Accelerating Angular Applications
Many people know Minko Gechev (rhyme.com) from the book “Switching to Angular” and the text “Angular Performance-Checklist”, which helps Angular developers to optimize their projects. At our December conference of HolyJS 2017 Moscow, he also developed the topic of Angular-performance, making a presentation on “Faster Angular applications”. And now, on the basis of this speech, we have prepared a habrapos, translating everything into Russian. Welcome under the cut! And if you prefer an English-language videotape of the speech, we also enclose it:
Today we will talk about performance during execution. In the case of single-page applications, it is usually either network performance or performance in runtime.
In the first case, they usually try to reduce the number of HTTP requests or data transmitted over the network. In this direction there is a lot of research. For example, the Google Closure Compiler team is beating on this, achieving the goal of more efficiently removing unused code and minifying code. We also have various compression algorithms, and the webpack team also sets similar goals. Finally, in Angular CLI they try to combine the best of different approaches and provide very well encapsulated assemblies.
')
However, with regard to performance during execution, the development is a bit. Here everything is in our own hands, there is no third-party "magic wand", by the wave of which our application will work faster. There are several possible approaches to the problem, today I will talk about more general solutions, often applicable not only to Angular.
To illustrate these solutions, I wrote a “simple business application.” In it, I tried to reproduce as many performance problems as possible that I have encountered over the past months. The result was a completely creepy product, which we will try to somehow improve.

In our most simplified application, you can add new employees, present them in the list and calculate some value for them. We will have two lists of employees: for the sales department and for the R & D department. In both, you can add new items. Already existing elements are presented in the list, where you can see the name and some numerical value (suppose, this is an assessment of the employee’s work). There is also a field to enter the name of the new employee. When adding an employee, we can simply take a number from somewhere, calculate something and display everything on the screen.
The application structure consists of an AppComponent (covering the entire application) and two EmployeeListComponent (one for each list).
Here is the EmployeeListComponent template:

Here pay attention to the input element. It uses the banana box syntax (square brackets first, then round brackets) to establish a two-way data binding between the label property declared in the EmployeeListComponent controller and the text field.
In addition, the EmployeeListComponent iterates through the list of employees in the dataset, and a list item is created for each employee. For each item, we display the name of the employee and calculate the numeric value using the calculate () method defined in the EmployeeListComponent class.
Now take a look at this class itself:

There are several important things. To begin with, the state is not stored in it, it receives all the necessary data (Employee [Data] array] on input from the parent component. Thus, this parent component, AppComponent, acts as a Container Component in Redux.
In addition, in the EmployeeListComponent class there is a calculate () method, the only task of which is to transfer the execution of a function that calculates Fibonacci numbers. At first glance, Fibonacci numbers are inconvenient to use here, but they have a number of important advantages. First, the method of calculating them is known to everyone; there is no need to explain the complicated work to a suitable function example. It could be replaced with standard deviation or something else like that.

Secondly, this function can be implemented in an extremely inefficient way, as we see it on the screen. We have two recursive calls, and for each Fibonacci number we will have to recalculate all the previous ones again. Thus, here I artificially slowed down the operation of the application so that the effect of the subsequent optimization could be better seen.
So, we have an application with a component of the application itself, and with two components of lists. Each of the items in the list requires a lot of processing power.
Let's try to use some real data in this application. We will have two lists containing a total of 140 items. In this case, when entering new names, typing is extremely slow. It is unlikely that users might like this application work. But why so slow? Profiling this problem is pretty easy with Chrome DevTools. Having done this, we find out that our function of calculating Fibonacci numbers is called very often. We can find out the exact number of calls by adding logging to this function.

It turns out that each time a user presses a key, the entire component tree is recalculated at least twice (once when pressed and once when the key is released). So we recalculate all the previously received values with each press.
This is what this situation looks like in terms of the component tree. Each time you press a key, a change occurs first in the AppComponent. Because change detection in Angular works like a deep search, it also triggers a change detection in the EmployeeListComponent, and then on each of the employee items. For each of these elements, their numerical value will be recalculated. Then the same bypass of the second EmployeeListComponent will occur.
All this is extremely inefficient. As a rule, we do not want to recalculate the numerical values for each element in the array, we would like this only when a new array appears. Now, if a new array is transferred from the AppComponent to the EmployeeListComponent, then you can calculate. Any thoughts on how best to do this?
For example, you can use the OnPush strategy. Thanks to it, change detection will be launched only when new input data appear on the component. When Angular, when checking references, detects the appearance of new inputs, the components will detect changes. That is, if we have a component tree, when the root component receives new data, we update the entire branch, starting with this component. We'll see how it looks later.
Let us turn to functional programming for help and try to imagine that EmployeeListComponent is a function. The input to the component is the input arguments to the function, and the image on the screen is the result of the function. I will demonstrate my idea with the help of pseudocode.

In the f constant, we save the reference to the EmployeeListComponent (now this is a function), in the data constant, the input arguments (data of one employee).
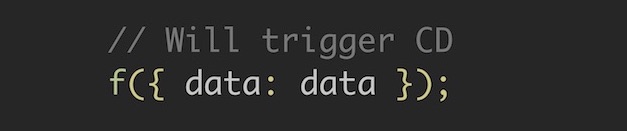
To begin with, we call the function with its initial input, and here Angular will perform the change detection. Since before this the value was undefined, by comparing data and undefined, Angular will see the change in the value of the input data.

But adding a new element to the list will already call a function with the same argument as before: we will modify the data structure pointed to by the same data constant. Therefore, Angular will not start detecting changes.

However, the detection of changes will occur if we send a copy of the array in the input argument of the function: the link will change there.
Does this mean that every time we need to detect changes, we need to copy the entire array? For several reasons, this would be extremely inefficient. First, it would be extremely non-optimal memory usage. For each change detection, we need to first allocate memory for the entire new array, and then the garbage collector will need to free it. Secondly, it is inefficient in terms of computing. The time complexity of this algorithm is at least O (n).
Regarding both of these things, it would be wiser to use something like Immutable.js. This is a set of various immutable data structures with two very important properties.
First, we cannot modify any existing data structure. Instead, calls that would change such a data structure receive a new reference to it with the changes already applied.
Secondly, we do not copy the entire data structure: a new instance of this structure will, if possible, use elements of the old one.
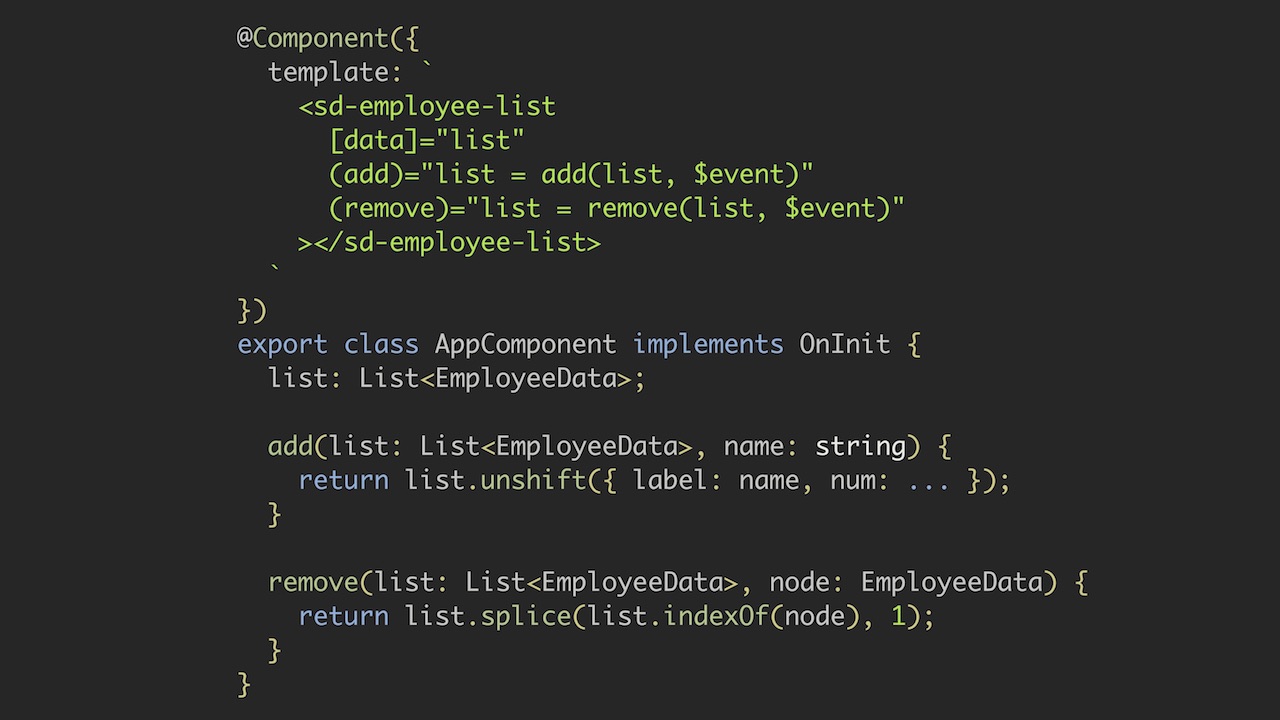
This is the kind of refactoring we need to do. First, we changed the contents of the add () and remove () methods. In add (), when executing the unshift () procedure, in which the element is moved to the top of the list, we get a new list. The same thing in the remove () method, the splice () call returns us a new list.
In addition to these two methods, we need to change the link to the list. Otherwise, we could not notify the EmployeeListComponent that the input data has changed. Thus, the output values add () and remove () must be assigned to the list property in the AppComponent.
Run the application and see how much faster everything is now. We optimized here, it should have been better ... Hmm, the application is still very slow. It may have become faster than before, but still the user’s impressions are unlikely to be good.
To measure how much faster the application began to work, I wrote several end-to-end tests and ran them on Angular Benchpress.

Thanks to them, we see that the application has accelerated the work at least twice. This, however, is not enough. The reason for the unsatisfactory work is that when you enter text, change detection is still triggered. The good news is that now it is launched only in one of the two lists, but even in it it is not needed, since none of the numerical values has changed.
Let's see how the work of the application now looks from the point of view of the component tree. Each time we press a key, we trigger change detection several times in the AppComponent, EmployeeListComponent, and in each of the individual components. However, we do not make calls to the second list. But why change detection occurs at all, because there were no calls to any of the calls that change the data structure of the list?
The reason lies in the specific characteristics of detecting OnPush changes, which are not well documented.

The bottom line is that the detection of OnPush changes is triggered not only when the input data changes, but also when the event is triggered in the corresponding component.
Knowing this feature, we can now refactor the code. This has its positive side, because at the same time we will be able to improve the division of responsibility in our application and make the component tree slimmer. Let's make two child components in the EmployeeListComponent: NameInputComponent and ListComponent.
The first of them will be responsible only for storing the current value of the input line and for triggering the event. In the second, the function will be evaluated, and OnPush change detection will be used there.
After these changes in the code, the application began to work much faster. How exactly does the application work now? Unfortunately, when a user presses a key, change detection is still invoked in the AppComponent, and then in both instances of the EmployeeListComponent. But this time, in the child components of the EmployeeListComponent, change detection is no longer triggered. The fact is that ListComponent uses OnPush change detection, and the event occurs in the EmployeeListComponent area, that is, in the parent component EmployeeList. Print speed increases by several orders of magnitude.

However, this is not enough for us. Another possible optimization concerns the addition of elements. When creating a new item, we call the add operation to the immutable list, so a new list is created and passed to the EmployeeListComponent entry. This causes change detection. That is, when you enter text, everything is now fast, but when you add an element, there is still an unnecessary re-calculation of the numerical value in all these components.
To solve this problem, you need to refer to our function calculating Fibonacci numbers. We have already mentioned pure functions today, and this is one of them. The good news is that pure functions are also found among the things that are really useful in our applications, such as calculating the standard deviation.
Pure functions have two very important properties. First, they have no side effects, that is, no calls are made through the network, no logging occurs, and so on. Secondly, a repeated function call with the same arguments gives an identical result. In the world of functional programming, this is called “pure function”.
And this is a very important concept. In Angular, there are “pure pipes” and “dirty pipes” (impure pipes, i.e., internal state pipes). They are usually used for data processing. Pure pipes usually format the data, an example of “pure” is DatePipe.
Dirty pipes store a certain state inside, such as AsyncPipe. The difference between these two cases is that Angular performs a clean pipe only when it detects that its argument has changed. As a rule, expressions with a clean pipe are considered by Angular as having no side effects, referentially transparent. This is a concept from functional programming to better understand it, take a look at the code created by the Angular compiler for a template with clean and dirty pipes.

We apply a clean date date to the birthday variable, and then a dirty impureDate. The screen shows two different results. At first it is difficult to understand. Mysterious characters at the beginning of the expression do not interest us, they are only needed so that developers do not use these imports.
The important part for us is following them. _ck () is a check, in it the current value of date will be compared with the previous one, and if the value is different, the date.transform () method will be called. If there are no changes, the previous result stored in the cache will be returned. In the case of impureDate, the impureDate.transform () method will simply be called.
Thus, referential transparency means that the semantics of an expression will not change at all, if we substitute its output value instead of this expression. Side effects will be minor.
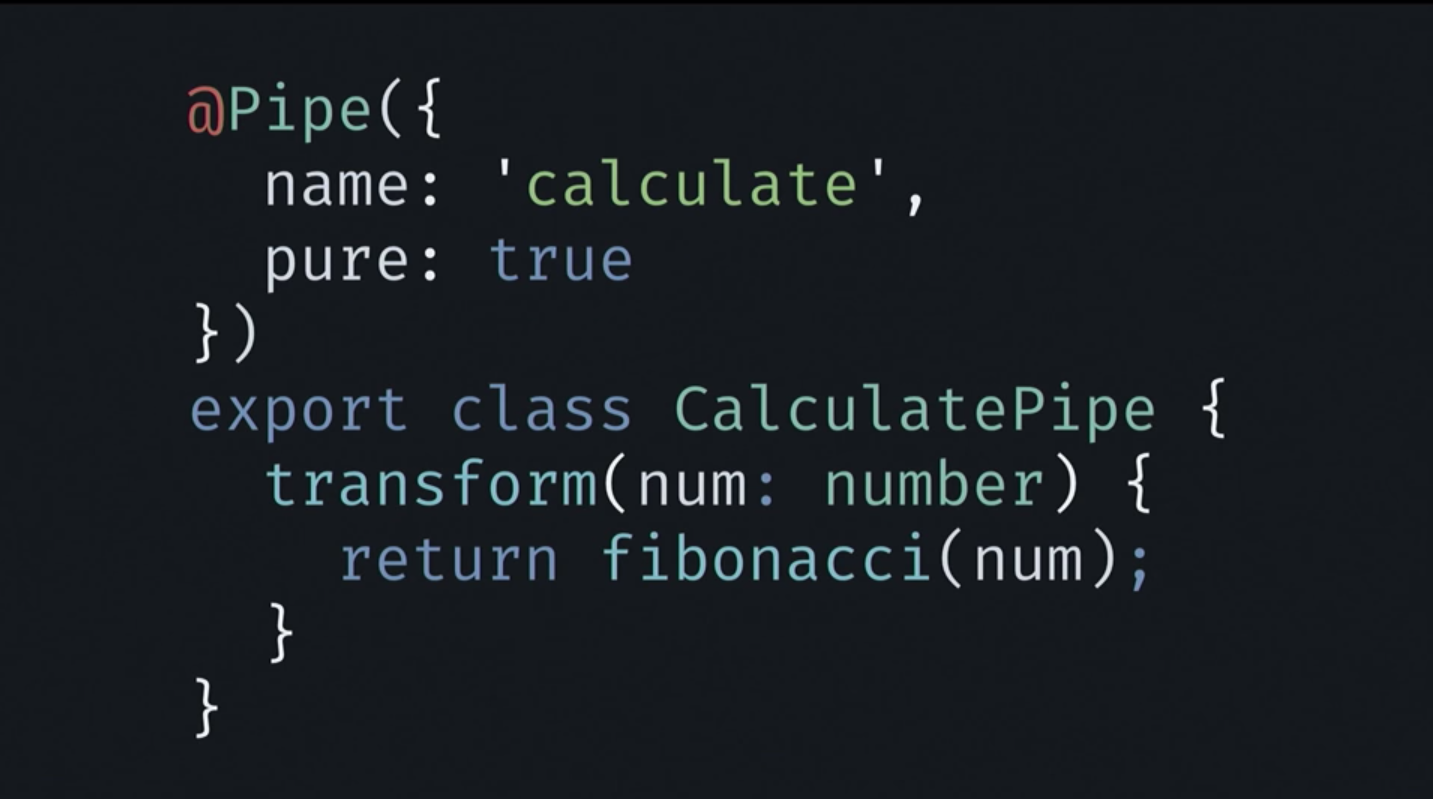
Based on this principle, I encapsulated our Fibonacci function in the CalculatePipe class I wrote, simply delegating the computation of the function fibonacci. In addition, we will need to change the pattern. Instead of the calculate method, we will use the pipe in it.
Now let's try to test the application: in Benchpress, a new user will be added and deleted repeatedly. It can be seen that the application is already fast enough. Productivity increased by several orders of magnitude.

I want to talk about two more optimizations. The first concerns the rendering efficiency. Let's try to display 1000 elements in our application at the same time. Of course, we will not do this in a real application - for such situations there is a virtual scrolling or pagination. But here we will try to optimize the work otherwise.
Suppose our application is already optimized in many ways. Removed unused code, the package weighs 50 kilobytes, we download it in 100 milliseconds. But drawing an image takes at least 8 seconds. Despite the fact that our network performance is excellent, the user will still be dissatisfied.
Take a look at our data. In them we see duplicate values. There are several copies of the Fibonacci function with arguments 27, 28 and 29.

Thanks to clean pipes, we have some caching, but these values are still calculated many times. Fortunately, all our examples are in a small gap. You can try to make the system global caching. Net pipes create cache only for a single expression. We will see the difference between this approach and real caching using memoization.
Memoisation, which we will use, is possible only for pure functions. Its use is quite simple:

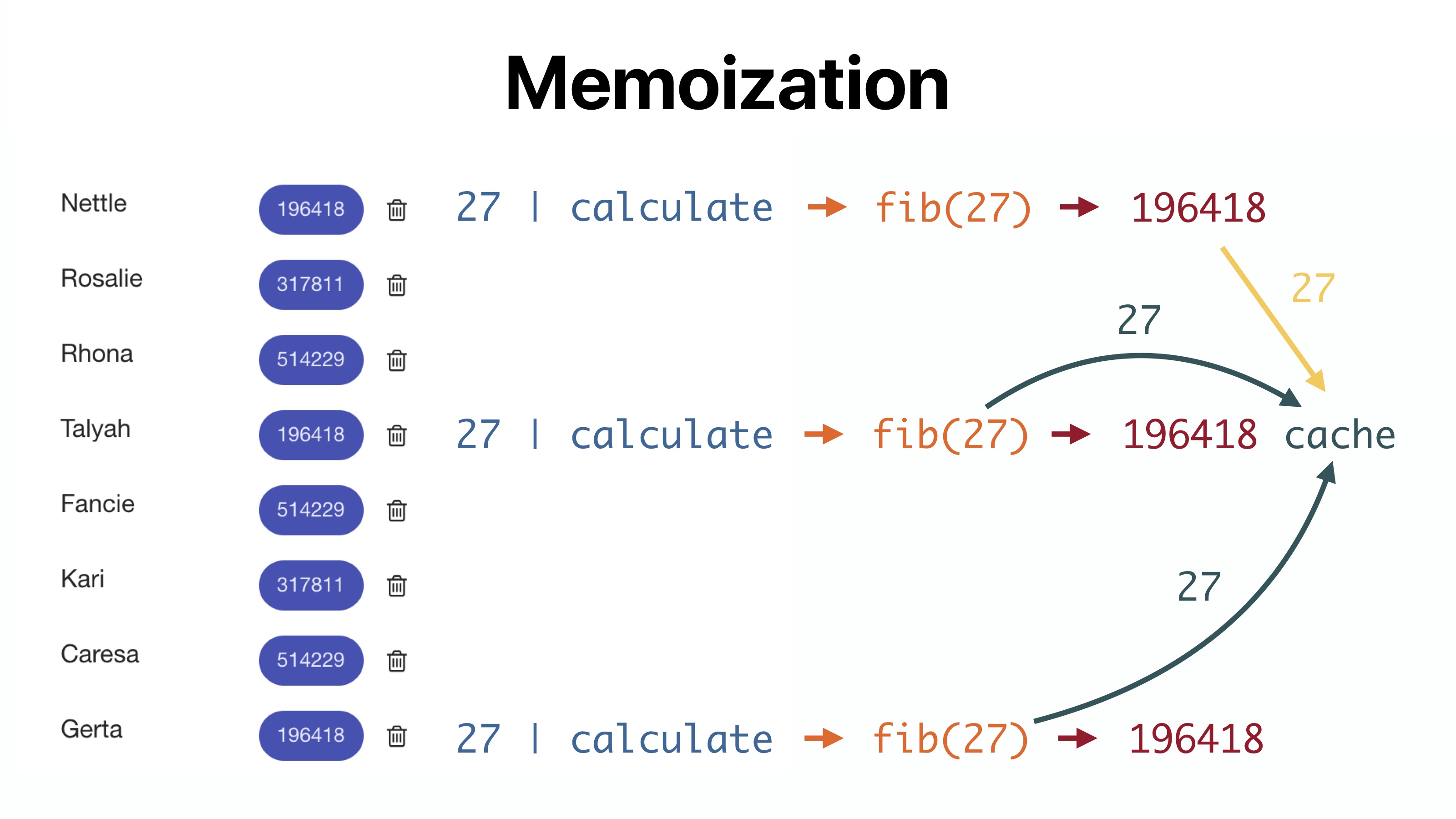
Through require ('lodash.memoize') we get the function memoize, and then call it. It will create the necessary Fibonacci function. Each time this created function is called, its input argument and result will be recorded in the correspondence table. We don't need anything else. We see that the application is now displayed in 6.7 seconds, before these operations took 9.5 seconds. For such a small optimization, this is not bad.
Let's compare clean pipes and memosize. In the first case, when Angular discovers that we are trying to call 27 | calculate, execution is delegated to the function fibonacci (27). Upon further traversal of the list, each time a call is made 27 | calculate, the same operation will be performed, since only local caching occurs.
However, when the next change is detected, Angular will not recalculate the result if the calculate arguments have not changed. Thus, for each subsequent execution of change detection, our optimization will work.

In the case of memoization, everything will look different. First we call 27 | calculate, the Fibonacci number will be calculated, and the number 27 and the output value of the Fibonacci function will be written to the cache. With all the following calls 27 | calculate the result will be taken from the cache. Saving time is obvious.
So, some general trends are beginning to emerge. From a conceptual point of view, OnPush change detection and memoization are similar. Both there and there we have referential transparency. If you present a tree of components as an expression, as an abstract syntactic tree, you can also apply to it optimizations that use referential transparency. However, in both cases it will only work with the latest input data.
Let's try to conduct some more advanced optimization. To do this, we need to refer to some Angular internal APIs. If you are not familiar with them, do not worry, I will try to tell about them in as much detail as possible.
About 90% of software development comes down to the requirement to present a list of items to the user. Angular uses the NgForOf directive for this purpose. We will try to optimize it in accordance with our needs. Here is how it works:

It has a constructor that takes an object of type IterableDiffers as input. And here’s the class IterableDiffers itself:
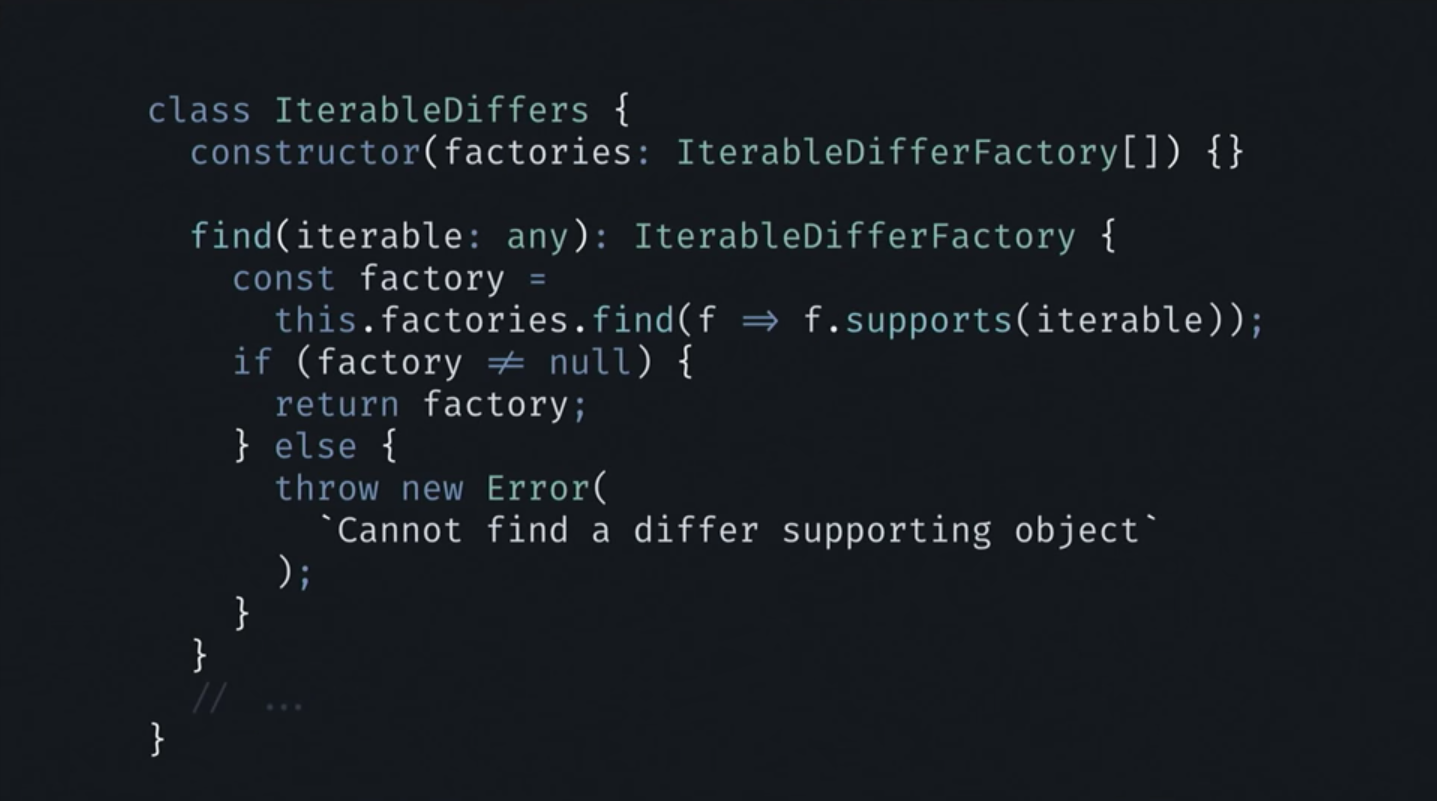
In the class of this object, only the constructor and the find () method. The constructor accepts the collection of IterableDifferFactory [] as input, and the find () method accepts any collection as input (list, binary search tree, or something else).
Then in this method there is a search among all available factories, one that supports the data structure received as input. If the desired factory is located, the method returns it. Nothing else happens here.
Let's look at 3 more interfaces:

The IterableDifferFactory supports () method I just described, and it also has a create method that accepts the trackByFunction function as input. With the latter, you may be familiar with the NgFor directive, there it is also there. The create method returns an instance of the IterableDiffer interface.
IterableDiffer is an abstraction that takes as input a data structure and stores some state. Its purpose is to compare two instances of the same data structure. The diff () method returns the number of differences between two instances (let's call them A and B), that is, the number of elements that need to be added to A to get B, the number of elements that need to be taken from A, and the number of elements that change places.
Finally, the TrackByFunction function. I will talk about it in detail later. First, let's consider the relationship between the structures described.
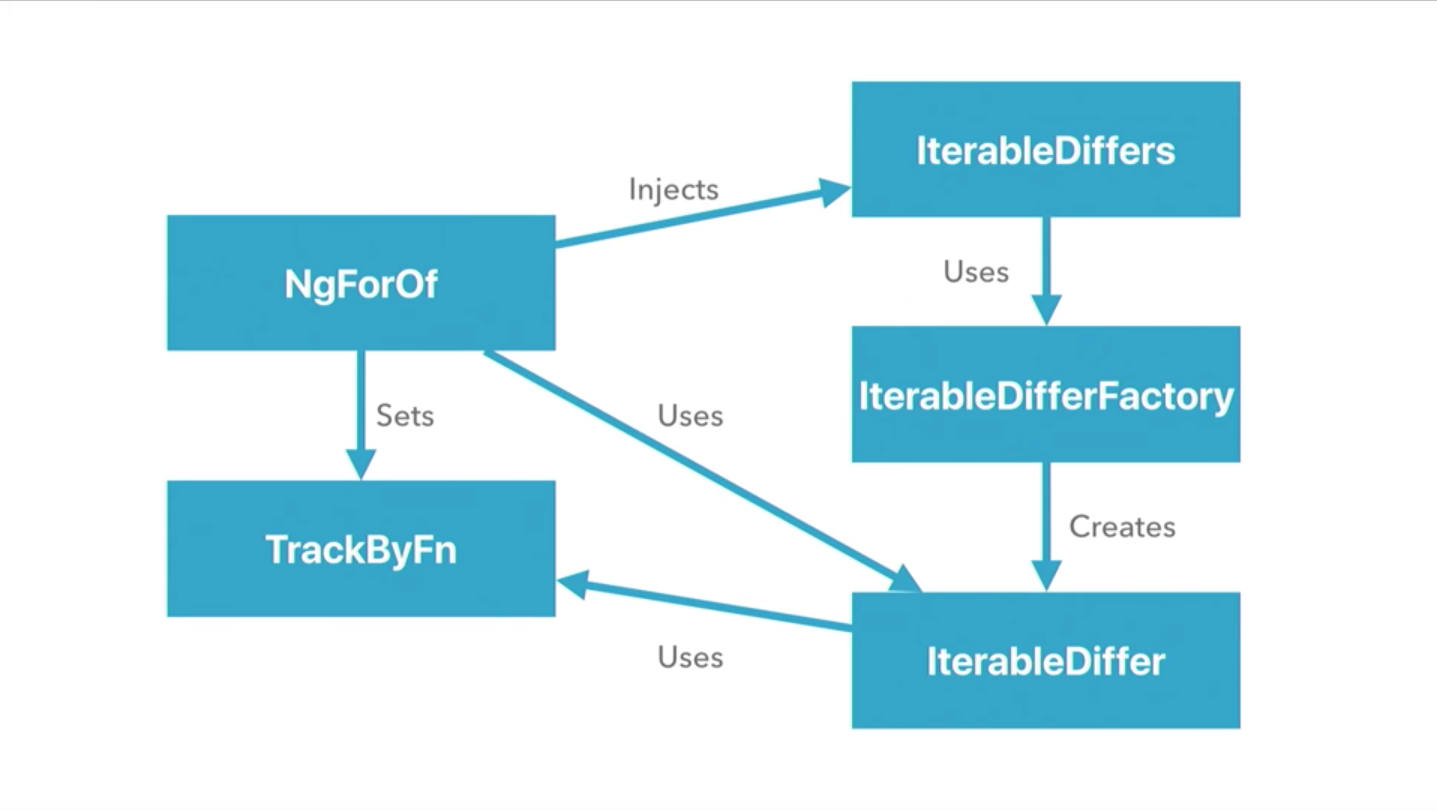
In the NgForOf directive, IterableDiffers is injected as an argument to the constructor. IterableDiffer is used in it to detect discrepancies between the current object that is being iterated and its previous value. IterableDiffers use a collection of factories that, in turn, create IterableDiffer. This latter uses TrackByFn to determine by which characteristics we will compare the elements in the collection with each other.
Take a look at how NgForOf uses differ.

It calls the diff () method with the current value of the collection that is being iterated, and compares it with the previous version of the collection. If changes are detected, they are applied to the DOM.
Let's see how all this will work with IterableDiffers and the specific trackBy function:
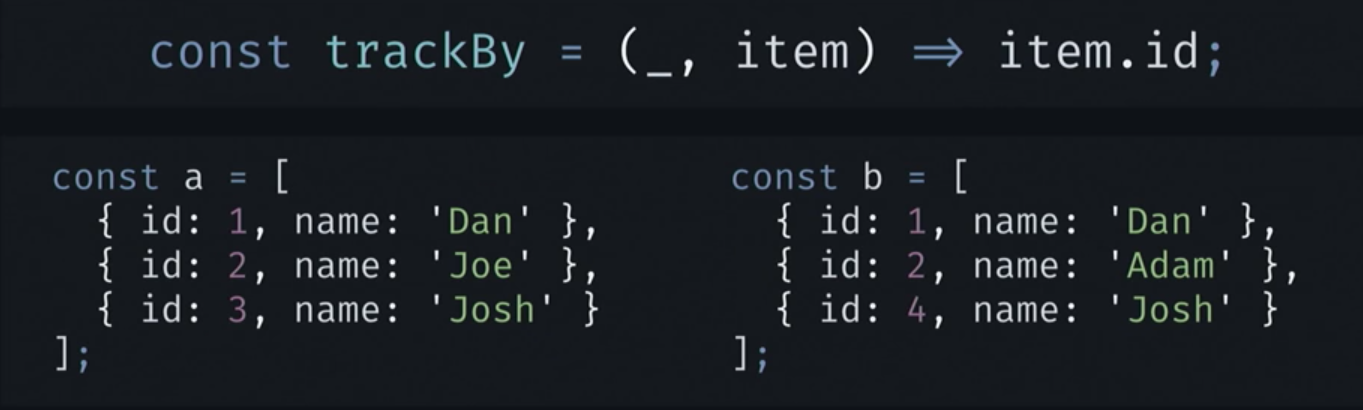
We have a trackBy function that returns the id of the item provided. And we have two collections, a and b. Both are lists, and there are only elements in them.
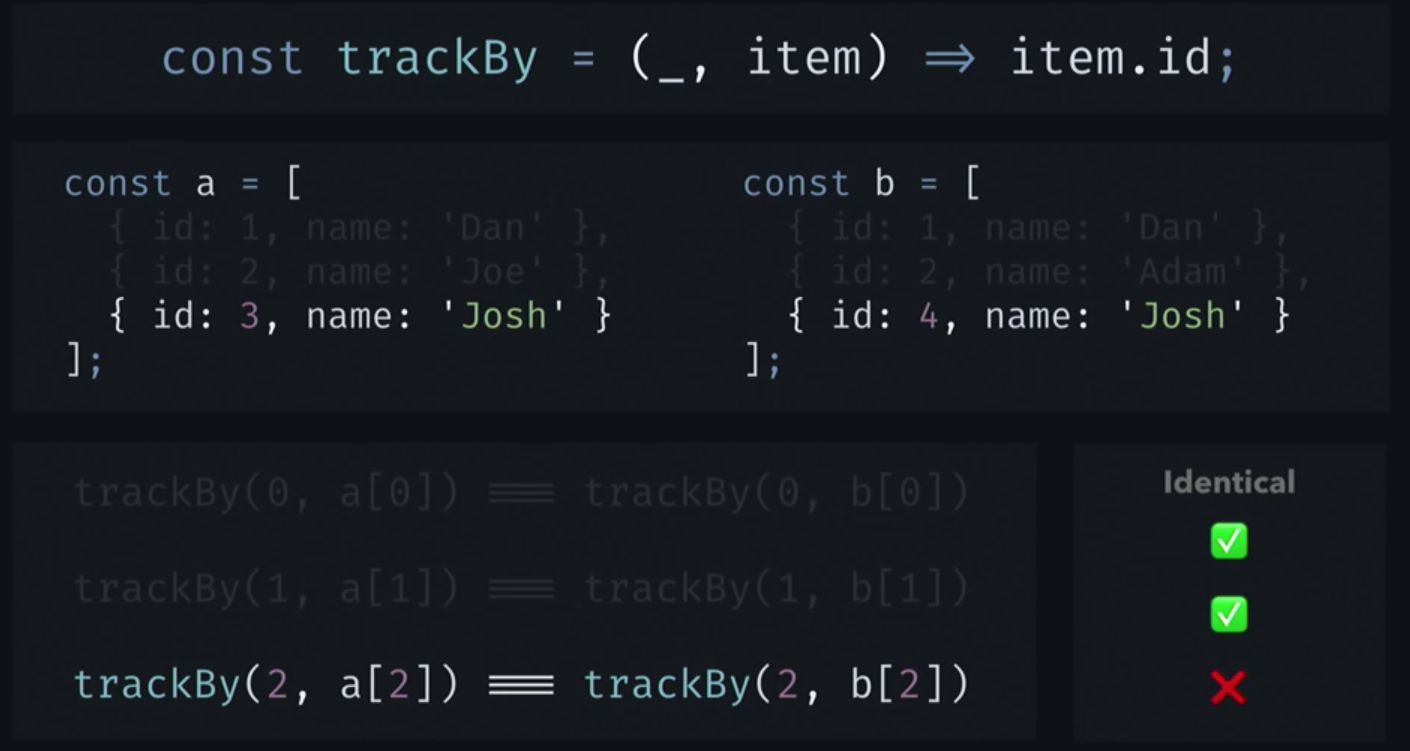
IterableDiffer will first compare the first element of a with the first element of b, and since they have the same identifier, IterableDiffer will conclude that the elements are identical. The same will happen with the second elements. Please note that here the names of the workers are different. For IterableDiffer, it doesn't matter. For him, only identifiers are important. However, identifiers are different, as is the case with the third items in each list, IterableDiffer concludes that the items are different. Therefore, it will produce a result in which it will appear that the last element from a has been deleted, and is replaced by the last element from b.
IterableDiffer checks externally whether the data structure has changed. He uses it as a consumer. But the data structure knows better whether it has changed or not. Let's try to implement our own DifferableList data structure, inspired by another concept from functional programming. It will keep records of changes occurring with it.
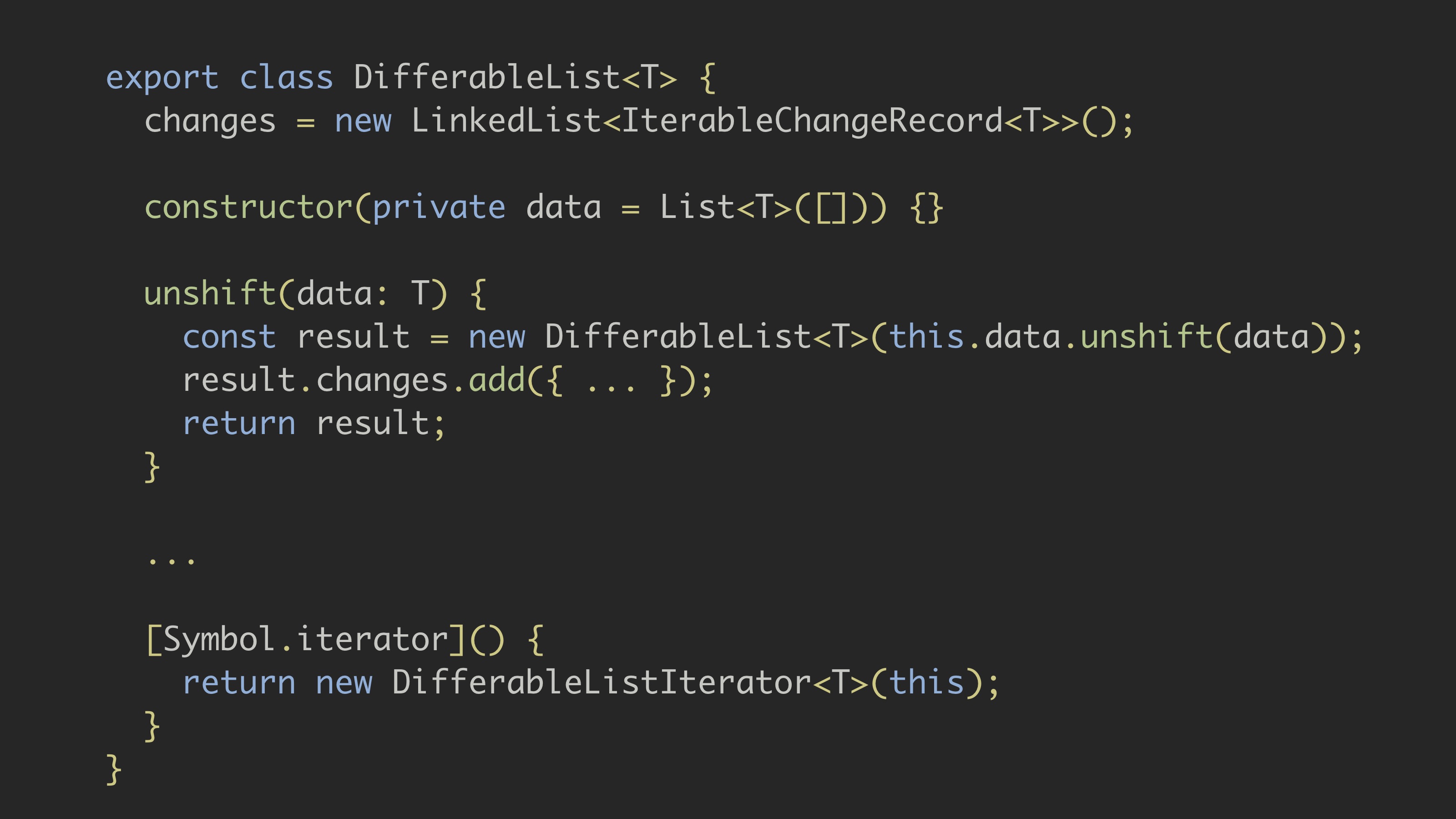
To do this, we will use LinkedList (stored in the changes variable), because it gives slightly better performance than Array, and we do not need random access to the elements.
We will store the data in an immutable Immutable.js list. If necessary, we will modify the list of changes.
We essentially apply the decorator pattern to the immutable list. In addition, we implement an “iterator” template so Angular can bypass this data structure.
Thus, we have created a data structure optimized for Angular. However, differ by default will not provide us with better performance.

We can use the special differ, where there will be a constant check for changes in the data structure. Therefore, it is not necessary to bypass it every time. Instead, you can simply work with the changes property.
These changes will require a little refactoring. We just need to extend the existing set of IterableDiffers.

The described data structure is made according to the general principle of immutable data structures - this is again a concept from functional programming. They allow you to do very unusual things: travel through time, create new universes as branches of existing ones. I recommend to take a look.
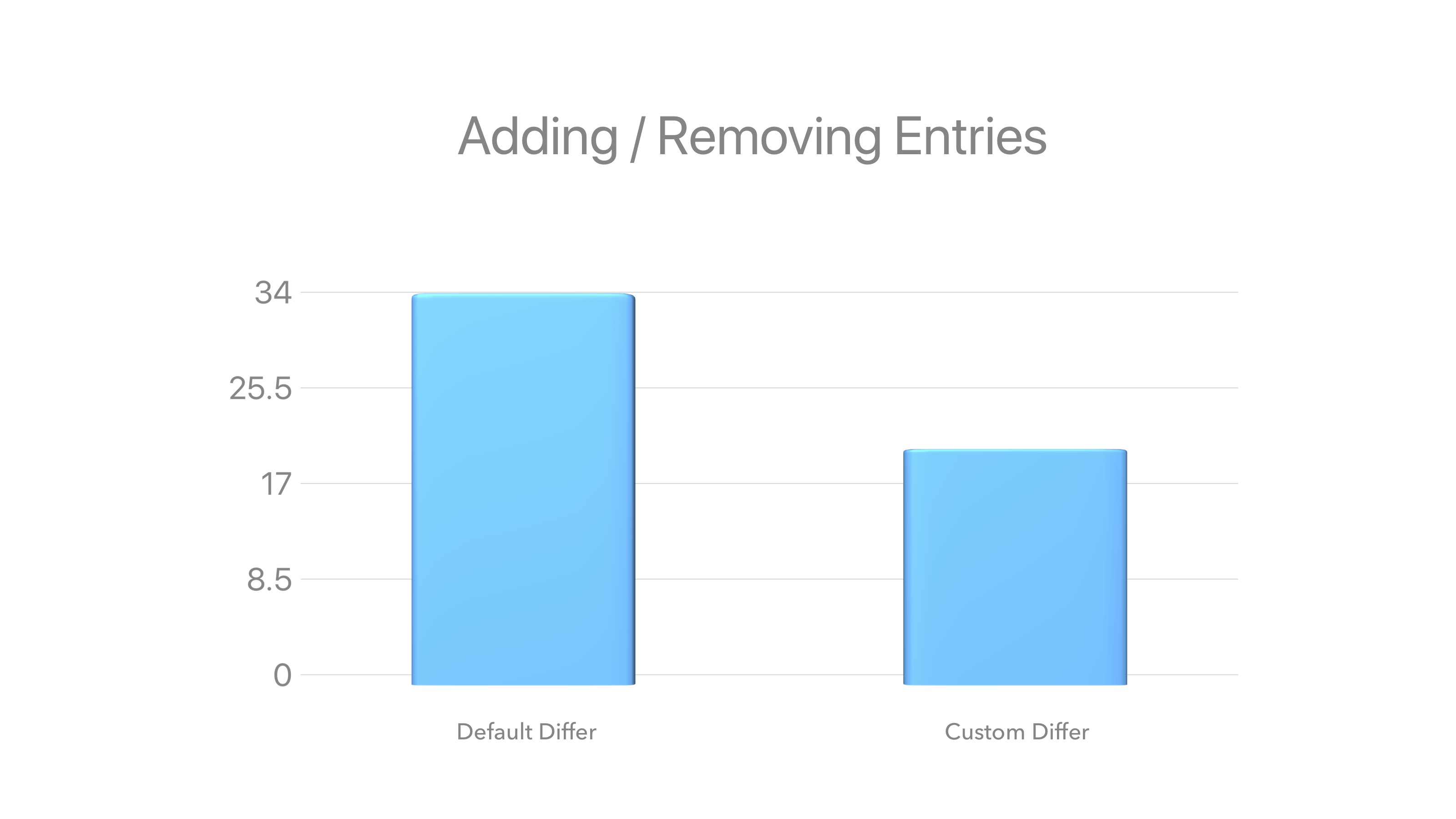
After the last refactoring, our performance increased by about 30%.
Detecting changes OnPush does not always behave as we expect. Change detection is invoked for the subtree of this component, not only when the input data of this component changes, but also when an event occurs in this component.
In addition, we learned the difference between clean pipes and memoization, and the difference between corresponding caching mechanisms. Understood the concepts of purity and referential transparency, taken from functional programming.
Finally, we looked at how the Differ objects and the TrackByFn function work. And they remembered that using other TrackByFn, which are different from this one by default, can only decrease performance.
As a conclusion, we can say that there is no magic bullet for optimizing performance. You need to understand very well how the component tree and the data with which we work are arranged, and, based on this, apply optimizations that are specific to our application. And, of course, it is necessary to apply the solutions proposed to us by Computer Science.
Here are some useful links:
On them it is possible to get acquainted with the described topics in more detail. The first article describes the detection of OnPush changes in Angular, the second deals with clean pipes and referential transparency, and the third about Angular Differs. In addition, there is a slightly more detailed version of the Angular performance checklist. It describes how to customize the detection of changes.
Today we will talk about performance during execution. In the case of single-page applications, it is usually either network performance or performance in runtime.
In the first case, they usually try to reduce the number of HTTP requests or data transmitted over the network. In this direction there is a lot of research. For example, the Google Closure Compiler team is beating on this, achieving the goal of more efficiently removing unused code and minifying code. We also have various compression algorithms, and the webpack team also sets similar goals. Finally, in Angular CLI they try to combine the best of different approaches and provide very well encapsulated assemblies.
')
However, with regard to performance during execution, the development is a bit. Here everything is in our own hands, there is no third-party "magic wand", by the wave of which our application will work faster. There are several possible approaches to the problem, today I will talk about more general solutions, often applicable not only to Angular.
To illustrate these solutions, I wrote a “simple business application.” In it, I tried to reproduce as many performance problems as possible that I have encountered over the past months. The result was a completely creepy product, which we will try to somehow improve.
In our most simplified application, you can add new employees, present them in the list and calculate some value for them. We will have two lists of employees: for the sales department and for the R & D department. In both, you can add new items. Already existing elements are presented in the list, where you can see the name and some numerical value (suppose, this is an assessment of the employee’s work). There is also a field to enter the name of the new employee. When adding an employee, we can simply take a number from somewhere, calculate something and display everything on the screen.
The application structure consists of an AppComponent (covering the entire application) and two EmployeeListComponent (one for each list).
Here is the EmployeeListComponent template:
Here pay attention to the input element. It uses the banana box syntax (square brackets first, then round brackets) to establish a two-way data binding between the label property declared in the EmployeeListComponent controller and the text field.
In addition, the EmployeeListComponent iterates through the list of employees in the dataset, and a list item is created for each employee. For each item, we display the name of the employee and calculate the numeric value using the calculate () method defined in the EmployeeListComponent class.
Now take a look at this class itself:
There are several important things. To begin with, the state is not stored in it, it receives all the necessary data (Employee [Data] array] on input from the parent component. Thus, this parent component, AppComponent, acts as a Container Component in Redux.
In addition, in the EmployeeListComponent class there is a calculate () method, the only task of which is to transfer the execution of a function that calculates Fibonacci numbers. At first glance, Fibonacci numbers are inconvenient to use here, but they have a number of important advantages. First, the method of calculating them is known to everyone; there is no need to explain the complicated work to a suitable function example. It could be replaced with standard deviation or something else like that.
Secondly, this function can be implemented in an extremely inefficient way, as we see it on the screen. We have two recursive calls, and for each Fibonacci number we will have to recalculate all the previous ones again. Thus, here I artificially slowed down the operation of the application so that the effect of the subsequent optimization could be better seen.
So, we have an application with a component of the application itself, and with two components of lists. Each of the items in the list requires a lot of processing power.
Let's try to use some real data in this application. We will have two lists containing a total of 140 items. In this case, when entering new names, typing is extremely slow. It is unlikely that users might like this application work. But why so slow? Profiling this problem is pretty easy with Chrome DevTools. Having done this, we find out that our function of calculating Fibonacci numbers is called very often. We can find out the exact number of calls by adding logging to this function.
It turns out that each time a user presses a key, the entire component tree is recalculated at least twice (once when pressed and once when the key is released). So we recalculate all the previously received values with each press.
This is what this situation looks like in terms of the component tree. Each time you press a key, a change occurs first in the AppComponent. Because change detection in Angular works like a deep search, it also triggers a change detection in the EmployeeListComponent, and then on each of the employee items. For each of these elements, their numerical value will be recalculated. Then the same bypass of the second EmployeeListComponent will occur.
All this is extremely inefficient. As a rule, we do not want to recalculate the numerical values for each element in the array, we would like this only when a new array appears. Now, if a new array is transferred from the AppComponent to the EmployeeListComponent, then you can calculate. Any thoughts on how best to do this?
For example, you can use the OnPush strategy. Thanks to it, change detection will be launched only when new input data appear on the component. When Angular, when checking references, detects the appearance of new inputs, the components will detect changes. That is, if we have a component tree, when the root component receives new data, we update the entire branch, starting with this component. We'll see how it looks later.
Let us turn to functional programming for help and try to imagine that EmployeeListComponent is a function. The input to the component is the input arguments to the function, and the image on the screen is the result of the function. I will demonstrate my idea with the help of pseudocode.
In the f constant, we save the reference to the EmployeeListComponent (now this is a function), in the data constant, the input arguments (data of one employee).
To begin with, we call the function with its initial input, and here Angular will perform the change detection. Since before this the value was undefined, by comparing data and undefined, Angular will see the change in the value of the input data.
But adding a new element to the list will already call a function with the same argument as before: we will modify the data structure pointed to by the same data constant. Therefore, Angular will not start detecting changes.
However, the detection of changes will occur if we send a copy of the array in the input argument of the function: the link will change there.
Does this mean that every time we need to detect changes, we need to copy the entire array? For several reasons, this would be extremely inefficient. First, it would be extremely non-optimal memory usage. For each change detection, we need to first allocate memory for the entire new array, and then the garbage collector will need to free it. Secondly, it is inefficient in terms of computing. The time complexity of this algorithm is at least O (n).
Immutable
Regarding both of these things, it would be wiser to use something like Immutable.js. This is a set of various immutable data structures with two very important properties.
First, we cannot modify any existing data structure. Instead, calls that would change such a data structure receive a new reference to it with the changes already applied.
Secondly, we do not copy the entire data structure: a new instance of this structure will, if possible, use elements of the old one.
This is the kind of refactoring we need to do. First, we changed the contents of the add () and remove () methods. In add (), when executing the unshift () procedure, in which the element is moved to the top of the list, we get a new list. The same thing in the remove () method, the splice () call returns us a new list.
In addition to these two methods, we need to change the link to the list. Otherwise, we could not notify the EmployeeListComponent that the input data has changed. Thus, the output values add () and remove () must be assigned to the list property in the AppComponent.
Run the application and see how much faster everything is now. We optimized here, it should have been better ... Hmm, the application is still very slow. It may have become faster than before, but still the user’s impressions are unlikely to be good.
To measure how much faster the application began to work, I wrote several end-to-end tests and ran them on Angular Benchpress.
Thanks to them, we see that the application has accelerated the work at least twice. This, however, is not enough. The reason for the unsatisfactory work is that when you enter text, change detection is still triggered. The good news is that now it is launched only in one of the two lists, but even in it it is not needed, since none of the numerical values has changed.
Let's see how the work of the application now looks from the point of view of the component tree. Each time we press a key, we trigger change detection several times in the AppComponent, EmployeeListComponent, and in each of the individual components. However, we do not make calls to the second list. But why change detection occurs at all, because there were no calls to any of the calls that change the data structure of the list?
The reason lies in the specific characteristics of detecting OnPush changes, which are not well documented.
The bottom line is that the detection of OnPush changes is triggered not only when the input data changes, but also when the event is triggered in the corresponding component.
Knowing this feature, we can now refactor the code. This has its positive side, because at the same time we will be able to improve the division of responsibility in our application and make the component tree slimmer. Let's make two child components in the EmployeeListComponent: NameInputComponent and ListComponent.
The first of them will be responsible only for storing the current value of the input line and for triggering the event. In the second, the function will be evaluated, and OnPush change detection will be used there.
After these changes in the code, the application began to work much faster. How exactly does the application work now? Unfortunately, when a user presses a key, change detection is still invoked in the AppComponent, and then in both instances of the EmployeeListComponent. But this time, in the child components of the EmployeeListComponent, change detection is no longer triggered. The fact is that ListComponent uses OnPush change detection, and the event occurs in the EmployeeListComponent area, that is, in the parent component EmployeeList. Print speed increases by several orders of magnitude.
However, this is not enough for us. Another possible optimization concerns the addition of elements. When creating a new item, we call the add operation to the immutable list, so a new list is created and passed to the EmployeeListComponent entry. This causes change detection. That is, when you enter text, everything is now fast, but when you add an element, there is still an unnecessary re-calculation of the numerical value in all these components.
To solve this problem, you need to refer to our function calculating Fibonacci numbers. We have already mentioned pure functions today, and this is one of them. The good news is that pure functions are also found among the things that are really useful in our applications, such as calculating the standard deviation.
Pure functions have two very important properties. First, they have no side effects, that is, no calls are made through the network, no logging occurs, and so on. Secondly, a repeated function call with the same arguments gives an identical result. In the world of functional programming, this is called “pure function”.
And this is a very important concept. In Angular, there are “pure pipes” and “dirty pipes” (impure pipes, i.e., internal state pipes). They are usually used for data processing. Pure pipes usually format the data, an example of “pure” is DatePipe.
Dirty pipes store a certain state inside, such as AsyncPipe. The difference between these two cases is that Angular performs a clean pipe only when it detects that its argument has changed. As a rule, expressions with a clean pipe are considered by Angular as having no side effects, referentially transparent. This is a concept from functional programming to better understand it, take a look at the code created by the Angular compiler for a template with clean and dirty pipes.
We apply a clean date date to the birthday variable, and then a dirty impureDate. The screen shows two different results. At first it is difficult to understand. Mysterious characters at the beginning of the expression do not interest us, they are only needed so that developers do not use these imports.
The important part for us is following them. _ck () is a check, in it the current value of date will be compared with the previous one, and if the value is different, the date.transform () method will be called. If there are no changes, the previous result stored in the cache will be returned. In the case of impureDate, the impureDate.transform () method will simply be called.
Thus, referential transparency means that the semantics of an expression will not change at all, if we substitute its output value instead of this expression. Side effects will be minor.
Based on this principle, I encapsulated our Fibonacci function in the CalculatePipe class I wrote, simply delegating the computation of the function fibonacci. In addition, we will need to change the pattern. Instead of the calculate method, we will use the pipe in it.
Now let's try to test the application: in Benchpress, a new user will be added and deleted repeatedly. It can be seen that the application is already fast enough. Productivity increased by several orders of magnitude.
Rendering optimization
I want to talk about two more optimizations. The first concerns the rendering efficiency. Let's try to display 1000 elements in our application at the same time. Of course, we will not do this in a real application - for such situations there is a virtual scrolling or pagination. But here we will try to optimize the work otherwise.
Suppose our application is already optimized in many ways. Removed unused code, the package weighs 50 kilobytes, we download it in 100 milliseconds. But drawing an image takes at least 8 seconds. Despite the fact that our network performance is excellent, the user will still be dissatisfied.
Take a look at our data. In them we see duplicate values. There are several copies of the Fibonacci function with arguments 27, 28 and 29.
Thanks to clean pipes, we have some caching, but these values are still calculated many times. Fortunately, all our examples are in a small gap. You can try to make the system global caching. Net pipes create cache only for a single expression. We will see the difference between this approach and real caching using memoization.
Memoisation, which we will use, is possible only for pure functions. Its use is quite simple:
Through require ('lodash.memoize') we get the function memoize, and then call it. It will create the necessary Fibonacci function. Each time this created function is called, its input argument and result will be recorded in the correspondence table. We don't need anything else. We see that the application is now displayed in 6.7 seconds, before these operations took 9.5 seconds. For such a small optimization, this is not bad.
Let's compare clean pipes and memosize. In the first case, when Angular discovers that we are trying to call 27 | calculate, execution is delegated to the function fibonacci (27). Upon further traversal of the list, each time a call is made 27 | calculate, the same operation will be performed, since only local caching occurs.
However, when the next change is detected, Angular will not recalculate the result if the calculate arguments have not changed. Thus, for each subsequent execution of change detection, our optimization will work.
In the case of memoization, everything will look different. First we call 27 | calculate, the Fibonacci number will be calculated, and the number 27 and the output value of the Fibonacci function will be written to the cache. With all the following calls 27 | calculate the result will be taken from the cache. Saving time is obvious.
So, some general trends are beginning to emerge. From a conceptual point of view, OnPush change detection and memoization are similar. Both there and there we have referential transparency. If you present a tree of components as an expression, as an abstract syntactic tree, you can also apply to it optimizations that use referential transparency. However, in both cases it will only work with the latest input data.
Let's try to conduct some more advanced optimization. To do this, we need to refer to some Angular internal APIs. If you are not familiar with them, do not worry, I will try to tell about them in as much detail as possible.
About 90% of software development comes down to the requirement to present a list of items to the user. Angular uses the NgForOf directive for this purpose. We will try to optimize it in accordance with our needs. Here is how it works:
It has a constructor that takes an object of type IterableDiffers as input. And here’s the class IterableDiffers itself:
In the class of this object, only the constructor and the find () method. The constructor accepts the collection of IterableDifferFactory [] as input, and the find () method accepts any collection as input (list, binary search tree, or something else).
Then in this method there is a search among all available factories, one that supports the data structure received as input. If the desired factory is located, the method returns it. Nothing else happens here.
Let's look at 3 more interfaces:
The IterableDifferFactory supports () method I just described, and it also has a create method that accepts the trackByFunction function as input. With the latter, you may be familiar with the NgFor directive, there it is also there. The create method returns an instance of the IterableDiffer interface.
IterableDiffer is an abstraction that takes as input a data structure and stores some state. Its purpose is to compare two instances of the same data structure. The diff () method returns the number of differences between two instances (let's call them A and B), that is, the number of elements that need to be added to A to get B, the number of elements that need to be taken from A, and the number of elements that change places.
Finally, the TrackByFunction function. I will talk about it in detail later. First, let's consider the relationship between the structures described.
In the NgForOf directive, IterableDiffers is injected as an argument to the constructor. IterableDiffer is used in it to detect discrepancies between the current object that is being iterated and its previous value. IterableDiffers use a collection of factories that, in turn, create IterableDiffer. This latter uses TrackByFn to determine by which characteristics we will compare the elements in the collection with each other.
Take a look at how NgForOf uses differ.
It calls the diff () method with the current value of the collection that is being iterated, and compares it with the previous version of the collection. If changes are detected, they are applied to the DOM.
Let's see how all this will work with IterableDiffers and the specific trackBy function:
We have a trackBy function that returns the id of the item provided. And we have two collections, a and b. Both are lists, and there are only elements in them.
IterableDiffer will first compare the first element of a with the first element of b, and since they have the same identifier, IterableDiffer will conclude that the elements are identical. The same will happen with the second elements. Please note that here the names of the workers are different. For IterableDiffer, it doesn't matter. For him, only identifiers are important. However, identifiers are different, as is the case with the third items in each list, IterableDiffer concludes that the items are different. Therefore, it will produce a result in which it will appear that the last element from a has been deleted, and is replaced by the last element from b.
IterableDiffer checks externally whether the data structure has changed. He uses it as a consumer. But the data structure knows better whether it has changed or not. Let's try to implement our own DifferableList data structure, inspired by another concept from functional programming. It will keep records of changes occurring with it.
To do this, we will use LinkedList (stored in the changes variable), because it gives slightly better performance than Array, and we do not need random access to the elements.
We will store the data in an immutable Immutable.js list. If necessary, we will modify the list of changes.
We essentially apply the decorator pattern to the immutable list. In addition, we implement an “iterator” template so Angular can bypass this data structure.
Thus, we have created a data structure optimized for Angular. However, differ by default will not provide us with better performance.
We can use the special differ, where there will be a constant check for changes in the data structure. Therefore, it is not necessary to bypass it every time. Instead, you can simply work with the changes property.
These changes will require a little refactoring. We just need to extend the existing set of IterableDiffers.
The described data structure is made according to the general principle of immutable data structures - this is again a concept from functional programming. They allow you to do very unusual things: travel through time, create new universes as branches of existing ones. I recommend to take a look.
After the last refactoring, our performance increased by about 30%.
Repeat the traversed
Detecting changes OnPush does not always behave as we expect. Change detection is invoked for the subtree of this component, not only when the input data of this component changes, but also when an event occurs in this component.
In addition, we learned the difference between clean pipes and memoization, and the difference between corresponding caching mechanisms. Understood the concepts of purity and referential transparency, taken from functional programming.
Finally, we looked at how the Differ objects and the TrackByFn function work. And they remembered that using other TrackByFn, which are different from this one by default, can only decrease performance.
As a conclusion, we can say that there is no magic bullet for optimizing performance. You need to understand very well how the component tree and the data with which we work are arranged, and, based on this, apply optimizations that are specific to our application. And, of course, it is necessary to apply the solutions proposed to us by Computer Science.
Here are some useful links:
- mgv.io/ng-cd - Angular's OnPush Change Detection Strategy
- mgv.io/ng-pure - Pure Pipes and Referential Transparency
- mgv.io/ng-diff - Understanding Angular Differs
- mgv.io/ng-perf-checklist - Angular Performance Checklist
- mgv.io/ng-checklist-video - Angular Performance Checklist
On them it is possible to get acquainted with the described topics in more detail. The first article describes the detection of OnPush changes in Angular, the second deals with clean pipes and referential transparency, and the third about Angular Differs. In addition, there is a slightly more detailed version of the Angular performance checklist. It describes how to customize the detection of changes.
Minute advertising. If you liked this report from the previous HolyJS, please note: on May 19-20, HolyJS 2018 Piter will pass. And also pay attention to the fact that from May 1 the ticket price will increase, so now is the time to decide!
Source: https://habr.com/ru/post/354552/
All Articles