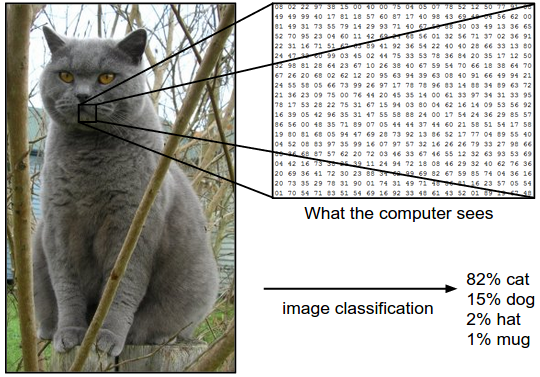
Whiskers, paws and tail: how does a neural network recognize cats and other objects?

Image recognition is a classic example of the use of neural networks. Recall how the network learning process takes place, what difficulties arise and why use biology in development. Details under the cut.
Dmitry Soshnikov, a technical evangelist of Microsoft, a member of the Russian Association of Artificial Intelligence, a teacher of functional and logical programming of AI in MAI, MIPT and HSE, as well as our courses will help us in the story.
Imagine that we have a lot of pictures that need to be sorted in two piles using a neural network. How can this be done? Of course, everything depends on the objects themselves, but we can always identify some features.
')
We need to know as much information as possible about the input data and take it into account when entering manually, even before learning the network. For example, if we have a task to detect multi-colored cats in a picture, it is not the color that is important, but the shape of the object. When we get rid of color by going to a black and white image, the network will learn much faster and more successfully: it will have to recognize several times less information.
For recognizing arbitrary objects, for example, cats and frogs, the color is obviously important: the frog is green, and cats are not. If we leave color channels, for each palette, the network learns to re-recognize image objects, because this color channel is fed to other neurons.
And if we want to destroy the famous meme about cats and bread, having taught the neural network to detect an animal in any picture? It would seem that the colors and shape are approximately the same. What to do then?
Filter banks and biological vision

Using different filters, you can select different image fragments, which are then detected and explored as separate properties. For example, to submit to the input of traditional machine learning or neural networks. If the neural network has additional information about the structure of objects with which it works, the quality of work increases.
In the field of machine vision, filter banks have been accumulated - filter sets to highlight the main features of objects.
Similar "architecture" is used in biology. Scientists believe that human vision does not determine the entire image as a whole, but highlights the characteristic features and unique features by which the brain identifies an object. Accordingly, for quick and correct recognition of the object, you can define the most unique features. For example, cats can have whiskers - fan horizontal dashes on the image.
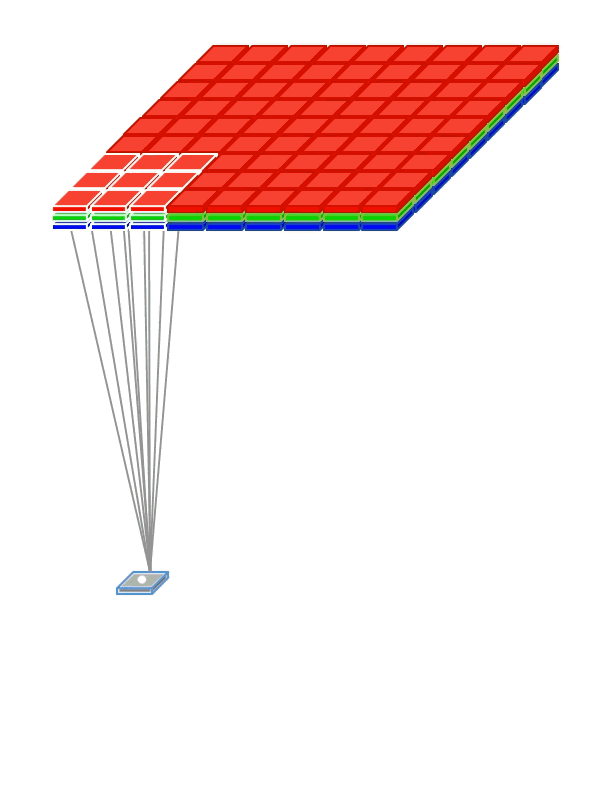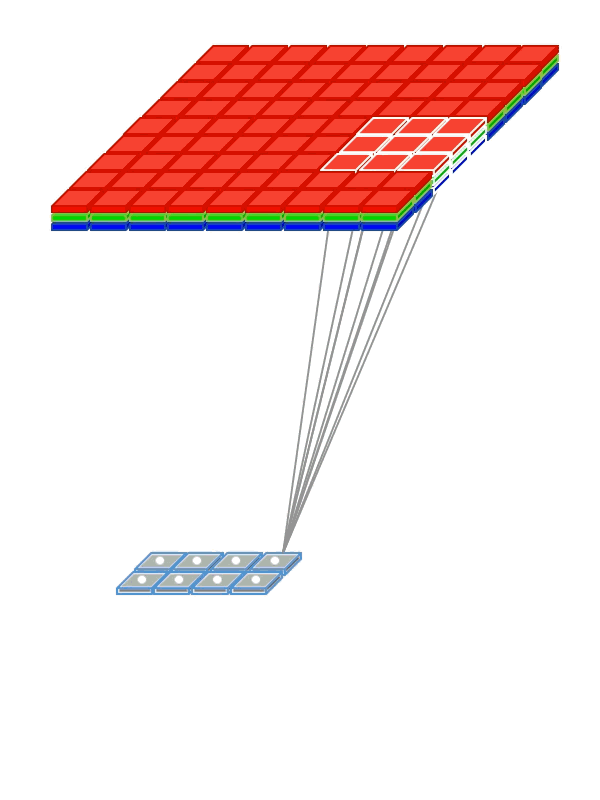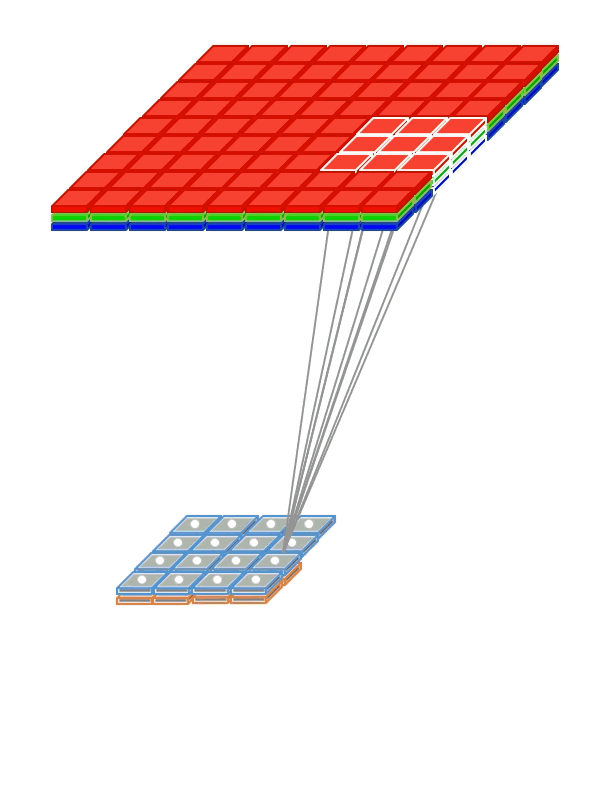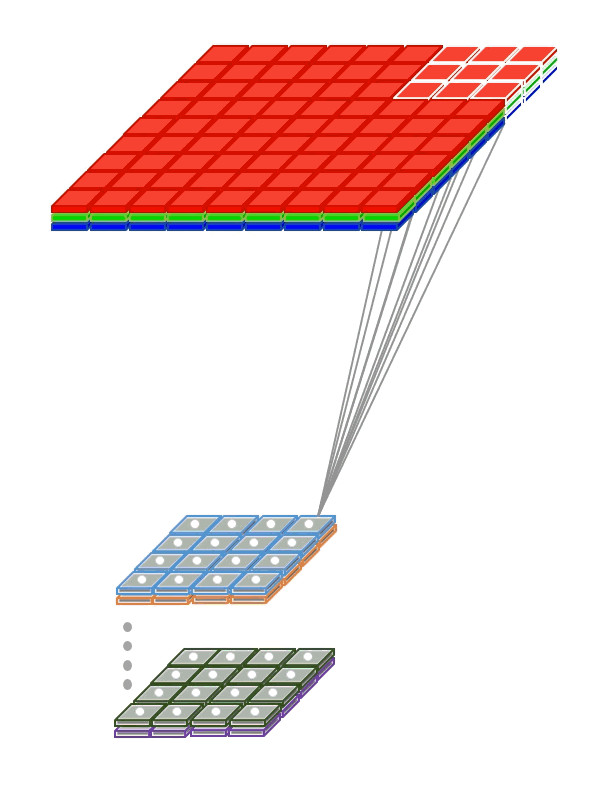
Weight Sharing
So that the network does not have to learn separately to recognize cats in different parts of the picture, we “share” the weights responsible for recognition between different fragments of input signals.
This requires a specialized network architecture:
- image convolutional networks
- text / string recurrent networks
Neural networks that are effectively used in image recognition, which use special convolutional layers (Convolution Layers).
The basic idea is this:
- Use weight sharing to create a “filter window” running through the image.
- The filter applied to the image helps to identify fragments that are important for recognition.
- While in traditional machine vision, filters are designed by hand, neural networks allow us to construct optimal filters through training.
- Image filtering can be naturally combined with neural network calculation.
For image processing, convolution is used, as in signal processing.
We describe the convolution function with the following parameters:
- kernel - the core of the bundle, the weights matrix
- pad - how many pixels should be added to the image along the edges
- stride - the frequency of the filter. For example, for stride = 2, we will take every second pixel of the image vertically and horizontally, reducing the resolution by half
In [1]: def convolve(image, kernel, pad = 0, stride = 1): rows, columns = image.shape output_rows = rows // stride output_columns = columns // stride result = np.zeros((output_rows, output_columns)) if pad > 0: image = np.pad(image, pad, 'constant') kernel_size = kernel.size kernel_length = kernel.shape[0] half_kernel = kernel_length // 2 kernel_flat = kernel.reshape(kernel_size, 1) offset = builtins.abs(half_kernel-pad) for r in range(offset, rows - offset, stride): for c in range(offset, columns - offset, stride): rr = r - half_kernel + pad cc = c - half_kernel + pad patch = image[rr:rr + kernel_length, cc:cc + kernel_length] result[r//stride,c//stride] = np.dot(patch.reshape(1, kernel_size), kernel_flat) return result In [2]: def show_convolution(kernel, stride = 1): """Displays the effect of convolving with the given kernel.""" fig = pylab.figure(figsize = (9,9)) gs = gridspec.GridSpec(3, 3, height_ratios=[3,1,3]) start=1 for i in range(3): image = images_train[start+i,0] conv = convolve(image, kernel, kernel.shape[0]//2, stride) ax = fig.add_subplot(gs[i]) pylab.imshow(image, interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) ax = fig.add_subplot(gs[i + 3]) pylab.imshow(kernel, cmap='gray', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) ax = fig.add_subplot(gs[i + 6]) pylab.imshow(conv, interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) pylab.show() In [3]: blur_kernel = np.array([[1, 4, 7, 4, 1], [4, 16, 26, 16, 4], [7, 26, 41, 26, 7], [4, 16, 26, 16, 4], [1, 4, 7, 4, 1]], dtype='float32') blur_kernel /= 273 Filters
Blur
The blur filter smooths out bumps and emphasizes the overall shape of objects.

In [4]: show_convolution(blur_kernel) Vertical edges
You can come up with a filter that highlights the vertical brightness transitions in the image. Here, blue indicates the transition from black to white, yellow - vice versa.

In [5]: vertical_edge_kernel = np.array([[1, 4, 0, -4, 1], [4, 16, 0, -16, -4], [7, 26, 0, -26, -7], [4, 16, 0, -16, -4], [1, 4, 0, -4, -1]], dtype='float32') vertical_edge_kernel /= 166 In [6]: show_convolution(vertical_edge_kernel) Horizontal edges
A similar filter can be constructed to highlight horizontal strokes in the image.

In [7]: horizontal_bar_kernel = np.array([[0, 0, 0, 0, 0], [-2, -8, -13, -8, -2], [4, 16, 26, 16, 4], [-2, -8, -13, -8, -2], [0, 0, 0, 0, 0]], dtype='float32') horizontal_bar_kernel /= 132 In [8]: show_convolution(horizontal_bar_kernel) Contour filter
You can also build a 9x9 filter that will highlight the edges of the image.

In [9]: blob_kernel = np.array([[0, 1, 1, 2, 2, 2, 1, 1, 0], [1, 2, 4, 5, 5, 5, 4, 2, 1], [1, 4, 5, 3, 0, 3, 5, 4, 1], [2, 5, 3, -12, -24, -12, 3, 5, 2], [2, 5, 0, -24, -40, -24, 0, 5, 2], [2, 5, 3, -12, -24, -12, 3, 5, 2], [1, 4, 5, 3, 0, 3, 5, 4, 1], [1, 2, 4, 5, 5, 5, 4, 2, 1], [0, 1, 1, 2, 2, 2, 1, 1, 0]], dtype='float32') blob_kernel /= np.sum(np.abs(blob_kernel)) In [10]: show_convolution(blob_kernel) Thus, the classic example of digit recognition works: each digit has its own characteristic geometric features (two circles - eight, slash for half of the image - unit, etc.), according to which the neural network can determine what kind of object it is. We create filters that characterize each digit, we run each of the filters through the image and minimize the error.
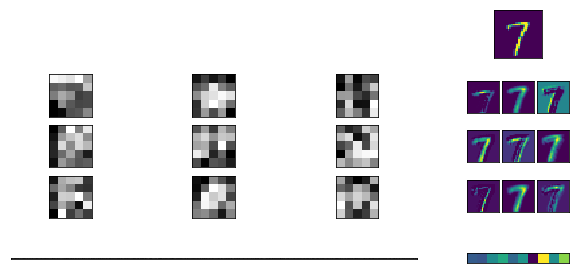
If you apply a similar approach to the search for cats in the picture, it quickly turns out that there are many signs of a quadruped for learning neural network, and they are all different: tails, ears, whiskers, noses, wool and color. And each cat can have nothing to do with the other. A neural network with a small amount of data on the structure of the object will not be able to understand that one cat lies, and the second is on its hind legs.
The basic idea of the convolution network
- Create a convolutional layer in the neural network, which ensures the application of the filter to the image.
- We teach filter weights using the back distribution algorithm.
For example, we have an image i , 2 convolution filters w with outputs o . Elements of the output image will be calculated as follows:

Weight training
The algorithm is as follows:
- A filter with the same weights is applied to all pixels of the image.
- At the same time, the filter “runs through” the entire image.
- We want to train these weights (common to all pixels) using the backpropagation algorithm.
- For this it is necessary to reduce the application of the filter to a single multiplication of matrices.
- In contrast to the full layer layer, there will be fewer training scales, and more examples.
- Trick - im2col
im2col
Let's start with the image x, where each pixel corresponds to a letter:

Then we extract all 3x3 image fragments and place them in the columns of the large matrix X:

Now we can save the filter weights in the usual matrix, where each row corresponds to one convolution filter:
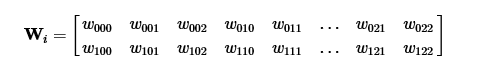
Then the convolution over the entire image turns into a regular matrix multiplication:

Image analysis problems
In the process of learning, many pitfalls can arise: incorrect sampling already on the second layer will ruin the whole learning process, it may not be large enough, because of which the network will not learn to detect all possible positions of the object features.
There is a reverse situation: with an increase in the number of layers, the gradient damping occurs, too many parameters appear, and the function can get stuck in a local minimum.
In the end, the curve code, too, has not been canceled.
To teach how to work with neural networks, to cope with its training and to determine where it is possible to use machine learning in practice, Dmitry Soshnikov and I developed a special Neuro Workshop course. Of course, it also describes how to solve the problems listed above.
Neuro Workshop will be held 2 times:
Choose a convenient day, come and ask Dmitry your questions.
Source: https://habr.com/ru/post/354524/
All Articles