Why the creation of a simple preview on the links in Wikipedia took four years
History preview pages.
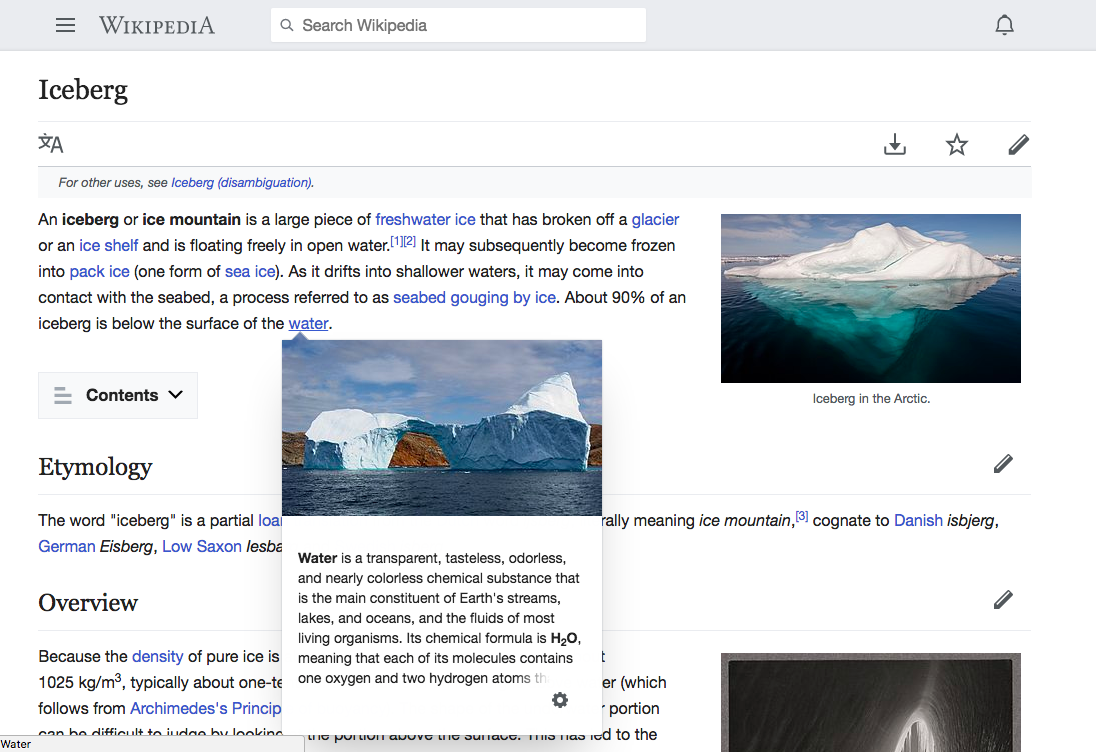
When you hover over a link, a preview card appears (and yes, I have a Wikipedia mobile skin on my desktop). Text from Wikipedia articles on icebergs and water , CC BY-SA 3.0 . Images from left to right, top to bottom: # 1 Kim Hansen, CC BY-SA 3.0 ; # 2 Andreas White, CC BY-SA 4.0 ; # 3 National Library of New Zealand, CC0
A few days ago, my team launched the “Page Preview” feature (preview) in hundreds of language versions of Wikipedia. Our API handles every minute up to half a million calls for issuing preview cards, which are displayed when you hover over any link.
')
At first glance, everything is very simple. This is on many sites. The image and some text are placed on the card - and it is displayed when you hover over the link. Nothing innovative ... at least it may seem so at first glance.
The original idea of this feature appeared four years ago on the basis of the idea that one volunteer / editor suggested many years before.
Thus, it took us several years to roll out the feature to all. This may seem strange, but as in the iceberg, the underwater part should be evaluated.
We have several million pages - all stored as a raw wiki text. One could not expect every article to be edited for the selected thumbnail.
Back in 2012, Max Semenik, a software engineer at our Community Tech group , developed an extension that algorithmically yields the most appropriate image for an article.
As with all algorithms, it did not work perfectly. And since it was not originally intended for use in a preview, it required a special configuration.
I had to make some changes to limit the image to the first section of the article. Working with algorithms is difficult, but in this case it is necessary.
We have several million pages in wiki text . How to generate a resume for each of them, without loading our editors with this painstaking work?
Max Semenik, who helped us with thumbnails, is also the author of the extension to generate excerpts from articles . Initially, it worked primarily with text format . We used it in the first versions of the preview, but soon realized that this was not the best option.
Then we stopped using it.
We understood the importance of HTML. For example, in chemistry, there are descriptors that require HTML support.

HTML is required to create a summary of content in which the presence of subscripts is important. Text from an English-language Wikipedia article on water , CC BY-SA 3.0 ; Image of Kim Hansen, CC BY-SA 3.0
Many of our articles begin with coordinates and word pronunciation information. Much of this content was not included in the summary, and for the rest it was not entirely clear: what to include here and what not. After studying a lot of design options, we determined which content should not be displayed in the preview. Then they made a specification that reinforces the desired behavior .

The coordinates of the place are indicated at the beginning of many articles, but it turned out to be problematic to include them in the summary ...

... as well as pronunciation information
In the end, we decided to work on top of an API that was originally developed for native Wikipedia applications for Android and iOS. Especially for this we have created a new API.
Now the summary is generated based on the whole HTML page. It is interpreted as in a browser and according to the specification the first “non-empty” paragraph of each article is determined.
One of the main problems was to get rid of the text in brackets. Since we support more than 300 languages, we had to create localized solutions (not all use the same character set!).
Of course, some brackets are extremely important ... border cases everywhere. I had to think through all the options for the potential use of brackets and how best to deal with them.
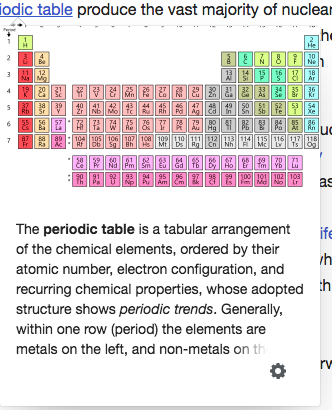
Sometimes content in brackets is very important, as this example shows. It is difficult to determine exactly when it is important. Text from the English-language Wikipedia article on the periodic table of elements , CC BY-SA 3.0 ; Image Offnfopt, public domain.
Clearing custom HTML brackets has also proven to be rather difficult. In a text format, you just need a simple regular expression, but it’s completely different to parse the nested levels of HTML.
It was important to make sure that after removing the content in brackets, the content still makes sense - and that we did not add any security vulnerabilities.
Thanks to our infrastructure team for helping to create this API.
For the community is very important result. That is why they write articles for you in their free time without remuneration.
We used their help at every stage and worked tirelessly with them, sorting out every border case (be it an incorrect resume or an inappropriate image). We tried to convince them that the work was proceeding in the right direction, we explained why and why we continue to do this.
Our initial version was not good enough. The community asked not to release it . We listened to opinions and tried to improve the preview.
Thanks to the community and those users who have helped to establish this communication!
They spent a lot of time on it. Our designer Nirzar wrote an excellent article , so I will not delve too much into this topic here. But the design work continued at each stage, be it the initial prototypes (thanks, Pratek Saxena !), The discussion of features with the performance team, the improvement of sketches and summaries, or the discussion with the community.
Thank you, design team !
Link preview is a major change in how people interact with content. We at Wikimedia are very concerned about privacy. Probably, we are one of the few large sites (the only one ?!) that does not install third-party scripts to track users.
Our privacy policy prohibits the issuance of visitor data.
We do not invite third-party companies to conduct A / B tests or analyze user behavior.
Despite all this, we do not cut corners and do not want to make stupid risky changes.
Every time we develop something important, we have to build an infrastructure for measuring. We build hypotheses and tests for the verification of these hypotheses. We are developing. We are testing. We study the data. Adapt the product. We are testing again.
This means that we combine the responsibilities of development teams and analytics. Our development team works in several ways. Given the scale, there are bugs. Sometimes we find major bugs in browsers .
Tilman Bayer's latest A / B test answered many questions. This is an entertaining reading !
Considering the results of this A / B test, we decided to add an additional metric for page views - views through the preview. This metric generates 1000 events per second , and our analytics department is working hard, trying to cope with such a scale.
Thanks to analysts, thanks to the analytical department!
Our API processes 0.5 million hits per minute .
Our API processes 0.5 million hits per minute .
I wrote it twice because it’s really big traffic.
Our traditional APIs were originally created for bots that clean up your edits. They were not intended for readers.
The Wikimedia service team has proved vital to the success of this project. She provided the infrastructure, provided a large amount of caching (we rely heavily on Varnish ), and provided guarantees that when editing the content, new resumes are generated. It is well known that cache invalidation is one of the most difficult problems in computer science.
Thank you, the service team!
Any finished business gives a feeling of satisfaction. I hope you enjoy these “simple” thumbnails developed by my team with the help of many other teams from around the Wikimedia Foundation.
Many were involved in this business - and we are proud of the result.
We haven't finished yet. Software is never complete.
We still need to clean up some code and check out new ideas that can grow out of this little feature.
Someone may say that now we face only the tip of the iceberg.
Original author: Jon Robson ; This translation is subject to CC BY 3.0 license.
When you hover over a link, a preview card appears (and yes, I have a Wikipedia mobile skin on my desktop). Text from Wikipedia articles on icebergs and water , CC BY-SA 3.0 . Images from left to right, top to bottom: # 1 Kim Hansen, CC BY-SA 3.0 ; # 2 Andreas White, CC BY-SA 4.0 ; # 3 National Library of New Zealand, CC0
A few days ago, my team launched the “Page Preview” feature (preview) in hundreds of language versions of Wikipedia. Our API handles every minute up to half a million calls for issuing preview cards, which are displayed when you hover over any link.
')
At first glance, everything is very simple. This is on many sites. The image and some text are placed on the card - and it is displayed when you hover over the link. Nothing innovative ... at least it may seem so at first glance.
The original idea of this feature appeared four years ago on the basis of the idea that one volunteer / editor suggested many years before.
Thus, it took us several years to roll out the feature to all. This may seem strange, but as in the iceberg, the underwater part should be evaluated.
It was necessary to choose a thumbnail
We have several million pages - all stored as a raw wiki text. One could not expect every article to be edited for the selected thumbnail.
Back in 2012, Max Semenik, a software engineer at our Community Tech group , developed an extension that algorithmically yields the most appropriate image for an article.
As with all algorithms, it did not work perfectly. And since it was not originally intended for use in a preview, it required a special configuration.
I had to make some changes to limit the image to the first section of the article. Working with algorithms is difficult, but in this case it is necessary.
It was necessary to generate a resume
We have several million pages in wiki text . How to generate a resume for each of them, without loading our editors with this painstaking work?
Max Semenik, who helped us with thumbnails, is also the author of the extension to generate excerpts from articles . Initially, it worked primarily with text format . We used it in the first versions of the preview, but soon realized that this was not the best option.
Then we stopped using it.
We understood the importance of HTML. For example, in chemistry, there are descriptors that require HTML support.
HTML is required to create a summary of content in which the presence of subscripts is important. Text from an English-language Wikipedia article on water , CC BY-SA 3.0 ; Image of Kim Hansen, CC BY-SA 3.0
Many of our articles begin with coordinates and word pronunciation information. Much of this content was not included in the summary, and for the rest it was not entirely clear: what to include here and what not. After studying a lot of design options, we determined which content should not be displayed in the preview. Then they made a specification that reinforces the desired behavior .
The coordinates of the place are indicated at the beginning of many articles, but it turned out to be problematic to include them in the summary ...
... as well as pronunciation information
In the end, we decided to work on top of an API that was originally developed for native Wikipedia applications for Android and iOS. Especially for this we have created a new API.
Now the summary is generated based on the whole HTML page. It is interpreted as in a browser and according to the specification the first “non-empty” paragraph of each article is determined.
One of the main problems was to get rid of the text in brackets. Since we support more than 300 languages, we had to create localized solutions (not all use the same character set!).
Of course, some brackets are extremely important ... border cases everywhere. I had to think through all the options for the potential use of brackets and how best to deal with them.
Sometimes content in brackets is very important, as this example shows. It is difficult to determine exactly when it is important. Text from the English-language Wikipedia article on the periodic table of elements , CC BY-SA 3.0 ; Image Offnfopt, public domain.
Clearing custom HTML brackets has also proven to be rather difficult. In a text format, you just need a simple regular expression, but it’s completely different to parse the nested levels of HTML.
It was important to make sure that after removing the content in brackets, the content still makes sense - and that we did not add any security vulnerabilities.
Thanks to our infrastructure team for helping to create this API.
We work with the community
For the community is very important result. That is why they write articles for you in their free time without remuneration.
We used their help at every stage and worked tirelessly with them, sorting out every border case (be it an incorrect resume or an inappropriate image). We tried to convince them that the work was proceeding in the right direction, we explained why and why we continue to do this.
Our initial version was not good enough. The community asked not to release it . We listened to opinions and tried to improve the preview.
Thanks to the community and those users who have helped to establish this communication!
Design, design, design
They spent a lot of time on it. Our designer Nirzar wrote an excellent article , so I will not delve too much into this topic here. But the design work continued at each stage, be it the initial prototypes (thanks, Pratek Saxena !), The discussion of features with the performance team, the improvement of sketches and summaries, or the discussion with the community.
Thank you, design team !
It was necessary to take measurements
Link preview is a major change in how people interact with content. We at Wikimedia are very concerned about privacy. Probably, we are one of the few large sites (the only one ?!) that does not install third-party scripts to track users.
Our privacy policy prohibits the issuance of visitor data.
We do not invite third-party companies to conduct A / B tests or analyze user behavior.
Despite all this, we do not cut corners and do not want to make stupid risky changes.
Every time we develop something important, we have to build an infrastructure for measuring. We build hypotheses and tests for the verification of these hypotheses. We are developing. We are testing. We study the data. Adapt the product. We are testing again.
This means that we combine the responsibilities of development teams and analytics. Our development team works in several ways. Given the scale, there are bugs. Sometimes we find major bugs in browsers .
Tilman Bayer's latest A / B test answered many questions. This is an entertaining reading !
Considering the results of this A / B test, we decided to add an additional metric for page views - views through the preview. This metric generates 1000 events per second , and our analytics department is working hard, trying to cope with such a scale.
Thanks to analysts, thanks to the analytical department!
You had to scale the API to support you
Our API processes 0.5 million hits per minute .
Our API processes 0.5 million hits per minute .
I wrote it twice because it’s really big traffic.
Our traditional APIs were originally created for bots that clean up your edits. They were not intended for readers.
The Wikimedia service team has proved vital to the success of this project. She provided the infrastructure, provided a large amount of caching (we rely heavily on Varnish ), and provided guarantees that when editing the content, new resumes are generated. It is well known that cache invalidation is one of the most difficult problems in computer science.
Thank you, the service team!
Thank you thank you thank you
Any finished business gives a feeling of satisfaction. I hope you enjoy these “simple” thumbnails developed by my team with the help of many other teams from around the Wikimedia Foundation.
Many were involved in this business - and we are proud of the result.
We haven't finished yet. Software is never complete.
We still need to clean up some code and check out new ideas that can grow out of this little feature.
Someone may say that now we face only the tip of the iceberg.
Original author: Jon Robson ; This translation is subject to CC BY 3.0 license.
Source: https://habr.com/ru/post/354236/
All Articles