SmartMailHack. Winners history in the task Name Entity Recognition
Last weekend (April 20-22), a student hackathon on machine learning was held in the office of Mail.ru Group. Hakaton brought together students from different universities, different courses and, most interestingly, from different directions: from programmers to security specialists.

Mail.ru Mail.ru provided three tasks:
')
It was allowed to choose one task from the first two, and in the solution of the third one could participate at will. We chose the second task, because we understood that the first one would definitely benefit from neurons, with whom we had little experience. But with the second task there was hope that the classic ML would shoot. In general, we really liked the idea of separation of tasks, because during the hackathon we could discuss solutions and ideas with non-competing teams.
The hackathon is notable for the fact that there was no public leaderboard, and the model was tested at the end of the hackathon in a closed dataset.
We were provided with postal letters from the stores confirming the orders made or sending out promotions. In addition to the original emails, a script was provided for parsing them and the marked results of his work, which was a dataset for training models.
The letter is parsed line by line, each line is divided into tokens, and each token is assigned a label.
In the markup file, first comes the parsed line beginning with the "#" character, then the result of parsing in the form of three columns: (line number, token, class label).
Tags are of the following types:
Mandatory prefix "B-" indicates the beginning of the token in the sentence. To evaluate the model, we used the f1-metric for all labels except OUT.
The distribution of tags in the training dataset is as follows:
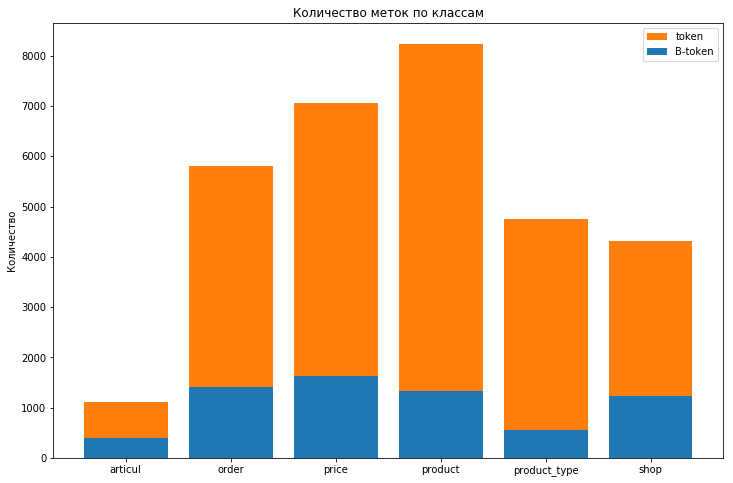
OUT class labels almost 580k
There is a strong imbalance of classes, and it does not make sense to take the OUT label into account for assessing the quality of the model. To take into account the imbalance of classes, we added the parameter class_weight = 'balanced' to the forest. Although this reduced the score on the train and on the test (from 0.27 and 0.15 to 0.09 and 0.08), however, it made it possible to get rid of retraining (the difference between these indicators decreased).
To represent words as a vector, fastText word embedding for the Russian language was used, which allowed us to represent the token as a vector of 300 values. While part of the team was trying to write a neuron, standard classification algorithms were tried, such as logreg, random forest, knn and xgboost. According to the results of the tests, a random forest was chosen as a backup, in case the neuron does not fly up. The choice was largely justified by a good learning rate and model prediction (which greatly saved at the end of the competition) with satisfactory quality compared to other models.
Having experience of passing the course mlcourse_open from ODS, we understood that only high-quality features can significantly increase the score, and the remaining time spent on generating them. The first thing that came to mind was to add simple attributes, such as a token index in a sentence; the length of the token; whether the token is alphanumeric; consists only of uppercase or lowercase letters, etc. This gave an increase in the metric f1 to 0.21 on the test sample. Further study dataset concluded that the context is important, and depending on it, two identical tokens could have different class labels. To take into account the context, they took a window - added the previous and the following tokens to the vector of signs. This increased the score to 0.55 on the train and 0.43 on the test. On the last night of the hackathon, we tried to enlarge the window and shove more signs into 12 gigabytes of RAM. As it turned out, it does not cram. Having abandoned these attempts, we began to think what other signs could be added to the model. Turned to the library pymorphy2, but did not have time to screw it properly.
Before issuing the test dataset and the first submission, there remained a couple of hours. After issuing the dataset, an hour was given to make predictions and send to the organizers - this was the first submit. After that, another hour was given for a second attempt. So, it's time to start doing preprocessing and train the forest for the entire sample. Also, we still have faith in neuron. The preprocessing and training of forests from 50 trees were surprisingly fast: 10 minutes for preprocessing (together with a five-minute dictionary loading for embedding) and another 10 minutes for training the forest on a matrix of size (609101, 906). This speed pleased us, because it indicated that we could quickly correct the model to the second submission and re-train it. The trained forest showed a score of 0.59 for the entire sample. Considering the previous testing of the model on a deferred sample, we hoped to show a result of at least 0.4 on the leaderboard, well, or at least at least 0.3.
Having received a test dataset of ~ 300,000 tokens and having already trained model, we literally made a prediction in just 2 minutes. Became the first and received a score of 0.2997. Waiting for the results of other teams and thinking about plans to improve their own model, we got the idea to add to the training sample the just-marked test. Firstly, this did not contradict the rules, since manual marking was forbidden, and secondly, we ourselves wondered what would happen. At this time, we learned the results of other teams - they were all behind us, to which we were pleasantly surprised. However, the result closest to us was 0.28, which gave the opponents a chance to get around us. We were also not sure that they did not have trumps up their sleeve. The second hour passed intensely, the teams kept submitting to the last, and our idea with an increase in the training sample failed: the laptop did not like the idea of cramming 1.5 times more data into its memory, and responded with freezes and MemoryError as a sign of its protest.
When the time was up, the final leaderboard appeared, some teams improved the result, and some got worse, but we were still in the first place. However, the answer was to be validated: it was necessary to show the working model and make a prediction before the organizers, and we just had a reloaded laptop in which the trees were trained, and the model was not saved. What to do? Here the organizers went to meet us and agreed to wait for the model to learn and make predictions. However, there was a snag: the forest was random, we did not fix the SEED, and the accuracy of the prediction had to be confirmed to the last digit. We hoped for the best, and also started training on the second laptop, where the dictionary was already loaded. At this time, the organizers carefully investigated the data and code, asked about the model, features. The laptop did not stop to get on your nerves and sometimes it hung for a few minutes, so that even the time did not change. When the training was completed, they made a second prediction and sent it to the organizers. At this time, the second laptop completed the training, and the predictions on the training sample on both laptops matched perfectly, which increased our confidence in the successful validation of the result. And now, after a few seconds, the organizers congratulate on the victory and shake hands :)
We had a great weekend at the Mail.Ru Group office, listened to interesting reports on ML and DL from the Mail team. We enjoyed endless supplies of cookies, milk chocolate (milk, however, turned out to be a finite resource, but replenishable) and pizza, as well as an unforgettable atmosphere and interaction with interesting people.
If we consider the problem itself and our experience, we can draw the following conclusions:

The EpicTeam team is the winners in the NER task. From left to right:
Mail.ru Mail.ru provided three tasks:
')
- Recognition and classification of company logos. This task is useful in anti-spam for identifying phishing emails.
- The definition of the text of the letter, which of its parts belong to certain categories. Named Entity Recognition (NER) recognition task
- The implementation of the last task was not regulated. It was necessary to invent and make a prototype of a new useful function for Mail. Evaluation criteria were utility, quality of implementation, the use of ML and high features.
It was allowed to choose one task from the first two, and in the solution of the third one could participate at will. We chose the second task, because we understood that the first one would definitely benefit from neurons, with whom we had little experience. But with the second task there was hope that the classic ML would shoot. In general, we really liked the idea of separation of tasks, because during the hackathon we could discuss solutions and ideas with non-competing teams.
The hackathon is notable for the fact that there was no public leaderboard, and the model was tested at the end of the hackathon in a closed dataset.
Task Description
We were provided with postal letters from the stores confirming the orders made or sending out promotions. In addition to the original emails, a script was provided for parsing them and the marked results of his work, which was a dataset for training models.
The letter is parsed line by line, each line is divided into tokens, and each token is assigned a label.
Sample Markup Data
# [](http://t.adidas-news.adidas.com/res/adidas-t/spacer.gif)
39 []( OUT
39 http OUT
39 :// OUT
39 t OUT
39 . OUT
39 adidas OUT
39 - OUT
39 news OUT
39 . OUT
39 adidas OUT
39 . OUT
39 com OUT
39 / OUT
39 res OUT
39 / OUT
39 adidas OUT
39 - OUT
39 t OUT
39 / OUT
39 spacer OUT
39 . OUT
39 gif OUT
39 ) OUT
39 B-PRICE
39 PRICE
39 PRICE
In the markup file, first comes the parsed line beginning with the "#" character, then the result of parsing in the form of three columns: (line number, token, class label).
Tags are of the following types:
- Marking of goods: B-ARTICUL, ARTICUL
- Order and its number: B-ORDER, ORDER
- Total order amount: B-PRICE, PRICE
- Ordered products: B-PRODUCT, PRODUCT
- Item Type: B-PRODUCT_TYPE, PRODUCT_TYPE
- Seller: B-SHOP, SHOP
- All other tokens: OUT
Mandatory prefix "B-" indicates the beginning of the token in the sentence. To evaluate the model, we used the f1-metric for all labels except OUT.
Score for logrega as baseline
Training time 157.34269189834595 s
================================================TRAIN======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.7981220657276995 Tokenwise recall: 0.188470066518847 Tokenwise f-measure: 0.30493273542600896
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.9154929577464789 Tokenwise recall: 0.04992319508448541 Tokenwise f-measure: 0.09468317552804079
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.6538461538461539 Tokenwise recall: 0.0160075329566855 Tokenwise f-measure: 0.03125000000000001
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.5172413793103449 Tokenwise recall: 0.02167630057803468 Tokenwise f-measure: 0.04160887656033287
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7852941176470588 Tokenwise recall: 0.05550935550935551 Tokenwise f-measure: 0.1036893203883495
================================================TEST=======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.8064516129032258 Tokenwise recall: 0.205761316872428 Tokenwise f-measure: 0.3278688524590164
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.8666666666666667 Tokenwise recall: 0.05263157894736842 Tokenwise f-measure: 0.09923664122137404
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.4 Tokenwise recall: 0.0071174377224199285 Tokenwise f-measure: 0.013986013986013988
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.3333333333333333 Tokenwise recall: 0.011627906976744186 Tokenwise f-measure: 0.02247191011235955
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7528089887640449 Tokenwise recall: 0.05697278911564626 Tokenwise f-measure: 0.10592885375494071
The distribution of tags in the training dataset is as follows:
OUT class labels almost 580k
There is a strong imbalance of classes, and it does not make sense to take the OUT label into account for assessing the quality of the model. To take into account the imbalance of classes, we added the parameter class_weight = 'balanced' to the forest. Although this reduced the score on the train and on the test (from 0.27 and 0.15 to 0.09 and 0.08), however, it made it possible to get rid of retraining (the difference between these indicators decreased).
Models
To represent words as a vector, fastText word embedding for the Russian language was used, which allowed us to represent the token as a vector of 300 values. While part of the team was trying to write a neuron, standard classification algorithms were tried, such as logreg, random forest, knn and xgboost. According to the results of the tests, a random forest was chosen as a backup, in case the neuron does not fly up. The choice was largely justified by a good learning rate and model prediction (which greatly saved at the end of the competition) with satisfactory quality compared to other models.
Having experience of passing the course mlcourse_open from ODS, we understood that only high-quality features can significantly increase the score, and the remaining time spent on generating them. The first thing that came to mind was to add simple attributes, such as a token index in a sentence; the length of the token; whether the token is alphanumeric; consists only of uppercase or lowercase letters, etc. This gave an increase in the metric f1 to 0.21 on the test sample. Further study dataset concluded that the context is important, and depending on it, two identical tokens could have different class labels. To take into account the context, they took a window - added the previous and the following tokens to the vector of signs. This increased the score to 0.55 on the train and 0.43 on the test. On the last night of the hackathon, we tried to enlarge the window and shove more signs into 12 gigabytes of RAM. As it turned out, it does not cram. Having abandoned these attempts, we began to think what other signs could be added to the model. Turned to the library pymorphy2, but did not have time to screw it properly.
Submission
Before issuing the test dataset and the first submission, there remained a couple of hours. After issuing the dataset, an hour was given to make predictions and send to the organizers - this was the first submit. After that, another hour was given for a second attempt. So, it's time to start doing preprocessing and train the forest for the entire sample. Also, we still have faith in neuron. The preprocessing and training of forests from 50 trees were surprisingly fast: 10 minutes for preprocessing (together with a five-minute dictionary loading for embedding) and another 10 minutes for training the forest on a matrix of size (609101, 906). This speed pleased us, because it indicated that we could quickly correct the model to the second submission and re-train it. The trained forest showed a score of 0.59 for the entire sample. Considering the previous testing of the model on a deferred sample, we hoped to show a result of at least 0.4 on the leaderboard, well, or at least at least 0.3.
Having received a test dataset of ~ 300,000 tokens and having already trained model, we literally made a prediction in just 2 minutes. Became the first and received a score of 0.2997. Waiting for the results of other teams and thinking about plans to improve their own model, we got the idea to add to the training sample the just-marked test. Firstly, this did not contradict the rules, since manual marking was forbidden, and secondly, we ourselves wondered what would happen. At this time, we learned the results of other teams - they were all behind us, to which we were pleasantly surprised. However, the result closest to us was 0.28, which gave the opponents a chance to get around us. We were also not sure that they did not have trumps up their sleeve. The second hour passed intensely, the teams kept submitting to the last, and our idea with an increase in the training sample failed: the laptop did not like the idea of cramming 1.5 times more data into its memory, and responded with freezes and MemoryError as a sign of its protest.
When the time was up, the final leaderboard appeared, some teams improved the result, and some got worse, but we were still in the first place. However, the answer was to be validated: it was necessary to show the working model and make a prediction before the organizers, and we just had a reloaded laptop in which the trees were trained, and the model was not saved. What to do? Here the organizers went to meet us and agreed to wait for the model to learn and make predictions. However, there was a snag: the forest was random, we did not fix the SEED, and the accuracy of the prediction had to be confirmed to the last digit. We hoped for the best, and also started training on the second laptop, where the dictionary was already loaded. At this time, the organizers carefully investigated the data and code, asked about the model, features. The laptop did not stop to get on your nerves and sometimes it hung for a few minutes, so that even the time did not change. When the training was completed, they made a second prediction and sent it to the organizers. At this time, the second laptop completed the training, and the predictions on the training sample on both laptops matched perfectly, which increased our confidence in the successful validation of the result. And now, after a few seconds, the organizers congratulate on the victory and shake hands :)
Total
We had a great weekend at the Mail.Ru Group office, listened to interesting reports on ML and DL from the Mail team. We enjoyed endless supplies of cookies, milk chocolate (milk, however, turned out to be a finite resource, but replenishable) and pizza, as well as an unforgettable atmosphere and interaction with interesting people.
If we consider the problem itself and our experience, we can draw the following conclusions:
- Do not chase the fashion and immediately apply the DL, perhaps the classic models can take off pretty well.
- Generate more useful features, and only then optimize the model and select hyper parameters.
- Fix SEED and save your models, and also make backups :)
The EpicTeam team is the winners in the NER task. From left to right:
- Leonid Zharikov, MSTU. Bauman, student TehnoPark.
- Andrei Atamanyuk, MSTU. Bauman, student TehnoPark.
- Milia Fatkhutdinova, REU them. Plekhanov.
- Andrei Pashkov, MEPhI NRNU, student of TechnoAtom.
Source: https://habr.com/ru/post/354456/
All Articles