Backend optimization when switching to api-based architecture

Hi, Habr.
At a recent mitup at the Tutu office, I talked about how we, as part of superjob.ru's redesign , made the transition from a monolithic application to an api-based architecture with beautiful single page applications on ReactJS on the front and a smart PHP application on the backend. In this article, I would like to tell you more about how we optimized our backend application so that it really becomes smart.
')
Interested - I ask under the cat.
Initial setup
We had a monolithic application on Yii1. Some symfony components have been added to Yii: for example, DI, Doctrine, EventDispatcher, and other magic. All this stuff spun under PHP 7.1.
As part of the site redesign, we decided to divide the monolith into two applications: one was responsible for the business logic and API, and the other - exclusively for rendering. Since the volume of the Superjob codebase inspires respect for experienced fighters, and fear for inexperienced ones, seditious thoughts of rewriting everything from scratch to go / again from scratch have been rejected. As the custodian of business logic and API provider, it was decided to use part of the monolith on Yii, and for rendering, the new application had to be responsible for ReactJS. Communicate with each other applications should have been through the JSON API . So we wanted to get the following setup:

To teach the application on Yii to talk on the JSON API, after long deliberation, we implemented our solution with the original name Mapper, which was already an article on Habré .
Mapper allowed us to describe model conversions in the essence of the JSON API using yaml-configs, which were then compiled into php-code. It looked like this:

This allowed us to write significantly less code with our hands, and also guaranteed uniformity of entities of a certain type in the API.
In addition, the Mapper took over the automation of many things, including:
- work with JSON API transport layer,
- interaction with the database (ActiveRecord, Doctrine),
- communication with services and DI,
- access check,
- validation of models
- documentation generation
- anything else that is very lazy to do with your hands.
Thanks to Mapper, we were able to implement as quickly as possible new endpoints, which were immediately picked up by the front-end application, the development of which proceeded in parallel.
Optimization
After analyzing the first results of the front-end application, we found that it generates an average of about 10 requests to the API per page , which means we should seriously think about optimizing the backend: the slower the API runs, the more the UX application suffers, requests consistently.
Mapper optimization
We decided to start from the most obvious - from the core of our API.
First of all, we made sure that Mapper did not perform the same work several times. Often in the API response the same entity may be mentioned several times (for example, several vacancies with a link to one company, several resumes belonging to one person, and so on), but we absolutely need to process the same thing several times. Therefore, we taught the Mapper to quickly understand with which models he was already working with in the framework of the current request, and to eliminate doubles. It would seem that there is difficult? If we know that models of a certain type that have a unique value in a certain property / getter can be transferred to us, the problem is solved trivially. But in a more general case, when neither the type nor the unique attribute is guaranteed to us, and the structure transferred to us can be a tree, everything becomes much more complicated. In the case of Mapper, we solved the duplicate search problem using the spl_object_hash combination and additional checks specific to our models. However, I want to warn the young Padawans who wish to repeat our path: do not underestimate the
To eliminate duplicates, we took another step: since the JSON API allows the client to request hierarchical relationships of entities, for example, the following query of connections will be legitimate: user.resume.user.resume.user.resume . Handling such links is a real pain, so we taught the Mapper how to handle such cases. Links that refer to each other were marked in the config with a special attribute, and when parsing the request, Mappper normalized the list of links, removing duplicates.

During the work on Mapper, we came up with two types of services that allowed us to influence the final API response: these are access rules and modifiers. The former allowed or denied access to a particular entity, and the latter could perform various transformations on the attributes and relationships of entities. Transmitting each entity into such services separately was a rather expensive pleasure, so we taught the Mapper to combine entities that require additional processing into collections, which were then transferred to the services. At its core, the mechanism for forming such collections was similar to transactions in the database: when we walked through the model tree, we rendered simple entities at once, and complex entities were sent to collections, where we waited for the tree to crawl. Then came the moment of commit — and the entities processed by the services took their places in the response tree.
Since Mapper uses compilation of entity configs into php code for its work (and at the moment in our API there are over 220 entities ), we made sure that the compiled code was as compact as possible:
- we take repeated pieces of code into common functions and traits;
- we postpone the instantiation of objects, and if the objects are already instantiated, then we try to reuse them;
- at the compilation stage, we try to perform all checks that are not dependent on runtime in order to reduce the number of actions in processing requests.
Bootstrap optimization
After optimizing Mapper, we started optimizing the bootstrap of our application.
To determine what is done with each request, we created an empty endpoint that did absolutely no useful work, and set a profiler on it (we use a bunch of tideways + blackfire ).
One of the problems of our bootstrap was too many services that were instantiated when the application was started, and, as a result, a large number of include files. That should be fixed.
We analyzed the services that the bootstrap itself instantiated, and abandoned some of them. We began to instantiate a part of the services depending on the current context: for example, we did not instantiate the service responsible for authorizing the user if the request did not include an authorization header. For services whose instantiation took significant time, we began to use the extension for Symfony DI - Lazy Services . This extension replaces the service instance with a lightweight dummy, and the service itself is not instantiated until the first access to it.
Then we decided to optimize the EventDispatcher. The fact is that by default EventDispatcher instantiates all its listeners, and this creates a tangible overhead, if there are many such listeners. To solve this problem, we wrote our CompilerPass for DI, which, based on the features of our application, either did not instantiate listeners at all, or instantiated some of them.
Finally, in order to further reduce the number of connected files, we performed a small optimization of the DI itself. By default, DI adds the reflection cache of a single class into several keys (in our case, files), which leads to a significant increase in read and deserialization operations. We rewrote the class responsible for collecting and caching reflection so that the cache for one class is kept in one key. This, despite the slightly increased cache size, gave us a gain in time by reducing the number of read operations.
In the end, all of our optimizations allowed us to reduce cpu consumption by 40% and save some memory.
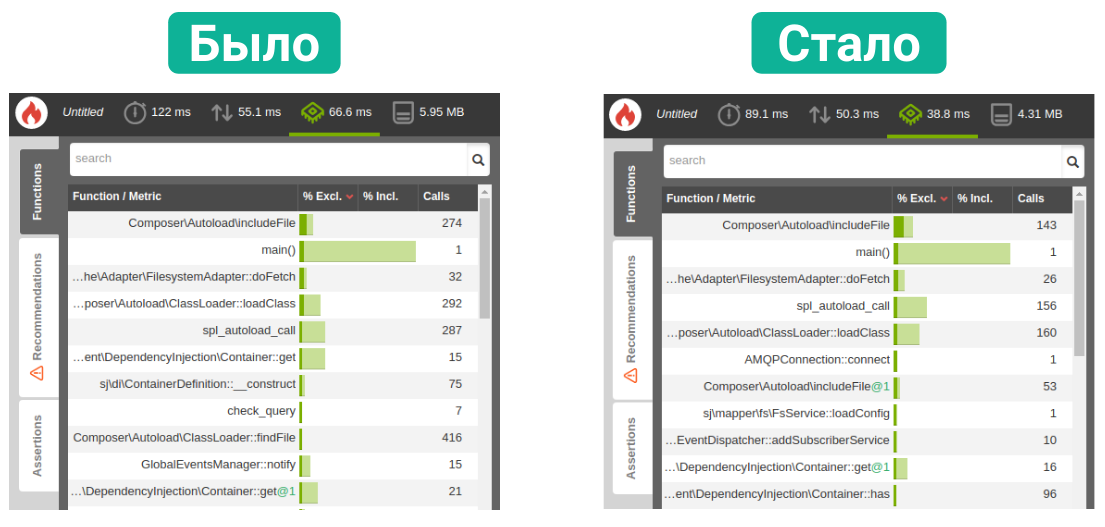
Endpoint Optimization
Finally, the final step in optimizing the backend was optimizing specific endpoints.
Since the only source of information for the front-end application was our API, we had a number of endpoints with reference books, dictionaries, configs, and other rarely changed data. Especially for such endpoints, we added support for server caching: the vocabulary endpoint using the combination of the Cache-Control and Expires headers could ask nginx to cache the response body for a certain amount of time.
For the rest of endpoints, we armed with special tools. We integrated our API with the debug-panel: with each API response, a link to the panel came in which we could go and see what was happening inside the endpoint:

The data from the panel fell into a pivot table, from which it was possible to obtain information about the working hours of endpoints, as well as a look at the profiling in blackfire.
Thanks to this set of tools, problem endpoints were literally visible to the naked eye, but we still armed with scripts that analyzed the table and looked for anomalies there. The latter were divided, as a rule, into two types: either the endpoint started to slow down with a certain combination of filters, or - with large amounts of requested data. For each problematic case, we conducted an investigation and made corrections.
Results
Compared to the old site, the speed of the initial page load in the redesign, despite the increased load on the backend, remained almost unchanged, and all subsequent transitions became noticeably faster thanks to the architecture of the front-end application, which does not require a complete redrawing of the page during each transition.
In addition to winning in speed, we got a cleaner code both on the back and on the front: the back does not think about the mapping, and the front does not keep business logic.
The division of the monolith into separate applications also influenced the speed of development and delivery of features to end users. Automating the routine in the backend application allowed us to implement endpoints for new features faster, and a clear specification made it possible for our colleagues from the front team to develop in parallel, using moki instead of endpoints.
We hope that our experience has been useful to someone, and is always happy to answer your questions in the comments.
Source: https://habr.com/ru/post/354388/
All Articles