Control of complexity and architecture of UDF

Complexity is the main enemy of the developer. There is such a hypothesis, although I would attribute it to the axioms that the complexity of any software product over time, in the process of adding a new functionality, inevitably grows. It grows until it reaches the threshold at which any change is guaranteed, i.e. with a probability close to 100%, will introduce an error. There is also an addition to this hypothesis - if such a project is continued and further supported, then sooner or later it will reach such a level of complexity that it will be impossible to make the necessary change at all. It is impossible to come up with a solution that does not contain any crutches, notorious anti-patterns.
Source of difficulty
The complexity is inevitably introduced by the input requirements, it is impossible to avoid this kind of complexity. For example, in any accounting program you have a task to make payments to a person, and among the calculation of these payments there is such a requirement that a person who has worked in a company for more than a certain period will receive an additional amount for length of service. Application code will inevitably contain something like this:
if(qualifiedForExtraPayment(employee)) { calculateThatExtraPayment(...) } This if is the element of complexity introduced into the application by a business requirement.
But there is a complexity that is not defined by the requirements, and is contributed directly by the developer. Most of all, this “artificial” complexity comes from some particular understanding of the DRY principle by developers.
For example, in the already mentioned hypothetical accounting program you need to make two almost identical pages, on both you need to count the payments to the person, and show the detailed information on these payments. But one page is purely informational, to see how many people will receive money, and the second page is already executive, with a third action present - to make the actual money transfer.
')
The example is of course fictional, but I regularly come across such things in the code of other developers.
How to solve it.
On the first page, the pseudocode will be
const payment = calculatePayment(employee); displayPayment(payment); On the second page
const payment = calculatePayment(employee); displayPayment(payment); proceedWithPayment(payment); How it is sometimes decided.
Instead of creating the second method, in the first one an additional parameter is entered.
const payment = calculatePayment(employee); displayPayment(payment); if(isOnlyInformation) { return; } proceedWithPayment(payment); And here we see another if, another element of complexity in our application. This item of complexity does not come from the requirements, but comes from the way the problem is solved by the developer.
Where the code is already sufficiently decomposed, it turns out that the two methods “stuck together” into one due to the fact that they only matched two lines. But initially, at the stage when the code is first written on the forehead, the implementation of these methods (calculatePayment and displayPayment) may not yet be rendered into separate methods, but written directly in the body of this, and the picture looks like the two methods are the same, say , 100 first lines. In this case, here is such a “getting rid of code duplication”, it may even seem like a good solution. But this is obviously not the case. In my last article about the dry anti-pattern, I have already given examples of how using the DRY principle carries complexity that you can avoid in your application. With ways to write the same code, but without using a pattern, without adding complexity to the application that does not come from requirements.
Thus, we come to the fact that in the hands of one developer, the complexity of the application grows linearly, in proportion to the complexity of the requirements, or at least tends to this, in the hands of another developer, the complexity grows exponentially.
Principle of sole responsibility
“Evenly distributed” complexity is not so harmful and dangerous, for all its inevitability, but it becomes a developer’s terrible dream when concentrated in one place. If you have an if function, then you add a second branch, if there are two, and no matter if it is nested or not, then there will be at least 4 possible options for passing through the method, the third if will make 8. And if you have two separate , successfully decomposed, not affecting each other functions, in each of which there are 4 branches of execution, then each of them potentially needs to be written four tests, total 8. If it was not possible to decompose, and all this logic is in one method, then the tests you need to write 4 * 4 => 16, and each such test will be more difficult than tes of the first eight. The number and complexity of tests just the same and reflect the final complexity of the application, which, with the same number of elements of complexity, will more than double.
The widely known principle of designing a code, hereinafter referred to as SRP, the first paragraph of the collection of SOLID principles, is aimed at combating such a heap of complexity. And if the remaining letters of this abbreviation contain rules for the most part refer to object-oriented programming, then SRP is universal, and applies not only to any programming paradigm, but also to architectural solutions, but what can I say, and to other engineering fields too. The principle, unfortunately, contains some understatement, it is not always clear, but how to determine right now the only responsibility for something or not. For example, here is a god-class in a million lines, but it has the only responsibility - it manages the satellite. He doesn't do anything else, is everything okay? Obviously not. The principle can be rephrased somewhat - if a certain element of your code, and this can be both a function, a class, and a whole layer of your application, is too much responsibility, it means you need to decompose, break into pieces. And the fact that it is too much can be determined just by such signs - if the test for this is too complicated, contains many steps, or if you need a lot of tests, it means that there is too much responsibility and you need to decompose. Sometimes this can be determined even without looking at the code. According to the so-called code-smell, if I go into a file with one class and I see 800 lines of code there, I don’t even need to read this code to see that this class has too much responsibility. If there is a whole page of dependencies in the file (imports, yuzings, etc.), I do not need to scroll down and start reading this code in order to come to the same conclusion. There are of course different tricks, IDE indulge citizens coders, collapsing imports "under the plus sign", there are tricks of the city of coders themselves who put the widescreen monitor vertically. Again, I don’t even need to read the code of such a developer in order to understand that I’ll probably not like it.
But decomposition does not have to reach the absolute, “the other end of this stick” - a million methods, each with one operand may be no better than one method with a million operands. Again, when excessive decomposition inevitably arises the first of those two playful "most difficult tasks in programming" - the naming of functions and cache invalidation. But before you get to this, the average developer must first learn how to decompose it at least minimally, at least slightly away from the end, with a class of 800 lines.
By the way, there is one more such jokingly-philosophical thought - a class, as a concept, carries in itself too much responsibility - behavior and state. It can be divided into two entities - functions for behavior and “plain” objects (POJO, POCO, etc., or structures in C) for the state. Hence, the OOP paradigm is untenable. Live with it.
Architecture as a struggle with complexity
As I have already said, complexity, like multiplication of complexity, is not specific to programming; they exist in all aspects of life. And the solution to this problem was proposed by Caesar - divide and conquer. The two problems linked with each other are more difficult to defeat than both of these problems one by one, as well as the more difficult to defeat the two barbarian tribes united to fight the Romans. If, however, they are somehow separated from each other, then defeating one tribe separately, then the other is much easier. At a low level, when writing already specific code, this is decomposition and SRP. At a high level, at the design level of the application, architectural solutions serve this.
From here on, I concentrate on UI / frontend specificity.
For the development of applications containing a UI, architectural solutions such as MVC, MVP, MVVM have long been used. All these solutions have two common features, the first - M, "model". They even give it some kind of definition, I will manage here with such a simplification - the rest of the program. The second is V, "view" or view. This layer is separated from the rest of the application, the sole responsibility of which is a visual representation of the data coming from the model. These architectures differ in the way M and V communicate with each other. I will not consider them, of course, I will only pay attention once again that all the forces spent on developing these architectures were directed at separating one problem from another, and, as you might guess, to reduce the complexity of the application.
And, saying that the visual presentation is the sole responsibility of this layer, I mean the fundamental principle of these architectures - there should be no logic in the presentation layer. Totally. It is for this that these architectures are conceived. And if we talk about the MVC architecture, then there was still such a term “thin controller”. Using this architecture, people came to the conclusion that the logic controller should not contain either. Totally. For logic, this will be the second responsibility of this layer, and we must strive to ensure that it is one.
Unidirectional Data Flow Architecture
Motivation
The purpose of this architecture, like the goal of the previously mentioned architectures, is exactly the same - reducing the complexity of the application, by separating the problems between themselves, and building a logical barrier between them. The advantage of this architecture, why it should be preferred to other architectures in the following. Applications are not limited to one “view” and one “model”, in any application you will have several. And some kind of connection between them should be. As an example, I will take the following - you need to calculate some amount on the table. In one view, a person enters data in the table, another model subscribes to this data, calculates the amount, tells his view what needs to be updated. Further, the example is expanded by the fact that then a third model is signed for this amount, in which you need to make the “Apply” button active. And sometimes the developer may be confused that this is the last action - the responsibility of the presentation, and we can see in the markup something like this:
<div *ngIf="otherModel.sumOfItems === 100"> .This is already a mistake, the comparison of two numbers is already logic, which the model should be in charge of strictly, the markup should operate with flags strictly counted for it -
<div *ngIf="myModel.canProceed"> .In particularly neglected cases, it is in the view that this connection is written between the two models, the data from the foreign model is checked, and the method is called that carries side effects in its model. In any case, between the models appears a graph of the distribution of changes.
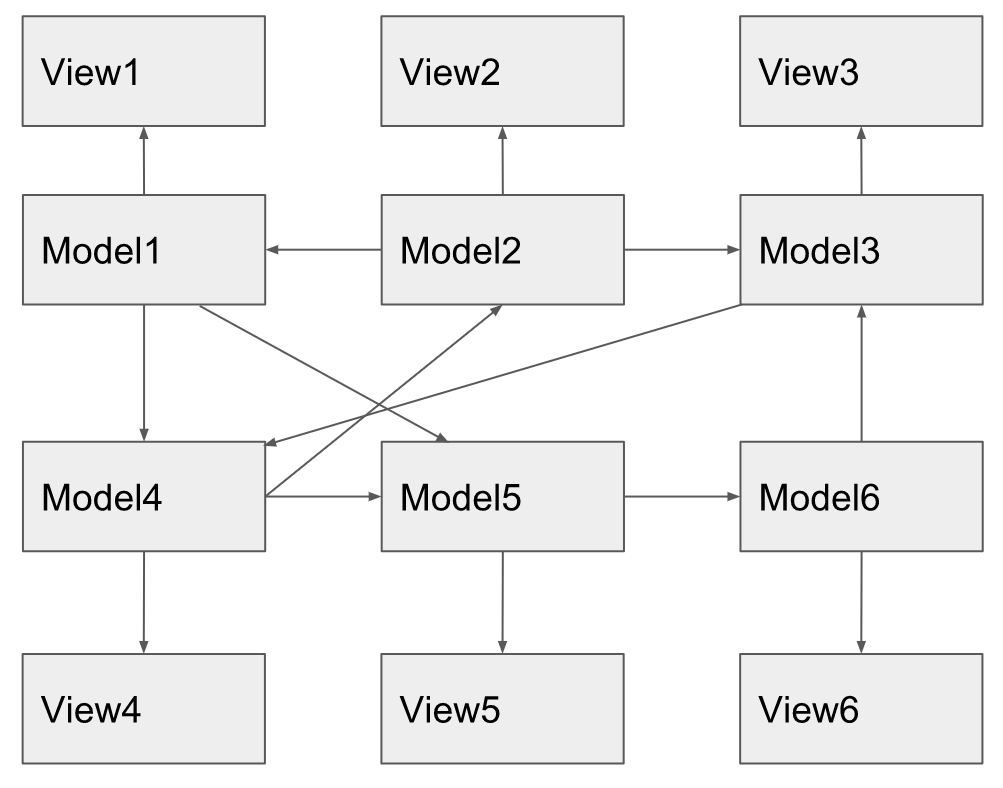
Sooner or later, this graph becomes uncontrollable and, making changes, it is not easy for the developer to track what consequences this will incur in the side-effects occurring lower in the graph. In the Facebook presentation, it was called downstream effects, this is not a term. Also, another developer trying to fix an error arising lower in the graph will have difficulty in tracking the root-cause of this problem, lying one or even several steps higher in this graph. In some places, this graph can get stuck in cycles, and the condition for exiting this cycle can be broken by a harmless change at a completely different point of the graph, as a result, your application hangs and you cannot understand why. It is easy to see that the distribution graph of changes does not come from customer requirements. They only dictate the sequential actions to be performed, and the fact that these actions are scattered throughout the code as {substitute the necessary epithet}, and subscriptions, event throws, etc. are inserted between them. This is on the conscience of the developer.
A little more about this can be found in the motivation of Redux .
The architecture of the UDF is a conveyor, on which two principal limitations are imposed 1) the next stage of the conveyor has no right to influence the previous one, or the results of its execution. 2) "Looping" of the pipeline can only produce input from the user. Hence the name of the architecture - the application itself moves data only in one direction, towards the user, and only external influence can go in the opposite direction to this main stream.
The main stages in the pipeline two, the first is responsible for the state, the second for the display. In some ways, this is similar to the model and representation in the above-mentioned architectures, the difference as well as between those architectures - in the interaction of the model with the representation. And in addition to this in the interaction of models with each other. The entire state of the application is concentrated in a certain stor, and when some external event occurs, such as user input, the entire state change from point A (to external stimulus) to point B (after stimulus) should occur in one action. That is, in the same script above, the code will look something like this, using the redux reducer as an example:
function userInputHappened(prev, input) { const table = updateRow(prev.table, input); const total = calculateTotal(prev.total, table); const canProceed = determineCanProceed(prev.canProceed, total); return { ...prev, table, total, canProceed }; } Here is illustrated the key principle, the main difference from the usual construction of logic. There are no subscriptions to one another, no abandoned events between two successive operations. All actions that need to be performed on a given external stimulus must be written in sequence. And when making changes to such a code, all the consequences of changes are foreseeable. And, as a result, this artificially introduced complexity is minimized.
Redux
Initially, the front-end UDF architecture was proposed by Facebook as part of a bundle of two react and flux libraries, and redux came to replace flux a bit later, offering a couple of very important changes. The first is that state control is now supposed to be written with pure code; in fact, all our state management can now be described with one simple formula.
The next state is equal to the pure function of the previous state and some stimulus.
Second, the presentation layer is now another pure function.
That is, the task of all UI components is to get an object as input, to produce a result markup.
Thus, the following are achieved:
1. “unclean”, asynchronous code is shifted from the application to its edge, two large, I can even say the defining blocks of your application become clean.
2. Very cool debasement instruments. The first one is hot reload, which allows you to replace the pure render function on the fly without losing your state, that is, you can edit the UI layer “hot” and immediately see the result. without restarting the application each time, and also without the need to “click on” to the point where the bug is played. The second tool is time travel, it allows you to remember all your states from State (1) to State (n), and walk back and forth on them, looking successively about what could go wrong. Additionally, it is possible to reproduce the bug on one PC, export the timeline, and download it on another PC, that is, transfer the bug from the tester to the developer, even without a description of the steps to play this bug. But this second tool imposes another requirement - the state and the action of the highest application must be serializable. Those. even base classes like Map or DateTime cannot be used. Only POJO. In addition, in redusers one cannot rely on the reference equality of objects, it is necessary to compare by value, for example, by id.
3. reuse - ask yourself questions - did you encounter a case when some UI component climbs into the model itself, gets data for itself, processes it and displays it itself?
Has it happened that a new task comes to use the same UI, but with a different data source, or in another scenario, with a different set of actions? Sometimes reusing the same markup in another scenario is simply unrealistic.
It is quite another thing to reuse the UI chunk, which accepts an object and produces the result markup. Even if you have a different data design in the right place, you convert it into something that takes this component, insert it to yourself and give it this object. As a result, you are fully confident that it will provide what you need and it will have absolutely no side effects.
Same with state management. You have a function that updates the line in the table. Suppose it does something else inside itself, normalizes the table in some way, sorts it, etc. What does it cost to call a clean function from another script? Again you are sure that it will not have any side effects.
It’s impossible to reuse the whole script. Due to the fact that there is a complete decoupling of the presentation state. And the entry points for such reuse will have to be duplicated, but the main “meat” at such entry points can and should be reused.
Unfortunately there is no good and no blessing, Redux lost one important limitation. , «», , FLUX — Action, . UI , , . , . redux .
Redux UDF
, .
1) UI , UI
2) UI (sick!) .
3) UI *Adapter ( , *Injector, *Factory?)
4) UI «», «»
5) UI , Action, «» ,
. , , UI , . — UI , ( , , , , , code-smell , ) , , , , . , , api, , , .
, , — . — , . , , if, 3 .
:
, redux, , «» , 4 , .
, , , Facebook.
Total:
1) UDF, redux , fancy pub-sub.
2) coupling
3) SRP —
4) — / .
, UI , « ». , , .
, , , , .
knockoutJS.
tableVm, table, ,
tableVm.table = ko.observable(someInitialData); tableVm.updateTable = function(input) { const current = tableVm.table(); const updated = ... // some code here tableVm.table(updated); } ( ) View-Model-
tableTotalVm.total = ko.computed(() => tableVm.table().map(...).sum()); VM
submitVm.canProceed = ko.computed(() => tableTotalVm.total() === 100); , — «back to square one», , UDF — , .. .
.
, , UI , , UI , .
lowerVm.index = ko.observable(indexLoadedFromApi); upperVm.index = ko.computed( () => lowerVm.index() + 1), (newVal) => lowerVm.index(newVal - 1) ); UI , computed . Since , , UI. — , , - , - . circular dependency detection «», , , stack overflow.
, . . Civilization , , , 100%, , . - computed. , . , computed , observable, . , observable .
, , , knockout, , . UDF « », . UI , , . , .
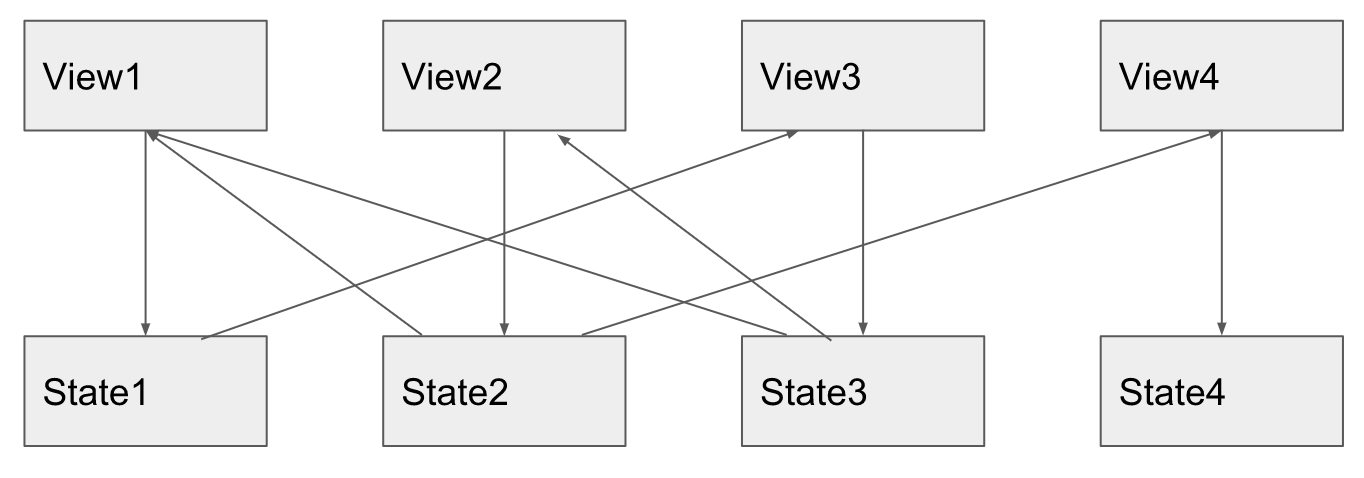
This misunderstanding can be seen by what the diagram is drawn, and it is drawn with a single model, the only view, where you don’t see what exactly the UDF should conquer the minds of the developers. Where all architectures look good, and in general it is not easy to understand the difference between them. And you need to draw a situation where there are a lot of these models and views. And where there are a lot of them with the use of reactive programming, the change distribution diagram looks like this:

view1, computed, observable, , computed5 , view3 . knockout , computed N , . , knockout , , , .
UDF
When I studied application examples on react / redux, I had the feeling that it was not fully worked out. In particular, by the author redux himself, Den Abramov suggests directly in UI components, in the same files to write so-called. dispatchToProps functions that are attached to the props ui components the following
(dispatch) => { return { someMethod: (someData) => { dispatch({type: Actions.someAction, someData }); } } }; Sometimes these methods become more complex, their content expands, including asynchronous operations appear.
(dispatch) => { return { async someMethod: (someId) => { dispatch({type: Actions.startedLoadingAction }); const someData = await api.loadSomeData(someId); dispatch({type: Actions.someAction, someData }); } } }; , . , UI - . , , , UDF. , , ? - , , , . — N- N-1. , , , . , backend, . , . , .
.
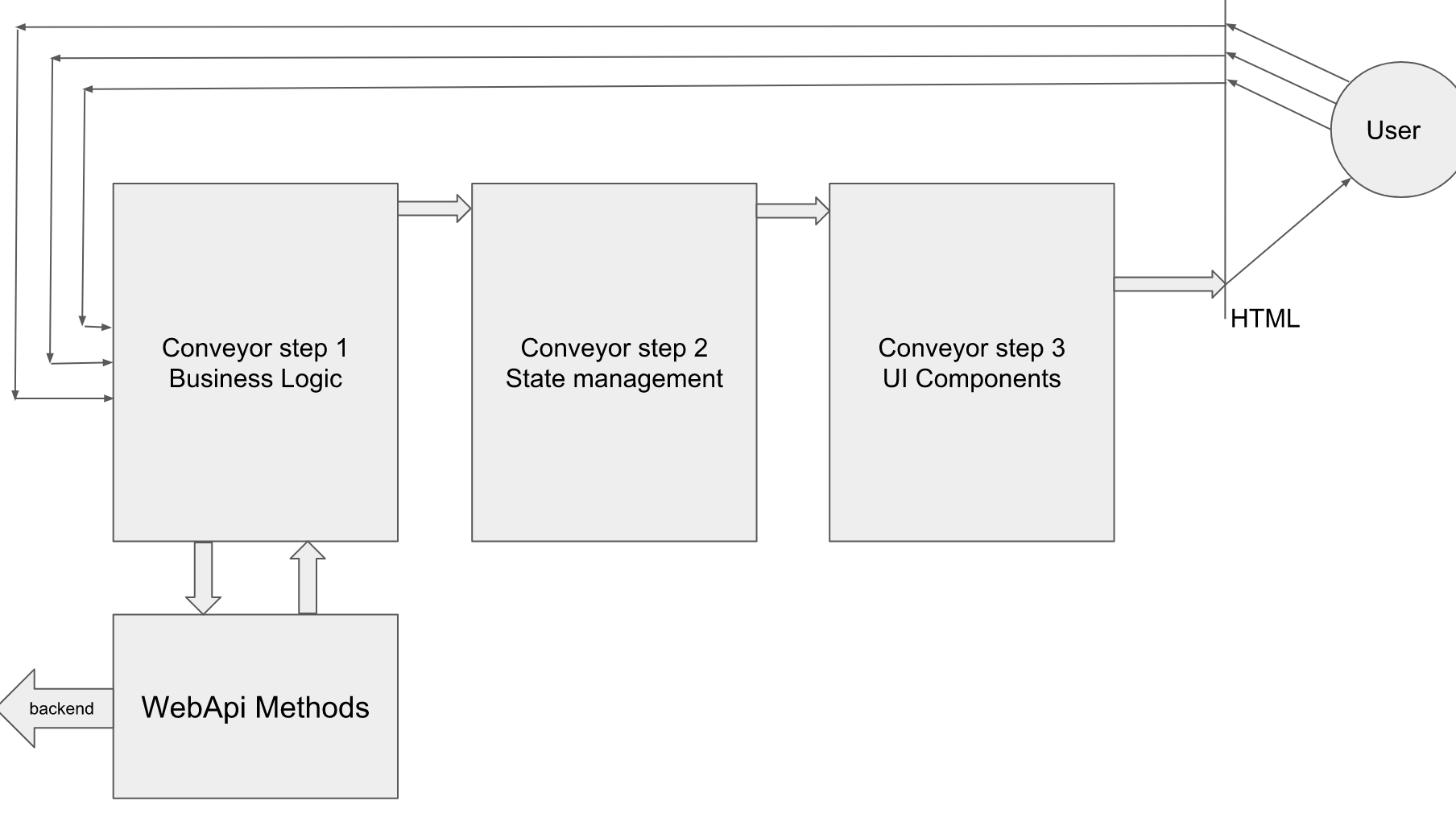
/ , . -. UI . Action- « », UI , .
. , , .
<button onClick={() => service.userClickedApply()} ></button> ui- , , - .
, . .
.
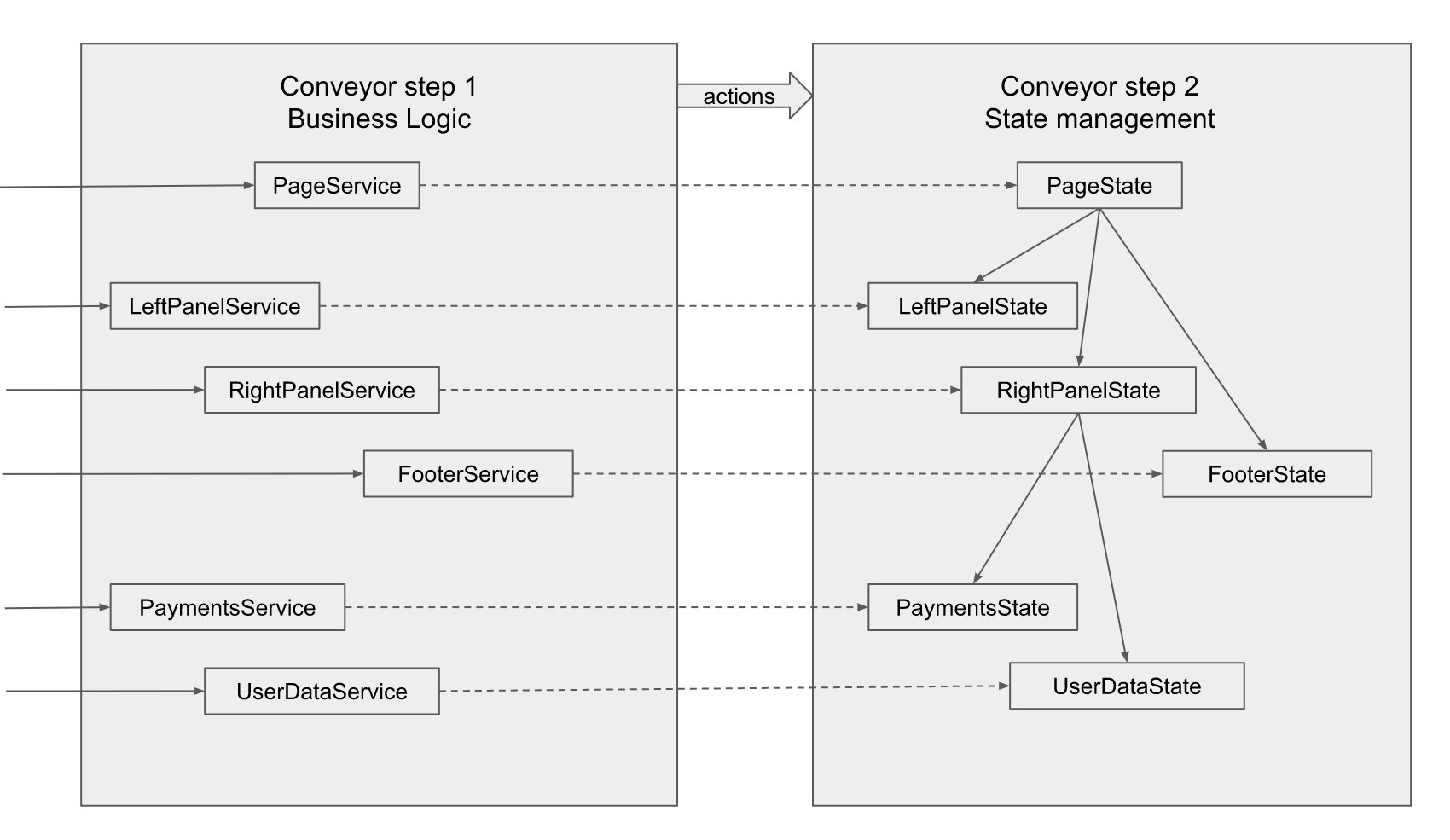
UI , . , , , Payments UserData. , UI , , , .
If user input concerns a particular component, i.e. according to the requirements, this user input does not affect anything else on the screen, the service corresponding to this particular component is called, its method creates an Action lying next to the definition of its state, i.e. interface (implied by the typescript), and the actual editor. The service naturally does not have a direct connection with the reduser of this component, therefore the arrow is dashed. Action is fed to the central entry point, to the stop.
, - , UserData « » payments, UserData «». , Action, , . , . , , , , , Action , . , , , . , , , , .
, . .
import {store} from ... import {LeftPanel, RightPanel, Footer } from ... export class Page extends React.Component { componentWillMount() { store.subscribe(() => this.setState(store.getState())); } render() { return ( <div> <h1>Title here</h1> <LeftPanel state={this.state.leftPanel} /> <RightPanel state={this.state.rightPanel} /> <Footer state={this.state.footer /> </div> ); } } , , — , , , . . UserData . , , .
import {rightPanelService, userDataService} from ... import {UserData } from ... export class RightPanel extends React.PureComponent{ render() { const state = this.props.state; return ( <div class="right-panel"> <UserData state={state.userData} onLastYearClicked={() => rightPanelService.lastYearClicked()} onUserNameChanged={(userName) => userDataService.userNameChanged(userName)} /> <Payments state={state.payments} ...etc. /> </div> ); } } , PureComponent, , rightPanel , , , . . PureComponent , , Redux, . ( 2, 4, 5...) . , @Input- ( reference equality), dirty check , , , , .
UserData
export function UserData({state, onLastYearClicked, onUserNameChanged}) { return ( <div class="user-data"> <input value={state.userName} onChange={(newVal) => onUserNameChanged(newVal)} /> ...etc. </div> ); } . , frontend- , . :
1) — «» behavior- UI .
2)
3) , , , .. .
those. , .
nodeJS? , , , , , -, . , ( ), , .
, , , . , , overnight. , behavior unit- , , , .
, . @Injectable, backend Http. dependency injection «» fetch Http Promise Observable , zone.js, , async/await.
At last
, redux, . typescript, .. , .
Source: https://habr.com/ru/post/353590/
All Articles