How we broke Glusterfs

The story began a year ago when our friend, a colleague and a great enterprise expert on large-scale enterprises came to us with the words: “Guys, I have a wonderful store here with all the fancy features lying around. 90Tb. We did not see any particular need for it, but, naturally, we did not refuse. We set up a couple of backups and safely forgot for a while.
Periodically, there were tasks such as transferring large files between hosts, building WAL for Postgre replicas, etc. Gradually, we began to transfer all the scattered good into this fridge, one way or another connected with our project. We set up rotate, alerts on successful and not-so-successful backup attempts. Over the year, this storage has become one of the important elements of our infrastructure in the operation group.
')
Everything was fine until our expert again came to us and said that he wants to take his gift. And it is necessary to return it urgently.
The choice was small - to shove it all up again anywhere or to assemble your own fridge from blackjack and sticks. By this time, we were already taught, we saw enough of not quite fault-tolerant systems, and fault tolerance became our second self.
Of the many options, our view is particularly hooked Gluster, Glaster. All the same, how to call. If only the result was. Therefore, we began to mock at him.
What is Glaster and why is he needed?
This is a distributed file system that has long been friends with Openstack and is integrated into oVIrt / RHEV. Although our IaaS is not on Openstack, Glaster has a large active community and has native qemu support in the form of the libgfapi interface. Thus, we kill two birds with one stone:
- We raise a stack for backups, fully supported by us. No longer have to be afraid of waiting for the vendor to send a broken part.
- We are testing a new type of storage (volume type), which we can provide to our customers in the future.
Hypotheses that we tested:
- What glaster works. Verified
- That it is fault tolerant - we can reboot any node and the cluster will continue to work, data will be available. We can rebuild several nodes, the data will not be lost. Verified
- That it is reliable - that is, it does not fall by itself, does not expire with memory, etc. Partially true, it took a long time to understand that the problem is not in our hands and heads, but in the Striped configuration of the woluma, which could not work stable in none of the configurations we assembled (details at the end).
The month was spent on experiments and assemblies of various configurations and versions, then there was a test operation in production as the second destination for our technical backups. We wanted to see how he behaves for half a year before relying on him completely.
How to raise
We had enough experimentation sticks with a surplus - a rack with Dell Poweredge r510 and a pack of not very nimble SATA-double-bytes who were inherited from the old S3.
We figured we didn’t need storage for more than 20 TB, and after that it took us about half an hour to fill in two old Dell Power Edge r510s with 10 disks, select another server for the role of arbitrator, download the sachets and secure it. It turned out this scheme.
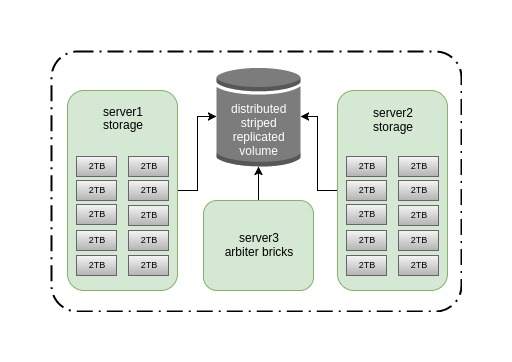
We chose striped-replicated with the arbitrator, because it is fast (data is spread evenly over several bricks), quite reliably (replica 2), you can survive the fall of one node without getting a split-brain. How wrong we were ...
The main disadvantage of our cluster in the current configuration is a very narrow channel, only 1G, but for our purpose it is quite enough. Therefore, this post is not about testing the speed of the system, but about its stability and what to do in case of accidents. Although in the future we plan to switch it to Infiniband 56G from rdma and conduct performance tests, but this is another story.
I will not go deep into the cluster assembly process, everything is quite simple here.
Create a directory for briks:
for i in {0..9} ; do mkdir -p /export/brick$i ; done We roll xfs on discs for briks:
for i in {b..k} ; do mkfs.xfs /dev/sd$i ; done Add mount points in / etc / fstab:
/dev/sdb /export/brick0/ xfs defaults 0 0 /dev/sdc /export/brick1/ xfs defaults 0 0 /dev/sdd /export/brick2/ xfs defaults 0 0 /dev/sde /export/brick3/ xfs defaults 0 0 /dev/sdf /export/brick4/ xfs defaults 0 0 /dev/sdg /export/brick5/ xfs defaults 0 0 /dev/sdh /export/brick6/ xfs defaults 0 0 /dev/sdi /export/brick7/ xfs defaults 0 0 /dev/sdj /export/brick8/ xfs defaults 0 0 /dev/sdk /export/brick9/ xfs defaults 0 0 We mount:
mount -a Add the directory for volyum to brika, which will be called holodilnik:
for i in {0..9} ; do mkdir -p /export/brick$i/holodilnik ; done Next, we need to remove the cluster hosts and create a Volyum.
We put packages on all three hosts:
pdsh -w server[1-3] -- yum install glusterfs-server -y Run Glaster:
systemctl enable glusterd systemctl start glusterd It is useful to know that Glaster has several processes, here are their purposes:
glusterd = management daemon
The main demon, manages Volyum, pulls the rest of the demons responsible for brik and data recovery.
glusterfsd = per-brick daemon
Each brika launches its glusterfsd daemon.
glustershd = self-heal daemon
Responsible for rebuild data from replicated volums in cases of cluster node nodes.
glusterfs = usually client-side, but also NFS on servers
For example, arrives with the glusterfs-fuse native client package.
Pirim nodes:
gluster peer probe server2 gluster peer probe server3 We collect Volyum, here the order of bricks is important - replicated bricks follow each other:
gluster volume create holodilnik stripe 10 replica 3 arbiter 1 transport tcp server1:/export/brick0/holodilnik server2:/export/brick0/holodilnik server3:/export/brick0/holodilnik server1:/export/brick1/holodilnik server2:/export/brick1/holodilnik server3:/export/brick1/holodilnik server1:/export/brick2/holodilnik server2:/export/brick2/holodilnik server3:/export/brick2/holodilnik server1:/export/brick3/holodilnik server2:/export/brick3/holodilnik server3:/export/brick3/holodilnik server1:/export/brick4/holodilnik server2:/export/brick4/holodilnik server3:/export/brick4/holodilnik server1:/export/brick5/holodilnik server2:/export/brick5/holodilnik server3:/export/brick5/holodilnik server1:/export/brick6/holodilnik server2:/export/brick6/holodilnik server3:/export/brick6/holodilnik server1:/export/brick7/holodilnik server2:/export/brick7/holodilnik server3:/export/brick7/holodilnik server1:/export/brick8/holodilnik server2:/export/brick8/holodilnik server3:/export/brick8/holodilnik server1:/export/brick9/holodilnik server2:/export/brick9/holodilnik server3:/export/brick9/holodilnik force We had to try a large number of combinations of parameters, kernel versions (3.10.0, 4.5.4) and Glusterfs itself (3.8, 3.10, 3.13) in order for Glaster to start to behave stably.
We also experimentally set the following parameter values:
gluster volume set holodilnik performance.write-behind on gluster volume set holodilnik nfs.disable on gluster volume set holodilnik cluster.lookup-optimize off gluster volume set holodilnik performance.stat-prefetch off gluster volume set holodilnik server.allow-insecure on gluster volume set holodilnik storage.batch-fsync-delay-usec 0 gluster volume set holodilnik performance.client-io-threads off gluster volume set holodilnik network.frame-timeout 60 gluster volume set holodilnik performance.quick-read on gluster volume set holodilnik performance.flush-behind off gluster volume set holodilnik performance.io-cache off gluster volume set holodilnik performance.read-ahead off gluster volume set holodilnik performance.cache-size 0 gluster volume set holodilnik performance.io-thread-count 64 gluster volume set holodilnik performance.high-prio-threads 64 gluster volume set holodilnik performance.normal-prio-threads 64 gluster volume set holodilnik network.ping-timeout 5 gluster volume set holodilnik server.event-threads 16 gluster volume set holodilnik client.event-threads 16 Additional useful options:
sysctl vm.swappiness=0 sysctl vm.vfs_cache_pressure=120 sysctl vm.dirty_ratio=5 echo "deadline" > /sys/block/sd[bk]/queue/scheduler echo "256" > /sys/block/sd[bk]/queue/nr_requests echo "16" > /proc/sys/vm/page-cluster blockdev --setra 4096 /dev/sd[bk] It is worth adding that these parameters are good in our case with backups, namely with linear operations. For random read / write cases, you need to select something else.
Now we will look at the pros and cons of different types of connection to Glaster and the results of negative test cases.
To connect to Volyum, we tested all the main options:
1. Gluster Native Client (glusterfs-fuse) with the backupvolfile-server option.
Minuses:
- installation of additional software on customers;
- speed.
Plus / minus:
- long inaccessibility of data in case of a dump of one of the nodes of the cluster. The problem is corrected by the server-side network.ping-timeout parameter. Setting the parameter to 5, the ball falls off, respectively, for 5 seconds.
A plus:
- it works quite stably, there were no massive problems with beaten files.
2. Gluster Native Client (gluster-fuse) + VRRP (keepalived).
Configured moving IP between two nodes of the cluster and extinguished one of them.
Minus:
- installation of additional software.
A plus:
- configurable timeout when switching in case of cluster node's dump.
As it turned out, specifying the backupvolfile-server parameter or the keepalived setting is optional, the client itself connects to the Glaster daemon (no matter which address), recognizes the remaining addresses and starts writing to all the nodes of the cluster. In our case, we saw symmetric traffic from the client to server1 and server2. Even if you give him a VIP address, the client will still use Glusterfs cluster addresses. We came to the conclusion that this parameter is useful when the client tries to connect to the Glusterfs server, which is unavailable, when it starts, then it will contact the host specified in the backupvolfile-server.
Comment from official documentation:
GlusterFS “round robin” style connection. In / etc / fstab , the node is used; It means that there is no need for further information. The performance based on tests, but not drastically so. The gain is an automatic HA client failover, which is typically worth the effect on performance.
3. NFS-Ganesha server, with Pacemaker.
The recommended type of connection, if for some reason you do not want to use the native client.
Minuses:
- even more additional software;
- fussing with pacemaker;
- caught the bug .
4. NFSv3 and NLM + VRRP (keepalived).
Classic NFS with lock support and moving IP between two cluster nodes.
Pros:
- fast switching in case of failure of the node;
- easy keepalived settings;
- nfs-utils is installed on all our client hosts by default.
Minuses:
- the client hangs NFS in status D after a few minutes rsync to the mount point;
- drop the node with the client entirely - BUG: soft lockup - CPU stuck for Xs!
- caught a lot of cases when the files broke with the errors stale file handle, Directory not empty with rm -rf, Remote I / O error, etc.
The worst option, moreover, in later versions of Glusterfs he became deprecated, we do not advise anyone.
As a result, we chose a glusterfs-fuse without keepalived and with a backupvolfile-server parameter. As in our configuration, he is the only one who showed stability, despite the relatively low speed of work.
In addition to the need to configure a highly available solution, in productive operation, we should be able to restore the service in case of accidents. Therefore, after assembling a stably operating cluster, we proceeded to destructive tests.
Unusual shutdown of the node (cold reboot)
We launched rsync of a large number of files from one client, hard put out one of the nodes of the cluster and got very funny results. After the node crashes, the recording first stopped for 5 seconds (the network.ping-timeout 5 parameter is responsible for this), after that the write speed to the ball doubled, as the client can no longer replicate data and starts sending all traffic to the remaining node, continuing to abut in our 1G channel.

When the server started up, the automatic data disinfection process started in the cluster, for which the glustershd daemon is responsible, and the speed dropped significantly.
So you can see the number of files that are treated after the node's dump:
gluster volume heal holodilnik info ...
Brick server2: / export / brick1 / holodilnik
/2018-01-20-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
Brick server2: / export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
Brick server3: / export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
...
/2018-01-20-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
Brick server2: / export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
Brick server3: / export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
Status: Connected
Number of entries: 1
...
At the end of the treatment, the counters were reset and the recording speed returned to the previous indicators.
Disc blade and its replacement
Blade disc with a briquette, as well as its replacement, did not slow down the speed of writing to the ball. Probably, the fact is that the bottleneck here is, again, the channel between the nodes of the cluster, and not the speed of the disks. As soon as we have additional Infiniband cards, we will conduct tests with a wider channel.
It is worth noting that when you change a disc that has flown out, it should return with the same name in sysfs (/ dev / sdX). It often happens that a new drive is assigned the next letter. I highly recommend not to enter it in this form, since during the subsequent reboot it will take the old name, the block device names will be eaten and the bricks will not rise. Therefore, it is necessary to carry out several actions.
Most likely, the problem is that somewhere in the system remained the mount point of the ejected disk. Therefore, we do umount.
umount /dev/sdX We also check which process can hold this device:
lsof | grep sdX And we stop this process.
After that, you need to make a rescan.
We look in dmesg-H for more detailed information on the location of the ejected disk:
[Feb14 12:28] quiet_error: 29686 callbacks suppressed
[ +0.000005] Buffer I/O error on device sdf, logical block 122060815
[ +0.000042] lost page write due to I/O error on sdf
[ +0.001007] blk_update_request: I/O error, dev sdf, sector 1952988564
[ +0.000043] XFS (sdf): metadata I/O error: block 0x74683d94 ("xlog_iodone") error 5 numblks 64
[ +0.000074] XFS (sdf): xfs_do_force_shutdown(0x2) called from line 1180 of file fs/xfs/xfs_log.c. Return address = 0xffffffffa031bbbe
[ +0.000026] XFS (sdf): Log I/O Error Detected. Shutting down filesystem
[ +0.000029] XFS (sdf): Please umount the filesystem and rectify the problem(s)
[ +0.000034] XFS (sdf): xfs_log_force: error -5 returned.
[ +2.449233] XFS (sdf): xfs_log_force: error -5 returned.
[ +4.106773] sd 0:2:5:0: [sdf] Synchronizing SCSI cache
[ +25.997287] XFS (sdf): xfs_log_force: error -5 returned.
sd 0:2:5:0 — :
h == hostadapter id (first one being 0)
c == SCSI channel on hostadapter (first one being 2) — PCI-
t == ID (5) —
l == LUN (first one being 0)
Rescan:
echo 1 > /sys/block/sdY/device/delete echo "2 5 0" > /sys/class/scsi_host/host0/scan where sdY is the wrong drive name.
Next, to replace the breeze, we need to create a new mount directory, roll out the file system and mount it:
mkdir -p /export/newvol/brick mkfs.xfs /dev/sdf -f mount /dev/sdf /export/newvol/ We are replacing brick:
gluster volume replace-brick holodilnik server1:/export/sdf/brick server1:/export/newvol/brick commit force We start the treatment:
gluster volume heal holodilnik full gluster volume heal holodilnik info summary Dump of the arbitrator:
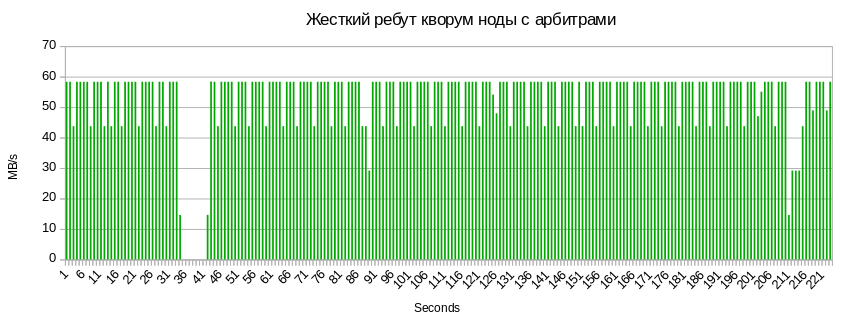
The same 5–7 seconds of inaccessibility are balls and 3 seconds of drawdown associated with syntax of metadata per quorum node.
Summary
The results of the destructive tests pleased us, and we partially introduced it into the food, but we were not happy for long ...
Problem 1, it’s a known bug
When deleting a large number of files and directories (about 100,000), we eaten this “beauty”:
rm -rf /mnt/holodilnik/* rm: cannot remove 'backups/public': Remote I/O error rm: cannot remove 'backups/mongo/5919d69b46e0fb008d23778c/mc.ru-msk': Directory not empty rm: cannot remove 'billing/2018-02-02_before-update_0.10.0/mongodb/': Stale file handle I read about 30 such applications that start in 2013. There is no solution to the problem anywhere.
Red Hat recommends updating the version , but it did not help us.
Our workaround is to simply clean up the remnants of broken directories in bricks on all nodes:
pdsh -w server[1-3] -- rm -rf /export/brick[0-9]/holodilnik/<failed_dir_path> But further - worse.
Problem 2, the worst
We tried to unpack the archive with a large number of files inside the Striped Volum balls and got dangling tar xvfz in Uninterruptible sleep. Which is treated only by the reboot of the client node.
Realizing that it was impossible to continue to live like this, we turned to the last configuration that we had not tried, which did not inspire confidence in us, erasure coding. Its only complexity is in understanding the principle of assembling volyum.
Having banished all the same destructive tests, we got the same pleasant results. Millions of files were uploaded and deleted. As soon as we tried, we failed to break the Dispersed volume. We have seen a higher load on the CPU, but for now this is uncritical.
Now it backs up a piece of our infrastructure and is used as a file storage for our internal applications. We want to live with him, see how he works under different loads. While it is clear that the type of volyum "strayp" works strangely, and the rest is very good. Further plans are to collect 50 TB of dispersed volume 4 + 2 on six servers with a wide Infiniband channel, drive out performance tests and continue to delve deeper into its principles of operation.
Source: https://habr.com/ru/post/353666/
All Articles