Code generation during application operation: real examples and techniques
Code generation in runtime is a very powerful and well-studied technique, but many developers are still reluctant to use it. Usually the study of Expression Trees begins with some simple example of how to create a predicate (filter) or a mathematical expression. But not a Expression Trees single .NET developer is alive. Most recently, it was possible to generate code using the compiler itself — this is done using the Roslyn / CodeAnalisys library APIs, which, among other things, also provide parsing, crawling, and source generation.
This article is based on the Raffaele Rialdi report (Twitter: @raffaeler ) at the DotNext 2017 Moscow conference. Together with Raphael, we will analyze the real ways of using code generation. In some cases, they allow to greatly improve the performance of the application, which in turn leads us to a dilemma - if the generated code is so useful and we are going to use it often, how can we debug this code? This is one of the fundamental questions that arise in real projects.
Rafael is a practicing architect, consultant and speaker with MVP in the Developer Security category since 2003, which right now has been involved in enterprise project backends, specializing in code generation and cross-platform development for C # and C ++.
What is code generation? Suppose you need to demonstrate performance. If you just show a benchmark - it would be a kind of trick, a cunning trick. Articles and reports should avoid showing benchmarks - not because it is dangerous for the author, but because the benchmark demonstrates only one scenario, and it is hardly useful to all readers. The reader is forced to try the proposed technologies and decide whether or not they are suitable for his particular scenarios. Therefore, do not exaggerate the value of benchmarks. For myself, I make them, they show decent results.
We know that a reflection program will by definition be slow. She needs to download the ECMA-335 metadata and interpret it. They are a very compact set of binary data, their reading is quite complicated. They should be compact because they should not take up too much memory after assembly. After these artifacts are deployed, performance is unsatisfactory because we are dealing with a very low-level API. By the way, reflection can be avoided by downloading all these artifacts directly from the assemblies. I will not speak about this in today's report, but, if you are interested, I have already used this method to avoid constant loading and assembly in memory; you can free up memory from everything except type information.
When exactly should the code be generated? On that part of the application life cycle, when there is enough information to simplify the algorithm. It is, for example, about information that can be obtained from the user interface for a filter that would reduce the number of records obtained from the database. Or information about the types loaded in the plugin. It is extremely undesirable to spend time on creating with the help of reflection a general algorithm that would take into account all possible options. Unfortunately, developers have a tendency to try to make the solutions they develop as general as possible, working in all possible and impossible cases. For our programming mind, this is a natural train of thought. I suggest exactly the opposite approach: patiently wait until there is enough information to generate the most concise code.
In which cases it may be necessary to generate code? For example, when using LINQ predicates. Predicate builders have been available for a long time. Or using formulas from, say, Excel. Either when loading types from a plugin, or using Reactive Extensions. Which of you is familiar with Reactive Extensions? This is a great library that allows you to create data streams and use expressions that can filter groups and change this data. I will show many of these examples to demonstrate the possibilities of reflection.

Let's start with Expression in C #. The screen shows a simple example of code in which a call to Console.WriteLine generated. Perhaps someone will ask - why use reflection if you have just pointed out the disadvantages of using reflection? The answer is not to abandon reflection in general, but to remove it from the most used sections of the code. You need to find a point in time at which, using reflection, you can extract the required amount of data, generate code and, for example, use delegation within the loop, so as not to wait until the code is executed.
In the code, I start by getting an exact WriteLine overload, then I create a parameter that will later become an input message. After that, I create the equivalent of the Call method. In a call to Expression.Call(null, methodInfo, message) , null denotes a static method ( WriteLine is a static method). In addition, this call also requires arguments with information about the method, and with the message.
After this is created lambda. It's very simple, you need to specify the parameters and the body of the lambda. A very useful .Compile() method is called on an already created lambda. It is good in that it directly and in a very simple way creates instruction in memory. There is no source code, there is nothing that would need to be processed in the ways described in the "Dragon Book". There is no first stage of compilation, that is, a long and complex analysis of the text. It is not needed, because in the case of Expression, we already know that it is syntactically correct. It is very important. That is why the expression tree is so bulky, it has an extremely unpleasant strict typification. If you have once tried to make several expressions with each other, you know what a jerk it is. But having a formed expression, it can really be compiled. The compiler simply takes the nodes of the tree (that is, certain expressions), and creates the corresponding node for the code we want to call. Ultimately, we form a delegate, that is, the fastest available means for executing code.

I will show an example in which the predicate will be created. A very simple function that takes an integer as an input and returns a boolean value. Let's look at its code. For the first input value, a parameter is created there: Expression.Parameter(typeof(int), "x") . One of the input arguments of this method is "x" , do not pay attention to it, it is needed only for debugging. The variable left denotes the left part of the expression x > -10 , right - the right. From these two variables, a binary comparison expression is created. Finally, the Lambda expression is returned. In this case, this is preferable to returning the delegate, since, if necessary, it will be possible to make changes to it. To do this, you can use the Visitor pattern, which enumerates all the nodes within the expression, and changes it in a very precise way. No work with the text is needed, the transition to the necessary node occurs immediately.

I will give an example in which it is necessary to attend some challenge. Suppose there is a retrieval of predicates from the where node, since the code is written in LINQ. Having the necessary Expression, you can write Visitor to it. And you can find this Expression, because where is a call to an extension method. The first where parameter is IQueryable<T> , and returns a boolean value. So we know exactly what form we need. If you need to add something to this Expression, you can do it at the place where the dots are written on the screen.
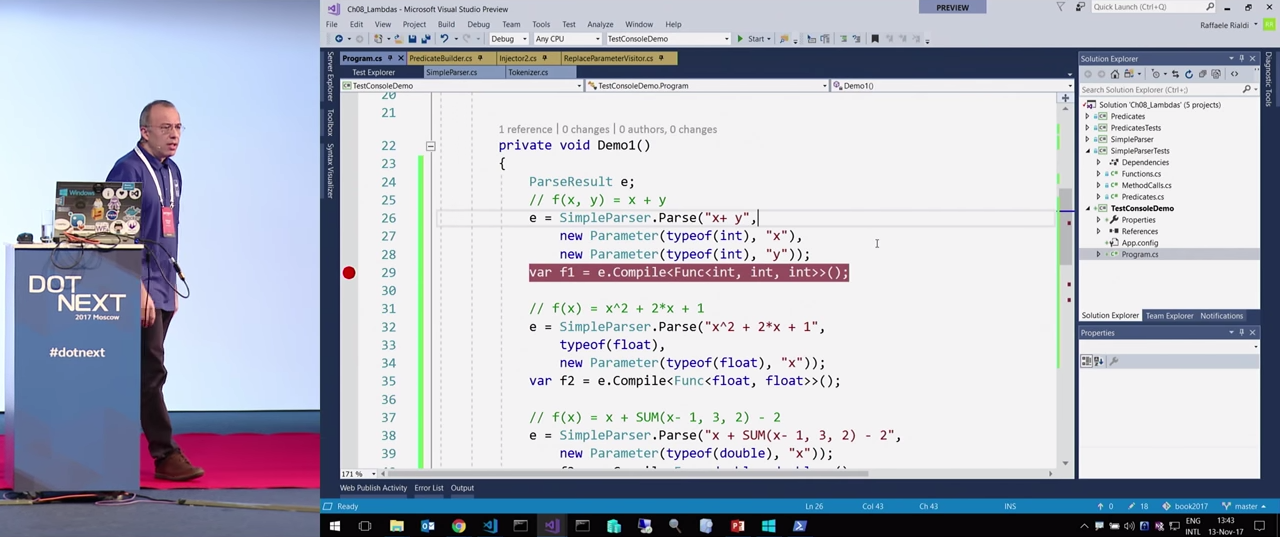
In order not to get bored, let's move on to the demonstrations. Initially, I did not want to write a tool for parsing, because it’s boring, such a program usually turns out slow, and there are libraries that perform this task better than self-written code. I needed something small and easily changeable. And when writing parsing tools you come to the fact that you need to write grammar, you have to use a lot of libraries. In addition, I wanted to write a tool in such a way that the nodes created after the analysis were similar to what Expressions actually express. In the end, I came to represent, for example, the expression x + y (which you see in the code) in the form of a text, and then recognize it.
That is, I tried to express the parameters manually. I did it for simplicity, and perhaps this can be avoided. At the very least, it is important to specify the types, since Expression cannot use the first stage of compilation. For example, automatic type conversion or implicit type conversion is not available, integer to double conversion is not available. All this has to be done manually.
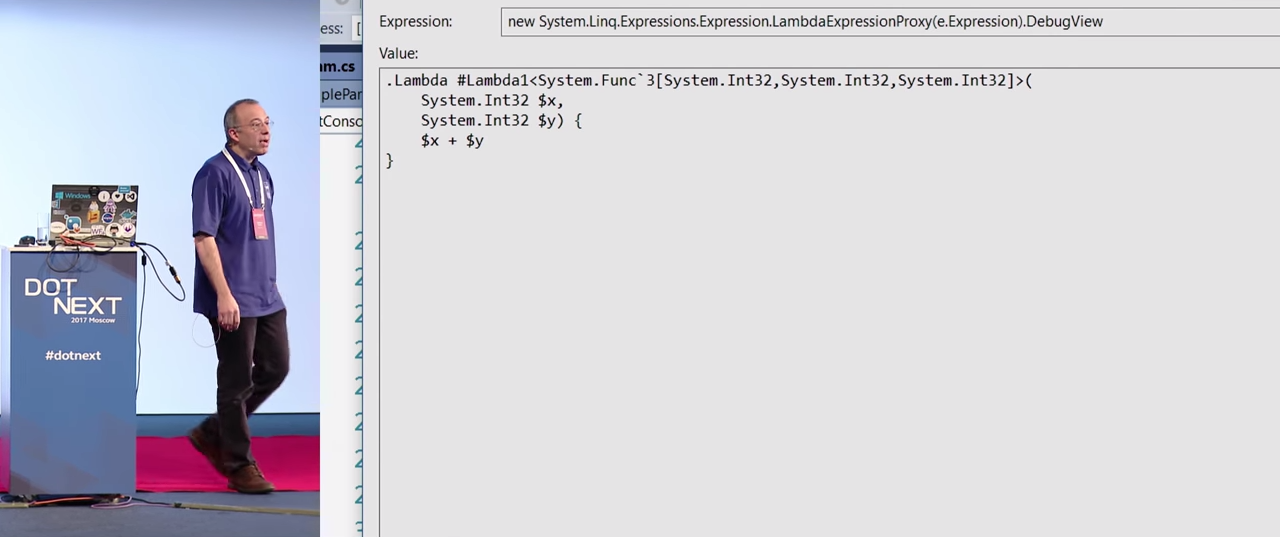
If you run the code that you see on the screen in the debugger, it will return an Expression. Lambda is presented in the Visual Studio debugger in a rather strange way, but that's okay. It looks difficult, but in the end, it's just x + y , you can live with it.

Let's see how you can translate the SUM() function written by me in text. The text visualizer shows us the variable e , which currently contains the result of the translation. You can see that I defined FunctionsHelper with a predefined function, just like Excel does. Such applications should predetermine a sort of dictionary of functions. All this is quite simple.
Let's try to go a little further in the code. There is a GetFilter() function.
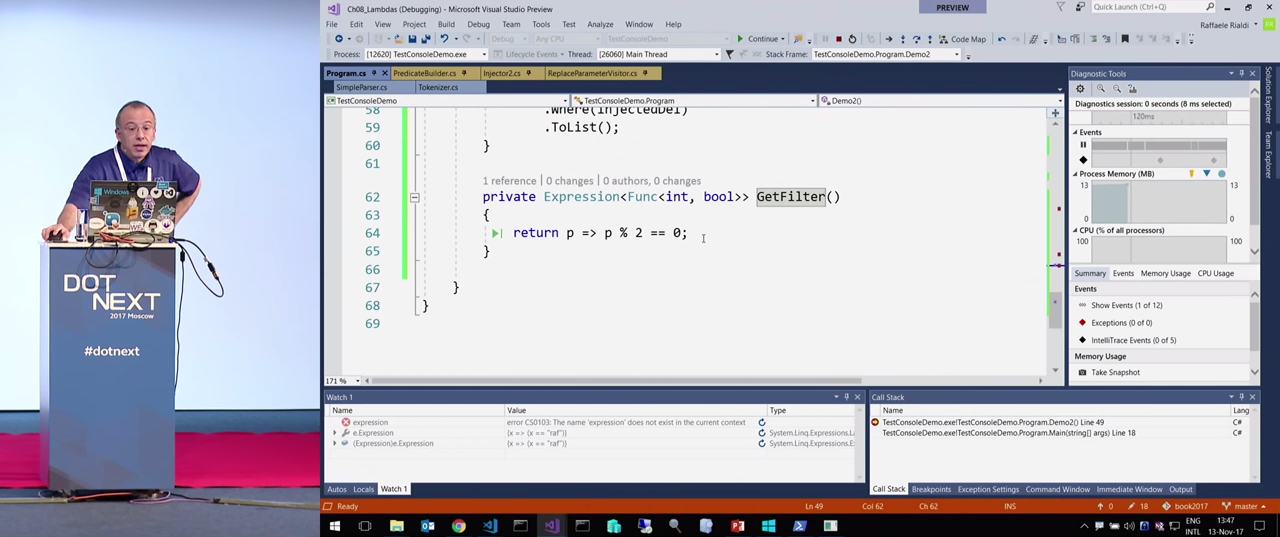
As you can see, it is lambda. Usually in such cases, it returns Func<int, bool> and nothing else. But the compiler has a special feature, which allows, in the absence of square brackets in the function body, to return Expression<Func<int, bool>> . That is, an Expression is automatically created for this view. This is very convenient because it can still be changed. If you want to remove the number and replace it with something else, you can simply write Visitor to express it and make all the necessary changes with it.

Let's look at the second demonstration. In it, from the very beginning, we have the Expression<Func<int, bool>> predicate .
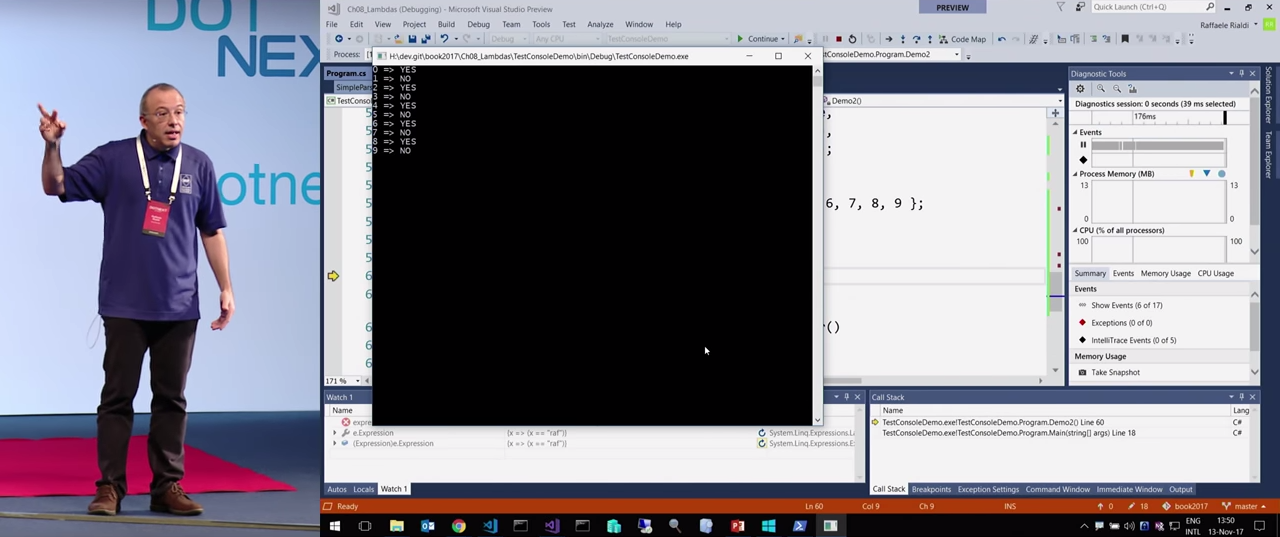
I want to make an injection into it that would output to the command line. I pass predicates and two lambdas to the injector and, when receiving the value of x indicate to output {x} => YES or {x} => NO each time. If we look at how the injected variable injected after the application starts, we will see a function with the If operator, it has been changed quite a lot compared to its initial value.

So, here an integer is fed into the input, If is injected, YES or NO is output to the console depending on the value, and finally the value returned by the expression is returned. This kind of code changes have already been put into practice, and they are very powerful.
There is a problem that you probably already noticed - the visualizer, in which I showed you the generated code so far, presents information in a rather strange form. Programming with expressions gives certain advantages, but from the point of view of the developer, the code is “dirty”.
Let's return to the demonstration. I have already spoken about deferred execution: until the enumeration of numbers is completed, the following code will not be executed. If we reach toList right now, we will get both the list and Console.WriteLine for them, which in this case will be executed automatically.

It all looks good, but I want to try something more complicated. The following example came to me in a dream. I want to create a lambda, which, when compiled, converts the data in a dictionary (possibly JSON) in a specific order. The task is quite ordinary.
If you execute this code with the help of reflection, the result will be the one that you now see on the screen.

There is an iteration on the properties of the display, the search for a match in the dictionary for each property and copying. Obviously, this code will be slow. If it is executed only once, this is not a problem, but if it needs to be performed a million times - well, you understand. If this happens in a server application that consumes server resources, someone might not like it.
Let's try to solve this problem in another way. Here the code creates an object `Order, the elements of which will be matched with the incoming dictionary.
Values are extracted from the dictionary, then they are reduced to the required type, copied, and this is all completely creepy and boring.
But what if I create a lambda that already knows the Order object?

It is important that I specify the type of this object. Notice that I do not use <Order> . That would be great, but what if we don't know this type? What if Order is defined in a deferred plugin? In some cases, generics can help, but in this case, their use would be undesirable because we may need to abstract from this information.
So, look at our lambda after compilation.

Is she really good? Code nice to read. It was generated using Expressions. Let's look at how they are written in the ExpressionGeneration class.

We see that the code is similar to what I wrote with the help of reflection. It is determined by Expression.Parameter() , the result variable is defined, a new newEntityType is created using Activator.CreateInstance , a new instance is assigned to the assign variable. Everything is very boring. Then I get the method through type.getMethod() and then entityProps around the entityProps properties.
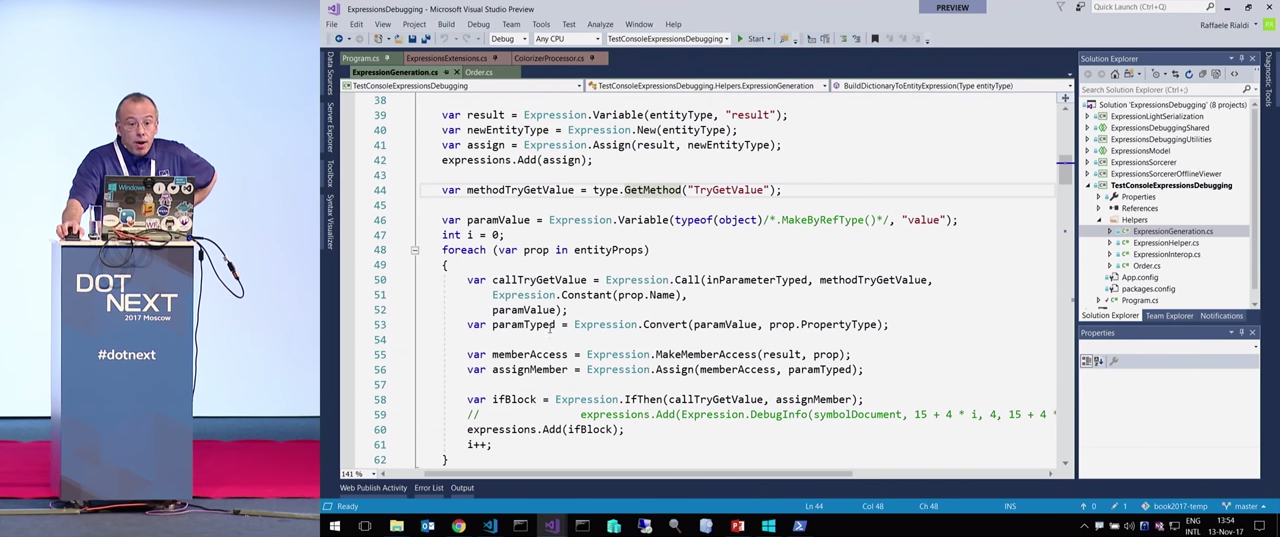
In this case, it is not necessary to create a cycle, since we know how many properties there will be. Thus, exactly those calls are generated here that are needed to extract the necessary value for callTryGetValue .

The next line calls the Expression.Convert() method, it needs to be cast to the type, since the types can be different. Next, to access the property, a call is made to Expression.MakeMemberAccess() . After that, a call is made to Expression.IfThen() for the try-catch construct. Finally, a block is created, that is, an opening and closing parenthesis. And as a result, we get lambda.
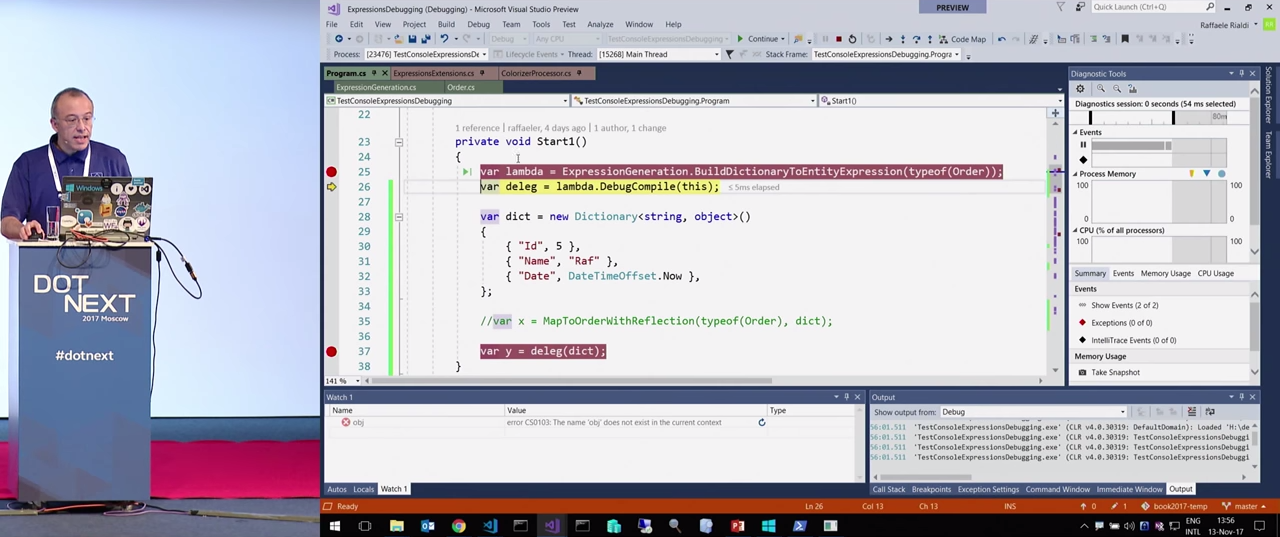
I wrote the ExpressionsSorcerer tool. You can take its code and place it in the %USERPROFILE%/Visual Studio 2017/Visualizers directory, and start debugging the code just discussed again. This time I can see the lambda through the visualizer, it will be presented in the form of a tree.
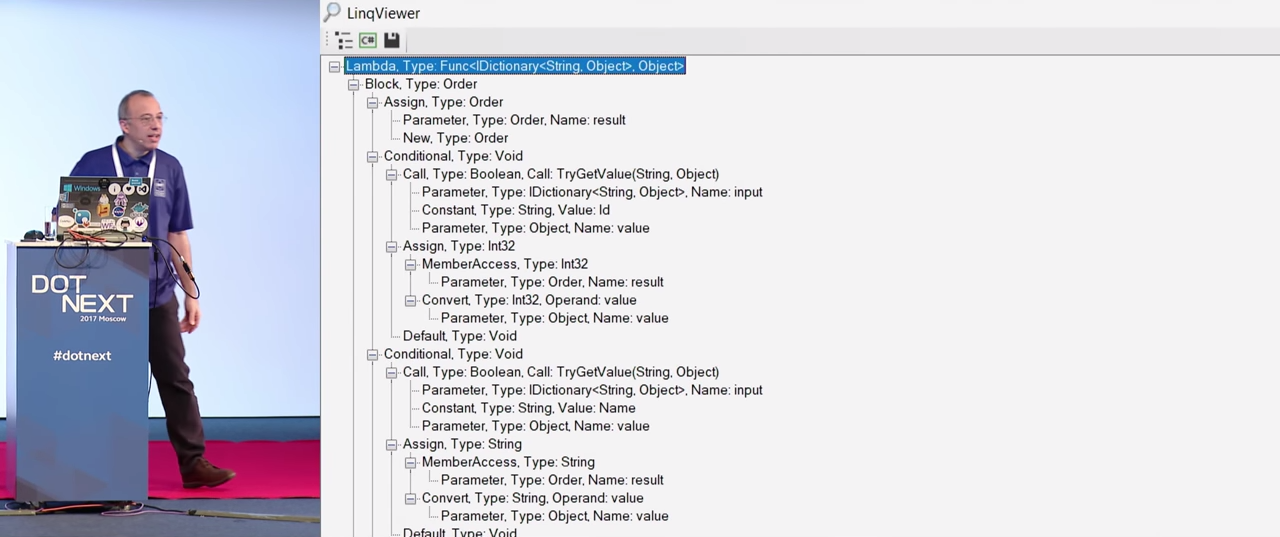
This kind of operation can be very useful, it helps to think, and what the hell am I writing here? When you select a separate tree node in the window on the right, properties and their values appear, which is very convenient. Open the “Show the decompiled source” tab. Before us is a code that I would write if I had the information that was passed to the code generator.

But I did not touch the code with this finger. I did not even generate a C # code. I wrote Expressions, i.e. there were only syntax nodes in memory, and I needed to decompile. Thanks to Roslyn, there is also a color marking here, if necessary, it can be changed. In addition, I added the DebuggableAttribute attribute, since I do not need optimizations that may arise during compilation. You might ask, why don't I need them? And in response, I will have another surprise for you.
If we compile with debugging (by pressing "F11"), we will enter the automatically generated method, which we did not write with our own hands. Impressive, isn't it? Here you can see the current values of the variables, you can check if there are any errors in Expressions. As you can see, the Description value in the input argument was not, so the TryGetValue method was used for a reason.

At the end of the function in question, we get the order variable with the correct number of values.
Summarize the interim. Expressions cover almost the entire language, with the help of them you can generate if , throw , catch , you can create complex structures. But for this, most likely, you will need a special tool. In my tool, the most difficult part to write was implicit type conversions. If you create a double x variable, and try to assign its value to a variable with integer type, you will get an InvalidCastException exception. The reason is that the implicit conversion is performed by the compiler, but we did not have it. So we had to do some things that the compiler usually does.
Let me demonstrate some more complex expressions. On the screen is a code in which a very simple object is created var newObject = ExpressionInterop.BuildNewObject(ctor) .

If you look at it in the renderer, you will see how to create a new object new Order() .
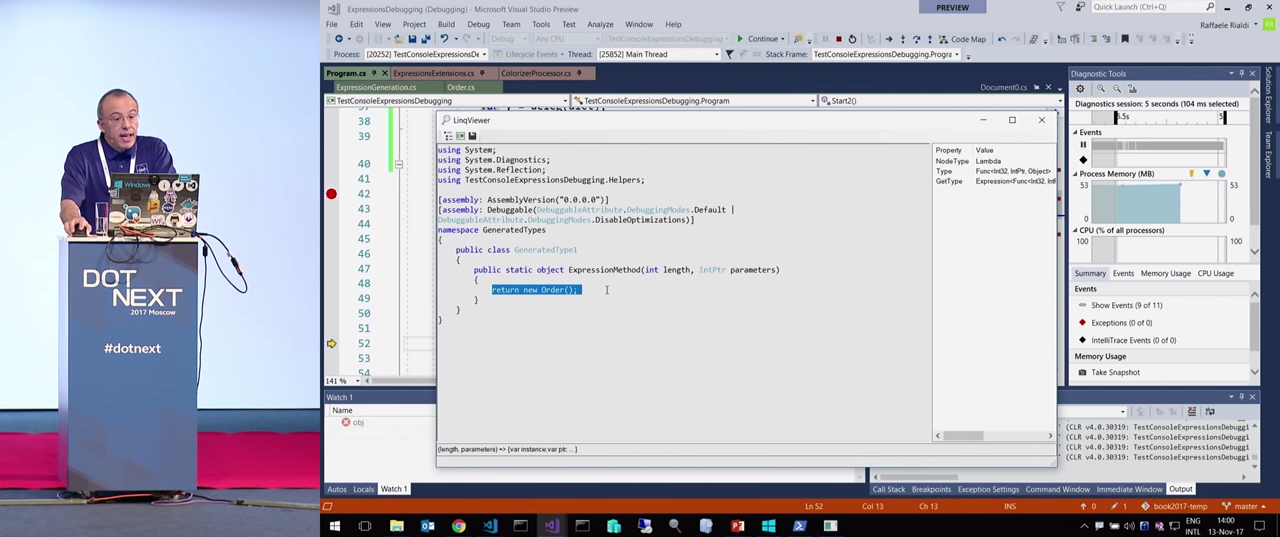
For the reasons already mentioned, I always recommend using the typeof() method. Next, through the GetConstructor method GetConstructor I get the constructor I need, and then through the GetMethod methods, the desired methods. After this, a new object is created to which information about the constructor is passed: ExpressionInterop.BuildNewObject(ctor) . And so on.
I will not elaborate on this. But I would like to show you what the expression looks like when you assign a value to a property ...
Here are the compilation artifacts:


But if we go back to this Expression, it looks quite confusing. One of the most complex Expressions created by me is used for marshaling. I generated code that allows me to execute asynchronous code for AddAsync ...

... even if there is no code in the expression that could represent Task<T> .
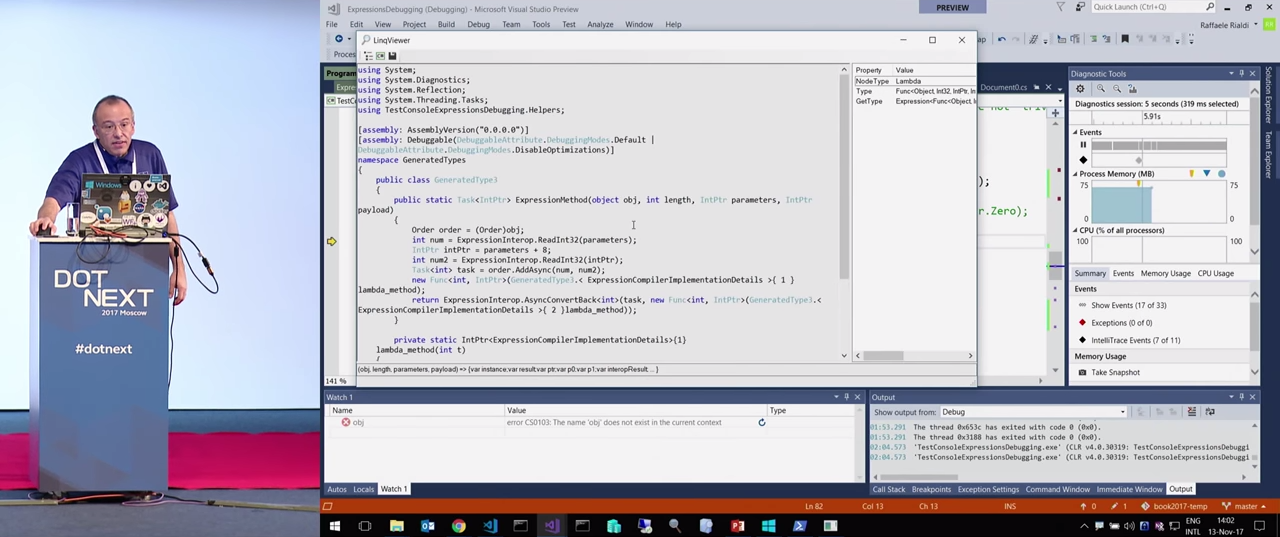
The code is quite confusing; it will not be possible to recompile it, since the compiler, Mono.Cecil , cannot create the perfect decompilation. Perhaps he will be able to do it in the future. In addition, the problem here is that for Task<int> it is necessary to inject an external function. This is because Expressions were created before asynchronous libraries and before changes in the compiler to support async / await. Therefore, it is impossible to generate with the compiler and use await. The compiler does all the magic, so if you use ILSpy and look at an artifact created with await, you will see a colback with a continuation there. The code is very complicated.
So where are we staying? We created Expressions to generate certain predicates, functions, fairly complex pieces of code with if-then-else, throw-catch, and more. Let's talk now about Roslyn.

Roslyn is a .NET compiler platform that for several years now has been working as the main compiler for C #. In other words, he rules our world. Before, we could do little, but Roslyn opened the API for us. Now, using the API of this compiler, we can directly do a lot of things. We have formatting, character information, you can compile different things, interpret characters, get into the metadata behind the assembler, and much more. As for the color marking, Roslyn does not control it directly. He does not indicate: "it must be green, and that - blue." Simply, there is a classification of the analyzed tokens, and they can be displayed in different ways.
Thus, we have a lot of tools available, but there is a problem. Roslyn does not have strict typing. There are syntax nodes, and they are very easy to use, since any element is a syntax node. There is no need to waste attention on connecting nodes with each other. But this has a downside. Without the very hard typing that gets on your nerves so much when you work with Expressions, we never know for sure whether the code we write will work correctly. Therefore, Roslyn has more chances of errors than in the code written with Expressions.
And yet, the benefits of Roslyn are great. They cover the whole language, i.e. any constructions can be created. For example, Roslyn can be accessed if you need to create new types during program execution. Suppose I want to create a DTO (Data Transfer Objects) of a non-existent object at runtime. I do not want to resort to using AutoMapper, since AutoMapper is usually used during development. The type created should be able to filter events, each of which will be of a different type. If you want to specify an Expression, you must create it and then work with the type representing this data. And for their deserialization, you need DTO.
The first and easiest way to generate code with Roslyn is a parser that has an API.

It analyzes the text, creates a syntax tree, with which you can continue to perform a variety of operations: change the format, make beautiful indents, convert. Suppose you need to refactor the API, change the names of variables, or replace the call, say, Console.WriteLine with Console.Write . Instead of creating everything from scratch, you can read the existing code, use it as a template, and replace only the necessary. The Visitor template is very well suited for this purpose. You can visit some of the tokens in the application, and, having found one, replace it. As you can see from the slide, formatting is very simple.
If this functionality is not enough, you can use SyntaxGenerator. This is a powerful high-level API, with a syntax factory under it. It can declare namespaces, classes, attributes, parameters, in other words, it is a full-fledged language. And using the node.AdjustWhitespace() command, you can make standard spaces between nodes.

For a start, look at a few examples of how this tool works. In the first one, we use SyntaxFactory , from which we get SyntaxTrivia , QualifiedName , CompilationUnit , UsingDirective . Perhaps you say - this is even worse than the trees Expressions. But what you see here is a low-level API. Knowing him is useful and can be explored using the Roslyn SDK. In it you can see how the syntax code tree is created, how the nodes in Roslyn are connected to each other. , , , , , -, , . , , .
, . . , , , , . , . -, . , . -, . - . .
Roslyn .
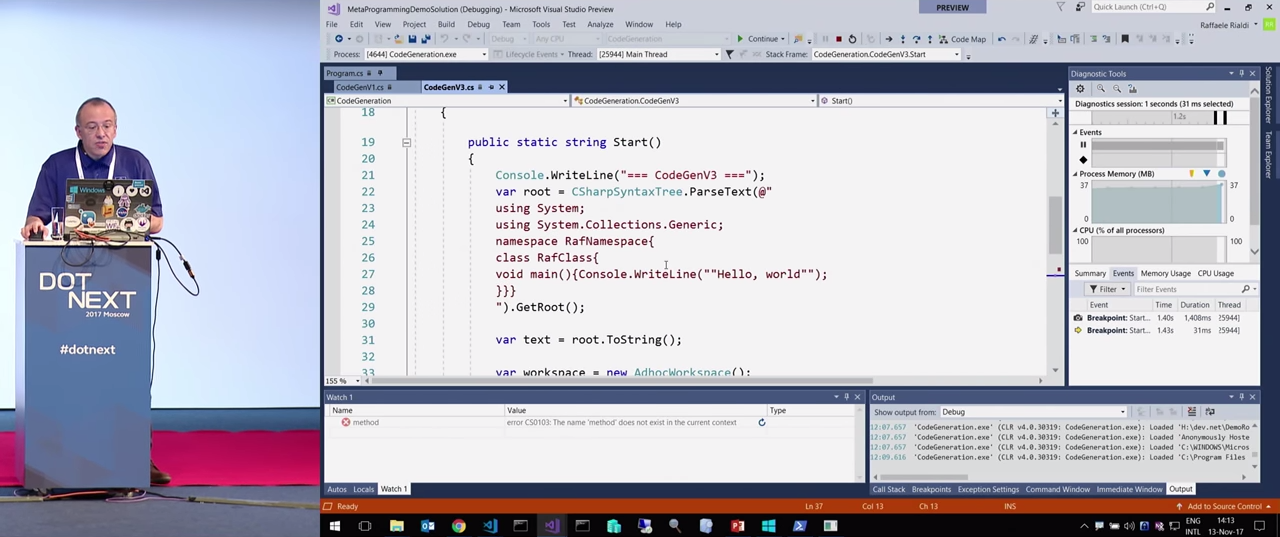
text :
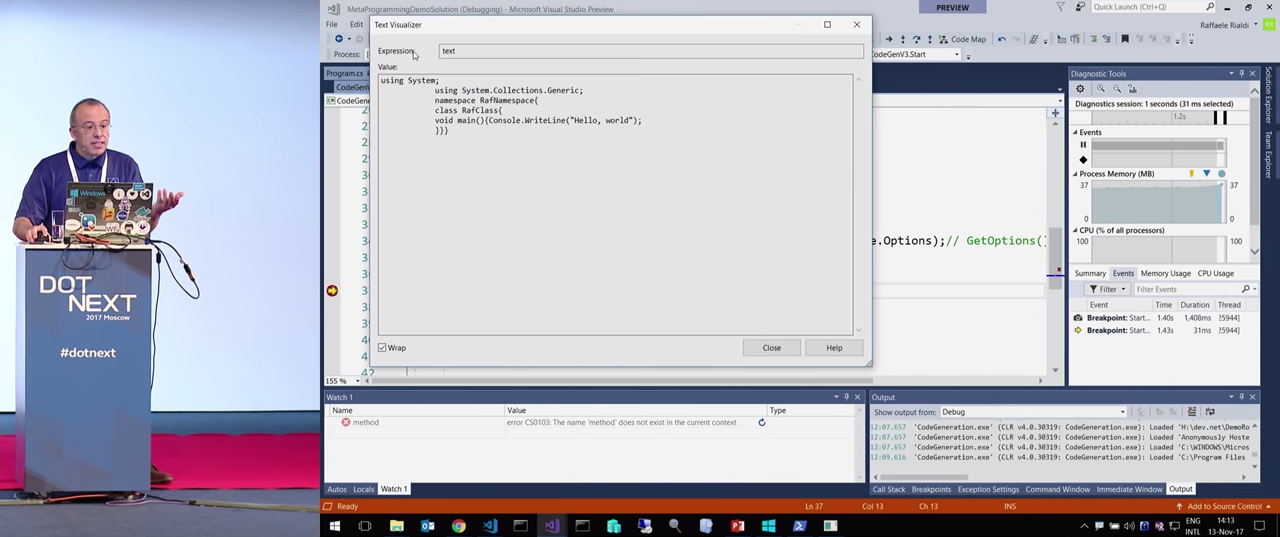
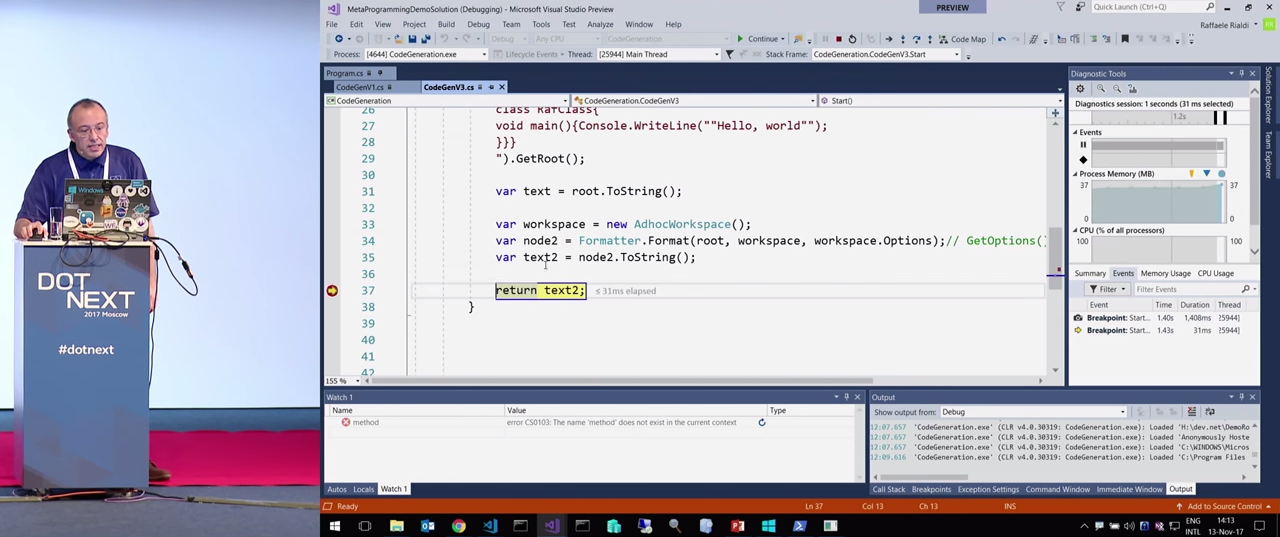
, ( text2 ):

, StringBuilder - .
.

:

PostProcess(SyntaxNode root) . , LINQ , , . , Console.WriteLine Console.Write . Console.ReadKey() . Console.Write Console.ReadKey .
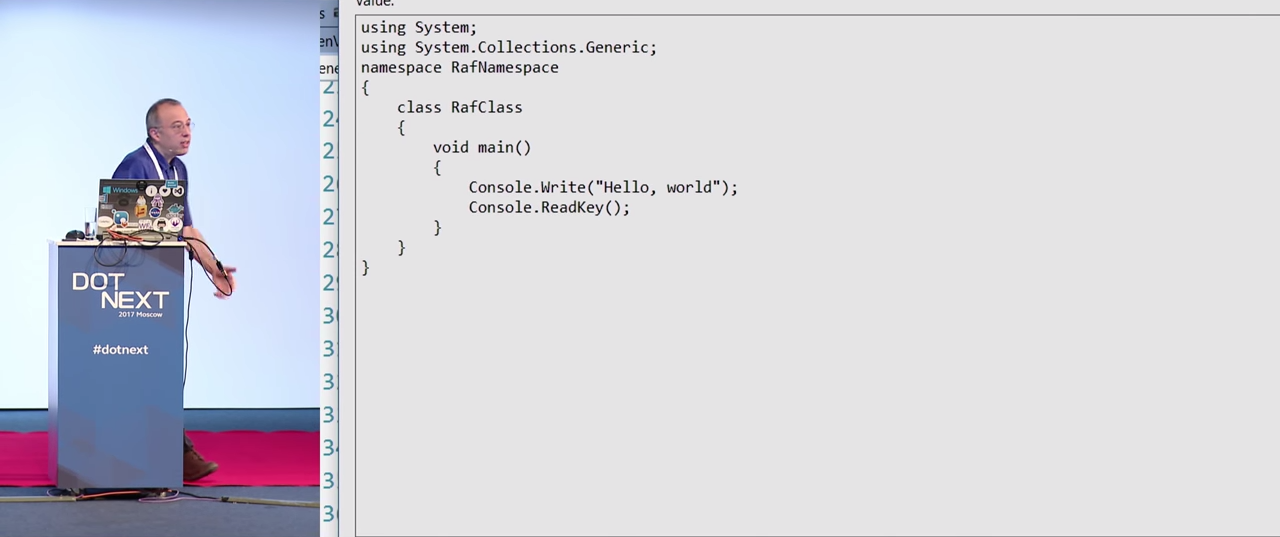
, . .
.
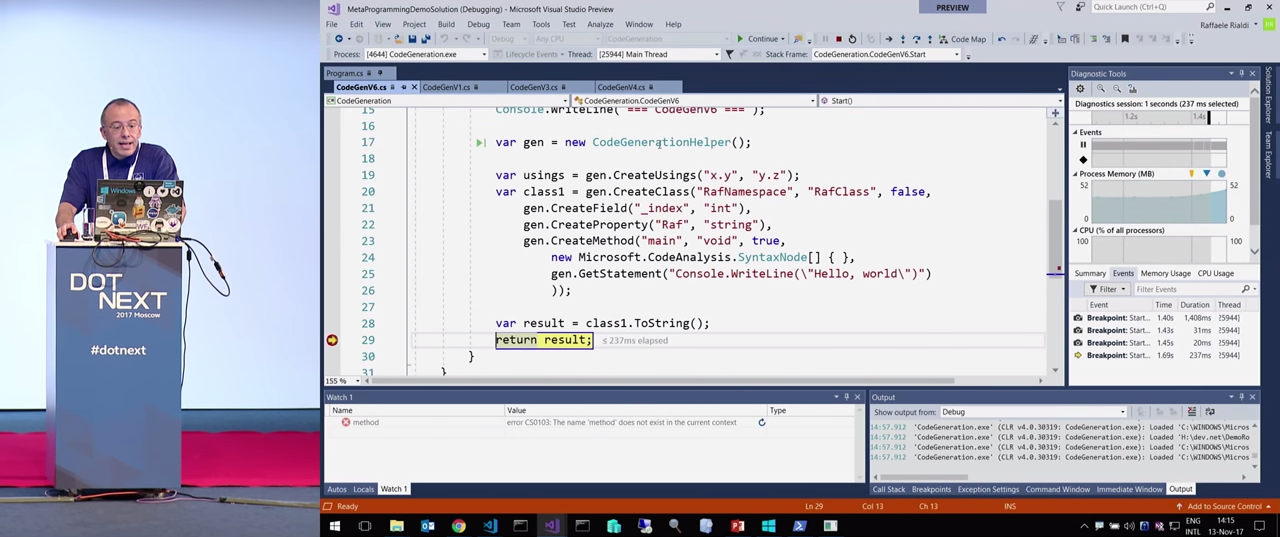
, CodeGenerationHelper() . SyntaxGenerator , , .
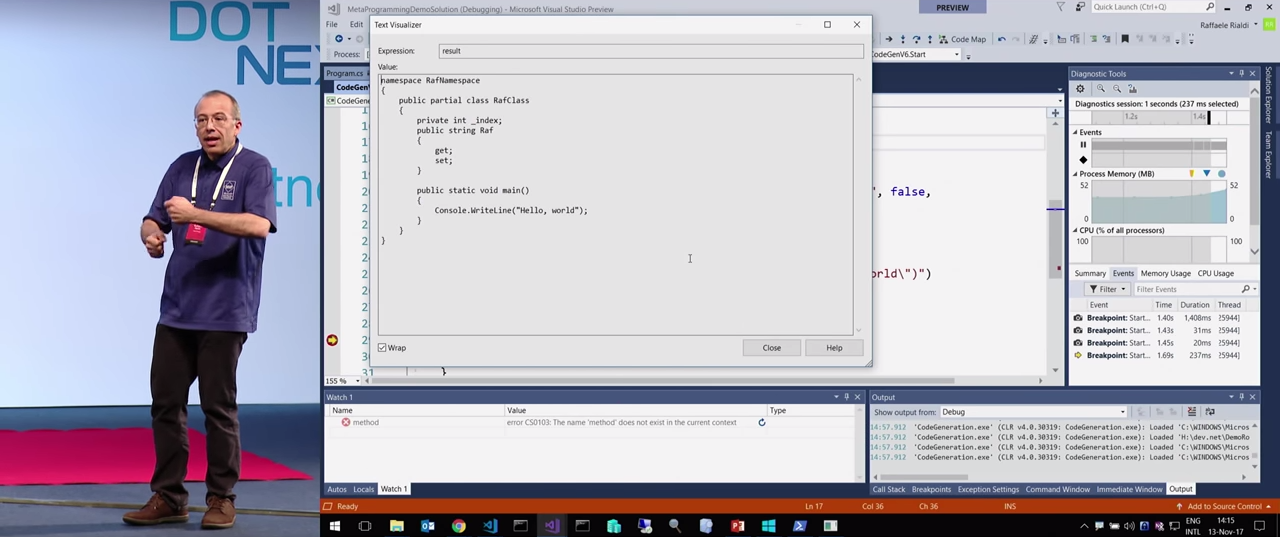
POCO DTO, .
, .

, ? , , , . . . , — . .
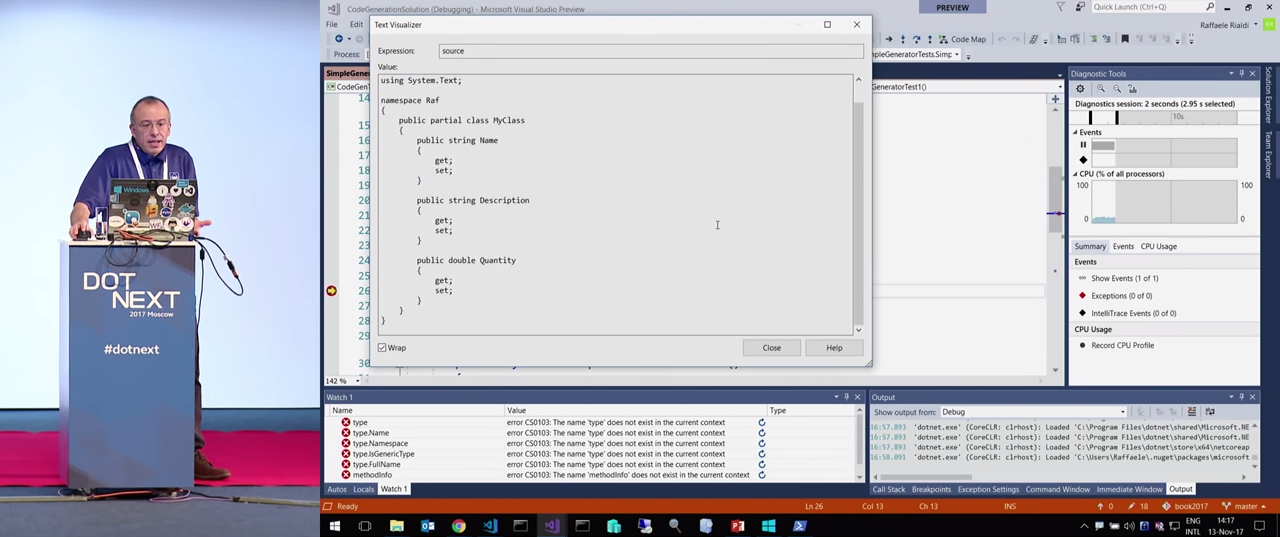
, , , , , DTO. , . , . , .
AddImplementINotifyPropertyChanged() .
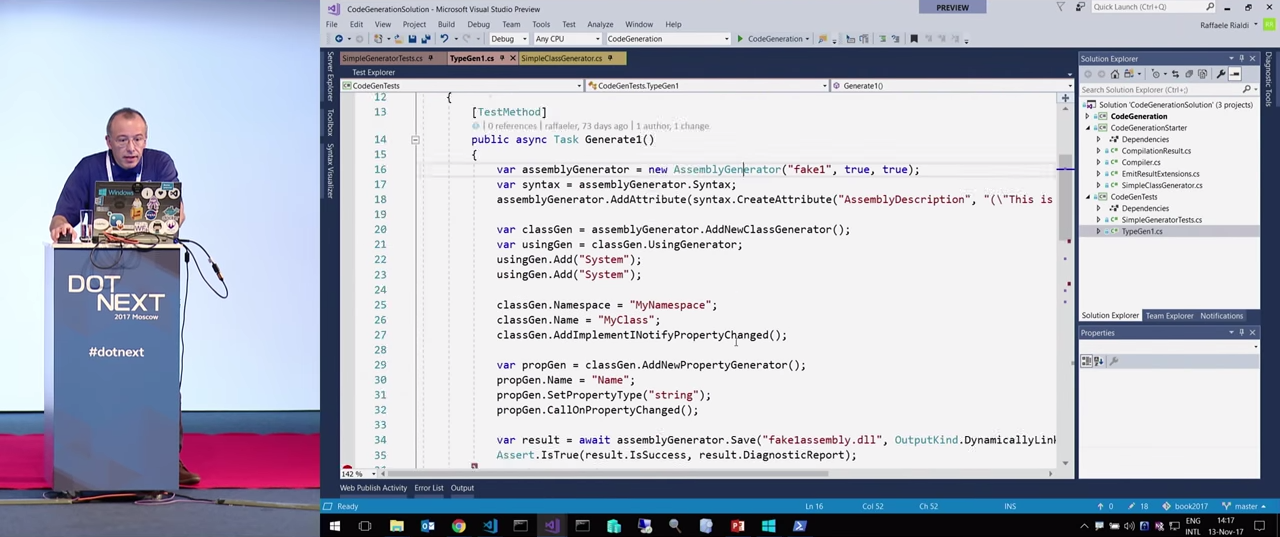
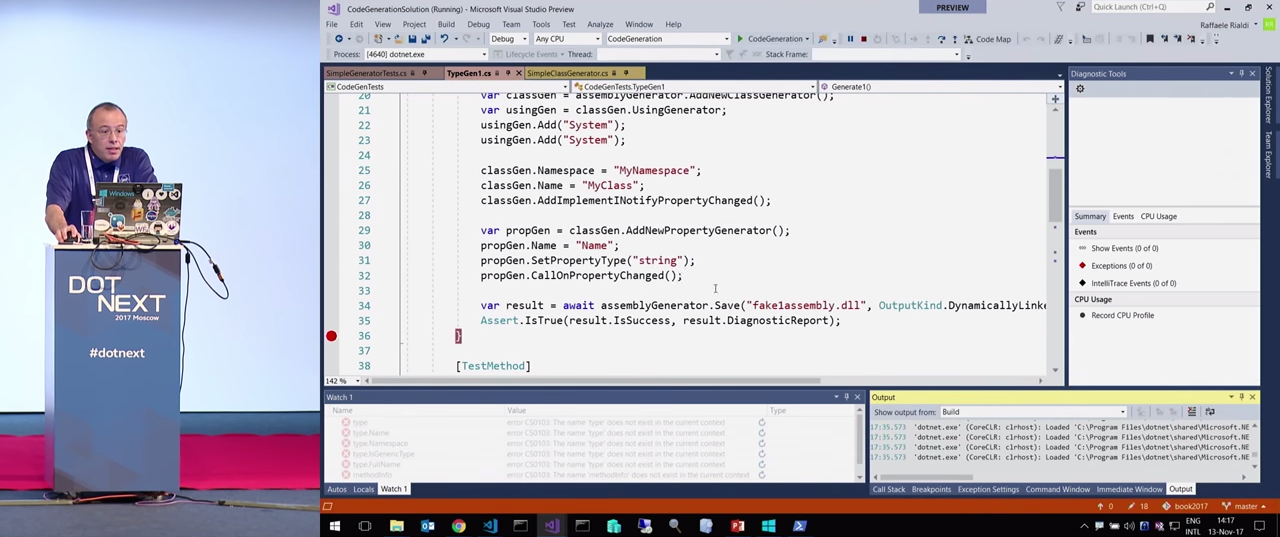
, result.DiagnosticReport , INotifyPropertyChanged .
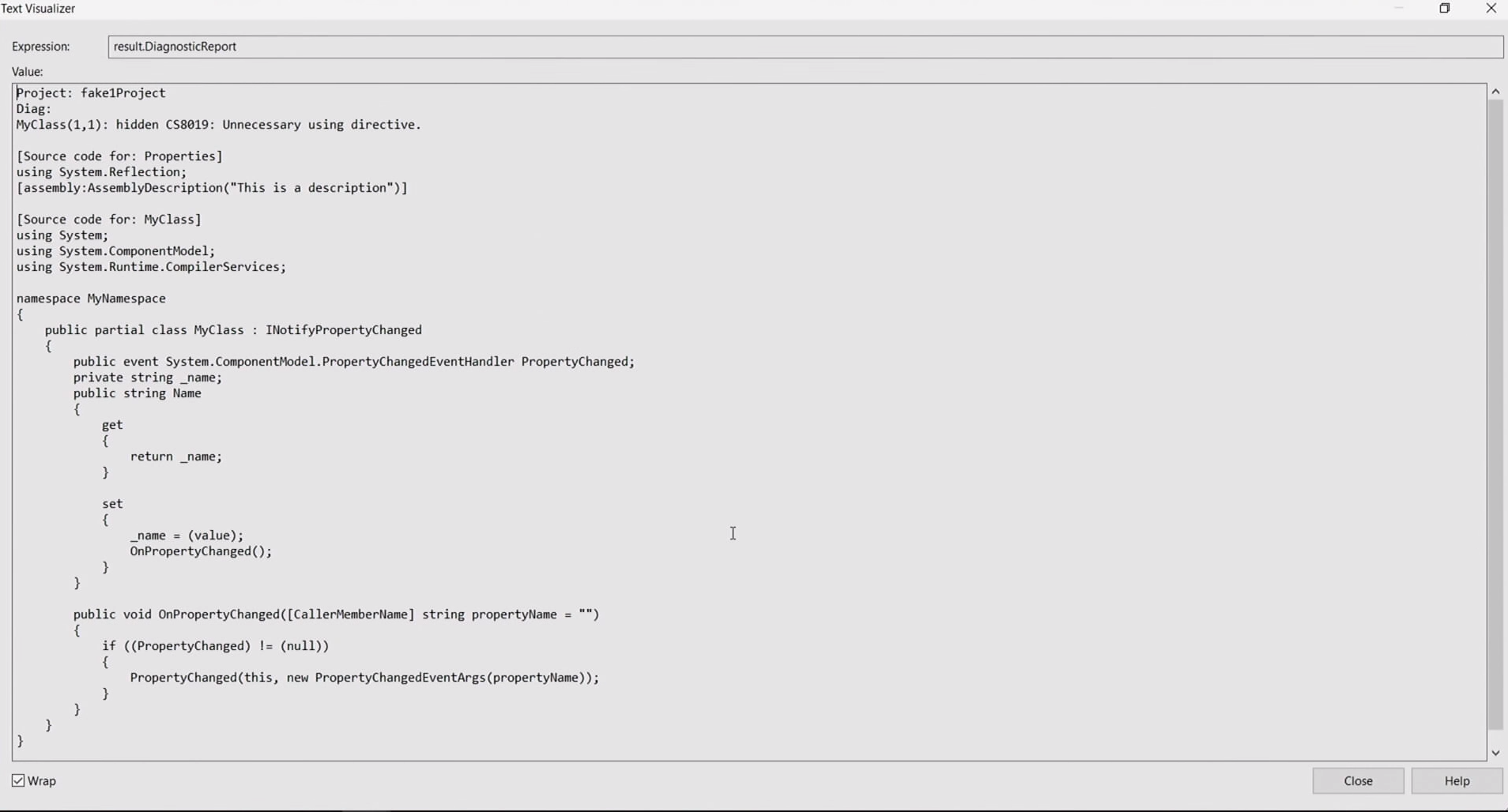
, string _name OnPropertyChanged() , OnPropertyChanged , [CallerMemberName] — . . , . . GitHub, .
— ? , — , SyntaxGenerator. , , , . , . SimpleClassGenerator .
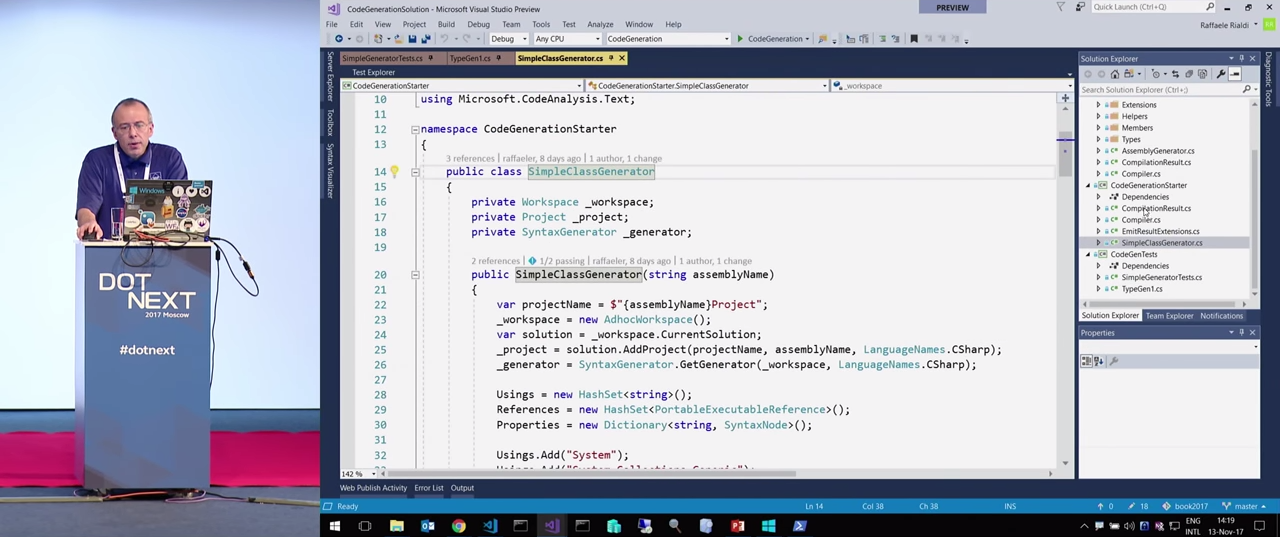
, HashSet<PortableExecutableReference> Reference , System.Runtime . , .NET Core, .NET Framework, — .NET Core, .

SimpleClassGenerator , IDictionary<string, Properties> Properties , . GetSource() , BuildClass() , .

-, CreateProperty() .
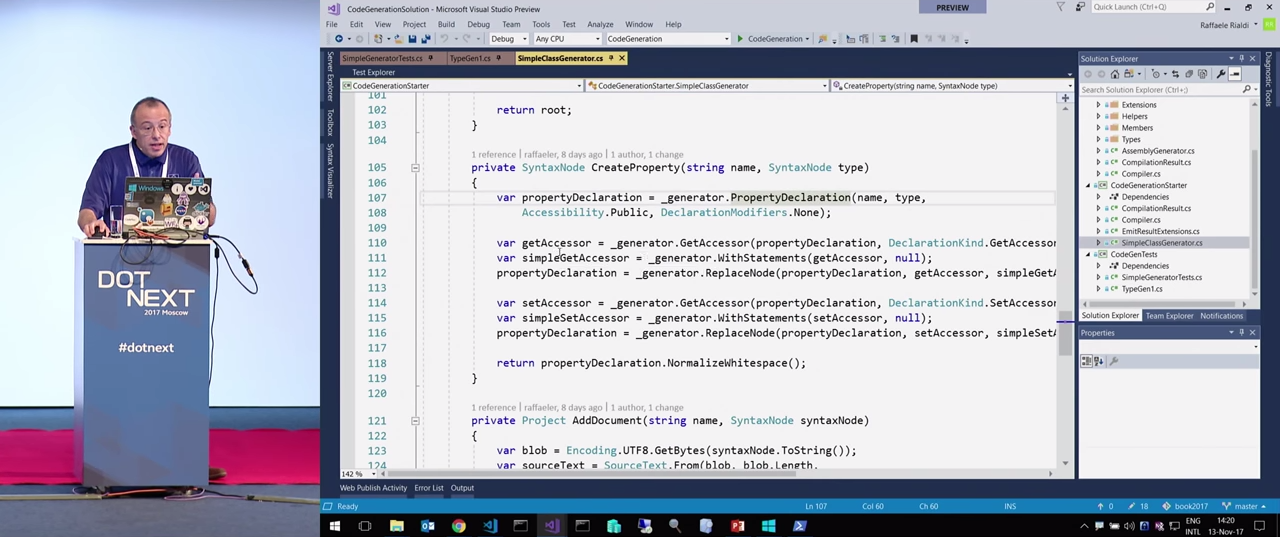
, , . , , . . backfield. . Accessor .
. , IL? , , , Reflection.Emit , . , . . x86-. , , . . - . , , « ». - , .
IL , , . , .dll, , . ILSpy . : , , . , . - , Visual Studio IL, . «F11», , .
, . , , . Mono.Cecil — . , , , , , . , . , GitHub , . , . , «F11» , IL, .
? sample1.dll , DataHelper , .

Employee DTO. Person , Printer , . , , Main , .

Start1 Person . Start2 , -, , , , Printer . , for-each ToList() . Linq , `Enumerable .
, . AssemblyHooker , (trap) .dll. VisualStudio Code, . , sample1.dll.
. , . , PlantUML ? , , , .
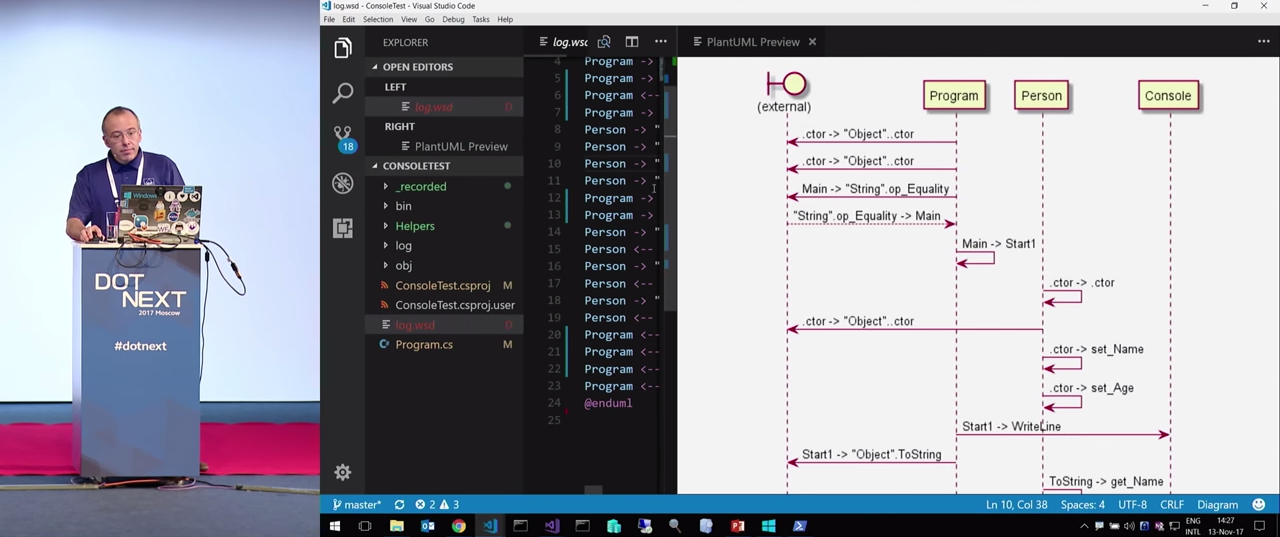
, . , . , . , , , WriteLine , . : Program , Person , Console . , .
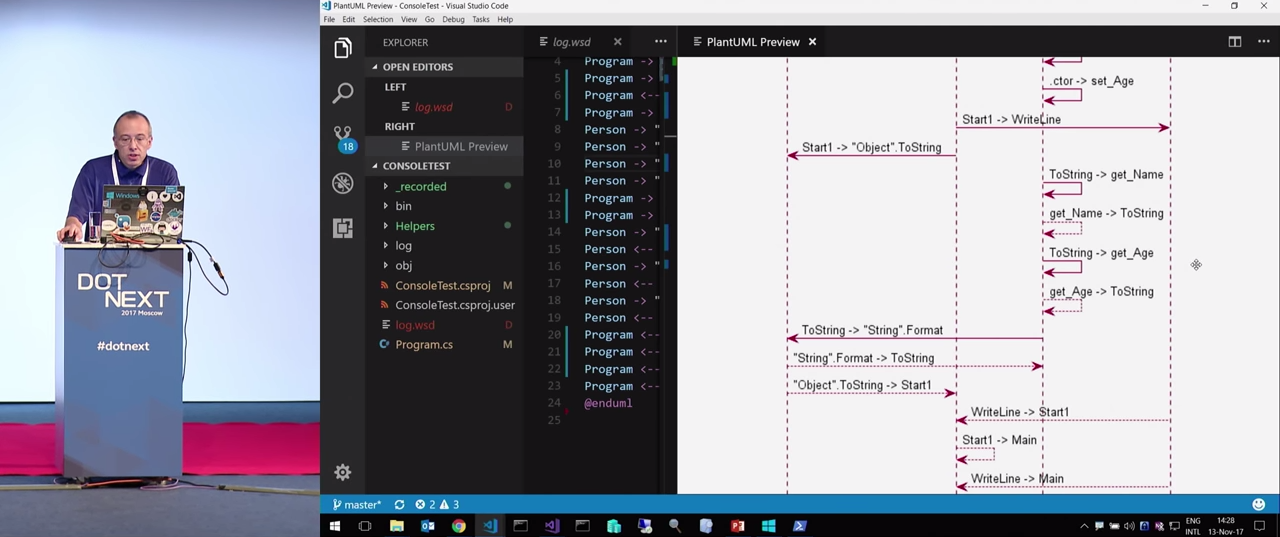
Main sample1.dll. . , . , , PlantUML . , Enumerable , . . , . , , . Main .
, , , IL . , -, , . IL .
, , , . , . : , , , . . ? . , , .
. , . , — Roslyn Quoter . , , Roslyn, . , Roslyn Quoter , .
. , , , . .NET — DotNext 2018 Piter . 22-23 2018 -. — YouTube . .NET . , , .
')
Source: https://habr.com/ru/post/353458/
All Articles