DevConf: Uber transition from PostgreSQL to MySQL
May 18, 2018 DevConf 2018 will be held in Digital October. And we decided to retell some interesting reports from last year’s conference. There was a report with a somewhat holivar headline: " What is the political instructor silent on: a discussion about the transition of Uber from PostgreSQL to MySQL ." In it, MySQL developer Alexey Kopytov looked at the differences between InnoDb and PostgreSQL at the lowest level, including data organization, memory, and replication. We offer you a brief retelling of the report.

Uber switched from MySQL to Postgres in 2013 and the reasons they list were first: PostGIS is a geographic information extension for PostgreSQL and HYIP. That is, PostgreSQL has a certain halo of a serious, solid DBMS, perfect, without flaws. At least when compared with MySQL. They did not know much about PostgreSQL, but they were led to this whole HYIP and switched, and after 3 years they had to move back. And the main reasons, if we sum up their report, are poor operational characteristics during operation in production.
Obviously, this was a big enough reputational blow to the PostgreSQL community. There were a lot of discussions at various sites, including mailing lists. I have read all these comments and will try to consider some of the most detailed, most detailed answers.
Here are our today's contestants. First is Robert Haas. Robert Haas is one of two key PostgreSQL developers. He gave the most balanced, balanced answer. He doesn’t blame Uber for anything; on the contrary, he says that, thank you, well done, they told us about the problems, we have work to do, we have already done a lot for PostgreSQL, but there is still quite a lot of room for improvement. The second answer from Christophe Pettus is the CEO of some company that does PostgreSQL consulting. That's what I saw in this report, I was shocked to the depths of my soul, because the feeling that a person did not even try to be objective. Initially, I set myself the task of making Uber a fool, and PostgreSQL white and fluffy. Everything turns inside out and I asked the opinion of Uber engineers what they think about this report. They said it was some kind of nonsense. We didn't say that at all. This is the exact opposite of Robert Haas.
')
There is also Simon Riggs. This is the CTO of the famous company 2ndQuadrant, which also does consulting, and develops a lot in PostgreSQL itself. It is somewhere between, in the middle. Simon answers some questions in detail, and gives some answers to some, and hides some things. And the fourth report by Alexander Korotkov, development director of the Russian company PostgreSQL professional. The expected report is detailed and thorough, but it seems to me that Alexander also sweeps up some things under the carpet.
And my moment of glory. A year ago, at last year’s DevConf, I also gave a report on Postgres problems. And this report was a month before Uber published its. Moreover, I considered PostgreSQL exclusively from an architectural point of view, having no real industrial experience of PostgreSQL, but I was able to determine most of the problems that Uber describes on the basis of actual operation correctly. The only Uber problem that I generally ignored in my report was the MVCC problem on the replicas. I saw that there were some problems there, I read something on this subject, but I decided that it was not so important in industrial application and decided to lower it all. As it turned out, Uber shows that this problem was important for them too.
There will be a lot of pictures. To explain the problem of Uber, we need to talk a little bit about the difference in MVCC, the implementation in MVCC, and the difference in data organization between MySQL, specifically InnoDB and PostgreSQL.

InnoDB uses a clustered index, which means that user data is stored along with index values for a selected single index. As such an index is usually the primary key “PRIMARY KEY”. Secondary indexes use pointers to records, but they use not just some kind of offset, they use a primary key to point to records.
PostgreSQL has a different organization of data on disk. The user data itself is stored separately from the index in an object called “heap” or “heap”, and all indexes, both primary and secondary, use pointers to data in the form of a page number, roughly speaking, and offsets on this page. That is, they use some kind of physical pointer.
In essence, this means that all indexes in PostgreSQL are secondary. The primary index is just a certain alias for the secondary. Organizationally, it is arranged in the same way, there is no difference.
If you go down a level, I use a simplified example of a Uber report here to see how data is stored in pages or in blocks. Let's say we have a table with the names and surnames of famous mathematicians, just the year of their birth, a secondary index is built on this column with the year of birth, and there is a primary key for some ID, just a number. This is how it looks approximately in InnoDB, schematically, this is how it looks in PostgreSQL.

What happens when a non-index update? That is, we perform the update without affecting any columns for which there are any indices, non-indexable columns. In the case of InnoDB, the data is updated directly in: the primary key, where it is stored locally, but we need lines that are visible to other transactions, we need some history for the lines. These historical data, leaving in a separate segment called UNDO log. Moreover, not the entire line leaves entirely, but only what we have changed. The so-called update vector.
Accordingly, the pointer in the secondary index, if we have it, does not need to be changed, because we use PRIMARY KEY. PRIMARY KEY has not changed, we only change non-indexed columns, which means that we don’t need to change anything, we simply transfer the old data to the UNDO log and enter the new data directly into the table. PostgreSQL has a completely different approach. if we make a non-indexed update, we insert another full copy of the line with new data, but, accordingly, then the indices must also be changed. Pointers in all indexes must point to the most recent version of the line. Accordingly, another record is also inserted in them, which already points not to the old version of the line, but to the new one.

What happens when indexed update? What if we update some indexed column, here is the year of birth here. In this case, InnoDB again makes a new entry in the UNDO log and again indicates only the data that has changed. Again, the secondary index does not change. Well, more precisely, a new one is inserted there, since we have now replaced the indexed column, a new record is inserted — a secondary index that points to the same line. In PostgreSQL, the same thing happens with non-indexed update. We insert another complete copy of the line and again update all the indexes. Insert new entries in each index. Both in primary, and in secondary. If there are several secondary, then in each secondary.

Both InnoDB and PostgreSQL accumulate such multiversion garbage. Old versions of lines that need to be deleted over time, when there are no transactions that theoretically can see them. In the case of InnoDB, the purge system is responsible for this operation. It passes through the UNDO log and removes those records from the UNDO log that are no longer visible to any transaction.
In the case of PostgreS, a process called “vacuum” is responsible for this; it scans data; the multi-version trash is stored along with the data itself, it goes through all the data and decides whether this line can already be marked as reusable or not . The same with indexes. Of these, you also need to remove the old version of the lines.
What's wrong with a vacuum? In my opinion, vacuum is the most archaic, most inefficient PostgreSQL system. There are many reasons for this and not because it is poorly written. No, it is written well. This follows from how PostgreS organizes data on disk.
First, it is solved by scanning the data. Not by scanning your own history, as is the case with InnoDB in the UNDO log, but by scanning the data. There, of course, there are some optimizations that allow, at least, to avoid all data scanning, and only certain segments that have been updated recently, there is some bitmask that notes that this data is clean, they have not been updated since the last vacuum, there is no need to look there, but all these optimizations work only for the case when the data are mostly chaotic. If you have a large set of frequently updated data, all these optimizations are dead poultices. All the same, you need to go through all the recently updated pages, and determine - this record can be thrown out or not, for each record. It is also executed in one thread. That is, vacuum makes a list of tables that need to be updated, and slowly and sadly goes through one table, then another, and so on.
In InnoDB purge, for example, you can parallel an arbitrary number of threads. By default, 4 threads are currently used. And besides, on vacuum, on how efficiently and often the vacuum works, is the efficiency of PostgreSQL itself. Different optimizations, query execution, like HOT, we'll talk about it again, or index-only scans, the efficiency of replication work is also tied to whether the vacuum has gone recently or not. We have this multi-version trash or not.
If someone needs bloody details, then Aleksey Lesovsky made a report “Nine circles of hell or PostgreSQL Vacuum”. There is such a big huge diagram that shows the vacuum operation algorithm. And about it you can break the brain, if you want.
Now, actually, to the problem of Uber. The first problem they show is write amplification. The bottom line is that even a small non-index update can lead to a large disk write. Because it is necessary, first, to write a new version of the line in heap, in a heap, update all new indices, which is an expensive operation in itself. From a computational point of view, updating the index is expensive. It is good if it is still a btree-index, and there may be some gin-indices that update very slowly. Add new records, all of these pages are modified both in the heap itself and in the indexes, as a result, they will go to disk, in addition, all this must be recorded in the transaction log. A lot of records for a relatively small update.
Here you can talk more about optimization in PostgreSQL, which exists for a long time, it is called “Heap-Only Tuples”, NOT updates. Uber in the report does not mention, it is not clear whether they knew about it or, maybe, in their case, it did not work simply. They just don't say anything about her. But there is such an optimization.

The point is that if both the old and the new version of the record for the index update are on the same page, instead of updating the indexes, we make a link to the new one from the old record. Indices continue to point to the old version. We can jump on this link and get a new version without touching the indexes. It seems like everything is fine. If another line appears, we make another link and get a chain like this called “Hot chain”. In fact, there is no complete happiness, because this is all up to the first index update. As soon as we receive the first update, which affects the indexes for this page, we need to collapse all this hot chain, because all indexes must point to the same record. We cannot change the link for one index, but leave it for others.
Accordingly, the more indices, the less chance the HOTs will have to work and even Robert Haas, he writes in his review that yes, there really is such a problem, and many companies suffer from it. Many developers are therefore neat about index creation. Theoretically, the index could even be useful, but if we add it, the update will no longer use this Heap-Only Tuples optimization. Secondly, it is obvious that this optimization only works if there is space on the page. The link can be put only if the old and the new version of the record are on the same page. If the new version of the record moves to another page, that's all, no Heap-Only Tuples optimization.
For this, again PostgreSQL made a crutch that, while we wait until the vacuum reaches, frees us up space on the page, let's do this mini vacuum or single gauge vacuum, this is called. Each time we access a specific page, we’ll also vacuum out a little more. See which records can be removed if they are not already visible to other transactions. Free up space on the page and, accordingly, increase the chance that the HOT optimization will work.
This is all ineffective, again, if you have many concurrent transactions. Then the chance that the current versions of the lines are not visible to any performing transaction, it decreases. Accordingly, the motto optimization stops working. It also does not work when there are not many parallel, but one long transaction that can see old versions of the lines on the page. Accordingly, we can not remove them, then this entry starts to move to the next page, and again no optimization optimization.
What is the community responsible? Robert Haas says in a rather balanced way: “Yes, there is a problem, NOT optimization is not a panacea, many companies suffer from it, not only Uber”. And in general, in an amicable way, I have been talking about this for a long time, we need to do the storage engine as in MySQL. In particular, we need a storage engine based on undo, and not what we currently have. Christophe Petus and Simon Rigs say: “There is an OOT optimization. Since Uber does not mention her, it means that they know nothing about her. So they are fools. ” Christophe, he is a well-mannered person, when he wants to say that Uber is a fool, he inserted a smiley shrug into the presentation. "What to take with them."
Alexander Korotkov says that there is a motto optimization, there are certain limitations, but then he begins to list a list of different experimental patches, which will not be included in the upcoming ten mager version and after listing these experimental patches he comes to the conclusion that, in fact, in a good way, need to do storage engine, based on undo. All other optimizations are more like backups, crutches for an inefficient system for organizing data in PostgreSQL.
What do all respondents miss? There is such a belief, I often see him, including in some Russian communities, that Uber was just some specific case. In fact, there is nothing specific about it. These are normal operations for OLTP, for Internet projects, queues, some counters, metrics, when it is necessary to update non-indexable columns. I do not see anything specific about this.
Secondly, none of the respondents said that MVCC and disk data organization in PostgreSQL are not well suited for OLTP loads.
Also, no one has formulated a simple thing that there is no complete solution to the problem and it probably will not be soon. Even experimental patches, they will appear, at best, in PostgreSQL 11 and then, they are more likely to be crutches and props, rather than a radical solution to the root problem. Also, the problem of write amplification, which Uber describes, is a rather special case of a more general problem. And on a more general problem in MySQL, they have been working for a long time; there are record-optimized TokuDB / MyRocks engines now gaining popularity. In this regard, PostgreSQL is still worse. There are no even theoretical alternatives even on the horizon.
The second problem that Uber points out is replication and MMVC issues on replicas. Suppose we have replication, master -> replica. Replication in PostgreSQL is physical, that is, it works at the file level and all changes in the files that occur on the master are transferred to the replica one-on-one. In fact, we end up building a master byte copy. The problem occurs if we also use a replica in order to twist some queries. And on read only, you cannot make changes there, but you can read. What to do if we have a select on the replica, if this select needs some old versions of the lines that have already been deleted on the master, because there are no such selets on the master. Vacuum went through and deleted these old versions without knowing that any queries that are still needed are executed on the replica or on the replicas. There are not many options. You can hold the replication, stop the replication on the replica until this select completes, but since replication cannot be delayed for an infinite time, there is some default timeout - this is max_standby_streaming_delay. 30 seconds, after which transactions that use some old version of the lines, just start to shoot.

Uber also notes that in general they had long transactions mainly due to the fault of the developer. There were transactions that, for example, opened a transaction, then opened an e-mail or some blocking I / O was performed. Of course, in theory, Uber says that it is impossible to do this, but there are no ideal developers, moreover, they often use some forms that hide a common fact. It’s not so easy to determine when a transaction starts, when it ends. High-level forms are used.
Such cases did arise, and for them it was a big problem. Either replication was delayed, or transactions were shot, from the point of view of the developer, at an unpredictable moment. Because, you know, if we, for example, wait 30 seconds and delay replication, and after that shoot the request, then by the time the request is shot, replication is already 30 seconds behind. Accordingly, the next transaction can be shot almost instantly, because these 30 seconds, this limit will be exhausted very quickly. From the developer's point of view, a transaction at some random moment ... we just started, have not yet had time to do anything, and already interrupt us.
Community response. Everyone says that it was necessary to use the hot_standby_feedback = on option, it was necessary to enable it. Christoph Petus adds that Uber are fools.
This option has its price. There are some negative consequences, otherwise it would be included simply by default. In this case, if going back to this picture, what it does. The replica starts transmitting to the master information about which versions, which transactions are open, and which versions of the lines are still needed. And in this case, the wizard actually simply holds the vacuum so that it does not delete these versions of the lines. There are a lot of problems here too. For example, replicas are often used for testing, so that developers play around not on a combat machine, and not on some replica. Imagine, the developer, when testing, started some kind of transaction and went for lunch, but at this time the vacuum stops at the wizard and eventually the place ends and the optimization stops working and as a result the wizard can simply die.
Or another case. Replicas are often used for some kind of analytics, long-playing queries. This is also a problem. We run a long-running request with the enabled option hot_standby_feedback = on, the vacuum on the wizard also stops. And here it turns out that for some long analytical queries there is no alternative at all. Either they just kill the master with the hot_standby_feedback = on option turned on, or, if it is turned off, they will simply be shot and never completed.
What is everyone silent about? As I said, the option that everyone advises, it delays the vacuum on the wizard and in PostgreSQL were going to make it turned on by default, but the bidders were immediately told why it was not necessary to do so. So simply advising her without reservation is not very fair, I would say.
Errors from developers happen. Christoph Petus says that since Uber couldn’t hire the right developers, they’re fools. Breaks where thin. Developers make mistakes where they are allowed to make mistakes. What no one has said is that physical replication is not well suited for scaling reads. If we use replicas to scale reading, to spin some selects, physical replication in PostgreSQL is simply not suitable for the architecture. It was a kind of hack that was easy to implement, but it had its limits. And this is again not a specific case. Replication can be used for different purposes. Using this replication to scale reading is also quite a typical case. Another problem reported by Uber is replication and write amplification. As we have already discussed, write amplification also happens on the wizard with some specific updates. Too much data is written to disk, but since replication in PostgreSQL is physical, and all changes in files go to replicas, then all these changes that occur in files on the wizard go to the network. It is quite redundant, physical replication, by nature. There are problems in speed between different data centers.If we replicate from one coast to another, then buying a fairly wide channel that would contain all this replication stream that comes from the master is problematic and it is not always possible.
What does the community respond to this. Robert Haas says that it was possible to try WAL compression, which is transmitted in replication over a network or SSL, there you can also enable compression at the network connection level. And also, it was possible to try a logical replication solution, which is available in PostgreSQL. He mentions Slony / Bucardo / Londiste. Simon Riggs gives a lecture on the pros and cons of physical replication, I would write it all here too, but lately I have said so often lately that I’m tired of it already, I suppose that they all have some idea of how logical replication differs from physical. Also, they add that soon there will be pglogical - it is an integrated solution for logical replication in PostgreSQL, which is developed by his company.
Christoph Petus says that there is no need to compare logical and physical replication. But this is strange, because that is exactly what Uber does. He compares the pros and cons of logical and physical replication, saying that physical replication is not very suitable for them, but logical replication in MySQL is just fine. It is not clear why it is not necessary to compare. He adds that Slony, Bucardo is difficult to install and difficult to manage, but this is Uber. If they could not do it, then they are fools. And besides, in version 9.4 there is pglogical. This is a third-party extension for PostgreSQL, which organizes logical replication. It must be said that Uber used older versions of PostgreSQL, 9.2, 9.3, for which there is no pglogical, but they could not move to 9.4. I will tell you further why.
Alexander Korotkov says that Uber compares logical replication in MySQL and physical. Exactly.That is what he does. MySQL does not have physical replication and Alibaba is working to add physical replication to MySQL - this is also true, only Alibaba does it for a completely different use case. Alibaba does this to ensure high availability for its cloud application within a single data center. They do not use cross-regional replication, they do not use reading from replicas. This is only used if a cloud server crashes the server so that they can quickly switch to the replica. That’s all. That is, this use case is different from what Uber uses.
Another Uber issue that they are talking about is cross-version updates. It is necessary to switch from one major version to another and it would be desirable to do this without stopping the wizard. Here in PostgreSQL with physical replication, this problem is not solved. Because, usually, in MySQL do as. Upgrade replicas first, or one replica, if it is only one, to a higher version, then requests are switched to it ... they actually make it a new master, and the old master will upgrade to a new version. It turns out that downtime is minimal. But with physical replication in PostgreSQL, you cannot replicate from a younger version to a higher version, and in general, the versions must be the same on both the master and the replica. Pglogical, again, was not an option for them, because they used older versions and at 9.4, from which pglogical is available, they could not move,because there was no replication. The recursion is like that.
Some of their legacy services, and in Ubere they still remain, they still work on PostgreSQL 9.2 for this simple reason.
Community response. Robert Haas does not comment on this. Simon Riegs says that in general there is pg_upgrade - this is a custom upgrade procedure and with the -k option when hardlinks are used this process takes less time, so downtime will still be, the master will have to be stopped and all requests will also have to be stopped. Well, this may not be so long. In addition, Simon Riggs says that they have a commercial solution in their company that allows them to integrate old versions with new ones.
Christoph Petus says that pg_upgrade is not a panacea, in particular PostGIS, a geographic information extension, due to which Uber switched to PostgreSQL causes a lot of problems when upgrading between major versions. I don't know, I believe him here, because he is a PostgreSQL consultant. He says that Uber is not mastered, again, Slony / Bucardo, pglogical, so they are fools. Alexander Korotkov shows how you can upgrade between major versions using pglogical.
Our report is called: “Uber-answer”, then for Uber it was not an option. The answer to current users, there also has its own nuances.
What is everyone silent about? Yes, there really are all sorts of third-party solutions for PostgreSQL that organize Slony / Bucardo / Londiste logical replication, but they are all trigger-based, they are all based on triggers, that is, a trigger is hung on every table, we take these changes for any update, who made and write them into a special relational journaling table, and then, when they move to replicas, all these changes from the relational table, we delete them. And here there are typical problems. PostgreSQL sore with Vacuum, when data is often inserted and deleted, a lot of work for the vacuum, respectively, a lot of all sorts of problems. Not to mention the fact that the trigger-based solution itself is not very effective, you know, and the data is pulled out of the tables altogether by some external scripts. Not in the DBMS itself,and written in pearl or python, there are different ways, it all depends on the decision and is shifted to replicas.
With pglogical everything is very strange. All advised that pglogical can be used for upgrades from a newer version to a new one. I read the documentation, the developers do not promise that such cross-version replication will work. They say that it can work, but in future versions, something can disperse and, in general, we do not promise anything.
Low “run-in” even now, in 2017. This is a relatively new technology, it is of course progressive, it potentially uses some built-in things in PostgreSQL, and not some external solutions, but I don’t really understand how Uber could be recommended for use in productions in 2015, when pglogical was just beginning to be developed. But what is good about pglogical is that, unlike the main PostgreSQL, you can go and see the bugtracker to assess the stability of the project, the maturity of the project, how widely it is used. Honestly, I was not impressed. It did not impress me as a stable project.

Activity is very low, there are some bugs that have been hanging there for years. Someone has problems with performance, someone has a problem with data loss. That does not give the impression of a stable project. In my hobby project ( sysbench ), there is more activity on the githaba than in pglogical.
What is still not talking? That all of these problems, all of these solutions, third-party and embedded pglogical have problems with sequences, because you cannot hang a trigger on them and the changes are not recorded in the transaction log, which means you have to do some special complex squats to ensure replication sequences. DDL is only through wrapper functions, because, again, triggers cannot be hung on DDL and for some reason they are not recorded in PostgreSQL in the transaction log. All three solutions do not have a log as such, that is, you cannot take any backup and roll logical changes from a log like in MySQL. You can only physical backup, but to make a physical PITR, you need a physical backup. On the logical back up you will not roll it. No GTID, any last things that appeared in replication in MySQL.I did not understand how to make repositioning with the help of these decisions. Say, switch a slave replica from one master to another and understand which transactions have already been lost and which not.
Finally, there is no parallelism. The only way to speed up logical replication is to parallelize it. MySQL has done a lot of work in this direction. All these solutions do not support concurrency at all in any way. He simply does not.
What is everyone missing? First, there is only one correct scenario for applying physical replication in PostgreSQL or in MySQL, when it appears somewhere or anywhere else. This is High Availability inside a single data center, when we have a fairly fast channel, and when we don’t need to read from replicas. This is the only correct use case. Everything else can work, and maybe not, depending on the load and on many other parameters.
At present, PostgreSQL cannot offer a complete replication alternative in MySQL. The bloglog is a strange thing. Many people say that pglogical will appear in PostgreSQL 10, built-in logical replication, in fact very few people in the Postgres community know that some reduced version of ploglog will go into 10. I never found some clear description of what exactly will go down and what will be left behind. In addition, the syntax in 10 will be used somewhat differently from that used by the third-party ploglog extension. It is not clear, it will be possible to somehow use them together. Is it possible to replicate pglogical from older versions in PostgreSQL 10 or not. I have not found anywhere. The ploglog documentation is also peculiar.
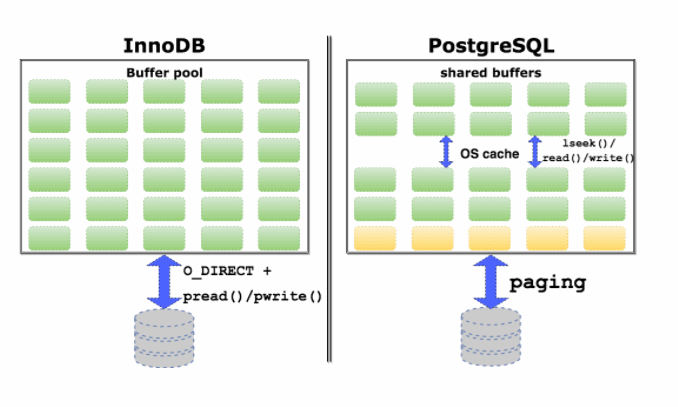
And finally, an inefficient cache. What is the difference between the implementation of the cache in InnoDB and PostgreSQL. InnoDB uses unbuffered I / O without relying on the operating system's own cache, so all the memory, all the maximum available memory on the machine is allocated to the InnoDB cache. InnoDB uses common pread and pwrite system calls to perform unbuffered I / O. Not relying on the operating system cache.
PostgreSQL has a different architecture. For some reason, direct I / O support for unbuffered I / O has not been done so far; therefore, PostgreSQL relies on both its own cache and the operating system cache at the same time. In addition, for some reason he uses not such system calls that allow you to immediately shift and read something and write, but first a separate system call to shift to the desired position, and then read and write. Two system calls for one operation. There is some duplication of data. Pages of data memory will be stored in its own cache and in the cache of the operating system.
Robert Haas and Simon Rigs do not respond to this. Christophe Petus, something happened to him, he does not call Uber a fool here, I agree that there is a problem, but the effect in practice is not clear. Alexander Korotkov says that pread instead of lseek only optimizes performance for 1.5 percent of performance, but this is part of the problems that Uber lists. Says nothing more.
What does everyone omit? That 1.5% was obtained on one benchmark on a laptop developer who developed this patch. Experimentally there was some discussion on the Postgres hackers mailing list, and the patch ended up stuck in discussions. Robert Haas said that this patch should be included. Even 1.5% is likely to be more on combat systems, even 1.5% is already good, and Tom Lane, another key developer of PostgreSQL, was against it, saying that you don’t need to touch the stable code because of some ,five%. In general, two key developers did not find understanding and the patch ended up stuck. He did not go anywhere.
This is far from the only problem in the design of shared buffers, I in my last year’s report on DevConf disclosed this in detail. There are far more problems there than Uber lists. There is data duplication, there is a problem with double calculation of checksums, there is a problem with “flushing” data from the operating system cache, which InnoDB with its cache can prevent. And in the future, if compression and encryption appear in PostgreSQL, problems with such an architecture will also begin there.
What we see in the end. Uber, I talked to them, and they also gave presentations at conferences, at Percona live. They say that: “We are generally satisfied with MySQL, we are not going to move anywhere. We have old legacy systems that still work on PostgreSQL, but all the main processing is done in MySQL. PostGIS is the main reason why we switched to PostgreSQL, the geoinformational extension. It's cool, but with its pitfalls, and besides, this thing doesn’t scale well for OLTP loads. We found a way to do without it in MySQL. Yes, there is no such possibility in MySQL yet. ”
I give advice that do not believe in this hype, in the halo of a perfect system, devoid of flaws. Be engineers, be skeptical, try to make decisions based on objective things, not based on rumors and some kind of general hysteria. And most importantly - test. Before you are going to replace a DBMS in your project, conduct at least some tests to see how your DBMS behaves on your particular case. I have it all!
Here is such a report with a clear desire to show the benefits of InnoDb :) Of course, soon we will dilute our habr with a report from the opposite camp. Come May 18th to DevConf(special prices are valid until April 30). Alexey promised to be there with a new report. True, now it will be more about MySQL. And Ivan Panchenko from Postgres Professional will talk about the very logical replication that was included in PostgreSQL 10.
Background
Uber switched from MySQL to Postgres in 2013 and the reasons they list were first: PostGIS is a geographic information extension for PostgreSQL and HYIP. That is, PostgreSQL has a certain halo of a serious, solid DBMS, perfect, without flaws. At least when compared with MySQL. They did not know much about PostgreSQL, but they were led to this whole HYIP and switched, and after 3 years they had to move back. And the main reasons, if we sum up their report, are poor operational characteristics during operation in production.
Obviously, this was a big enough reputational blow to the PostgreSQL community. There were a lot of discussions at various sites, including mailing lists. I have read all these comments and will try to consider some of the most detailed, most detailed answers.
Here are our today's contestants. First is Robert Haas. Robert Haas is one of two key PostgreSQL developers. He gave the most balanced, balanced answer. He doesn’t blame Uber for anything; on the contrary, he says that, thank you, well done, they told us about the problems, we have work to do, we have already done a lot for PostgreSQL, but there is still quite a lot of room for improvement. The second answer from Christophe Pettus is the CEO of some company that does PostgreSQL consulting. That's what I saw in this report, I was shocked to the depths of my soul, because the feeling that a person did not even try to be objective. Initially, I set myself the task of making Uber a fool, and PostgreSQL white and fluffy. Everything turns inside out and I asked the opinion of Uber engineers what they think about this report. They said it was some kind of nonsense. We didn't say that at all. This is the exact opposite of Robert Haas.
')
There is also Simon Riggs. This is the CTO of the famous company 2ndQuadrant, which also does consulting, and develops a lot in PostgreSQL itself. It is somewhere between, in the middle. Simon answers some questions in detail, and gives some answers to some, and hides some things. And the fourth report by Alexander Korotkov, development director of the Russian company PostgreSQL professional. The expected report is detailed and thorough, but it seems to me that Alexander also sweeps up some things under the carpet.
And my moment of glory. A year ago, at last year’s DevConf, I also gave a report on Postgres problems. And this report was a month before Uber published its. Moreover, I considered PostgreSQL exclusively from an architectural point of view, having no real industrial experience of PostgreSQL, but I was able to determine most of the problems that Uber describes on the basis of actual operation correctly. The only Uber problem that I generally ignored in my report was the MVCC problem on the replicas. I saw that there were some problems there, I read something on this subject, but I decided that it was not so important in industrial application and decided to lower it all. As it turned out, Uber shows that this problem was important for them too.
There will be a lot of pictures. To explain the problem of Uber, we need to talk a little bit about the difference in MVCC, the implementation in MVCC, and the difference in data organization between MySQL, specifically InnoDB and PostgreSQL.
Data organization
InnoDB uses a clustered index, which means that user data is stored along with index values for a selected single index. As such an index is usually the primary key “PRIMARY KEY”. Secondary indexes use pointers to records, but they use not just some kind of offset, they use a primary key to point to records.
PostgreSQL has a different organization of data on disk. The user data itself is stored separately from the index in an object called “heap” or “heap”, and all indexes, both primary and secondary, use pointers to data in the form of a page number, roughly speaking, and offsets on this page. That is, they use some kind of physical pointer.
In essence, this means that all indexes in PostgreSQL are secondary. The primary index is just a certain alias for the secondary. Organizationally, it is arranged in the same way, there is no difference.
If you go down a level, I use a simplified example of a Uber report here to see how data is stored in pages or in blocks. Let's say we have a table with the names and surnames of famous mathematicians, just the year of their birth, a secondary index is built on this column with the year of birth, and there is a primary key for some ID, just a number. This is how it looks approximately in InnoDB, schematically, this is how it looks in PostgreSQL.
What happens when a non-index update? That is, we perform the update without affecting any columns for which there are any indices, non-indexable columns. In the case of InnoDB, the data is updated directly in: the primary key, where it is stored locally, but we need lines that are visible to other transactions, we need some history for the lines. These historical data, leaving in a separate segment called UNDO log. Moreover, not the entire line leaves entirely, but only what we have changed. The so-called update vector.
Accordingly, the pointer in the secondary index, if we have it, does not need to be changed, because we use PRIMARY KEY. PRIMARY KEY has not changed, we only change non-indexed columns, which means that we don’t need to change anything, we simply transfer the old data to the UNDO log and enter the new data directly into the table. PostgreSQL has a completely different approach. if we make a non-indexed update, we insert another full copy of the line with new data, but, accordingly, then the indices must also be changed. Pointers in all indexes must point to the most recent version of the line. Accordingly, another record is also inserted in them, which already points not to the old version of the line, but to the new one.
What happens when indexed update? What if we update some indexed column, here is the year of birth here. In this case, InnoDB again makes a new entry in the UNDO log and again indicates only the data that has changed. Again, the secondary index does not change. Well, more precisely, a new one is inserted there, since we have now replaced the indexed column, a new record is inserted — a secondary index that points to the same line. In PostgreSQL, the same thing happens with non-indexed update. We insert another complete copy of the line and again update all the indexes. Insert new entries in each index. Both in primary, and in secondary. If there are several secondary, then in each secondary.
Both InnoDB and PostgreSQL accumulate such multiversion garbage. Old versions of lines that need to be deleted over time, when there are no transactions that theoretically can see them. In the case of InnoDB, the purge system is responsible for this operation. It passes through the UNDO log and removes those records from the UNDO log that are no longer visible to any transaction.
In the case of PostgreS, a process called “vacuum” is responsible for this; it scans data; the multi-version trash is stored along with the data itself, it goes through all the data and decides whether this line can already be marked as reusable or not . The same with indexes. Of these, you also need to remove the old version of the lines.
What's wrong with a vacuum? In my opinion, vacuum is the most archaic, most inefficient PostgreSQL system. There are many reasons for this and not because it is poorly written. No, it is written well. This follows from how PostgreS organizes data on disk.
First, it is solved by scanning the data. Not by scanning your own history, as is the case with InnoDB in the UNDO log, but by scanning the data. There, of course, there are some optimizations that allow, at least, to avoid all data scanning, and only certain segments that have been updated recently, there is some bitmask that notes that this data is clean, they have not been updated since the last vacuum, there is no need to look there, but all these optimizations work only for the case when the data are mostly chaotic. If you have a large set of frequently updated data, all these optimizations are dead poultices. All the same, you need to go through all the recently updated pages, and determine - this record can be thrown out or not, for each record. It is also executed in one thread. That is, vacuum makes a list of tables that need to be updated, and slowly and sadly goes through one table, then another, and so on.
In InnoDB purge, for example, you can parallel an arbitrary number of threads. By default, 4 threads are currently used. And besides, on vacuum, on how efficiently and often the vacuum works, is the efficiency of PostgreSQL itself. Different optimizations, query execution, like HOT, we'll talk about it again, or index-only scans, the efficiency of replication work is also tied to whether the vacuum has gone recently or not. We have this multi-version trash or not.
If someone needs bloody details, then Aleksey Lesovsky made a report “Nine circles of hell or PostgreSQL Vacuum”. There is such a big huge diagram that shows the vacuum operation algorithm. And about it you can break the brain, if you want.
Now, actually, to the problem of Uber. The first problem they show is write amplification. The bottom line is that even a small non-index update can lead to a large disk write. Because it is necessary, first, to write a new version of the line in heap, in a heap, update all new indices, which is an expensive operation in itself. From a computational point of view, updating the index is expensive. It is good if it is still a btree-index, and there may be some gin-indices that update very slowly. Add new records, all of these pages are modified both in the heap itself and in the indexes, as a result, they will go to disk, in addition, all this must be recorded in the transaction log. A lot of records for a relatively small update.
Here you can talk more about optimization in PostgreSQL, which exists for a long time, it is called “Heap-Only Tuples”, NOT updates. Uber in the report does not mention, it is not clear whether they knew about it or, maybe, in their case, it did not work simply. They just don't say anything about her. But there is such an optimization.
The point is that if both the old and the new version of the record for the index update are on the same page, instead of updating the indexes, we make a link to the new one from the old record. Indices continue to point to the old version. We can jump on this link and get a new version without touching the indexes. It seems like everything is fine. If another line appears, we make another link and get a chain like this called “Hot chain”. In fact, there is no complete happiness, because this is all up to the first index update. As soon as we receive the first update, which affects the indexes for this page, we need to collapse all this hot chain, because all indexes must point to the same record. We cannot change the link for one index, but leave it for others.
Accordingly, the more indices, the less chance the HOTs will have to work and even Robert Haas, he writes in his review that yes, there really is such a problem, and many companies suffer from it. Many developers are therefore neat about index creation. Theoretically, the index could even be useful, but if we add it, the update will no longer use this Heap-Only Tuples optimization. Secondly, it is obvious that this optimization only works if there is space on the page. The link can be put only if the old and the new version of the record are on the same page. If the new version of the record moves to another page, that's all, no Heap-Only Tuples optimization.
For this, again PostgreSQL made a crutch that, while we wait until the vacuum reaches, frees us up space on the page, let's do this mini vacuum or single gauge vacuum, this is called. Each time we access a specific page, we’ll also vacuum out a little more. See which records can be removed if they are not already visible to other transactions. Free up space on the page and, accordingly, increase the chance that the HOT optimization will work.
This is all ineffective, again, if you have many concurrent transactions. Then the chance that the current versions of the lines are not visible to any performing transaction, it decreases. Accordingly, the motto optimization stops working. It also does not work when there are not many parallel, but one long transaction that can see old versions of the lines on the page. Accordingly, we can not remove them, then this entry starts to move to the next page, and again no optimization optimization.
What is the community responsible? Robert Haas says in a rather balanced way: “Yes, there is a problem, NOT optimization is not a panacea, many companies suffer from it, not only Uber”. And in general, in an amicable way, I have been talking about this for a long time, we need to do the storage engine as in MySQL. In particular, we need a storage engine based on undo, and not what we currently have. Christophe Petus and Simon Rigs say: “There is an OOT optimization. Since Uber does not mention her, it means that they know nothing about her. So they are fools. ” Christophe, he is a well-mannered person, when he wants to say that Uber is a fool, he inserted a smiley shrug into the presentation. "What to take with them."
Alexander Korotkov says that there is a motto optimization, there are certain limitations, but then he begins to list a list of different experimental patches, which will not be included in the upcoming ten mager version and after listing these experimental patches he comes to the conclusion that, in fact, in a good way, need to do storage engine, based on undo. All other optimizations are more like backups, crutches for an inefficient system for organizing data in PostgreSQL.
What do all respondents miss? There is such a belief, I often see him, including in some Russian communities, that Uber was just some specific case. In fact, there is nothing specific about it. These are normal operations for OLTP, for Internet projects, queues, some counters, metrics, when it is necessary to update non-indexable columns. I do not see anything specific about this.
Secondly, none of the respondents said that MVCC and disk data organization in PostgreSQL are not well suited for OLTP loads.
Also, no one has formulated a simple thing that there is no complete solution to the problem and it probably will not be soon. Even experimental patches, they will appear, at best, in PostgreSQL 11 and then, they are more likely to be crutches and props, rather than a radical solution to the root problem. Also, the problem of write amplification, which Uber describes, is a rather special case of a more general problem. And on a more general problem in MySQL, they have been working for a long time; there are record-optimized TokuDB / MyRocks engines now gaining popularity. In this regard, PostgreSQL is still worse. There are no even theoretical alternatives even on the horizon.
MMVC and replication
The second problem that Uber points out is replication and MMVC issues on replicas. Suppose we have replication, master -> replica. Replication in PostgreSQL is physical, that is, it works at the file level and all changes in the files that occur on the master are transferred to the replica one-on-one. In fact, we end up building a master byte copy. The problem occurs if we also use a replica in order to twist some queries. And on read only, you cannot make changes there, but you can read. What to do if we have a select on the replica, if this select needs some old versions of the lines that have already been deleted on the master, because there are no such selets on the master. Vacuum went through and deleted these old versions without knowing that any queries that are still needed are executed on the replica or on the replicas. There are not many options. You can hold the replication, stop the replication on the replica until this select completes, but since replication cannot be delayed for an infinite time, there is some default timeout - this is max_standby_streaming_delay. 30 seconds, after which transactions that use some old version of the lines, just start to shoot.
Uber also notes that in general they had long transactions mainly due to the fault of the developer. There were transactions that, for example, opened a transaction, then opened an e-mail or some blocking I / O was performed. Of course, in theory, Uber says that it is impossible to do this, but there are no ideal developers, moreover, they often use some forms that hide a common fact. It’s not so easy to determine when a transaction starts, when it ends. High-level forms are used.
Such cases did arise, and for them it was a big problem. Either replication was delayed, or transactions were shot, from the point of view of the developer, at an unpredictable moment. Because, you know, if we, for example, wait 30 seconds and delay replication, and after that shoot the request, then by the time the request is shot, replication is already 30 seconds behind. Accordingly, the next transaction can be shot almost instantly, because these 30 seconds, this limit will be exhausted very quickly. From the developer's point of view, a transaction at some random moment ... we just started, have not yet had time to do anything, and already interrupt us.
Community response. Everyone says that it was necessary to use the hot_standby_feedback = on option, it was necessary to enable it. Christoph Petus adds that Uber are fools.
This option has its price. There are some negative consequences, otherwise it would be included simply by default. In this case, if going back to this picture, what it does. The replica starts transmitting to the master information about which versions, which transactions are open, and which versions of the lines are still needed. And in this case, the wizard actually simply holds the vacuum so that it does not delete these versions of the lines. There are a lot of problems here too. For example, replicas are often used for testing, so that developers play around not on a combat machine, and not on some replica. Imagine, the developer, when testing, started some kind of transaction and went for lunch, but at this time the vacuum stops at the wizard and eventually the place ends and the optimization stops working and as a result the wizard can simply die.
Or another case. Replicas are often used for some kind of analytics, long-playing queries. This is also a problem. We run a long-running request with the enabled option hot_standby_feedback = on, the vacuum on the wizard also stops. And here it turns out that for some long analytical queries there is no alternative at all. Either they just kill the master with the hot_standby_feedback = on option turned on, or, if it is turned off, they will simply be shot and never completed.
What is everyone silent about? As I said, the option that everyone advises, it delays the vacuum on the wizard and in PostgreSQL were going to make it turned on by default, but the bidders were immediately told why it was not necessary to do so. So simply advising her without reservation is not very fair, I would say.
Errors from developers happen. Christoph Petus says that since Uber couldn’t hire the right developers, they’re fools. Breaks where thin. Developers make mistakes where they are allowed to make mistakes. What no one has said is that physical replication is not well suited for scaling reads. If we use replicas to scale reading, to spin some selects, physical replication in PostgreSQL is simply not suitable for the architecture. It was a kind of hack that was easy to implement, but it had its limits. And this is again not a specific case. Replication can be used for different purposes. Using this replication to scale reading is also quite a typical case. Another problem reported by Uber is replication and write amplification. As we have already discussed, write amplification also happens on the wizard with some specific updates. Too much data is written to disk, but since replication in PostgreSQL is physical, and all changes in files go to replicas, then all these changes that occur in files on the wizard go to the network. It is quite redundant, physical replication, by nature. There are problems in speed between different data centers.If we replicate from one coast to another, then buying a fairly wide channel that would contain all this replication stream that comes from the master is problematic and it is not always possible.
What does the community respond to this. Robert Haas says that it was possible to try WAL compression, which is transmitted in replication over a network or SSL, there you can also enable compression at the network connection level. And also, it was possible to try a logical replication solution, which is available in PostgreSQL. He mentions Slony / Bucardo / Londiste. Simon Riggs gives a lecture on the pros and cons of physical replication, I would write it all here too, but lately I have said so often lately that I’m tired of it already, I suppose that they all have some idea of how logical replication differs from physical. Also, they add that soon there will be pglogical - it is an integrated solution for logical replication in PostgreSQL, which is developed by his company.
Christoph Petus says that there is no need to compare logical and physical replication. But this is strange, because that is exactly what Uber does. He compares the pros and cons of logical and physical replication, saying that physical replication is not very suitable for them, but logical replication in MySQL is just fine. It is not clear why it is not necessary to compare. He adds that Slony, Bucardo is difficult to install and difficult to manage, but this is Uber. If they could not do it, then they are fools. And besides, in version 9.4 there is pglogical. This is a third-party extension for PostgreSQL, which organizes logical replication. It must be said that Uber used older versions of PostgreSQL, 9.2, 9.3, for which there is no pglogical, but they could not move to 9.4. I will tell you further why.
Alexander Korotkov says that Uber compares logical replication in MySQL and physical. Exactly.That is what he does. MySQL does not have physical replication and Alibaba is working to add physical replication to MySQL - this is also true, only Alibaba does it for a completely different use case. Alibaba does this to ensure high availability for its cloud application within a single data center. They do not use cross-regional replication, they do not use reading from replicas. This is only used if a cloud server crashes the server so that they can quickly switch to the replica. That’s all. That is, this use case is different from what Uber uses.
Another Uber issue that they are talking about is cross-version updates. It is necessary to switch from one major version to another and it would be desirable to do this without stopping the wizard. Here in PostgreSQL with physical replication, this problem is not solved. Because, usually, in MySQL do as. Upgrade replicas first, or one replica, if it is only one, to a higher version, then requests are switched to it ... they actually make it a new master, and the old master will upgrade to a new version. It turns out that downtime is minimal. But with physical replication in PostgreSQL, you cannot replicate from a younger version to a higher version, and in general, the versions must be the same on both the master and the replica. Pglogical, again, was not an option for them, because they used older versions and at 9.4, from which pglogical is available, they could not move,because there was no replication. The recursion is like that.
Some of their legacy services, and in Ubere they still remain, they still work on PostgreSQL 9.2 for this simple reason.
Community response. Robert Haas does not comment on this. Simon Riegs says that in general there is pg_upgrade - this is a custom upgrade procedure and with the -k option when hardlinks are used this process takes less time, so downtime will still be, the master will have to be stopped and all requests will also have to be stopped. Well, this may not be so long. In addition, Simon Riggs says that they have a commercial solution in their company that allows them to integrate old versions with new ones.
Christoph Petus says that pg_upgrade is not a panacea, in particular PostGIS, a geographic information extension, due to which Uber switched to PostgreSQL causes a lot of problems when upgrading between major versions. I don't know, I believe him here, because he is a PostgreSQL consultant. He says that Uber is not mastered, again, Slony / Bucardo, pglogical, so they are fools. Alexander Korotkov shows how you can upgrade between major versions using pglogical.
Our report is called: “Uber-answer”, then for Uber it was not an option. The answer to current users, there also has its own nuances.
What is everyone silent about? Yes, there really are all sorts of third-party solutions for PostgreSQL that organize Slony / Bucardo / Londiste logical replication, but they are all trigger-based, they are all based on triggers, that is, a trigger is hung on every table, we take these changes for any update, who made and write them into a special relational journaling table, and then, when they move to replicas, all these changes from the relational table, we delete them. And here there are typical problems. PostgreSQL sore with Vacuum, when data is often inserted and deleted, a lot of work for the vacuum, respectively, a lot of all sorts of problems. Not to mention the fact that the trigger-based solution itself is not very effective, you know, and the data is pulled out of the tables altogether by some external scripts. Not in the DBMS itself,and written in pearl or python, there are different ways, it all depends on the decision and is shifted to replicas.
With pglogical everything is very strange. All advised that pglogical can be used for upgrades from a newer version to a new one. I read the documentation, the developers do not promise that such cross-version replication will work. They say that it can work, but in future versions, something can disperse and, in general, we do not promise anything.
Low “run-in” even now, in 2017. This is a relatively new technology, it is of course progressive, it potentially uses some built-in things in PostgreSQL, and not some external solutions, but I don’t really understand how Uber could be recommended for use in productions in 2015, when pglogical was just beginning to be developed. But what is good about pglogical is that, unlike the main PostgreSQL, you can go and see the bugtracker to assess the stability of the project, the maturity of the project, how widely it is used. Honestly, I was not impressed. It did not impress me as a stable project.
Activity is very low, there are some bugs that have been hanging there for years. Someone has problems with performance, someone has a problem with data loss. That does not give the impression of a stable project. In my hobby project ( sysbench ), there is more activity on the githaba than in pglogical.
What is still not talking? That all of these problems, all of these solutions, third-party and embedded pglogical have problems with sequences, because you cannot hang a trigger on them and the changes are not recorded in the transaction log, which means you have to do some special complex squats to ensure replication sequences. DDL is only through wrapper functions, because, again, triggers cannot be hung on DDL and for some reason they are not recorded in PostgreSQL in the transaction log. All three solutions do not have a log as such, that is, you cannot take any backup and roll logical changes from a log like in MySQL. You can only physical backup, but to make a physical PITR, you need a physical backup. On the logical back up you will not roll it. No GTID, any last things that appeared in replication in MySQL.I did not understand how to make repositioning with the help of these decisions. Say, switch a slave replica from one master to another and understand which transactions have already been lost and which not.
Finally, there is no parallelism. The only way to speed up logical replication is to parallelize it. MySQL has done a lot of work in this direction. All these solutions do not support concurrency at all in any way. He simply does not.
What is everyone missing? First, there is only one correct scenario for applying physical replication in PostgreSQL or in MySQL, when it appears somewhere or anywhere else. This is High Availability inside a single data center, when we have a fairly fast channel, and when we don’t need to read from replicas. This is the only correct use case. Everything else can work, and maybe not, depending on the load and on many other parameters.
At present, PostgreSQL cannot offer a complete replication alternative in MySQL. The bloglog is a strange thing. Many people say that pglogical will appear in PostgreSQL 10, built-in logical replication, in fact very few people in the Postgres community know that some reduced version of ploglog will go into 10. I never found some clear description of what exactly will go down and what will be left behind. In addition, the syntax in 10 will be used somewhat differently from that used by the third-party ploglog extension. It is not clear, it will be possible to somehow use them together. Is it possible to replicate pglogical from older versions in PostgreSQL 10 or not. I have not found anywhere. The ploglog documentation is also peculiar.
Ineffective cache
And finally, an inefficient cache. What is the difference between the implementation of the cache in InnoDB and PostgreSQL. InnoDB uses unbuffered I / O without relying on the operating system's own cache, so all the memory, all the maximum available memory on the machine is allocated to the InnoDB cache. InnoDB uses common pread and pwrite system calls to perform unbuffered I / O. Not relying on the operating system cache.
PostgreSQL has a different architecture. For some reason, direct I / O support for unbuffered I / O has not been done so far; therefore, PostgreSQL relies on both its own cache and the operating system cache at the same time. In addition, for some reason he uses not such system calls that allow you to immediately shift and read something and write, but first a separate system call to shift to the desired position, and then read and write. Two system calls for one operation. There is some duplication of data. Pages of data memory will be stored in its own cache and in the cache of the operating system.
Robert Haas and Simon Rigs do not respond to this. Christophe Petus, something happened to him, he does not call Uber a fool here, I agree that there is a problem, but the effect in practice is not clear. Alexander Korotkov says that pread instead of lseek only optimizes performance for 1.5 percent of performance, but this is part of the problems that Uber lists. Says nothing more.
What does everyone omit? That 1.5% was obtained on one benchmark on a laptop developer who developed this patch. Experimentally there was some discussion on the Postgres hackers mailing list, and the patch ended up stuck in discussions. Robert Haas said that this patch should be included. Even 1.5% is likely to be more on combat systems, even 1.5% is already good, and Tom Lane, another key developer of PostgreSQL, was against it, saying that you don’t need to touch the stable code because of some ,five%. In general, two key developers did not find understanding and the patch ended up stuck. He did not go anywhere.
This is far from the only problem in the design of shared buffers, I in my last year’s report on DevConf disclosed this in detail. There are far more problems there than Uber lists. There is data duplication, there is a problem with double calculation of checksums, there is a problem with “flushing” data from the operating system cache, which InnoDB with its cache can prevent. And in the future, if compression and encryption appear in PostgreSQL, problems with such an architecture will also begin there.
What we see in the end. Uber, I talked to them, and they also gave presentations at conferences, at Percona live. They say that: “We are generally satisfied with MySQL, we are not going to move anywhere. We have old legacy systems that still work on PostgreSQL, but all the main processing is done in MySQL. PostGIS is the main reason why we switched to PostgreSQL, the geoinformational extension. It's cool, but with its pitfalls, and besides, this thing doesn’t scale well for OLTP loads. We found a way to do without it in MySQL. Yes, there is no such possibility in MySQL yet. ”
I give advice that do not believe in this hype, in the halo of a perfect system, devoid of flaws. Be engineers, be skeptical, try to make decisions based on objective things, not based on rumors and some kind of general hysteria. And most importantly - test. Before you are going to replace a DBMS in your project, conduct at least some tests to see how your DBMS behaves on your particular case. I have it all!
Here is such a report with a clear desire to show the benefits of InnoDb :) Of course, soon we will dilute our habr with a report from the opposite camp. Come May 18th to DevConf(special prices are valid until April 30). Alexey promised to be there with a new report. True, now it will be more about MySQL. And Ivan Panchenko from Postgres Professional will talk about the very logical replication that was included in PostgreSQL 10.
Source: https://habr.com/ru/post/353682/
All Articles