JupyterHub, or how to manage hundreds of Python users. Yandex lecture
The Jupyter platform allows novice developers, data analysts, and students to quickly begin programming in Python. Suppose your team is growing - now there are not only programmers, but also managers, analysts, researchers. Sooner or later, the lack of a shared working environment and the complexity of the settings will begin to slow down the work. JupyterHub, a multi-user server with the ability to launch Jupyter with one button, will help to cope with this problem. It is great for those who teach Python, as well as for analysts. The user only needs a browser: no problems installing software on a laptop, compatibility, packages. Jupyter maintainers actively develop JupyterHub along with JupyterLab and nteract.
My name is Andrei Petrin, I am the head of the growth analyst group at Yandex. In a report at the Moscow Python Meetup, I recalled the advantages of Jupyter and spoke about the architecture and principles of JupyterHub, as well as about the experience of using these systems in Yandex. At the end you will learn how to raise JupyterHub on any computer.
- To begin with, who are analysts in Yandex. There is an analogy that this is such a many-handed Shiva who can do many different things at once and combines many roles.
')
Hello! My name is Andrei Petrin, I am the head of the growth analyst group at Yandex. I will talk about the JupyterHub library, which at one time greatly simplified our lives in Yandex analytics, we literally felt the productivity boost of a large number of teams.

For example, analysts at Yandex are a little bit managers. Analysts always know the timeline, timeline of the process, what is the moment to do.
This is a little bit of developers, they are familiar with different ways of processing data. For example, on the slide in Shiva’s hands, those Python libraries that come to my mind are not a complete list, but something that is used on a daily basis. Naturally, we are developing not only in Python, but I will talk primarily about Python.
Analysts - a little bit of mathematics, we need to make decisions carefully, look at the real data, not at the managerial point of view, but look for some truth and understand this.
In this whole task, the Jupyter ecosystem helps us quite a lot.
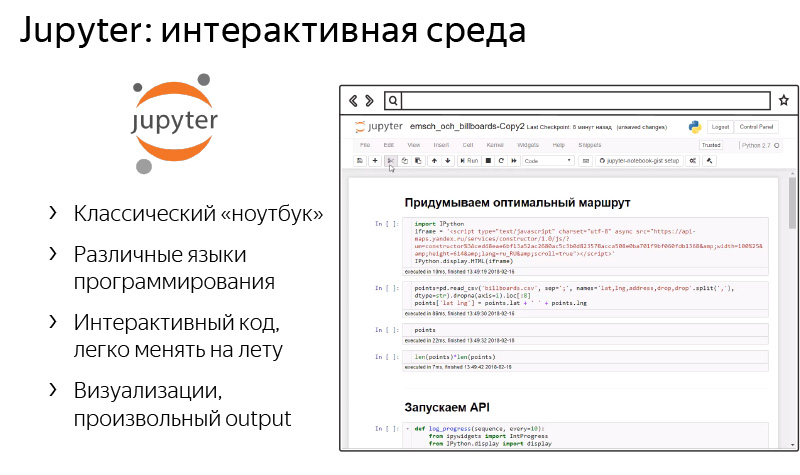
This is such a platform for interactive programming and creating laptop reports. The key essence of Jupyter laptops is such a laptop, where there are a large variety of widgets, interactive elements that can be changed. As the main entity - microelements of the code that you program. They can be printed in a laptop in your browser, which you constantly use. It can be both pictures and interactive HTML-derived elements. You can simply print, print, display items - a variety of things.
The Jupyter system has been developing for a long time, it supports various programming languages of various versions, Python 2 and 3, Go, various things. Allows you to cool to solve our everyday tasks.
What do we do in analytics and how does Jupyter help us a lot with this?
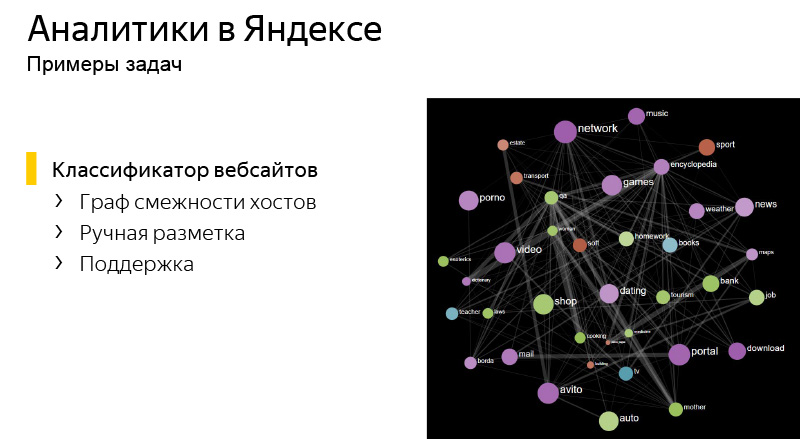
The first task is the classification of websites. It turns out that for big Yandex, who knows about the entire Internet, it is quite laborious to look at specific sites. We have such a number of sites, each of which can have its own specifics, that we need to aggregate this to some topics - groups of sites that are not very large, which generally behave similarly.
For this task, we build the adjacency graph of all Internet hosts, the graph of the similarity of the two sites to each other. With the help of manual markup of hosts, we get some primary base on what sites on the Internet are there, and further we extrapolate manual markup to the entire Internet. Literally in each of the tasks we use Jupyter. From the point of view of constructing an adjacency graph, it allows one to constantly launch operations on MapReduce, to construct such graphs, to carry out such data analytics.
We automated the manual layout in Jupyter with the help of widgets. We have for each host the intended subject, which is likely correct. We almost always guess topics, but for manual marking people still need.
And you get all sorts of interesting pictures.

For example, it shows sports websites and related search queries that are present in sports topics.

Subject encyclopedias. Sites and generally unique requests are smaller, but more basic requests.
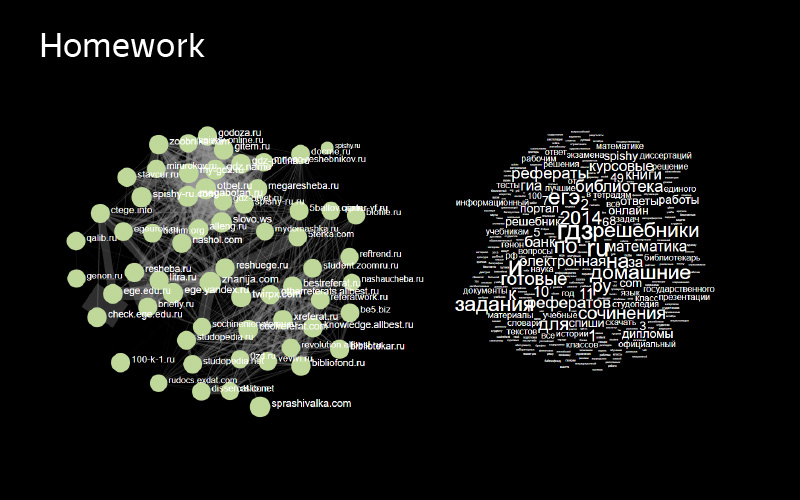
Subject homework - finished homework. Interesting enough, because inside it there are two independent clusters of sites that are similar to each other, but not similar to the others. This is a good example of topics that I would like to break into two. One half of the sites clearly solves one problem within the homework, the other - the other.

It was quite interesting to do a bid optimizer, a completely different puzzle. In Yandex, a certain number of mobile applications are purchased, including for money, and we already know how to predict the user's lifetime, how much we can get from installing some kind of application for each user, but it turns out that unfortunately, this knowledge is difficult to convey to the marketer, Executive who will be engaged in the purchase of traffic. This is usually due to the fact that there is always a budget, there is a rather large number of restrictions. It is necessary to do this multidimensional optimization task, which is interesting from the point of view of analytics, but you need to make a device for the manager.
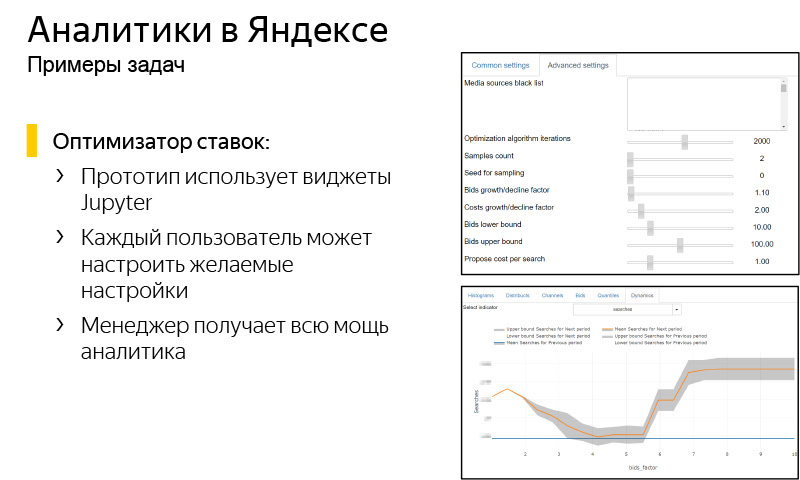
Jupyter helps a lot here. This is the interface that we developed in Jupyter so that a user manager who does not have knowledge of Python can log in and get the result of our prediction. You can choose there whether we choose Android or iOS, on which countries, which application. There are quite complex controllers and handles that can be changed, for example, some progress bars, budget size, some kind of risk tolerance. These tasks are solved with the help of Jupyter, and we are very pleased that the analyst, being a multi-armed Shiva, can solve these problems alone.
About five years ago we came to the conclusion that there are some limitations and problems of the platform with which I want to fight. The first problem is that we have a lot of different analysts, each of which is always on different versions, operating systems, etc. Often, the code that works for one person does not run for another.
Another big problem is the package versions. I think it’s not necessary to tell how hard it is to maintain some consistent environment so that everything can start out of the box.
And in general, we began to understand that if you provide a new analyst who just came to the team in a pre-configured environment where everything will be set up, all packages are delivered to the current version and mainframe in a single place, it is as good for analytical work as and for development. In general, the thought is slim for the developer, but it is not always applicable to the analyst because of the constant changes in the analytics that are occurring.
This is where the JupyterHub library came to our rescue.
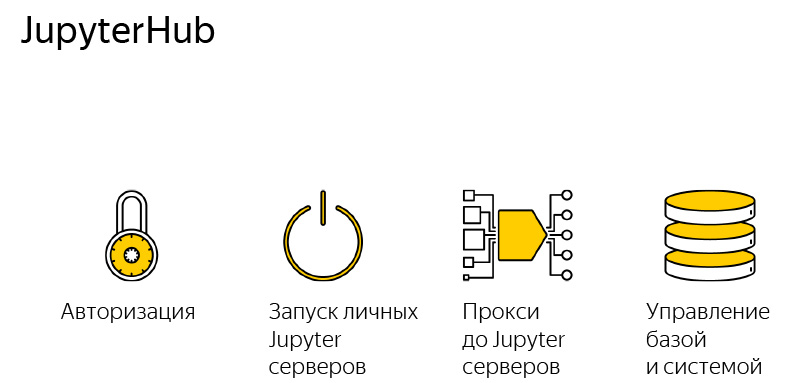
This is a very simple application, it consists of four components, just shared.
The first part of the application is responsible for authorization. We need to check the password and login, whether we can let this person.
The second is the launch of Jupyter servers, each user runs the very familiar Jupyter server that can run Jupyter laptops. What is happening on your computer, only in the cloud, if it is a cloud deployment, or different processes are spun on the same machine.
Proxy There is a single point of access to the entire server, and JupyterHub determines which user to which port to go to, everything is absolutely transparent for the user. Naturally, some DB management and the entire system.
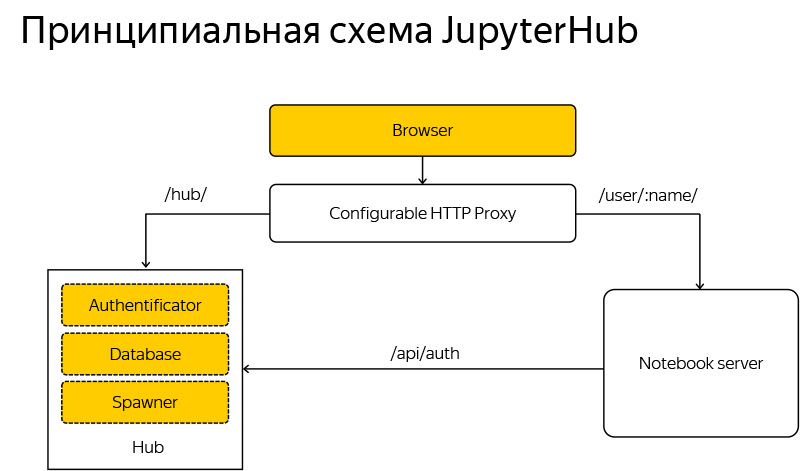
If it is superficial to describe how JupyterHub looks like, the user browser comes to the JupyterHub system, and if this user has not yet started the server or is not authorized. JupyterHub enters the game and starts asking some questions, creating servers and preparing the environment.
If the user is already logged in, then they directly proxy them to their own server, and the Jupyter laptop actually communicates directly with the person, sometimes asking the server about access, whether this user is allowed to access this laptop, etc.
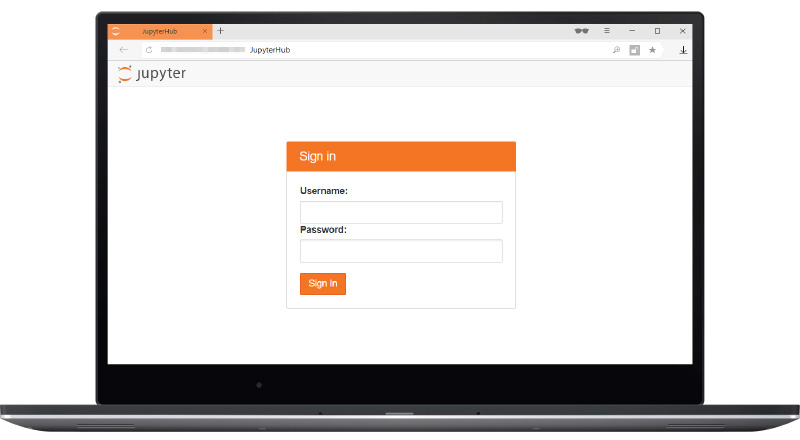
The interface is quite simple and convenient. By default, the deployment uses the username and password of the computer where it is deployed. If you have a server where there are several users, then the login and password is the login and password to the system, and the user sees his / home directory as his home directory. Very convenient, no need to think about any users.
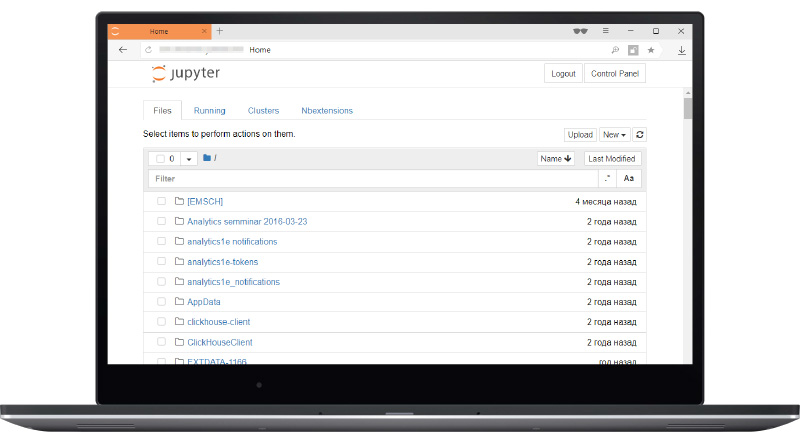
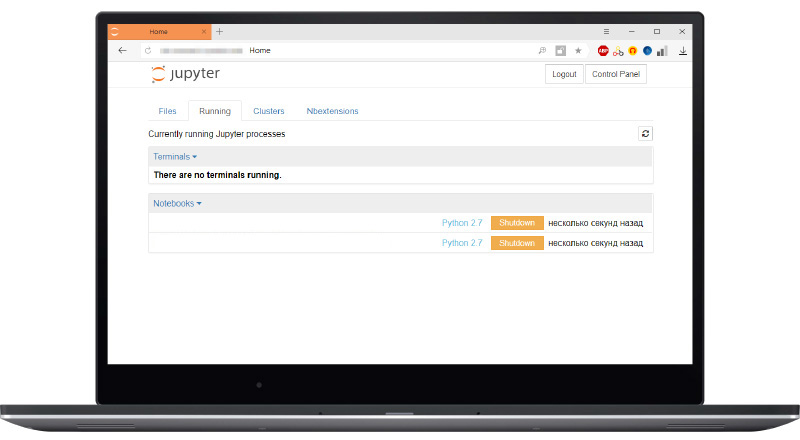
The rest of the interfaces are generally quite familiar to you. These are the standard Jupyter laptops that you have all seen. You can see the active laptops.

This thing you probably have not seen. This is the JupyterHub management window, you can turn off your server, start it or, for example, get a token to communicate on your behalf with JupyterHub, for example, to run some microservices inside JupyterHub.
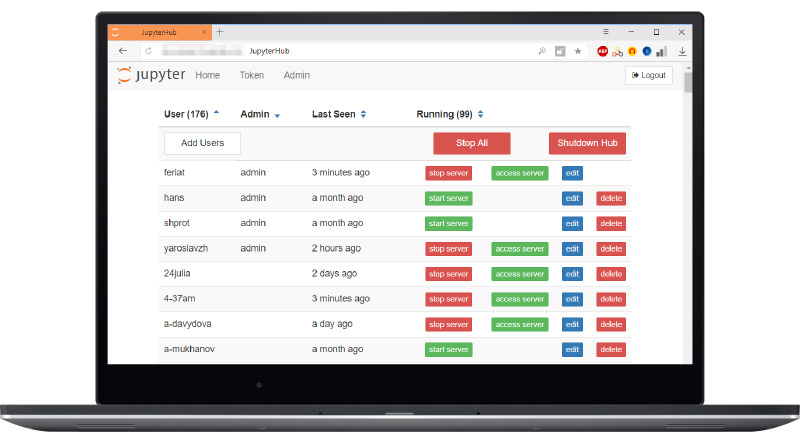
Finally, the administrator can manage each user, start individual Jupyter servers, stop them, add, delete users, shut down all servers, shut down, turn on the hub. All this is done in the browser without any settings and is quite convenient.
In general, the system is developing very strongly.

In the picture, the UC Berkley course, which ended this December, was the largest data science course in the world, in my opinion, 1,200 students who couldn’t program, and came to learn programming. This was done on the JupyterHub platform, students did not need to install any Python on their computer, they could just go to the browser on this server.
Naturally, with further stages of learning, the need to install packages appeared, but this famously solves the problem of the first entry. When you teach Python, and the person is not familiar with it at all, quite often you realize that some routines associated with installing packages, maintaining some kind of system, and the like, are a bit superfluous. You want to inspire a person, to tell about this world, without going into details that a person can master in the future.
Installation:
Python 3 is supported exclusively, inside JupyterHub you can run cells in the second Python, but the JupyterHub itself only works on the third. The only dependency is this configurable-http-proxy, which is what is used in Python for simplification.
Configuration:
The first thing you want to do is generate a config. Everything will work itself, even without any settings, by default the local server will be raised with some port 8000, with access to your users by login and password, it will work only under trial, it will work out of the box, but generate-config will create a JupyterHub config file for you, where you can read absolutely all of its settings in the form of documentation. This is very convenient, you can even without going into the documentation, to understand which lines you need to include, everything is commented out, you can manage, all the default settings are visible.

I want to make some kind of pause and reservation. By default, when you deploy this, you will deploy it on your own server, and if you don’t make any effort, and you don’t use HTTPS, the server will rise via HTTP, and your passwords and user logins will will enter, will be in open form to glow when communicating with JupyterHub. This is a very dangerous story, an incredible amount of problems can be stalled here. Therefore, do not ignore the problem with HTTPS. If you do not have your own HTTPS certificate, you can create it, or you have the wonderful service letsencrypt.org, which allows you to get certificates for free, and you can run on your domain without problems and without money. This is quite convenient, do not ignore it.
By default, the hub runs as root, obviously, it spawns its own laptops from a specific user. This can be changed, but by default it is. And all users are local, home directory prokibyvaetsya for each specific user. I will tell you more about what can be done.
JupyterHub’s classiness is that it’s such a constructor. Literally, in each element of the diagram that I showed, you can insert, embed your own elements that simplify the work. For example, suppose you do not want your users to drive in a username and password system, this is not very safe or inconvenient. You want to make another login system. This can be done using oauth and, for example, github.

Instead of forcing the user to enter a username and password, you simply turn on authorization with the help of two lines of code with the githabb and the user will automatically log in with the githabb, and will be localized through the github username.

Other user authorization methods are supported out of the box. If you have LDAP, you can. Any OAuth is possible, there is a REMOTE_USER Authenticator, allowing remote servers to check access to your local. Anything you want.

Suppose you have several types of tasks. For example, one uses a GPU, and for this you need one technology stack, a specific set of packages, and you want to separate it from the CPU with a different usage scenario. To do this, you can write your own spawner. This is the system that creates custom Jupyter laptops. Here is the tincture with Docker, you can collect a Docker file that will be deployed for each user, and the user will not be local, but in his internal container.
There are a number of other convenient JupyterHub features, services.

Suppose you run on some machine where there is a limited amount of memory, and you want to save your resources and disconnect this user through the time after the user is not in the system, because he does not use them, but takes up memory. Or, for example, you have a cloud deployment, and you can save money on virtual machines by turning off the unused at night, and turn them on only when needed.
There is a ready-made cull_idle_servers service that allows you to shut down any user servers after inactivity. All data will be saved, resources will not be used, you will be able to save a little.
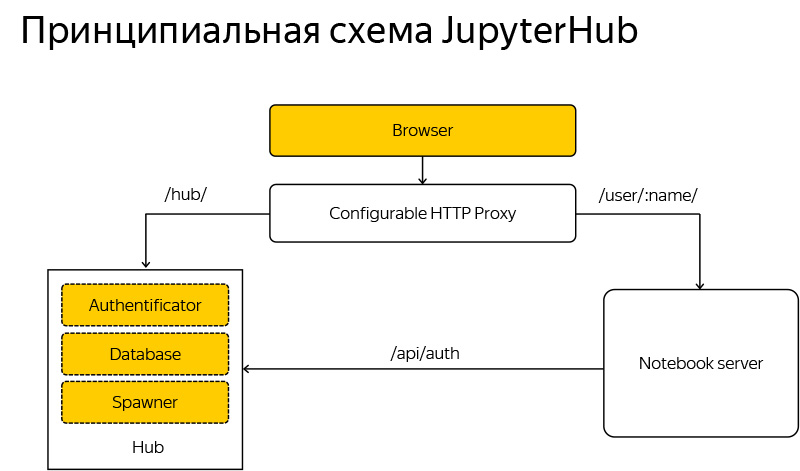
I said that literally every piece of this scheme can include something different. You can make some addon to the proxy, in some way to do prokidyvanie users. You can write your own authorizer, you can directly communicate with the database using services. You can create your own spuner.
I would like to recommend such a project, a system on top of Kubernetes, which allows everything that I have told, to be directly deployed in any supporting Kerbernate cloud, literally without any specific settings. This is very convenient if you do not want to bother with your own server, devops and support. Everything will work out of the box, a very good detailed guide.

You need JupyterHub in case you have several people using Jupyter. And it is not necessary that they use Jupyter for the same thing. This is a convenient system that will allow these people to unite and avoid further problems. And if they, moreover, do the same task - most likely, they will need a more or less consistent set of packages.
The same is true if you receive complaints that my model is remarkably well built, some analyst Vasechkin tries to reproduce it and it does not work. At one time we had a constant problem. And of course, a consistent server state helps a lot with this.
Very cool to use this for learning Python. There is a nbgrader service that, on top of JupyterHub, allows you to make convenient batteries by sending homework to students. They fill in the solutions themselves, send them back, there is an automatic test that checks the Jupyter cells and allows you to immediately give marks. Very convenient system, I recommend.
Imagine that you came to a seminar where you want to show something in Python. In this case, you do not want to spend the first three hours to ensure that everything will work from your how to. You want to start doing something interesting right away.
You can raise such a system on your server, provide users with your Internet address, where you can log in, and start using, not waste time on unnecessary routines. That's all, thank you.
My name is Andrei Petrin, I am the head of the growth analyst group at Yandex. In a report at the Moscow Python Meetup, I recalled the advantages of Jupyter and spoke about the architecture and principles of JupyterHub, as well as about the experience of using these systems in Yandex. At the end you will learn how to raise JupyterHub on any computer.
- To begin with, who are analysts in Yandex. There is an analogy that this is such a many-handed Shiva who can do many different things at once and combines many roles.
')
Hello! My name is Andrei Petrin, I am the head of the growth analyst group at Yandex. I will talk about the JupyterHub library, which at one time greatly simplified our lives in Yandex analytics, we literally felt the productivity boost of a large number of teams.
For example, analysts at Yandex are a little bit managers. Analysts always know the timeline, timeline of the process, what is the moment to do.
This is a little bit of developers, they are familiar with different ways of processing data. For example, on the slide in Shiva’s hands, those Python libraries that come to my mind are not a complete list, but something that is used on a daily basis. Naturally, we are developing not only in Python, but I will talk primarily about Python.
Analysts - a little bit of mathematics, we need to make decisions carefully, look at the real data, not at the managerial point of view, but look for some truth and understand this.
In this whole task, the Jupyter ecosystem helps us quite a lot.
This is such a platform for interactive programming and creating laptop reports. The key essence of Jupyter laptops is such a laptop, where there are a large variety of widgets, interactive elements that can be changed. As the main entity - microelements of the code that you program. They can be printed in a laptop in your browser, which you constantly use. It can be both pictures and interactive HTML-derived elements. You can simply print, print, display items - a variety of things.
The Jupyter system has been developing for a long time, it supports various programming languages of various versions, Python 2 and 3, Go, various things. Allows you to cool to solve our everyday tasks.
What do we do in analytics and how does Jupyter help us a lot with this?
The first task is the classification of websites. It turns out that for big Yandex, who knows about the entire Internet, it is quite laborious to look at specific sites. We have such a number of sites, each of which can have its own specifics, that we need to aggregate this to some topics - groups of sites that are not very large, which generally behave similarly.
For this task, we build the adjacency graph of all Internet hosts, the graph of the similarity of the two sites to each other. With the help of manual markup of hosts, we get some primary base on what sites on the Internet are there, and further we extrapolate manual markup to the entire Internet. Literally in each of the tasks we use Jupyter. From the point of view of constructing an adjacency graph, it allows one to constantly launch operations on MapReduce, to construct such graphs, to carry out such data analytics.
We automated the manual layout in Jupyter with the help of widgets. We have for each host the intended subject, which is likely correct. We almost always guess topics, but for manual marking people still need.
And you get all sorts of interesting pictures.
For example, it shows sports websites and related search queries that are present in sports topics.
Subject encyclopedias. Sites and generally unique requests are smaller, but more basic requests.
Subject homework - finished homework. Interesting enough, because inside it there are two independent clusters of sites that are similar to each other, but not similar to the others. This is a good example of topics that I would like to break into two. One half of the sites clearly solves one problem within the homework, the other - the other.
It was quite interesting to do a bid optimizer, a completely different puzzle. In Yandex, a certain number of mobile applications are purchased, including for money, and we already know how to predict the user's lifetime, how much we can get from installing some kind of application for each user, but it turns out that unfortunately, this knowledge is difficult to convey to the marketer, Executive who will be engaged in the purchase of traffic. This is usually due to the fact that there is always a budget, there is a rather large number of restrictions. It is necessary to do this multidimensional optimization task, which is interesting from the point of view of analytics, but you need to make a device for the manager.
Jupyter helps a lot here. This is the interface that we developed in Jupyter so that a user manager who does not have knowledge of Python can log in and get the result of our prediction. You can choose there whether we choose Android or iOS, on which countries, which application. There are quite complex controllers and handles that can be changed, for example, some progress bars, budget size, some kind of risk tolerance. These tasks are solved with the help of Jupyter, and we are very pleased that the analyst, being a multi-armed Shiva, can solve these problems alone.
About five years ago we came to the conclusion that there are some limitations and problems of the platform with which I want to fight. The first problem is that we have a lot of different analysts, each of which is always on different versions, operating systems, etc. Often, the code that works for one person does not run for another.
Another big problem is the package versions. I think it’s not necessary to tell how hard it is to maintain some consistent environment so that everything can start out of the box.
And in general, we began to understand that if you provide a new analyst who just came to the team in a pre-configured environment where everything will be set up, all packages are delivered to the current version and mainframe in a single place, it is as good for analytical work as and for development. In general, the thought is slim for the developer, but it is not always applicable to the analyst because of the constant changes in the analytics that are occurring.
This is where the JupyterHub library came to our rescue.
This is a very simple application, it consists of four components, just shared.
The first part of the application is responsible for authorization. We need to check the password and login, whether we can let this person.
The second is the launch of Jupyter servers, each user runs the very familiar Jupyter server that can run Jupyter laptops. What is happening on your computer, only in the cloud, if it is a cloud deployment, or different processes are spun on the same machine.
Proxy There is a single point of access to the entire server, and JupyterHub determines which user to which port to go to, everything is absolutely transparent for the user. Naturally, some DB management and the entire system.
If it is superficial to describe how JupyterHub looks like, the user browser comes to the JupyterHub system, and if this user has not yet started the server or is not authorized. JupyterHub enters the game and starts asking some questions, creating servers and preparing the environment.
If the user is already logged in, then they directly proxy them to their own server, and the Jupyter laptop actually communicates directly with the person, sometimes asking the server about access, whether this user is allowed to access this laptop, etc.
The interface is quite simple and convenient. By default, the deployment uses the username and password of the computer where it is deployed. If you have a server where there are several users, then the login and password is the login and password to the system, and the user sees his / home directory as his home directory. Very convenient, no need to think about any users.
The rest of the interfaces are generally quite familiar to you. These are the standard Jupyter laptops that you have all seen. You can see the active laptops.
This thing you probably have not seen. This is the JupyterHub management window, you can turn off your server, start it or, for example, get a token to communicate on your behalf with JupyterHub, for example, to run some microservices inside JupyterHub.
Finally, the administrator can manage each user, start individual Jupyter servers, stop them, add, delete users, shut down all servers, shut down, turn on the hub. All this is done in the browser without any settings and is quite convenient.
In general, the system is developing very strongly.
In the picture, the UC Berkley course, which ended this December, was the largest data science course in the world, in my opinion, 1,200 students who couldn’t program, and came to learn programming. This was done on the JupyterHub platform, students did not need to install any Python on their computer, they could just go to the browser on this server.
Naturally, with further stages of learning, the need to install packages appeared, but this famously solves the problem of the first entry. When you teach Python, and the person is not familiar with it at all, quite often you realize that some routines associated with installing packages, maintaining some kind of system, and the like, are a bit superfluous. You want to inspire a person, to tell about this world, without going into details that a person can master in the future.
Installation:
python3 -m pip install jupyterhub sudo apt-get install npm nodejs-legacy npm install -g configurable-http-proxy Python 3 is supported exclusively, inside JupyterHub you can run cells in the second Python, but the JupyterHub itself only works on the third. The only dependency is this configurable-http-proxy, which is what is used in Python for simplification.
Configuration:
jupyterhub --generate-config The first thing you want to do is generate a config. Everything will work itself, even without any settings, by default the local server will be raised with some port 8000, with access to your users by login and password, it will work only under trial, it will work out of the box, but generate-config will create a JupyterHub config file for you, where you can read absolutely all of its settings in the form of documentation. This is very convenient, you can even without going into the documentation, to understand which lines you need to include, everything is commented out, you can manage, all the default settings are visible.
I want to make some kind of pause and reservation. By default, when you deploy this, you will deploy it on your own server, and if you don’t make any effort, and you don’t use HTTPS, the server will rise via HTTP, and your passwords and user logins will will enter, will be in open form to glow when communicating with JupyterHub. This is a very dangerous story, an incredible amount of problems can be stalled here. Therefore, do not ignore the problem with HTTPS. If you do not have your own HTTPS certificate, you can create it, or you have the wonderful service letsencrypt.org, which allows you to get certificates for free, and you can run on your domain without problems and without money. This is quite convenient, do not ignore it.
By default, the hub runs as root, obviously, it spawns its own laptops from a specific user. This can be changed, but by default it is. And all users are local, home directory prokibyvaetsya for each specific user. I will tell you more about what can be done.
JupyterHub’s classiness is that it’s such a constructor. Literally, in each element of the diagram that I showed, you can insert, embed your own elements that simplify the work. For example, suppose you do not want your users to drive in a username and password system, this is not very safe or inconvenient. You want to make another login system. This can be done using oauth and, for example, github.
Instead of forcing the user to enter a username and password, you simply turn on authorization with the help of two lines of code with the githabb and the user will automatically log in with the githabb, and will be localized through the github username.
Other user authorization methods are supported out of the box. If you have LDAP, you can. Any OAuth is possible, there is a REMOTE_USER Authenticator, allowing remote servers to check access to your local. Anything you want.
Suppose you have several types of tasks. For example, one uses a GPU, and for this you need one technology stack, a specific set of packages, and you want to separate it from the CPU with a different usage scenario. To do this, you can write your own spawner. This is the system that creates custom Jupyter laptops. Here is the tincture with Docker, you can collect a Docker file that will be deployed for each user, and the user will not be local, but in his internal container.
There are a number of other convenient JupyterHub features, services.
Suppose you run on some machine where there is a limited amount of memory, and you want to save your resources and disconnect this user through the time after the user is not in the system, because he does not use them, but takes up memory. Or, for example, you have a cloud deployment, and you can save money on virtual machines by turning off the unused at night, and turn them on only when needed.
There is a ready-made cull_idle_servers service that allows you to shut down any user servers after inactivity. All data will be saved, resources will not be used, you will be able to save a little.
I said that literally every piece of this scheme can include something different. You can make some addon to the proxy, in some way to do prokidyvanie users. You can write your own authorizer, you can directly communicate with the database using services. You can create your own spuner.
I would like to recommend such a project, a system on top of Kubernetes, which allows everything that I have told, to be directly deployed in any supporting Kerbernate cloud, literally without any specific settings. This is very convenient if you do not want to bother with your own server, devops and support. Everything will work out of the box, a very good detailed guide.
You need JupyterHub in case you have several people using Jupyter. And it is not necessary that they use Jupyter for the same thing. This is a convenient system that will allow these people to unite and avoid further problems. And if they, moreover, do the same task - most likely, they will need a more or less consistent set of packages.
The same is true if you receive complaints that my model is remarkably well built, some analyst Vasechkin tries to reproduce it and it does not work. At one time we had a constant problem. And of course, a consistent server state helps a lot with this.
Very cool to use this for learning Python. There is a nbgrader service that, on top of JupyterHub, allows you to make convenient batteries by sending homework to students. They fill in the solutions themselves, send them back, there is an automatic test that checks the Jupyter cells and allows you to immediately give marks. Very convenient system, I recommend.
Imagine that you came to a seminar where you want to show something in Python. In this case, you do not want to spend the first three hours to ensure that everything will work from your how to. You want to start doing something interesting right away.
You can raise such a system on your server, provide users with your Internet address, where you can log in, and start using, not waste time on unnecessary routines. That's all, thank you.
Source: https://habr.com/ru/post/353546/
All Articles