10,000 likes
At the very beginning of January, coin and I roamed the cold and rainy streets of London and talked about technology, life and something else. From time to time I took photos on my old Canon EOS 400D, and at some point my friend said: “Here you take pictures, take pictures, and nobody likes your pictures”. I didn’t find what to answer, but when I returned home, I created an account in one of the social networks where I could post and like photos, and made a plan: in 100 days to gain 10,000 followers and by the end of this period receive 500 likes for the post. After that, he selected a couple of hundred interesting photos and posted the first one. And only a few people liked her. It was not enough, it was necessary to come up with some method.

To increase the number of subscribers, you need to be noticed. This can be done in many ways, but the easiest and most working one is to subscribe to someone and make photos of them in the hope that the person will do the same in response. It is thoughtless to do this not hunting for two reasons: it is very similar to spam, and there is a limit to the number of such actions. Therefore, it was necessary to figure out how to follow only those who are likely to sign up in response.
At first, I randomly subscribed to two or three thousand people, after that I wrote down in the table the three numbers that are in the user profile: the number of posts N p , the number of subscriptions N f and the number of subscribers N fd . In the last column of the M table, I entered information about whether the user subscribed to me in response or not.
')
The following seemed plausible.
Experiments with visualization have shown that everything looks better in logarithmic coordinates. Although the clouds of points intersect strongly, you can build a classifier and see what happens.
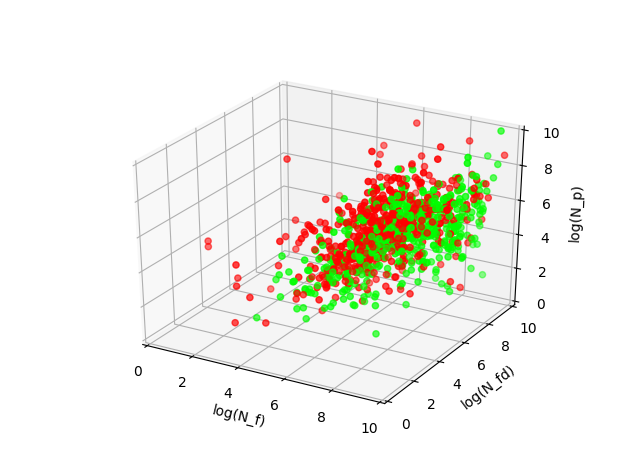
Using the support vector method, I obtained the following linear classifier, which is consistent with what was expected:
–0.19 log N fd + 0.42 log N f - 0.18 log N p > 0.57.
After that, things went more fun: 20 percent more subscribed to me back, that is, approximately every fourth or fifth. But this is not the result that I wanted. It was necessary to come up with something better.
I didn’t want to waste time extracting any other information besides the three numbers mentioned, so I wondered what would happen if we looked at these parameters again, but in three days.
Having again gathered data, I began to play with different combinations of these quantities. And it turned out that a very good result can be achieved by adding just one factor - by how much the number of subscriptions for an account has increased. It turns out that the more people have folded people in three days, the greater the chance that he will follow me.
Here, too, everything is better with logarithms, so the new factor in the end looks like this: log + ( N ' f - N f ), where the difference N' f - N f is the change in the number of subscriptions for three days,
This feature allows you to avoid logarithmic problems with negative values. Also, people who have fewer subscriptions are probably not interested in us.
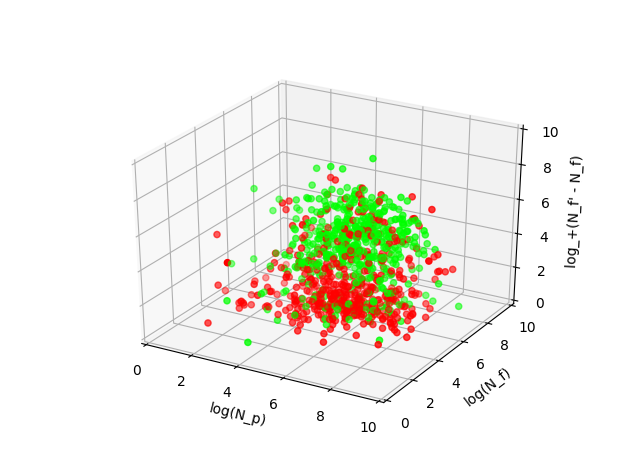
The support vector method gives the following linear classifier:
–0.06 log N fd + 0.17 log N f - 0.10 log N p + 0.16 log + ( N ' f - N f )> 0.55.
Since a mistake, when we do not subscribe to a person who subscribes to us, doesn’t particularly interest us, we can slightly increase the right-hand side of inequality in order to further improve the result. As a result, about every second subscribed to me.
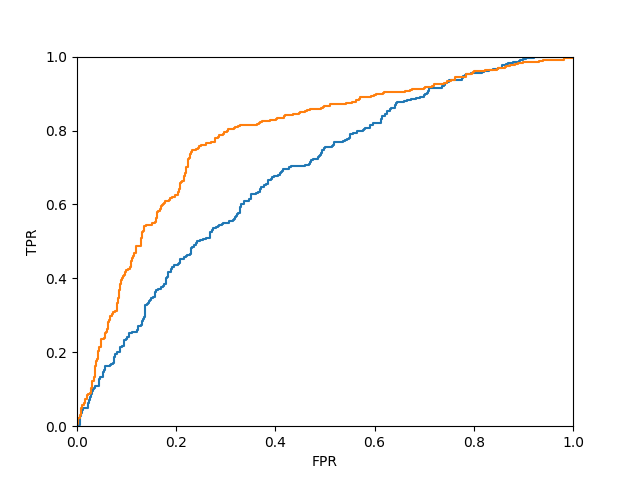
Below are the ROC curves for the two classifiers obtained.
After 87 days, having caught 10,000 subscribers, I stopped. The average number of likes of the last 15 posts turned out to be 490, which is almost equal to the number I was aiming for. Considering that I maximized the number of subscribers, and not the number of likes, I think this result is not bad, especially since it is close to the average value for such an account.
But the most interesting for me in this experiment was the fourth factor - the change in the number of subscriptions for three days. It turned out to be very simple and at the same time unexpectedly very significant.
To increase the number of subscribers, you need to be noticed. This can be done in many ways, but the easiest and most working one is to subscribe to someone and make photos of them in the hope that the person will do the same in response. It is thoughtless to do this not hunting for two reasons: it is very similar to spam, and there is a limit to the number of such actions. Therefore, it was necessary to figure out how to follow only those who are likely to sign up in response.
At first, I randomly subscribed to two or three thousand people, after that I wrote down in the table the three numbers that are in the user profile: the number of posts N p , the number of subscriptions N f and the number of subscribers N fd . In the last column of the M table, I entered information about whether the user subscribed to me in response or not.
')
The following seemed plausible.
- The more subscriptions a person has, the sooner the user will subscribe to me.
- The greater the ratio of the number of subscriptions to the number of posts, the sooner the user will follow me. (Since the more posts, the older the account. And if the account has been created for a long time, and there are few subscriptions, the user is not interested in subscribing to others.)
- The greater the ratio of the number of subscribers to the number of subscribers, the sooner the user subscribes to me. (Observation shows that this number is small for shops, bots, famous personalities, etc., and close to 1 for ordinary people.)
Experiments with visualization have shown that everything looks better in logarithmic coordinates. Although the clouds of points intersect strongly, you can build a classifier and see what happens.
Using the support vector method, I obtained the following linear classifier, which is consistent with what was expected:
–0.19 log N fd + 0.42 log N f - 0.18 log N p > 0.57.
After that, things went more fun: 20 percent more subscribed to me back, that is, approximately every fourth or fifth. But this is not the result that I wanted. It was necessary to come up with something better.
I didn’t want to waste time extracting any other information besides the three numbers mentioned, so I wondered what would happen if we looked at these parameters again, but in three days.
Having again gathered data, I began to play with different combinations of these quantities. And it turned out that a very good result can be achieved by adding just one factor - by how much the number of subscriptions for an account has increased. It turns out that the more people have folded people in three days, the greater the chance that he will follow me.
Here, too, everything is better with logarithms, so the new factor in the end looks like this: log + ( N ' f - N f ), where the difference N' f - N f is the change in the number of subscriptions for three days,
This feature allows you to avoid logarithmic problems with negative values. Also, people who have fewer subscriptions are probably not interested in us.
The support vector method gives the following linear classifier:
–0.06 log N fd + 0.17 log N f - 0.10 log N p + 0.16 log + ( N ' f - N f )> 0.55.
Since a mistake, when we do not subscribe to a person who subscribes to us, doesn’t particularly interest us, we can slightly increase the right-hand side of inequality in order to further improve the result. As a result, about every second subscribed to me.
Below are the ROC curves for the two classifiers obtained.
After 87 days, having caught 10,000 subscribers, I stopped. The average number of likes of the last 15 posts turned out to be 490, which is almost equal to the number I was aiming for. Considering that I maximized the number of subscribers, and not the number of likes, I think this result is not bad, especially since it is close to the average value for such an account.
But the most interesting for me in this experiment was the fourth factor - the change in the number of subscriptions for three days. It turned out to be very simple and at the same time unexpectedly very significant.
Source: https://habr.com/ru/post/354008/
All Articles