Basics of programming on the SAS Base. Lesson 3. Reading text files
In the previous article, we familiarized ourselves with the concept of the SAS library, learned how to assign a library to an Excel file, and also got acquainted with the procedure that creates detailed reports.
Let me remind you that you can download the software on the SAS website , the link to the SAS UE installation documentation is listed in article 1 .
In this article you will learn about several ways to read text files.
')

All examples are based on files stored in the c: \ workshop \ habrahabr directory and created in advance in Notepad.
To create a SAS dataset from a text file, the first one needs to be analyzed in order to correctly select the type of text file reading. A text file can contain both standard and non-standard data.
Standard data is data that SAS considers without any instructions, for example, the value of the Salary variable in a text file is stored as 12355.44 or the date is already recorded as the standard SAS date ( see Lesson 1 ). And if you need to process a value, for example, $ 12,355.44 or 01JAN2018, then you need to specify the reading rule, the instruction according to which these values are converted into SAS format. This article briefly describes the use of the INPUT operator to convert raw data into SAS data sets.
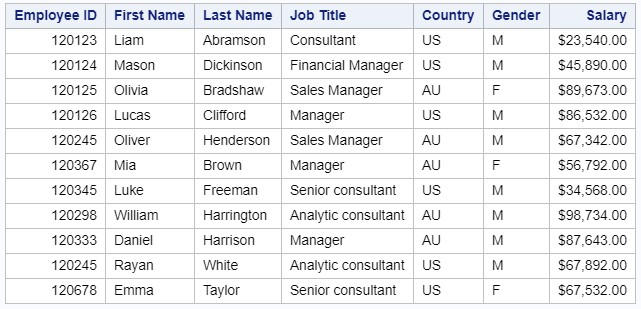
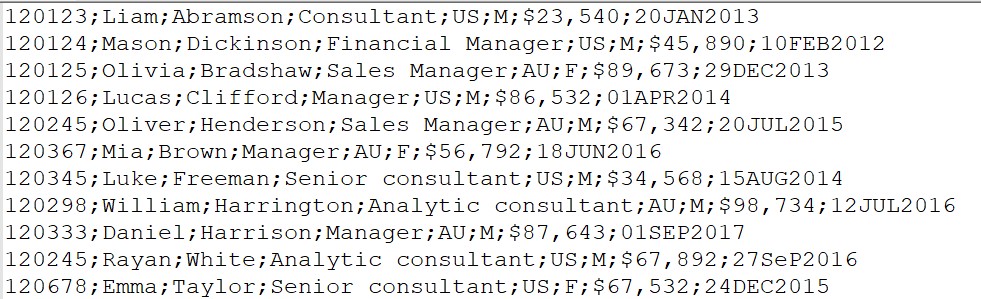
Consider the simplest example of a text file. The managers1.dat file is a comma-delimited text file and looks like this:

The new SAS dataset must contain the following variables: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary. You may notice that the data stored in this file is standard, and SAS considers it without problems.
Reading a text file is implemented using the INFILE and INPUT operators in the DATA step.
You can study the INFILE operator in detail in the SAS 9.4 DATA Step Statements: Reference .
The INFILE statement specifies an external file to read.
The general syntax of the statement is:
file-specification - identifies the data source, it can be an external file or a link to an external file.
device-type is an access method.
options are valid options.
operating-environment-options - working environment options .
In our particular case, the INFILE statement will be written as follows:
DLM = (or delimiter =) is an INFILE operator option that specifies an alternative delimiter (a space is the default delimiter) that will be used to read an external file. The list of delimiters is specified in double quotes.
After we set the path, you need to specify the names of the variables. The INPUT operator will help us in this task.
The general syntax of the operator INPUT:
specification (s) —can include variables, variable lists, text type attribute ($), pointer-control, column specification, formats for reading, and so on (for more details, see the SAS 9.4 DATA Step Statements: Reference ).
@ Is a string hold specifier.
The INPUT operator in our case will be written as follows:
I repeat once again that reading a text file occurs in the DATA step, so the code required for reading a text file will look like this:
We create a temporary SAS dataset called managers, which will be stored in the WORK library until the SAS session is closed ( see Lesson 2 )
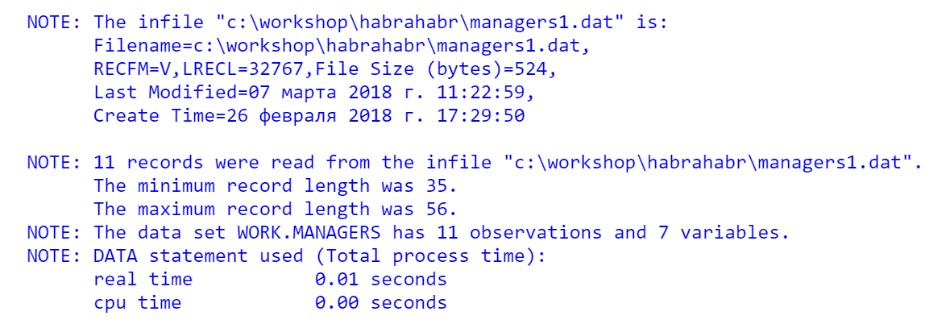
Check if the code works correctly. Run the program and check the Log:
Print the dataset:
The result of the PROC PRINT step:

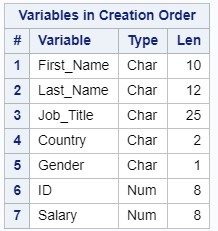
Notice that the text values in some columns are truncated. Run the PROC CONTENTS procedure to determine the length of the created variables:
The VARNUM option displays the variables in the order in which they are stored in the table.
Fragment of the withdrawal procedure:

By default, SAS Base creates variables of any type with a length of 8 bytes. To avoid “truncated” values, the length must be explicitly specified. This problem is easily solved with the LENGTH operator.
It is important to know that this operator must be written before the INPUT operator, this is due to the peculiarities of the SAS Base.
So, our program code using the LENGTH operator will look like this:
We specified the type of variables in the LENGTH operator, so the names of the variables were simply listed in INPUT. Note that in the INPUT statement, the variables are listed in the order in which they appear in the source!
Run the program and examine the results:
The result of the PROC PRINT step:

The result of the PROC CONTENTS:
Variables are displayed in a different order. This is due to the fact that SAS Base reads everything sequentially: first the variables from the LENGTH operator are entered, and only then the INPUT is checked, and the data set is supplemented with the ID and Salary variables.
In order to display the columns in their original order, we can explicitly specify the length of the ID and Salary variables in the LENGTH operator. The minimum length for numeric variables is 3 bytes, but do not forget that if you change the length of a numeric variable to a smaller one, you can lose the accuracy of numeric values.
Thus, the program takes the following form:
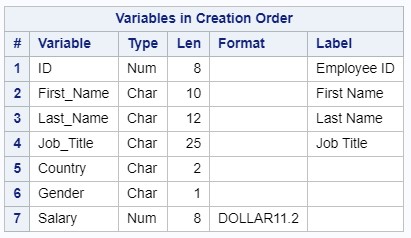
In the DATA step, we will assign constant attributes to the variables: format and label. In this case, the attributes will be written to the descriptor of the output data set and will be used at each PROC step.
Attributes of the output dataset are written to the descriptor:
Create a report from the resulting SAS dataset. Please note that in the PROC PRINT options we specify the label parameter in order for this procedure to use the specified labels in the report.
Consider the text file managers2.dat from the c: \ workshop \ habrahabr directory.
Compared to the previous one, there are columns that contain non-standard data for SAS.
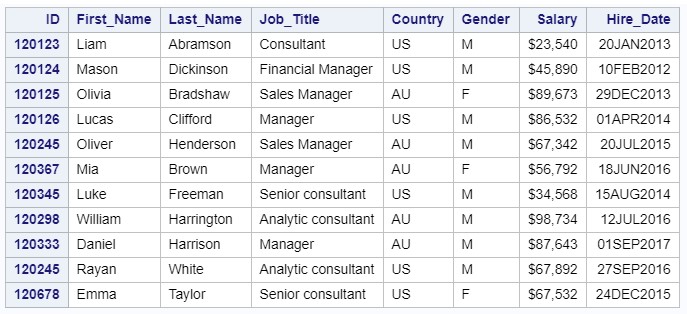
The new data set should contain the following variables: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary, Hire_Date.
The variable Salary contains special characters, the date in SAS format is a number representing the number of days since January 1, 1960 ( see Lesson 1 ), and HireDate stores other values. In order to read non-standard data, you must use the input format - Informat. It is important to remember that the data in the column must be of the same type in order to use the input format.
All information on input formats can be found in the SAS 9.4 Formats and Informats: Reference .
Infromat is a rule that is used to read non-standard SAS input data. The format type to read corresponds to the SAS data type. For example, the source stores the value of $ 100,000. To remove a dollar sign and a comma before converting a given value to a number, you must use INFORMAT comma8. or dollar8. In this case, the final table will store the values 100000.
The general format syntax for reading is as follows:
$ Is a text type pointer.
Informat - the name of the format for reading.
w - field width, including all characters.
d is the number of decimal places.
We consider a text file managers2.dat
The results of the procedure:
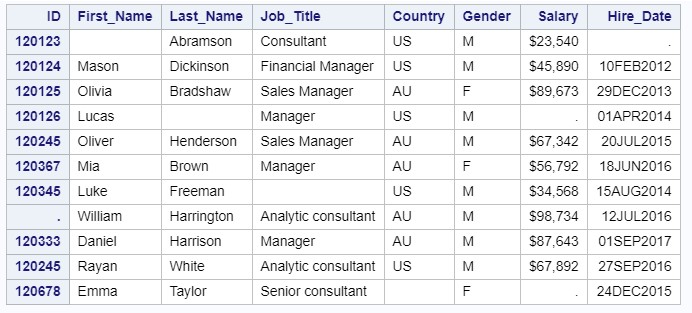
If there are missing values in the data, you can use 2 DSD and MISSOVER options.
DSD searches for missing values within the string, and MISSOVER at the end.
Thus, if we want to read the file managers2a, in which two successive delimiters encode the missing value:

Using the specified options, we can easily read this text file:
The result of the program:
If the column data of different types or formats, consider the following example
The c: \ workshop \ habrahabr directory stores the file bad_data.dat

We write DATA Step, which counts this file:
Run the code and see the Log:
The log indicates an error reading data:

Two automatic variables are created: _N_ and _ERROR_.
_N_ - iteration step.
_ERROR_ - the value 1 indicates an error.
The result of the program:

Please note that the value “44” in the Country variable was considered without data reading errors, and for the variables Salary and Hire_Date in the Log, an indication of a data reading error appeared.
If we need to read a similar text file info.dat from the c: \ workshop \ habrahabr directory:

Another option to read an external file is to use the pointer position of the initial character of a variable.
The position, the variable name and the input format (informat) are indicated.
The code for our case will look like this:
Run the code and check the result:
If we need to read a text file, in which one observation takes several lines:

This problem can be solved in several ways:
In either case, the managers data set is created, which is located in the WORK temporary library ( see Lesson 2 )
Print the resulting data set:
The result of the procedure:
To read external files, you can use the PROC IMPORT procedure.
Import a text file managers5.

The PROC IMPORT procedure in our case is as follows:
Run the code and see the Log:
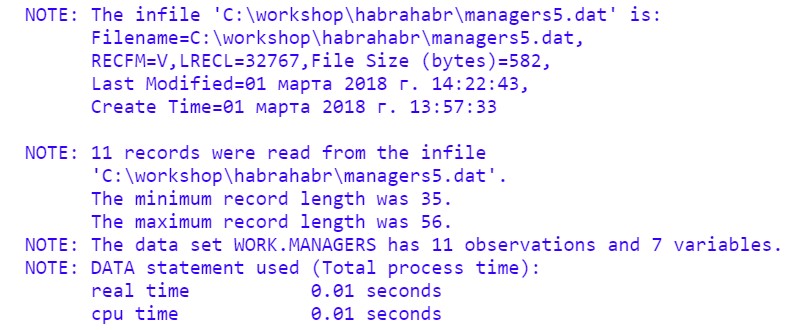
The result of the program:

So, this is a brief reading of text files. Please note that the functionality of the considered operators and procedures is much more extensive, a detailed description is provided in the documentation.
In the next article, we will look at creating SAS datasets. And, of course, traditionally - Grow with SAS!
Let me remind you that you can download the software on the SAS website , the link to the SAS UE installation documentation is listed in article 1 .
In this article you will learn about several ways to read text files.
')
All examples are based on files stored in the c: \ workshop \ habrahabr directory and created in advance in Notepad.
To create a SAS dataset from a text file, the first one needs to be analyzed in order to correctly select the type of text file reading. A text file can contain both standard and non-standard data.
Standard data is data that SAS considers without any instructions, for example, the value of the Salary variable in a text file is stored as 12355.44 or the date is already recorded as the standard SAS date ( see Lesson 1 ). And if you need to process a value, for example, $ 12,355.44 or 01JAN2018, then you need to specify the reading rule, the instruction according to which these values are converted into SAS format. This article briefly describes the use of the INPUT operator to convert raw data into SAS data sets.
Reading a text file with standard data with a separator.
Consider the simplest example of a text file. The managers1.dat file is a comma-delimited text file and looks like this:
The new SAS dataset must contain the following variables: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary. You may notice that the data stored in this file is standard, and SAS considers it without problems.
Reading a text file is implemented using the INFILE and INPUT operators in the DATA step.
You can study the INFILE operator in detail in the SAS 9.4 DATA Step Statements: Reference .
The INFILE statement specifies an external file to read.
The general syntax of the statement is:
INFILE file-specification<device-type><options><operating-environment-options>; file-specification - identifies the data source, it can be an external file or a link to an external file.
device-type is an access method.
options are valid options.
operating-environment-options - working environment options .
In our particular case, the INFILE statement will be written as follows:
infile "c:\workshop\habrahabr\managers1.dat" dlm=','; DLM = (or delimiter =) is an INFILE operator option that specifies an alternative delimiter (a space is the default delimiter) that will be used to read an external file. The list of delimiters is specified in double quotes.
After we set the path, you need to specify the names of the variables. The INPUT operator will help us in this task.
The general syntax of the operator INPUT:
INPUT <specification(s)> <@ | @@>; specification (s) —can include variables, variable lists, text type attribute ($), pointer-control, column specification, formats for reading, and so on (for more details, see the SAS 9.4 DATA Step Statements: Reference ).
@ Is a string hold specifier.
The INPUT operator in our case will be written as follows:
input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary; I repeat once again that reading a text file occurs in the DATA step, so the code required for reading a text file will look like this:
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary; run; We create a temporary SAS dataset called managers, which will be stored in the WORK library until the SAS session is closed ( see Lesson 2 )
Check if the code works correctly. Run the program and check the Log:
Print the dataset:
proc print data=managers; run; The result of the PROC PRINT step:
Notice that the text values in some columns are truncated. Run the PROC CONTENTS procedure to determine the length of the created variables:
proc contents data=managers varnum; run; The VARNUM option displays the variables in the order in which they are stored in the table.
Fragment of the withdrawal procedure:
Variable length
By default, SAS Base creates variables of any type with a length of 8 bytes. To avoid “truncated” values, the length must be explicitly specified. This problem is easily solved with the LENGTH operator.
It is important to know that this operator must be written before the INPUT operator, this is due to the peculiarities of the SAS Base.
So, our program code using the LENGTH operator will look like this:
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1; input ID First_Name Last_Name Job_Title Country Gender Salary; run; proc print data=managers; run; proc contents data=managers varnum; run; We specified the type of variables in the LENGTH operator, so the names of the variables were simply listed in INPUT. Note that in the INPUT statement, the variables are listed in the order in which they appear in the source!
Run the program and examine the results:
The result of the PROC PRINT step:
The result of the PROC CONTENTS:
Variables are displayed in a different order. This is due to the fact that SAS Base reads everything sequentially: first the variables from the LENGTH operator are entered, and only then the INPUT is checked, and the data set is supplemented with the ID and Salary variables.
In order to display the columns in their original order, we can explicitly specify the length of the ID and Salary variables in the LENGTH operator. The minimum length for numeric variables is 3 bytes, but do not forget that if you change the length of a numeric variable to a smaller one, you can lose the accuracy of numeric values.
Thus, the program takes the following form:
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8; input ID First_Name Last_Name Job_Title Country Gender Salary; run; proc print data=managers; run; Permanent attributes.
In the DATA step, we will assign constant attributes to the variables: format and label. In this case, the attributes will be written to the descriptor of the output data set and will be used at each PROC step.
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8; input ID First_Name Last_Name Job_Title Country Gender Salary; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar11.2; run; proc contents data=managers varnum; run; Attributes of the output dataset are written to the descriptor:
Create a report from the resulting SAS dataset. Please note that in the PROC PRINT options we specify the label parameter in order for this procedure to use the specified labels in the report.
proc print data=managers label noobs; run; Reading a text file with non-standard data with a separator.
Consider the text file managers2.dat from the c: \ workshop \ habrahabr directory.
Compared to the previous one, there are columns that contain non-standard data for SAS.
The new data set should contain the following variables: ID, First_Name, Last_Name, Job_Title, Country, Gender, Salary, Hire_Date.
The variable Salary contains special characters, the date in SAS format is a number representing the number of days since January 1, 1960 ( see Lesson 1 ), and HireDate stores other values. In order to read non-standard data, you must use the input format - Informat. It is important to remember that the data in the column must be of the same type in order to use the input format.
All information on input formats can be found in the SAS 9.4 Formats and Informats: Reference .
Infromat is a rule that is used to read non-standard SAS input data. The format type to read corresponds to the SAS data type. For example, the source stores the value of $ 100,000. To remove a dollar sign and a comma before converting a given value to a number, you must use INFORMAT comma8. or dollar8. In this case, the final table will store the values 100000.
The general format syntax for reading is as follows:
<$>informat<w>.<d> $ Is a text type pointer.
Informat - the name of the format for reading.
w - field width, including all characters.
d is the number of decimal places.
We consider a text file managers2.dat
data managers2; infile "c:\workshop\habrahabr\managers2.dat" dlm=';'; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=managers2 noobs; ID ID; run; The results of the procedure:
Handling missing values.
If there are missing values in the data, you can use 2 DSD and MISSOVER options.
DSD searches for missing values within the string, and MISSOVER at the end.
Thus, if we want to read the file managers2a, in which two successive delimiters encode the missing value:
Using the specified options, we can easily read this text file:
data managers2a; infile "c:\workshop\habrahabr\managers2a.dat" dlm=';' dsd missover; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=managers2a; ID ID; run; The result of the program:
Error reading data.
If the column data of different types or formats, consider the following example
The c: \ workshop \ habrahabr directory stores the file bad_data.dat
We write DATA Step, which counts this file:
data new; infile "c:\workshop\habrahabr\bad_data.dat" dlm=','; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :5. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=new; ID ID; run; Run the code and see the Log:
The log indicates an error reading data:
Two automatic variables are created: _N_ and _ERROR_.
_N_ - iteration step.
_ERROR_ - the value 1 indicates an error.
The result of the program:
Please note that the value “44” in the Country variable was considered without data reading errors, and for the variables Salary and Hire_Date in the Log, an indication of a data reading error appeared.
Using the pointer position of the initial character of a variable when reading a text file
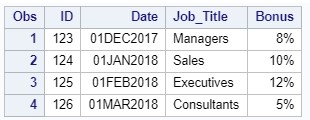
If we need to read a similar text file info.dat from the c: \ workshop \ habrahabr directory:
Another option to read an external file is to use the pointer position of the initial character of a variable.
The position, the variable name and the input format (informat) are indicated.
The code for our case will look like this:
data info; infile "c:\workshop\habrahabr\info.dat"; input @1 ID 3. @4 Date mmddyy10. @15 Job_Title $11. @26 Bonus percent3.; format Date date9. Bonus percent.; run; proc print data=info; run; Run the code and check the result:
Reading a text file with observation in several lines.
If we need to read a text file, in which one observation takes several lines:
This problem can be solved in several ways:
- Use multiple INPUT statements.
data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10.; input Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run; - Use pointer.
SAS loads the following entry (string) when the slash (/) character is found in the INPUT statement:data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10./ Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run;
In either case, the managers data set is created, which is located in the WORK temporary library ( see Lesson 2 )
Print the resulting data set:
proc print data=managers6 noobs; id id; run; The result of the procedure:
Import external files
To read external files, you can use the PROC IMPORT procedure.
Import a text file managers5.
The PROC IMPORT procedure in our case is as follows:
proc import datafile="C:\workshop\habrahabr\managers5.dat" dbms=dlm out=managers replace; delimiter=','; getnames=yes; run; proc print data=managers; run; Run the code and see the Log:
The result of the program:
So, this is a brief reading of text files. Please note that the functionality of the considered operators and procedures is much more extensive, a detailed description is provided in the documentation.
In the next article, we will look at creating SAS datasets. And, of course, traditionally - Grow with SAS!
Source: https://habr.com/ru/post/354284/
All Articles