The story about the repository of images. Or how the bike saved from the crutch

We recently released a new feature - Traffic events in the navigator. Now users of mobile applications can not only look at traffic jams and locations of high-speed cameras, but also participate in the exchange of information on the roads: indicate places of an accident, road works, ceilings, and also just talk. In addition to the indicated places, the added photos will help orient you in the situation.
The article will tell you how we have developed a service that can store millions of photos and serve thousands of requests per second.
Where did we go?
In 2GIS a lot of attention is paid to the content and its quality. One type of content is images. We often have tasks before us:
')
- take and store photos of users (both internal and external),
- generate previews of different sizes
- quickly distribute stored data and meta information about them.
We have a decent service. And every time we do everything again and we don’t want to step on the same rake.
One fine sunny day while planning, we received another task: road events will appear in the applications soon. In addition to being able to be created by users, photos can be attached to them in order to provide users with more information about the traffic situation.
At that time, the situation with the addition of custom photos to the product meant two options:
- Integration with the existing Photo service (stores photos of companies and geo-objects). Calling a convenient option is very difficult:
- The business logic is sharpened for specific scenarios of working with photo objects of the reference API.
- There are many links in the uploading scheme of the photo: loading in several requests + sending binaries between data centers.
- A large number of clients, changing the format of work with which is simply impossible. We do not break backward compatibility.
- Integration with Ceph (object storage with S3 support) without intermediaries also does not look very rosy:
- Transformations and validation of images at boot must be implemented in each service.
- Accessibility in several data-centers of resayers and CDN must be organized separately, or embedded in an existing solution from Photo, which is inconvenient to debug.
- From implementation to implementation errors will be repeated.

What is the implementation path chosen
The choice was quite difficult for us: integration with the Photo service added additional inconvenience to all participants of the interaction, and the way direct integration with the storage - another bike within each service. In addition, the need for support for working with images was not only the Road events, but also a few more features.
Therefore, we went the other way - we identified the specialized FileKeeper service, which in addition to the basic operations on images:
- will not be tied to domain data models of integrated services, limited to grouping the stored data by source (we call each such group “space”),
- encapsulates knowledge about image storage logic,
- just scaled and ready for high loads (focusing on the ability to reach several thousand RPS if necessary).
It should be noted that most of the requirements and decisions were quickly formulated thanks to the experience gained during the operation of the Photo service.
Architecture
The conceptual diagram of a new service, or rather, a group of services:
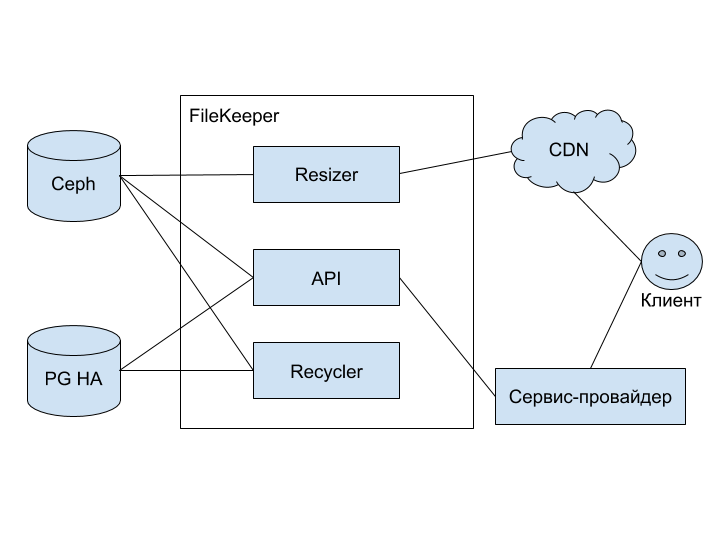
The diagram shows the following elements:
- Ceph - object storage with S3 protocol support (you can read in detail here ),
- PG HA - highly available PostgreSQL based cluster,
- FileKeeper - a group of services for storing and working with images,
- Resizer - image converter service; the main type of conversion is resizing,
- API - a service that provides a REST interface for managing stored images,
- Recycler - a service that is responsible for cleaning old files and zombie files (I'll tell you about the way they appear below),
- A service provider is a master service that uses FileKeeper to store images associated with its own data.
- CDN - delivery network of images and their converted copies closer to the client,
- The client is an application with which the end user interacts (web or mobile version of 2GIS).
Integration
The architecture is clear. Now it's worth telling how the service can be used. Integration is based on the following rules:
- access to work with API is carried out using an authorization key,
- all restrictions and operations are carried out within the framework of the space,
- the provider is both the initiator of the file download and the initiator of its removal,
- integration is possible only at the service - service level.
Compliance with such rules simplifies implementation, and also allows the flexibility to manage the connection of new providers, providing opportunities to set restrictions on their data and even choose the method of storage.
It may seem a bit strange that the file download goes through the provider - an extra link.
The reasons for this decision:
- Without a provider in any way. The provider, as a master system, should somehow participate in the interaction. Otherwise, he will not know about the file relating to his data.
- Control and security. To download from the client, you need to provide a special authorization method to prevent the use of the service as a file dump.
- Time. We deliberately did not complicate the task and implement complex scenarios in order to minimally influence the release dates of the Road events.
File upload
Considering all the interaction scenarios between the provider and the API is quite boring. The most interesting to parse - download images. It is on it and dwell.
At the entrance we have: a key issued by the provider for interacting with the FileKeeper API, a set of images for downloading and knowledge of the space in which we want to put all the images.
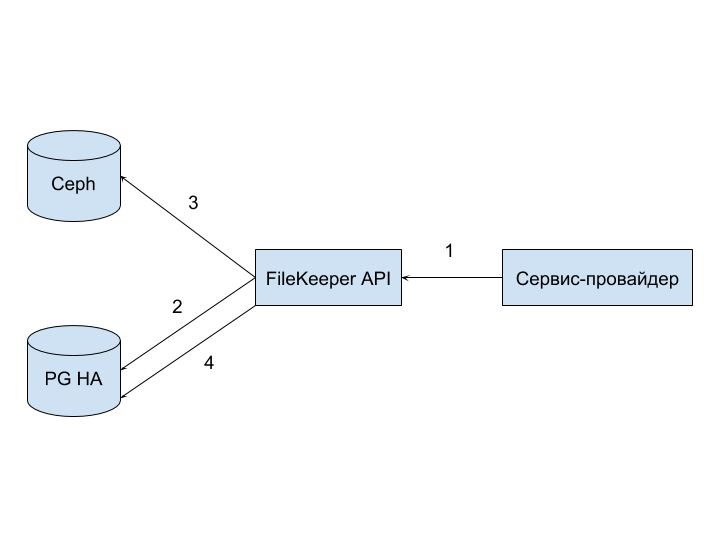
Positive scenario:
- Upload: The provider sends the request to the API.
- Prepare: The API pre-saves the file meta information and the current date in PG HA with a note that “file is prepared”.
- Store: saving the images themselves in Ceph.
- Ready: The Public API marks all files with a “file uploaded” flag in PG HA.
And everything would be fine if all the scenarios were positive, but ...
Can something go wrong?
Any integration between different applications leads to a large number of nuances and places for a header: service unavailability, network delays, disconnections, ending disk space, the arrival of an OOM killer.
Most of the problems can be divided into groups that correspond to the interaction channel together with the “receiver service”. Consider them in order.
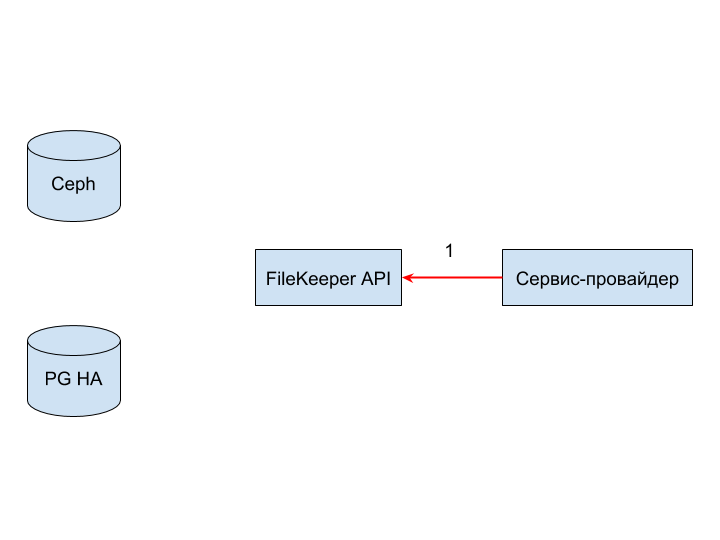
FileKeeper API (1) failure can occur due to service unavailability, connection timeout or error during disassembly and validation of the request.
Failure can be fraught with only the fact that the request will be rejected at the start of processing and the provider will have to process it.
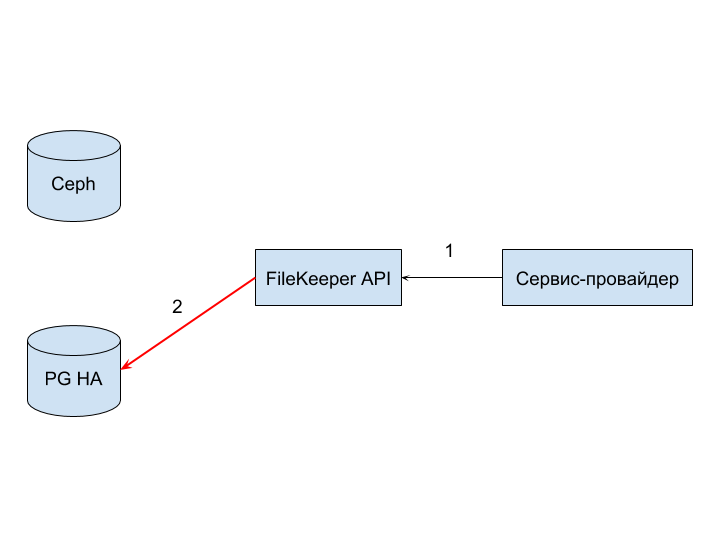
PG HA (2) failure can occur due to incorrect sql query, violation of integrity constraints set at the database level, discontinuity or network problems.
In this case, the error should be handled not only by the provider, but also by the FileKeeper API service.
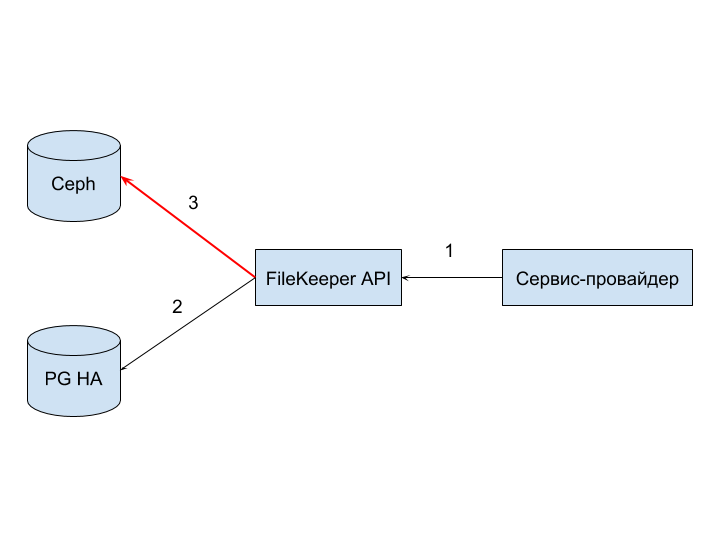
Ceph (3) failure can occur as a result of network problems, similar to previous options for failures, and because of a denial of service due to incorrect access keys, lack of available space, insufficient rights to write.
The failure is more problematic than the previous two, since PG HA already has an entry for the file, and it failed to bring it to the active state - this is how the “zombie” file appeared. This is exactly the case when you need to process the error and clean the data. Cleaning up trash after such problems is one of the tasks of Recycler.
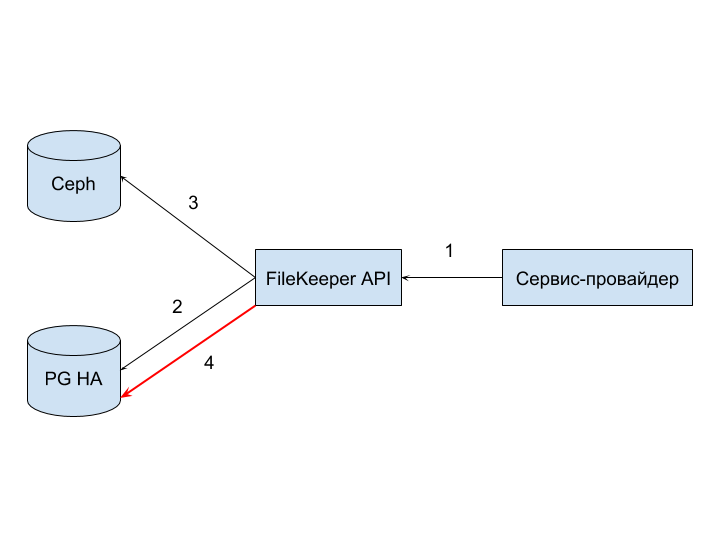
The causes of PG HA failure (4) are similar (2) , the consequences and their resolution are similar (3) .
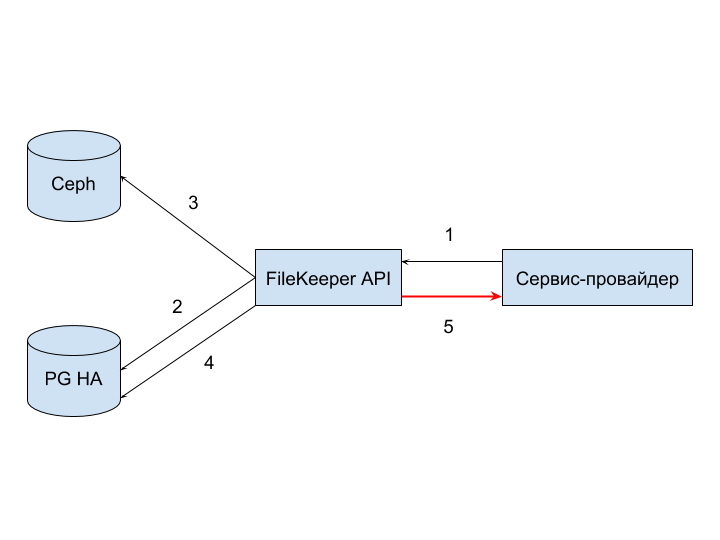
There is one more type - the refusal of the provider to accept the answer (5) . It can occur due to the timeout for the request processing on the provider side.
Such failures are hard to systematically handle, since the connection is out of control of the service. Liquidation of correctly processed requests that have not reached the initiator can be carried out through monitoring, as well as by periodically checking the stored files and files that the provider knows about.
results
The release of the road events was a success. Now is the time to think about what has been achieved and where to go next.
In addition to the obvious, implementing FileKeeper we:
- They identified the demanded part of the functionality as a separate service, that is, they did not complicate the support of the existing product.
- Once again we realized the importance of availability and timeliness of load testing in the development. Converting images is quite an expensive operation, requiring a decent amount of RAM and processor time. The first implementation did not perform well under load, quickly eating gigabytes of memory and dying from being hit by an OOM killer, which delayed the release date.
- We got a flexible implementation of the file storage service, ready for servicing different providers with different needs: one provider is already there, the second one is on the way. At the same time, different binary and metadata storages can be used for different providers, depending on the accessibility needs and the speed of reading and writing in different DCs.
Some tips from the captain
- It is not always worth trying to embed a new feature into an existing solution. If embedding looks like a crutch, it is worth stopping and thinking: maybe the moment has come to single out the claimed functionality as a separate service? Such a stop helped us. Perhaps it will help you.
- Distributed systems compared to monoliths are complicated by the fact that you can catch a lot of problems with interconnection - do not forget to provide for the processing of negative scenarios.
- Other services interact with your service - the monitoring system should be ready to separate the sources of requests. If you see that the load on the service suddenly increased dramatically, but you can not figure out the culprit, then it is unlikely that you will be able to influence the situation.
- Do not attempt to build an image conversion service based on an on-the-fly conversion approach for each request. Without caching, the service is doomed to a huge amount of system resources. Caching should be predictable and manageable - it will benefit both in the process of debugging and testing, and in case of a letter from Roskomnadzor.
- We decided to process images under load - conduct load testing on the prototype. In the process of testing there is a chance to change more than one library for image processing. We changed not one because of the gluttony in relation to the RAM.
Source: https://habr.com/ru/post/354248/
All Articles