It's all about the combination: the history of the security system of one site

One of the customers, a very large online store, once asked us to protect the web application from web attacks. Given the scale of the resource, we began to search for the right approach. As a result, we decided to apply a combination of positive and negative security models, implementing it using a firewall for web applications (in this case, the F5 ASM product was used as WAF, but the overall approach is universal for most WAF). Many companies do not like to use a positive model, because they are very afraid (and often fair) that for some users the resource may be unavailable and sales will decrease, and even have to spend a lot of time setting policies. However, without this, the protection of the web resource will not be complete.
What is a positive and negative model?
The negative security model is probably the simplest thing that can be in a WAF. From the point of view of the logic of work, of course. The setting itself can be quite non-trivial. The negative model can be described by the principle “ what is not forbidden is allowed ”. This is usually a set of security policies and signatures that contain descriptions of known attacks. For obvious reasons, it is impossible to rely solely on such an approach: there will always be a whole bunch of attacks for which no policies or signatures are written. However, this model should not be neglected either, since it is the first line of defense, especially when you do not have a ready-made positive model or it is in the process of building.
A positive security model describes the structure of a web resource with all possible limitations. This model works according to the principle: “ what is not allowed is forbidden ”. Deviations from this model should be blocked. The positive security model is based on URLs, parameters and methods. Moreover, a positive model can be configured very rigidly, for example, for each URL to describe which methods you can use for it, which parameters, describe the valid values of these parameters, from which URLs you can go to it. Creating such a model for a large site is no easy task. And if the site also changes every week or two, it is not easy to keep the worn out and polished model up to date. It should also be borne in mind that no one can guarantee the absolute correctness of the constructed model. This means that absolutely normal user requests may well be blocked. Hence we conclude that a positive model is, of course, good and safe, but problems may arise with the availability of the resource. A rigidly defined positive model is viable only for small infrequently changing resources. Therefore, for large and rapidly changing, it will be necessary to weaken it for the sake of accessibility. But more on that later.
As a result, we get that using only one of these models has significant drawbacks: for a negative model, this is a low level of security, for a positive one - possible problems with the availability of a web resource. But if you combine both solutions, you can already get an acceptable level of both security and resource availability.
')
Protection system design
This is what the weekly average distribution of the types of attacks on the online store of the customer looks like (based on the response of the negative model):
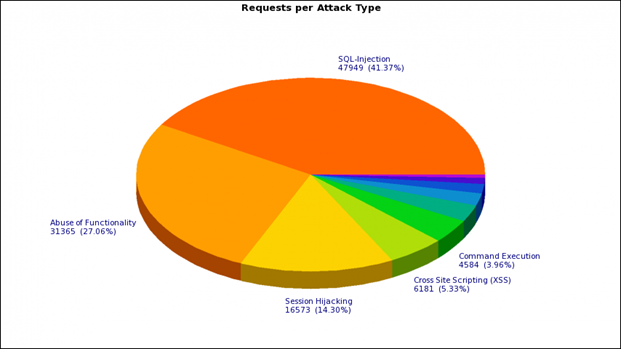
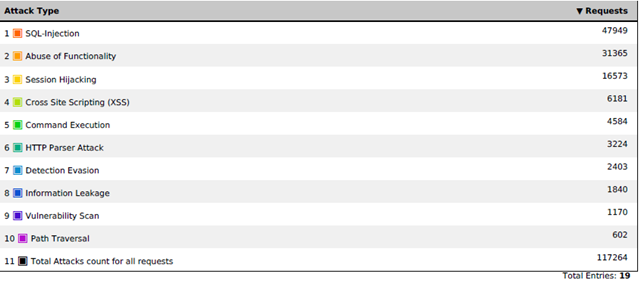
As you probably already understood, we decided not to deviate from the classical approach to protecting a web application and create a hybrid of positive and negative models. Started with a negative. The F5 ASM has a large set of signatures available from the box — just select the appropriate groups from the list. Signatures can be both system-independent and designed for a specific type of system (IIS, Apache, MySQL, MSSQL, etc.). Assigning all signatures in a row is impractical - it will only increase the load on WAF and may lead to additional false positives. For example, if you have IIS on Windows, there is not much point in assigning Linux group signatures, unless you want to get rid of all garbage requests going to the web server, even if they can do no harm.
Signatures are a relatively accurate method, but you may not experience illusions: you will still not be able to avoid false positives. For example, we are faced with a situation where developers have included the word “shell” in the name of several URLs (in the context of “bumper” or “cover”). For such cases, of course, you have to set up exceptions. After processing false positives, setting up exceptions for some cases or turning off the signature in principle - for others, we got a base to protect the site. I almost forgot: in addition to signatures, WAFs can validate web requests for RFC compliance, which allows you to block all garbage and incorrectly formed HTTP requests. Of course, we did not neglect such protection.
But to find an approach to a positive security model, we had to pretty much sweat. There are more than 10 thousand different URLs on the site. The very first and the most insane thought was to build a full-fledged positive model with a full list of URLs, but we quickly realized the inappropriateness of this approach. And before we understood this, we managed to try to get this list automatically.
An important remark: you can build a positive model in manual mode, but the pleasure is dubious. Modern WAFs have an automatic learning mechanism that, based on user requests, builds the very positive model.
But not every machine learning is equally useful. Yes, in order for an element to fall into a positive model, it must meet in more than one web request, and also come from different addresses. But in the end it turns out all the same pretty decent amount of garbage that needs to be cleaned. Also, do not forget about the URL and parameters with dynamic elements. There may be a lot of them, and they can make a positive model unattended. After the automatic training, we got something that was unattended. It was aggravated by the fact that every day from a few tens to hundreds of URLs were added / removed to the web resource and the system simply did not have time to make changes so quickly.
The second attempt to obtain a list of URLs automatically involved reading sitemap.xml, which in turn contained links to pages with the necessary content, as we then thought. The list of URLs obtained in this way, we downloaded the API. He was pretty big. However, this list was not complete.
After the experiments, we reluctantly decided to abandon the white list of the URL, so as not to produce a bunch of policy triggers if there is no URL in the specified list. Instead, we decided to resort to a different approach - protection based on parameters, in which both user data and some internal data are transmitted. The greatest number of attacks is carried out just through the parameters. Taking into account the fact that we refused the “white list” of the URL, we decided to protect the parameters without reference to a specific URL. The WAF used in this project is such an opportunity due to the use of the concept of Global Parameters.
The problem may arise if there are parameters with the same name on different URLs, but containing different data types. Usually, though, so few do. But if you encounter a similar problem, you will have to define these parameters for each URL separately and specify different valid values for them.
In the case of the online store that we defended, the rule rather than the exception worked, and if there were parameters with the same name on different pages, they contained data of the same type. We also proceeded from the principle that it is extremely difficult to attack through parameters that can contain only numeric-literal values without special characters . And therefore, in the list of protected parameters, they placed only those that contain special characters , all the others described as “*”. Thus, if the parameter containing the special character appears, we add it to the list. For all other parameters there is a restriction: they must contain only numeric-letter values.
The result was about 300-400 parameters. This model is quite possible to serve. After this model has stabilized, and the number of false positives has decreased to an acceptable value, the next stage has come, which many ignore due to strained relations between departments. And absolutely nothing. It is highly desirable to coordinate the resulting model with the developers of the customer’s web application. This step can significantly improve the quality of the constructed model. In our case, on the part of the customer, quite sensible specialists worked, who, despite their high employment, went to meet us. We did not waste time introducing developers to the WAF interface. Instead, they wrote a simple Python script that parses the WAF policy in XML format and gives a csv-file with the list of parameters and special characters allowed for them. The file is transferred to the developers, they look for the necessary parameter in their dictionary and correct the valid values if necessary.
One of the problems of the positive security model is that it is difficult to limit some of the parameters. For example, user-entered comments, especially when the customer does not want to restrict users. In this case, to protect such parameters, you will have to use the services of a negative security model, checking user input for the presence of known malicious code. And of course, such parameters should be additionally carefully checked on the side of the web server itself.
Another feature that you encounter is user input errors. For example, in the input field of the city name the user writes “ {f, fhjdcr ” instead of “Khabarovsk”. As a result, his request should be blocked, because it violates the valid values of the parameter, in which there can be only numeric-letter values. It would seem that nothing terrible: the user was mistaken - the user paid. But not all customers can be satisfied with such a WAF reaction, and in this case it will be necessary to weaken the positive model for the sake of functionality.
As a result, we got a combined system that combines both models. Next begins a rather tedious update process. With each release of patches or releases, the positive model may change, new false positives may occur in one or the other.
Well, after this begins the most crucial stage - the inclusion of a blocking mode. Up to this point, WAF, of course, works by generating security events, but does not increase the security of the web resource and does not affect user activity in any way.
In our case, due to the complexity of the approvals on the customer side, the process of switching on the blocking mode was greatly delayed. There was not enough strong-willed decision that would allow to move on. Therefore, for a sufficiently long period of time, we simply updated the existing models.
Commissioning
Finally, the customer decided, but put forward a number of fairly stringent requirements. The number of false positives should be minimal, and the availability of the site should be maximized. The requirement is, of course, excellent, but difficult to implement in practice. At the same time, we did not provide any quantitative metrics to fulfill these requirements. On average, the number of web requests per day was in the range of 100-150 million
As previously shown in the figure, on average, the negative model worked about 100-150 thousand times a week, which gives a figure of about 20 thousand positives per day. Most of these triggers are really attacks, in most cases automated. Based on our observations, the number of false positives as a percentage was no more than 5%. I’ll just make a reservation: we didn’t view all 20 thousand requests per day, however, these attacks are rather easily eliminated when analyzing the IP addresses of the attackers. It makes no sense to look at all requests from the attacker's address, two or three is enough.
The positive model gave about 50 thousand more hits per day. For the most part, they duplicated the negative model alerts, and such responses could easily be thrown out of the analysis, but about 20 thousand queries had to be analyzed. And here a lot depends on how WAF can group responses, simplifying the analysis. In our case, WAF grouped the triggers by special characters, and then by the parameters in which this special character was encountered. Then everything is more or less simple: we look at the combination, the parameter is a special character for which there were the greatest number of operations. If they were from a large IP range, this is a sign that the alarm could be false. And then analyze the examples of requests. In most cases, it is possible to understand, without help, an attack, a user input error, or a lack of a positive model. In the case of controversial situations, you should not disdain communicating with developers (if, of course, there is such an opportunity). After completion of the analysis of mass positives, we proceed to the analysis of single positives. They are usually more difficult to analyze, especially at the very beginning, when you do not know the specifics of the applications. Upon completion of the analysis, we get from 5 to 10% of false positives, which together with the false positives of the negative model gives up to 6,000 false positives or 0.005% of the total number of requests. This figure is no longer frightening - as a result, she arranged for the customer. Important note: this does not mean that the work of 6000 users will be paralyzed. Just when switching to some page or entering some data, the user will be redirected to the page with an error, after which he will be able to continue to interact normally with the web resource.
Total: the numbers have been received and they suit the customer, however, it will not be superfluous to be safe, especially if the client himself insists on this. We decided to introduce the protection system into operation in stages. For the test blocking inclusion, we were kindly provided with a macro-region, in which the customer is testing his new releases and patches. The traffic there is quite militant, the regions change periodically and there are millionaire cities / regions. We copy the existing policy and apply it to the macro-region. And then we turn on blocking, but also not immediately, but only for the negative model. We test during the week - the number of false positives did not exceed the calculated value. After that, we turn on blocking based on the negative model for the entire site, we also look at the week, measure the indicators. Then we do the same trick with a positive model: first we turn on the lock for the macro-region, for a week or two we look at the results and turn on the lock for the whole site. It may seem that everything went suspiciously smooth, but do not forget that this was preceded by a long stage of updating the models, which allowed us to turn on the defense rather painlessly.
What to do if there is no full-fledged test zone (test macro-region in our case)? You can select a group of internal employees who will also access the resource through WAF and enable blocking only for this group of users. Yes, such testing is less complete, but still better than nothing.
According to the results, it can be recognized that WAF is either slow or poor quality. Many customers are not ready to wait for enough time to form a high-quality positive model, or they don’t want / do not have the opportunity to update it. In this regard, they either abandon the positive model, or leave it to their fate, not including blocking. There are still those who fully rely on the automatic construction of a positive model, in the end it turns out far from ideal. Both of these approaches are not able to provide full protection. By setting WAF must be approached thoroughly. The time spent is worth it.
Andrei Chernykh, expert of the Information Security Center "Jet Infosystems"
Source: https://habr.com/ru/post/353718/
All Articles