Three data centers without seams, or how VTB protects business systems
VTB's retail business is served by more than 150 systems, and everything needs to be securely protected. Some systems are critical, some are tightly tied to each other - in general, the task is ambitious. In this post you will learn how it was solved. So that even when a meteorite falls on one of the data centers, the work of the bank is not interrupted, and the data remain intact.

Initially they planned to implement a disaster-proof solution from two identical data centers, the main and the backup, with a “manual” switch to the backup site. But with such a scheme, the backup site would stand idle, although it would require the same maintenance as the main one. As a result, we decided to apply an active-active scheme, in which both data centers (separated by 40 km) operate in a regular mode and serve business systems simultaneously. As a result, the total capacity and performance doubles, which is especially important at peak loads (there is no need to scale). And maintenance can be carried out without compromising business processes.

')
Creating a disaster-proof data center system was divided into two stages. On the first, about 50 important business systems were reserved for which RPOs should be close to zero — including ABS, anti-fraud, processing, CRM, and remote banking, providing online connections for both individuals and legal entities. Such a variety of systems has become the main difficulty in the development of design solutions for redundancy infrastructure.
In the first approximation, everything was built on standard solutions. But when the sketch began to be applied to real business systems, it turned out that a lot of work had to be done on the file: many components simply could not be described with typical solutions. In such cases, it was necessary to look for individual approaches, for example, for the largest business system — the ABS “Glavnaya Kniga”. We also had to rework a typical solution for Oracle, because it did not meet the requirement of a complete absence of data loss. The same thing happened with Microsoft SQL databases, and with a number of other systems. Among the critical ones were internal information buses, through which other systems exchange data. In particular, UBS-front and UBS-back.

Reservation scheme of IS USB-front
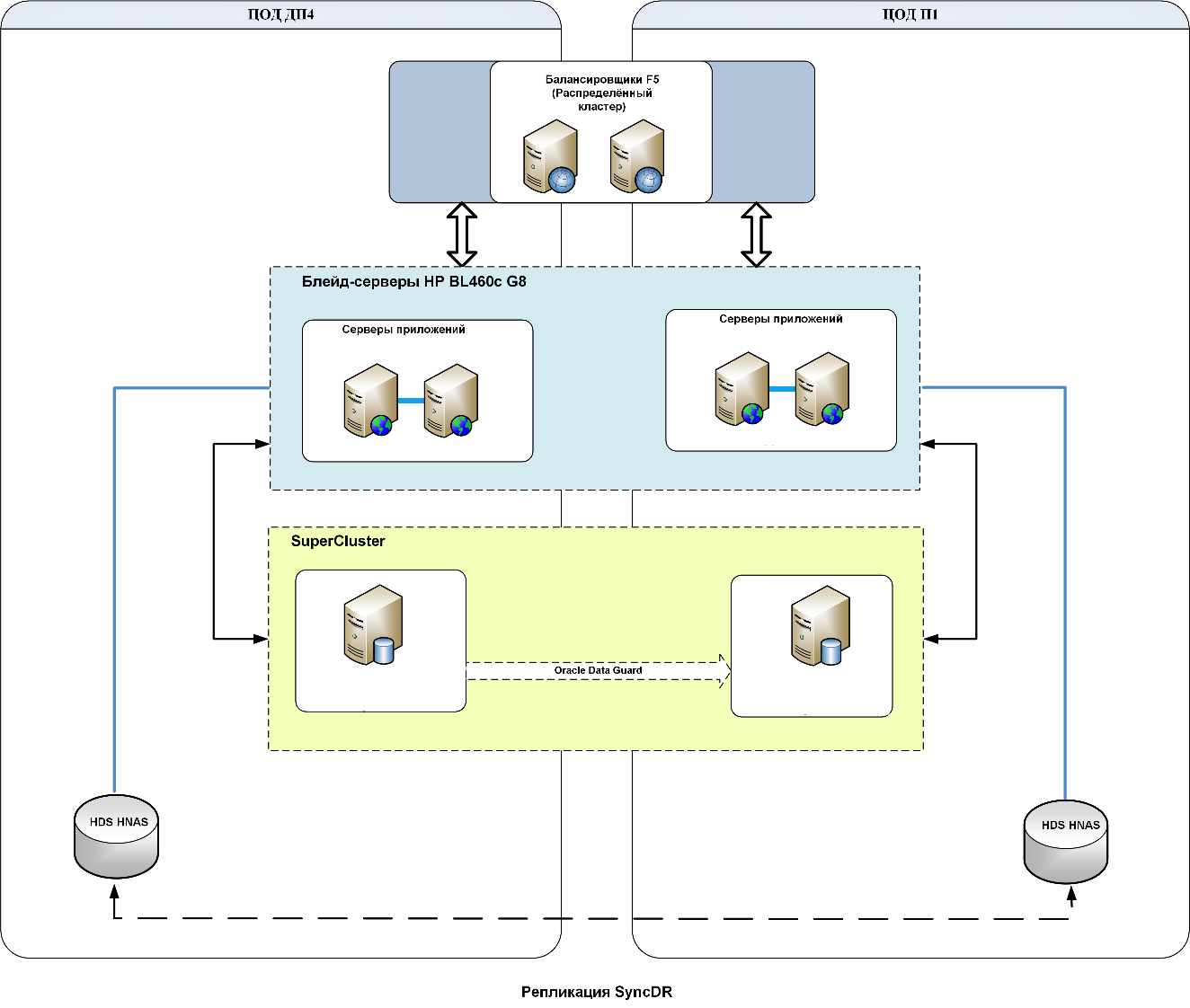
Reservation scheme of IS USB-back
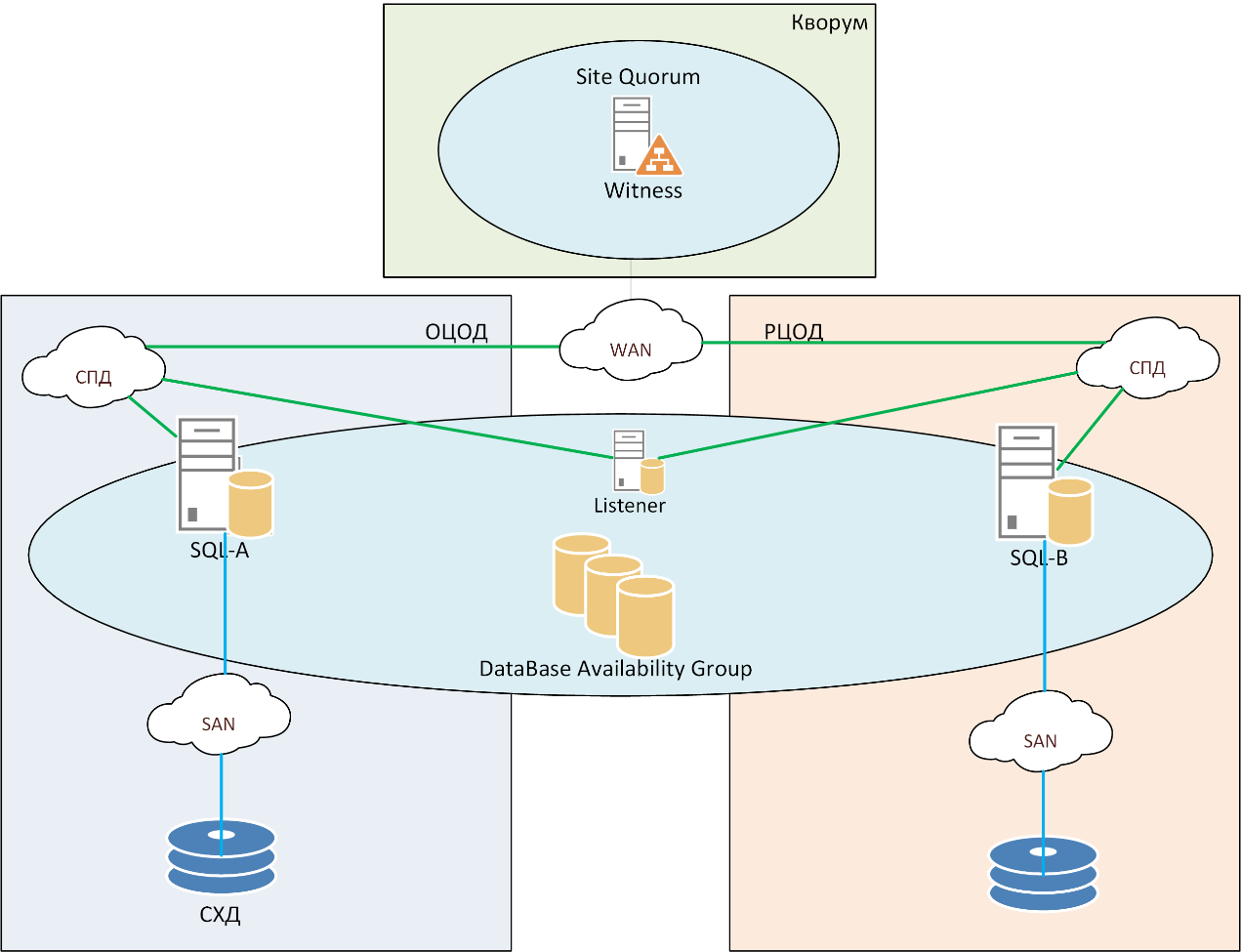
MS SQL Server Backup Scheme
In addition to the two main data centers operating in active-active mode, a third data center was created, which contains devices that act as coordinators. This is done so that in the event of a break in communication between the two main sites, a split-brain situation does not arise. The network of two main data centers is flat, without routing, built on Cisco equipment, uses the L2 tunnel in L3 via OTV, and the sites themselves are connected via MPLS over fiber (going in two different ways). A 160 Gbps channel is used for the data network, and 256 Gbps for the storage network. In the storage area network, both sites are connected by optics.
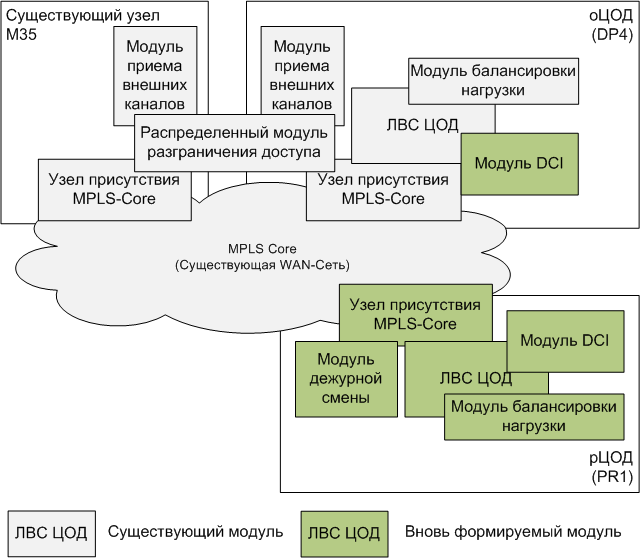
Data Network Diagram
For the implementation of the project, we purchased only 40% of the equipment, the remaining 60% were already available.
On both sites, the storage systems are combined, and for universal access from the outside to the application server, a cluster of F5 BIG-IP balancers is made. For VMware, a stretched VMware cluster was built, EMC VPLEX virtualizers and EMC Vmax and Hitachi VSP disk arrays were used, which were connected to virtualization clusters at sites. The file service is extended between two data centers and built on Hitachi technologies: Hitachi GAD is used to synchronize data between sites, and HNAS clustered devices located in both data centers are used to provide file services.
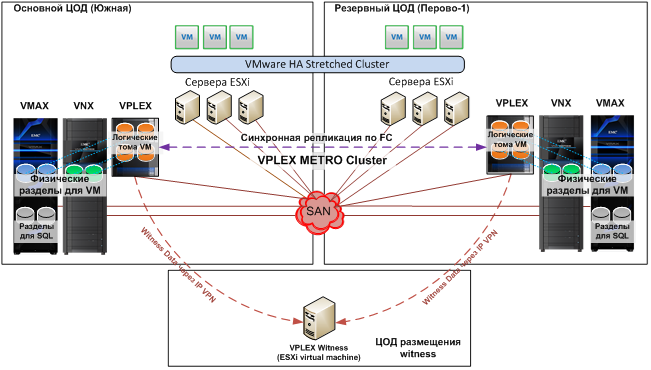
VMware and VPLEX Disk Array Interaction Diagram
For databases, we use replication with built-in tools: Oracle Data Guard for Oracle and Always On for Microsoft SQL servers. To avoid data loss, Always On works in synchronous mode, while Oracle is simultaneously recording redo to another site, this will allow to recover at the last moment. The technique is developed, debugged and documented.
The databases of many systems use IBM Power servers, 1700 Hewlett Packard x86 blade servers from different generations, mostly dual-processor. The network is built on Cisco Nexus 7000 equipment, SAN - on Brocade DCX of different generations. Also, the Oracle engineering systems are distributed over the platforms: Exadata, SuperCluster, Exalogic.
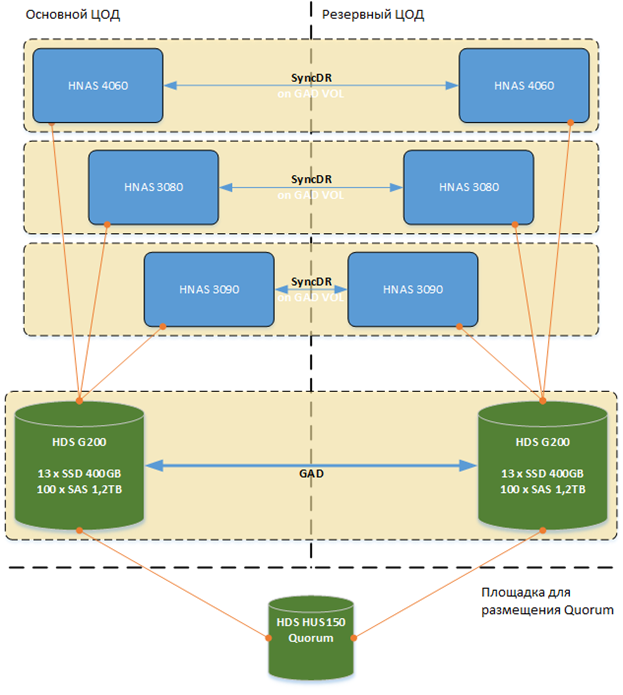
File Service Scheme
The usable capacity of the reserved systems in each of the two main data centers is approximately 2 petabytes. Only storage, virtual machine systems and file services are reserved by hardware. All other databases and application systems are backed up by software. Synchronization between arrays is performed in the file service using Hitachi GAD technology. In all other cases, the data is replicated by means of the databases or applications themselves.
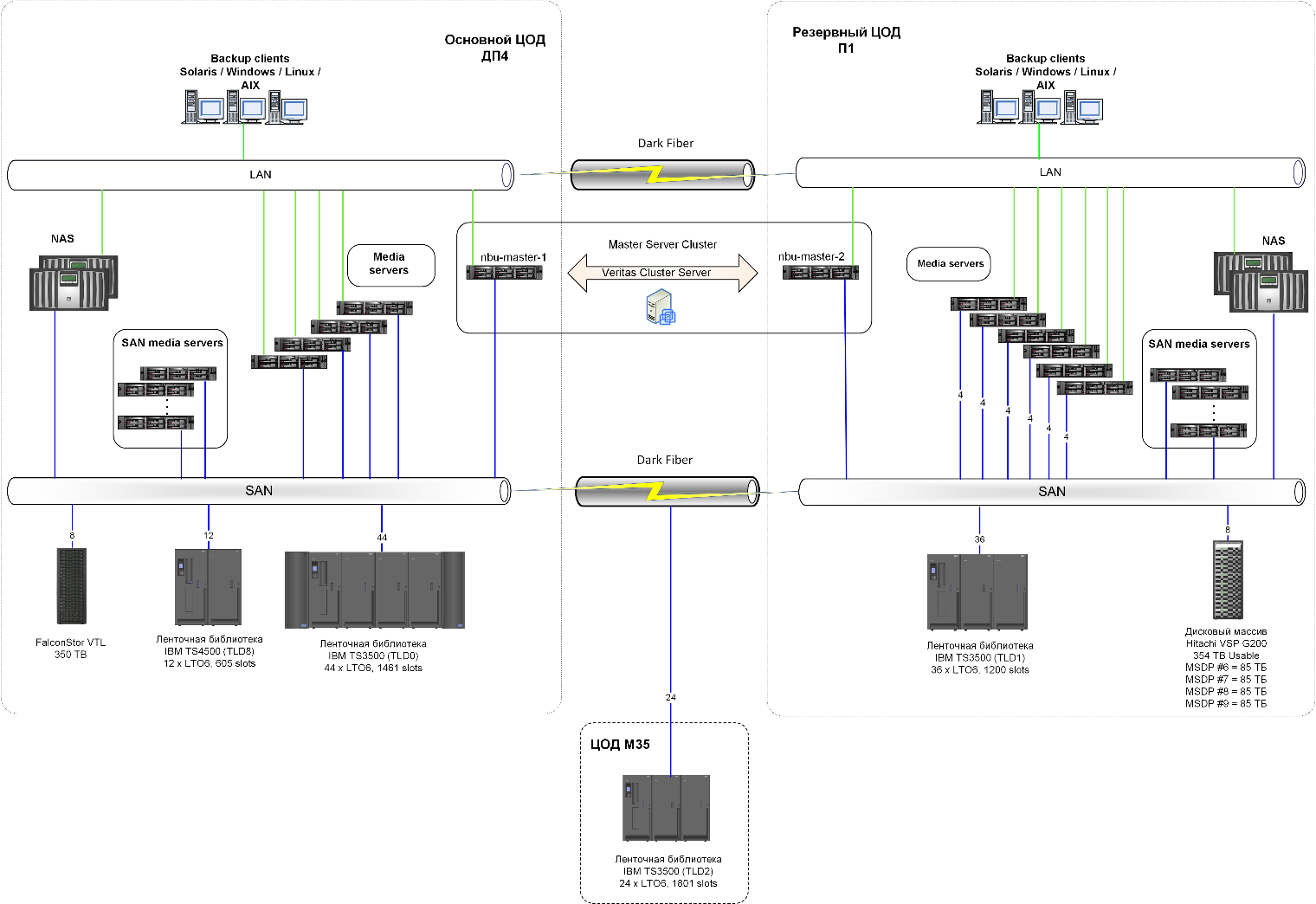
Scheme of IBS
After completing the first stage - backing up about 50 of the most critical business systems - we and colleagues from Jet Infosystems checked the operation of all the elements: networks, disk arrays, storage virtualization and others. We tested the operation of each business system while simultaneously using the data center and switching between them: putting the system into a disaster-resistant environment, then completely switching to another data center, checking the system operation there and returning it back to normal production environment. During all tests, performance was measured and dynamics measured. With any schemes of work and switching performance has not decreased, accessibility is not affected. As a result, we provided a seamless connection between data centers at the level of physical servers (cluster configuration), virtual infrastructure (distributed cluster), data storage systems (mirroring), and data networks (redundant network core).
Ahead is a new stage - transfer to a disaster-resistant model of other business systems of the bank. The project is being implemented by Jet Infosystems .
Project development
Initially they planned to implement a disaster-proof solution from two identical data centers, the main and the backup, with a “manual” switch to the backup site. But with such a scheme, the backup site would stand idle, although it would require the same maintenance as the main one. As a result, we decided to apply an active-active scheme, in which both data centers (separated by 40 km) operate in a regular mode and serve business systems simultaneously. As a result, the total capacity and performance doubles, which is especially important at peak loads (there is no need to scale). And maintenance can be carried out without compromising business processes.
')
Creating a disaster-proof data center system was divided into two stages. On the first, about 50 important business systems were reserved for which RPOs should be close to zero — including ABS, anti-fraud, processing, CRM, and remote banking, providing online connections for both individuals and legal entities. Such a variety of systems has become the main difficulty in the development of design solutions for redundancy infrastructure.
In the first approximation, everything was built on standard solutions. But when the sketch began to be applied to real business systems, it turned out that a lot of work had to be done on the file: many components simply could not be described with typical solutions. In such cases, it was necessary to look for individual approaches, for example, for the largest business system — the ABS “Glavnaya Kniga”. We also had to rework a typical solution for Oracle, because it did not meet the requirement of a complete absence of data loss. The same thing happened with Microsoft SQL databases, and with a number of other systems. Among the critical ones were internal information buses, through which other systems exchange data. In particular, UBS-front and UBS-back.
Reservation scheme of IS USB-front
Reservation scheme of IS USB-back
MS SQL Server Backup Scheme
In addition to the two main data centers operating in active-active mode, a third data center was created, which contains devices that act as coordinators. This is done so that in the event of a break in communication between the two main sites, a split-brain situation does not arise. The network of two main data centers is flat, without routing, built on Cisco equipment, uses the L2 tunnel in L3 via OTV, and the sites themselves are connected via MPLS over fiber (going in two different ways). A 160 Gbps channel is used for the data network, and 256 Gbps for the storage network. In the storage area network, both sites are connected by optics.
Data Network Diagram
Infrastructure
For the implementation of the project, we purchased only 40% of the equipment, the remaining 60% were already available.
On both sites, the storage systems are combined, and for universal access from the outside to the application server, a cluster of F5 BIG-IP balancers is made. For VMware, a stretched VMware cluster was built, EMC VPLEX virtualizers and EMC Vmax and Hitachi VSP disk arrays were used, which were connected to virtualization clusters at sites. The file service is extended between two data centers and built on Hitachi technologies: Hitachi GAD is used to synchronize data between sites, and HNAS clustered devices located in both data centers are used to provide file services.
VMware and VPLEX Disk Array Interaction Diagram
For databases, we use replication with built-in tools: Oracle Data Guard for Oracle and Always On for Microsoft SQL servers. To avoid data loss, Always On works in synchronous mode, while Oracle is simultaneously recording redo to another site, this will allow to recover at the last moment. The technique is developed, debugged and documented.
The databases of many systems use IBM Power servers, 1700 Hewlett Packard x86 blade servers from different generations, mostly dual-processor. The network is built on Cisco Nexus 7000 equipment, SAN - on Brocade DCX of different generations. Also, the Oracle engineering systems are distributed over the platforms: Exadata, SuperCluster, Exalogic.
File Service Scheme
The usable capacity of the reserved systems in each of the two main data centers is approximately 2 petabytes. Only storage, virtual machine systems and file services are reserved by hardware. All other databases and application systems are backed up by software. Synchronization between arrays is performed in the file service using Hitachi GAD technology. In all other cases, the data is replicated by means of the databases or applications themselves.
Scheme of IBS
Testing
After completing the first stage - backing up about 50 of the most critical business systems - we and colleagues from Jet Infosystems checked the operation of all the elements: networks, disk arrays, storage virtualization and others. We tested the operation of each business system while simultaneously using the data center and switching between them: putting the system into a disaster-resistant environment, then completely switching to another data center, checking the system operation there and returning it back to normal production environment. During all tests, performance was measured and dynamics measured. With any schemes of work and switching performance has not decreased, accessibility is not affected. As a result, we provided a seamless connection between data centers at the level of physical servers (cluster configuration), virtual infrastructure (distributed cluster), data storage systems (mirroring), and data networks (redundant network core).
Ahead is a new stage - transfer to a disaster-resistant model of other business systems of the bank. The project is being implemented by Jet Infosystems .
Source: https://habr.com/ru/post/353842/
All Articles