Apache Kafka - my summary
This is my summary in which I briefly and in essence touch on such Kafka concepts as:
- Topic (Topic)
- Subscribers (consumer)
- Publisher (producer)
- Group (partition)
- Streams
When studying Kafka, there were questions, the answers to which I had to experimentally get on examples, and this is what is outlined in this summary. How to start and where to start I will give one of the links below in the materials.
')
Apache Kafka is a Java based message dispatcher. Kafka has a message subject in which publishers write messages and there are subscribers in topics that read these messages, all messages in the dispatch process are written to disk and are not dependent on consumers.

Kafka includes a set of utilities for creating topics, sections, ready-made publishers, subscribers for examples, etc. Kafka needs a ZooKeeper coordinator, so first we start ZooKeeper (zkServer.cmd) then Kafka server (kafka-server-start.bat ), batch files are located in the appropriate bin folders, there are utilities.
Create a theme Kafka utility, part of
For simple testing, you can use the included kafka-console-consumer and kafka-console-producer applications, but I'll make my own. Subscribers in practice are grouped together, this will allow different applications to read messages from the topic in parallel.
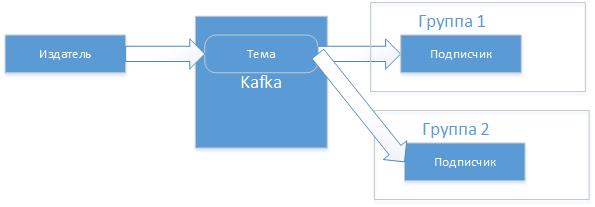
For each application, there will be an organized queue, reading from which it performs the movements of the pointer of the last message read (offset), this is called reading commit. And so if the publisher sends a message to the topic, it will be guaranteed to be read by the recipient of this topic if it is running or as soon as it is connected. And if there are different clients (client.id) that read from the same topic, but in different groups, then they will receive messages regardless of each other and at the time when they are ready.
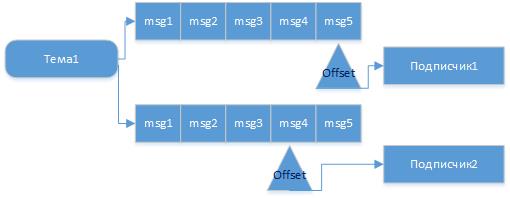
So you can submit a follower of messages and independent reading of their consumers from one topic.
But there is a situation when messages in a subject can begin to arrive faster than to leave, i.e. consumers process them longer. To do this, the topic can provide partitions and run consumers in the same group for this topic.
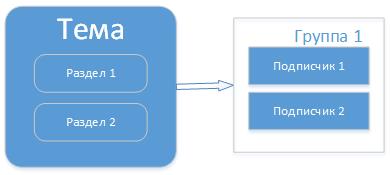
Then there will be a load distribution and not all messages in the subject and group will go through one consumer. And then the strategy will be chosen, how to distribute messages into sections. There are several strategies: round-robin is in a circle, according to a hash of the key value, or an explicit indication of the section number where to write. Subscribers in this case are distributed evenly across sections. If, for example, there are more subscribers in the group than sections, then someone will not receive the message. Thus, partitions are made to improve scalability.
For example, after creating a theme with one section, I changed to two sections.
and message n: 1 to client02
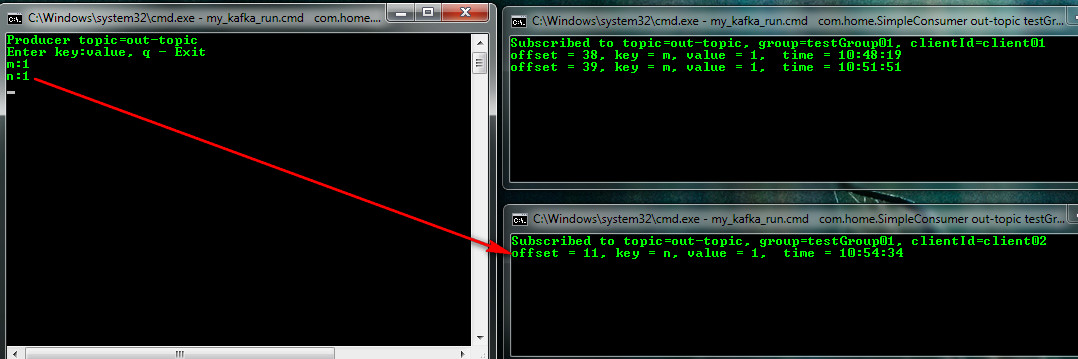
If I start typing without specifying the key: value pairs (I did this in the publisher), the strategy will be selected in a circle. The first message "m" got client01, and already three times client02.
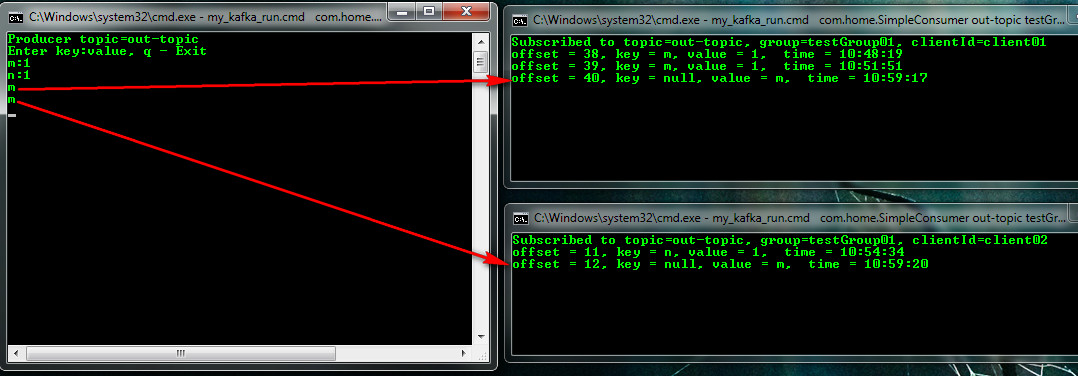
And another option with the indication of the section, for example in this format key: value: partition
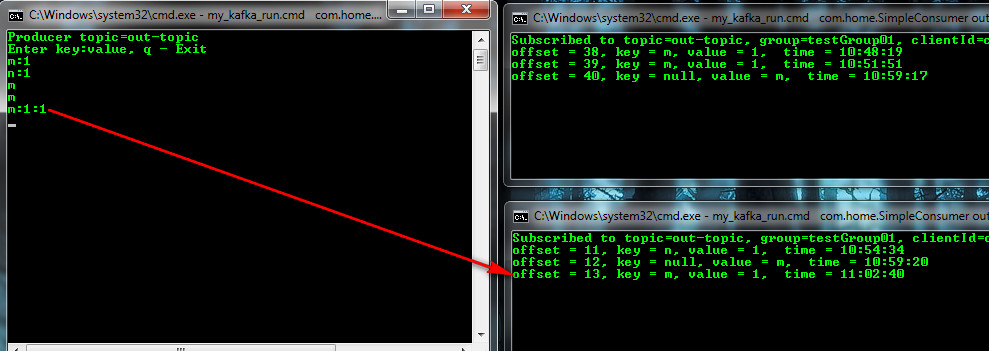
Earlier in the hash strategy, m: 1 went to another client (client01), now with the explicit indication of the section (# 1, they are numbered from 0) to client02.
If you start a subscriber with a different group name testGroup02 and for the same topic, the messages will go in parallel and independently to the subscribers, i.e. if the first one is read and the second is not active, then it will read as soon as it becomes active.
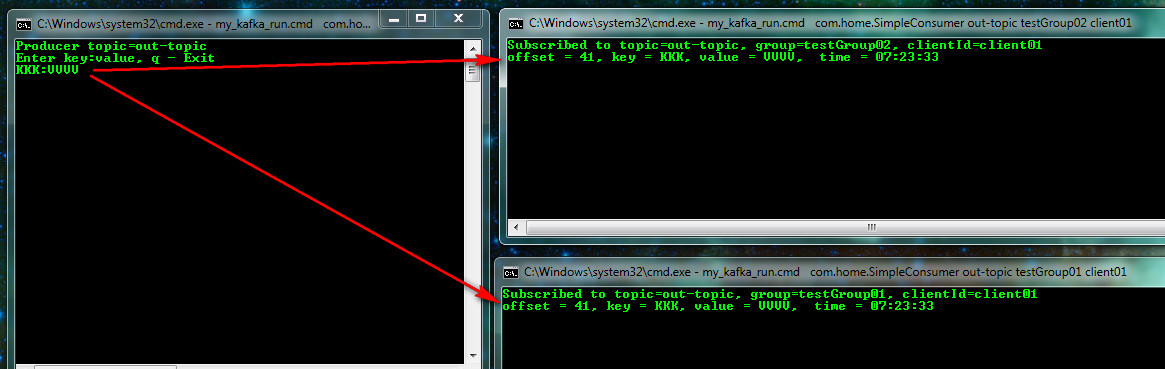
You can see the descriptions of groups, topics, respectively:


To run my programs, I made a batch file - my_kafka_run.cmd
startup example:
So, the streams in Kafka are a sequence of events that are obtained from a topic, over which you can perform certain operations, transformations and then return the result further, for example, to another topic or save it to a database, generally anywhere. Operations can be either for example filtering (filter), transformation (map), or aggregation (count, sum, avg). To do this, there are corresponding classes KStream, KTable, where KTable can be represented as a table with current aggregated values that are constantly updated as new messages arrive in the topic. How does this happen?

For example, the publisher writes to the subject of the event (message), Kafka saves all messages in the message log, which has a retention policy (for example, 7 days). For example, a quote change event is a stream, then we want to know the average value, then we will create a Stream that will take the history from the magazine and calculate the average, where the key is the share, and the value is the average (this is a table with a status). There is a feature here - aggregation operations, unlike operations, for example, filtering, retain state. Therefore, the newly received messages (events) in the topic will be subject to calculation, and the result will be saved (state store), then the newly received messages will be written to the log, Stream will process them, add changes to the already saved state. Filtering operations do not require state preservation. And here, too, stream will do this regardless of the publisher. For example, the publisher writes messages, and the program - stream does not work at this time, nothing is lost, all messages will be saved in the log and as soon as the program-stream becomes active, it will do the calculations, save the state, perform the offset for the messages read (it says they have been read) and in the future it will not return to them, moreover, these messages will leave the log (kafka-logs). It seems that the main thing is that the log (kafka-logs) and its storage policy allow this. By default, the state of Kafka Stream is stored in RocksDB. The message log and everything related to it (themes, offsets, flows, clients, etc.) is located along the path specified in the “log.dirs = kafka-logs” parameter of the “config \ server.properties” configuration file, and the same log storage policy is specified. "Log.retention.hours = 48". Log example
And the path to the database with stream states is specified in the application parameter.

Now let's check how Stream works. Prepare the Stream application from the example, which is the delivery (with some refinement for the experiment), which counts the number of identical words and the application is the publisher and the subscriber. Will write in the topic in-topic

We start to enter words and see their counting with an indication of which Stream App-ID counted them

The work will go independently, you can stop the Stream and continue to write in the topic, he then at the start will count. And now we will connect the second Stream with App-ID = app_02 (this is also an application, but with a different ID), it will read the log (a sequence of events that is saved according to the Retention policy), count the number, save the status and issue the result. Thus, two streams starting to work at different times came to the same result.
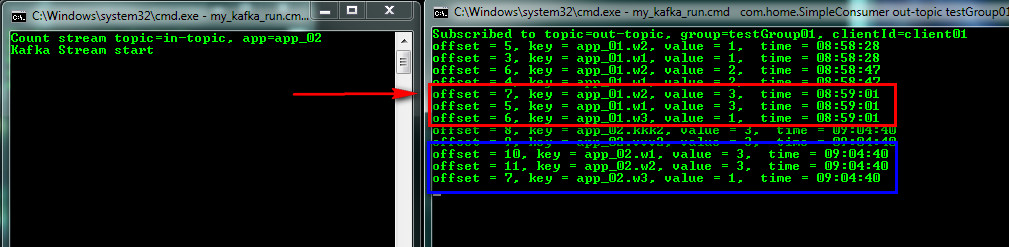
And now let's imagine our magazine is outdated (Retention policy) or we deleted it (which is what needs to be done) and connect the third stream with App-ID = app_03 (I stopped Kafka for this, deleted kafka-logs and started again) and introduce a new topic the message and see the first (app_01) stream continued counting and the new third started from scratch.
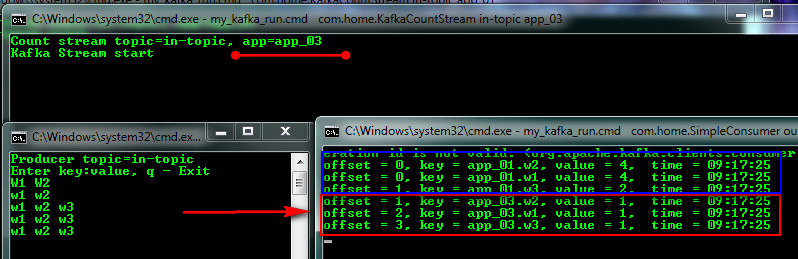
If we then run the app_02 stream, it will catch up with the first one and they will be equal in values. From the example, it became clear how Kafka processes the current log, adds to the previously saved state and so on.
The Kafka theme is very extensive, I made the first general presentation for myself :-)
Materials:
How to start and where to start
- Topic (Topic)
- Subscribers (consumer)
- Publisher (producer)
- Group (partition)
- Streams
Kafka - basic
When studying Kafka, there were questions, the answers to which I had to experimentally get on examples, and this is what is outlined in this summary. How to start and where to start I will give one of the links below in the materials.
')
Apache Kafka is a Java based message dispatcher. Kafka has a message subject in which publishers write messages and there are subscribers in topics that read these messages, all messages in the dispatch process are written to disk and are not dependent on consumers.
Kafka includes a set of utilities for creating topics, sections, ready-made publishers, subscribers for examples, etc. Kafka needs a ZooKeeper coordinator, so first we start ZooKeeper (zkServer.cmd) then Kafka server (kafka-server-start.bat ), batch files are located in the appropriate bin folders, there are utilities.
Create a theme Kafka utility, part of
kafka-topics.bat --create --zookeeper localhost: 2181 --replication-factor 1 --partitions 1 --topic out-topichere we specify the zookeeper server, replication-factor is the number of replicas of the message log, partitions - the number of sections in the topic (more on this below) and the topic itself is “out-topic”.
For simple testing, you can use the included kafka-console-consumer and kafka-console-producer applications, but I'll make my own. Subscribers in practice are grouped together, this will allow different applications to read messages from the topic in parallel.
For each application, there will be an organized queue, reading from which it performs the movements of the pointer of the last message read (offset), this is called reading commit. And so if the publisher sends a message to the topic, it will be guaranteed to be read by the recipient of this topic if it is running or as soon as it is connected. And if there are different clients (client.id) that read from the same topic, but in different groups, then they will receive messages regardless of each other and at the time when they are ready.
So you can submit a follower of messages and independent reading of their consumers from one topic.
But there is a situation when messages in a subject can begin to arrive faster than to leave, i.e. consumers process them longer. To do this, the topic can provide partitions and run consumers in the same group for this topic.
Then there will be a load distribution and not all messages in the subject and group will go through one consumer. And then the strategy will be chosen, how to distribute messages into sections. There are several strategies: round-robin is in a circle, according to a hash of the key value, or an explicit indication of the section number where to write. Subscribers in this case are distributed evenly across sections. If, for example, there are more subscribers in the group than sections, then someone will not receive the message. Thus, partitions are made to improve scalability.
For example, after creating a theme with one section, I changed to two sections.
kafka-topics.bat --zookeeper localhost: 2181 --alter --topic out-topic --partitions 2I launched my publisher and two subscribers in the same group on the same topic (examples of java programs will be below). Configuring the group names and client IDs is not necessary, Kafka takes it upon himself.
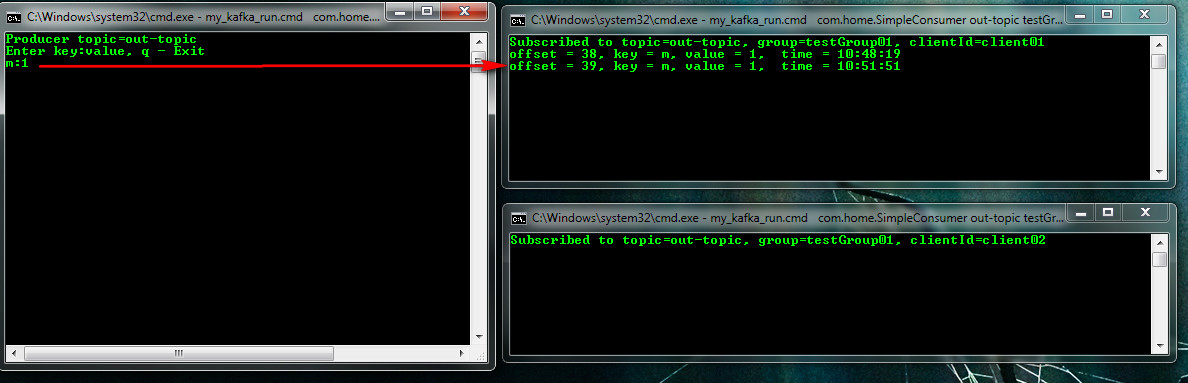
my_kafka_run.cmd com.home.SimpleProducer out-topic (publisher)Starting to enter a key in the publisher of a key: the value can be observed who gets them. For example, according to the key distribution strategy of the key hash, the message m: 1 got into the client01 client
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01 (first subscriber)
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client02 (second subscriber)
and message n: 1 to client02
If I start typing without specifying the key: value pairs (I did this in the publisher), the strategy will be selected in a circle. The first message "m" got client01, and already three times client02.
And another option with the indication of the section, for example in this format key: value: partition
Earlier in the hash strategy, m: 1 went to another client (client01), now with the explicit indication of the section (# 1, they are numbered from 0) to client02.
If you start a subscriber with a different group name testGroup02 and for the same topic, the messages will go in parallel and independently to the subscribers, i.e. if the first one is read and the second is not active, then it will read as soon as it becomes active.
You can see the descriptions of groups, topics, respectively:
kafka-consumer-groups.bat --bootstrap-server localhost: 9092 --describe --group testGroup01
kafka-topics.bat --describe --zookeeper localhost: 2181 --topic out-topic
SimpleProducer Code
public class SimpleProducer { public static void main(String[] args) throws Exception { // Check arguments length value if (args.length == 0) { System.out.println("Enter topic name"); return; } //Assign topicName to string variable String topicName = args[0].toString(); System.out.println("Producer topic=" + topicName); // create instance for properties to access producer configs Properties props = new Properties(); //Assign localhost id props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //Set acknowledgements for producer requests. props.put("acks", "all"); //If the request fails, the producer can automatically retry, props.put("retries", 0); //Specify buffer size in config props.put("batch.size", 16384); //Reduce the no of requests less than 0 props.put("linger.ms", 1); //The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer(props); BufferedReader br = null; br = new BufferedReader(new InputStreamReader(System.in)); System.out.println("Enter key:value, q - Exit"); while (true) { String input = br.readLine(); String[] split = input.split(":"); if ("q".equals(input)) { producer.close(); System.out.println("Exit!"); System.exit(0); } else { switch (split.length) { case 1: // strategy by round producer.send(new ProducerRecord(topicName, split[0])); break; case 2: // strategy by hash producer.send(new ProducerRecord(topicName, split[0], split[1])); break; case 3: // strategy by partition producer.send(new ProducerRecord(topicName, Integer.valueOf(split[2]), split[0], split[1])); break; default: System.out.println("Enter key:value, q - Exit"); } } } } } SimpleConsumer code
public class SimpleConsumer { public static void main(String[] args) throws Exception { if (args.length != 3) { System.out.println("Enter topic name, groupId, clientId"); return; } //Kafka consumer configuration settings final String topicName = args[0].toString(); final String groupId = args[1].toString(); final String clientId = args[2].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", groupId); props.put("client.id", clientId); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); //props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); //props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); //Kafka Consumer subscribes list of topics here. consumer.subscribe(Arrays.asList(topicName)); //print the topic name System.out.println("Subscribed to topic=" + topicName + ", group=" + groupId + ", clientId=" + clientId); SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss"); // looping until ctrl-c while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s, time = %s \n", record.offset(), record.key(), record.value(), sdf.format(new Date())); } } } To run my programs, I made a batch file - my_kafka_run.cmd
@echo off set CLASSPATH="C:\Project\myKafka\target\classes"; for %%i in (C:\kafka_2.11-1.1.0\libs\*) do ( call :concat "%%i" ) set COMMAND=java -classpath %CLASSPATH% %* %COMMAND% :concat IF not defined CLASSPATH ( set CLASSPATH="%~1" ) ELSE ( set CLASSPATH=%CLASSPATH%;"%~1" ) startup example:
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup02 client01
Kafka streams
So, the streams in Kafka are a sequence of events that are obtained from a topic, over which you can perform certain operations, transformations and then return the result further, for example, to another topic or save it to a database, generally anywhere. Operations can be either for example filtering (filter), transformation (map), or aggregation (count, sum, avg). To do this, there are corresponding classes KStream, KTable, where KTable can be represented as a table with current aggregated values that are constantly updated as new messages arrive in the topic. How does this happen?
For example, the publisher writes to the subject of the event (message), Kafka saves all messages in the message log, which has a retention policy (for example, 7 days). For example, a quote change event is a stream, then we want to know the average value, then we will create a Stream that will take the history from the magazine and calculate the average, where the key is the share, and the value is the average (this is a table with a status). There is a feature here - aggregation operations, unlike operations, for example, filtering, retain state. Therefore, the newly received messages (events) in the topic will be subject to calculation, and the result will be saved (state store), then the newly received messages will be written to the log, Stream will process them, add changes to the already saved state. Filtering operations do not require state preservation. And here, too, stream will do this regardless of the publisher. For example, the publisher writes messages, and the program - stream does not work at this time, nothing is lost, all messages will be saved in the log and as soon as the program-stream becomes active, it will do the calculations, save the state, perform the offset for the messages read (it says they have been read) and in the future it will not return to them, moreover, these messages will leave the log (kafka-logs). It seems that the main thing is that the log (kafka-logs) and its storage policy allow this. By default, the state of Kafka Stream is stored in RocksDB. The message log and everything related to it (themes, offsets, flows, clients, etc.) is located along the path specified in the “log.dirs = kafka-logs” parameter of the “config \ server.properties” configuration file, and the same log storage policy is specified. "Log.retention.hours = 48". Log example
And the path to the database with stream states is specified in the application parameter.
config.put (StreamsConfig.STATE_DIR_CONFIG, "C: /kafka_2.11-1.1.0/state");States are stored by application IDs independently ( StreamsConfig.APPLICATION_ID_CONFIG ). Example
Now let's check how Stream works. Prepare the Stream application from the example, which is the delivery (with some refinement for the experiment), which counts the number of identical words and the application is the publisher and the subscriber. Will write in the topic in-topic
my_kafka_run.cmd com.home.SimpleProducer in-topicThe Stream application will read this topic count count of identical words, it is not explicit for us to save the state and redirect out-topic to another topic. Here I want to clarify the relationship of the log and state (state store). And so ZooKeeper and Kafka server are running. I launch Stream with App-ID = app_01
my_kafka_run.cmd com.home.KafkaCountStream in-topic app_01publisher and subscriber accordingly
my_kafka_run.cmd com.home.SimpleProducer in-topicHere they are:
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01
We start to enter words and see their counting with an indication of which Stream App-ID counted them
The work will go independently, you can stop the Stream and continue to write in the topic, he then at the start will count. And now we will connect the second Stream with App-ID = app_02 (this is also an application, but with a different ID), it will read the log (a sequence of events that is saved according to the Retention policy), count the number, save the status and issue the result. Thus, two streams starting to work at different times came to the same result.
And now let's imagine our magazine is outdated (Retention policy) or we deleted it (which is what needs to be done) and connect the third stream with App-ID = app_03 (I stopped Kafka for this, deleted kafka-logs and started again) and introduce a new topic the message and see the first (app_01) stream continued counting and the new third started from scratch.
If we then run the app_02 stream, it will catch up with the first one and they will be equal in values. From the example, it became clear how Kafka processes the current log, adds to the previously saved state and so on.
KafkaCountStream code
public class KafkaCountStream { public static void main(final String[] args) throws Exception { // Check arguments length value if (args.length != 2) { System.out.println("Enter topic name, appId"); return; } String topicName = args[0]; String appId = args[1]; System.out.println("Count stream topic=" + topicName +", app=" + appId); Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, appId); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 2000); config.put(StreamsConfig.STATE_DIR_CONFIG, "C:/kafka_2.11-1.1.0/state"); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> textLines = builder.stream(topicName); // State store KTable<String, Long> wordCounts = textLines .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+"))) .groupBy((key, word) -> word) .count(); // out to another topic KStream<String, String> stringKStream = wordCounts.toStream() .map((k, v) -> new KeyValue<>(appId + "." + k, v.toString())); stringKStream.to("out-topic", Produced.with(Serdes.String(), Serdes.String())); KafkaStreams streams = new KafkaStreams(builder.build(), config); // additional to complete the work final CountDownLatch latch = new CountDownLatch(1); // attach shutdown handler to catch control-c Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") { @Override public void run() { System.out.println("Kafka Stream close"); streams.close(); latch.countDown(); } }); try { System.out.println("Kafka Stream start"); streams.start(); latch.await(); } catch (Throwable e) { System.exit(1); } System.out.println("Kafka Stream exit"); System.exit(0); } } The Kafka theme is very extensive, I made the first general presentation for myself :-)
Materials:
How to start and where to start
Source: https://habr.com/ru/post/354486/
All Articles