How JS Works: Browser Network Subsystem, Optimizing Its Performance and Security
[We advise you to read] Other 19 parts of the cycle
Part 1: Overview of the engine, execution time mechanisms, call stack
Part 2: About the V8 internals and code optimization
Part 3: Memory management, four types of memory leaks and dealing with them
Part 4: Event loop, asynchrony, and five ways to improve code with async / await
Part 5: WebSocket and HTTP / 2 + SSE. What to choose?
Part 6: Features and Scope of WebAssembly
Part 7: Web Workers and Five Use Cases
Part 8: Service Workers
Part 9: Web push notifications
Part 10: Tracking DOM Changes with MutationObserver
Part 11: The engines of rendering web pages and tips to optimize their performance
Part 12: Browser networking subsystem, optimizing its performance and security
Part 13: Animation with CSS and JavaScript
Part 14: How JS works: abstract syntax trees, parsing and its optimization
Part 15: How JS Works: Classes and Inheritance, Babil and TypeScript Transformation
Part 16: How JS Works: Storage Systems
Part 17: How JS Works: Shadow DOM Technology and Web Components
Part 18: How JS: WebRTC and P2P Communication Mechanisms Work
Part 19: How JS Works: Custom Elements
Part 2: About the V8 internals and code optimization
Part 3: Memory management, four types of memory leaks and dealing with them
Part 4: Event loop, asynchrony, and five ways to improve code with async / await
Part 5: WebSocket and HTTP / 2 + SSE. What to choose?
Part 6: Features and Scope of WebAssembly
Part 7: Web Workers and Five Use Cases
Part 8: Service Workers
Part 9: Web push notifications
Part 10: Tracking DOM Changes with MutationObserver
Part 11: The engines of rendering web pages and tips to optimize their performance
Part 12: Browser networking subsystem, optimizing its performance and security
Part 13: Animation with CSS and JavaScript
Part 14: How JS works: abstract syntax trees, parsing and its optimization
Part 15: How JS Works: Classes and Inheritance, Babil and TypeScript Transformation
Part 16: How JS Works: Storage Systems
Part 17: How JS Works: Shadow DOM Technology and Web Components
Part 18: How JS: WebRTC and P2P Communication Mechanisms Work
Part 19: How JS Works: Custom Elements
The translation of the twelfth part of a series of materials about JavaScript and its ecosystem, which we are publishing today, will deal with the network subsystem of browsers and the optimization of performance and security of network operations. The author of the material says that the difference between a good and an excellent JS-developer is not only in the level of language acquisition, but also in how well he understands the mechanisms that are not part of the language, but used by it. As a matter of fact, working with the network is one of these mechanisms.

A bit of history
49 years ago the computer network ARPAnet was created, uniting several scientific institutions. It was one of the first packet-switched networks , and the first network to which the TCP / IP model was implemented. Twenty years later, Tim Bernes-Lee proposed a project known as the World Wide Web. Over the years that have passed since the launch of ARPAnet, the Internet has come a long way - from a pair of computers exchanging data packets to more than 75 million servers, about 1.3 billion websites and 3.8 billion users.

')
In this article we will talk about what mechanisms browsers use to improve network performance (these mechanisms are hidden in their depths, you probably don’t even think about them while working with the network in JS). In addition, we will pay particular attention to the network level of browsers and give here a few recommendations on how a developer can help the browser improve the performance of the network subsystem that web applications use.
Overview
When developing modern web browsers, special attention is paid to fast, efficient and safe loading of web site pages and web applications. Browsers are provided with hundreds of components that run at various levels and solve a wide range of tasks, including process management, safe code execution, audio and video decoding and playback, interaction with a computer’s video subsystem, and much more. All this makes browsers look more like operating systems, rather than ordinary applications.
The overall performance of the browser depends on a number of components, among which, if we consider them enlarged, we can mention subsystems that solve the problems of parsing downloadable code, creating page layouts, applying styles, performing JavaScript and WebAssembly-code. Of course, this includes the information visualization system and the network stack implemented in the browser.
Programmers often think that the browser's bottleneck is precisely its network subsystem. Often this is the case, since all resources must be downloaded from the network before they can be done with them. In order for the browser's network layer to be effective, it needs capabilities that allow it to play the role of something more than the role of a simple means for working with sockets. The network layer gives us a very simple data loading mechanism, but, in fact, behind this external simplicity is a whole platform with its own optimization criteria, APIs and services.

Browser Network Subsystem
Being engaged in web development, we can not worry about individual TCP or UDP packets, about formatting requests, about caching, and about everything else that happens during the interaction of the browser with the server. The browser deals with all these complex tasks, which gives us the opportunity to focus on application development. However, knowing what goes on in the browser can help us create faster and safer software.
Let's talk about how a typical user interaction session with the browser looks like. In general, it consists of the following operations:
- The user enters the URL in the address bar of the browser.
- The browser, receiving this URL, leading to any web resource, begins by checking its own caches, the local cache and the application cache, so that if there is what the user needs there, execute the query based on local copies of resources.
- If the cache cannot be used, the browser takes the domain name from the URL and requests the server's IP address, accessing DNS . At the same time, if the information about the IP address of the domain is already in the browser cache, it will not have to contact DNS.
- The browser generates the HTTP package, which is needed to request a page from a remote server.
- The HTTP packet is sent to the TCP level, which adds to it its own information necessary to control the session.
- Then the resulting package goes to the IP level, the main task of which is to find a way to send the package from the user's computer to a remote server. At this level, additional information is also added to the packet to ensure the transfer of the packet.
- The package is sent to a remote server.
- After the server receives the request packet, the response to this request is sent to the browser, following a similar path.
There is a browser API, the so-called Navigation Timing API , which is based on the Navigation Timing specification prepared by the W3C. It allows you to get information about how long it takes to perform various operations during the life cycle of requests. Consider the components of the life cycle of the request, since each of them seriously affects how comfortable it is for the user to work with the web resource.
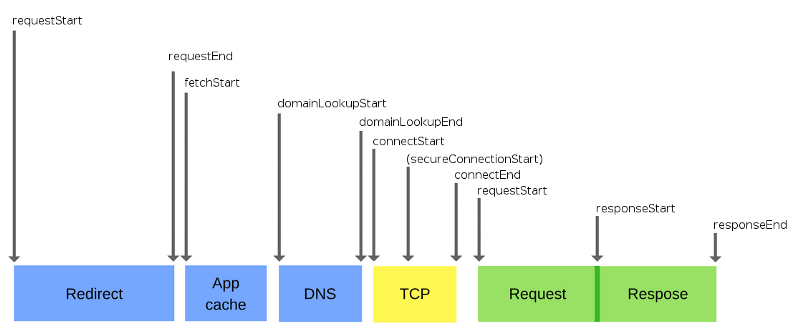
Request life cycle
The whole process of data exchange over the network is very complex, it is represented by a multitude of levels, each of which can become a bottleneck. That is why browsers strive to improve performance on their side, using various approaches. This helps to reduce, to the lowest possible values, the impact of network features on site performance.
Socket management
Before we talk about managing sockets, consider some important concepts:
- The origin (origin) is a data set that describes the source of information, which consists of three parts: the protocol, the domain name and the port number. For example: https, www.example.com , 443.
- A socket pool is a group of sockets belonging to the same source (all major browsers limit the maximum pool size to six sockets).
JavaScript and WebAssembly do not allow the programmer to manage the life cycle of a separate network socket, and I must say, this is good. This not only saves the developer from the need to work with low-level network mechanisms, but also allows the browser to automatically apply many performance optimizations, including socket reuse, query prioritization and late binding, protocol negotiation, enforcing connection restrictions and many others.
In fact, modern browsers spare no effort to separate the management of requests and sockets. Sockets are organized into pools, which are grouped by source. Each pool has its own connection limits and security restrictions. Requests made to the source are queued, prioritized, and then tied to specific sockets in the pool. Unless the server deliberately closes the connection, the same socket can be automatically reused to perform many requests.

Request Queues and Socket Management System
Since opening a new TCP connection requires a certain amount of system resources and some time, reusing connections, by itself, is an excellent means of increasing productivity. By default, the browser uses the so-called “keepalive” mechanism, which saves time in opening a connection to the server when executing a new request. Here are the average times needed to open a new TCP connection:
- Local requests: 23 ms.
- Transcontinental requests: 120 ms.
- Intercontinental queries: 225 ms.
This architecture opens up possibilities for many other optimizations. For example, queries can be executed in order, depending on their priority. The browser can optimize the allocation of bandwidth by distributing it between all sockets, or it can open sockets in advance, waiting for the next request.
As already mentioned, all this is controlled by the browser and does not require the efforts of the programmer. However, this does not mean that the programmer can not do anything to help the browser. For example, the choice of suitable networking templates, data transfer frequencies, protocol selection, tuning and optimization of the server stack can play a significant role in improving the overall application performance.
Some browsers go even further in optimizing network connections. For example, Chrome can “self-educate” as it is used, which speeds up work with web resources. It analyzes the visited sites and typical patterns of work on the Internet, which gives him the opportunity to predict user behavior and take some measures even before the user does something. The simplest example is a preliminary rendering of the page at the moment when the user hovers the mouse over the link. If you are interested in the internal optimization mechanisms used in Chrome, here is useful material on this topic.
Network Security and Limitations
The fact that the browser is allowed to manage individual sockets has, in addition to optimizing performance, another important goal: thanks to this approach, the browser can apply a uniform set of restrictions and rules regarding security when working with untrusted application resources. For example, the browser does not give direct access to sockets, as this would allow any potentially dangerous application to make arbitrary connections to any network systems. The browser also applies a limit on the number of connections, which protects the server and client from excessive use of network resources.
The browser formats all outgoing requests to protect the server from requests that may be formed incorrectly. In the same way, the browser also applies to server responses, automatically decoding them and taking measures to protect the user from possible threats posed by the server.
TLS negotiation procedure
TLS (Transport Layer Security) is a cryptographic protocol that provides secure data transmission over computer networks. He found widespread use in a variety of areas, one of which is working with websites. Websites can use TLS to protect all communication sessions between servers and web browsers.
Here is how, in general, the TLS-handshake procedure looks like:
- The client sends a ClientHello message to the server, indicating, among other things, a list of supported encryption methods and a random number.
- The server responds to the client by sending a ServerHello message, where, among other things, there is a random number generated by the server.
- The server sends the client its certificate used for authentication purposes and may request such a certificate from the client. Next, the server sends a ServerHelloDone message to the client.
- If the server has requested a certificate from a client, the client sends it a certificate.
- The client creates a random key, PreMasterSecret, and encrypts it with the public key from the server's certificate, sending the encrypted key to the server.
- The server accepts the PreMasterSecret key. Based on it, the server and client generate the MasterSecret key and session keys.
- The client sends a ChangeCipherSpec message to the server indicating that the client will start using the new session keys for hashing and encrypting messages. In addition, the client sends a ClientFinished message to the server.
- The server accepts the message ChangeCipherSpec and switches the security system of its record level to symmetric encryption using a session key. The server sends a ServerFinished message to the client.
- Now the client and the server can exchange application data via the secure communication channel they have installed. All of these messages will be encrypted using the session key.
The user will be warned if verification fails, that is, for example, if the server uses a self-signed certificate.
Principle of one source
In accordance with the principle of one source (Same-origin policy), two pages have the same source, if their protocol, port (if specified) and host match.
Here are some examples of resources that can be built into the page with non-observance of the principle of one source:
- JS code connected to the page using the
<script src="…"></script>construction. Syntax error messages are available only for scripts that have the same source as the page. - CSS styles that are attached to the page using the
<link rel="stylesheet" href="…">tag<link rel="stylesheet" href="…">. Due to less stringent syntax, when retrieving CSS from another source, a validContent-Typeheader is required. Restrictions in this case depend on the browser. - Images (
<img>). - Media files (
<video>and<audio>tags). - Plugins (
<object>,<embed>and<applet>tags). - Fonts using
@font-face. Some browsers allow the use of fonts from sources other than the page source; some do not. - Everything that is loaded into the
<frame>and<iframe>tags. The site can use theX-Frame-Optionsheader to prevent interactions between resources downloaded from different sources.
The above list is not exhaustive. His main goal is to show the principle of "least privilege." The browser gives the application code access to only those APIs and resources that it needs. The application transmits data and URLs to the browser, and it formats requests and supports each connection throughout its life cycle.
It is worth noting that there is no single concept of the “single source principle”. Instead, there is a set of related mechanisms that apply restrictions on access to the DOM, on cookie management and session state, on working with network resources, and on other browser components.
Caching
The best, fastest request is a request that did not go online, but was processed locally. Before queuing the request for execution, the browser automatically checks its resource cache, checks the resources found there for relevance, and returns local copies of the resources if they match a specific set of requirements. If there are no resources in the cache, a network request is performed, and the materials received in response to it, if they can be cached, are cached for later use. In the process of working with the cache, the browser performs the following actions:
- It automatically evaluates the caching directives on the resources being worked on.
- It automatically, if there is such an opportunity, rechecks resources whose caching period has expired.
- It independently manages the size of the cache and removes unnecessary resources from it.
Managing the resource cache in an effort to optimize work with it is a difficult task. Fortunately for us, the browser takes on this task. The developer only needs to make sure that his server returns the appropriate caching directives. Here you can read details about caching resources on the client. In addition, we hope that when your servers donate the requested resources, they provide the answers with the correct Cache-Control, ETag, and Last-Modified headers.
And, finally, it is worth mentioning one more set of browser functions, which are often ignored. We are talking about managing cookies, working with sessions and authentication. Browsers support separate sets of cookies, separated by source, providing the necessary application-level APIs and servers for reading and writing cookies, for working with sessions and for performing authentication. The browser automatically creates and processes suitable HTTP headers in order to automate all these processes.
Example
Here is a simple but illustrative example of the convenience of deferred session state management in a browser. An authenticated session can be shared across multiple tabs or browser windows, and vice versa; the end of the session in one of the tabs leads to the fact that the session will be invalid in all the others.
API and protocols
Going up the hierarchy of browsers' network capabilities, we finally arrive at the level at which the APIs available to the application and the protocols are located. As we have seen, the lowest levels provide many extremely important features: managing sockets and connections, handling requests and responses, applying security policies, caching, and more. Whenever we initiate an HTTP request, use the XMLHttpRequest mechanism, use tools to work with events sent by the server, start a WebSocket session or WebRTC connection, we actually interact with at least some of these levels.
There is no “best protocol” or “fastest API”. Any real application requires a mixture of various network tools whose composition is determined by different requirements. Among them are the features of interaction with the browser cache, system resources required for the operation of the protocol, delays in the transfer of messages, reliability of the connection, the type of data transferred, and much more. Some protocols may offer low latency message delivery (for example, a mechanism for handling events sent by the server, the WebSocket protocol), but may not meet other important criteria, such as the ability to use the browser cache or support efficient transfer of binary data for any use cases.
Tips for optimizing the performance and security of web-based network subsystems
Here are some tips to help you improve the performance and security of the network subsystems of your web applications.
- Always use the Connection: Keep-Alive header in queries. Browsers, by the way, use it by default. Check that the server uses the same mechanism.
- Use the appropriate Cache-Control, Etag, and Last-Modified headers when working with resources. This will speed up the loading of pages when re-accessing them from the same browser and save traffic.
- Spend time tuning and optimizing the server. In this area, by the way, you can see real wonders. Remember that the process of this setup is very dependent on the characteristics of a particular application and the type of data transmitted.
- Always use TLS. In particular - if your web application uses any user authentication mechanisms.
- Find out which security policies browsers provide and use them in your applications.
Results
Browsers take on most of the complex tasks of managing everything related to networking. However, this does not mean that the developer can completely ignore all this attention. Anyone who at least in general terms knows what is happening in the depths of the browser can penetrate into the necessary details and help the browser with its actions, which means to make its web applications run faster.
Previous parts of a series of articles:
Part 1: How JS Works: Overview of the Engine, Runtime Mechanisms, Call Stack
Part 2: How JS Works: About V8 Inside and Code Optimization
Part 3: How JS works: memory management, four types of memory leaks and how to deal with them
Part 4: How JS works: event loop, asynchrony, and five ways to improve code with async / await
Part 5: How JS: WebSocket and HTTP / 2 + SSE work. What to choose?
Part 6: How JS Works: Features and Scope of WebAssembly
Part 7: How JS Works: Web Workers and Five Use Cases
Part 8: How JS Works: Service Workers
Part 9: How JS Works: Web Push Notifications
Part 10: How JS Works: Tracking DOM Changes with MutationObserver
Part 11: How JS Works: Web Page Rendering Engines and Tips for Optimizing Their Performance
Dear readers! What problems concerning irrational work with the browser’s network subsystem have you encountered?

Source: https://habr.com/ru/post/354070/
All Articles