Map matching and processing of raw GPS data on an industrial scale
Any measuring device, whether analog or digital, shows the result with a certain error and noise. The error of the GPS sensor is determined by the error of the sensor itself and by factors such as: landscape, movement speed, number and position of satellites.
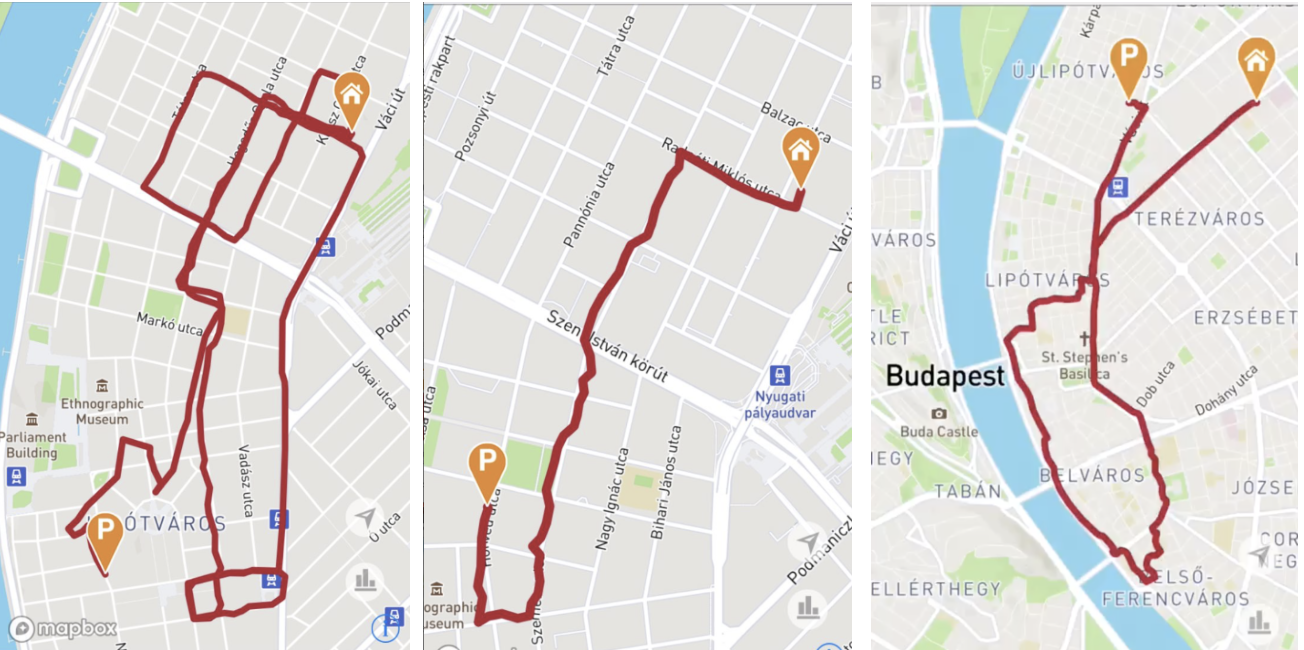
In our application, we give the user the opportunity to view in detail the routes of his travels. And if you display raw, not filtered data, it turns out that the route passes not along the road, but through buildings or water, some points of the route are very far from the neighboring or even there are no pieces of the route.
I think it is no secret that there are solutions on the market that provide the Map matching service. It performs the processing of coordinates and as a result gives the coordinates attached to the road. However, no service will understand the specifics of your data, and the result of processing raw data may not be the best. In this regard, we developed a solution that allowed us to filter and impose sensor data on the roads as much as possible.
Input data
At the time of development, the OBD-dongle transmitted telematic data to the server in the form of points, each of which had the following parameters:
- Coordinates obtained from the GPS sensor;
- The speed received from the car;
- Engine speed obtained from the car;
- Time specific point.
The points were transmitted according to the following algorithm - every 3 seconds or every 20 meters. Note that the transfer algorithm is not perfect, but within the framework of a specific problem we decided not to change it, because Obviously, if you transfer points using a more advanced algorithm, the result will only improve. Also, the dongle collected such data as: heading (motion vector) and dilution of precision (roughly speaking, GPS accuracy), but this data was not transmitted to the server.
Algorithm
The algorithm that we used can be divided into two parts:
- Data filtering;
- Map matching;
- Partial processing.
Filtration
No one knows the specifics of your data better than you. We decided to use our knowledge and filter the data on the side of our own service. Let's look at a simple route example:

The graph shows the speed of the car, received by the dongle from the car, and the speed calculated from the GPS. As you can see, there are a lot of emissions on the graph - both upwards and downwards. Standard filtering algorithms immediately come to mind: Kalman filter, alpha-beta filter. For them, we undertook in the first place. However, these filters did not perform well. There were several reasons for this: low frequency and absolute heterogeneity of data (it is difficult to choose a single modified algorithm with a suitable error), the presence of transformations of incoming data was unacceptable. Much better during testing showed a very simple linear velocity filter. The essence of the algorithm is very simple: for all neighboring points, we calculate the speed using GPS and compare it with the speed obtained from the car, and if the differences are higher than the permissible error, then we throw out one of the points.
Here is the pseudocode:
`for i in range (1, len (data)):
velocity_gps = calc_dist (data [i - 1] .lat, data [i - 1] .lon, data [i] .lat, data [i] .lon) / (data [i] - data [i - 1])
velocity_vehicle = (data [i - 1] .speed + data [i] .speed) / 2
relative_error = abs (velocity_gps - velocity_vehicle) / (velocity_vehicle)
if relative_error> 1.5:
data.remove (data [i]) ` As a result of filtering, we obtain data without emissions, while points still do not fall on the road. However, before the Map matching procedure, it’s worth to thin our data, It makes no sense to transfer 10 points lying on one line, when two points are enough to define a line. However, you don’t have to be zealous with filtering, for the Map matching service can count our data as noise. To remove the extra points, we used the Ramer-Douglas-Peucker algorithm, or rather its slightly modified version.

For a time-ordered pack of points, we calculate the distance for all points to the arc connecting the first and last points of the pack. If the distance from each point is less than some value of E, then only the starting and ending points of the pack are returned. Otherwise we divide the pack into two, division occurs at the point as far as possible from the arc, and then repeat the procedure.
Map matching
Due to the fact that the maps for our mobile applications and portals are provided by the Mapbox service, it was decided to use their Map matching service. But we immediately faced a limitation - 100 points in the query. Even taking into account filtering and reducing the number of points by the RDP algorithm, the average number on our routes is 250 points. Accordingly, we need to handle batch files (batch), plus everything overlap, since in some cases, with simple batching, processing errors will occur. The batching algorithm is as follows:
- N - the number of points for processing overlap;
- Cut the route into batches of no more than 100-N;

- Then we process the first batch;
- We take the last N points of processed data and the second batch;
- We continue to the last batch;
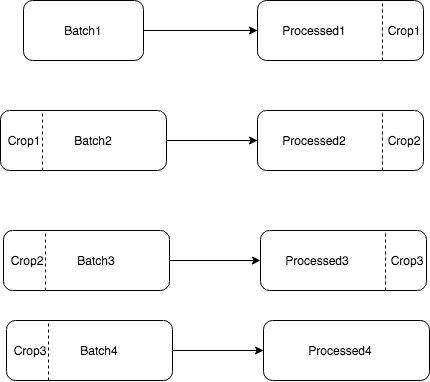
- The end result consists of Processed1, Processed2, Processed3, Processed4.

The next problem we encountered was the determination of the accuracy of the data. The Mapbox API requires you to specify the accuracy of the data being transferred, even though this parameter is specified as optional in the document. And if not to transfer it, it will be exposed from default value. The parameter responsible for accuracy is gps_precision. This is what the documentation says about it:
The used tracking device. Use higher numbers (5-10) for noisy traces and lower numbers (1-3) for clean traces. The default value is 4.
However, we did not transmit this data from the dongle at the time of developing the service. Due to the rare frequency of the data, the use of noise level determination algorithms was impossible. Thus, we processed a certain number of routes and tried to find the most suitable parameters. But how to choose the best option for 1000 routes? Manually doing it is impractical. It turned out that this process can be automated due to the specificity of the results with the unsuccessfully chosen parameter. If you select too low a parameter value, pieces of the route may disappear, and if you overstate a parameter, then extra loops will appear.

The DTW algorithm is well suited to detect such cases. As a result of processing 1000 routes and comparing the results of work using the DTW algorithm, it became clear that the best results are obtained with the values of precision 3, 6, 10 (in different cases).
As a result, in the absence of GPS data on accuracy, we launched processing in parallel with three different gps_precision (3,6,10), and then chose the best of them. It was also planned to add a shipment of the dilution parameter from the dongle, which made it possible to greatly improve the quality of service.
Partial processing
The end points of the routes are often in places where the road is not marked on the map (parking, paths between houses, etc.). Algorithms Map matching in such situations do not work very well, and I would like to specify as precisely as possible where the user left his car. To solve this problem, we began to perform a cycle of processing not the entire route, but only internal points: we discard the beginning and end of the route, then add the beginning and end of the original route to the processed data. The beginning and the end are defined as follows: we take 5% of the route or a part before the speed of the car becomes more than 10 km / h.
Final result
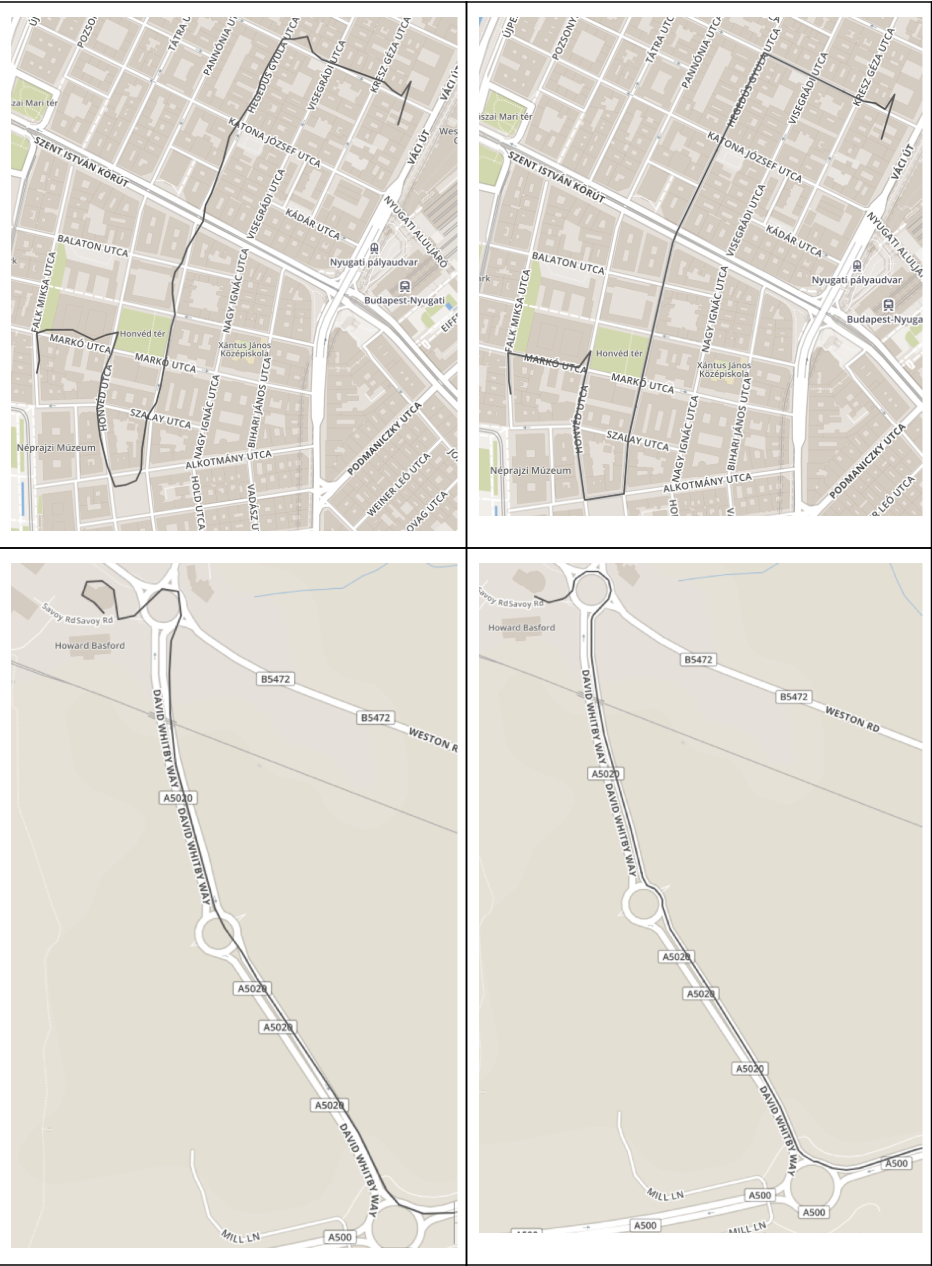
In the end I would like to demonstrate the result of processing routes. As a result, routes pass almost everywhere along the roads, loud noises have disappeared, the missing pieces of routes have been restored (riding on a ring or a bridge).

Author: Kirill Kulchenkov, kulchenkov32 , Senior Software Developer, Bright Box.
')
Source: https://habr.com/ru/post/353868/
All Articles