sides. That's why we contacted Google and Nvidia engineers - and invited them to comment on the draft of this article. To guarantee the absence of bias, we also invited independent experts. Due to this, as far as we know, the most complete to date comparison of TPUv2 and V100 has turned out.
Experimental setup
Below are compared four TPUv2 (which form one Cloud TPU) with four Nvidia V100. Both have a full memory of 64 GB, so they can be taught the same models with the same size of the training sample. In the experiments, we teach models in the same way: four TPUv2 in Cloud TPU and four V100s perform the task of simultaneous distributed distributed learning.
')
As a model, we chose ResNet-50 on ImageNet , the de facto standard and benchmark for image classification. ResNet-50 benchmark implementations are publicly available, but none of them support learning simultaneously on Cloud TPU and on several GPUs.
Nvidia recommends using MXNet for multiple V100s or TensorFlow implementations that are available as Docker images on the Nvidia GPU Cloud . Unfortunately, it turned out that both implementations do not agree well with the default settings when working on several GPUs with large training samples. It is necessary to make changes, in particular, in the learning rate (learning rate schedule).
Instead, we took the implementation of ResNet-50 from the TensorFlow benchmark repository and launched it as a Docker image (tensorflow / tensorflow: 1.7.0-gpu, CUDA 9.0, CuDNN 7.1.2). It is significantly faster than the Nvidia recommended TensorFlow implementation and is only slightly inferior (by about 3%, see below) to the MXNet implementation. But it fits well. In addition, there is an additional advantage that we compare two implementations on the same version of the framework (TensorFlow 1.7.0).
Google recommends using the Cloud TPU implementation of bfloat16 with TensorFlow 1.7.0 from the official TPU repository. In both implementations, TPU and GPU, mixed precision calculations are used on the appropriate architecture, and most tensors are stored in half-precision numbers.
The V100 tests were run on the p3.8xlarge instance (16 Xeon E5-2686@2.30GHz cores, 244 GB of memory, Ubuntu 16.04) on AWS with four V100 GPUs (each with 16 GB of memory). The TPU tests were run on a small n1-standard-4 instance (2 Xeon@2.3GHz cores, 15 GB of memory, Debian 9), for which Cloud TPU (v2–8) of four TPUv2 (each with 16 GB of memory) was allocated.
We made two different comparisons. First, we studied the performance in terms of bandwidth (images per second) on synthetic data without augmentation, that is, without creating additional training data from the available data. This comparison is independent of convergence, there are no I / O bottlenecks, and augmentation of data does not affect the result. The second comparison examined the accuracy and convergence of the two implementations on ImageNet.
Bandwidth test
We measured the bandwidth by the number of images per second on synthetic data , that is, with the creation of data for learning on the fly, with different sample sizes (batch size). Note that only sample size of 1024 is recommended for TPU, but according to numerous requests from readers, we report the rest of the results.

Performance (images per second) on different sample sizes on synthetic data and without augmentation. The sample sizes are “global”, that is, 1024 means the size 256 on each of the GPU / TPU chips at each step
With a training sample size of 1024, there is practically no difference in throughput! TPU is only slightly ahead with a difference of about 2%. On smaller training samples, bandwidth drops on both platforms, and GPUs work a little better. But as mentioned above, such training sample sizes are currently not recommended for TPU.
Following the recommendations of Nvidia, we conducted an experiment with a GPU on MXNet . The ResNet-50 implementation was used in the Docker image ( mxnet: 18.03-py3 ), available on the Nvidia GPU Cloud . With a training sample size of 768 (1024 too many), the GPU processes about 3280 images per second . This is about 3% faster than the best result for TPU. But as mentioned above, the MXNet implementation does not converge very well on several GPUs with this size of the training sample, so here and below we will focus on the implementation of TensorFlow.
Cost in the cloud
Cloud TPU (four TPUv2 chips) is currently available only in the Google cloud. It connects on request to any VM instance only when such calculations are required. For V100, we looked at a cloud solution from AWS (V100 is not yet available in the Google cloud). Based on the results above, we can normalize the number of images per second per dollar for each platform and provider.
Performance: images per second per dollar
| Cloud TPU | 4 × V100 | 4 × V100 | |
|---|---|---|---|
| Cloud | Google cloud | AWS | Reserved AWS Instance |
| Price per hour | $ 6.7 | $ 12.2 | $ 8.4 |
| Images per second | 3186 | 3128 | 3128 |
| Performance (images per second per dollar) | 476 | 256 | 374 |
With such prices Cloud TPU comes out a clear winner. However, the situation may look different if you are considering renting for a longer period or purchasing equipment (although this option is currently not available for Cloud TPU). The table above also includes the price of the p3.8xlarge reserved instance on AWS when renting for 12 months (without prepayment). This significantly improves performance per dollar up to 374 images / s per $ 1.
For the GPU, there are other interesting options. For example, Cirrascale offers a monthly server rental with four V100 for about $ 7,500 (about ~ $ 10.3 per hour). But for direct comparison, additional tests are required, since this equipment differs from the equipment on AWS (type of CPU, memory, support for NVLink, etc.).
Accuracy and convergence
In addition to the performance reports, we wanted to check that the calculations are actually “meaningful”, that is, the implementations converge to good results. Since two different implementations were compared, some deviation can be expected. Therefore, our comparison is not only an indicator of the speed of the equipment, but also the quality of implementation. For example, implementing a TPU involves very resource-intensive preprocessing steps and actually sacrifices bandwidth. According to Google, this is the expected behavior. As we will see below, it is justified.
We trained models on the ImageNet data set , where the challenge is to classify the image into one of 1000 categories, such as hummingbirds , burritos, or pizza . The dataset consists of 1.3 million images for learning (~ 142 GB) and 50,000 images for validation (~ 7 GB).
Training goes 90 epochs with a sample size of 1024, after which the results are compared with control data. The implementation of TPU sequentially processes about 2796 images per second , and the implementation of the GPU - about 2839 images per second . This is different from previous throughput results, where we turned off augmentation and used synthetic data to compare the net speed of TPU and GPU.

The accuracy of the top 1 (i.e., for each image, only the prediction with the most confidence is taken into account) of two realizations after 90 epochs
As shown above, the accuracy of the top 1 after 90 epochs for the implementation of TPU by 0.7 percentage points it is better. This may seem insignificant, but it is extremely difficult to achieve improvement at this very high level. Depending on the application, such small improvements can significantly affect the result.
Let's look at the accuracy of the top 1 in different eras during training models.
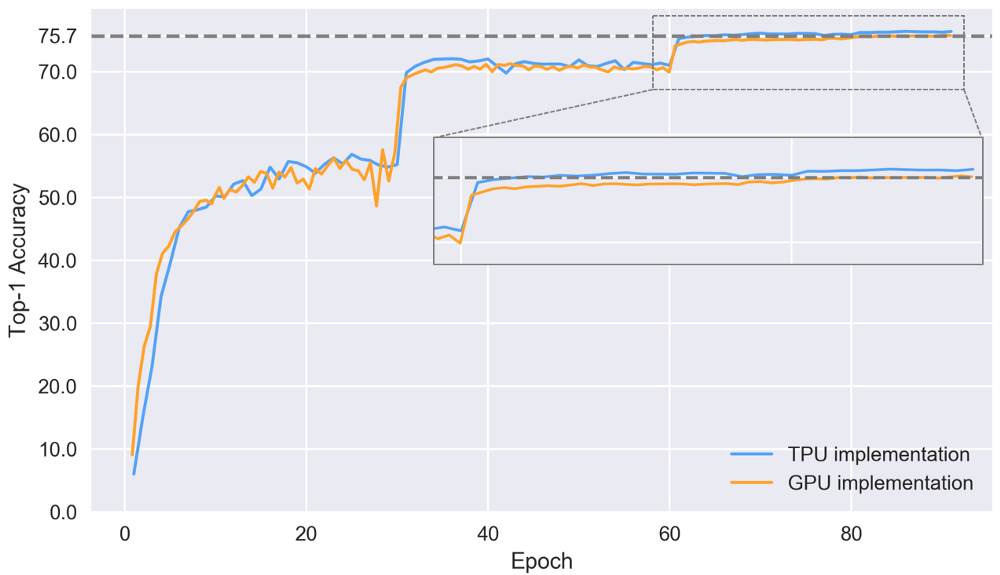
Top-1 accuracy on a control set for two implementations
The dramatic changes in the above graph coincide with changes in learning speed. The trend of convergence is better in the implementation of TPU. Here the final accuracy is reached 76.4% after 86 epochs. The GPU implementation is lagging behind and reaches a final accuracy of 75.7% after 84 epochs, whereas only 64 epochs are required to achieve such accuracy on TPU. The improvement in TPU convergence is likely to be associated with better pre-processing and augmentation of data, but more experiments are needed to confirm this hypothesis.
Cost-effective cloud based solution
Ultimately, time and cost are important to achieve a certain accuracy. If we take the solution at the level of 75.7% (the best accuracy achieved by the implementation of the GPU), then we can calculate the cost of achieving this accuracy based on the required epochs and the speed of learning in images per second. This eliminates the time to evaluate the model in between periods and the time to start training.

Price to achieve accuracy top 75.7%. * Reserved for 12 months
As shown above, Cloud TPU's current pricing policy allows you to train a model from zero to 75.7% accuracy on ImageNet in less than 9 hours for $ 55! Education to the convergence of 76.4% costs $ 73. Although the V100 works just as fast, the higher price and the slower convergence result in a significantly higher solution cost.
Again, note that the comparison depends on the quality of the implementation, as well as on the price of the cloud.
It would be interesting to compare the difference in energy consumption. But currently there is no publicly available information on the energy consumption of TPUv2.
Conclusion
As for the base performance on ResNet-50, the four TPUv2 chips (one Cloud TPU module) and the four V100 graphics processors are equally fast in our tests (a difference of 2%). Probably, due to future software optimizations (for example, TensorFlow or CUDA), performance will improve and the ratio will change.
However, in practice, most often the main thing is the time and financial costs necessary to achieve a certain accuracy on a specific task. The current TPU Cloud pricing, combined with the excellent implementation of the ResNet-50, lead to impressive results in time and cost on ImageNet, which allows training the model to 76.4% accuracy for about $ 73.
For detailed comparison, benchmarks are needed on models from other areas and with different network architectures. It is also interesting to understand how much effort is required to effectively use each hardware platform. For example, calculations with mixed accuracy are accompanied by a significant increase in performance, but are implemented differently on the GPU and TPU.
Source: https://habr.com/ru/post/354602/
All Articles