A simple filter to automatically remove the background from images
There are many ways to remove a background from an image of an object by making it transparent (in graphic editors, special services). But sometimes it may be necessary to remove the background from a variety of photos with minimal human involvement.
I want to share a way based on creating a transparency mask using the Sobel operator and some other transformations. The basic idea is not new at all, but the use of some additional techniques in the right order made it possible to improve the results, which this note will be about.

')
Implementation became possible thanks to OpenCV and C # wrapper OpenCVSharp .
The main task is to form an alpha channel based on the input image, thus leaving only the object of interest on it.
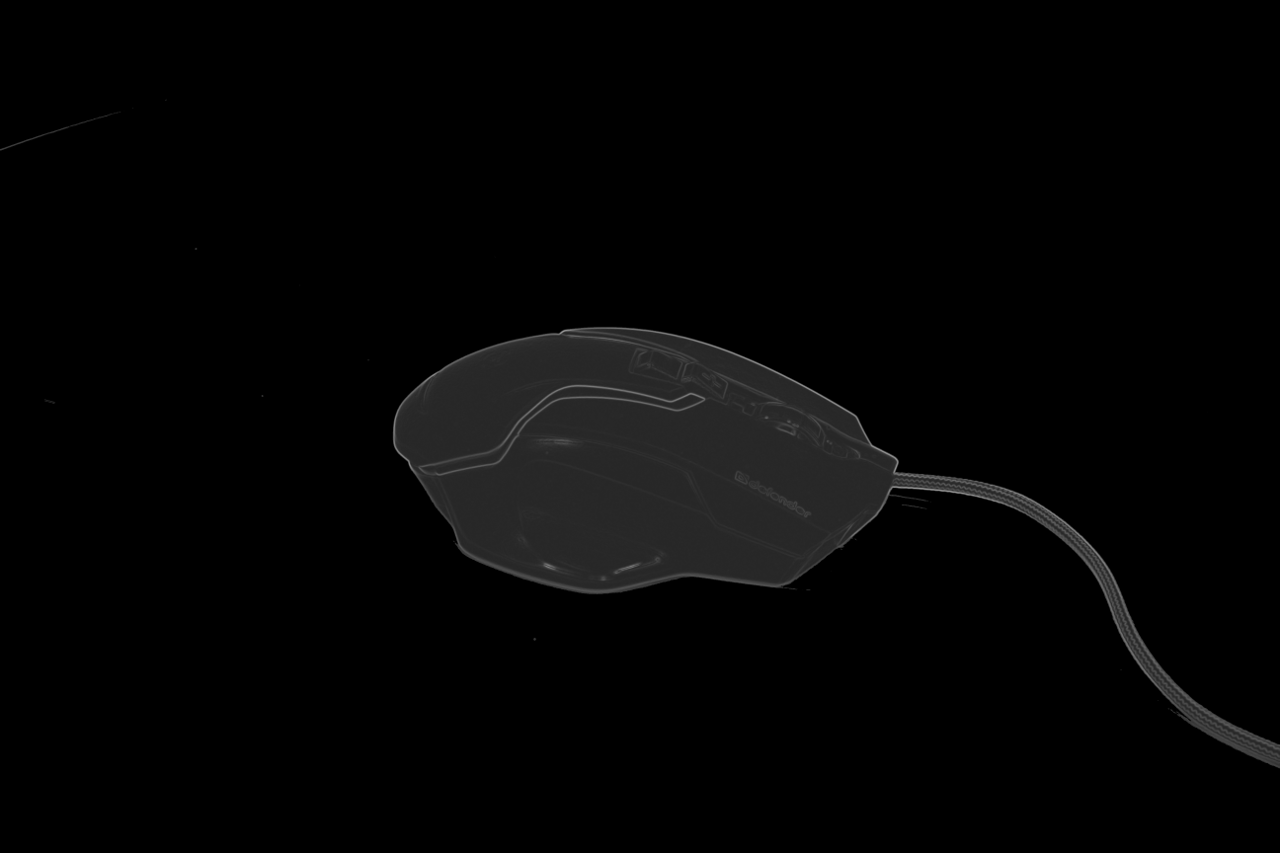
Consider each item in detail on the example of my mouse with KDPV. The full filter code can be found in the repository .
Under the spoiler, there is a base filter class that defines its interface, we will inherit from it. Introduced for convenience, it does not require special explanation, it is made in the image of BaseFilter from Accord .NET, another very worthy .NET library for image processing and more.
I will only note that the Mat used here is the universal OpenCV entity, representing a matrix with elements of a certain type (MatType) and with a certain number of channels. For example, a matrix with elements of type CV_8U3 is suitable for storing images in the RGB (BGR) format, one byte per color. And CV_32FC1 is for storing a single-channel image with float values.
The fundamental stage of the filter. In the most basic version can be implemented as:
This is a typical example of using the Sobel function:
Here you should pay attention to the following:
Unfortunately, this simple code is not always suitable. The problem is that the Sobel operator is resolution-dependent. The left half of the image below is the result for an image size of 1280x853. Right - the result for the original photos 5184x3456.

The lines of the edges of objects have become much less pronounced, since, with the same core size, the pixel distances between the same points of the image have become several times larger. For less successful photographs (the object is worse to separate from the background) important details may be completely lost.
The Sobel function can accept other kernel sizes. But to use it anyway will not work for the following reasons:
Fortunately, OpenCV allows you to independently call these functions with automatic normalization, so you don’t have to invent your own generation of cores:
The code has become somewhat more complicated and has not been without small props. Instead of using Sobel, a local Derivative function is declared, using GetDerivKernels to get normalized kernels and SepFilter2D to use them. For larger images, larger kernel sizes are selected (GetDerivKernels supports sizes up to 31). In order for the results between different sizes to have a minimum of differences, already normalized large kernels are additionally multiplied by 2 (the same backup).
Let's look at the result:

The picture is somewhat “grayed out” due to the added constant at the end. The reason for such a strange action will be understood in the next step.
Actually, fill in the simplest way - from the corner of the image. FloodFillRelativeSeedPoint is just a constant that defines the relative indentation from the corner, and FloodFillTolerance is the “greed” of the fill:
And we get:
I think it is now clear why the addition of a constant was required. It is seen that there are noises, but this is the subject of the next item. But before that, let's look at a less successful outcome of events for some other image — say, a camera photo:

It is seen that the black color "flowed" through a small gap to where it was not worth it. Of course, you can try to lower FloodFillTolerance (here is 0.04), but in this case there are more pieces of background and noise that we don’t need. And here, another very useful type of image operations is useful: morphological transformations . The documentation has a great example of their actions, so I will not repeat. Add one dilatation pass before pouring to close possible gaps in the contours:
Got better:

The local function PerformMorphologyEx simply applies the specified morphological operation to the image. In this case, an ellipsoidal structural element is selected (it can be taken rectangular, but in this case sharp right angles will appear) with a size dependent on resolution (so that the results remain consistent on different image sizes). The formula for choosing the size can still twist, it was chosen "by eye".
Here we have the perfect polygon for the application of morphological opening - in one or two passes, all these islands of gray pixels are perfectly removed, and even the remnants of many shadows. Add these three lines after the fill:
First, we do erosion to compensate for the dilation from the previous step, after which two iterations of erosion and dilation (morphological contraction and expansion, respectively). While we receive the following:

The third line (passage by erosion) is needed in order to avoid the end result
By and large, the mask is ready. Add to the end of the filter:
Here is the final result

Of course, the method is not ideal. The most notable problems:
However, for many images the result is acceptable, maybe this method will be useful to someone ( source ). My goal was to remove the background from photographs of objects taken using such turntables .
I want to share a way based on creating a transparency mask using the Sobel operator and some other transformations. The basic idea is not new at all, but the use of some additional techniques in the right order made it possible to improve the results, which this note will be about.
')
Implementation became possible thanks to OpenCV and C # wrapper OpenCVSharp .
General scheme
The main task is to form an alpha channel based on the input image, thus leaving only the object of interest on it.
- Edge detection : We create the basis for the future mask by acting on the original image using the gradient calculation operator.
- Fill : we fill the outer area with black color.
- Noise removal: we remove the non-filled islands of pixels, smooth the borders.
- Final stage : We perform binarization of the mask, slightly blur and get the output alpha channel.
Consider each item in detail on the example of my mouse with KDPV. The full filter code can be found in the repository .
Preliminary preparation
Under the spoiler, there is a base filter class that defines its interface, we will inherit from it. Introduced for convenience, it does not require special explanation, it is made in the image of BaseFilter from Accord .NET, another very worthy .NET library for image processing and more.
I will only note that the Mat used here is the universal OpenCV entity, representing a matrix with elements of a certain type (MatType) and with a certain number of channels. For example, a matrix with elements of type CV_8U3 is suitable for storing images in the RGB (BGR) format, one byte per color. And CV_32FC1 is for storing a single-channel image with float values.
Opencvfilter
/// <summary> /// Base class for custom OpenCV filters. More convenient than plain static methods. /// </summary> public abstract class OpenCvFilter { static OpenCvFilter() { Cv2.SetUseOptimized(true); } /// <summary> /// Supported depth types of input array. /// </summary> public abstract IEnumerable<MatType> SupportedMatTypes { get; } /// <summary> /// Applies filter to <see cref="src" /> and returns result. /// </summary> /// <param name="src">Source array.</param> /// <returns>Result of processing filter.</returns> public Mat Apply(Mat src) { var dst = new Mat(); ApplyInPlace(src, dst); return dst; } /// <summary> /// Applies filter to <see cref="src" /> and writes to <see cref="dst" />. /// </summary> /// <param name="src">Source array.</param> /// <param name="dst">Output array.</param> /// <exception cref="ArgumentException">Provided image does not meet the requirements.</exception> public void ApplyInPlace(Mat src, Mat dst) { if (!SupportedMatTypes.Contains(src.Type())) throw new ArgumentException("Depth type of provided Mat is not supported"); ProcessFilter(src, dst); } /// <summary> /// Actual filter. /// </summary> /// <param name="src">Source array.</param> /// <param name="dst">Output array.</param> protected abstract void ProcessFilter(Mat src, Mat dst); } Edge detection
The fundamental stage of the filter. In the most basic version can be implemented as:
As in tutorials
/// <summary> /// Performs edges detection. Result will be used as base for transparency mask. /// </summary> private Mat GetGradient(Mat src) { using (var preparedSrc = new Mat()) { Cv2.CvtColor(src, preparedSrc, ColorConversionCodes.BGR2GRAY); preparedSrc.ConvertTo(preparedSrc, MatType.CV_32F, 1.0 / 255); // From 0..255 bytes to 0..1 floats using (var gradX = preparedSrc.Sobel(ddepth: MatType.CV_32F, xorder: 0, yorder: 1, ksize: 3, scale: 1 / 4.0)) using (var gradY = preparedSrc.Sobel(ddepth: MatType.CV_32F, xorder: 1, yorder: 0, ksize: 3, scale: 1 / 4.0)) { var result = new Mat(); Cv2.Magnitude(gradX, gradY, result); return result; } } } This is a typical example of using the Sobel function:
- Let's discolor the image (there is practically no sense in the calculation of the gradient for all three channels - the result will be very little different).
- Calculate the vertical and horizontal components.
- We calculate the final result using the Magnitude function.
Here you should pay attention to the following:
- The kernel size (ksize) is transferred to the Sobel function. 3. A kernel of this size is used most often.
- A 1/4 normalization factor is also transmitted. Normalization is required to obtain a clean image with optimal brightness and minimal noise. More details can be found in this question (the value of the accepted answer to which, perhaps, exceeds the value of the entire given post).
Unfortunately, this simple code is not always suitable. The problem is that the Sobel operator is resolution-dependent. The left half of the image below is the result for an image size of 1280x853. Right - the result for the original photos 5184x3456.
The lines of the edges of objects have become much less pronounced, since, with the same core size, the pixel distances between the same points of the image have become several times larger. For less successful photographs (the object is worse to separate from the background) important details may be completely lost.
The Sobel function can accept other kernel sizes. But to use it anyway will not work for the following reasons:
- Kernels of arbitrary sizes inside are generated by integers and require normalization, otherwise the range of the values obtained will be different from 0..1 and it will be difficult to work with them further, the image will be very noisy and overexposed after applying magnitude.
- What specific kernels were chosen by the OpenCV developers for sizes larger than 5 is undocumented. You can find discussions of larger kernels, but not all of them coincide with what is used in OpenCV.
- Internal functions in deriv.cpp have a normalize boolean parameter, but the cv :: sobel function calls them with the false parameter.
Fortunately, OpenCV allows you to independently call these functions with automatic normalization, so you don’t have to invent your own generation of cores:
What happened
private Mat GetGradient(Mat src) { using (var preparedSrc = new Mat()) { Cv2.CvtColor(src, preparedSrc, ColorConversionCodes.BGR2GRAY); preparedSrc.ConvertTo(preparedSrc, MatType.CV_32F, 1.0 / 255); // Calculate Sobel derivative with kernel size depending on image resolution Mat Derivative(Int32 dx, Int32 dy) { Int32 resolution = preparedSrc.Width * preparedSrc.Height; // Larger image --> larger kernel Int32 kernelSize = resolution < 1280 * 1280 ? 3 : resolution < 2000 * 2000 ? 5 : resolution < 3000 * 3000 ? 9 : 15; // Compensate lack of contrast on large images Single kernelFactor = kernelSize == 3 ? 1 : 2; using (var kernelRows = new Mat()) using (var kernelColumns = new Mat()) { // Get normalized Sobel kernel of desired size Cv2.GetDerivKernels(kernelRows, kernelColumns, dx, dy, kernelSize, normalize: true ); using (var multipliedKernelRows = kernelRows * kernelFactor) using (var multipliedKernelColumns = kernelColumns * kernelFactor) { return preparedSrc.SepFilter2D( MatType.CV_32FC1, multipliedKernelRows, multipliedKernelColumns ); } } } using (var gradX = Derivative(1, 0)) using (var gradY = Derivative(0, 1)) { var result = new Mat(); Cv2.Magnitude(gradX, gradY, result); //Add small constant so the flood fill will perform correctly result += 0.15f; return result; } } } The code has become somewhat more complicated and has not been without small props. Instead of using Sobel, a local Derivative function is declared, using GetDerivKernels to get normalized kernels and SepFilter2D to use them. For larger images, larger kernel sizes are selected (GetDerivKernels supports sizes up to 31). In order for the results between different sizes to have a minimum of differences, already normalized large kernels are additionally multiplied by 2 (the same backup).
Let's look at the result:
The picture is somewhat “grayed out” due to the added constant at the end. The reason for such a strange action will be understood in the next step.
Note
In addition to the operator Sobel there are others that give a slightly better result. For example, in OpenCV from box Scharr is available. But only for Sobel there is a built-in generator of nuclei of arbitrary size, so I used it.
Fill
Actually, fill in the simplest way - from the corner of the image. FloodFillRelativeSeedPoint is just a constant that defines the relative indentation from the corner, and FloodFillTolerance is the “greed” of the fill:
Floodfill
protected override void ProcessFilter(Mat src, Mat dst) { using (Mat alphaMask = GetGradient(src)) { Cv2.FloodFill( // Flood fill outer space image: alphaMask, seedPoint: new Point( (Int32) (FloodFillRelativeSeedPoint * src.Width), (Int32) (FloodFillRelativeSeedPoint * src.Height)), newVal: new Scalar(0), rect: out Rect _, loDiff: new Scalar(FloodFillTolerance), upDiff: new Scalar(FloodFillTolerance), flags: FloodFillFlags.FixedRange | FloodFillFlags.Link4); ... } } And we get:
I think it is now clear why the addition of a constant was required. It is seen that there are noises, but this is the subject of the next item. But before that, let's look at a less successful outcome of events for some other image — say, a camera photo:
It is seen that the black color "flowed" through a small gap to where it was not worth it. Of course, you can try to lower FloodFillTolerance (here is 0.04), but in this case there are more pieces of background and noise that we don’t need. And here, another very useful type of image operations is useful: morphological transformations . The documentation has a great example of their actions, so I will not repeat. Add one dilatation pass before pouring to close possible gaps in the contours:
Code
protected override void ProcessFilter(Mat src, Mat dst) { using (Mat alphaMask = GetGradient(src)) { // Performs morphology operation on alpha mask with resolution-dependent element size void PerformMorphologyEx(MorphTypes operation, Int32 iterations) { Double elementSize = Math.Sqrt(alphaMask.Width * alphaMask.Height) / 300; if (elementSize < 3) elementSize = 3; if (elementSize > 20) elementSize = 20; using (var se = Cv2.GetStructuringElement( MorphShapes.Ellipse, new Size(elementSize, elementSize))) { Cv2.MorphologyEx(alphaMask, alphaMask, operation, se, null, iterations); } } PerformMorphologyEx(MorphTypes.Dilate, 1); // Close small gaps in edges Cv2.FloodFill(...); } ... } Got better:
The local function PerformMorphologyEx simply applies the specified morphological operation to the image. In this case, an ellipsoidal structural element is selected (it can be taken rectangular, but in this case sharp right angles will appear) with a size dependent on resolution (so that the results remain consistent on different image sizes). The formula for choosing the size can still twist, it was chosen "by eye".
Noise reduction
Here we have the perfect polygon for the application of morphological opening - in one or two passes, all these islands of gray pixels are perfectly removed, and even the remnants of many shadows. Add these three lines after the fill:
PerformMorphologyEx(MorphTypes.Erode, 1); // Compensate initial dilate PerformMorphologyEx(MorphTypes.Open, 2); // Remove not filled small spots (noise) PerformMorphologyEx(MorphTypes.Erode, 1); // Final erode to remove white fringes/halo around objects First, we do erosion to compensate for the dilation from the previous step, after which two iterations of erosion and dilation (morphological contraction and expansion, respectively). While we receive the following:
The third line (passage by erosion) is needed in order to avoid the end result
such a stroke
Final stage
By and large, the mask is ready. Add to the end of the filter:
Following code
AddAlphaChannel simply adds an alpha channel to the input image and writes the result to the output:
Cv2.Threshold( src: alphaMask, dst: alphaMask, thresh: 0, maxval: 255, type: ThresholdTypes.Binary); // Everything non-filled becomes white alphaMask.ConvertTo(alphaMask, MatType.CV_8UC1, 255); if (MaskBlurFactor > 0) Cv2.GaussianBlur(alphaMask, alphaMask, new Size(MaskBlurFactor, MaskBlurFactor), MaskBlurFactor); AddAlphaChannel(src, dst, alphaMask); AddAlphaChannel simply adds an alpha channel to the input image and writes the result to the output:
/// <summary> /// Adds transparency channel to source image and writes to output image. /// </summary> private static void AddAlphaChannel(Mat src, Mat dst, Mat alpha) { var bgr = Cv2.Split(src); var bgra = new[] {bgr[0], bgr[1], bgr[2], alpha}; Cv2.Merge(bgra, dst); } Here is the final result
Of course, the method is not ideal. The most notable problems:
- If you try to remove the background from a donut or similar object, the inner region will not be cut (since the fill will not go inside).
- Shadows. Partially overcome by sensitivity, partially removed along with noise, but, often, one way or another get into the final result. It remains to either live with them, or additionally implement the search and removal of shadows.
However, for many images the result is acceptable, maybe this method will be useful to someone ( source ). My goal was to remove the background from photographs of objects taken using such turntables .
Source: https://habr.com/ru/post/353890/
All Articles