Splunk 7.1. What's new? New web interface, integration with Apache Kafka and much more ...

A few days ago, Splunk released a new release of its Splunk 7.1 platform in which, probably, the most anticipated change has occurred in the last few years - yes, the graphical interface has completely changed. In this article we will tell about the main innovations and improvements of the platform. What else is new besides GUI? Look under the cat.
Interface
As we have said, yes, and probably this is the most noticeable change, Splunk completely changed the interface, even changing the page with an error. Appearance becomes more modern and stylish. Elements of diagrams and event viewing have been fixed to improve the readability of information. After updating it is a bit unusual, but after using the system for a couple of days you get used to it and start to like it. Yes, really like it.
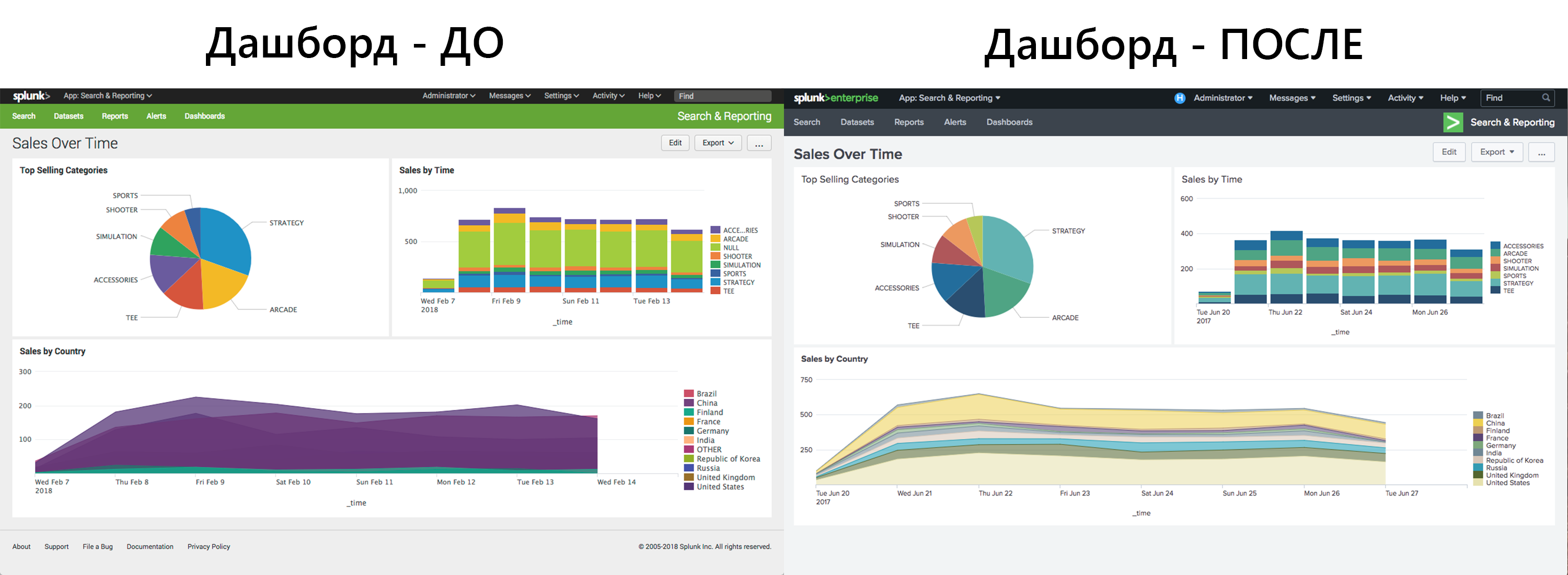
')
Integration with Apache Kafka
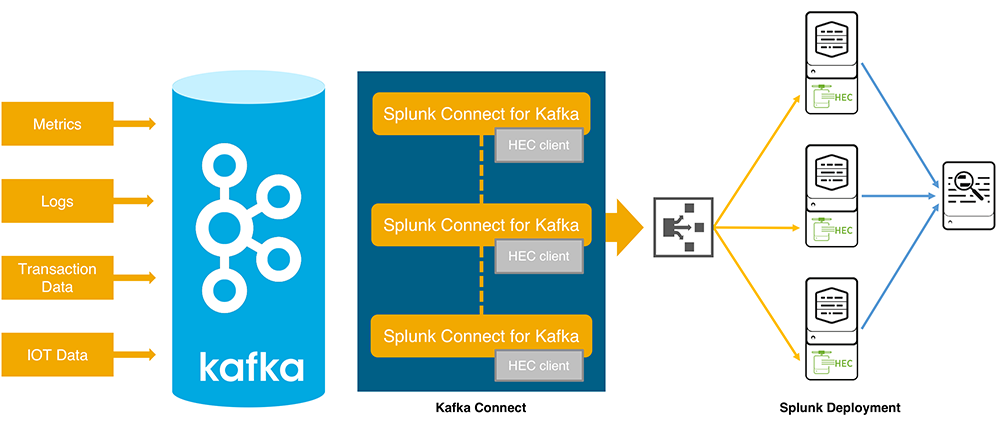
Splunk has a connector for Kafka. Now you can stream your data from Kafka to your Splunk installation using Splunk HTTP Event Collector. Also in this release, Splunk offers the ability to integrate with AWS Kinesis Firehose, but in our realities this is less interesting. A detailed description of the functionality and instructions for deployment are available here .
Access control
Splunk began to seriously think about the security of your platform and starting with this release you will forget about the admin / changeme combination . Now you will be prompted to enter your password during the installation phase with the requirement of 8 characters.

Also in the new version in order to increase security, the opportunity to configure extended account policies has been added. Now the Splunk administrator can set password complexity requirements, expiration date, blocking after repeated unsuccessful login attempts.
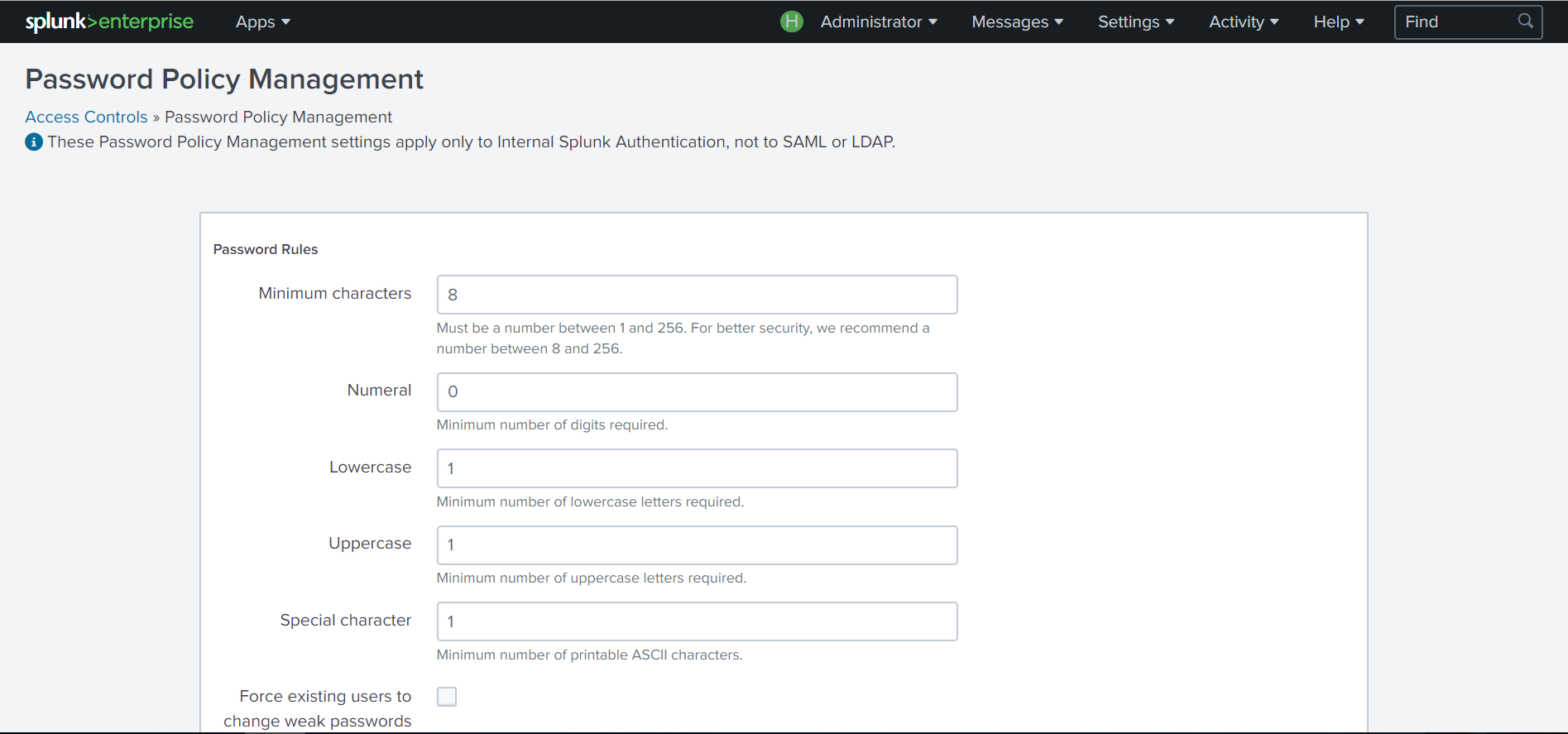
Splunk component status monitoring
Hooray! Splunk is becoming more sociable. Now, when something breaks during the collection / parsing / indexing stage, he himself will try to tell us about it and we don’t need to look in the _internal log and look for what happened.
Splunk version 7.1 has the ability to monitor the health of Splunk components. If there are any deviations, Splunk can indicate the cause, error messages and give advice to solve the problem. The health status is indicated in the menu bar.


Improving metrics and new SPL teams
In release 7.0 Splunk, a new type of data indexing appeared - metrics. You can read more about them in our Splunk 7.0 review . Using metrics enhances the processing of search queries and reduces the overall load on the system. But in the first release, the toolkit for working with metrics was somewhat limited.
In the new version, the mstats command has been improved, and the mcollect command has been added .
1. Improving mstats
In 7.0 we could calculate only one indicator in this command. And in order to calculate several, we had to use additional tools that complicated the search query.
For example:
| mstats avg(_value) as "Average_speed" WHERE metric_name="car.speed" AND index=car_data span=1m
| appendcols [
| mstats max(_value) as "Max_speed" WHERE metric_name="car.speed" AND index=car_data span=1m ]In version 7.1, it became possible to calculate several indicators at once in one team.
| mstats avg(_value) as "Average_speed" max(_value) as "Max_speed" WHERE metric_name="car.speed" AND index=car_data span=1m
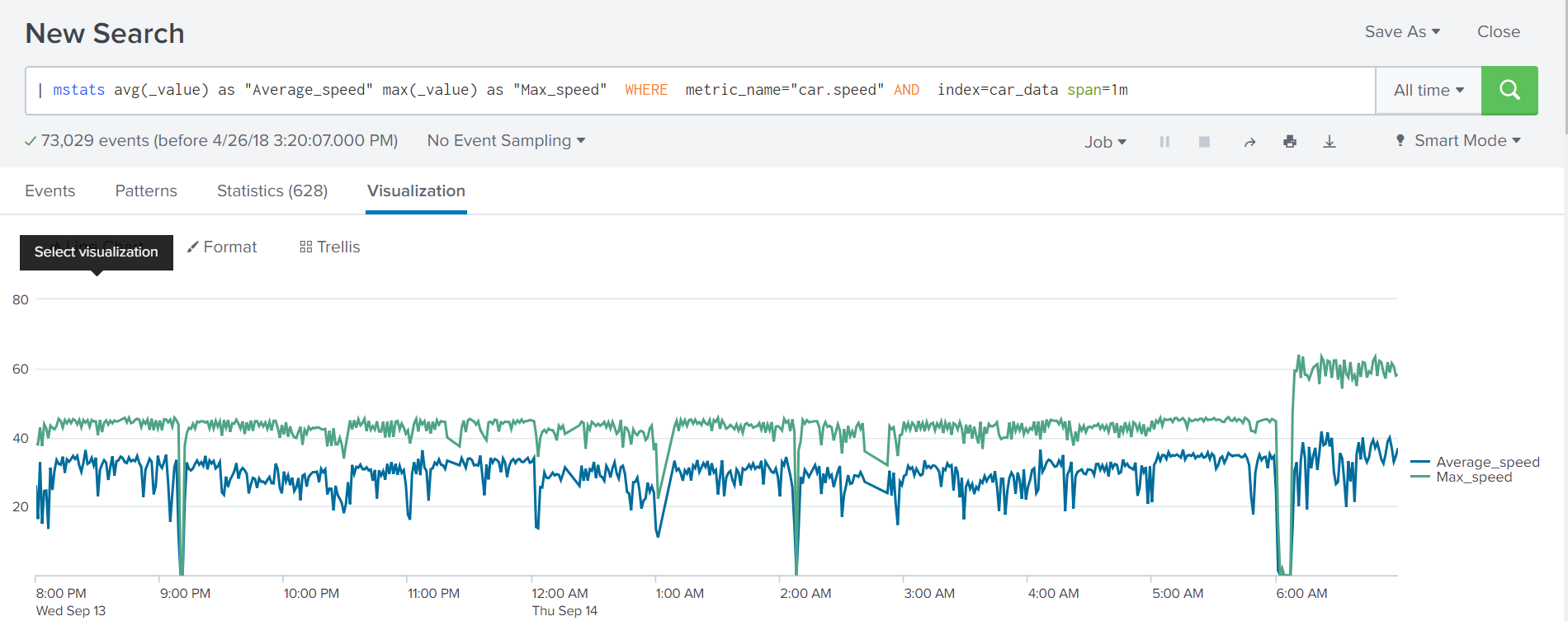
2. New mcollect command
With the mcollect command , we can convert search results into metrics. Before executing the command, it is necessary to create a new index for the metrics in which we will save the indicators.
For example, create the error number metric:
ERROR | stats count BY type | rename count AS _value type AS metric_name | mcollect index=my_metric_indexAnd yes, they forgot to say, they increased the speed of working with metrics 10 times. Now search by metrics is even faster!
Machine Learning Toolkit Update
The ML Toolkit has also been updated, which allows you to get answers from your data to important questions about anomalies, forecasts and clustering, using various machine learning algorithms.
X-means
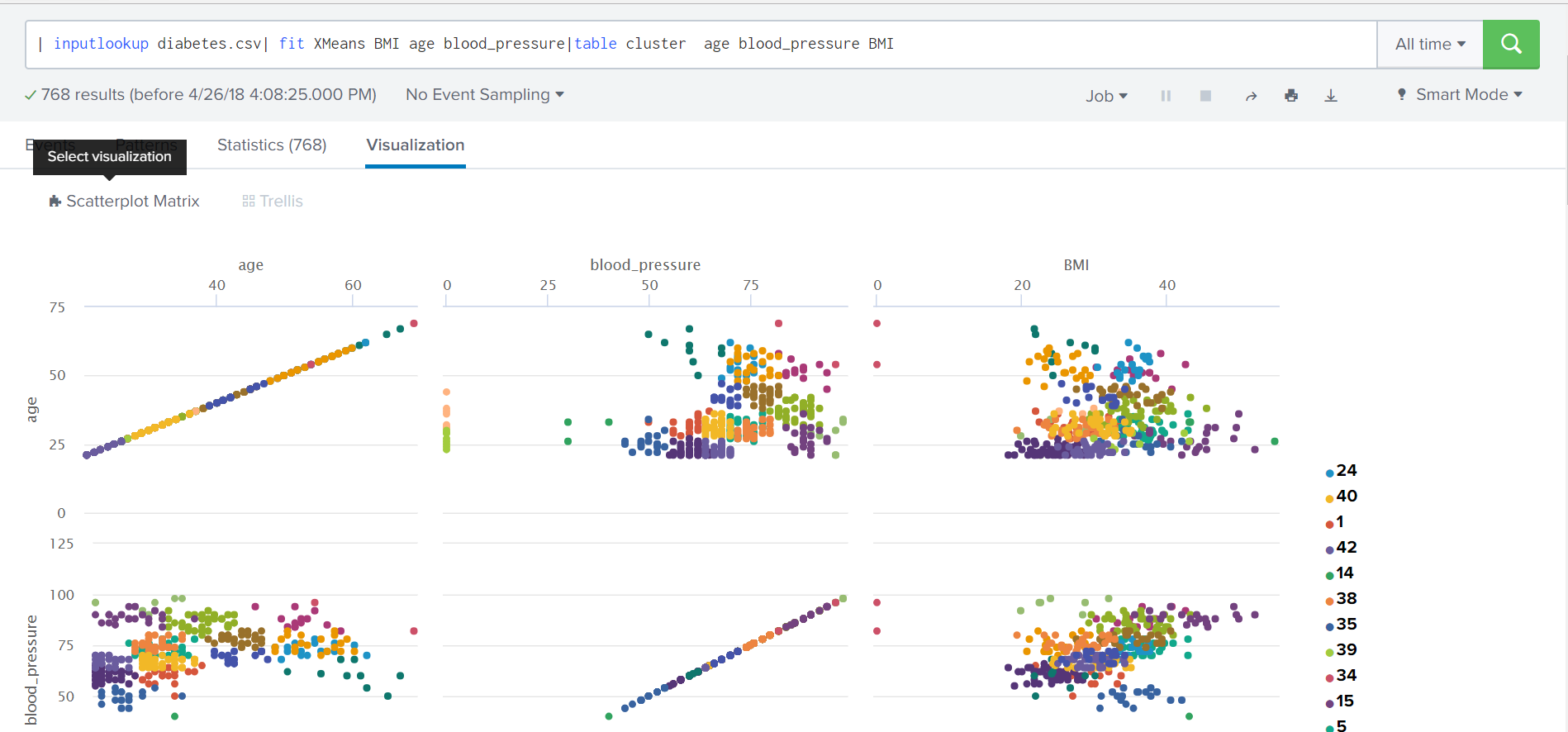
The first thing to note is the addition of the new X-means clustering algorithm, which differs from the standard clustering algorithm, K-means, in that it automatically determines the optimal number of clusters according to the Bayesian information criterion. The X-means algorithm is convenient to use when you do not know in advance how many clusters you can split the data.
Management of models and experiments
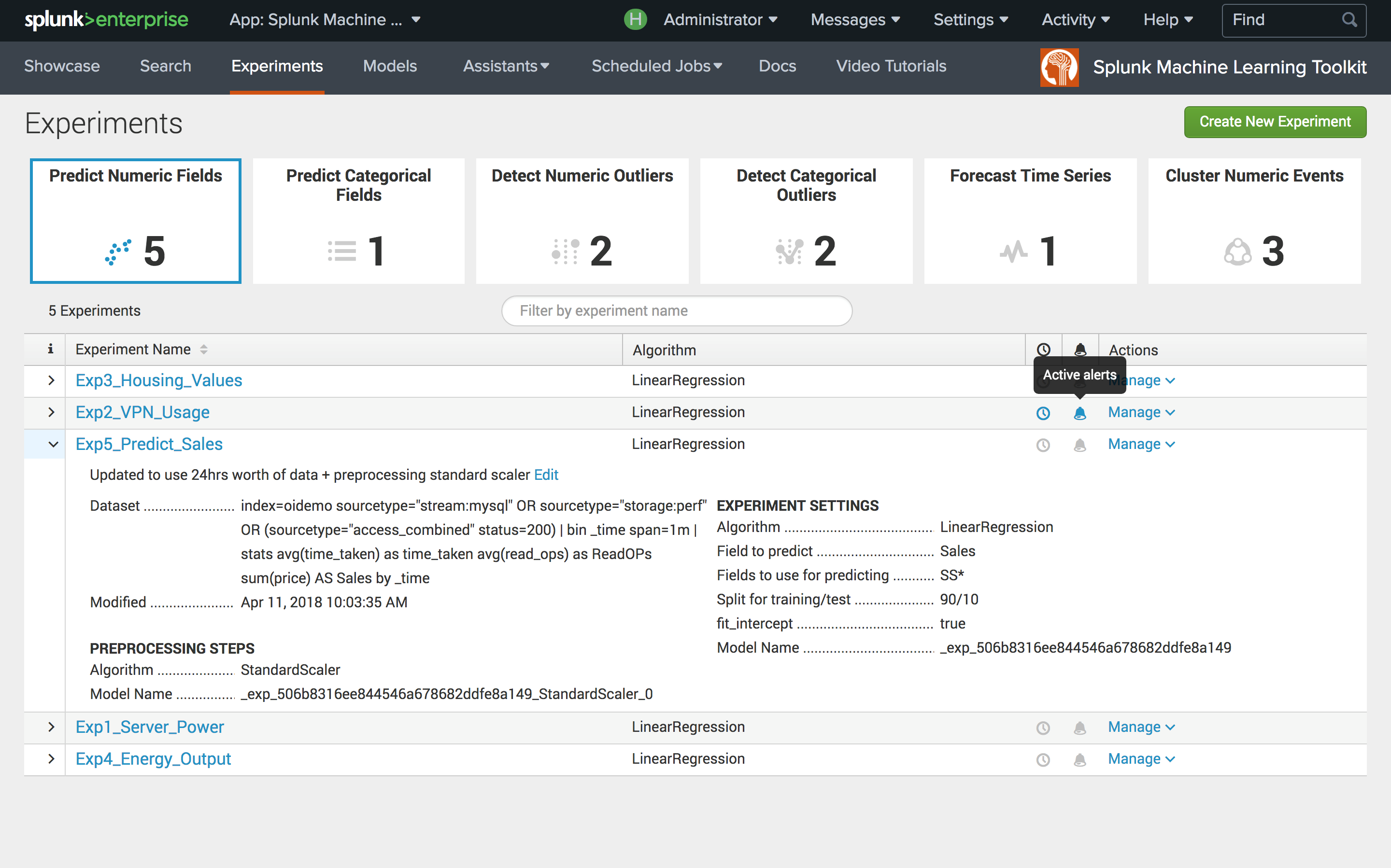
Also, a single interface appeared that allows you to view existing models and their parameters, configure access to experiments for various user roles, set alerts, get a history of experiments and alerts.
Conclusion
Of course, in the new release there are many more innovations and features, such as: Diagnostic UI , optimization of work with clusters: the impact on the system operation during updates, restarts, regular scheduled search queries and many other changes is minimized. As part of this article, we tried to tell you about the most interesting innovations that anyone who uses Splunk may encounter.
Additionally
For the most in-depth study of the issue is to install the application Splunk Enterprise 7.1 Overview , as well as watch the official video release.
Also, do not forget that for any question regarding Splunk : its implementation, updating, developing applications on it, adding new, difficult to index events and everything else we can help you.
We are the official Premier Splunk Partner .

PS
On June 28, 2018, “ Splunk Getting Started ” will be taught in Moscow , where in 6 hours the participants will receive a theoretical base and practical skills for working in Splunk. Learn more about learning and register at this link .
Source: https://habr.com/ru/post/354474/
All Articles