We apply the Deep Watershed Transform in the Kaggle Data Science Bowl 2018 competition.
We apply the Deep Watershed Transform in the Kaggle Data Science Bowl 2018 competition.
We present you the translation of the article by reference and the original dokerized code . This solution allows you to get about the top 100 on a private leaderboard at the second stage of the competition among the total number of participants in the area of several thousand, using only one model on one fold without ensembles and without additional post-processing. Given the instability of the target metric in the competition, I believe that adding a few chips described below in principle can also greatly improve this result if you want to use this solution for your tasks.
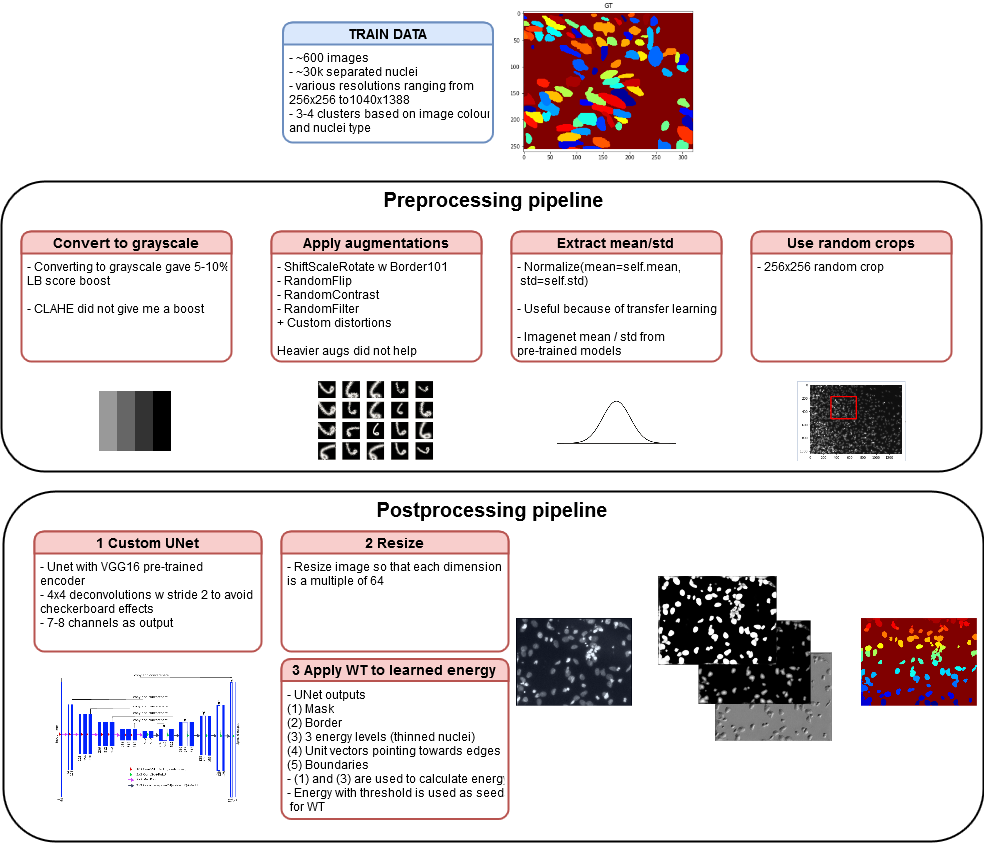
solution pipeline description
Tldr
( Translator’s note - some terms are left as they are, that is, I’m not at all sure that there are adequate analogues in Russian. If you know of those, write in a comment - we’ll make some changes).
Each year, Caggle launches the Data Science Bowl competition. Last year it was pretty cool:
- New interesting topic in the form of 3D-images
- A worthy task is lung cancer;
- Big dataset - 50 + GB;
- Seductive prize;
Unfortunately, when last year the competition started, I was not yet ready to take part in it. This year, after Google bought Kaggl, I began to notice some of the first "alarm bells" (a couple of "notes in the margins" - here and there ). Briefly - before the machine learning competition seemed to me mutually beneficial for both the community and the organizers of the competition, but now I am seeing some strange trend for the worse - it feels like the competitions turn into data marking exercises and / or awards become unattractive regarding the amount of effort that must be applied to participate normally (sort out / get to the top or give prizes / pump over).
Why I didn’t like the organization of this competition:
- Small dataset (600 images for training and 65 for validation) at the first stage of the competition along with many times larger at the second stage of the competition (3000 pictures for the test only);
- The distribution of data in the second stage had nothing to do with the first (put a bold exclamation mark here);
- Kaggl is also notorious for not particularly suppressing cheating - in this particular competition, for example, it was possible to re-train the model after the release of data from the second stage;
- If you don't believe me - ask around for the community members who participated;
- (In order not to be unfounded, towards the end it will be described how to avoid such problems);
- Also, the target metric - the average mAP at several levels of accuracy (from 0.5 to 0.95) - behaves very unstable. Judging by the choice of such a metric, the organizers were clearly confident in the "ideality" of their markup, but in practice this was certainly not the case. For example, if you take the markup, shift it 1 pixel to the side, then the speed drops from 1 to 0.6;
At first, when I opened the data, I generally did not want to participate, because their volume in megabytes did not inspire confidence at all. But then I examined them more closely and realized that the task here was in instance segmentation , which was a novelty for me. The task itself - instance segmentation is very interesting, despite the small size of the dataset. It is expected that you will not only create an exact binary mask of cells, as well as divide adherent cells (sorry, maybe there are nuclei, not cells, but judging by the markup, the organizers themselves are not sure about this either). On the other hand, the size of the dataset and the quality of the markup seemed a bit inadequate, especially considering the fact that the organizers of the competition, among other things, reported that some companies have similar datasets with terabytes of data .

Basic computer vision tasks. Here in the list, in theory, there should also be a classification of objects (the classic task is to find cats and dogs in the photo)
In this post, I will explain my approach to solving this problem. I will also share my pipeline inspired article Deep Watershed Transform for Instance Segmentation and tell you about other hikes and solutions, and also share my opinion on how such competitions should ideally be organized.
EDA or why ML is not magic
The training dataset contained about 600 images and the validation dataset - 65. The deferred test dataset from the second stage contained ~ 3000 images.
The images from the first stage had different resolutions - which in itself was a challenge - how would you build a universal pipeline for all of them?
256x256 358 256x320 112 520x696 96 360x360 91 512x640 21 1024x1024 16 260x347 9 512x680 8 603x1272 6 524x348 4 519x253 4 520x348 4 519x162 2 519x161 2 1040x1388 1 390x239 1 There were about three clusters among the training data that are easy to find with K-means:
- Images with black background;
- Images with dye;
- Images with white background;
This was the main reason why converting RGB images to black and white helped on a public leaderboard.
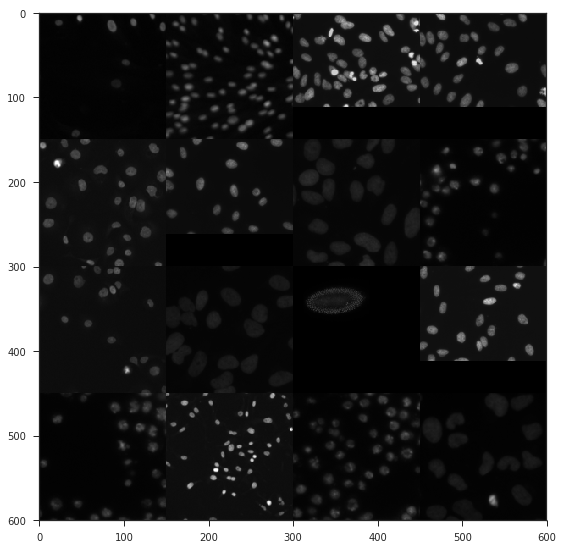
Black images

Different variations of cores in shape, color, size
Visual viewing of a test dataset with three thousand pictures showed that 50 +% of these pictures have nothing to do with the training dataset, which caused a lot of controversy and resentment from the community. So you participate in the competition for "thank you", spend time, optimize the model, and bang and get 3000 pictures that do not look like training data? It is clear that the goals may be different (including preventing manual marking on between the stages of the competition) - but this can be done much less clumsy.
Some noteworthy files from the test dataset:
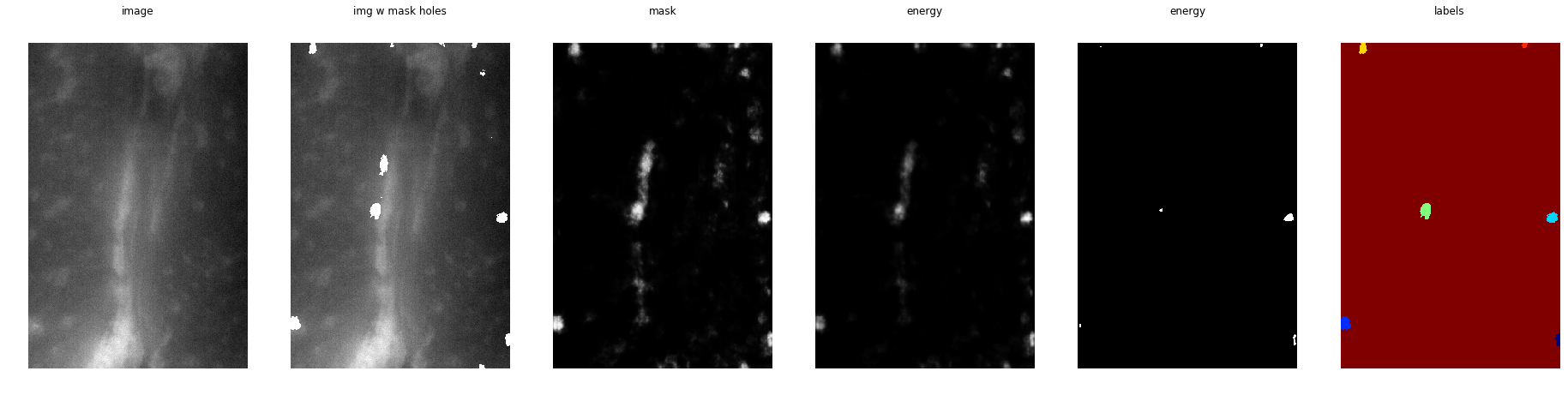
I would suggest that the little thing in the background is the core

Honestly no idea what's

Looks like muscle. Once again, are these white pieces cores or what?
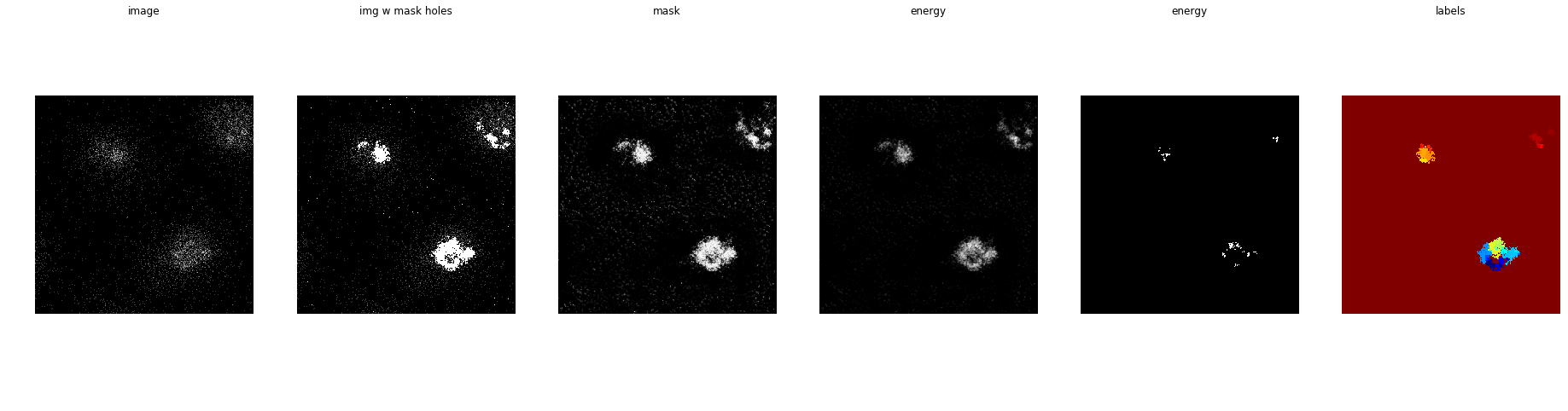
Night sky ... Is it a core or just noise?
Deep watershed transform
If you do not know what it is, then go here . Intuitively, the watershed method is fairly simple - it turns your image into a negative "mountain landscape" (height = intensity of pixels / masks) and fills the pools of the markers of your choice with water until the pools connect. You can find a bunch of tutorials with OpenCV or skimage , but all of them usually ask questions like this:
- How should we choose labels where water will flow from?
- How should we define the boundaries of the watershed?
- How should we determine the height of the landscape?
Deep Watershed Transform (DWT) will help us solve some of these problems.
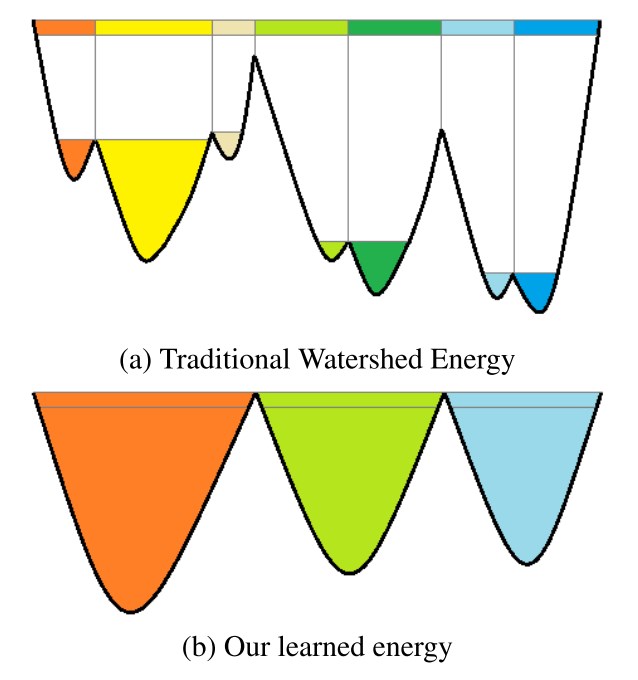
The main motivation of the original work
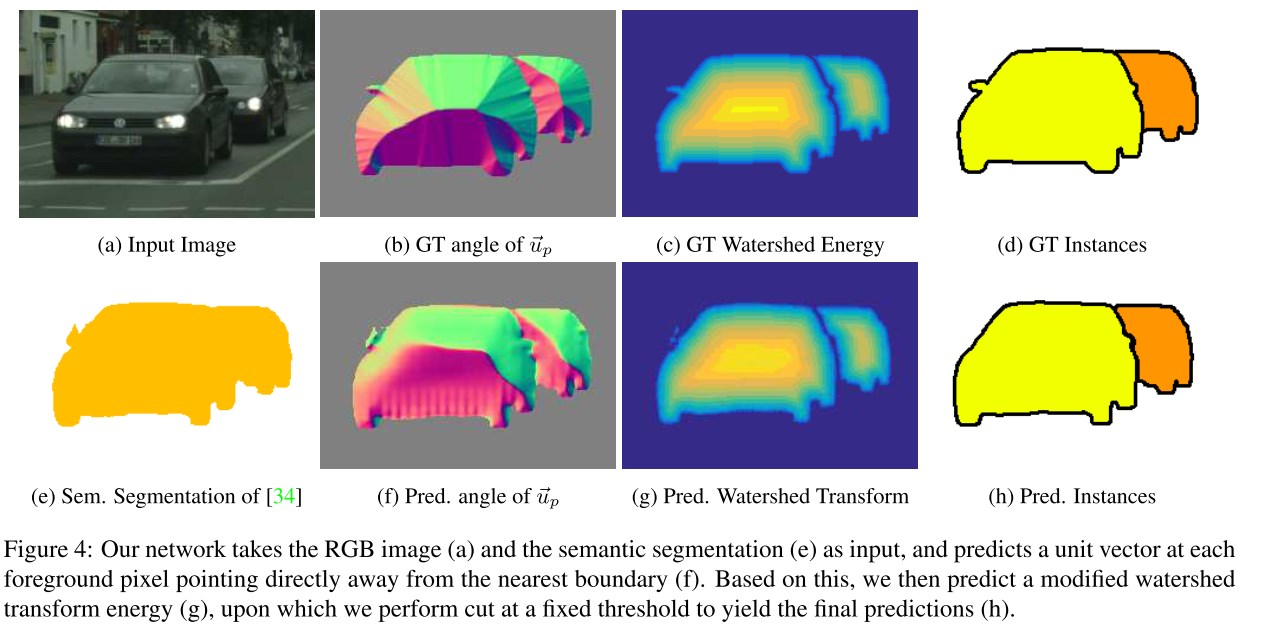
The idea is for CNN to take into account two things - single vectors indicating the boundaries and energy level (height of the mountains)
In practice, if you simply apply a WT (Watershed Transform), you will most likely get a very parcel segmentation. The intuition behind DWT is such - we must teach CNN to find the "mountain landscape" for us.
The authors of the original article used 2 separate CNG VGG-type to obtain:
- Energy (or landscape heights);
- Unit vectors directed to the boundaries of objects or from the boundaries, to then help CNN to learn the energy and boundaries of objects;
In practice, you can use one network or just train several smaller end-to-end networks . In my case, I played with networks that gave out:
- Binary cell mask;
- Several masks with different levels of erosion (1.5.7 pixels);
- The centers of the nuclei (not really helped in my case);
- Unit vectors (slightly helped, locally);
- Borders (slightly helped, locally);
Then you need a little magic to combine it all and voila, you have the "energy". I didn’t experiment a lot with architecture, but Dmitro (the author of the solution above) then told me that he didn’t get better results when adding the second CNN.
For me, the best post processing ( energy_baseline function by reference) was the following algorithm:
- Summarize the predicted mask and the three levels of the predicted erosion masks;
- Apply a threshold of 0.4 to separate cell centers;
- We use the found centers as markers for the fill;
- We use the distance to the border of the masks as a measure of the "height of the landscape";

One of the best examples - the net was able to clearly separate the stuck cores
The gradients learned are not suitable for use as a watershed.
Sometimes a direct search for nucleus centers also worked, but overall, this did not help improve speed.
Other approaches
Personally, I would divide the possible approaches of this task into 4 categories:
- UNet-style approaches (UNet + pre-trained Resnet34, UNet + pre-trained VGG16, etc.) + Deep Watershed Transform post-processing. UNet (its cousin, LinkNet ) is known as universal and simple tools when it is necessary to solve semantic segmentation problems;
- Recurrent architectures. I found only this less relevant work (even with the availability of ready code on PyTorch, I did not have time to try it);
- Proposal based model type Mask-RCNN . Although they are quite difficult to use (and there is no suitable implementation on PyTorch), it was reported that the approach initially yields better results, but with almost no options, then they will be improved;
- Others are a little "adventurous" (read - the author himself writes that they do not seem to work very well) the approaches described here ;
For me, in favor of choosing DWT + UNet, this is a solution, where you don’t have to bother too much, because it is simple (you can simply feed layers of energy as additional channels for the mask) and then easily shift the work to other tasks. I also really like the recurrent extension UNet, but I didn’t have enough time to try it.
In the case of recurrent UNet, there are three new components in essence compared to regular UNet:
- ConvLSTM layer;
- A loss function component that penalizes CNN for learning too many cores;
- Using the Hungarian algorithm for optimally combining predicted objects with markup;
It all seems stunning at first, but I will definitely try it in the future. Although, this method combines two memory-hungry architectures — the RNN and the encoder-decoder network — which may not be practical in actual use outside of small datasets and permissions.

ConvLSTM Layer Description

Recurrent Unet Architecture
My pipeline
You can find the details here , but my approach is as follows:
- Unet with VGG16 encoder (there are many different encoders in the repository);
- Deep Watershed;
- Many small hacks, including converting to black and white pictures and
transfer learning; - Training the model on 256x256 random crocs;
- Prediction on resize images (for image sizes to be shared by 64) ( this may be a bad choice );
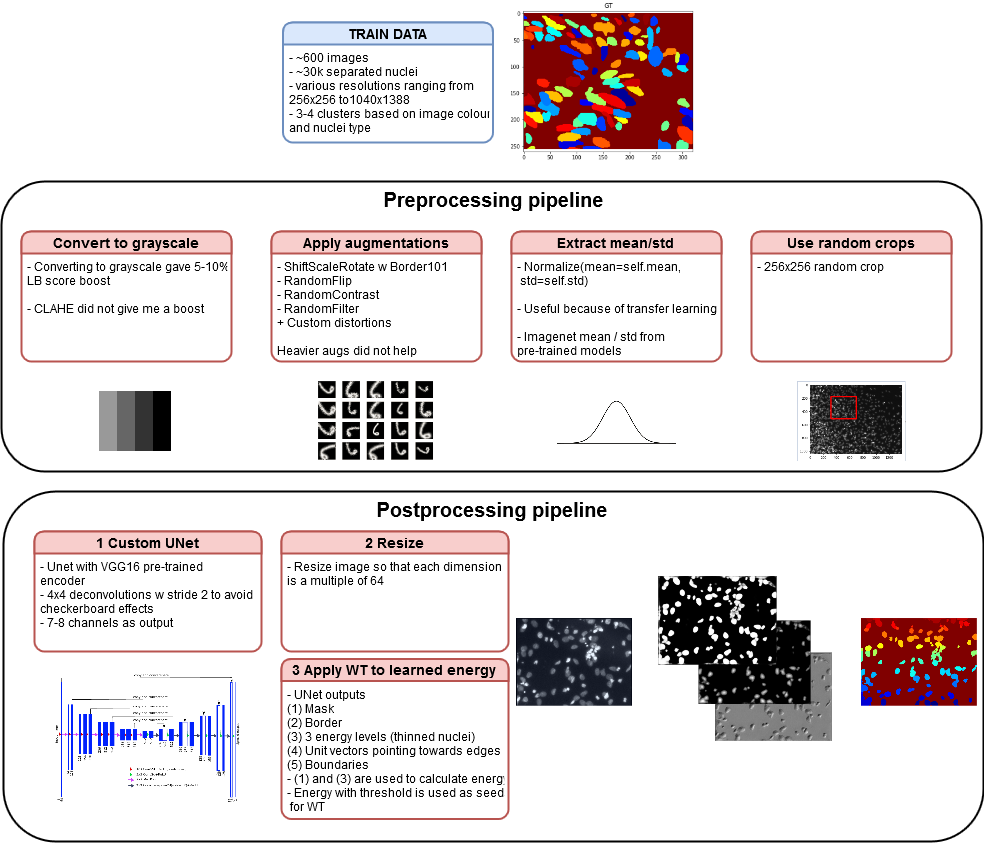
Whole pipeline
If you want to greatly improve the result of this pipeline, then you need to replace the VGG-16 encoder with Resnet152 - according to the participants of the competition, this encoder behaved much more stable on delayed validation. Also replacing softmax with sigmoid as the last activation function gives less blurred borders.
And now about how, in theory, such competitions should be organized
In short, SpaceNet from this point of view was almost perfect if you discount the annoying moments of the TopCoder platform:
- Large dataset with a balanced training sample and test sample;
- Clear restrictions on external data;
- Decrease and freeze the code for verification by the organizers
- No additional training of models between the first and second stage;
- Reproducible results;
Thanks
As always, many thanks to Dmytro for fruitful conversations and tips!
References:
- Kaggle Competition Page
- Github decision code
- Deep Watershed Transform for Instance Segmentation
- IMAGE SEGMENTATION AND MATHEMATICAL MORPHOLOGY
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Feature Forwarding: Exploiting Encoder Representations for Efficient Semantic Segmentation
- From Pixels to Object Sequences: Recurrent Semantic Instance Segmentation and Project Page
- Mask R-CNN
- Instance Embedding: Segmentation Without Proposals
- Recurrent Instance Segmentation (onvLSTM)
- TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
- Nuclei mosaic
')
Source: https://habr.com/ru/post/354040/
All Articles