We write our own clever thread_pool-dispatcher for SObjectizer
What is this article about?
One of the main distinguishing features of the SObjectizer C ++ framework is the presence of dispatchers. Dispatchers determine where and how the actors (agents in the SObjectizer terminology) will handle their events: on a separate thread, on a working thread pool, on one thread common to a group of actors, etc.
SObjectizer already includes eight full-time dispatchers (plus one more in the set of extensions for SObjectizer ). But even with all this diversity there are situations when it makes sense to make your own dispatcher for a specific specific task. The article just examines one of these situations and shows how you can make your own dispatcher, if the staff dispatchers for some reason do not like us. And at the same time it will be shown how easy it is to change the behavior of an application just by tying the same actor to different dispatchers. Well, a few more interesting little things and not very small things.
In general, if someone is interested in touching on the details of the implementation of one of the few living and developing actor frameworks for C ++, then we can safely read further.
')
Preamble
Recently, one of the users of SObjectizer talked about a specific problem that he had to face in the process of using SObjectizer. The point is that, on the basis of SObjectizer agents, an application is being developed for managing devices connected to a computer. Some operations (namely, the operation of initializing and re-initializing the device) are performed synchronously, which leads to blocking of the working thread for some time. The same I / O operations are carried out asynchronously, so the read / write initiation and the read-write result processing are performed much faster and do not block the working thread for a long time.
There are many devices, from several hundred to several thousand, so using the “one device - one working thread” scheme is not profitable. Because of what the small pool of working threads on which all operations with devices are performed is used.
But such a simple approach has an unpleasant feature. When a large number of applications for initialization and re-initialization of devices arise, these applications begin to be distributed among all threads from the pool. And there are regular situations when all the working threads of the pool are busy with performing long operations, while short operations, like reading and writing, accumulate in queues and are not processed for a long time. This situation is consistently observed, for example, at the start of the application, when a large “bundle” of applications for device initialization is immediately formed. And until this “bundle” is disassembled, I / O operations on already initialized devices are not performed.
To eliminate this trouble, you can use several approaches. In this article we will analyze one of them, namely, writing your own clever thread_pool-dispatcher, analyzing the types of requests.
What do we want to achieve?
The problem is that long-running processors (i.e., handlers for initializing and reinitializing devices) block all working threads in the pool and because of this request for short operations (i.e., I / O operations) can wait in the queue is very long. We want to get such a dispatch scheme so that when a request for a short operation arrives, its waiting in queues will be minimized.
Imitation "stand"
In the article we will use the imitation of the problem described above . Why imitation? Because, first of all, we have an idea only about the essence of the user's problem, but we don’t know the details and have never seen his code. And, secondly, imitation allows you to concentrate on the most significant aspects of the problem being solved, without dispersing attention to small details, of which there are a great many in real production code.
However, there is one important detail that has become known to us from our user and which most seriously affects the solution described below. The fact is that in SObjectizer there is a thread-safety concept for message handlers. Those. if the message handler is marked as thread-safe, then SObjectizer has the right to run this handler in parallel with other thread-safe handlers. And there is an adv_thread_pool-dispatcher that does just that.
So, our user used a stateless agent tied to an adv_thread_pool-dispatcher to manage devices. This greatly simplifies the whole kitchen.
So what are we going to consider?
We made an imitation consisting of the same agents. One agent is an auxiliary agent of type a_dashboard_t. His task is to collect and record statistics, according to which we will judge the results of simulation experiments. We will not consider the implementation of this agent.
The second agent, implemented by the a_device_manager_t class , simulates working with devices. We will talk a little about how this agent works below. This can be an interesting example of how agents can be implemented in SObjectizer that do not need to change their state.
The imitation consists of two applications that do almost the same thing: parse the command line arguments and run the imitation with the a_dashboard_t and a_device_manager_t agents inside. But the first application binds a_device_manager_t to the adv_thread_pool dispatcher. But the second application implements its own type of dispatcher and binds a_device_manager_t to this own dispatcher.
Based on the results of each of the applications, it will be possible to see how different types of dispatchers affect the nature of service requests.
Agent a_device_manager_t
In this section, we will try to highlight the main points in the implementation of the a_device_manager_t agent. All other details can be seen in the full agent code . Or clarify in the comments.
The a_device_manager_t agent should imitate work with many devices of the same type, but it should be a “stateless agent”, i.e. he should not change his state in the process. Exactly that the agent does not change its state and allows it to have thread-safe event handlers.
However, if the a_device_manager_t agent does not change its state, how does it determine which device should be initialized, which device should be reinitialized, and which device should perform input / output operations? It's simple: all this information is sent inside the messages that a_device_manager_t agent sends to itself.
At start, the a_device_manager_t agent sends N messages to init_device_t. Upon receiving such a message, the a_device_manager_t agent creates an instance of the “device” —an object of the device_t type and performs its initialization. Then point to this instance is sent in the message perform_io_t. It looks like this:
void on_init_device(mhood_t<init_device_t> cmd) const { // . handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd); // , // . auto dev = std::make_unique<device_t>(cmd->id_, calculate_io_period(), calculate_io_ops_before_reinit(), calculate_reinits_before_recreate()); std::this_thread::sleep_for(args_.device_init_time_); // IO- // . send_perform_io_msg(std::move(dev)); } Upon receiving the perform_io_t message, the a_device_manager_t agent simulates an I / O operation for the device, the pointer to which is inside the perform_io_t message. At the same time, for a device_t, the counter of IO operations is decremented. If this counter reaches zero, then a_device_manager_t either sends itself a reinit_device_t message (if the reinitialization counter is not yet reset), or the init_device_t message to re-create the device. This simple logic simulates the behavior of real devices that have the property of "sticking" (that is, ceasing to perform normal IO-operations) and then they need to be reinitialized. And also the sad fact that every device has a limited resource, having exhausted the device that needs to be replaced.
If the counter of IO operations has not yet been reset, the a_device_manager_t agent once again sends itself the message perform_io_t.
In the code, it all looks like this:
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) const { // . handle_msg_delay(a_dashboard_t::op_type_t::io_op, *cmd); // IO-. std::this_thread::sleep_for(args_.io_op_time_); // IO- . cmd->device_->remaining_io_ops_ -= 1; // , . // , . if(0 == cmd->device_->remaining_io_ops_) { if(0 == cmd->device_->remaining_reinits_) // . . so_5::send<init_device_t>(*this, cmd->device_->id_); else // . so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_)); } else // , IO-. send_perform_io_msg(std::move(cmd->device_)); } This is such a simple logic, regarding which the specification of some details may make sense.
Sending information to a_dashboard_t agent
In the init_device_t, reinit_device_t message handlers and perform_io_t, the first line is a similar construction:
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd); This is the transfer to the a_dashboard_t agent of how much a particular message has spent in the request queue. Based on this information, statistics are built.
In principle, accurate information about how much time the message spent in the queue of applications could be obtained only by taking root in the giblets of SObjectizer: then we could fix the time for submitting the application to the queue and the time it was taken from there. But for such a simple experiment, we will not deal with such an extreme. Let's do it easier: when sending the next message, we will save it the expected time of arrival of the message. For example, if we send a deferred message to 250ms, then we wait for it to arrive at the time (Tc + 250ms), where Tc is the current time. If the message came through (Tc + 350ms), then it spent 100ms in the queue.
This, of course, is not an exact way, but it is quite suitable for our imitation.
Blocking the current working thread for a while
Also in the code of the message handlers init_device_t, reinit_device_t and perform_io_t, you can see the call to std :: this_thread :: sleep_for. This is nothing more than an imitation of synchronous operations with the device, which should block the current thread.
The delay times can be set via the command line, and the default values are as follows: for init_device_t - 1250ms, for perform_io_t - 50ms. Duration for reinit_device_t is calculated as 2/3 of the duration of init_device (i.e. 833ms by default).
Using mutable messages
Perhaps the most interesting feature of the a_device_manager_t agent is how the lifetime of the dynamically created device_t objects is ensured. After all, the device_t instance is created dynamically during the processing of init_device_t and then it must remain alive until the attempts to reinitialize this device have been exhausted. And when reinitialization attempts are exhausted, the device_t instance should be destroyed.
At the same time, a_device_manager_t should not change its state. Those. we cannot get into a_device_manager_t some kind of std :: map or std :: unordered_map, which would be a living device_t dictionary.
To solve this problem, use the following trick. In the reinit_device_t and perform_io_t messages, a unique_ptr is passed, containing a pointer to the device_t instance. Accordingly, when we process reinit_device_t or perform_io_t and want to send the following message for this device, we simply transfer the unique_ptr from the old message instance to the new instance. And if the instance is no longer needed, i.e. we don’t send reinit_device_t or perform_io_t for it anymore, the device_t instance is automatically destroyed because The unique_ptr instance is destroyed in the already processed message.
But there is a little trick. Normally messages in a SObjectizer are sent as immutable objects that should not be modified. This is because SObjectizer implements the Pub / Sub model and sending a message to the mbox in general cannot say with certainty how many subscribers will receive the message. Maybe there will be ten. Maybe a hundred. Maybe a thousand. Accordingly, some subscribers will process the message simultaneously. Therefore, it is impossible to allow one subscriber to modify an instance of a message while another subscriber is trying to work with this instance. It is because of this that ordinary messages are passed to the handler via a constant link.
However, there are situations when a message is guaranteed to be sent to a single recipient. And this recipient wants to modify the received copy of the message. Here's how in our example, when we want to take the value of unique_ptr from the received_per_________fr__fr and give this value to a new instance of reinit_device_t.
For such cases, support for mutable messages has been added to SObjectizer-5.5.19. These messages are marked in a special way. And the SObjectizer checks in run-time whether mutable messages are sent to multi-producer / multi-consumer mboxes. Those. A mutable message can be delivered to no more than one recipient. Therefore, it is transmitted to the recipient by a normal, non-constant link, which allows modifying the content of the message.
Traces of this are found in the a_device_manager_t code. For example, this handler signature says that the handler is expecting a mutable message:
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) const And this code says that a copy of the mutable message will be retrieved:
so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_)); Imitation using adv_thread_pool-manager
In order to see how our a_device_manager_t will behave with the regular adv_thread_pool-manager, you need to create cooperation from the a_dashboard_t and a_device_manager_t agents, assigning a_device_manager_t to the adv_thread_pool-manager. What looks like this :
void run_example(const args_t & args ) { print_args(args); so_5::launch([&](so_5::environment_t & env) { env.introduce_coop([&](so_5::coop_t & coop) { const auto dashboard_mbox = coop.make_agent<a_dashboard_t>()->so_direct_mbox(); // // adv_thread_pool-. namespace disp = so_5::disp::adv_thread_pool; coop.make_agent_with_binder<a_device_manager_t>( disp::create_private_disp(env, args.thread_pool_size_)-> binder(disp::bind_params_t{}), args, dashboard_mbox); }); }); } As a result of a test run with 20 worker threads in the pool and other default values, we get the following image:

You can see a large “blue” peak at the very beginning (this is mass creation of devices at the start), as well as large “gray” peaks soon after the start of work. First, we receive a large number of init_device_t messages, some of which are long waiting for their turn to be processed. Then perform_io_t is processed very quickly and a large number of reinit_device_t is generated. Some of these reinit_device_t are waiting in queues, hence the noticeable gray peaks. You can also see noticeable dips in the green lines. This drop in the number of messages processed by perform_io_t during those moments when there is a massive processing of reinit_device_t and init_device_t.
Our task is to reduce the number of “gray” bursts and make the “green” dips not so deep.
The idea of a tricky thread_pool dispatcher
The problem with the adv_thread_pool-manager is that all requests are equal for him. Therefore, as soon as the working thread is released, he gives her the first application from the queue. Absolutely not understanding what type of this application. This leads to situations where all the worker threads are busy processing the init_device_t or reinit_device_t requests, while in the queue there are requests of the type perform_io_t.
To get rid of this problem we will make our clever thread_pool-dispatcher, which will have two sub-pools from the working threads of two types.
The working threads of the first type can process applications of any type. Priority is given to requests of the type init_device_t and reinit_device_t, but if they are not present at the moment, then you can process requests of the type perform_io_t.
The working threads of the second type cannot process requests of the type init_device_t and reinit_device_t. An application of type perform_io_t can be processed, but an application of type init_device_t cannot.
Thus, if we have 50 applications of the type reinit_device_t and 150 applications of the type perform_io_t, then the first subpool will rake the applications reinit_device_t, and the second subpool will rake the applications perform_io_t. When all applications of the type reinit_device_t are processed, the worker threads from the first subpool will be freed and will be able to help process the remaining requests of type perform_io_t.
It turns out that our clever thread_pool-controller holds a separate set of threads for processing short requests and this allows us not to slow down short requests even when there are a large number of long requests (as, say, at the very beginning of work, when a large number of init_device_t is sent at one time).
Imitation using tricky thread_pool-manager
In order to do the same imitation, but with another dispatcher, we need only slightly redo the already shown function run_example:
void run_example(const args_t & args ) { print_args(args); so_5::launch([&](so_5::environment_t & env) { env.introduce_coop([&](so_5::coop_t & coop) { const auto dashboard_mbox = coop.make_agent<a_dashboard_t>()->so_direct_mbox(); // // . coop.make_agent_with_binder<a_device_manager_t>( tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(), args, dashboard_mbox); }); }); } Those. we create all the same agents, only this time we bind a_device_manager_t to another dispatcher.
As a result of the launch with the same parameters, we will see a different picture:
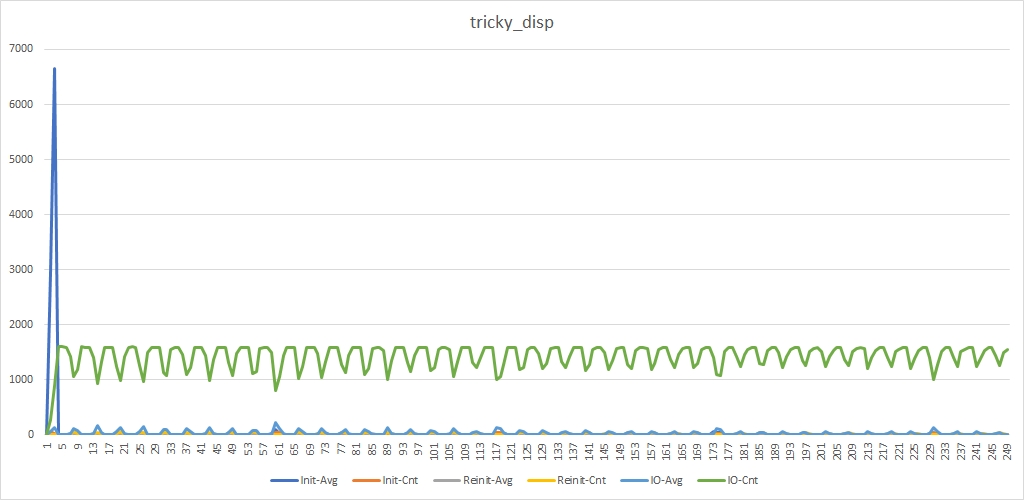
There is the same "blue" peak. Now he has become even taller, which is not surprising, since for processing init_device_t, fewer worker threads are now allocated. But we do not see the "gray" peaks and the "green" dips become less deep.
Those. we got the result we wanted. And now we can look at the code of this very cunning dispatcher.
Implementing a tricky thread_pool dispatcher
Dispatchers in SObjectizer are divided into two types:
First, public dispatchers. Each public dispatcher must have a unique name. Usually, dispatcher instances are created before SObjectizer starts, while SObjectizer starts up, and public dispatchers start, and when SObjectizer ends, it stops. These controllers must have a specific interface . But this is an obsolete type of dispatchers. There is far from zero chance that there will be no public dispatchers in the next major version of SObjectizer.
Secondly, private dispatchers. The user creates these dispatchers at any time after starting SObjectizer. The private dispatcher should start immediately after creation and it finishes its work after it is no longer used. Just for our imitation, we will create a dispatcher, which can only be used as a private dispatcher.
Let's look at the main points related to our dispatcher.
disp_binder for our dispatcher
Private controllers do not have a strictly defined interface, since All basic operations are performed in the constructor and destructor. But the private dispatcher must have a public method, usually called binder (), that returns a special binder object. This binder object will bind the agent to a specific dispatcher. And binder already should have quite a specific interface - disp_binder_t .
Therefore, for our dispatcher, we make our own binder type that implements the disp_binder_t interface:
class tricky_dispatcher_t : public std::enable_shared_from_this<tricky_dispatcher_t> { friend class tricky_event_queue_t; friend class tricky_disp_binder_t; class tricky_event_queue_t : public so_5::event_queue_t {...}; class tricky_disp_binder_t : public so_5::disp_binder_t { std::shared_ptr<tricky_dispatcher_t> disp_; public: tricky_disp_binder_t(std::shared_ptr<tricky_dispatcher_t> disp) : disp_{std::move(disp)} {} virtual so_5::disp_binding_activator_t bind_agent( so_5::environment_t &, so_5::agent_ref_t agent) override { return [d = disp_, agent] { agent->so_bind_to_dispatcher(d->event_queue_); }; } virtual void unbind_agent( so_5::environment_t &, so_5::agent_ref_t) override { // . } }; ... // , so_5::event_queue_t , // . tricky_event_queue_t event_queue_; ... public: ... // , . so_5::disp_binder_unique_ptr_t binder() { return so_5::disp_binder_unique_ptr_t{ new tricky_disp_binder_t{shared_from_this()}}; } }; Our tricky_dispatcher_t class is inherited from std :: enable_shared_from_this so that we can use the reference count to control the lifetime of the dispatcher. As soon as the dispatcher is no longer used, the reference count is reset and the dispatcher is automatically destroyed.
In the ticky_dispatcher_t class, there is a public binder () method that returns a new instance of tricky_disp_binder_t. A smart pointer to the dispatcher itself is passed to this instance. This allows you to then associate a specific agent with a specific dispatcher, as we saw earlier in the run_example code:
// // . coop.make_agent_with_binder<a_device_manager_t>( tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(), args, dashboard_mbox); }); }); The binder object must perform two actions. The first is to bind the agent to the dispatcher. What does bind_agent () do? Although, in fact, the agent is associated with the dispatcher in two stages. First, in the process of registering cooperation, the bind_agent () method is called and this method must create all the resources necessary for the agent. For example, if an agent is bound to the active_obj dispatcher, then a new working thread should be allocated for the agent. This should just happen in bind_agent (). The bind_agent () method returns a functor that already completes the agent binding procedure using previously allocated resources. Those. it turns out that when registering a co-operation, bind_agent () is first called, and a bind_agent returned by a functor returned a little later.
In our case, bind_agent () is very simple. No resources need to be allocated, just return the functor, which will connect the agent with the dispatcher (more on this below).
The second action is unbinding the agent from the dispatcher. This unbinding occurs when the agent is removed from the SObjectizer (deregistered). In this case, it may be necessary to clear some resources that were allocated to the agent. For example, the active_obj dispatcher stops the worker thread allocated to the agent.
The unbind_agent () method is responsible for performing the second action. But in our case it is empty, because for tricky_dispatcher_t, clearing resources when unbinding an agent is not required.
tricky_event_queue_t
Above, we talked about “binding an agent to a dispatcher,” but what is the meaning of this binding? Meaning in two simple things.
First, some dispatchers, such as active_obj, mentioned above, must allocate certain resources to the agent at the time of binding.
Secondly, in SObjectizer, agents do not have their own message / request queues. This is the fundamental difference between the SObjectizer implementation of the "classical Actor Model", in which each actor has its own mailbox (and, therefore, its own message queue).
In SObjectizer, dispatchers own the order queues. It is the dispatchers who determine where and how applications are stored (that is, messages addressed to the agent), where, when and how applications are retrieved and processed.
Accordingly, when the agent starts working inside SObjectizer, you need to establish a connection between the agent and the order queue into which messages addressed to the agent should be added. To do this, call the agent a special method so_bind_to_dispatcher () and transfer to this method a reference to the object that implements the event_queue_t interface. What, in fact, we see in the implementation of tricky_disp_binder_t :: bind_agent ().
But the question is what exactly tricky_disp_binder_t gives to so_bind_to_dispatcher (). In our case, this is a special implementation of the event_queue_t interface, which serves only as a thin proxy for calling tricky_dispatcher_t :: push_demand ():
class tricky_event_queue_t : public so_5::event_queue_t { tricky_dispatcher_t & disp_; public: tricky_event_queue_t(tricky_dispatcher_t & disp) : disp_{disp} {} virtual void push(so_5::execution_demand_t demand) override { disp_.push_demand(std::move(demand)); } }; What does tricky_dispatcher_t :: push_demand hide?
So, in our tricky_dispatcher_t there is a single instance of tricky_event_queue_t, the link to which is passed to all agents attached to the dispatcher. And this instance itself simply delegates all the work to the tricky_dispatcher_t :: push_demand () method. It's time to look inside the push_demand:
void push_demand(so_5::execution_demand_t demand) { if(init_device_type == demand.m_msg_type || reinit_device_type == demand.m_msg_type) { // . so_5::send<so_5::execution_demand_t>(init_reinit_ch_, std::move(demand)); } else { // , . so_5::send<so_5::execution_demand_t>(other_demands_ch_, std::move(demand)); } } Everything is simple here. For each new application, its type is checked. If the application relates to the init_device_t or reinit_device_t messages, then it is put in one place. If this is an application of any other type, then it is put in another place.
The most interesting is what init_reinit_ch_ and other_demands_ch_ are? And they represent nothing more than CSP-shny channels, which in SObjectizer are called mchains :
// , . so_5::mchain_t init_reinit_ch_; so_5::mchain_t other_demands_ch_; It turns out that when a new application has been created for the agent and this application has reached push_demand, then its type is analyzed and the application is sent either to one channel or to another. And the working threads that are included in the dispatcher pool are already retrieved and processed.
Implementing Manager Worker Threads
As mentioned above, our cunning dispatcher uses working threads of two types.It is now clear that the working threads of the first type must read the requests from init_reinit_ch_ and execute them. And if init_reinit_ch_ is empty, then you need to read and execute requests from other_demands_ch_. If both channels are empty, then you need to sleep until a request arrives in one of the channels. Or until both channels are closed.
With working threads of the second type is even simpler: you only need to read requests from other_demands_ch_.
Actually, this is exactly what we see in the tricky_dispatcher_t code:
// so_5::execution_demand_t. static void exec_demand_handler(so_5::execution_demand_t d) { d.call_handler(so_5::null_current_thread_id()); } // . void first_type_thread_body() { // , . so_5::select(so_5::from_all(), case_(init_reinit_ch_, exec_demand_handler), case_(other_demands_ch_, exec_demand_handler)); } // . void second_type_thread_body() { // , . so_5::select(so_5::from_all(), case_(other_demands_ch_, exec_demand_handler)); } Those.the thread of the first type hangs on a select of two channels. While the thread of the second type is on select from only one channel (in principle, inside second_type_thread_body () one could use so_5 :: receive () instead of so_5 :: select ()).
Actually, this and all that we needed to do was to organize two thread-safe queues of requests and reading these queues on different working threads.
Start-stop of our cunning dispatcher
For completeness, it makes sense to provide in the article also the code related to starting and stopping tricky_dispatcher_t. The start is performed in the constructor, and the stop, respectively, in the destructor:
// . tricky_dispatcher_t( // SObjectizer Environment, . so_5::environment_t & env, // , . unsigned pool_size) : event_queue_{*this} , init_reinit_ch_{so_5::create_mchain(env)} , other_demands_ch_{so_5::create_mchain(env)} { const auto [first_type_count, second_type_count] = calculate_pools_sizes(pool_size); launch_work_threads(first_type_count, second_type_count); } ~tricky_dispatcher_t() noexcept { // . shutdown_work_threads(); } In the constructor you can also see the creation of the init_reinit_ch_ and other_demands_ch_ channels.
Helper methods launch_work_threads () and shutdown_work_threads () look like this:
// . // , // . void launch_work_threads( unsigned first_type_threads_count, unsigned second_type_threads_count) { work_threads_.reserve(first_type_threads_count + second_type_threads_count); try { for(auto i = 0u; i < first_type_threads_count; ++i) work_threads_.emplace_back([this]{ first_type_thread_body(); }); for(auto i = 0u; i < second_type_threads_count; ++i) work_threads_.emplace_back([this]{ second_type_thread_body(); }); } catch(...) { shutdown_work_threads(); throw; // . } } // , . void shutdown_work_threads() noexcept { // . so_5::close_drop_content(init_reinit_ch_); so_5::close_drop_content(other_demands_ch_); // , // . for(auto & t : work_threads_) t.join(); // . work_threads_.clear(); } Here, perhaps, the only tricky moment is the need to catch exceptions in launch_work_threads, call shutdown_work_threads, and then forward the exception further. Everything else seems to be trivial and should not cause difficulties.
Conclusion
Generally speaking, the development of controllers for SObjectizer is not an easy topic. And the regular dispatchers that are part of SO-5.5 and so_5_extra have a much more sophisticated implementation than the tricky_dispatcher_t shown in this article. However, in some specific situations, when no full-time dispatcher is 100% suitable, you can implement your own dispatcher, specially tailored to your task. If you do not try to touch on such a complex topic as run-time monitoring and statistics, then writing your own dispatcher does not look so prohibitively complex.
It should also be noted that the tricky_dispatcher_t shown above turned out to be simple due to the very important assumption that the events of all the agents attached to it will be thread-safe and can be called in parallel without thinking anything. However, this is usually not the case. In most cases, agents have only thread-unsafe handlers. But even when there are thread-safe handlers, they exist simultaneously with the thread-unsafe handlers. And when dispatching applications, you have to check the type of the next processor. For example, if the handler for the next thread-safe request, and now thread-unsafe is working, then you need to wait until the previously launched thread-unsafe handler is completed. Just all this is done by the staff adv_thread_pool-dispatcher. But it is rarely used in practice. More often other dispatchers are used,which do not analyze the thread-safety flag for handlers, but consider that all handlers are thread-unsafe.
, SObjectizer SObjectizer C++Russia 2017 . - SObjectizer , , C++Russia 2018 .
Source: https://habr.com/ru/post/353712/
All Articles